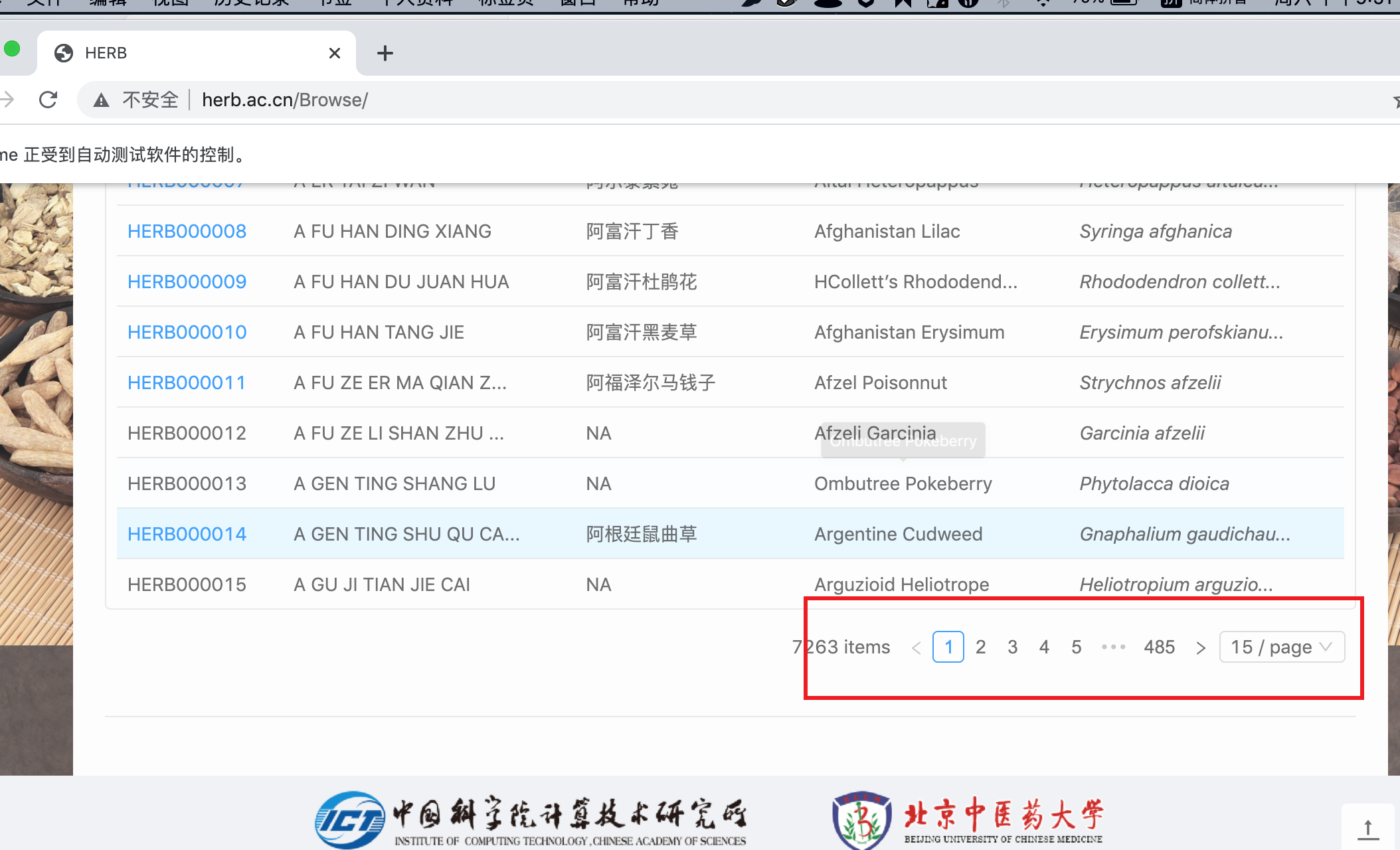
这里主要是因为有些网站是非静态的,比如下面的内容就是通过动态翻页实现的(简单理解的话,就是不同的页面均显示为一个地址):
1. 下载及安装
首先是chromedriver 与selenium server 的配置:
参见:https://blog.csdn.net/weixin_40628687/article/details/78971934
java -Dwebdriver.chrome.driver="/Users/appe/Desktop/B.计算机学习笔记/R练习/爬虫/selenium_file/chromedriver" -jar /Users/appe/Desktop/B.计算机学习笔记/R练习/爬虫/selenium_file/selenium-server-standalone-3.141.59.jar
首先是两个包:
install_github("crubba/Rwebdriver")install.packages("RSelenium")
ps: 这里真的非常的玄学。
我之前用mac 一直装不上,这次直接换win 尝试,发现又出现了之前的问题:

很显然是电脑找不到我的chromedriver了。(然而我该添加环境变量都添加了啊~~~)
而mac 这边,则是一下就成功了。

ps:今天刚开始也用不了,然后挂上梯子又突然可以了。😢
贴一下代码:
# 0. packages loaded && data preparation ----my_packages<- c("maftools", "data.table", "RColorBrewer","paletteer", "devtools", "Rwebdriver","RSelenium")tmp <- sapply(my_packages, function(x) library(x, character.only = T)); rm(tmp)# install_github("crubba/Rwebdriver")# 1. test and startup Rselenium ----remDr <- remoteDriver(remoteServerAddr = "localhost", port = 4444, browserName = "chrome")remDr$open() #打开浏览器remDr$navigate("http://herb.ac.cn/Browse/")
2. 几个功能的实现
我们需要将这个代码想像成真实人类的操作逻辑。
我们上网获取数据一般有哪些操作呢?简单来说包括:
- 翻页
- 点击子页面
- 获取页面中的内容
但其实归结起来,我们的动作无非就是两种:
- 点击
- 选中指定数据复制
- 粘贴
点击
其实也就是获取按钮的地址,这里通过XPATH 获取。
首先调取检查:

接着直接复制XPATH 地址: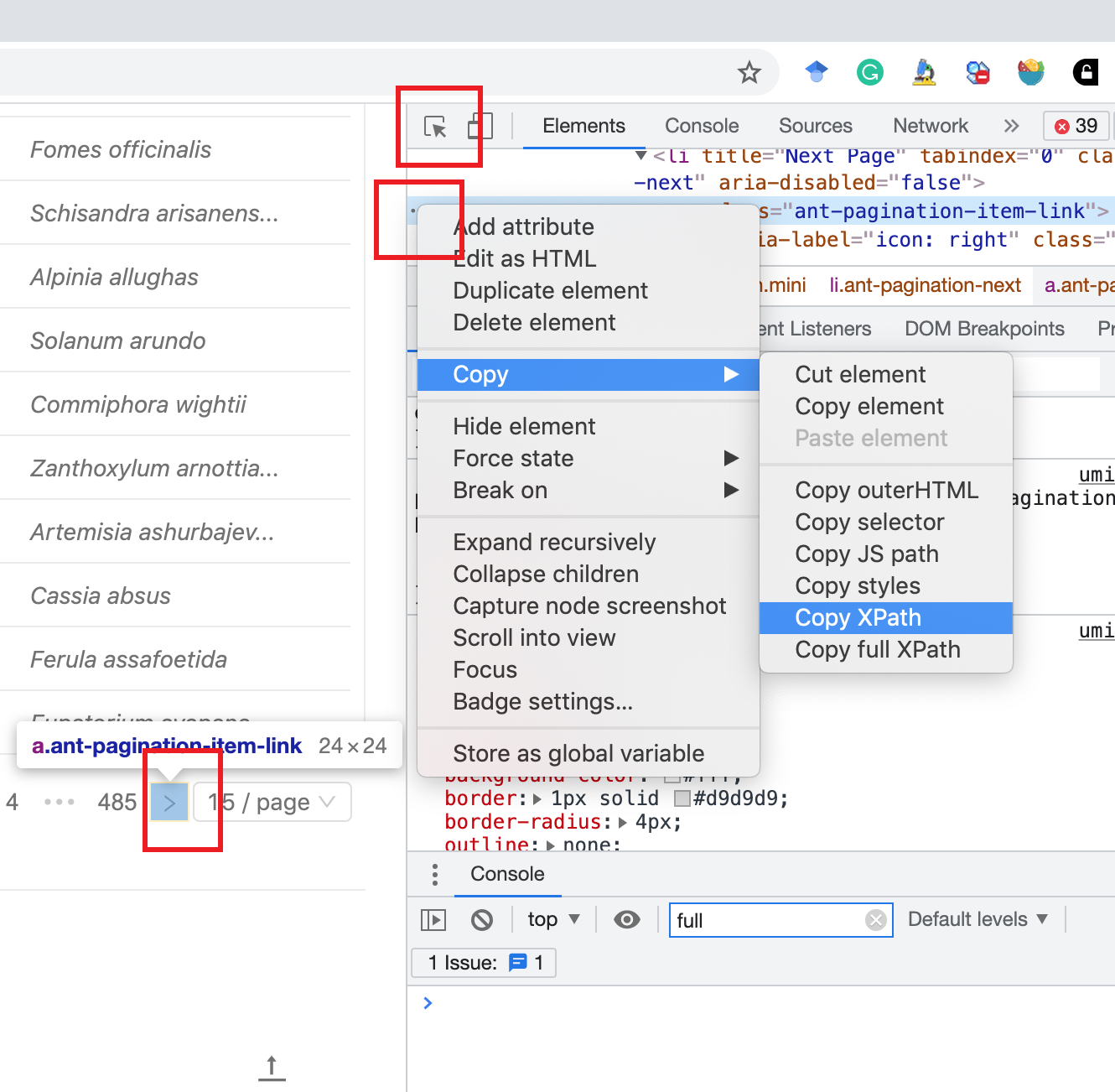
将其按钮对象通过findElement 函数获取,并通过clickElement 点击:
xpath <- '//*[@id="root"]/section/main/div/div[1]/div[2]/div/div/ul/li[10]/a'nextBtn <- remDr$findElement(using ='xpath',value = xpath)nextBtn$clickElement()

实现了这一步,其实翻页也就实现了。(循环该步骤即可)
那么该如何实现循环点击每个子页面呢?
