Mybatis
数据库使用的是SQLServer,JDK版本1.8,运行在SpringBoot环境下 对比3种可用的方式
- 反复执行单条插入语句
- xml拼接sql
- 批处理执行
先说结论:少量插入请使用反复插入单条数据,方便。数量较多请使用批处理方式。(可以考虑以有需求的插入数据量20条左右为界吧,在测试和数据库环境下耗时都是百毫秒级的,方便最重要)
无论何时都不用xml拼接sql的方式。
代码
拼接SQL的xml
newId()是sqlserver生成UUID的函数,与本文内容无关
<insert id="insertByBatch" parameterType="java.util.List">INSERT INTO tb_item VALUES<foreach collection="list" item="item" index="index" separator=",">(newId(),#{item.uniqueCode},#{item.projectId},#{item.name},#{item.type},#{item.packageUnique},#{item.isPackage},#{item.factoryId},#{item.projectName},#{item.spec},#{item.length},#{item.weight},#{item.material},#{item.setupPosition},#{item.areaPosition},#{item.bottomHeight},#{item.topHeight},#{item.serialNumber},#{item.createTime}</foreach></insert>
Mapper接口Mapper 是 mybatis插件tk.Mapper 的接口,与本文内容关系不大
public interface ItemMapper extends Mapper<Item> {int insertByBatch(List<Item> itemList);}
Service类
@Servicepublic class ItemService {@Autowiredprivate ItemMapper itemMapper;@Autowiredprivate SqlSessionFactory sqlSessionFactory;//批处理@Transactionalpublic void add(List<Item> itemList) {SqlSession session = sqlSessionFactory.openSession(ExecutorType.BATCH,false);ItemMapper mapper = session.getMapper(ItemMapper.class);for (int i = 0; i < itemList.size(); i++) {mapper.insertSelective(itemList.get(i));if(i%1000==999){//每1000条提交一次防止内存溢出session.commit();session.clearCache();}}session.commit();session.clearCache();}//拼接sql@Transactionalpublic void add1(List<Item> itemList) {itemList.insertByBatch(itemMapper::insertSelective);}//循环插入@Transactionalpublic void add2(List<Item> itemList) {itemList.forEach(itemMapper::insertSelective);}}
测试类
@RunWith(SpringRunner.class)@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT, classes = ApplicationBoot.class)public class ItemServiceTest {@AutowiredItemService itemService;private List<Item> itemList = new ArrayList<>();//生成测试List@Beforepublic void createList(){String json ="{\n" +" \"areaPosition\": \"TEST\",\n" +" \"bottomHeight\": 5,\n" +" \"factoryId\": \"0\",\n" +" \"length\": 233.233,\n" +" \"material\": \"Q345B\",\n" +" \"name\": \"TEST\",\n" +" \"package\": false,\n" +" \"packageUnique\": \"45f8a0ba0bf048839df85f32ebe5bb81\",\n" +" \"projectId\": \"094b5eb5e0384bb1aaa822880a428b6d\",\n" +" \"projectName\": \"项目_TEST1\",\n" +" \"serialNumber\": \"1/2\",\n" +" \"setupPosition\": \"1B柱\",\n" +" \"spec\": \"200X200X200\",\n" +" \"topHeight\": 10,\n" +" \"type\": \"Steel\",\n" +" \"uniqueCode\": \"12344312\",\n" +" \"weight\": 100\n" +" }";Item test1 = JSON.parseObject(json,Item.class);test1.setCreateTime(new Date());for (int i = 0; i < 1000; i++) {//测试会修改此数量itemList.add(test1);}}//批处理@Test@Transactionalpublic void tesInsert() {itemService.add(itemList);}//拼接字符串@Test@Transactionalpublic void testInsert1(){itemService.add1(itemList);}//循环插入@Test@Transactionalpublic void testInsert2(){itemService.add2(itemList);}}
测试结果
10条 25条数据插入经多次测试,波动性较大,但基本都在百毫秒级别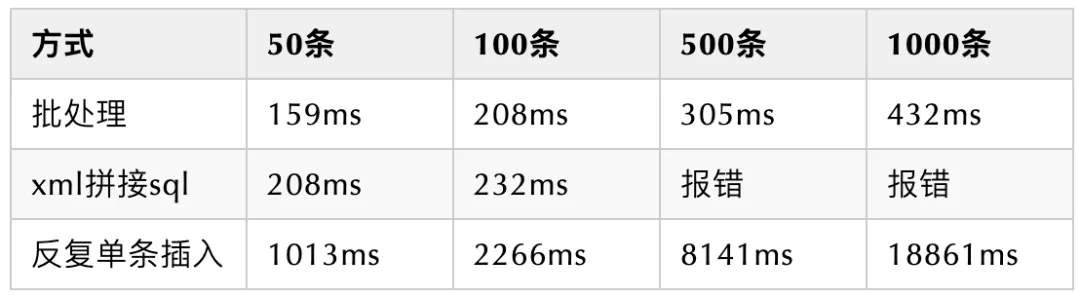
其中 拼接sql方式在插入500条和1000条时报错(似乎是因为sql语句过长,此条跟数据库类型有关,未做其他数据库的测试):com.microsoft.sqlserver.jdbc.SQLServerException: 传入的表格格式数据流(TDS)远程过程调用(RPC)协议流不正确,此RPC请求中提供了过多的参数,最多应为2100
可以发现
- 循环插入的时间复杂度是 O(n),并且常数C很大
- 拼接SQL插入的时间复杂度(应该)是 O(logn),但是成功完成次数不多,不确定
- 批处理的效率的时间复杂度是 O(logn),并且常数C也比较小
结论
循环插入单条数据虽然效率极低,但是代码量极少,在使用tk.Mapper的插件情况下,仅需代码:
因此,在需求插入数据数量不多的情况下肯定用它了。@Transactionalpublic void add1(List<Item> itemList) {itemList.forEach(itemMapper::insertSelective);}
xml拼接sql是最不推荐的方式,使用时有大段的xml和sql语句要写,很容易出错,工作效率很低。更关键点是,虽然效率尚可,但是真正需要效率的时候挂了,又有什么用呢?
批处理执行是有大数据量插入时推荐的做法,使用起来也比较方便。

若有收获,就点个赞吧
0 人点赞
