思维导图
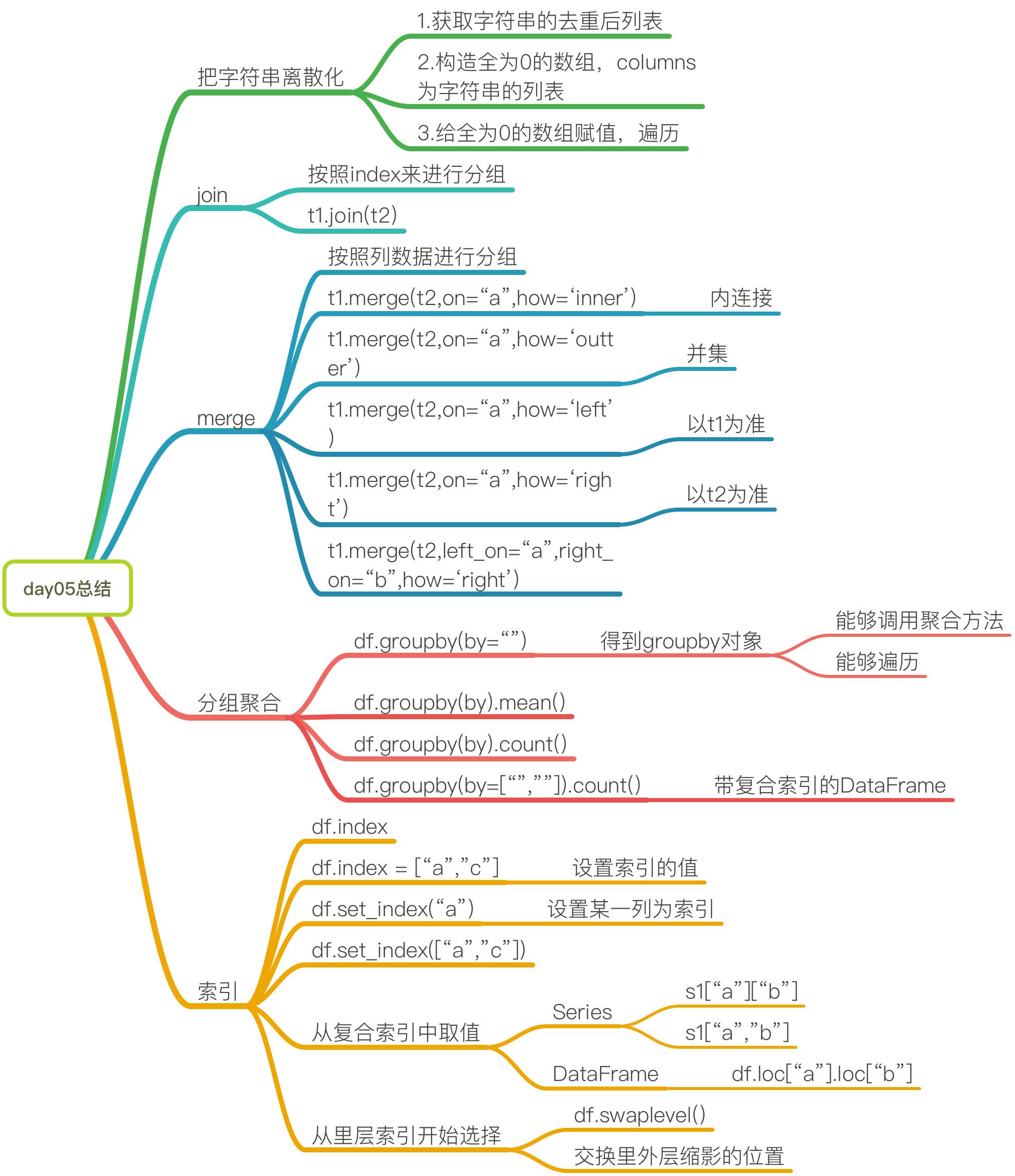
字符串离散化进行统计
- 获取分类去重后的列表
- 构造全为0的DataFrame,形状是(数据的行数,分类列表的长度),列索引是分类去重后的列表
- 遍历原始数据,对全为0的df赋值
- zeros_df.loc[i,[“T”,”M”]] = 1
-
join
-
merge
按照某一列进行和并
[[1,2,3],[4,5,6]][[10,2,31],[43,52,62]]ret: 左连接[[1,2,3,10,2,31],[4,5,6,nan,nan,nan]]ret: 内连接[[1,2,3,10,2,31]]ret: 外连接[[1,2,3,10,2,31][4,5,6,nan,nan,nan][nan,nan,nan,43,52,62]]ret: 右连接[[1,2,3,10,2,31][nan,nan,nan,43,52,62]]
数据的分组和聚合
groupby(by=””).count()
- groupby(by=[“”,””]).count() —->返回复合索引的df
-
索引的相关知识点
df.index
- df.index = []
- df.set_index(“a”) #把某一列作为索引
- df.set_index([“a”,”b”]) #把某几列作为索引
- series
s1["a"]["b"]s1["a","b"]
- DataFrame
df.loc["a"].loc["b"]
- 从内层开始选择
- df.swaplevel()

若有收获,就点个赞吧
0 人点赞
