一、昨日作业讲解
先来回顾一下昨日的内容
1.os模块和操作系统交互工作目录 文件夹 文件 操作系统命令 路径相关的2.模块最本质的区别 import会创建一个专属于模块的名字,所有导入模块中的都会在这个空间中importfrom importas 起别名* 和 __all__
作业讲解:
os.listdir() 返回一个列表,里面的每一个元素都是相对路径
值就是文件,或者文件夹
使用递归的方式实现
import osdef get_size(dir):sum_size = 0 # 初始大小for item in os.listdir(dir): # 返回一个列表,里面的每一个元素都是相对路径path = os.path.join(dir,item) # 由于item是相对路径的文件或者文件夹,需要join拼出绝对路径if os.path.isfile(path): # 判断绝对路径是否为文件sum_size += os.path.getsize(path) # 计算文件大小else:sum_size += get_size(path) # 调用自身函数。加上文件夹的大小,固定为4096,空的也是那么大。return sum_sizeret = get_size('E:\python_script\day26') # 传入一个目录print(ret)
执行输出:
4950326
栈(先进先出)
使用栈的思想完成上面的代码:
import osdef get_size(path):l = [path] # 文件夹列表sum_size = 0 # 初始文件大小while l: # 判断列表是否为空path = l.pop() # 删除列表最后一个元素,并返回给path l = ['E:\python_script\day26']for item in os.listdir(path): #遍历列表,path = 'E:\python_script\day26'path2 = os.path.join(path, item) # 组合绝对路径 path2 = 'E:\python_script\day26\test'if os.path.isfile(path2): # 判断绝对路径是否为文件sum_size += os.path.getsize(path2) # 计算文件大小。sum = 文件的大小 + 0else:l.append(path2) # 为文件夹时,添加到列表中。再次循环。l = ['E:\python_script\day26\test']return sum_sizeprint(get_size('E:\python_script\day26'))
执行输出:
4951192
和上面的结果有微小的差异,是因为,当前 py 文件,增加了几行代码。
查看文件夹属性
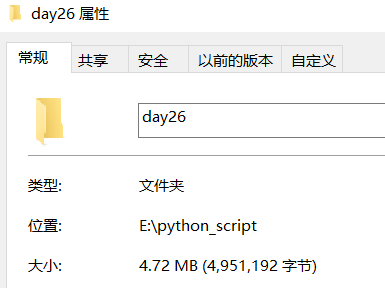
大小是一致的,有些 windows 系统,可能有微小的差异。
栈也可以解决深度问题,比如文件夹里面的所有文件统计
l 就是一个栈
栈也可以完成递归的功能。
递归比较占用空间,每调用一次,产生一个新的空间
但是栈不会每次产生新的空间,非常节省空间
栈可以解决不确定深度问题
栈的精髓就是先进后出
第二题
思考:假如有两个模块a,b。我可不可以在a模块中import b ,再在b模块中import a?
新建文件 demo1.py,内容如下:
import my_moduleprint('demo1')
新建文件 my_module.py,内容如下:
import demo1print('my_module')
执行 demo1.py,结果如下:
demo1
my_module
demo1
分析:
第一步执行 demo1.py 中的 import my_module
第二步执行 my_module.py 中的 import demo1
第三步执行 demo1.py 中的 import my_module,发现 mysql_modulel 已经被导入了,那么不会再次导入!
第四步执行 demo1.py 中的 print(‘demo1’),为什么呢?因为从上至下代码执行原则
第五步执行 my_module.py 中的 print(‘my_module’),为什么呢?因为从上至下原则
引用有一个模块,是为了引用方法
修改 demo1.py,增加一个函数
import my_moduledef func():print('ret')my_module.func2() # 执行函数
修改 my_module.py,增加一个函数
import demo1def func2():print('in func2')demo1.func1()
执行 demo1.py,输出报错:
AttributeError: module ‘my_module’ has no attribute ‘func2’
为什么呢?
