1.相对于vue2的优化
A.数据劫持优化
Vue.js 区别于 React 的一大特色是它的数据是响应式的,react是单项数据流。
Vue中DOM是数据的一种映射,数据发生变化自动更新DOM,用户只需要专注于数据的更改。在Vue内部实现这个功能采用的是劫持数据的访问和更新。内部依赖一个watcher的数据结构做依赖管理。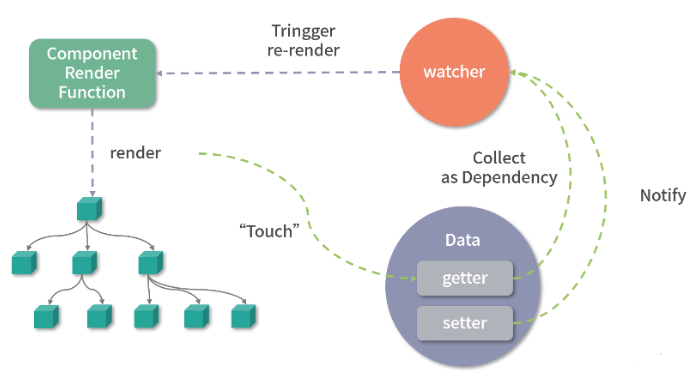
内部通过 Object.defineProperty 这个 API 去劫持数据的 getter 和 setter。但是该方式有一个问题,如果定义的响应式数据层级嵌套过深,由于Vue无法判断在运行时会访问哪个属性,所以对于这样一个对象就需要遍历整个对象执行Object.defineProperty把每一层对象数据都变成响应式。还有对数组的一些方法要单独出来,才能监听到数组数据的变化。为了解决这些问题,vue3使用了Proxy API做数据劫持。
Proxy 劫持的是对象本身,并不能劫持子对象的变化,这点和 Object.defineProperty API 一致。但是 Object.defineProperty 是在初始化阶段,即定义劫持对象的时候就已经递归执行了,而 Proxy 是在对象属性被访问的时候才递归执行下一步 reactive,这其实是一种延时定义子对象响应式的实现,在性能上会有较大的提升。
Proxy劫持整个对象,对象的属性的增加和删除都能监测到。Proxy API并不监听对象内部深层次的变化,vue3处理方式在getter中递归响应式,这样做的到真正访问到内部对象时才会变成响应式,而不是无限制递归。
target 作为原始的数据,key 作为访问的属性。我们创建了全局的 targetMap 作为原始数据对象的 Map,它的键是 target,值是 depsMap,作为依赖的 Map;这个 depsMap 的键是 target 的 key,值是 dep 集合,dep 集合中存储的是依赖的副作用函数。为了方便理解,可以通过下图表示它们之间的关系: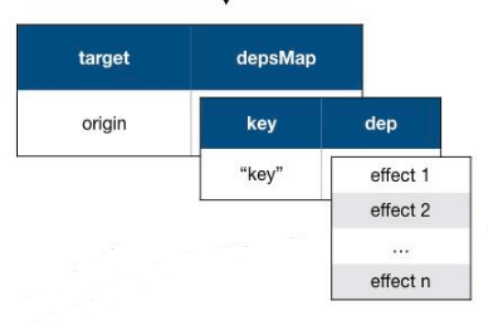
B.编译期间-指定动态节点-优化
vue2的数据更新触发并重新渲染的粒度是组件级,vnode 的性能跟模版大小正相关,跟动态节点的数量无关,当一些组件的整个模版内只有少量动态节点时,这些遍历都是性能的浪费。
vue3优化到动态节点级,它通过编译阶段对静态模板的分析,编译生成了Block tree,Block tree是一个将模板基于动态节点指令切割的嵌套区块,每个区块内部节点机构固定,而且每个区块只需要以一个array来追踪自身包含的动态节点。
vue3将vnode更新性能由与模板整体大小相关提升为与动态内容的数量相关。
C.compositionAPI 逻辑(复用)组织的优化
在vue2中通常使用mixins复用逻辑,由于每个mixin都可以定义自己的props、data,这样复用导入到组件中无法明确知道数据来自于哪个mixin。很容易定义相同的变量,导致命名冲突,数据来源不清晰。例如
const mousePositionMixin = {data() {return {x: 0,y: 0}},mounted() {window.addEventListener('mousemove', this.update)},destroyed() {window.removeEventListener('mousemove', this.update)},methods: {update(e) {this.x = e.pageXthis.y = e.pageY}}}export default mousePositionMixin
在组件中使用,无法感知x,和y变量的来源。
<template><div>Mouse position: x {{ x }} / y {{ y }}</div></template><script>import mousePositionMixin from './mouse'export default {mixins: [mousePositionMixin]}</script>
vue3使用了Composition API,方便的解决了mixins的问题。
import { ref, onMounted, onUnmounted } from 'vue'export default function useMousePosition() {const x = ref(0)const y = ref(0)const update = e => {x.value = e.pageXy.value = e.pageY}onMounted(() => {window.addEventListener('mousemove', update)})onUnmounted(() => {window.removeEventListener('mousemove', update)})return { x, y }}
这种用法类似react的hook,在组件中使用,可以将x和y变量解构出来。
<template><div>Mouse position: x {{ x }} / y {{ y }}</div></template><script>import useMousePosition from './mouse'export default {setup() {const { x, y } = useMousePosition()return { x, y }}}</script>
可以看到,整个数据来源清晰了,即使编写更多的 hook 函数,也不会出现命名冲突的问题。
2.组件->vnode的过程
vue内部,组件想要真正的渲染成DOM需要经历 以下三个过程
普通元素节点
<button class="btn" style="width:100px;height:50px">click me</button>
创建vnode
const vnode = {type: 'button',props: {'class': 'btn',style: {width: '100px',height: '50px'}},children: 'click me'}
type表示DOM的标签类型,props表示DOM的附加属性信息,比如style、class等,children表示DOM的子节点,它可以是一个vnode数组,只不过vnode可以用字符串表示简单的文本。vnode是对抽象事物的描述。使用vnode 的优势:抽象,跨平台。