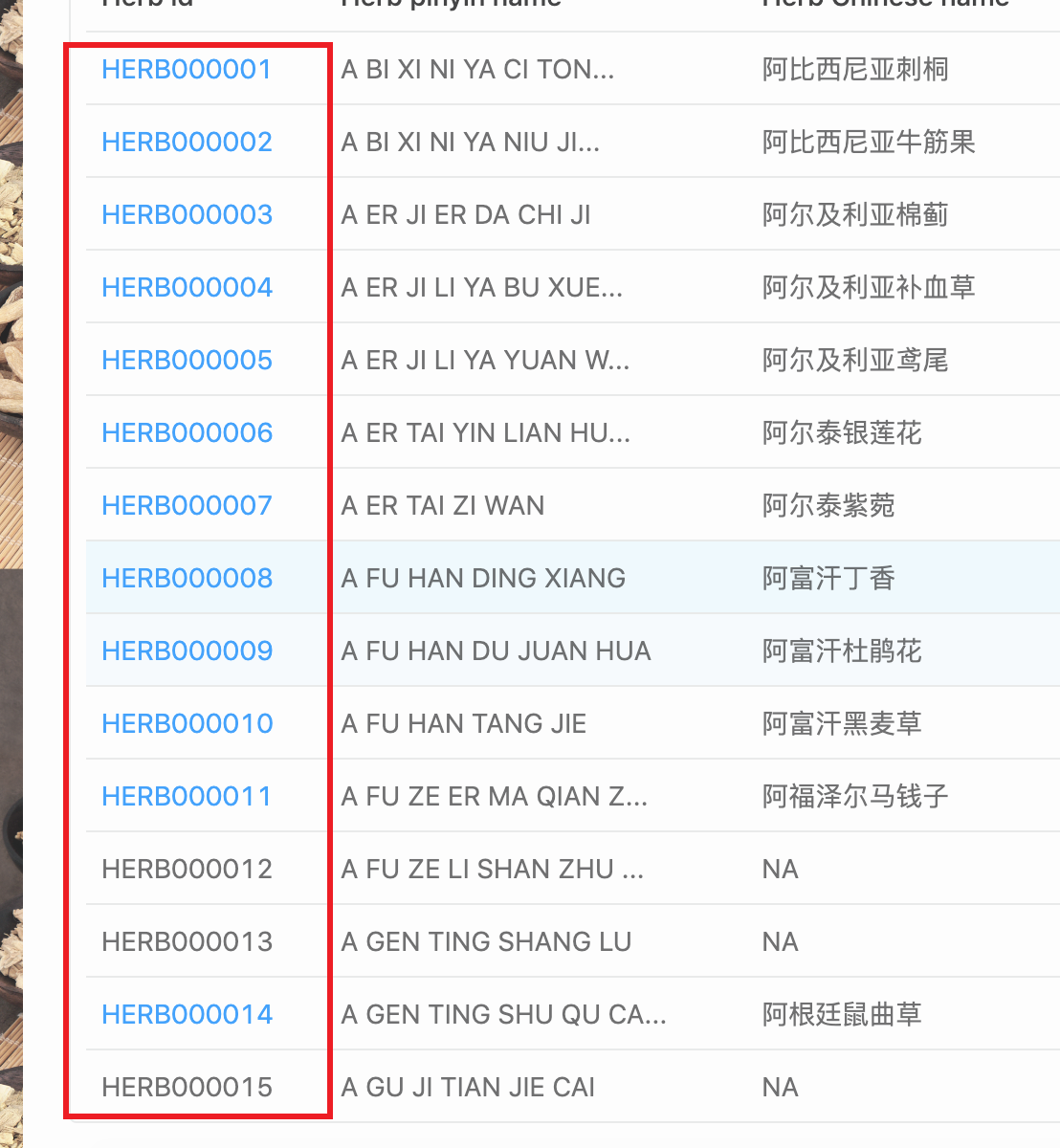
循环访问每个子页面
其实也非常简单,我们看看每个子链接的Xpath 有没有什么规律:
//*[@id="root"]/section/main/div/div[1]/div[2]/div/div/div/div/div/table/tbody/tr[1]/td[1]/span/a//*[@id="root"]/section/main/div/div[1]/div[2]/div/div/div/div/div/table/tbody/tr[2]/td[1]/span/a//*[@id="root"]/section/main/div/div[1]/div[2]/div/div/div/div/div/table/tbody/tr[14]/td[1]/span/a
结果显而易见,仅仅是tr** 更换了数字,且每个页面都是相同的。
