图的主要存储结构都有两种:邻接矩阵和邻接表。根据是否有方向,分为有向图还是无向图;
图的算法难度较大,对于图的不同存储结构,将对程序的效率产生相当大的影响,所以存储结构应适合于求解问题
本系列实现图的算法邻接表,它属于图的链式存储结构
邻接表
邻接表对图中每个顶点都建立一个单链表,第  个单链表中的节点表示依附于顶点
个单链表中的节点表示依附于顶点  的边,对于有向图则是以顶点
的边,对于有向图则是以顶点  为尾的弧,这个单链表就成为顶点
为尾的弧,这个单链表就成为顶点  的边表。所以在邻接表中存在两种节点:顶点表节点和边表节点
的边表。所以在邻接表中存在两种节点:顶点表节点和边表节点
顶点表节点结构
// 顶点 表节点class Vertex {/*** @description:* @param {*} data记录顶点节点的数值* @return {*}*/constructor(data) {this.data = data; // 顶点域this.firstEdge = null; // 指向第一个邻接边的指针,指向当前顶点的边表中的第一个节点this.outNum = 0; // 在无向图中表示与顶点邻接的边的数量,在有向图中为出度this.inNum = 0; // 在有向图中为顶点的入度}}
data记录顶点节点的数值,firstEdge则指向当前顶点的边表中的第一个节点。outNum在无向图中表示的是与顶点邻接的边的数量,在有向图中则是出度。inNum在无向图中没有意义,在有向图中表示顶点的入度。
边表节点结构
// 边表节点class Edge {constructor(data, weight = 0, nextEdge = null) {this.data = data; // 邻接点域this.nextEdge = nextEdge; // 指向下一条邻接边this.weight = weight; // 权重}}
data为数据域,nextEdge则是指向与顶点 [公式] 相邻的下一个节点。weight表示顶点 [公式] 到当前节点的权重。
无向图展示
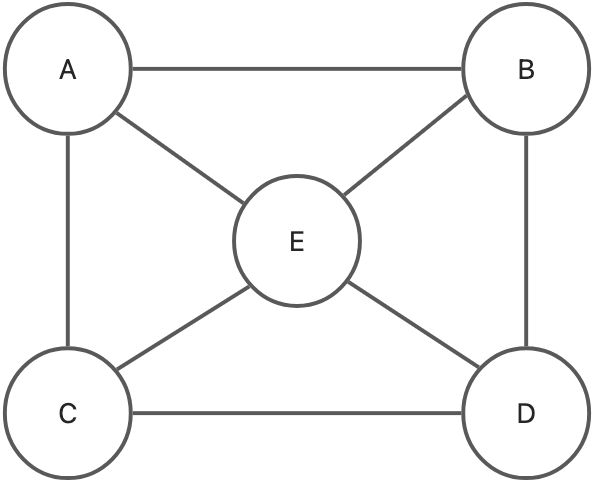
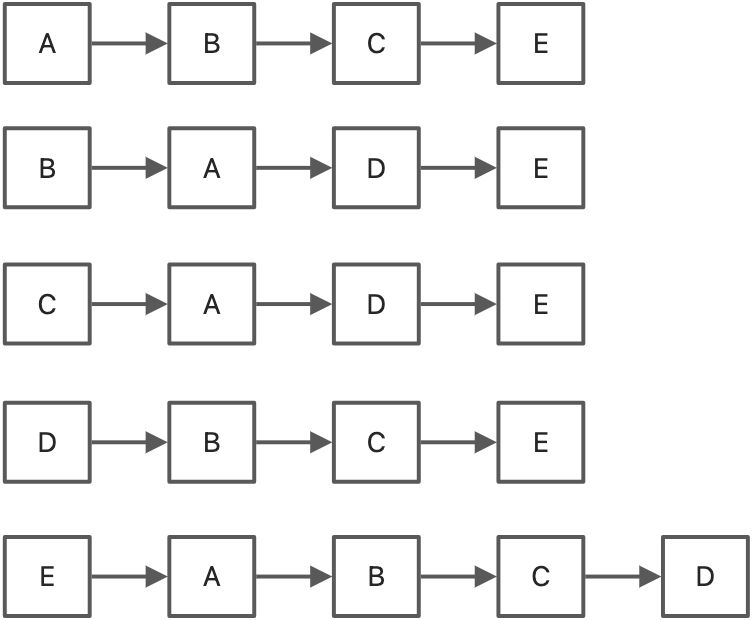
图的重要的操作
insertVertex(x) // 向图中插入新的顶点allNeightbors(x) // 与顶点x邻接的所有节点addEdge(x, y, w = 0) // 向图中插入边(x, y)removeEdge(x, y) // 在图中删除边(x, y)deleteVertex(x) // // 从图中删除顶点xhasEdge(x, y) // 判断是否存在边(x,y)或者<x, y>getAllEdge() // 获取图中所有的边getEdgeWeight(x, y) // 获取边(x, y)或<x, y>对应的权值getMaxEdgeWeight() // 获得图中最大的权值getMinEdgeWeight() // 获得图中最小的权值setEdgeWeight(x, y, w) // 设置边(x, y)或<x, y>的权值BFSTraverse(x) // 广度优先遍历DFSTraverse(x) // 深度优先遍历isConnected() // 判断当前的图是否是连通图getMSTree(method) // 最小生成树getShortestPath(x) // 求带权图顶点x到其他顶点的最短路径getTopoSort() // 拓扑排序getCriticalPath() // 关键路径
代码结构
isDirect为0表示这是一张无向图,为1则表示这是一张有向图。
class Graph {constructor(isDirect) {this.eNum = 0; // 边的数目this.adj = []; // 顶点表this.isDirect = isDirect; // 是否是有向图}// 初始化顶点表initVertex(verArr) {}// 插入新的顶点insertVertex(x) {}// 找到节点x在adj中所在的位置// 前面加上下划线表示不应该在具体实例中调用该方法_find(x) {}// 判断图中是否存在边(x,y)或者<x, y>。hasEdge(x, y) {}// 向图中插入边(x, y)或者边<x, y>addEdge(x, y, w = 0) {}// 在图中删除边(x, y)或者边<x, y>removeEdge(x, y) {}// 从图中删除顶点xdeleteVertex(x) {}// 与顶点x邻接的所有节点allNeightbors(x) {}}
构建过程
初始化顶点表
初始化顶点表的时候可以传入一个数组类型的参数, 将使用传入的值来构建顶点类Vertex,然后将顶点不断的压入当前的顶点数组中。
initVertex(verArr) {for (let i = 0; i < verArr.length; i++) {let newVer = new Vertex(verArr[i]);this.adj[i] = newVer;}}
插入新的顶点
向图中插入新的顶点只要添加到当前的顶点表中
// 插入新的顶点insertVertex(x) {// 创建新顶点let newVer = new Vertex(x);// 添加到当前的顶点表this.adj.push(newVer);}
在顶点表中查找给定数值的方法
// 找到节点x在adj中所在的位置// 前面加上下划线表示不应该在具体实例中调用该方法_find(x) {let pos = -1;for (let i = 0; i < this.adj.length; i++) {if (x == this.adj[i].data) pos = i;}return pos;}
两点之间是否有边
在为顶点之间插入边之前,还需要知道顶点之间是否已经有了边,下面的代码判断x和y之间是否具有边,从顶点x的边表第一元素开始遍历,如果发现存在y节点则说明顶点x和顶点y之间已经有一条边
// 判断图中是否存在边(x,y)或者<x, y>。// 从顶点x的边表第一元素开始遍历,如果发现存在y节点则说明顶点x和顶点y之间已经有了一条边hasEdge(x, y) {let pos = this._find(x);if (pos > -1) {let curVer = this.adj[pos].firstEdge;if (!curVer) { // 没有与顶点x的邻接点return false;} else { // 至少有一个节点与顶点x是相邻的// 遍历顶点的所有邻接节点while (curVer) {if (curVer.data === y) return true;curVer = curVer.nextEdge;}return false;}}}
两点之间创建边
所有的准备工作做完,然后就可以连接任意顶点。此时分为有向图还是无向图
