一、RabbitMQ
队列
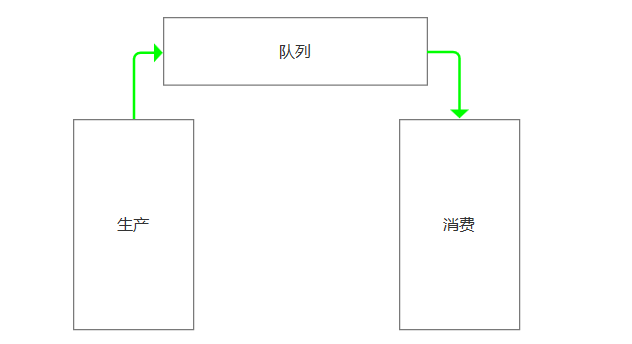
在生产者消费模型中,比如去餐馆吃饭的例子。生产者相当于厨师,队列相当于服务员,消费者就是你。
我们必须通过服务员,才能吃饭!
如果队列满了,队列会一直hold住。必须让消费者,获取一个,队列才能解除hold状态。
队列本身就有一个锁,保证数据安全
举例:
import queueq = queue.Queue(maxsize=10)q.put(10)q.put(8)q.put(6)print(q.get())print(q.get())print(q.get())print(q.get())
执行输出:
1086
注意:此时程序并没有结束掉!由于队列已经空了,最后一个get操作会hold住。
如果不想hold住,加一个参数block=0就可以了
import queueq = queue.Queue(maxsize=10)q.put(10)q.put(8)q.put(6)print(q.get())print(q.get())print(q.get())print(q.get(block=0))
执行报错
queue.Empty
这个时候,应该使用try
import queueq = queue.Queue(maxsize=10)q.put(10)q.put(8)q.put(6)print(q.get())print(q.get())print(q.get())try:print(q.get(block=0))except Exception as e:print("raise Empty")
关于队列,请参考链接:
https://www.cnblogs.com/yuanchenqi/articles/6755717.html#_label1
什么叫消息队列
消息(Message)是指在应用间传送的数据。消息可以非常简单,比如只包含文本字符串,也可以更复杂,可能包含嵌入对象。
消息队列(Message Queue)是一种应用间的通信方式,消息发送后可以立即返回,由消息系统来确保消息的可靠传递。消息发布者只管把消息发布到 MQ 中而不用管谁来取,消息使用者只管从 MQ 中取消息而不管是谁发布的。这样发布者和使用者都不用知道对方的存在。
为何用消息队列
从上面的描述中可以看出消息队列是一种应用间的异步协作机制,那什么时候需要使用 MQ 呢?
以常见的订单系统为例,用户点击【下单】按钮之后的业务逻辑可能包括:扣减库存、生成相应单据、发红包、发短信通知。在业务发展初期这些逻辑可能放在一起同步执行,随着业务的发展订单量增长,需要提升系统服务的性能,这时可以将一些不需要立即生效的操作拆分出来异步执行,比如发放红包、发短信通知等。这种场景下就可以用 MQ ,在下单的主流程(比如扣减库存、生成相应单据)完成之后发送一条消息到 MQ 让主流程快速完结,而由另外的单独线程拉取MQ的消息(或者由 MQ 推送消息),当发现 MQ 中有发红包或发短信之类的消息时,执行相应的业务逻辑。
RabbitMQ
RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现。
rabbitMQ是一款基于AMQP协议的消息中间件,它能够在应用之间提供可靠的消息传输。在易用性,扩展性,高可用性上表现优秀。使用消息中间件利于应用之间的解耦,生产者(客户端)无需知道消费者(服务端)的存在。而且两端可以使用不同的语言编写,大大提供了灵活性。

官方文档:
https://www.rabbitmq.com/tutorials/tutorial-one-python.html
中文文档:
rabbitMQ安装
linux平台
1.安装配置epel源rpm -ivh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm2.安装erlangyum -y install erlang3.安装RabbitMQyum -y install rabbitmq-server4.启动服务centos6:service rabbitmq-server startcentos7:systemctl start rabbitmq-server5.启动web管理插件rabbitmq-plugins enable rabbitmq_management6.重启rabbitmq生效web插件centos6:service rabbitmq-server restartcentos7:systemctl restart rabbitmq-server访问页面: http://ip地址:15672# 添加账户rabbitmqctl add_user admin 123456# 设置为超级管理员rabbitmqctl set_user_tags admin administrator
mac
bogon:~ yuan$ brew install rabbitmqbogon:~ yuan$ export PATH=$PATH:/usr/local/sbinbogon:~ yuan$ rabbitmq-server
windows
1.安装erlang双击运行opt_win64_21.1.exe2.安装rabbitmq双击运行 rabbitmq-server-3.7.83.添加windows环境变量Path=%ERLANG_HOME%\bin;%RABBITMQ_SERVER%\sbin4.检测rabbitmq状态rabbitmqctl status5.启动web管理插件rabbitmq-plugins enable rabbitmq_management6.登录web管理界面,账号密码默认都是guest,guesthttp://127.0.0.1:15672/rabbitmq 5672 是提供客户端连接的端口, 15672是提供web管理的端口
rabbitMQ工作模型
简单模式
安装pkia
pip3 install pika
示例
注意:本环境的RabbitMQ是安装在Centos 7 x64系统上面的,IP地址为:192.168.142.128,默认端口5672
生产者
producer.py
import pika# 基于socket连接中间服务器上的rabbitmqconnection = pika.BlockingConnection(pika.ConnectionParameters(host='192.168.142.128'))# 创建对象channel = connection.channel()# 声明一个名为hello的队列channel.queue_declare(queue='hello')# 插数据channel.basic_publish(exchange='', # 交换机routing_key='hello', # 指定的队列名称body='Hello Yuan!') # 值print(" [x] Sent 'Hello Yuan!'")connection.close()
注意:在简单模式中,是没有交换机的。所以exchange参数的值为空
消费者
consumer.py
