 |
|---|
| © getcodify.com |
由於語法渲染問題而影響閱讀體驗, 請移步博客閱讀~
本文GitPage地址
瓦雀.py
自己寫肯定是不可能的, 瓦雀那麼好用, 爲什麼要自己寫呢???
ummmm, 爲什麼我的代碼都變了???
本地明明是
except:Date= str(grep("b'Date:",lines)).replace("b'",'')From= Decode(str(grep("b'From:",lines)).replace("b'",''))To= Decode(str(grep("b'To:",lines)).replace("b'",''))Subject= Decode(str(grep("b'Subject:",lines)).replace("b'",''))print("",From,To,"\n",Subject,'\n\n',"this mail are purely composed by img or html",sep='\n')print('\n\n'+Date)
上傳以後,就翻車了。。 github和語雀問原作者,似乎一直沒有回 = =
except:Date= str(grep("b'Date:",lines)).replace("b'",'')From= Decode(str(grep("b'From:",lines)).replace("b'",''))To= Decode(str(grep("b'To:",lines)).replace("b'",''))Subject= Decode(str(grep("b'Subject:",lines)).replace("b'",''))print("",From,To,"\n",Subject,'\n\n',"this mail are purely composed by img or html",sep='\n')print('\n\n'+Date)
好吧, 那我還是自己寫一個把。 反正API都已經公開了。
而且語雀很多語法, 不支持。 正好可以, 個性化一些小東西。 避免一些bug和尷尬。
基礎
查看 repositories
import requestsUSER = ${你的repors前面那段名字}## 比如, 你的主頁是 https://www.yuque.com/xiaoming## 則, USER = ‘xiaoming’url = 'https://www.yuque.com/api/v2/users/' + USERheader = {"X-Auth-Token": "Your Token"}requests.get(url, headers = header).json()
{'data': {'id': 691897, 'type': 'User', 'space_id': 0, 'account_id': 494138, 'login': 'liuwenkan', 'name': 'Karroben',...
這裏可以獲得你自己的ID和一些主頁身份信息。 之後就可以用ID來做請求了。
url = 'https://www.yuque.com/api/v2/users/' + USER + "/repos"## or url = 'https://www.yuque.com/api/v2/users/' + ID + "/repos"Repo_Result = requests.get(url, headers = header).json()['data']
現在, 你可以查看Repo的信息了。 這裏包括了所有倉庫及其統計信息。 如果不想查看, 請直接忽略。
重要的是, 我們需要 倉庫 所對應的 ID
比如, 我需要blog倉庫的ID
for i in Repo_Result:if 'blog' == i['slug']:print(i['id'])
646554
有了ID, 就可以查看倉庫內的文章了。 同樣的, 我們更新文章,也需要獲得ID
發表一篇新文章
Doc_ID = '646554'url = 'https://www.yuque.com/api/v2/repos/'+Doc_ID+'/docs'data = {#'id': 我不想指定, 還是隨機吧'slug': 'test3' , # 這個還是最好要一個。 這個是網址'title': '又來測試了', # 這就不用多說了吧。'format': 'markdown', # 這必須markdown 呀'body': "# 這是第一個小標題<br>這是正文\n這個看看有效沒,換行符號",'status': "1" # 0 是草稿, 直接發佈把}BACK = requests.post(url, data= data, headers = header).json()['data']print(Doc_Result[0])
這就, 成功啦~!