Vue.js 3.0 内部针对 vnode 的 type,做了更详尽的分类,包括 Suspense、Teleport 等,且把 vnode 的类型信息做了编码,以便在后面的 patch 阶段,可以根据不同的类型执行相应的处理。
3.vue的diff算法patch函数
diff算法核心,求解最长递增子序列。Vue.js 内部使用的是维基百科提供的一套“贪心 + 二分查找”的算法,贪心算法的时间复杂度是 O(n),二分查找的时间复杂度是 O(logn),所以它的总时间复杂度是 O(nlogn)
假设我们有这个样一个数组 arr:[2, 1, 5, 3, 6, 4, 8, 9, 7],求解它最长递增子序列的步骤如下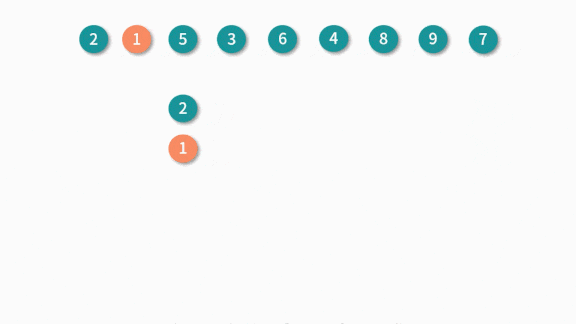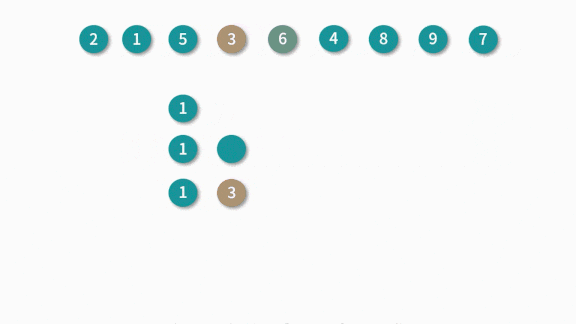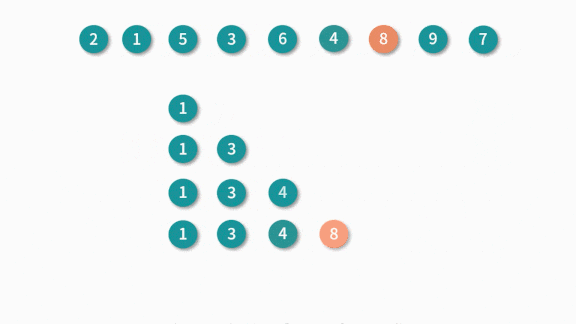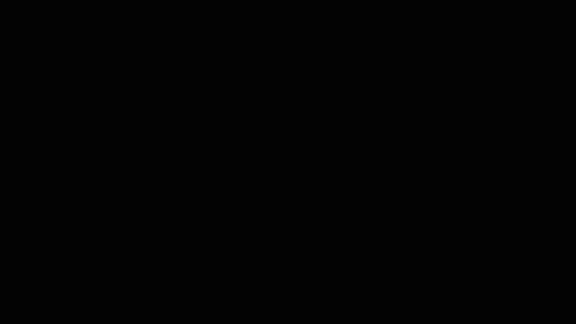
最终求得最长递增子序列的值就是 [1, 3, 4, 8, 9]
通过演示我们可以得到这个算法的主要思路:对数组遍历,依次求解长度为 i 时的最长递增子序列,当 i 元素大于 i - 1 的元素时,添加 i 元素并更新最长子序列;否则往前查找直到找到一个比 i 小的元素,然后插在该元素后面并更新对应的最长递增子序列。
这种做法的主要目的是让递增序列的差尽可能的小
源码实现
function getSequence (arr) {const p = arr.slice()const result = [0]let i, j, u, v, cconst len = arr.lengthfor (i = 0; i < len; i++) {const arrI = arr[i]if (arrI !== 0) {j = result[result.length - 1]if (arr[j] < arrI) {// 存储在 result 更新前的最后一个索引的值p[i] = jresult.push(i)continue}u = 0v = result.length - 1// 二分搜索,查找比 arrI 小的节点,更新 result 的值while (u < v) {c = ((u + v) / 2) | 0if (arr[result[c]] < arrI) {u = c + 1}else {v = c}}if (arrI < arr[result[u]]) {if (u > 0) {p[i] = result[u - 1]}result[u] = i}}}u = result.lengthv = result[u - 1]// 回溯数组 p,找到最终的索引while (u-- > 0) {result[u] = vv = p[v]}return result}
result 存储的是长度为 i 的递增子序列最小末尾值的索引。
result 值就是 [1, 3, 4, 7, 9] ,这不是最长递增子序列,它只是存储的对应长度递增子序列的最小末尾。因此在整个遍历过程中会额外用一个数组 p,来存储在每次更新 result 前最后一个索引的值,并且它的 key 是这次要更新的 result 值。
最终的 result 值是 [1, 3 ,5 ,6 ,7],也就找到最长递增子序列的最终索引。我们求解的是最长子序列索引值,它的每个元素其实对应的是数组的下标。对于我们的例子而言,[2, 1, 5, 3, 6, 4, 8, 9, 7] 的最长子序列是 [1, 3, 4, 8, 9],而我们求解的 [1, 3 ,5 ,6 ,7] 就是最长子序列中元素在原数组中的下标所构成的新数组。
4.setUp组件渲染前初始化过程
setupState、data、props、ctx ,判断变量数据的顺序,在变量名相同时,它决定了数据获取的优先级。
<template><p>{{msg}}</p></template><script>import { ref } from 'vue'export default {data() {return {msg: 'msg from data'}},setup() {const msg = ref('msg from setup')return {msg}}}</script>
data 和 setup 中都定义了 msg 变量,但最终输出到界面上的是”msg from setup”,这是因为 setupState 的判断优先级要高于 data。
在setup(props, {emit})可以给组件传递props和emit事件。
Reactive API
依赖收集track发生在数据访问的阶段
用 Proxy API 劫持了数据对象,所以当这个响应式对象属性被访问的时候就会执行 get 函数。 get 函数最核心的部分其实是执行 track 函数收集依赖, 以下是track 函数的实现
//是否需要进行依赖收集let shouldTrack = true;// 当前激活的 effectlet activeEffect// 原始数据对象 mapconst targetMap = new WeakMap()// track依赖收集函数function tarck(target, type, key){//不用依赖收集或者activeEffect函数为undefined,直接返回if(!shouldTrack || activeEffect === undefined){return}let depsMap = targetMap.get(target)if(!depsMap){// 每个target对应一个depsMap,如果target的没找到对应的depsMap则创建一个targetMap.set(target, (depsMap = new Map()))}let dep = depsMap.get(key)if(!dep){//每个key对应一个dep集合,dep集合存放的effect,如果key对应的dep集合不存在则创建一个depsMap.set(key, (dep = new Set()))}if(!dep.has(activeEffect)){// 收集当前激活的effect作为依赖dep.add(activeEffect)// 当前激活的effect收集dep 集合作为依赖activeEffect.deps.push(dep)}}