- 无向图:在插入边(x, y)后还要再插入边(y, x),因为用邻接表来存储无向图时,顶点x的边表中具有顶点y,那么顶点y的边表中必然也有顶点x。
- 有向图:只需要插入边
在插入边的时候,首先判断下顶点x和顶点y之间是否已经存在一条边,只有x和y之间没有边时,才可以在顶点x和顶点y之间插入一条边。
需要注意的是,在插入边的过程中,如果是有向图时,也同时更新了每个顶点的入度和出度,而如果是无向图的话,则分别更新了与x和y相邻的节点的数量。
之所以需要顶点的入度和出度,是为了后面求图的拓扑排序和关键路径准备的。
// 向图中插入边(x, y)或者边<x, y>/**1.连接任意顶点,分为有向图还是无向图,如果是无向图的话,在插入边(x, y)后还要再插入边(y, x),因为用邻接表来存储无向图时,顶点x的边表中具有顶点y,那么顶点y的边表中必然也有顶点x。如果是有向图中的话,只需要插入边<x, y>就可以2.在插入边的时候,首先判断下顶点x和顶点y之间是否已经存在了一条边了,只有x和y之间没有边时,才可以在顶点x和顶点y之间插入一条边3.在插入边的过程中,如果是有向图时,同时更新每个顶点的入度和出度,而如果是无向图的话,则分别更新了与x和y相邻的节点的数量。*/addEdge(x, y, w = 0) {let posX = this._find(x);let posY = this._find(y);let newEdgeX = new Edge(x, w);let newEdgeY = new Edge(y, w);// 如果是无向图,在插入边(x, y)时还要插入边(y, x)if (!this.isDirect) {// <x, y>或者<y, x>边不存在if (!this.hasEdge(x, y) && !this.hasEdge(y, x)) {// 如果顶点x在顶点表中if (posX > -1) {// 取出顶点x的第一条边let curVer = this.adj[posX].firstEdge;// 如果第一条边不存在if (!curVer) {// 创建第一条边this.adj[posX].firstEdge = newEdgeY;// outNum无向图中,表示顶点邻接边的数量this.adj[posX].outNum++;} else {let len = this.adj[posX].outNum - 1;// x点的邻接边存在,往所有边之后追加边while (len--) {curVer = curVer.nextEdge;}curVer.nextEdge = newEdgeY;// 邻接边数量+1this.adj[posX].outNum++;}}// 如果顶点y在顶点表中if (posY > -1) {// 取出顶点y的第一条边let curVer = this.adj[posY].firstEdge;if (!curVer) {this.adj[posY].firstEdge = newEdgeX;this.adj[posY].outNum++;} else {let len = this.adj[posY].outNum - 1;while (len--) {curVer = curVer.nextEdge;}curVer.nextEdge = newEdgeX;this.adj[posY].outNum++;}}// 边的数量+1this.eNum++;}}// 有向图, 只用处理<x, y>方向的边else {if (!this.hasEdge(x, y)) {// 如果顶点x在顶点表中if (posX > -1) {// x顶点的第一条边let curVer = this.adj[posX].firstEdge;// 如果当前顶点没有第一个边节点if (!curVer) {this.adj[posX].firstEdge = newEdgeY;// x顶点的出度+1this.adj[posX].outNum++;} else {let len = this.adj[posX].outNum - 1;while (len--) {curVer = curVer.nextEdge;}curVer.nextEdge = newEdgeY;// 顶点x的出度+1this.adj[posX].outNum++;}}// 如果顶点x在顶点表中if (posY > -1) {let curVer = this.adj[posY];// 顶点y的入度增长curVer.inNum++;}}}}
删除边的操作
在无向图中删除边(x, y)时,同时也需要删除(y, x),有向图则只需要删除边
需要注意的是,在删除边时,涉及到更新顶点的边表,而顶点类中的firstEdge指针,指向与该顶点边表中的第一个节点,如果需要删除这个节点,还需要更新firstEdge指向。这里的操作和单链表中删除有点类似
// 在图中删除边(x, y)或者边<x, y>// 在无向图中删除边(x, y)时,同时也需要删除(y, x),有向图则只需要删除边<x, y>就可以// 由于是由邻接表表示的数据结构,当删除边(x, y)时也需要同时删除边(y, x);removeEdge(x, y) {//在图中删除边(x, y)if (this.hasEdge(x, y)) {let posX = this._find(x); //查找x顶点let posY = this._find(y); //查找y顶点let curVerX = this.adj[posX].firstEdge; // x的第一条边let curVerY = this.adj[posY].firstEdge; //y的第一条边// 首先是无向图,当删除边(x, y)时也需要同时删除边(y, x)if (!this.isDirect) {// 删除边(x, y)// 如果顶点的第一个节点即是要找的节点if (curVerX.data === y) {// 删除第一条边,把顶点x的nextEdge作为第一条边this.adj[posX].firstEdge = curVerX.nextEdge;this.add[posX].outNum--;curVerX = null;}// curVerX如果存在,说明要找的节点不是顶点的第一个节点while (curVerX) {let preVerX = curVerX;// 继续查找下一条边curVerX = curVerX.nextEdge;if (curVerX && curVerX.data === y) {preVerX.nextEdge = curVerX.nextEdge;this.adj[posX].outNum--;curVerX = null;}}// 删除边(y, x)// 如果顶点的第一个节点即是要找的节点if (curVerY.data === x) {// 把y顶点的下一条边赋值给第一条边this.adj[posY].firstEdge = curVerY.nextEdge;this.adj[posY].outNum--;curVerY = null;}//curVerY如果存在,说明要找的节点不是顶点的第一个节点while (curVerY) {let preVerY = curVerY;curVerY = curVerY.nextEdge;if (curVerY && curVerY.data === x) {preVerY.nextEdge = curVerY.nextEdge;this.adj[posY].outNum--;curVerY = null;}}} else {// 删除边<x, y>// 如果顶点的第一个节点即是要找的节点if (curVerX.data === y) {this.adj[posX].firstEdge = curVerX.nextEdge;this.adj[posX].outNum--;curVerX = null;}// curVerX如果存在,说明要找的节点不是顶点的第一个节点while (curVerX) {let preVerX = curVerX;curVerX = curVerX.nextEdge;if (curVerx && curVerX.data === y) {preVerX.nextEdge = curVerX.nextEdge;this.adj[posX].outNum--;curVerX = null;}}this.adj[posY].inNum--;}this.eNum--;}}
删除顶点
与删除边操作不同的是,在删除图中的一个顶点时,与此顶点所有相邻的边都要删除。此时需要分为两步操作,第一步删除所有以x为起点的边,第二步删除所有以x为终点的边。
// 从图中删除顶点x,与删除边操作不同//在删除图中的一个顶点时,与此顶点所有相邻的边都要删除。// 两步操作,第一步删除所有以x为起点的边,第二步删除所有以x为终点的边deleteVertex(x) {let pos = this._find(x);if (pos > -1) {// 删除从x出发的边let curVer = this.adj[pos].firstEdge;while (curVer) {this.removeEdge(x, curVer.data);curVer = curVer.nextEdge;}// 删除终点是x的边for (let i = 0; i < this.adj.length; i++) {let temVer = this.adj[i].firstEdge;while (temVer) {if (temVer.data === x) {this.removeEdge(this.adj[i].data, temVer.data);}temVer = temVer.nextEdge;}}// 删除顶点xthis.adj.splice(pos, 1);}}
所有相邻节点
// 与顶点x邻接的所有节点// 不断的遍历每个顶点的边allNeightbors(x) {let pos = this._find(x);if (pos > -1) {let result = `${x}`;let curVer = this.adj[pos].firstEdge;while (curVer) {result += `=>${curVer.data}`;curVer = curVer.nextEdge;}console.log(result);}}
测试邻接表结构
let arr = ["A", "B", "C", "D", "E"];let myGraph = new Graph(0);myGraph.initVertex(arr);myGraph.addEdge("A", "B");myGraph.addEdge("A", "C");myGraph.addEdge("A", "E");myGraph.addEdge("B", "E");myGraph.addEdge("C", "E");myGraph.addEdge("D", "B");myGraph.addEdge("D", "C");myGraph.addEdge("D", "E");for (let i = 0; i < arr.length; i++) {myGraph.allNeightbors(arr[i]);}// 断开c和、e的连接myGraph.removeEdge("C", "E");for (let i = 0; i < arr.length; i++) {myGraph.allNeightbors(arr[i]);}
输出为:
A=>B=>C=>EB=>A=>E=>DC=>A=>E=>DD=>B=>C=>EE=>A=>B=>C=>D
将C和E之间断开测试
myGraph.removeEdge('C', 'E');for(let i=0; i<arr.length; i++) {myGraph.allNeightbors(arr[i]);}// 输出为A=>B=>C=>EB=>A=>E=>DC=>A=>DD=>B=>C=>EE=>A=>B=>D
图的深度遍历和广度遍历
代码结构:
class Graph {// 广度优先求出图中所有的连通分量,从给定的顶点x开始BFSTraverse(x) {}// 实际进行广度遍历的函数,每次遍历都是得到一个以顶点x为起点的连通分量_BFS(x, visited) {}// 深度优先求出图中所有的连通分量,从给定的顶点x开始DFSTraverse(x) {}// 实际进行深度遍历的函数,每次遍历都是得到一个以顶点x为起点的连通分量_DFS(x, visited) {}}
广度优先遍历
BFS breath first search | BFSTraverse(x)函数每次从顶点x出发,使用_BFS()函数遍历图中以x为起点的一个连通分量。如果从x开始不能遍历到图中的所有顶点,则BFSTraverse(x)会尝试从另一个没有被访问过的顶点开始求其连通分量,直到图中所有的顶点都被访问过
首先访问起始顶点v,接着由v出发,依次访问v的各个未访问过的邻接顶点w1,w2,……,然后再依次访问w1,w2,……,wi的所有未被访问过的邻接顶点。
再从访问过的顶点出发,再访问所有未被访问过的邻接顶点,依次类推,直到所有的顶点都被访问过。完成广度优先遍历
- 如果无向图是连通的,则从给定的顶点出发,仅需一次遍历就能够访问图中所有的顶点;如果无向图是非连通的,则给定的顶点出发,一次遍历只能访问到该顶点所在的连通分量的所有顶点,而对于图中其他连通分量的顶点,则无法通过这次遍历访问。
- 有向图,如果从初始点到图中的每个顶点都有路径,则能访问到图中所有的顶点,否则不能访问到所有的顶点。
使用visted数组表示顶点是否被访问过。
