1. 功能
- Union: 合并两个集合
- Find: 查询两个元素是否在同一集合
特别注意每个集合本身的含义是什么!
2. 基本原理
并查集的重要思想在于,用集合中的一个元素代表集合。
每个集合用一棵树来表示,树根的编号就是整个集合的编号,每个节点存储它的父节点。根节点的父节点是它自己。
3. 问题
初始化
int[] p = new int[N];void init(){for (int i = 0; i < N; ++i)p[i] = i;}
如何判断一个节点是不是树根?
p[x] == x 说明该节点是树根
如何求
x所在的集合编号?int find(int x) {if (x == p[x])return x;return find(p[x]);}
如何查询两个元素是否在同一集合?
boolean isConnected(int x, int y) {return find(x) == find(y);}
如何合并两个集合?
px是x的集合编号,py是y的集合编号p[px] = py 或者 p[py] = px
void merge(int x, int x){p[find(x)] = find(y);//或者//p[find(y)] = find(x);}
采用递归的思想 p[x] = find(p[x])
int find(int x) {return x == p[x] ? x : (p[x] = find(p[x]))}
- 按秩合并
根据树的高度,低的向高的上合并。不常用
//使用rank数组记录以每个元素为根节点的子树最大深度(不一定就是树的深度,因为有路径压缩的存在),初始化每个元素自成一树,rank[i] = 1int[] p = new int[N];int[] rank = new int[N];void init() {for (int i = 0; i < N; i++) {p[i] = i;rank[i] = 1;}}void merge(int x, int y) {//先找到两个根节点int px = find(x), py = find(y);if (p[px] == p[py])return;else if (rank[px] <= rank[py]) {p[px] = py;rank[py] = rank[py] == rank[px] ? rank[py] + 1 : rank[py];} else {p[py] = px;}}
例如,合并7和8,右边的树一定优于左边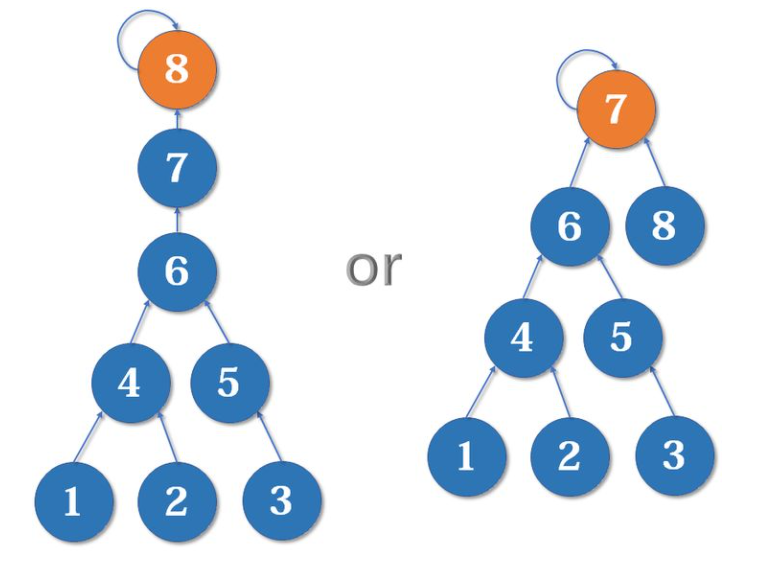
5. 用类包装好并查集
6. 带邻域的并查集
1. 集合大小
绑定到根节点
2. 到根节点的距离/偏移量
每个子节点到其父节点的距离
7. 扩展并查集
一般的并查集每个集合内是一个个元素,而扩展域并查集每个集合内是一个个条件
8. 例题
1. 经典并查集
836. 合并集合
一共有 n 个数,编号是 1∼n,最开始每个数各自在一个集合中。
现在要进行 m 个操作,操作共有两种:
M a b,将编号为 a 和 b 的两个数所在的集合合并,如果两个数已经在同一个集合中,则忽略这个操作;Q a b,询问编号为 a 和 b 的两个数是否在同一个集合中;
输入格式
第一行输入整数 n 和 m。
接下来 m 行,每行包含一个操作指令,指令为 M a b 或 Q a b 中的一种。
输出格式
对于每个询问指令 Q a b,都要输出一个结果,如果 a 和 b 在同一集合内,则输出 Yes,否则输出 No。
每个结果占一行。
数据范围
1≤n,m≤105
输入样例:
4 5M 1 2M 3 4Q 1 2Q 1 3Q 3 4
输出样例:
YesNoYes
import java.util.*;import java.io.*;public class Main {public static void main(String[] sss) throws IOException{BufferedReader br = new BufferedReader(new InputStreamReader(System.in));BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));String[] str = br.readLine().split(" ");int n = Integer.parseInt(str[0]);int m = Integer.parseInt(str[1]);int[] a = new int[n + 1];for (int i = 1; i <= n; i++) a[i] = i;while (m -- > 0) {str = br.readLine().split(" ");int x, y;x = Integer.parseInt(str[1]);y = Integer.parseInt(str[2]);switch (str[0]) {case "M" :a[find(a, x)] = find(a, y);break;case "Q":if (find(a, x) == find(a, y)) {bw.write("Yes\n");} else {bw.write("No\n");}}}br.close();bw.close();}static int find(int[] a, int x) {int cur = x;while (cur != a[cur]) {cur = a[cur];}while (x != cur) {int nx = a[x];a[x] = cur;x = nx;}return cur;}static int find(int[] a, int x) {return a[x] == x ? x : (a[x] = find(a[x]));}}
2. 带邻域的并查集

带权并查集
