1、SGD
随机梯度下降算法,每次参数更新时,仅仅选取一个样本计算其梯度。
算法:
函数:
class torch.optim.SGD(params, lr=, momentum=0, dampening=0, weight_decay=0, nesterov=False)'''参数:params (iterable) – 待优化参数的iterable或者是定义了参数组的dictlr (float) – 学习率momentum (float, 可选) – 动量因子(默认:0)weight_decay (float, 可选) – 权重衰减(L2惩罚)(默认:0)dampening (float, 可选) – 动量的抑制因子(默认:0)nesterov (bool, 可选) – 使用Nesterov动量(默认:False)'''http://www.cs.toronto.edu/~hinton/absps/momentum.pdf
自定义优化器基类:
import warningsimport functoolsfrom collections import defaultdictclass CustomOptimizer:def __init__(self, params, defaults):self.defaults = defaults"""defaultdict的作用在于当字典里的key被查找但不存在时,返回的不是keyError而是一个默认值,此处defaultdict(dict)返回的默认值会是个空字典。"""self.state = defaultdict(dict)self.param_groups = []param_groups = list(params)if len(param_groups) == 0:raise ValueError('optimizer got an empty parameter list')ifnotisinstance(param_groups[0], dict):param_groups = [{'params': param_groups}]for param_group in param_groups:self.add_param_group(param_group)def add_param_group(self, param_group):"""作用是将param_group放进self.param_groups中param_group是字典,Key是params,Value是param_groups=list(params)"""assert isinstance(param_group, dict), "param group must be a dict"params = param_group['params']if isinstance(params, torch.Tensor):param_group['params'] = [params]else:param_group['params'] = list(params)"""将self.defaults中的键值对遍历放到字典param_group中"""for name, default in self.defaults.items():param_group.setdefault(name, default)params = param_group['params']if len(params) != len(set(params)):warnings.warn("optimizer contains a parameter group with duplicate parameters; ""in future, this will cause an error; ", stacklevel=3)"""对self.param_groups和param_group中的元素进行判断,确保没有重复的参数"""param_set = set()for group in self.param_groups:param_set.update(set(group['params']))if not param_set.isdisjoint(set(param_group['params'])):raise ValueError("some parameters appear in more than one parameter group")"""将字典param_group放进列表self.param_groups"""self.param_groups.append(param_group)def __setstate__(self, state):self.