我们直接paste 整列数据即可。
演示如下:

获取网页中的指定文本
3. 开始抓取-以herb 数据库herb-ingrediant 信息为例
这里发现herbs 数据库不完全需要动态爬取,每个子页面就包含了全部的信息。而子页面的地址也非常的有规律:
http://herb.ac.cn/Detail/?v=HERB000001&label=Herbhttp://herb.ac.cn/Detail/?v=HERB000002&label=Herbhttp://herb.ac.cn/Detail/?v=HERB000003&label=Herb...http://herb.ac.cn/Detail/?v=HERB007263&label=Herb
但进入到具体的子界面,还是需要实现一个翻页获取的动作:
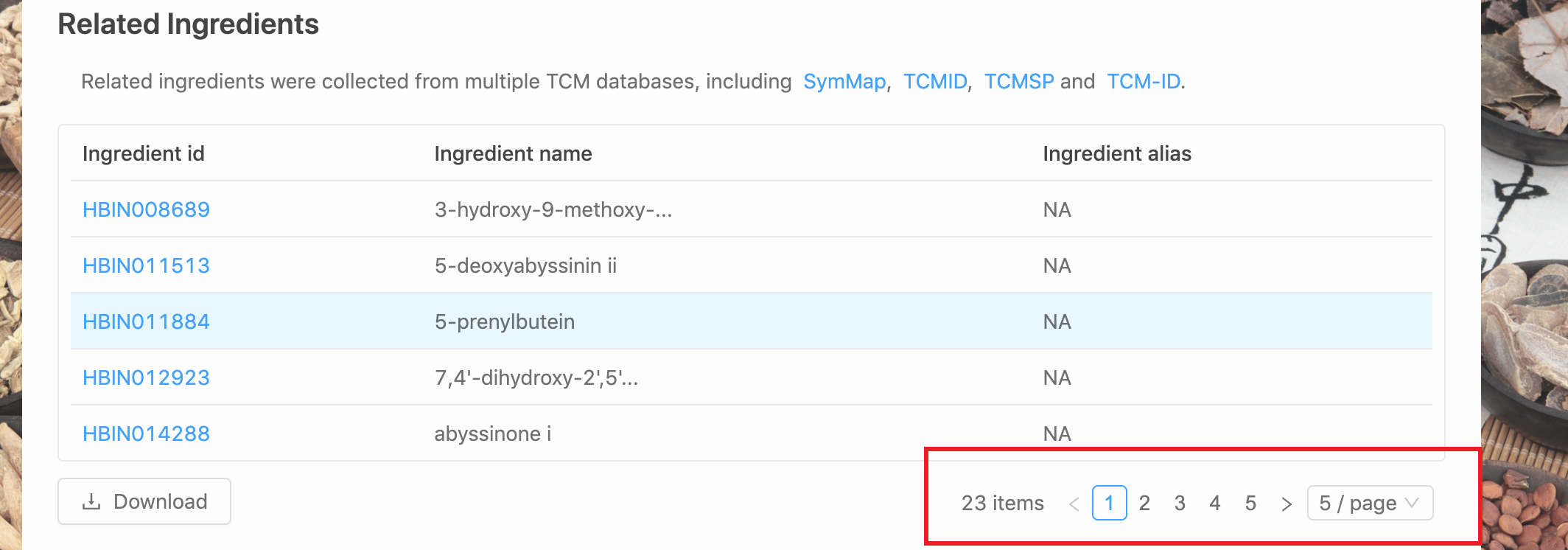
但也仅此而已。

若有收获,就点个赞吧
0 人点赞