收集的依赖就是数据变化后执行的副作用函数。 target 作为原始的数据,key 作为访问的属性。我们创建了全局的 targetMap 作为原始数据对象的 Map,它的键是 target,值是 depsMap,作为依赖的 Map;这个 depsMap 的键是 target 的 key,值是 dep 集合,dep 集合中存储的是依赖的副作用函数。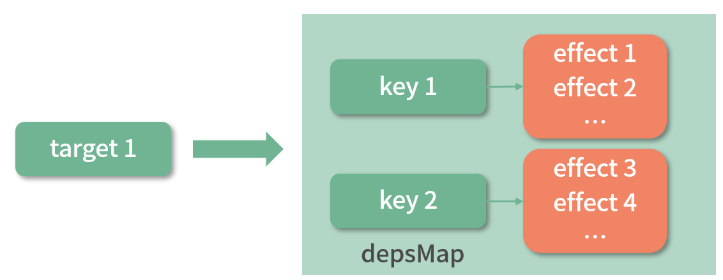
派发通知trigger发生在数据更新的阶段
由于我们用 Proxy API 劫持了数据对象,所以当这个响应式对象属性更新的时候就会执行 set 函数。整个 set 函数最核心的部分就是 执行 trigger 函数派发通知
function createSetter() {return function set(target, key, value, receiver) {const oldValue = target[key]value = toRaw(value)const hadKey = hasOwn(target, key)const result = Reflect.set(target, key, value, receiver)// 如果目标的原型链也是一个 proxy,通过 Reflect.set 修改原型链上的属性会再次触发 setter,这种情况下就没必要触发两次 trigger 了if (target === toRaw(receiver)) {if (!hadKey) {trigger(target, "add" /* ADD */, key, value)}else if (hasChanged(value, oldValue)) {trigger(target, "set" /* SET */, key, value, oldValue)}}return result}}
以下是trigger 函数的实现,为了分析主要流程,这里省略了 trigger 函数中的一些分支逻辑:
// 原始数据对象maplet targetMap = new WeakMap()function trigger(target, type, key, newValue){// 通过targetMap获取到target对应的依赖集合const depsMap = targetMap.get(target)// 如果target没有对应的依赖,直接返回if(!depsMap){return}// 创建运行的effects集合const effects = new Set()// 添加effects的函数const add = (effectsToAdd) =>{if(effectsToAdd){effectsToAdd.forEach(effect => {effects.add(effect)})}}// SET | ADD | DELETE 操作之一,添加对应的 effectsif(key !== void 0){add(depsMap.get(key))}const run = (effect) =>{//调度执行if(effect.options.scheduler){effect.options.scheduler(effect)}else{effect()}}// 遍历执行effectseffects.forEach(run)}
trigger 函数的实现也很简单,主要做了四件事情:
- 通过 targetMap 拿到 target 对应的依赖集合 depsMap;
- 创建运行的 effects 集合;
- 根据key从depsMap中找到对应的effects添加到effects集合
- 遍历effects执行相关的副作用函数
每次 trigger 函数就是根据 target 和 key ,从 targetMap 中找到相关的所有副作用函数遍历执行一遍。
副作用Effect函数分析
介绍副作用函数前,我们先回顾一下响应式的原始需求,即我们修改了数据就能自动执行某个函数,举个简单的例子:
import {reactive} from 'vue'const counter = reactive({num:0})function logCount(){console.log(counter.num) }function count(){ counter.num ++ }logCount()count()
上边把counter定义成响应式对象,然后在logCount中访问counter.num,希望通过执行count函数修改counter.num值的时候,能自动执行logCount函数。
按照之前对依赖收集track的过程分析,要在运行logCount函数前,把logCount赋值给activeEffect就能实现需求。
利用高阶函数的思想,对 logCount 做一层封装
function wrapper(fn){const wrapped = function(...args){activeEffect = fnfn(...args)}return wrapped}const wrappedLog = wrapper(logCount)wrapperLog()
wrapper 本身也是一个函数,它接受 fn 作为参数,返回一个新的函数 wrapped,然后维护一个全局的 activeEffect,当 wrapped 执行的时候,把 activeEffect 设置为 fn,然后执行 fn ,当执行 wrappedLog 后,再去修改 counter.num,就会自动执行 logCount 函数
Vue.js 3.0 就是采用类似的做法,内部有一个 effect 副作用函数,以下是effect的实现