// 广度优先求出图中所有的连通分量,从给定的顶点x开始BFSTraverse(x = this.adj[0].data) {// 访问过的标记数组,标记数组和顶点表 相关联的是下标let visited = [];let result = "";for (let i = 0; i < this.adj.length; i++) {// 设置一个visited数组,将其全部赋值为false表示所有的节点都没有被访问过visited[i] = false;}// 使用_BFS()函数来求以顶点x为起点的连通分量,并将visited数组作为参数传入// 求以x为起始点的连通分量, 第一次Aresult = this._BFS(x, visited);// 求出以顶点x为起点的连通分量后,BFSTraverse()函数则再次遍历visited数组,查看是否还有未被访问过的节点。for (let i = 0; i < visited.length; i++) {// 如果有还未被访问过的顶点,则从该顶点继续遍历if (!visited[i]) {let x = this.adj[i].data;// 再次调用_BFS()函数,并传入未被访问过的顶点和visited数组。result += `&${this._BFS(x, visited)}`; // 其他的连通分量}}return result;}//两个循环,外层循环每次从队列中取出一个顶点,使用内层循环依次访问该顶点的边表中的所有节点。// 实际进行广度遍历的函数,每次遍历都是 获得一个以顶点x为起点的所有连通分量_BFS(x, visited) {let result = "";let queue = [];let pos = this._find(x);if (pos > -1) {result += `${x}`;visited[pos] = true;// 获取到当前顶点let curVer = this.adj[pos];// 顶点x入队列queue.push(curVer);while (queue.length) {// 取出队列的第一个值,取出一个顶点curVer = queue.shift();// 回到顶点的表中,再次计算pos = this._find(curVer.data);curVer = this.adj[pos].firstEdge; // 第一次是 A - B//检测顶点的所有邻接点,内层循环依次访问该顶点边表中所有节点while (curVer) {pos = this._find(curVer.data); // B// 如果当前顶点未被访问过if (!visited[pos]) {result += `->${curVer.data}`;// 标记未已经访问过visited[pos] = true;// 内层循环不断的将当前起始节点的所有未访问过的边表节点加入队列queue.push(curVer);}curVer = curVer.nextEdge;}}}return result;}
简而言之,_BFS()函数就是从顶点x出发,依次遍历与x相邻的节点,再从这些相邻的节点出发再访问各自的相邻节点。为了不重复访问同一个节点,使用visited数组做访问标识,如果发现要访问的节点已经被访问过了就跳过这个节点。
广度优先遍历下图
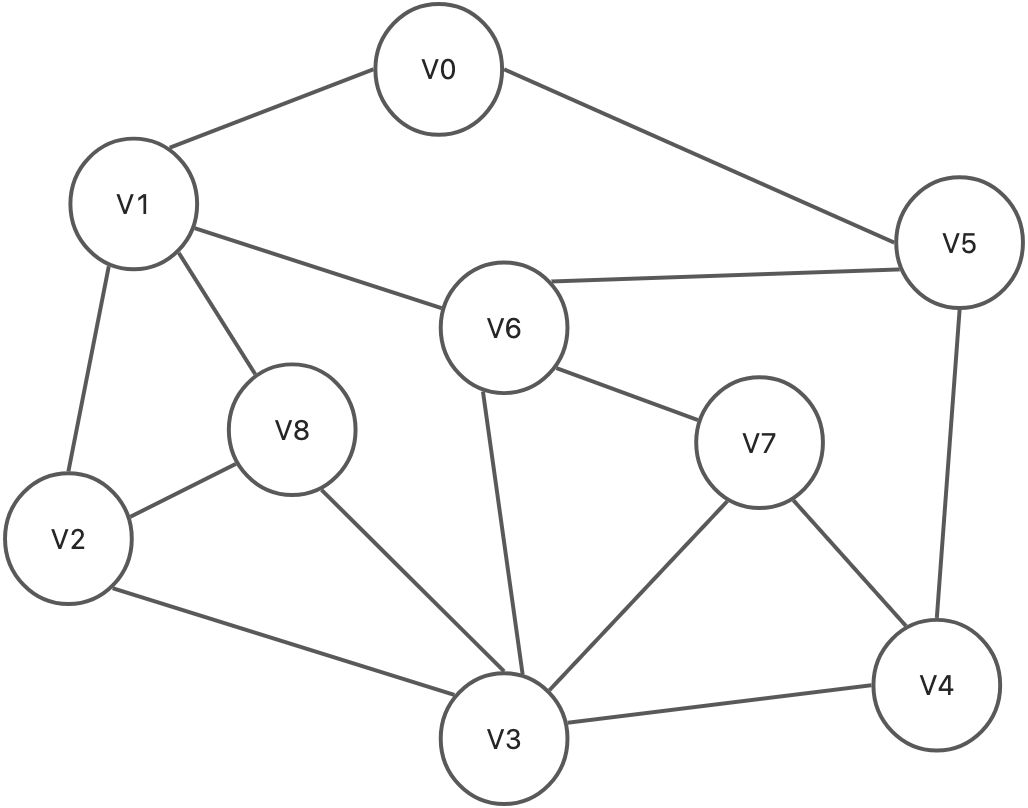
构建图结构
let arr = ['V0', 'V1', 'V2', 'V3', 'V4', 'V5', 'V6', 'V7', 'V8'];let myGraph = new Graph(0); // 0表示无向图myGraph.initVertex(arr);// 插入边myGraph.addEdge('V0', 'V1');myGraph.addEdge('V0', 'V5');myGraph.addEdge('V1', 'V2');myGraph.addEdge('V1', 'V6');myGraph.addEdge('V1', 'V8');myGraph.addEdge('V2', 'V3');myGraph.addEdge('V2', 'V8');myGraph.addEdge('V3', 'V4');myGraph.addEdge('V3', 'V6');myGraph.addEdge('V3', 'V7');myGraph.addEdge('V3', 'V8');myGraph.addEdge('V4', 'V5');myGraph.addEdge('V4', 'V7');myGraph.addEdge('V5', 'V6');myGraph.addEdge('V6', 'V7');// 输出图的邻接表for(let i=0; i<arr.length; i++) {myGraph.allNeightbors(arr[i]);}/*V0=>V1=>V5V1=>V0=>V2=>V6=>V8V2=>V1=>V3=>V8V3=>V2=>V4=>V6=>V7=>V8V4=>V3=>V5=>V7V5=>V0=>V4=>V6V6=>V1=>V3=>V5=>V7V7=>V3=>V4=>V6V8=>V1=>V2=>V3*/// 从顶点V0到V8依次广度优先遍历/*V0->V1->V5->V2->V6->V8->V4->V3->V7V1->V0->V2->V6->V8->V5->V3->V7->V4V2->V1->V3->V8->V0->V6->V4->V7->V5V3->V2->V4->V6->V7->V8->V1->V5->V0V4->V3->V5->V7->V2->V6->V8->V0->V1V5->V0->V4->V6->V1->V3->V7->V2->V8V6->V1->V3->V5->V7->V0->V2->V8->V4V7->V3->V4->V6->V2->V8->V5->V1->V0V8->V1->V2->V3->V0->V6->V4->V7->V5*/
如果断开V0和V1,V5的连接, 且还是从V0开始遍历会发生什么呢?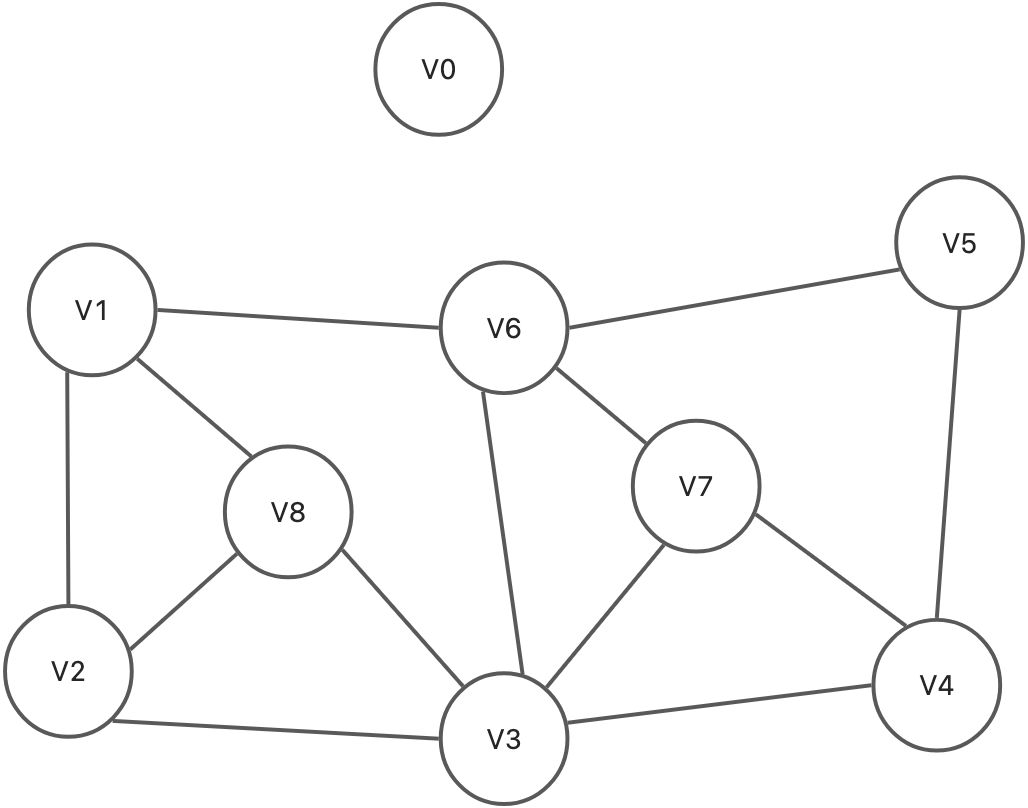
myGraph.removeEdge('V0', 'V1');myGraph.removeEdge('V0', 'V5');for(let i=0; i<arr.length; i++) {console.log(myGraph.BFSTraverse(arr[i]));}// V0成单独的连通分量/*V0&V1->V2->V6->V8->V3->V5->V7->V4V1->V2->V6->V8->V3->V5->V7->V4&V0V2->V1->V3->V8->V6->V4->V7->V5&V0V3->V2->V4->V6->V7->V8->V1->V5&V0V4->V3->V5->V7->V2->V6->V8->V1&V0V5->V4->V6->V3->V7->V1->V2->V8&V0V6->V1->V3->V5->V7->V2->V8->V4&V0V7->V3->V4->V6->V2->V8->V5->V1&V0V8->V1->V2->V3->V6->V4->V7->V5&V0*/
深度优先遍历