__dict__.update(state)def __getstate__(self):return {'defaults': self.defaults,'state': self.state,'param_groups': self.param_groups,}def step(self, closure):raise NotImplementedErrordef zero_grad(self):r"""将梯度置为零"""for group in self.param_groups:for p in group['params']:if p.grad isnotNone:p.grad.detach_()p.grad.zero_()def __repr__(self):format_string = self.__class__.__name__ + ' ('for i, group in enumerate(self.param_groups):format_string += '\n'format_string += 'Parameter Group {0}\n'.format(i)for key in sorted(group.keys()):if key != 'params':format_string += ' {0}: {1}\n'.format(key, group[key])format_string += ')'return format_string
自定义SGD优化器:
class CustomSGD(CustomOptimizer):def __init__(self, params, lr, momentum=0, dampening=0, weight_decay=0, nesterov=False, maximize=False):"""参数被打包进字典中命名为defaults"""defaults = dict(lr=lr, momentum=momentum, dampening=dampening,weight_decay=weight_decay, nesterov=nesterov, maximize=maximize)super(CustomSGD, self).__init__(params, defaults)def __setstate__(self, state):super(CustomSGD, self).__setstate__(state)for group in self.param_groups:group.setdefault('nesterov', False)group.setdefault('maximize', False)@torch.no_grad()def step(self, closure=None):"""更新参数Arguments:closure (callable, optional): A closure that reevaluates the modeland returns the loss."""loss = Noneif closure isnotNone:loss = closure()"""self.param_groups 是在父类的__init__函数中创建的"""for group in self.param_groups:weight_decay = group['weight_decay']momentum = group['momentum']dampening = group['dampening']nesterov = group['nesterov']maximize = group['maximize']for p in group['params']:if p.grad isNone: continued_p = p.grad.dataif weight_decay != 0:d_p.add_(weight_decay, p.data)if momentum != 0:param_state = self.state[p]if 'momentum_buffer'notin param_state:buf = param_state['momentum_buffer'] = torch.clone(d_p).detach()else:buf = param_state['momentum_buffer']buf.mul_(momentum).add_(1 - dampening, d_p)if nesterov:d_p = d_p.add(momentum, buf)else:d_p = buf# 对参数进行更新if maximize:p.data.add_(group['lr'], d_p)else:p.data.add_(-group['lr'], d_p)return loss
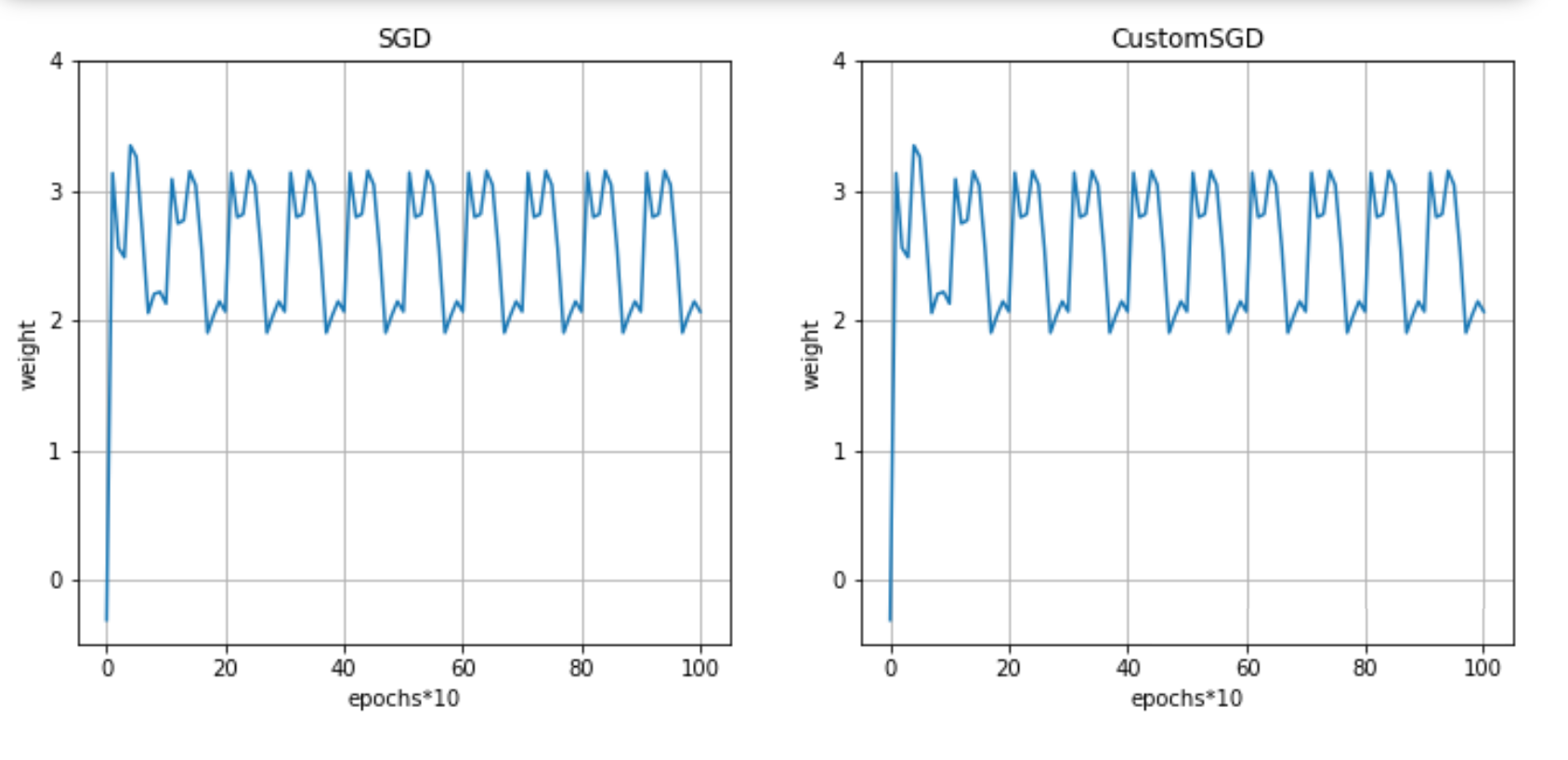
对比:
from torch.optim import SGDw0=optim(model, optim_fn=SGD, lr=0.1,weight_decay=0.5)w0_custom = optim(model, optim_fn=CustomSGD, lr=0.1,weight_decay=0.5)plot([w0,w0_custom], titles=['SGD','CustomSGD'])
2、Adam
将Momentum算法和RMSProp算法结合起来使用的一种算法,既用动量来累积梯度,又使得收敛速度更快同时使得波动的幅度更小,并进行了偏差修正。
算法:
函数:
class torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)[source]'''参数:betas (Tuple[float, float], 可选) – 用于计算梯度以及梯度平方的运行平均值的系数(默认:0.9,0.999)eps (float, 可选) – 为了增加数值计算的稳定性而加到分母里的项(默认:1e-8)'''https://arxiv.org/abs/1412.6980
自定义Adam优化器:
import mathclass CustomAdam(CustomOptimizer):def __init__(self, params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False, maximize=False):defaults = dict(lr=lr, betas=betas, eps=eps,weight_decay=weight_decay, amsgrad=amsgrad, maximize=maximize)super(CustomAdam, self).__init__(params, defaults)def __setstate__(self, state):super(CustomAdam, self).