// 全局effect 栈const effectStack = []// 当前激活的effectlet activeEffectfunction effect(fn, options = EMPTY_OBJ){if(isEffect(fn)){// 如果fn已经是一个effect函数,则指向原始函数fn = fn.raw}//创建一个wrapper,一个响应式的副作用的函数const effect = createReactiveEffect(fn, options)if(!options.lazy){//lazy配置,计算属性会使用到,如果为非lazy则直接执行一次,如果为lazy则使用上次结果effect()}return effect}function createReactiveEffect(fn, options){const effect = function reactiveEffect(...args){if(!effect.active){// 非激活状态下,如果非调度执行,则直接执行原始函数return options.scheduler ? undefined : fn(...args)}if(!effectStack.includes(effect)){// 清空effect 引用的依赖cleanup(effect)try{//开启全局shouldTrack,允许依赖收集enableTracking()//入栈effectStack.push(effect)activeEffect = effect//执行原函数return fn(...args)}finally{// 出栈effectStack.pop()// 恢复shouldTrack开启之前的状态resetTracking()// 指向栈最后一个effectactiveEffect = effectStack[effectStack.length -1]}}}effect.id = uid++// 标识是一个 effect 函数effect._isEffect = true// effect 自身的状态effect.active = true// 包装的原始函数effect.raw = fn// effect 对应的依赖,双向指针,依赖包含对 effect 的引用,effect 也包含对依赖的引用effect.deps = []// effect 的相关配置effect.options = optionsreturn effect}
effect 内部通过执行 createReactiveEffect 函数去创建一个新的 effect 函数,为了和外部的 effect 函数区分,我们把它称作 reactiveEffect 函数,并且还给它添加了一些额外属性。这个 reactiveEffect 函数就是响应式的副作用函数,当执行 trigger 过程派发通知的时候,执行的 effect 就是它。
reactiveEffect 函数只需要做两件事情: ①把全局的 activeEffect 指向它 ② 然后执行被包装的原始函数 fn 即可 。
为什么设置成栈的数据结构?
考虑到以下这样一个嵌套 effect 的场景
import { reactive} from 'vue'import { effect } from '@vue/reactivity'const counter = reactive({num: 0,num2: 0})function logCount() {effect(logCount2)console.log('num:', counter.num)}function count() {counter.num++}function logCount2() {console.log('num2:', counter.num2)}effect(logCount)count()
针对嵌套 effect 的场景,我们不能简单地赋值 activeEffect,应该考虑到函数的执行本身就是一种入栈出栈操作,因此我们也可以设计一个 effectStack,这样每次进入 reactiveEffect 函数就先把它入栈,然后 activeEffect 指向这个 reactiveEffect 函数,接着在 fn 执行完毕后出栈,再把 activeEffect 指向 effectStack 最后一个元素,也就是外层 effect 函数对应的 reactiveEffect。
在入栈前会执行 cleanup 函数清空 reactiveEffect 函数对应的依赖 。
为什么要执行cleanup清空操作?
cleanup函数
function cleanup(effect) {const { deps } = effectif (deps.length) {for (let i = 0; i < deps.length; i++) {deps[i].delete(effect)}deps.length = 0}}
主要是为了解决一下effect已经不必重新渲染执行的时候会重复执行操作的性能损耗。
<template><div v-if="state.showMsg">{{ state.msg }}</div><div v-else>{{ Math.random()}}</div><button @click="toggle">Toggle Msg</button><button @click="switchView">Switch View</button></template><script>import { reactive } from 'vue'export default {setup() {const state = reactive({msg: 'Hello World',showMsg: true})function toggle() {state.msg = state.msg === 'Hello World' ? 'Hello Vue' : 'Hello World'}function switchView() {state.showMsg = !state.showMsg}return {toggle,switchView,state}}}</script>
以上代码,如果没有cleanup,第一次渲染模板的时候,activeEffect是组件的副作用渲染函数,因为模板render的时候访问state.msg,所以会执行依赖收集,把副作用渲染函数作为state.msg的依赖。然后点击Switch view按钮后,视图期货显示为随机数,此时在点击Toggle msg按钮,由于修改了state.msg就会派发通知,触发了组件的重新渲染,这是不符合预期。当视图显示为随机数的时候,视图并没有渲染state.msg,所以它的改动不应该影响到组件的重新渲染。
因此在组件的render effect执行之前,使用cleanup清理依赖,就删除了state.msg收集的render effect依赖。
ReadOnly API
用 const 声明一个对象变量,虽然不能直接对这个变量赋值,但我们可以修改它的属。如果我们希望创建只读对象,不能修改它的属性,也不能给这个对象添加和删除属性,让它变成一个真正意义上的只读对象。
const original = {foo: 1}const wrapped = readonly(original)wrapped.foo = 2// warn: Set operation on key "foo" failed: target is readonly.