首先访问图中某一个起始顶点x,然后由x出发,访问与x邻接且未被访问的任一个顶点w1,再访问与w1邻接的未被访问的任一个顶点w2,重复这个过程,当不能再继续向下访问时,依次退回到最近被访问的顶点,若它还有邻接顶点未被访问过,则从该点开始继续上述搜索过程,直到图中所有的顶点都被访问过为止。
与广度优先遍历一样,从某个给定顶点开始,如果无向图是连通的,则这个给定的顶点出发,仅需一次遍历就能够访问图中所有的顶点;如果无向图是非连通的,则从这个顶点出发,一次遍历只能访问到该顶点所在的连通分量的所有顶点,而对于图中其他连通分量的顶点,则无法通过这次遍历访问。
对于有向图来说,如果从初始点到图中的每个顶点都有路径,则能够访问到图中所有的顶点,否则不能访问到所有的顶点。
代码如下:
// 深度优先求出图中所有的连通分量,从给定的顶点x开始DFSTraverse(x) {let result = "";//设置一个visited数组,let visited = [];for (let i = 0; i < this.adj.length; i++) {//将其全部赋值为false,表示所有的节点都没有被访问过。visited[i] = false;}//使用_DFS()函数来求以顶点x为起点的连通分量,并将visited数组作为参数传入result = this._DFS(x, visited);//当_DFS()函数求出以顶点x为起点的连通分量后,DFSTraverse()函数再次遍历visited数组,//查看是否还有未被访问过的节点。// 如果还有未被访问过的顶点,则以该顶点再次出发,for (let i = 0; i < visited.length; i++) {if (!visited[i]) {let x = this.adj[i].data;//再次调用_DFS()函数,并传入未被访问过的顶点和visited数组。result += `&${this._DFS(x, visited)}`;}}return result;}// 实际进行深度遍历的函数,每次遍历都是得到 以顶点x为起点的连通分量_DFS(x, visited) {let result = "";let stack = []; // 辅助堆栈let pos = this._find(x);let curVer = this.adj[pos]; // 根据给的x值找到具体的顶点if (pos > -1) {stack.push(curVer); // 顶点x入栈result += `${x}`;// 访问过的顶点,做标记visited[pos] = true;while (stack.length) {// 获取栈顶元素,不能使用pop,pop会把节点删除curVer = stack[stack.length - 1];// 获取栈顶元素在顶点表中的位置pos = this._find(curVer.data);// 获取顶点的第一个邻接点curVer = this.adj[pos].firstEdge;// 邻接点存在while (curVer) {pos = this._find(curVer.data);if (visited[pos]) {// 如果该节点已经访问过了,则访问该节点的下一个相邻的节点curVer = curVer.nextEdge;} else {stack.push(curVer);result += `->${curVer.data}`;visited[pos] = true;break;}}// 如果顶点的所有邻接点都访问过if (!curVer) stack.pop();}}return result;}
与广度优先遍历一样,也使用visited标记数组,作用是相同的。
_DFS()函数:
当不能再继续向下访问时,依次退回到最近被访问的顶点,使用一个堆栈来辅助完成遍历。每次遇到一个节点,就将其压入堆栈,做已访问标识后访问其一个相邻的节点:
- 如果发现这个节点的相邻节点中有未被访问过的,则访问这个节点,并将其压入堆栈,做已访问标识,再访问这个节点的一个相邻节点
- 如果这个节点的所有相邻节点都被访问过了,而此时堆栈还不为空,就将其弹出去。再取堆栈的栈顶元素重复步骤1的操作,如果这个节点的所有相邻节点又全被访问过了,就再将其弹出去…,依此往复,直到堆栈为空结束。
从顶点V0到V8对其进行深度优先遍历:
for(let i=0; i<arr.length; i++) {console.log(myGraph.DFSTraverse(arr[i]));}/*V0->V1->V2->V3->V4->V5->V6->V7->V8V1->V0->V5->V4->V3->V2->V8->V6->V7V2->V1->V0->V5->V4->V3->V6->V7->V8V3->V2->V1->V0->V5->V4->V7->V6->V8V4->V3->V2->V1->V0->V5->V6->V7->V8V5->V0->V1->V2->V3->V4->V7->V6->V8V6->V1->V0->V5->V4->V3->V2->V8->V7V7->V3->V2->V1->V0->V5->V4->V6->V8V8->V1->V0->V5->V4->V3->V2->V6->V7*/
for(let i=0; i<arr.length; i++) {console.log(myGraph.DFSTraverse(arr[i]));}/*V0&V1->V2->V3->V4->V5->V6->V7->V8V1->V2->V3->V4->V5->V6->V7->V8&V0V2->V1->V6->V3->V4->V5->V7->V8&V0V3->V2->V1->V6->V5->V4->V7->V8&V0V4->V3->V2->V1->V6->V5->V7->V8&V0V5->V4->V3->V2->V1->V6->V7->V8&V0V6->V1->V2->V3->V4->V5->V7->V8&V0V7->V3->V2->V1->V6->V5->V4->V8&V0V8->V1->V2->V3->V4->V5->V6->V7&V0*/
最小生成树
最小生成树具有某些特定的性质:
- 最小生成树的边数总是比其顶点数少一个。
- 最小生成树可能不是唯一的,但是不同的最小生成树的权值之和总是相同的。
求最小生成树有两种非常经典的方法——普里姆算法和克鲁斯卡尔算法, 在本篇中会详细介绍如何使用JS实现这两种经典算法。
代码结构
class Graph {// ...以上实现的代码,省略// 获取边(x, y)或<x, y>对应的权值getEdgeWeight(x, y) {}// 获得图中权重之和getSumOfWeight() {}// 判断当前的图是否是连通图isConnected(x = this.adj[0].data) {}// 普里姆算法getPrimMST(){}// 获取图中所有的边getAllEdges() {}// 克鲁斯卡尔算法getKruskalMST(){}}