看我上面写的步骤分析,执行第 4 步时,由于 my_module.py 中的 func2 还没有加载到内容
执行第 5 步时,调用 my_module 中的 func2 函数,就会直接报错,提示找不到函数
结论:
代码不会发现循环引用问题
模块中的引用不能成环
看下面一张图
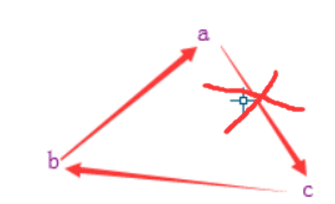
b 引用 a,c 引用 b。但是 a 不能引用 c,否则就是一个环。反反复复,无法终止。
2 个模块之间引用,那么就产生高层模块和底层模块
根据依赖倒置原则,高层模块不应该依赖底层模块
否则就违反了开发原则。
二、模块搜索路径
导入一个模块,就会从 sys.path 里面的路径中寻找
程序运行时,会将当前路径加入到搜索路径中
目前是 demo1.py 和 my_module.py 在同一个文件夹中
将 my_module.py 文件移动到上一层目录中
import sysprint(sys.path)<br>import my_module # 执行报错
执行就会报错,因为 sys.path 提供的搜索路径中,找不到 my_module.py 文件
如果手动添加一个呢?
import sysprint(sys.path)sys.path.append('E:\python_script\day26') # 添加搜索路径import my_module
再次执行,就不会报错了。
能不能导入一个模块,不是靠 Pycharm 画红线决定的
而是 sys.path 决定的。
总结:
引入的模块必须满足两个条件
1.模块名必须满足变量名的规范
2.被导入的模块所在的位置必须在 sys.path 所在的搜索路径中
模块
py 文件是一个模块
脚本
py 文件也是一个模块
如果一个 py 文件被导入了 他就是一个模块
如果这个 py 文件被直接执行 这个被直接执行的文件就是一个脚本
模块
没有具体的调用过程
但是能对外提供功能
比如三次登录程序
创建文件 login.py,内容如下:
def log_in():user = input('>>>')pwd = input('>>>')print('三次登录')
创建文件 test.py,内容如下:
import loginlogin.log_in() # 执行登录
执行文件 test.py,效果如下:
111
222
三次登录
现在有一个需求:
当 login 模块被当做脚本执行的时候,能够独立完成登陆功能
当 login 模块被当做模块导入的时候,需要等待调用才能完成功能
修改 login.py
def log_in():# user = input()# pwd = input()print('三次登陆')print(__name__)
修改 test.py
import loginlogin.log_in()print(__name__)
执行 test.py,输出:
login
三次登陆
main
说明由 test.py 调用 login.py 时,输出 login,也就是模块名
如果 login.py 想直接执行 log_in 方法,但是不想被导入时,自动执行。可以做一个 if 判断
def log_in():# user = input()# pwd = input()print('三次登陆')if __name__ == '__main__':log_in()
执行输出:三次登陆
修改 test.py,只包含一行
import login
执行 test.py,输出为空
if name == ‘main‘: 这句话,永远不会变,它是为了区分脚本和模块
所有的 print 不应该出现在模块里面,而是出现在 if 下面的代码中
结论:
当一个模块被当做脚本执行的时候,name是一个字符串数据类型的’main‘
当一个模块被当做模块导入的时候,name是一个字符串数据类型模块名
三、编译 python 文件
执行导入操作时,会自动创建目录pycache
查看里面的文件

那么这些文件是谁创建的呢?