readOnly 和 reactive API 最大的区别就是不做依赖收集,因为它的属性不会被修改,所以不用跟踪变化。
readonly 的实现分析
function readonly(target) {return createReactiveObject(target, true, readonlyHandlers, readonlyCollectionHandlers)}function createReactiveObject(target, isReadonly, baseHandlers, collectionHandlers) {if (!isObject(target)) {// 目标必须是对象或数组类型if ((process.env.NODE_ENV !== 'production')) {console.warn(`value cannot be made reactive: ${String(target)}`)}return target}if (target.__v_raw && !(isReadonly && target.__v_isReactive)) {// target 已经是 Proxy 对象,直接返回// 有个例外,如果是 readonly 作用于一个响应式对象,则继续return target}if (hasOwn(target, isReadonly ? "__v_readonly" /* readonly */ : "__v_reactive" /* reactive */)) {// target 已经有对应的 Proxy 了return isReadonly ? target.__v_readonly : target.__v_reactive}// 只有在白名单里的数据类型才能变成响应式if (!canObserve(target)) {return target}// 利用 Proxy 创建响应式const observed = new Proxy(target, collectionTypes.has(target.constructor) ? collectionHandlers : baseHandlers)// 给原始数据打个标识,说明它已经变成响应式,并且有对应的 Proxy 了def(target, isReadonly ? "__v_readonly" /* readonly */ : "__v_reactive" /* reactive */, observed)return observed}
Ref API
reactive API 对传入的 target 类型有限制,必须是对象或者数组类型,而对于一些基础类型(比如 String、Number、Boolean)是不支持的。希望把一个字符串或数字变成响应式,Vue.js 3.0 设计并实现了 ref API。
ref 的实现分析
function ref(value) {return createRef(value)}const convert = (val) => isObject(val) ? reactive(val) : valfunction createRef(rawValue) {if (isRef(rawValue)) {// 如果传入的就是一个 ref,那么返回自身即可,处理嵌套 ref 的情况。return rawValue}// 如果是对象或者数组类型,则转换一个 reactive 对象。let value = convert(rawValue)const r = {__v_isRef: true,get value() {// getter// 依赖收集,key 为固定的 valuetrack(r, "get" /* GET */, 'value')return value},set value(newVal) {// setter,只处理 value 属性的修改if (hasChanged(toRaw(newVal), rawValue)) {// 判断有变化后更新值rawValue = newValvalue = convert(newVal)// 派发通知trigger(r, "set" /* SET */, 'value', void 0)}}}return r}
5.计算属性computed
computed函数作为计算属性API
const count = ref(1)const plusOne = computed(() => count.value + 1)console.log(plusOne.value) // 2plusOne.value++ // error, 计算属性不能赋值count.value++console.log(plusOne.value) // 3
先使用 ref API 创建了一个响应式对象 count,然后使用 computed API 创建另一个响应式对象 plusOne,它的值是 count.value + 1,当我们修改 count.value 的时候, plusOne.value 就会自动发生变化。注意,这里我们直接修改 plusOne.value 会报一个错误,这是因为如果我们传递给 computed 的是一个函数,那么这就是一个 getter 函数,我们只能获取它的值,而不能直接修改它。
在 getter 函数中,我们会根据响应式对象重新计算出新的值,这也就是它被叫做计算属性的原因,而这个响应式对象,就是计算属性的依赖。
有时候我们也希望能够直接修改 computed 的返回值,那么我们可以给 computed 传入一个对象:
const count = ref(1)const plusOne = computed({get: () => count.value + 1,set: val => {count.value = val - 1}})plusOne.value = 1console.log(count.value) // 0
computed API 的实现
function computed(getterOrOptions) {// getter 函数let getter// setter 函数let setter// 标准化参数if (isFunction(getterOrOptions)) {// 表面传入的是 getter 函数,不能修改计算属性的值getter = getterOrOptionssetter = (process.env.NODE_ENV !== 'production')? () => {console.warn('Write operation failed: computed value is readonly')}: NOOP}else {getter = getterOrOptions.getsetter = getterOrOptions.set}// 数据是否脏的let dirty = true// 计算结果let valuelet computed// 创建副作用函数const runner = effect(getter, {// 延时执行lazy: true,// 标记这是一个 computed effect 用于在 trigger 阶段的优先级排序computed: true,// 调度执行的实现scheduler: () => {if (!dirty) {dirty = true// 派发通知,通知运行访问该计算属性的 activeEffecttrigger(computed, "set" /* SET */, 'value')}}})// 创建 computed 对象computed = {__v_isRef: true,// 暴露 effect 对象以便计算属性可以停止计算effect: runner,get value() {// 计算属性的 getterif (dirty) {// 只有数据为脏的时候才会重新计算value = runner()dirty = false}// 依赖收集,收集运行访问该计算属性的 activeEffecttrack(computed, "get" /* GET */, 'value')return value},set value(newValue) {// 计算属性的 settersetter(newValue)}}return computed}