import pikaconnection = pika.BlockingConnection(pika.ConnectionParameters(host='192.168.142.128'))channel = connection.channel()# 声明一个名为hello的队列channel.queue_declare(queue='hello')# 确定回调函数def callback(ch, method, properties, body):print(" Received %r" % body)channel.basic_consume(callback,queue='hello',no_ack=True)print(' [*] Waiting for messages. To exit press CTRL+C')channel.start_consuming()
先执行producer.py,输出:
[x] Sent 'Hello Yuan!'
再执行consumer.py,输出:
[*] Waiting for messages. To exit press CTRL+CReceived b'Hello Yuan!'
消费者接收到了 Hello Yuan!
为什么消费者要声明一个名为hello的队列呢?生产者,不是明明已经声明了队列了吗?
注意:
如果生产者先运行,那么就会创建hello队列。那么消费者运行时,就不会创建hello队列。这句代码,不会执行!
channel.queue_declare(queue='hello')
如果消费者先执行,那么这里就会创建。假设没有创建hello队列,执行就会报错!
其实生产者和消费者,谁来创建,都无所谓。只要保证队列存在就可以了!
相关参数
(1) no-ack = False
如果消费者遇到情况(its channel is closed, connection is closed, or TCP connection is lost)挂掉了,那么,RabbitMQ会重新将该任务添加到队列中。
- 回调函数中的
ch.basic_ack(delivery_tag=method.delivery_tag) - basic_comsume中的
no_ack=False
消息接收端应该这么写:
import pikaconnection = pika.BlockingConnection(pika.ConnectionParameters(host='10.211.55.4'))channel = connection.channel()channel.queue_declare(queue='hello')def callback(ch, method, properties, body):print(" [x] Received %r" % body)import timetime.sleep(10)print 'ok'ch.basic_ack(delivery_tag = method.delivery_tag)channel.basic_consume(callback,queue='hello',no_ack=False)print(' [*] Waiting for messages. To exit press CTRL+C')channel.start_consuming()
(2) durable :消息不丢失
生产者
import pikaconnection = pika.BlockingConnection(pika.ConnectionParameters(host='10.211.55.4'))channel = connection.channel()# make message persistentchannel.queue_declare(queue='hello', durable=True)channel.basic_publish(exchange='',routing_key='hello',body='Hello World!',properties=pika.BasicProperties(delivery_mode=2, # make message persistent))print(" [x] Sent 'Hello World!'")connection.close()
消费者
import pikaconnection = pika.BlockingConnection(pika.ConnectionParameters(host='10.211.55.4'))channel = connection.channel()# make message persistentchannel.queue_declare(queue='hello', durable=True)def callback(ch, method, properties, body):print(" [x] Received %r" % body)import timetime.sleep(10)print 'ok'ch.basic_ack(delivery_tag = method.delivery_tag)channel.basic_consume(callback,queue='hello',no_ack=False)print(' [*] Waiting for messages. To exit press CTRL+C')channel.start_consuming()
(3) 消息获取顺序
默认消息队列里的数据是按照顺序被消费者拿走,例如:消费者1 去队列中获取 奇数 序列的任务,消费者1去队列中获取 偶数 序列的任务。
channel.basic_qos(prefetch_count=1) 表示谁来谁取,不再按照奇偶数排列
import pikaconnection = pika.BlockingConnection(pika.ConnectionParameters(host='10.211.55.4'))channel = connection.channel()# make message persistentchannel.queue_declare(queue='hello')def callback(ch, method, properties, body):print(" [x] Received %r" % body)import timetime.sleep(10)print 'ok'ch.basic_ack(delivery_tag = method.delivery_tag)channel.basic_qos(prefetch_count=1)channel.basic_consume(callback,queue='hello',no_ack=False)print(' [*] Waiting for messages. To exit press CTRL+C')channel.start_consuming()
exchange模型
3.1 发布订阅
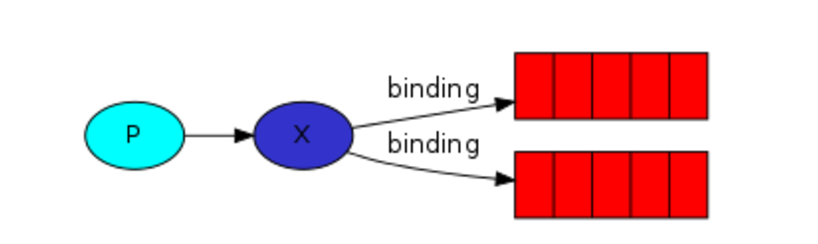