__setstate__(state)for group in self.param_groups:group.setdefault('amsgrad', False)group.setdefault('maximize', False)@torch.no_grad()def step(self, closure=None):loss = Noneif closure isnotNone:loss = closure()for group in self.param_groups:for p in group['params']:if p.grad isNone: continueif group['maximize']:grad = -p.grad.dataelse:grad = p.grad.dataif group['weight_decay'] != 0:grad.add_(group['weight_decay'], p.data)"""Adam Optimizer只能处理dense gradient,要想处理sparse gradient需要使用SparseAdam Optimizer"""if grad.is_sparse:raise RuntimeError('Adam does not support sparse gradients, ''please consider SparseAdam instead')amsgrad = group['amsgrad']state = self.state[p]# 状态初始化if len(state) == 0:state['step'] = 0# 梯度值的指数移动平均state['exp_avg'] = torch.zeros_like(p.data)# 梯度平方值的指数移动平均state['exp_avg_sq'] = torch.zeros_like(p.data)if amsgrad:# 保留最大的梯度平均和梯度平方state['max_exp_avg_sq'] = torch.zeros_like(p.data)exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']if amsgrad:max_exp_avg_sq = state['max_exp_avg_sq']beta1, beta2 = group['betas']state['step'] += 1bias_correction1 = 1 - beta1 ** state['step']bias_correction2 = 1 - beta2 ** state['step']# Decay the first and second moment running average coefficientexp_avg.mul_(beta1).add_(1 - beta1, grad)exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad)if amsgrad:# Maintains the maximum of all 2nd moment running avg. till nowtorch.max(max_exp_avg_sq, exp_avg_sq, out=max_exp_avg_sq)# Use the max. for normalizing running avg. of gradientdenom = (max_exp_avg_sq.sqrt() / math.sqrt(bias_correction2)).add_(group['eps'])else:denom = (exp_avg_sq.sqrt() / math.sqrt(bias_correction2)).add_(group['eps'])step_size = group['lr'] / bias_correction1p.data.addcdiv_(-step_size, exp_avg, denom)return loss
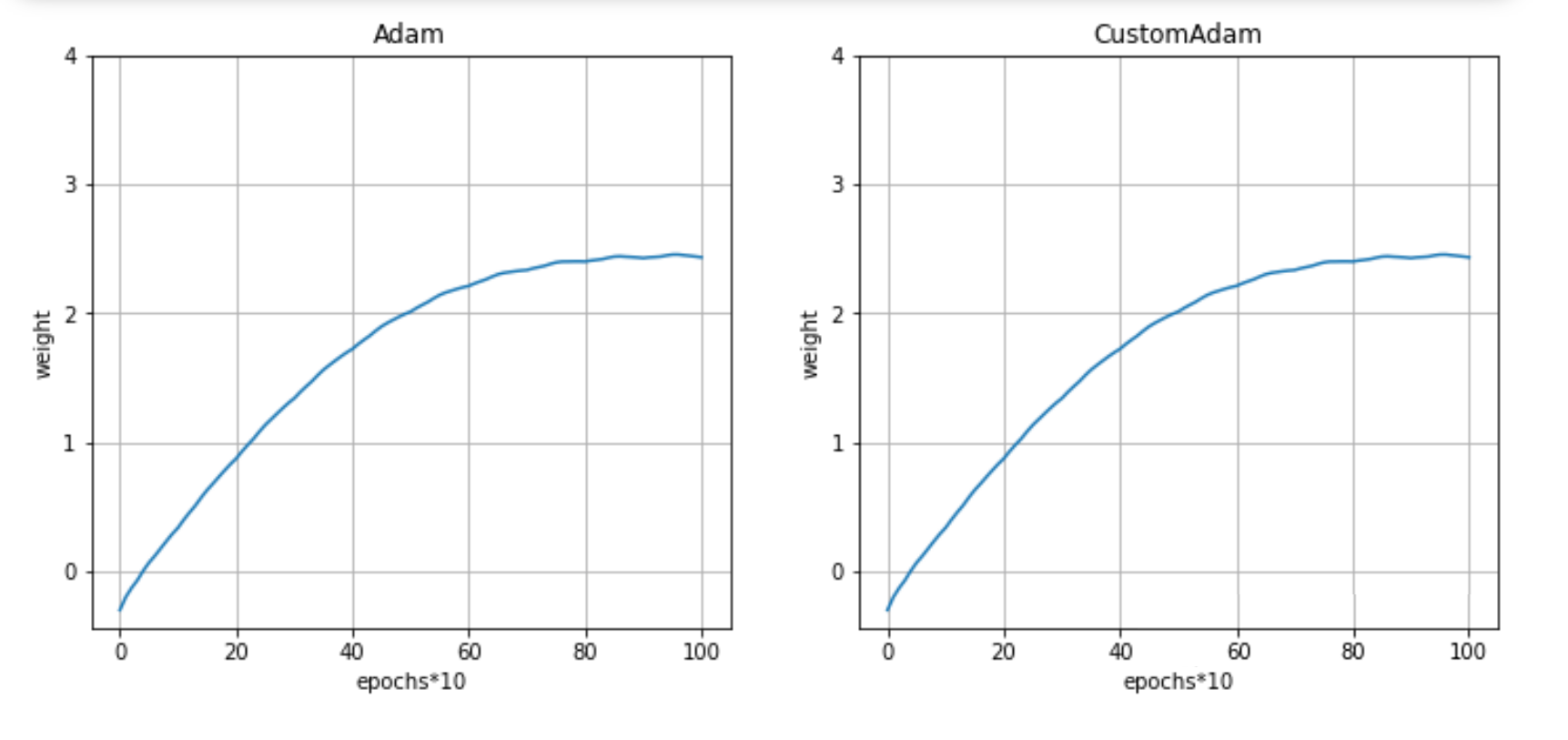
对比:
from torch.optim import Adamw0=optim(model, optim_fn=Adam, lr=0.1,weight_decay=0.5)w0_custom = optim(model, optim_fn=CustomAdam, lr=0.1,weight_decay=0.5)plot([w0,w0_custom], titles=['Adam','CustomAdam'])

若有收获,就点个赞吧
0 人点赞
