本人是个资深彩民,每周都会在彩票上花上50-100块钱买彩票,虽说一直没中。 上网时,经常听到别人讨论说,彩票是8点钟禁售,9点15分开奖,很多人都会想,这一个半时内,福彩中心会不会算一个最小人买的彩票呢。 刚好,最近在学买流式计算,尝试着用这个来算一下最小得奖。 当然,写这个东东没有说彩票造假,也没有特别的意思,只是想将学到的东西用起来的尝试。
- 设计:
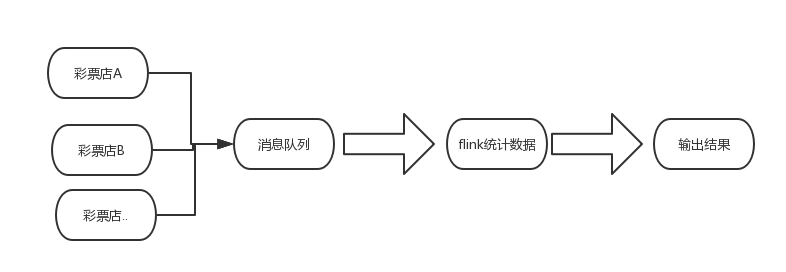
- 把各个彩票站做一个客户端,所有彩票站都发送到一个消息队列(kafak),发送单注消息到kafka中。有人会说,彩票有复式的,这里我不管,因为复式也可以拆成多个单式.
- flink读取kafka的彩票数据,进行统计,统计最小的得奖结果,并输出结果
人员架构.jpg
- 算法: 如何用最简单的办法,算出哪一注是最小人买 的呢。 这里我换了个概念,具体如下:
- 将所有有可能选择的彩票结果都初始为1,都认为有人买了,共1107568组合
- 随机生成彩票,发送到kafka中
- flink把所有彩票都当成字符串(注意这个字符串是有序的),进行统计,统计出现最小的彩票 这样彩票的统计就变成统计最小的词频,这个统计词频的例子在flink里就有了。
随机生成彩票 示例生成代码如下:
public class BallCase {/*** 初始化所有红球*/private static ArrayList<Integer> redBalls = new ArrayList<Integer>();/*初始化所有蓝球*/private static ArrayList<Integer> blueBalls = new ArrayList<Integer>();/*** 初始化数据*/static {for (int i = 1; i <= 33; i++) {redBalls.add(i);}for (int i = 1; i <= 16; i++) {blueBalls.add(i);}}private static Properties kafkaProps = new Properties();static {kafkaProps.put("bootstrap.servers", "127.0.0.1:9092");kafkaProps.put("acks", "all");kafkaProps.put("retries", 0);kafkaProps.put("batch.size", 16384);kafkaProps.put("linger.ms", 1);kafkaProps.put("buffer.memory", 33554432);kafkaProps.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");kafkaProps.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");}/*** 随机生成6个红球* @return*/private List<String> chooseRedBall() {List<Integer> resultRedBalls = new ArrayList<>();List<Integer> redBallsClone = (ArrayList<Integer>) redBalls.clone();int[] ballorder = {33, 32, 31, 30, 29, 28};for (int i = 0; i < ballorder.length; i++) {int choseRed = this.chooseBall(ballorder[i]);resultRedBalls.add(redBallsClone.get(choseRed));redBallsClone.remove(choseRed);}return resultRedBalls.stream().sorted().map(String::valueOf).collect(Collectors.toList());}/*** 随机生成1个蓝球* @return*/private String chooseBlueBall() {int choseBlue = this.chooseBall(16);return blueBalls.get(choseBlue) + "";}/*** 生成随机数* @param ranger* @return*/private Integer chooseBall(int ranger) {Random random = new Random();return random.nextInt(ranger);}/*** 获取随机双色球* @return*/private String getRandomBall() {List<String> balls = this.chooseRedBall();balls.add(this.chooseBlueBall());return String.join(",", balls);}public static void main(String[] args) {BallCase ballCase = new BallCase();Long statTime = Instant.now().getEpochSecond();//初始化所有双色球选项for (int ball1 = 1; ball1 < 29; ball1++) {for (int ball2 = ball1+1; ball2 < 30; ball2++) {for (int ball3 = ball2+1; ball3 < 31; ball3++) {for (int ball4 = ball3+1; ball4 < 32; ball4++) {for (int ball5 = ball4+1; ball5 < 33; ball5++) {for (int ball6 = ball5+1; ball6 < 34; ball6++) {for (int ball7 =1; ball7<=16; ball7++) {ballCase.sendKafka(ball1+","+ball2+","+ball3+","+ball4+","+ball5+","+ball6+","+ball7 );}}}}}}}Long endTime = Instant.now().getEpochSecond();System.out.println(endTime - statTime);System.out.println(statTime);System.out.println(endTime);System.out.println("开始时间:"+new Date());//随机生成双色球数目for (int ball1 = 1; ball1 < 186864001; ball1++) {ballCase.sendKafka(ballCase.getRandomBall());}System.out.println("结束时间:"+new Date());}/*** 发送到kafka* @param balls*/public void sendKafka(String balls) {System.out.println(balls);Producer<String, String> producer = new KafkaProducer<>(kafkaProps);producer.send(new ProducerRecord<>("test", balls), new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata, Exception exception) {if (exception != null) {System.out.println("Failed to send message with exception " + exception);}}});producer.close();}}