computed 函数的流程主要做了三件事情:标准化参数,创建副作用函数和创建 computed 对象。
创建副作用函数 runner。computed 内部通过 effect 创建了一个副作用函数,它是对 getter 函数做的一层封装,另外我们这里要注意第二个参数,也就是 effect 函数的配置对象。其中 lazy 为 true 表示 effect 函数返回的 runner 并不会立即执行;computed 为 true 用于表示这是一个 computed effect,用于 trigger 阶段的优先级排序
创建 computed 对象并返回,这个对象也拥有 getter 和 setter 函数。当 computed 对象被访问的时候会触发 getter,然后会判断是否 dirty,如果是就执行 runner,然后做依赖收集;当我们直接设置 computed 对象时会触发 setter,即执行 computed 函数内部定义的 setter 函数。
计算属性的运行机制
dirty 表示一个计算属性的值是否是“脏的”,用来判断需不需要重新计算,第二个 value 表示计算属性每次计算后的结果。
<template><div>{{plusOne}}<button @click="plus">plus</button></div></template><script>import { ref, computed } from 'vue'export default {setup(){const count = ref(0)const plusOne = computed(()=>{return count.value + 1})function plus(){count.value ++}return {count, plusOne, plus}}}</script>
利用 computed API 创建了计算属性对象 plusOne,它传入的是一个 getter 函数,为了和后面计算属性对象的 getter 函数区分,我们把它称作 computed getter。另外,组件模板中引用了 plusOne 变量和 plus 函数。
组件渲染阶段会访问 plusOne,也就触发了 plusOne 对象的 getter 函数:
get value() {// 计算属性的 getterif (dirty) {// 只有数据为脏的时候才会重新计算value = runner()dirty = false}// 依赖收集,收集运行访问该计算属性的 activeEffecttrack(computed, "get" /* GET */, 'value')return value}
默认 dirty 是 true,所以这个时候会执行 runner 函数,并进一步执行 computed getter,也就是 count.value + 1,因为访问了 count 的值,并且由于 count 也是一个响应式对象,所以就会触发 count 对象的依赖收集过程。
由于是在 runner 执行的时候访问 count,所以这个时候的 activeEffect 是 runner 函数。runner 函数执行完毕,会把 dirty 设置为 false,并进一步执行 track(computed,”get”,’value’) 函数做依赖收集,这个时候 runner 已经执行完了,之后 activeEffect 是组件副作用渲染函数。
两个依赖收集过程:
- 对于 plusOne 来说,它收集的依赖是组件副作用渲染函数;
- 对于 count 来说,它收集的依赖是 plusOne 内部的 runner 函数。
点击按钮的时候,会执行 plus 函数,函数内部通过 count.value++ 修改 count 的值,并派发通知。请注意,这里不是直接调用 runner 函数,而是把 runner 作为参数去执行 scheduler 函数。
const run = (effect) => {// 调度执行if (effect.options.scheduler) {effect.options.scheduler(effect)}else {// 直接运行effect()}}
computed API 内部创建副作用函数时,已经配置了 scheduler 函数
scheduler: () => {if (!dirty) {dirty = true// 派发通知,通知运行访问该计算属性的 activeEffecttrigger(computed, "set" /* SET */, 'value')}}
它并没有对计算属性求新值,而仅仅是把 dirty 设置为 true,再执行 trigger(computed, “set” , ‘value’),去通知执行 plusOne 依赖的组件渲染副作用函数,即触发组件的重新渲染。
在组件重新渲染的时候,会再次访问 plusOne,我们发现这个时候 dirty 为 true,然后会再次执行 computed getter,此时才会执行 count.value + 1 求得新值。这就是虽然组件没有直接访问 count,但是当我们修改 count 的值的时候,组件仍然会重新渲染的原因。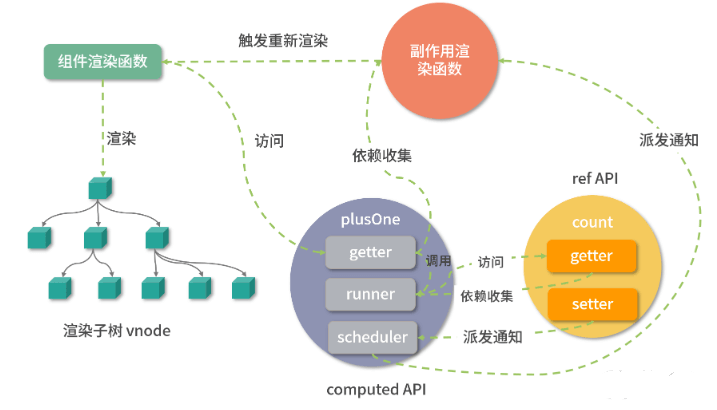
以上分析,我们可以看出 computed 计算属性有两个特点:
- 延时计算,只有当我们访问计算属性的时候,它才会真正运行 computed getter 函数计算;
- 缓存,它的内部会缓存上次的计算结果 value,而且只有 dirty 为 true 时才会重新计算。如果访问计算属性时 dirty 为 false,那么直接返回这个 value。
现在,我们就可以回答开头提的问题。和单纯使用普通函数相比,计算属性的优势是:只要依赖不变化,就可以使用缓存的 value 而不用每次在渲染组件的时候都执行函数去计算,这是典型的空间换时间的优化思想。
6.侦听器watch API
watch API 可以侦听一个 getter 函数,但是它必须返回一个响应式对象,当该响应式对象更新后,会执行对应的回调函数。
import {reactive, watch} from "vue"const state = reactive({count:0})watch(()=> {state.count}, (count,prevCount) => {//当state.count变化时,会触发此回调函数})
watch API 也可以直接侦听一个响应式对象,当响应式对象更新后,会执行对应的回调函数。
import {ref, watch} from "vue"const count = ref(0)watch(count, (count, prevCount)=>{//当count.value更新时,会触发回调函数})
watch API 还可以直接侦听多个响应式对象,任意一个响应式对象更新后,就会执行对应的回调函数。
import { ref, watch } from 'vue'const count = ref(0)const count2 = ref(1)watch([count, count2], ([count, count2], [prevCount, prevCount2]) => {// 当 count.value 或者 count2.value 更新,会触发此回调函数},{immediate: true})
watch API 实现原理