python 解释器创建的
当一个文件被当做模块导入的时候,
如果 pyc 文件不存,python 解释器就会创建,存在不会再次被创建
pyc 文件 编译文件
python —> 字节码 —>机器码
编译过程
从上到下 编译 成字节码 pyc
从上倒下 解释 执行代码
为什么要编译
1.一个文件如果作为模块 一定会经常被导入
2.每次被导入都要经历一个被编译的过程
3.包.编译耗费时间
4.所以模块在被第一次导入的时候被编译存在 pyc 文件里
5.之后的导入可以直接呐 pyc 文件中的字节码,就可以直接执行了
主要功能:
编译文件 在模块导入的一瞬间 能够提高代码的执行速度
不能提高程序在具体执行的时候的效率
程序第一次执行,可能会慢一点,因为有一个编译过程
补充:dir()函数
内建函数 dir 是用来查找模块中定义的名字,返回一个有序字符串列表
import my_moduledir(my_module)
如果没有参数,dir()列举出当前定义的名字
dir()不会列举出内建函数或者变量的名字,它们都被定义到了标准模块 builtin 中,可以列举出它们,
import builtinsdir(builtins)
四、包以及包的 import 和 from
包是一种通过使用’.模块名’ 来组织 python 模块名称空间的方式。
1. 无论是import形式还是from…import形式,凡是在导入语句中(而不是在使用时)遇到带点的,都要第一时间提高警觉:这是关于包才有的导入语法
2. 包是目录级的(文件夹级),文件夹是用 py 文件来组成(包的本质就是一个包含init.py 文件的目录)
3. import 导入文件时,产生名称空间中的名字来源于文件,import 包,产生的名称空间的名字同样来源于文件,即包下的init.py,导入包本质就是在导入该文件
强调:
1. 在 python3 中,即使包下没有init.py 文件,import 包仍然不会报错,而在 python2 中,包下一定要有该文件,否则 import 包报错
2. 创建包的目的不是为了运行,而是被导入使用,记住,包只是模块的一种形式而已,包即模块
使用 Pycharm 创建一个包,会自动创建init.py 文件
所谓的包,就是一个包含init.py 文件的文件夹
包 A 和包 B 下有同名模块也不会冲突,如 A.a 与 B.a 来自俩个命名空间
模块是对外提供功能的
如果我写的模块足够强大,能提供的功能足够多
多到一个文件写不
把对外提供的功能,根据提供的内容不同,分成几个文件
把这些文件放在一个文件夹下,就形成了包
比如 django 框架
是所有框架中,功能最全的
功能:
1.操作数据库的模块
2.和 web 页面交互的模块
3.登录认证的模块
4.安全的中间件 模块,比如 web 攻击
django 将所有的模块集合成一个包
自动创建目录结构
import osos.makedirs('glance/api')os.makedirs('glance/cmd')os.makedirs('glance/db')l = []l.append(open('glance/__init__.py','w'))l.append(open('glance/api/__init__.py','w'))l.append(open('glance/api/policy.py','w'))l.append(open('glance/api/versions.py','w'))l.append(open('glance/cmd/__init__.py','w'))l.append(open('glance/cmd/manage.py','w'))l.append(open('glance/db/models.py','w'))map(lambda f:f.close() ,l)
执行代码,查看目录结构
文件内容如下:
#policy.pydef get():print('from policy.py')#versions.pydef create_resource(conf):print('from version.py: ',conf)#manage.pydef main():print('from manage.py')#models.pydef register_models(engine):print('from models.py: ',engine)
手动将内容复制到对应的 py 文件中去
这里面的每一个文件夹,都是包
包里面的每一个 py 文件,都是模块
新建一个文件 new.py
目录结构如下:
./├── glance│ ├── api│ │ ├── __init__.py│ │ ├── policy.py│ │ └── versions.py│ ├── cmd│ │ ├── __init__.py│ │ └── manage.py│ ├── db│ │ └── models.py│ └── __init__.py└── new.py
new.py 想用 glance 目录下的 api 文件夹下的 policy 模块
修改 new.py
from glance.api import policypolicy.get()
执行输出:
from policy.py
注意事项
1.关于包相关的导入语句也分为 import 和 from … import …两种,但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则:凡是在导入时带点的,点的左边都必须是一个包,否则非法。可以带有一连串的点,如 item.subitem.subsubitem,但都必须遵循这个原则。
2.对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。
3.对比 import item 和 from item import name 的应用场景:
如果我们想直接使用 name 那必须使用后者。
也可以用这种写法:
import glance.api.policyglance.api.policy.get()
执行输出:
from policy.py
对于点没有约束,对比 2 种方式,使用 from 方式,就比较简单了。
from … import …
需要注意的是 from 后 import 导入的模块,必须是明确的一个不能带点,否则会有语法错误,如:from a import b.c 是错误语法这样就报错了
from glance import api.policypolicy.get()
下面的方式,也是不对的
import glanceglance.api.policy.get()
症结就是导入一个包,并没有把包里面的所有内容,导入进来
导入一个包,相当于执行了这个包下面的init.py 文件
修改 glance 下面的init.py 文件
import api
手动执行init.py 文件,没有报错
修改 new.py
import glanceglance.api.policy.get()
执行 new.py,提示报错
ImportError: No module named ‘api’
为什么?