import java.util.*;public class Main {static final int N = 30010;//fa为并查集数组,size只对每个并查集根节点有效,表示该集合元素个数//d为距离数组,表示该点到其父节点之间排了多少个元素static int[] fa = new int[N], size = new int[N], d = new int[N];static {for (int i = 0; i < N; i++) {fa[i] = i;size[i] = 1;}}public static void main(String[] args) {Scanner sc = new Scanner(System.in);int t = sc.nextInt();while (t-- > 0) {String op = sc.next();int a = sc.nextInt(), b = sc.nextInt();int pa = find(a), pb = find(b);if (op.equals("M")) {fa[pa] = pb;d[pa] = size[pb];size[pb] += size[pa];} else {if (pa != pb)System.out.println(-1);else//有点类似与前缀和的思想,因为在调用query前调用了find,所以query查询的结果一定是该点到根节点的距离System.out.println(Math.max(0, Math.abs(query(a) - query(b)) - 1));}}}//find变形//在路径压缩压缩的同时由于该点的父节点发生了变化(变成了根节点),所以要更新该点到其父节点的距离static int find(int x) {if (fa[x] != x) {int root = find(fa[x]);d[x] += d[fa[x]];fa[x] = root;}return fa[x];}static int query(int x) {return d[x];}}
3. 扩展并查集
小 A 和小 B 在玩一个游戏。
首先,小 A 写了一个由 0 和 1 组成的序列 S,长度为 N。
然后,小 B 向小 A 提出了 M 个问题。
在每个问题中,小 B 指定两个数 l 和 r,小 A 回答 S[l∼r] 中有奇数个 1 还是偶数个 1。
机智的小 B 发现小 A 有可能在撒谎。
例如,小 A 曾经回答过 S[1∼3] 中有奇数个 1,S[4∼6] 中有偶数个 1,现在又回答 S[1∼6] 中有偶数个 1,显然这是自相矛盾的。
请你帮助小 B 检查这 M 个答案,并指出在至少多少个回答之后可以确定小 A 一定在撒谎。
即求出一个最小的 k,使得 01 序列 S 满足第 1∼k 个回答,但不满足第 1∼k+1 个回答。
输入格式
第一行包含一个整数 N,表示 01 序列长度。
第二行包含一个整数 M,表示问题数量。
接下来 M 行,每行包含一组问答:两个整数 l 和 r,以及回答 even 或 odd,用以描述 S[l∼r] 中有偶数个 1 还是奇数个 1。
输出格式
输出一个整数 k,表示 01 序列满足第 1∼k 个回答,但不满足第 1∼k+1 个回答,如果 01 序列满足所有回答,则输出问题总数量。
数据范围
N≤109,M≤10000
输入样例:
10
5
1 2 even
3 4 odd
5 6 even
1 6 even
7 10 odd
输出样例:
3
方法1:带邻域的并查集
每个集合的含义是集合中的元素两两之间有关系,至于是什么关系,体现在每个元素的邻域中,即其到集合根节点的距离/偏移量。
import java.util.*;public class Main {static final int N = 20010;static int idx = 0;static int[] fa = new int[N], d = new int[N];static Map<Integer, Integer> map = new HashMap<>();static {for (int i = 0; i < N; i++)fa[i] = i;}static int get(int x) {if (!map.containsKey(x)) {map.put(x, idx);return idx++;}return map.get(x);}public static void main(String[] args) {Scanner sc = new Scanner(System.in);int n = sc.nextInt(), m = sc.nextInt();int res = m;for (int i = 0; i < m; i++) {int a = sc.nextInt() - 1, b = sc.nextInt();String op = sc.next();a = get(a);b = get(b);int t = 0;if (op.equals("odd"))t = 1;int pa = find(a), pb = find(b);if (pa == pb) {if ((d[a] ^ d[b]) != t) {res = i;break;}} else {fa[pa] = pb;d[pa] = d[a] ^ d[b] ^ t;}}System.out.println(res);}static int find(int x) {if (x != fa[x]) {int root = find(fa[x]);d[x] ^= d[fa[x]];fa[x] = root;}return fa[x];}}
本题离散化无需保序,因为转化为前缀和之后只涉及到两个独立点的关系,即 s[r] 与 s[l - 1]
方法2:扩展域并查集
import java.util.*;public class Main {static final int N = 40010;static int idx;static int[] fa = new int[N];static Map<Integer, Integer> map = new HashMap<>();static {for (int i = 0; i < N; i++) {fa[i] = i;}}static int get(int x) {if (!map.containsKey(x)) {map.put(x, idx);return idx++;}return map.get(x);}public static void main(String[] args) {Scanner sc = new Scanner(System.in);int n = sc.nextInt(), m = sc.nextInt();n = N / 2;int res = m;for (int i = 0; i < m; i++) {int a = sc.nextInt() - 1, b = sc.nextInt();String op = sc.next();a = get(a);b = get(b);int pa = find(a), pb = find(b), pa2 = find(a + n), pb2 = find(b + n);if (op.equals("even")) {if (pa == pb2) {res = i;break;}fa[pa] = pb;fa[pa2] = pb2;} else {if (pa == pb) {res = i;break;}fa[pa] = pb2;fa[pa2] = pb;}}System.out.println(res);}static int find(int x) {return x == fa[x] ? x : (fa[x] = find(fa[x]));}}

若有收获,就点个赞吧
0 人点赞