function watch(source, cb, options) {if ((process.env.NODE_ENV !== 'production') && !isFunction(cb)) {warn(`\`watch(fn, options?)\` signature has been moved to a separate API. ` +`Use \`watchEffect(fn, options?)\` instead. \`watch\` now only ` +`supports \`watch(source, cb, options?) signature.`)}return doWatch(source, cb, options)}function doWatch(source, cb, { immediate, deep, flush, onTrack, onTrigger } = EMPTY_OBJ) {// 标准化 source// 构造 applyCb 回调函数// 创建 scheduler 时序执行函数// 创建 effect 副作用函数// 返回侦听器销毁函数}
标准化 source流程
// source 不合法的时候会报警告const warnInvalidSource = (s) => {warn(`Invalid watch source: `, s, `A watch source can only be a getter/effect function, a ref, ` +`a reactive object, or an array of these types.`)}// 当前组件实例const instance = currentInstancelet getterif (isArray(source)) {getter = () => source.map(s => {if (isRef(s)) {return s.value}else if (isReactive(s)) {return traverse(s)}else if (isFunction(s)) {return callWithErrorHandling(s, instance, 2 /* WATCH_GETTER */)}else {(process.env.NODE_ENV !== 'production') && warnInvalidSource(s)}})}else if (isRef(source)) {getter = () => source.value}else if (isReactive(source)) {getter = () => sourcedeep = true}else if (isFunction(source)) {if (cb) {// getter with cbgetter = () => callWithErrorHandling(source, instance, 2 /* WATCH_GETTER */)}else {// watchEffect 的逻辑}}else {getter = NOOP(process.env.NODE_ENV !== 'production') && warnInvalidSource(source)}if (cb && deep) {const baseGetter = gettergetter = () => traverse(baseGetter())}
source 标准化主要是根据 source 的类型,将其变成 getter 函数
如果 source 是 ref 对象,则创建一个访问 source.value 的 getter 函数;
- 如果 source 是 reactive 对象,则创建一个访问 source 的 getter 函数,并设置 deep 为 true(deep 的作用我稍后会说);
- 如果 source 是一个函数,则会进一步判断第二个参数 cb 是否存在,对于 watch API 来说,cb 是一定存在且是一个回调函数,这种情况下,getter 就是一个简单的对 source 函数封装的函数。
构造回调函数
处理完 watch API 第一个参数 source 后,接下来处理第二个参数 cb。
cb 是一个回调函数,它有三个参数:第一个 newValue 代表新值;第二个 oldValue 代表旧值。第三个参数 onInvalidate
回调函数的处理逻辑 ```javascript let cleanup // 注册无效回调函数 const onInvalidate = (fn) => { cleanup = runner.options.onStop = () => { callWithErrorHandling(fn, instance, 4 / WATCH_CLEANUP /) } } // 旧值初始值 let oldValue = isArray(source) ? [] : INITIAL_WATCHER_VALUE /{}/ // 回调函数 const applyCb = cb ? () => { // 组件销毁,则直接返回 if (instance && instance.isUnmounted) { return } // 求得新值 const newValue = runner() if (deep || hasChanged(newValue, oldValue)) { // 执行清理函数 if (cleanup) {
} callWithAsyncErrorHandling(cb, instance, 3 / WATCH_CALLBACK /, [cleanup()
]) // 更新旧值 oldValue = newValue } } : void 0newValue,// 第一次更改时传递旧值为 undefinedoldValue === INITIAL_WATCHER_VALUE ? undefined : oldValue,onInvalidate
<a name="CzWFs"></a>#### 创建 effectwatcher 内部创建的 effect 函数```javascriptconst runner = effect(getter, {// 延时执行lazy: true,// computed effect 可以优先于普通的 effect 先运行,比如组件渲染的 effectcomputed: true,onTrack,onTrigger,scheduler: applyCb ? () => scheduler(applyCb) : scheduler})// 在组件实例中记录这个 effectrecordInstanceBoundEffect(runner)// 初次执行if (applyCb) {if (immediate) {applyCb()}else {// 求旧值oldValue = runner()}}else {// 没有 cb 的情况runner()}
这块代码逻辑是整个 watcher 实现的核心部分,即通过 effect API 创建一个副作用函数 runner,我们需要关注以下几点。
- runner 是一个 computed effect。因为 computed effect 可以优先于普通的 effect(比如组件渲染的 effect)先运行,这样就可以实现当配置 flush 为 pre 的时候,watcher 的执行可以优先于组件更新。
- runner 执行的方式。runner 是 lazy 的,它不会在创建后立刻执行。第一次手动执行 runner 会执行前面的 getter 函数,访问响应式数据并做依赖收集。注意,此时activeEffect 就是 runner,这样在后面更新响应式数据时,就可以触发 runner 执行 scheduler 函数,以一种调度方式来执行回调函数。
- runner 的返回结果。手动执行 runner 就相当于执行了前面标准化的 getter 函数,getter 函数的返回值就是 watcher 计算出的值,所以我们第一次执行 runner 求得的值可以作为 oldValue。
- 配置了 immediate 的情况。当我们配置了 immediate ,创建完 watcher 会立刻执行 applyCb 函数,此时 oldValue 还是初始值,在 applyCb 执行时也会执行 runner 进而执行前面的 getter 函数做依赖收集,求得新值。
异步任务队列的设计
思考以下代码修改了三次 state.count,那么 watcher 的回调函数会执行三次吗?