因为 sys.path,路径中找不到 api。init.py 执行时,在它的工作目录中可以找到 api
但是 new.py 所在的工作目录,无法直接找到 api 目录,所以就报错了
绝对导入和相对导入
我们的最顶级包 glance 是写给别人用的,然后在 glance 包内部也会有彼此之间互相导入的需求,这时候就有绝对导入和相对导入两种方式:
绝对导入:以 glance 作为起始
相对导入:用.或者..的方式最为起始(只能在一个包中使用,不能用于不同目录内)
修改 glance 目录下的init.py 文件
from glance import api
修改 api 目录下的init.py
from glance.api import policy
再次执行 new.py,输出:
from policy.py
为什么呢?因为首先执行了 glance 目录下的init.py 文件,再执行了 api 目录下的init.py
所以就能找到 policy 模块
所有导入,都是以 glance 为基础
这就是绝对路径导入
这个时候,新建一个文件 new_pac
将 glance 目录剪切到 new_pac
当前目录结构如下:
./├── new_pac│ └── glance│ ├── api│ │ ├── __init__.py│ │ ├── policy.py│ │ ├── __pycache__│ │ │ ├── __init__.cpython-35.pyc│ │ │ └── policy.cpython-35.pyc│ │ └── versions.py│ ├── cmd│ │ ├── __init__.py│ │ └── manage.py│ ├── db│ │ └── models.py│ ├── __init__.py│ └── __pycache__│ └── __init__.cpython-35.pyc└── new.py
如果 new.py 想调用 new_pac 目录下 glance 文件夹下面的内容呢?
修改 new.py 文件
from new_pac import glanceglance.api.policy.get()
执行报错:
ImportError: No module named ‘glance’
为什么?因为 glance 下的所有init.py 路径不对,都得改
修改 glance 目录下的init.py
from new_pac.glance import api
修改 api 目录下的init.py
from new_pac.glance.api import policy
再次执行 new.py,输出
from policy.py
但是这样太麻烦了,有缺点
一旦上级目录发生变化,那么所有的 init_py,都得修改
总结:
绝对路径
被直接执行的文件与包的关系必须是固定的,
一旦发生改变,包内的所有关系都要重新指定
跨包引用的问题,无法解决
如果 policy 想要执行 manage 呢?
