读取纯文本
最近遇到一个问题,需要读取MsigDB/h.all.v7.2.symbols.gmt 文件进行分析:
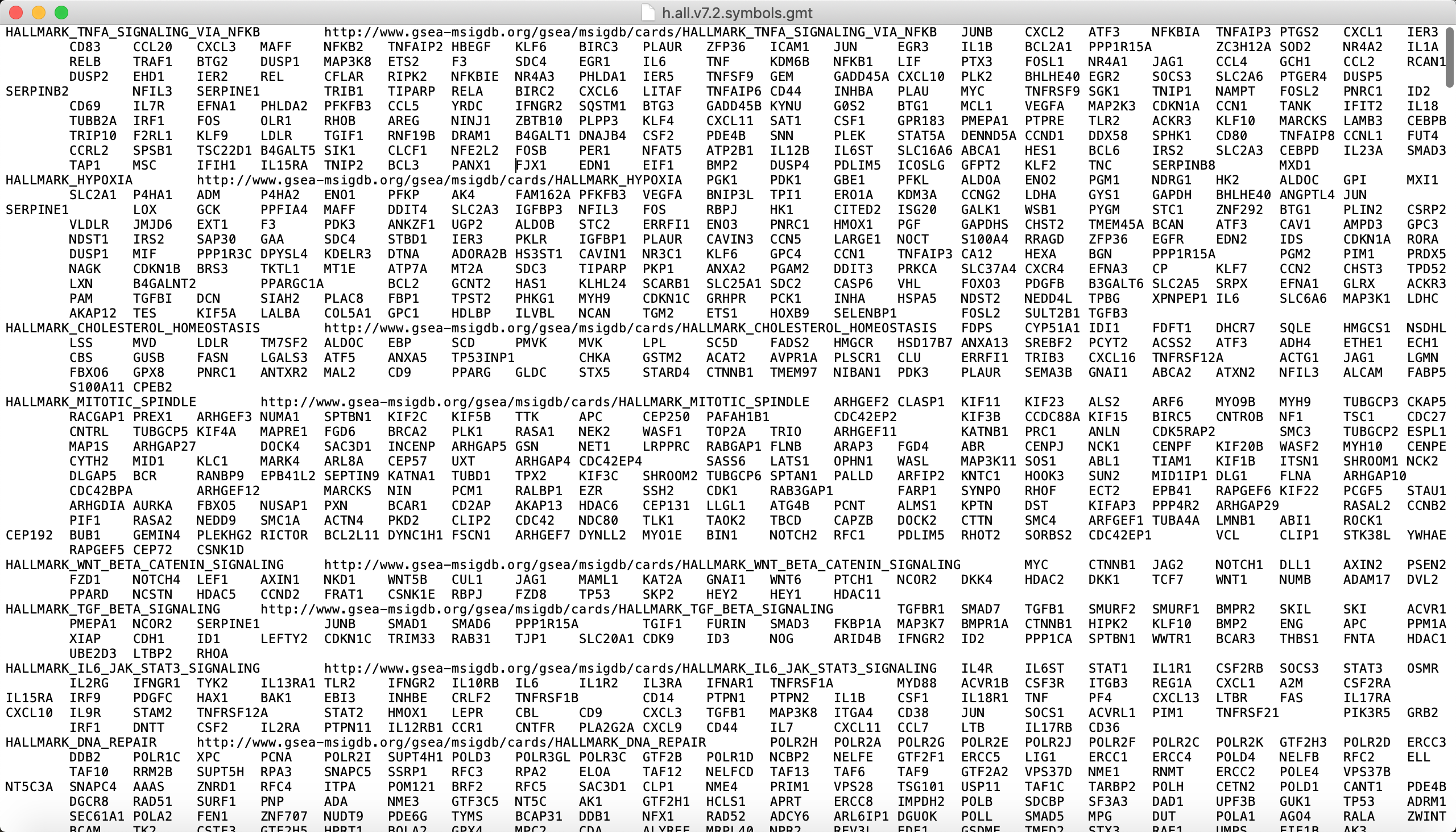
这个文件有点奇葩呀,应该是对应每个开头的两个字符对应通路名和通路的网页注释页面,而字符与字符间通过制表符 \t 间隔,而每一组(通路名开头)文字间,通过换行符 \n 间隔:

尝试用read.table 读取一下:
> a <- read.table("MsigDB/h.all.v7.2.symbols.gmt")Error in scan(file = file, what = what, sep = sep, quote = quote, dec = dec, :line 3 did not have 202 elements
看来是不等长的内容。
这时候就祭出readLines 函数。
类似py 中的readlines 方法,同样,R 的函数也会逐行(识别)
x_line <- readLines("MsigDB/h.all.v7.2.symbols.gmt")
ps:发现对于gmt 已经有成熟的函数read.gmt 了:

纯文本-> 列表
果然文本按照换行符分隔为50个向量,readLines 会按照换行符分隔读取,每个换行符读取一个元素:
> length(x_line)[1] 50> sapply(as.list(x_line[1:2]), function(x) substr(x, 1, 100))[1] "HALLMARK_TNFA_SIGNALING_VIA_NFKB\thttp://www.gsea-msigdb.org/gsea/msigdb/cards/HALLMARK_TNFA_SIGNALIN"[2] "HALLMARK_HYPOXIA\thttp://www.gsea-msigdb.org/gsea/msigdb/cards/HALLMARK_HYPOXIA\tPGK1\tPDK1\tGBE1\tPFKL\tA"
‘strsplit 函数将文本按照换行符切割:
x_split <- strsplit(x_line, "\t")
每个向量会被按照指定符号切割,每个向量会被转换为列表对象,列表中的元素为按照换行符拆开的一个个元素。
接着我们需要将该列表元素再进行一些处理:
names(x_split) <- vapply(x_split, function(x) x[1], character(1)) # 将每个列表的第一个元素,也就是通路名,作为列表名x_split <- lapply(x_split, "[",-c(1,2)) # 删除每个列表中的前两个元素# 这里 "[" 方法可以理解为 function(x) x[-c(1,2)]length(names(x_split))head(names(x_split))[1] "HALLMARK_TNFA_SIGNALING_VIA_NFKB"[2] "HALLMARK_HYPOXIA"[3] "HALLMARK_CHOLESTEROL_HOMEOSTASIS"[4] "HALLMARK_MITOTIC_SPINDLE"[5] "HALLMARK_WNT_BETA_CATENIN_SIGNALING"[6] "HALLMARK_TGF_BETA_SIGNALING"
纯文本-> 数据框
直接do.call 连接就可:
test <- do.call('cbind', x_split)> test[1:5,1:5]HALLMARK_TNFA_SIGNALING_VIA_NFKB HALLMARK_HYPOXIA[1,] "JUNB" "PGK1"[2,] "CXCL2" "PDK1"[3,] "ATF3" "GBE1"[4,] "NFKBIA" "PFKL"[5,] "TNFAIP3" "ALDOA"HALLMARK_CHOLESTEROL_HOMEOSTASIS HALLMARK_MITOTIC_SPINDLE[1,] "FDPS" "ARHGEF2"[2,] "CYP51A1" "CLASP1"[3,] "IDI1" "KIF11"[4,] "FDFT1" "KIF23"[5,] "DHCR7" "ALS2"HALLMARK_WNT_BETA_CATENIN_SIGNALING[1,] "MYC"[2,] "CTNNB1"[3,] "JAG2"[4,] "NOTCH1"[5,] "DLL1"
但对于不等长的列表元素,一定要小心使用cbind 连接,因为不等长的连接会自动删除那些过长的列表中的元素(木桶中最短的那根板)

若有收获,就点个赞吧
0 人点赞