在求最小生成树之前,还有一些准备工作要做:
- 获取图中边的权值
- 判断给定的图是否是一幅连通图
- 获取图中的权值之和
- 获取图中所有的边
首先是获取图中边上的权值,不管是普里姆算法还是克鲁斯卡尔算法都要用到这个方法,该方法获取边(x, y)或
// 获取边(x, y)或<x, y>对应的权值getEdgeWeight(x, y) {let pos = this._find(x);if (pos > -1) {let curVer = this.adj[pos].firstEdge;while (curVer) {if (curVer.data === y) return curVer.weight;curVer = curVer.nextEdge;}return 0;}}
判断给定的图是否是一幅连通图
然后要知道所求最小生成树的图是不是连通图,如果不是连通图,那么对其求最小生成树就没有意义。
该方法使用到了上文提到的_BFS方法,或_DFS方法来遍历一幅图,若其在遍历完一次之后仍有顶点未被访问到,那么说明这张图不是一幅连通图。
// 判断当前的图是否是连通图isConnected(x = this.adj[0].data) {// 任选一个点作为顶点let len = this.adj.length;let visited = new Array(len); // 把所有点都有进行记录,后边判断是否还有未被访问的点时使用for (let i = 0; i < len; i++) {visited[i] = false;}this._BFS(x, visited);// 如果遍历一边之后仍有顶点未被访问,则该图不是连通的for (let i = 0; i < len; i++) {if (!visited[i]) return false;}return true;}
普里姆算法
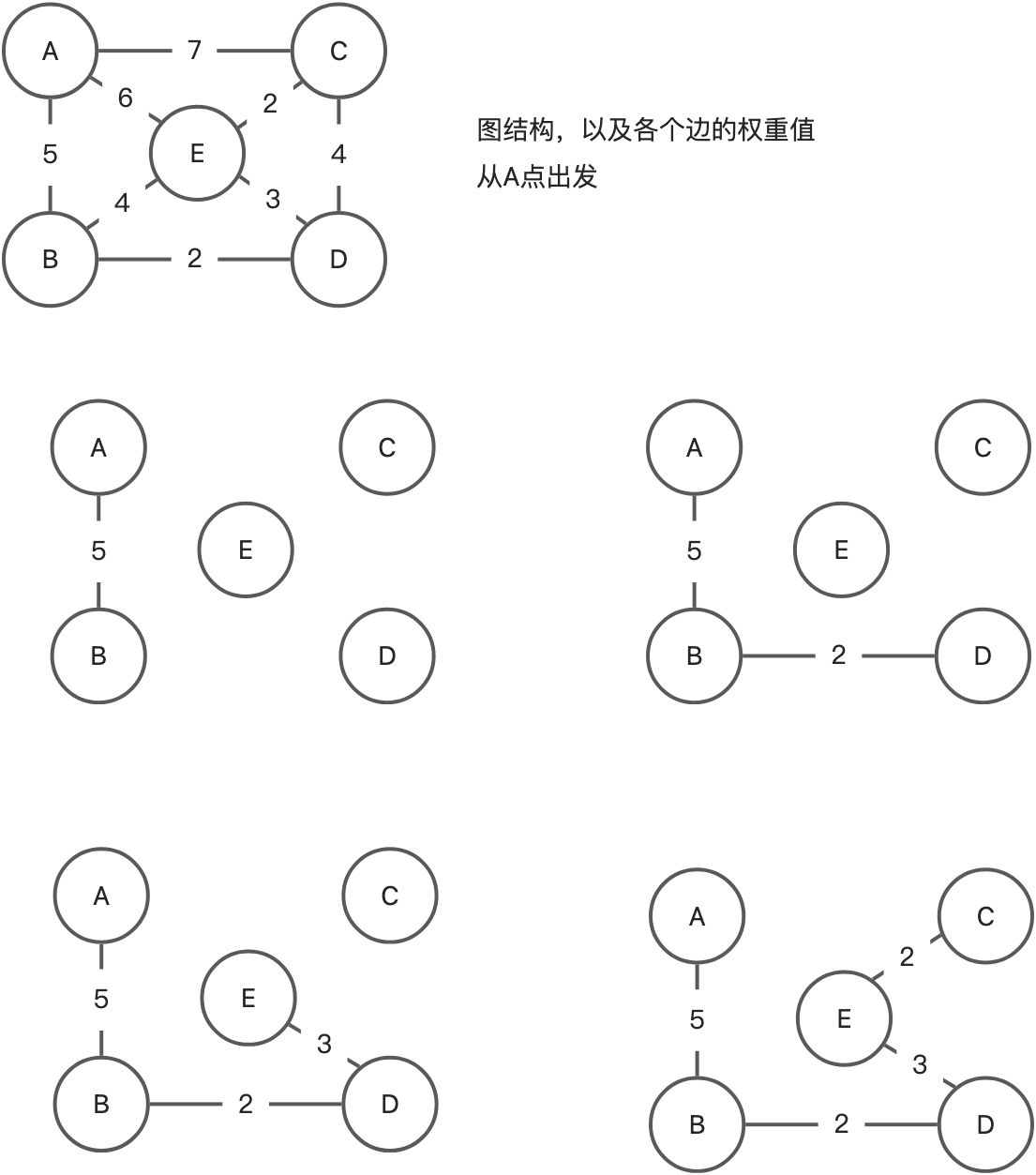
按照上图查找下一步的过程,可以得出最小生成树的结果。接下来用代码实现。
尝试使用文字来描述这个过程:
假设 N={V, E} 是连通网,V是图中所有顶点的集合,E是图中所有边的结合,ET是N上最小生成树边的集合,初始时ET={},VT={V0}。 算法在u∈VT,v∈V-VT中选择一条权值最小的边(u,v)加入ET集合中,同时将v加入VT中,重复这个过程,一直到VT等于V为止。
换上一种更容易懂的说法:假设V是图中所有所有顶点的集合,VT初始时在V中任选一个顶点(算法实现里假设总是选择第一个顶点),找出VT与V-VT中所有能构成的边的组合,选择其中权重最小的组合,然后取出这个组合在V-VT的中顶点放入VT中,直到VT=V。
// 普里姆算法getPrimMSTree() {// 不是连通图时求最小生成树没有意义if (!this.isConnected) return;let V = this.adj; // 顶点集Vlet Vt = [V[0]]; // 添加任意一个顶点let VVt = V.filter((x) => Vt.indexOf(x) === -1); // VVt = V - Vt, 出去Vt点的其他点集合//初始化空图let MinTree = new Graph(this.isDirect);// 将点集合,插入到树中V.forEach((x) => MinTree.insertVertex(x.data));// 若树中不含全部顶点while (Vt.length !== V.length) {//当找到权值最小的边时,m VT是边的一个顶点let mVt = null;//当找到权值最小的边时,m V_VT是边的另一个顶点let mVVt = null;// 最小权重值,先将minW赋个极大的数值let minW = Number.MAX_SAFE_INTEGER;// 在VT和V_VT中找到边中的最小权值// 从VT中取出一个顶点for (let i = 0; i < Vt.length; i++) {// 从VVt中取出一个顶点for (let j = 0; j < VVt.length; j++) {// 获取Vt-VVt之间的权重值let weight = this.getEdgeWeight(Vt[i].data, VVt[j].data);// 权重值weight小于最小值if (weight && minW > weight) {// 更新最小值minW = weight;mVt = Vt[i];mVVt = VVt[j];}}}Vt.push(mVVt);MinTree.addEdge(mVt.data, mVVt.data, minW);VVt = V.filter((x) => Vt.indexOf(x) === -1);}return MinTree;}
算法在u∈VT,v∈V-VT中选择一条权值最小的边(u,v)加入ET集合中,同时将v加入VT中
其在算法中的实现过程是在新建的空树中添加一条连接顶点u和v的一条边(u,v),并赋予相同的权值。重复这个过程,随着VT和V相等之后,这个新建的图就变成最小生成树
实现一个获取权重之和的函数,来判断最小生成树是否正确生成
// 获得图中权重之和getSumOfWeight() {// 当图不是连通的时候,获取权重之和没有意义if (!this.isConnected()) return;let sum = 0;let vertex = this.adj;if (!this.isDirect) {// 如果是无向图for (let i = 0; i < vertex.length - 1; i++) {for (let j = i; j < vertex.length; j++) {let weight = this.getEdgeWeight(vertex[i].data, vertex[j].data);if (weight) sum += weight;}}} else {for (let i = 0; i < vertex.length; i++) {for (let j = 0; j < vertex.length; j++) {let weight = this.getEdgeWeight(vertex[i].data, vertex[j].data);if (weight) sum += weight;}}}return sum;}
使用Prim算法求得最小生成树,并用这个方法来测试下上图:
let arr = ['A', 'B', 'C', 'D', 'E'];let myGraph = new Graph(0); // 0表示无向图myGraph.initVertex(arr);myGraph.addEdge('A', 'B', 5);myGraph.addEdge('A', 'C', 7);myGraph.addEdge('A', 'E', 6);myGraph.addEdge('B', 'D', 2);myGraph.addEdge('B', 'E', 4);myGraph.addEdge('C', 'D', 4);myGraph.addEdge('C', 'E', 2);myGraph.addEdge('D', 'E', 3);let MSTree = myGraph.getPrimMSTree();console.log(MSTree.BFSTraverse()); // 广度优先遍历下看看// 输出A->B->D->E->Cconsole.log(MSTree.DFSTraverse()); // 深度优先遍历下看看// 输出A->B->D->E->Cconsole.log(MSTree.getSumOfWeight());// 输出12
克鲁斯卡尔算法
使用图片来描述克鲁斯卡尔算法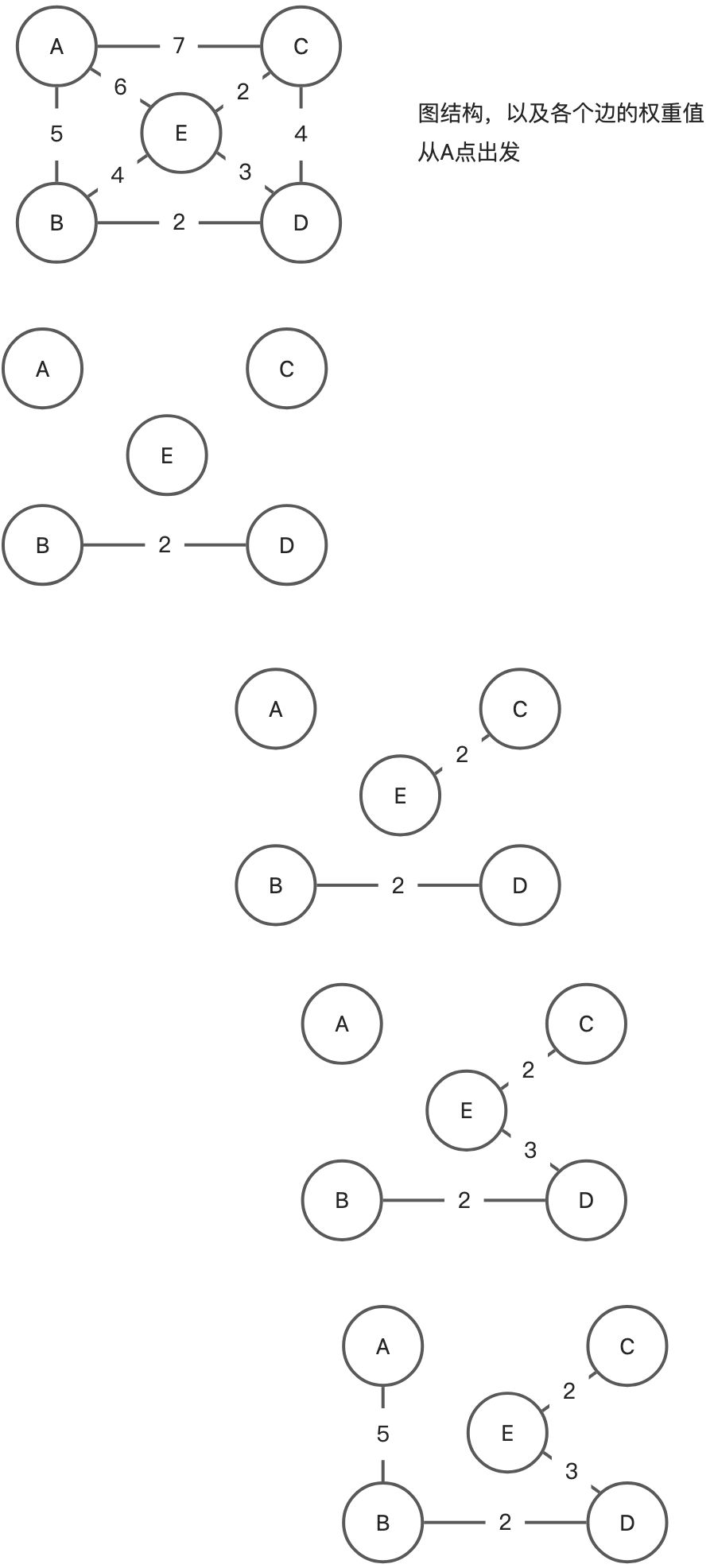
克鲁斯卡尔算法比较好理解一些,它是一种按照权值递增次序选择合适的边来构造最小生成树的方法。
假设在一个给定的带权连通无向图 N=(V, E) 中,其对应的最小生成树是 T=(VT, ET),克鲁斯卡尔算法的过程为:
初始时有VT=V,ET=Ø。可以把每个顶点都看作是一颗独立的树,T此时是一个仅含有顶点的森林,在E-ET中按照权值递增的顺序依次选择一条边,如果将这条边加入T后不构成回路,则将其加入ET中,否则舍弃,直到ET中边的个数比T中的顶点的个数少一个。
算法的基本思想是先找权重最小的边,再找权重次小的边…,如果找到的边加入最小生成树中不构成回路就保留,否则舍弃。
为了在所有的边中按照权值递增的次序选择边,在实现克鲁斯卡尔算法前首先要实现一个方法用来获取图中的所有的边。这个方法叫getAllEdges
// 获取图中所有的边getAllEdges() {let vertex = this.adj; // 图中的所有顶点let edges = []; // 在edges中存放图中所有的边// 如果是无向图if (!this.isDirect) {for (let i = 0; i < vertex.length - 1; i++) {for (let j = i; j < vertex.length; j++) {// 判断2个点之间是否有边if (this.hasEdge(vertex[i].data, vertex[j].data)) {let weight = this.getEdgeWeight(vertex[i].data, vertex[j].data);edges.push([vertex[i].data, vertex[j].data, weight]);}}}}// 如果有向图else {for (let i = 0; i < vertex.length; i++) {for (let j = 0; j < vertex.length; j++) {if (this.hasEdge(vertex[i].data, vertex[j].data)) {let weight = this.getEdgeWeight(vertex[i].data, vertex[j].data);edges.push([vertex[i].data, vertex[j].data, weight]);}}}}// 在edges数组中,每一个元素都是一个数组,该数组一共三个元素// 顶点x的值,顶点y的值,和顶点x和y构成的边上的权值return edges;}
这个方法返回一个二维数组,在edges数组中,每一个元素都是一个数组,该数组一共三个元素,分别是顶点x的值,顶点y的值,和顶点x和y构成的边上的权值。
在算法中,新建一颗空树,并用给定的连通图中的顶点来初始化这颗树。一开始的时候,由于这个空树中只有顶点,所以在这棵空树中的连通分量就是顶点的数目,每次找到一条符合条件的权值最小的边加入这颗空树中后,该空树的连通分量就会减一,如果循环一直继续的话,随着边的不断加入,如果不加以控制的话,该最小生成树最后就会形成回路,需要在其形成回路前终止循环,也就是随着边的不断加入,该最小生成树中的连通分量在等于1之前结束循环。
在找到权值最小的边之后,假设这条边叫做(u, v),从顶点u开始对该尚未形成的最小生成树进行一次广度或者深度优先遍历,因为之前的遍历算法中,如果一张图中具有多个连通分量,那么对这张图进行遍历后的结果就会以 ‘&’ 将每个连通分量隔开,因为是从顶点u开始遍历的,那么在遍历后的结果中,顶点u所在的连通分量一定在第一个 ‘&’ 分隔符之前,所以算法中在遍历的结果中只取第一个 ‘&’ 前面的字符串,如果发现顶点v不在该字符串当中,那就说明u和v属于树中不同的连通分量,可以放心大胆的将边(u,v)加入要生成的最小生成树当中而不必担心产生回路。而如果顶点u和顶点v属于同一个连通分量的话,就说明顶点u和顶点v之间已经具有路径了,此时如果再直接连接顶点u和顶点v则必然会产生回路,所以就应该舍弃这条边
// 克鲁斯卡尔算法// 算法的基本思想是先找权重最小的边,再找权重次小的边getKruskalMSTree() {// 不是连通图时求最小生成树没有意义if (!this.isConnected()) return;let V = this.adj; // 顶点集Vlet numS = V.length; // 树中的连通分量let E = this.getAllEdges(); // 在E中存放图中所有的边let mEdge = null;let MSTree = new Graph(this.isDirect); // 初始化空树V.forEach((x) => MSTree.insertVertex(x.data)); // 树中只有顶点while (numS > 1) {let minWeight = Number.MAX_SAFE_INTEGER;// 从图中取出权值最小的边<u, v>for (let i = 0; i < E.length; i++) {if (E[i][2] < minWeight) {mEdge = E[i];minWeight = E[i][2];}}//广度优先遍历let result = MSTree.BFSTraverse(mEdge[0]);//只取&前面的字符串result = result.split("&")[0];let pos = result.indexOf(mEdge[1]);// 如果u和v属于树中不同的连通分量,就将此边加入生成树中// 从顶点mEdge[0]遍历一遍发现没有mEdge[1],说明两个顶点不在一个连通分量之中if (pos === -1) {MSTree.addEdge(mEdge[0], mEdge[1], mEdge[2]);numS--;}// 去掉E中权值最小的边E = E.filter((x) => x !== mEdge);}return MSTree;}
测试下克鲁斯卡尔算法