修改 policy.py,内容如下:
from new_pac.glance.cmd import managedef get():print('from policy.py')manage.main()
执行报错:
ImportError: No module named ‘new_pac’
不能单独执行 policy.py
它取决于 sys.path
不改变 new.py 内容,执行 new.py,输出:
from manage.py
from policy.py
结果正常。
特别需要注意的是:可以用 import 导入内置或者第三方模块(已经在 sys.path 中),但是要绝对避免使用 import 来导入自定义包的子模块(没有在 sys.path 中),应该使用 from… import …的绝对或者相对导入,且包的相对导入只能用 from 的形式。
相对导入
用.或者..的方式最为起始(只能在一个包中使用,不能用于不同目录内)
好处就是,比方是你电脑开发的。换了另外一台电脑,也依然可以正常运行,不需要修改文件路径。
再次执行创建文件的脚本
import osos.makedirs('glance/api')os.makedirs('glance/cmd')os.makedirs('glance/db')l = []l.append(open('glance/__init__.py','w'))l.append(open('glance/api/__init__.py','w'))l.append(open('glance/api/policy.py','w'))l.append(open('glance/api/versions.py','w'))l.append(open('glance/cmd/__init__.py','w'))l.append(open('glance/cmd/manage.py','w'))l.append(open('glance/db/models.py','w'))map(lambda f:f.close() ,l)
再次补充文件内容
#policy.pydef get():print('from policy.py')#versions.pydef create_resource(conf):print('from version.py: ',conf)#manage.pydef main():print('from manage.py')#models.pydef register_models(engine):print('from models.py: ',engine)
新建文件 new2.py
目录结构如下:
./├── glance│ ├── api│ │ ├── __init__.py│ │ ├── policy.py│ │ └── versions.py│ ├── cmd│ │ ├── __init__.py│ │ └── manage.py│ ├── db│ │ └── models.py│ └── __init__.py└── new2.py
修改 glance 下的init.py,内容如下:
from . import api
点表示当前路径
api 目录的init.py,内容如下:
from . import policy
修改 new2.py,内容如下:
import glanceglance.api.policy.get()
执行 new2.py,输出:
from policy.py
新建目录 new_pac2,将目录 glance 剪切到 new_pac2 下面
目录结构如下:
./├── new2.py└── new_pac2└── glance├── api│ ├── __init__.py│ ├── policy.py│ └── versions.py├── cmd│ ├── __init__.py│ └── manage.py├── db│ └── models.py└── __init__.py
修改 new2.py,内容如下:
from new_pac2 import glanceglance.api.policy.get()
再次执行 new2.py,输出:
from policy.py
居然没有报错,666 啊!
修改 policy.py,导入 versions 模块
from . import versionsdef get():print('from policy.py')versions.create_resource('userinfo')
执行 new2.py,输出:
from version.py: userinfo
from policy.py