流式计算统计最小复奖 flink写这个很简单,代码如下:
public class KafkaDeme {public static void main(String[] args) throws Exception {// set up the streaming execution environmentfinal StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 告诉系统按照 EventTime 处理env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);// 为了打印到控制台的结果不乱序,我们配置全局的并发为1,改变并发对结果正确性没有影响env.setParallelism(1);//默认情况下,检查点被禁用。要启用检查点,请在StreamExecutionEnvironment上调用enableCheckpointing(n)方法,// 其中n是以毫秒为单位的检查点间隔。每隔5000 ms进行启动一个检查点,则下一个检查点将在上一个检查点完成后5秒钟内启动env.enableCheckpointing(5000);env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);Properties properties = new Properties();properties.setProperty("bootstrap.servers", "127.0.0.1:9092");//kafka的节点的IP或者hostName,多个使用逗号分隔properties.setProperty("zookeeper.connect", "127.0.0.1:2181");//zookeeper的节点的IP或者hostName,多个使用逗号进行分隔properties.setProperty("group.id", "test-consumer-group");//flink consumer flink的消费者的group.idFlinkKafkaConsumer09<String> myConsumer = new FlinkKafkaConsumer09<String>("test", new SimpleStringSchema(),properties);//test0是kafka中开启的topicDataStream<String> keyedStream = env.addSource(myConsumer);//将kafka生产者发来的数据进行处理,本例子我进任何处理//计数DataStream<Tuple2<String, Integer>> ds= keyedStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {@Overridepublic void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {System.out.println(s);collector.collect(new Tuple2<String, Integer>(s, 1));}});DataStream<Tuple2<String, Integer>> wcount = ds.keyBy(0) //按照Tuple2<String, Integer>的第一个元素为key,也就是单词.window(SlidingProcessingTimeWindows.of(Time.minutes(2),Time.minutes(1)))//key之后的元素进入一个总时间长度为600s,每20s向后滑动一次的滑动窗口.sum(1);;DataStream<Tuple2<String, Integer>> ret = wcount.windowAll(TumblingProcessingTimeWindows.of(Time.minutes(1)))//所有key元素进入一个20s长的窗口(选20秒是因为上游窗口每20s计算一轮数据,topN窗口一次计算只统计一个窗口时间内的变化).process(new TopNAllFunction(1));//计算该窗口TopNret.writeAsText("D:\\logs\\log.txt",FileSystem.WriteMode.OVERWRITE);// execute programenv.execute("Flink Streaming Java API Skeleton");}private static class TopNAllFunctionextends ProcessAllWindowFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, TimeWindow> {private int topSize = 10;public TopNAllFunction(int topSize) {this.topSize = topSize;}@Overridepublic void process(ProcessAllWindowFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, TimeWindow>.Context arg0,Iterable<Tuple2<String, Integer>> input,Collector<Tuple2<String, Integer>> out) throws Exception {TreeMap<Integer, Tuple2<String, Integer>> treemap = new TreeMap<Integer, Tuple2<String, Integer>>(new Comparator<Integer>() {@Overridepublic int compare(Integer y, Integer x) {return (x < y) ? 1 : -1;}}); //treemap按照key降序排列,相同count值不覆盖for (Tuple2<String, Integer> element : input) {treemap.put(element.f1, element);if (treemap.size() > topSize) { //只保留前面TopN个元素treemap.pollLastEntry();}}for (Map.Entry<Integer, Tuple2<String, Integer>> entry : treemap.entrySet()) {out.collect(entry.getValue());}}}}
验证
- 当数据很小时,很快就算出结果,基本是秒出。
- 当以大数据处理时,并且时间窗口调成一个小时,发现kafka的数据处理不过来了。当然这个可能是我本机即是服务端,客户端有关系.如果有更好的机子,估计会更快. flink是刚学习的,不一定正确,只是个玩票的,如果有发现问题,请留言。 文章写完了,赶紧再去买几注彩票压压惊。

若有收获,就点个赞吧
0 人点赞