实际上只输出了一次 count 的值,也就是最终计算的值 3。import { reactive, watch } from 'vue'const state = reactive({ count: 0 })watch(() => state.count, (count, prevCount) => {console.log(count)})state.count++state.count++state.count++
watchEffect API
watchEffect API 的作用是注册一个副作用函数,副作用函数内部可以访问到响应式对象,当内部响应式对象变化后再立即执行这个函数。
它的结果是依次输出 0 和 1。import { ref, watchEffect } from 'vue'const count = ref(0)watchEffect(() => console.log(count.value))count.value++
watchEffect 和前面的 watch API 有哪些不同呢?主要有:
- 侦听的源不同 。watch API 可以侦听一个或多个响应式对象,也可以侦听一个 getter 函数,而 watchEffect API 侦听的是一个普通函数,只要内部访问了响应式对象即可,这个函数并不需要返回响应式对象。
- 没有回调函数 。watchEffect API 没有回调函数,副作用函数的内部响应式对象发生变化后,会再次执行这个副作用函数。
- 立即执行 。watchEffect API 在创建好 watcher 后,会立刻执行它的副作用函数,而 watch API 需要配置 immediate 为 true,才会立即执行回调函数。
- 获取的值,只能获取当前值,无法获取前一个值
7.生命周期函数
// Vue.js 2.x 定义生命周期钩子函数export default {created() {// 做一些初始化工作},mounted() {// 可以拿到 DOM 节点},beforeDestroy() {// 做一些清理操作}}// Vue.js 3.x 生命周期 API 改写上例import { onMounted, onBeforeUnmount } from 'vue'export default {setup() {// 做一些初始化工作onMounted(() => {// 可以拿到 DOM 节点})onBeforeUnmount(()=>{// 做一些清理操作})}}
Vue.js 3.0 针对 Vue.js 2.x 的生命周期钩子函数做了全面替换,映射关系如下:
beforeCreate -> 使用 setup()created -> 使用 use setup()beforeMount -> onBeforeMountmounted -> onMountedbeforeUpdate -> onBeforeUpdateupdated -> onUpdatedbeforeDestroy-> onBeforeUnmountdestroyed -> onUnmountedactivated -> onActivateddeactivated -> onDeactivatederrorCaptured -> onErrorCaptured
Vue.js 3.0 还新增了两个用于调试的生命周期 API:onRenderTracked 和 onRenderTriggered。onRenderTracked 和 onRenderTriggered 是在开发阶段渲染调试用的。
8.子孙组件之间的数据通信
依赖注入的解决方案
祖先组件调用 provide API:
// Providerimport { provide, ref } from 'vue'export default {setup() {const theme = ref('dark')provide('theme', theme)}}
子孙组件调用 inject API:
// Consumerimport { inject } from 'vue'export default {setup() {const theme = inject('theme', 'light')return {theme}}}
inject 函数接受第二个参数作为默认值,如果祖先组件上下文没有提供 theme,则使用这个默认值。
可以把依赖注入看作一部分“大范围有效的 prop”,而且它的规则更加宽松:祖先组件不需要知道哪些后代组件在使用它提供的数据,后代组件也不需要知道注入的数据来自哪里。
provide API 的实现原理:
function provide(key, value) {let provides = currentInstance.providesconst parentProvides = currentInstance.parent && currentInstance.parent.providesif (parentProvides === provides) {provides = currentInstance.provides = Object.create(parentProvides)}provides[key] = value}
默认情况下,组件实例的 provides 继承它的父组件,但是当组件实例需要提供自己的值的时候,它使用父级提供的对象创建自己的 provides 的对象原型。通过这种方式,在 inject 阶段,我们可以非常容易通过原型链查找来自直接父级提供的数据。
如果组件实例提供和父级 provides 中有相同 key 的数据,是可以覆盖父级提供的数据。
import {createApp, h, provide, inject} from "vue"const ProviderOne = {setup(){provide("foo", "foo")provide("bar", "bar")return ()=>h(ProviderTwo)}}const ProviderTwo = {setup(){provider("foo", "fooOverride")provider("baz", "baz")return ()=>h(Consumer)}}const Consumer = {setup(){const foo = inject("foo")const bar = inject("bar")const baz = inject("baz")return ()=> h("div", [foo, bar, baz].join("&"))}}createApp(ProviderOne).mount("#app")
根据 provide 函数的实现,ProviderTwo 提供的 key 为 foo 的 provider 会覆盖 ProviderOne 提供的 key 为 foo 的 provider,所以最后渲染在 Consumer 组件上的就是 fooOverride&bar&baz 。
inject API分析
function inject(key, defaultValue) {const instance = currentInstance || currentRenderingInstanceif (instance) {const provides = instance.providesif (key in provides) {return provides[key]}else if (arguments.length > 1) {return defaultValue}else if ((process.env.NODE_ENV !== 'production')) {warn(`injection "${String(key)}" not found.`)}}}
inject 支持两个参数,第一个参数是 key,我们可以访问组件实例中的 provides 对象对应的 key,层层查找父级提供的数据。第二个参数是默认值,如果查找不到数据,则直接返回默认值。
对比模块化共享数据的方式
模块化共享数据
// Root.jsexport const sharedData = ref('')export default {name: 'Root',setup() {// ...},// ...}//子组件中使用 sharedData:import { sharedData } from './Root.js'export default {name: 'Root',setup() {// 这里直接使用 sharedData 即可}}
provide 和 inject 与模块化方式有如下几点不同。
- 作用域不同
对于依赖注入,它的作用域是局部范围,所以你只能把数据注入以这个节点为根的后代组件中,不是这棵子树上的组件是不能访问到该数据的;对于模块化的方式,它的作用域是全局范围的,可以在任何地方引用数据。
- 数据来源不同
对于依赖注入,后代组件是不需要知道注入的数据来自哪里,只管注入并使用即可;而对于模块化的方式提供的数据,用户必须明确知道这个数据是在哪个模块定义的,从而引入它。
- 上下文不同
对于依赖注入,提供数据的组件的上下文就是组件实例,而且同一个组件定义是可以有多个组件实例的,我们可以根据不同的组件上下文提供不同的数据给后代组件;而对于模块化提供的数据,它是没有任何上下文的,仅仅是这个模块定义的数据,如果想要根据不同的情况提供不同数据,那么从 API 层面设计就需要做更改。
依赖注入的缺陷
依赖注入是上下文相关的,所以它会将你应用程序中的组件与它们当前的组织方式耦合起来,这使得重构变得困难。依赖注入的特点 :祖先组件不需要知道哪些后代组件使用它提供的数据,后代组件也不需要知道注入的数据来自哪里。
不推荐在普通应用程序中使用依赖注入,依赖注入更适合在组件库中使用,它和嵌套的子组件上下文联系很紧密

若有收获,就点个赞吧
0 人点赞