let MSTree = myGraph.getKruskalMST();console.log(MSTree.BFSTraverse()); // 广度优先遍历下看看// 输出A->B->D->E->Cconsole.log(MSTree.DFSTraverse()); // 深度优先遍历下看看// 输出A->B->D->E->Cconsole.log(MSTree.getSumOfWeight());// 输出12
最短路径
在带权图中,把从一个顶点到图中任一个顶点的一条路径(可能有多条路径)上所经过边上的权值之和定义为该路径的带权路径长度,其中权值之和最小的那条路径叫做最短路径。【在有向图中】
求最短路径还可以分为求单源最短路径和各个顶点之间的最短路径问题。本篇中只会介绍使用Dijkstra算法求单源最短路径。
Dijkstra算法
求带权有向图中某个源点到其余各顶点的最短路径,最常用的是Dijkstra算法。该算法设置一个集合S(可用数组实现)用来记录已求得的最短路径的顶点。该集合初始时将源点放入其中,此后每求出源点到某个顶点的最短路径,就将该顶点放入集合中来。
除此之外,实现该算法时用到了两个辅助数组:
- dist:记录了从源点到其他各顶点当前的最短路径长度。
- path:表示从源点到顶点 i 之间的最短路径。
假设从顶点0出发,集合S最初只包含顶点0,邻接矩阵arcs表示带权有向图, arcs[i][j]表示有向边
- 集合S初始时为{V0},dist的初始值dist[i] = arcs[0][i],i 表示顶点Vi。0表示顶点V0。
- 从顶点集合V-S中选出一个顶点,假设为Vj,其满足dist[j] = Min {dist[i] | Vi∈V-S},Vj就是当前求得的V0到Vj的最短路径的终点,并令S = S ∪ { Vj }。
- 修改从V0出发到集合V-S上任意一个顶点Vk可到达的最短路径,V0初始时可能并不能直接到达顶点Vk,这时可以通过顶点 Vj 作为中转看看是否能够到达,或者通过Vj作为中转后到达的路径权值之后小于之前已有的数值,那么就可以做出一些修改了:如果dist[j] + arcs[j][k] < dist[k],则令dist[k] = dist[j] + arcs[j][k]。
重复步骤2和3,直到所有的顶点都包含在集合S中。
/*** 求带权图顶点x到其他顶点的最短路径* 从x到y可能有多条路径,把带权路径长度最短的那条路径称为最短路径* 求解最短路径的算法通常都依懒于一种性质,* 也就是两点之间的最短路径也包含了路径上的其他顶点间的最短路径* @param {*} x*/// x点到其他各个点最短路径getShortestPath(x) {// 使用Dijkstra算法,// 如果是无向图或者边有负的权值时退出// 如果x不存在于图中时退出// 如果从顶点x到不了图中任意一个顶点则退出if (!this.isDirect ||this.getMinEdgeWeight() < 0 ||this._find(x) === -1 ||!this.isConnected(x)) {return -1;}var MAX = Number.MAX_SAFE_INTEGER;// 初始化var len = this.adj.length;// 在dist数组中,dist[i]的初值为顶点x到顶点i之间的权值,// x到i没有路径时,dist[i]记为无穷大var dist = [];var path = []; // path[i]表示顶点x到i的最短路径var vers = []; // 顶点集var exts = [x]; // 已找到最短路径的点的集合// 初始化path和dist数组for (let i = 0; i < len; i++) {vers[i] = this.adj[i].data;dist[i] = this.getEdgeWeight(x, vers[i]) || MAX;if (dist[i] !== MAX) {path[i] = `${x}->${vers[i]}`;} else {path[i] = "";}}var rem = vers.filter((x) => exts.indexOf(x) === -1); // 剩余的顶点var n = 1;while (n < len) {// 在dist中寻找最小值var min = MAX;var idx = -1;for (let i = 0; i < len; i++) {if (min > dist[i]) {min = dist[i];idx = i;}}var Vj = vers[idx]; // 直接找到Vjdist[idx] = MAX;exts.push(Vj);rem = vers.filter((x) => exts.indexOf(x) === -1);console.log(path[idx]); // 输出最短路径// 松弛工作for (let i = 0; i < rem.length; i++) {// Vj到其他节点的距离var w = this.getEdgeWeight(Vj, rem[i]) || MAX;var k = vers.indexOf(rem[i]);if (w + min < dist[k]) {dist[k] = w + min;path[k] = `${path[idx]}->${rem[i]}`;}}n++;}}
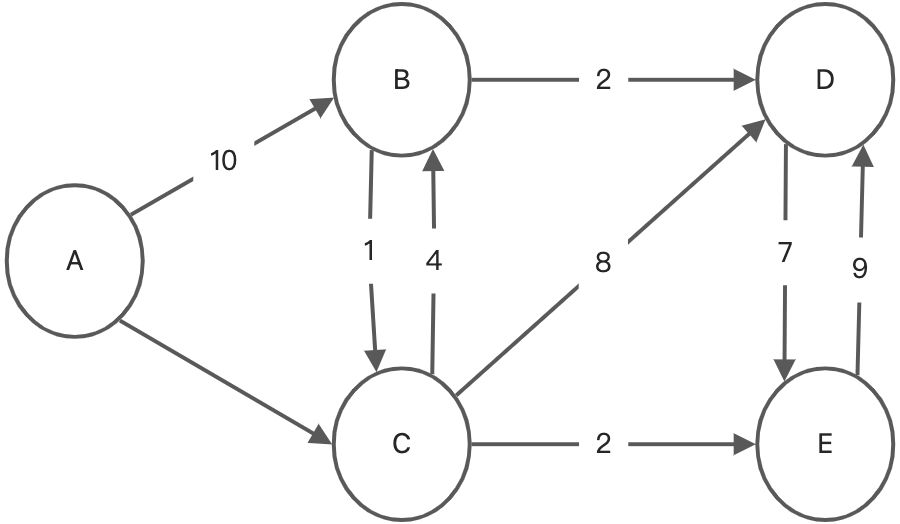
var arr = ['A', 'B', 'C', 'D', 'E'];var myGraph = new Graph(1); // 1表示有向图myGraph.initVertex(arr);myGraph.addEdge('A', 'B', 10);myGraph.addEdge('A', 'C', 3);myGraph.addEdge('B', 'C', 1);myGraph.addEdge('B', 'D', 2);myGraph.addEdge('C', 'B', 4);myGraph.addEdge('C', 'D', 8);myGraph.addEdge('C', 'E', 2);myGraph.addEdge('D', 'E', 7);myGraph.addEdge('E', 'D', 9);// 查看邻接表for(let i=0; i<arr.length; i++) {myGraph.allNeightbors(arr[i]);}// 输出:// A=>B=>C// B=>C=>D// C=>B=>D=>E// D=>E// E=>D// 用上面写的代码求顶点A到其他顶点的最短路径myGraph.getShortestPath('A');// 输出:// A->C// A->C->E// A->C->B// A->C->B->D
从输出中可以看到最短路径中有一个很重要的性质:两点之间最短路径包含路径上其他顶点间的最短路径。

若有收获,就点个赞吧
0 人点赞