手动执行 policy.py,输出:
ImportError: attempted relative import with no known parent package
它不能当成脚本执行
结论:
在一个 py 文件中使用了相对路径引入一个模块
那么这个文件就不能被当成脚本运行了
修改 policy.py,导入 manage 模块
from . import versionsfrom .. cmd import managedef get():print('from policy.py')versions.create_resource('userinfo')manage.main()
点点表示上一级目录
执行 new2.py,输出:
from version.py: userinfofrom manage.pyfrom policy.py
new2.py 只能关联到 glance 包
from glance.api import *
在讲模块时,我们已经讨论过了从一个模块内导入所有,此处我们研究从一个包导入所有。
此处是想从包 api 中导入所有,实际上该语句只会导入包 api 下init.py 文件中定义的名字,我们可以在这个文件中定义all_:
修改 policy.py
from . import versionsfrom ..cmd import manage__all__ = ['get']def get():print('from policy.py')versions.create_resource('userinfo')manage.main()
修改 api.py,内容如下:
from . import policy__all__ = ['policy']
修改 new2.py
from new_pac2.glance.api import *
执行输出:
from version.py: userinfo
from manage.py
总结:
包就是 py 模块的集合
自带init.py 文件
py2 包中必须有一个init.py 文件
py3 不存在也可以
能不能导入一个包:要看 sys.path 中的路径下有没有这个包
从包中导入模块: 把包与包之间的关系写清楚,精确到模块,就一定能导入
直接导入一个包,并不会导入包下的模块,而是执行这个包下的init.py 文件
如果对导入还有更高的要求
可以对包中的init.py 文件做定义
绝对路径导入的方式
相对路径导入的方式 使用相对路径导入的模块不能作为脚本执行
sys.path 是所有模块的核心
是导入的关键
记住下面的:
#导入具体的文件#1.使用fromfrom glance.api import policypolicy.get()##1.使用import加别名import glance.api.policy as policypolicy.get()
保你 2 年平安…
五、软件开发规范
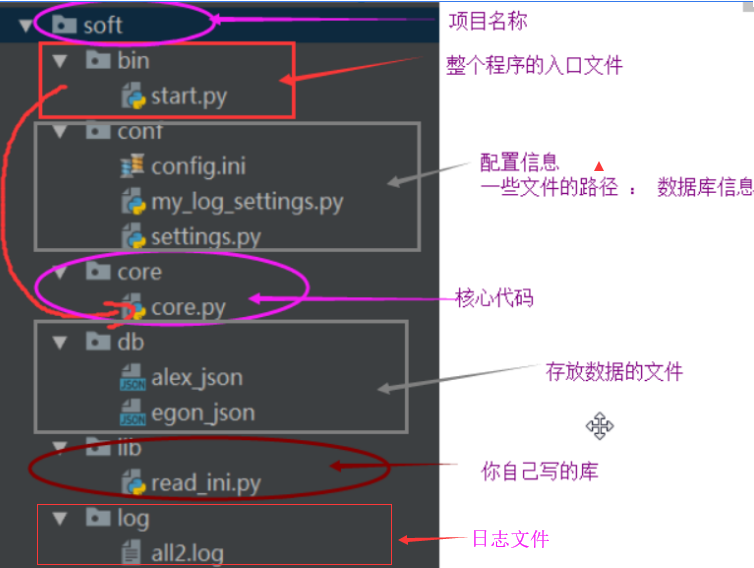
比如校园管理系统,目录结构如下:
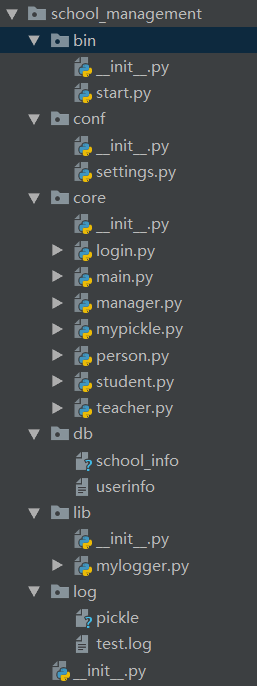
开始程序为 start.py
为什么要设计好目录结构?
“设计项目目录结构”,就和”代码编码风格”一样,属于个人风格问题。
设计一个层次清晰的目录结构,就是为了达到以下两点:
1.可读性高: 不熟悉这个项目的代码的人,一眼就能看懂目录结构,知道程序启动脚本是哪个,测试目录在哪儿,配置文件在哪儿等等。从而非常快速的了解这个项目。
2.可维护性高: 定义好组织规则后,维护者就能很明确地知道,新增的哪个文件和代码应该放在什么目录之下。这个好处是,随着时间的推移,代码/配置的规模增加,项目结构不会混乱,仍然能够组织良好。
所以,我认为,保持一个层次清晰的目录结构是有必要的。更何况组织一个良好的工程目录,其实是一件很简单的事儿。
关于 README 的内容
这个我觉得是每个项目都应该有的一个文件,目的是能简要描述该项目的信息,让读者快速了解这个项目。
它需要说明以下几个事项:
1.软件定位,软件的基本功能。
2.运行代码的方法: 安装环境、启动命令等。
3.简要的使用说明。
4.代码目录结构说明,更详细点可以说明软件的基本原理。
5.常见问题说明。
我觉得有以上几点是比较好的一个 README。在软件开发初期,由于开发过程中以上内容可能不明确或者发生变化,并不是一定要在一开始就将所有信息都补全。但是在项目完结的时候,是需要撰写这样的一个文档的。
可以参考 Redis 源码中 Readme 的写法,这里面简洁但是清晰的描述了 Redis 功能和源码结构。

若有收获,就点个赞吧
0 人点赞