发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。
关键参数:
exchange type = fanout
生产者
import pikaimport sysconnection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))channel = connection.channel()channel.exchange_declare(exchange='logs',type='fanout')message = ' '.join(sys.argv[1:]) or "info: Hello World!"channel.basic_publish(exchange='logs',routing_key='',body=message)print(" [x] Sent %r" % message)connection.close()
消费者
import pikaconnection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))channel = connection.channel()channel.exchange_declare(exchange='logs',type='fanout')result = channel.queue_declare(exclusive=True)queue_name = result.method.queuechannel.queue_bind(exchange='logs',queue=queue_name)print(' [*] Waiting for logs. To exit press CTRL+C')def callback(ch, method, properties, body):print(" [x] %r" % body)channel.basic_consume(callback,queue=queue_name,no_ack=True)channel.start_consuming()
3.2 关键字发送

关键参数
exchange type = direct
之前事例,发送消息时明确指定某个队列并向其中发送消息,RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。
import pikaimport sysconnection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))channel = connection.channel()channel.exchange_declare(exchange='direct_logs',type='direct')result = channel.queue_declare(exclusive=True)queue_name = result.method.queueseverities = sys.argv[1:]if not severities:sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0])sys.exit(1)for severity in severities:channel.queue_bind(exchange='direct_logs',queue=queue_name,routing_key=severity)print(' [*] Waiting for logs. To exit press CTRL+C')def callback(ch, method, properties, body):print(" [x] %r:%r" % (method.routing_key, body))channel.basic_consume(callback,queue=queue_name,no_ack=True)channel.start_consuming()
3.3 模糊匹配

关键参数
exchange type = topic发送者路由值 队列中old.boy.python old.* -- 不匹配old.boy.python old.# -- 匹配
在topic类型下,可以让队列绑定几个模糊的关键字,之后发送者将数据发送到exchange,exchange将传入”路由值“和 ”关键字“进行匹配,匹配成功,则将数据发送到指定队列。
示例:
import pikaimport sysconnection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))channel = connection.channel()channel.exchange_declare(exchange='topic_logs',type='topic')result = channel.queue_declare(exclusive=True)queue_name = result.method.queuebinding_keys = sys.argv[1:]if not binding_keys:sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0])sys.exit(1)for binding_key in binding_keys:channel.queue_bind(exchange='topic_logs',queue=queue_name,routing_key=binding_key)print(' [*] Waiting for logs. To exit press CTRL+C')def callback(ch, method, properties, body):print(" [x] %r:%r" % (method.routing_key, body))channel.basic_consume(callback,queue=queue_name,no_ack=True)channel.start_consuming()
由于时间关系,详细过程略…
本文参考链接:
https://www.cnblogs.com/yuanchenqi/articles/8507109.html
二、基于scrapy-redis实现分布式爬虫
Scrapy-Redis则是一个基于Redis的Scrapy分布式组件。它利用Redis对用于爬取的请求(Requests)进行存储和调度(Schedule),并对爬取产生的项目(items)存储以供后续处理使用。scrapy-redi重写了scrapy一些比较关键的代码,将scrapy变成一个可以在多个主机上同时运行的分布式爬虫。
单机玩法:

按照正常流程就是大家都会进行重复的采集;我们都知道进程之间内存中的数据不可共享的,那么你在开启多个Scrapy的时候,它们相互之间并不知道对方采集了些什么那些没有没采集。那就大家伙儿自己玩自己的了。完全没没有效率的提升啊!
怎么解决呢?
这就是我们Scrapy-Redis解决的问题了,不能协作不就是因为请求和去重这两个不能共享吗?
那我把这两个独立出来好了。
将Scrapy中的调度器组件独立放到大家都能访问的地方不就OK啦!加上scrapy,Redis的后流程图就应该变成这样了
分布式玩法: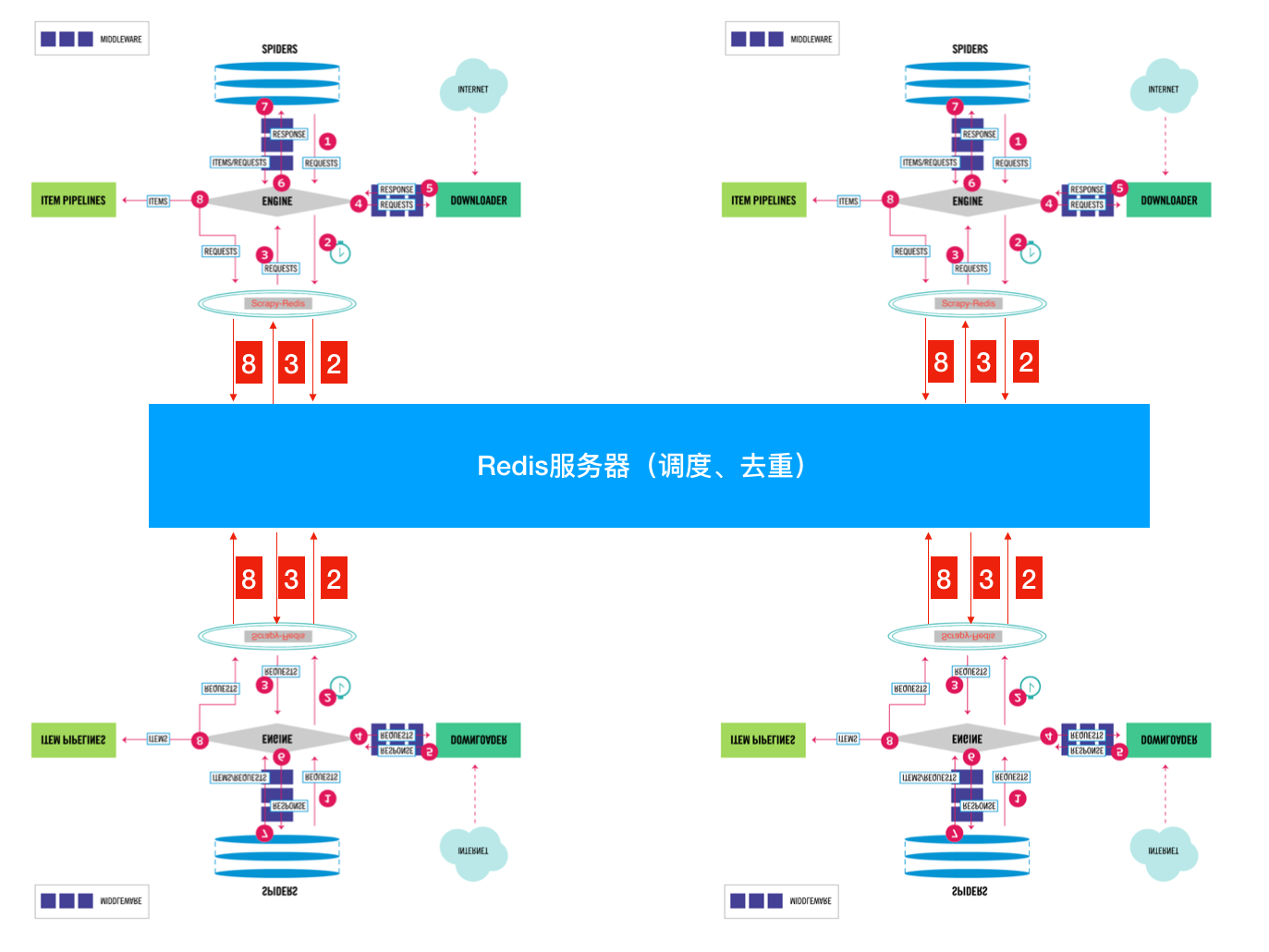
1. redis连接
配置scrapy使用redis提供的共享去重队列
# 在settings.py中配置链接RedisREDIS_HOST = 'localhost' # 主机名REDIS_PORT = 6379 # 端口REDIS_URL = 'redis://user:pass@hostname:9001' # 连接URL(优先于以上配置)REDIS_PARAMS = {} # Redis连接参数REDIS_PARAMS['redis_cls'] = 'myproject.RedisClient' # 指定连接Redis的Python模块REDIS_ENCODING = "utf-8" # redis编码类型# 默认配置:\python3.6\Lib\site-packages\scrapy_redis\defaults.py
2. dupefilter
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"#使用scrapy-redis提供的去重功能,查看源码会发现是基于Redis的集合实现的# 需要指定Redis中集合的key名,key=存放不重复Request字符串的集合DUPEFILTER_KEY = 'dupefilter:%(timestamp)s'#源码:dupefilter.py内一行代码key = defaults.DUPEFILTER_KEY % {'timestamp': int(time.time())}
3. Scheduler
#1、源码:\python3.6\Lib\site-packages\scrapy_redis\scheduler.py#2、settings.py配置# Enables scheduling storing requests queue in redis.SCHEDULER = "scrapy_redis.scheduler.Scheduler"# 调度器将不重复的任务用pickle序列化后放入共享任务队列,默认使用优先级队列(默认),其他:PriorityQueue(有序集合),FifoQueue(列表)、LifoQueue(列表)SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'# 对保存到redis中的request对象进行序列化,默认使用pickleSCHEDULER_SERIALIZER = "scrapy_redis.picklecompat"# 调度器中请求任务序列化后存放在redis中的keySCHEDULER_QUEUE_KEY = '%(spider)s:requests'# 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空SCHEDULER_PERSIST = True# 是否在开始之前清空 调度器和去重记录,True=清空,False=不清空SCHEDULER_FLUSH_ON_START = False# 去调度器中获取数据时,如果为空,最多等待时间(最后没数据,未获取到)。如果没有则立刻返回会造成空循环次数过多,cpu占用率飙升SCHEDULER_IDLE_BEFORE_CLOSE = 10# 去重规则,在redis中保存时对应的keySCHEDULER_DUPEFILTER_KEY = '%(spider)s:dupefilter'# 去重规则对应处理的类,将任务request_fingerprint(request)得到的字符串放入去重队列SCHEDULER_DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'
4. RedisPipeline(持久化)
ITEM_PIPELINES = { 'scrapy_redis.pipelines.RedisPipeline': 300, }#将item持久化到redis时,指定key和序列化函数REDIS_ITEMS_KEY = '%(spider)s:items'REDIS_ITEMS_SERIALIZER = 'json.dumps'
5. 从Redis中获取起始URL
scrapy程序爬取目标站点,一旦爬取完毕后就结束了,如果目标站点更新内容了,我们想重新爬取,那么只能再重新启动scrapy,非常麻烦scrapy-redis提供了一种供,让scrapy从redis中获取起始url,如果没有scrapy则过一段时间再来取而不会关闭这样我们就只需要写一个简单的脚本程序,定期往redis队列里放入一个起始url。#具体配置如下#1、编写爬虫时,起始URL从redis的Key中获取REDIS_START_URLS_KEY = '%(name)s:start_urls'#2、获取起始URL时,去集合中获取还是去列表中获取?True,集合;False,列表REDIS_START_URLS_AS_SET = False # 获取起始URL时,如果为True,则使用self.server.spop;如果为False,则使用self.server.lpop
由于时间关系,详细过程略…
本文参考链接:
https://www.cnblogs.com/yuanchenqi/articles/9509793.html#_label7
未完待续…
若有收获,就点个赞吧
0 人点赞