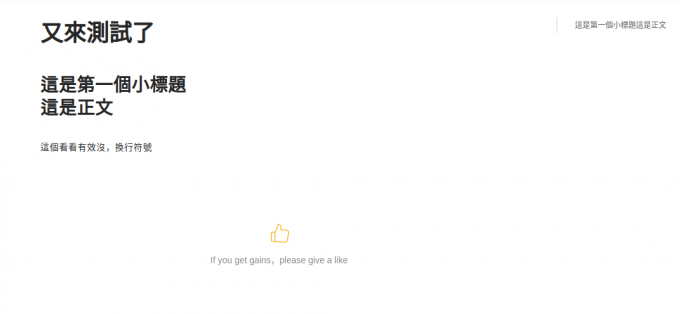
註: slug 必須是唯一的, 所以最好先檢查slug是否存在
def Slug_check(slug):try:requests.get(url+'/'+slug, headers = header).json()['status']print('slug is unique')return Trueexcept:print('Please check the slug. It may be occupied already.')return False
查看倉庫中的文章
Repos_ID = '646554'url = 'https://www.yuque.com/api/v2/repos/'+Repos_ID+'/docs'Doc_Result = requests.get(url, headers = header).json()['data']print(Doc_Result[0])
{'id': 32290390, 'slug': 'test3', 'title': '又來測試了', 'description': None, 'user_id': 691897, 'book_id': 646554, 'format': 'markdown', 'public': 1, 'status': 1, 'view_status': 0, 'read_status': 1, 'likes_count': 0, 'comments_count': 0, 'content_updated_at': '2021-03-03T14:33:25.000Z', 'created_at': '2021-03-03T14:33:25.000Z', 'updated_at': '2021-03-03T14:33:43.000Z', 'published_at': '2021-03-03T14:33:25.000Z', 'first_published_at': '2021-03-03T14:33:25.000Z', 'draft_version': 0, 'last_editor_id': 691897, 'word_count': 24, 'cover': None, 'custom_description': None, 'last_editor': {'id': 691897, 'type': 'User', 'login': 'liuwenkan', 'name': 'Karroben', 'description': '博客:https://karobben.github.io\n若不兼容情况, 请移步gitpage浏览(看地址)', 'avatar_url': 'https://cdn.nlark.com/yuque/0/2019/jpeg/anonymous/1576914522864-5dabd37e-9a90-4ee4-96b4-a1973dbcede4.jpeg', 'followers_count': 21, 'following_count': 2, 'created_at': '2019-12-21T07:49:03.000Z', 'updated_at': '2021-03-03T11:29:54.000Z', '_serializer': 'v2.user'}, 'book': None, '_serializer': 'v2.doc'}
可以看見, 第一篇文章, 是最新發的。 更新這篇文章把, 已知id是32290390
Doc_ID = '32290390'url = 'https://www.yuque.com/api/v2/repos/'+Repos_ID+'/docs/'+Doc_IDdata = {#'id': 我不想指定, 還是隨機吧'slug': 'test3' , # 這個還是最好要一個。 這個是網址'title': '標題也改一下把', # 這就不用多說了吧。'format': 'markdown', # 這必須markdown 呀'body': "# 這是第一個小標題\n\n這是正文\n換行符號.`來看看代碼框把'\n'`",'status': "1" # 0 是草稿, 直接發佈把}Doc_Result = requests.put(url, data = data, headers = header).json()['data']print(Doc_Result[0])

完美~
腳本化
配置文件準備
準備yuque.yml文件
repo: 'xiaoming/blog'
Markdown 標題格式
---title: ""url: ''date: ''---
爲了安全起見, 我選擇單獨把Token保存在一個文件裏面, 給路徑來讀取
echo $Token > ~/.yuqueToken
import yamlimport requestsimport osdef Yml_json(yml):f = open(yml, 'r')ystr = f.read()aa = yaml.load(ystr, Loader=yaml.FullLoader)return aadef ReporsID_get(Identity):url = 'https://www.yuque.com/api/v2/users/' + Identity['repo'].split('/')[0]+"/repos"header = {"X-Auth-Token": Identity['Token']}List = requests.get(url, headers = header).json()['data']for i in List:if Identity['repo'].split('/')[1] == i['slug']:Repos_ID = i['id']return Repos_IDdef DocList_get(Repos_ID):header = {"X-Auth-Token": Identity['Token']}url = 'https://www.yuque.com/api/v2/repos/'+str(Repos_ID)+'/docs'Doc_Result = requests.get(url, headers = header).json()['data']return Doc_Resultdef MDbody_clean(MD_body):MD_body = MD_body[MD_body.find('---',1)+3:]# 語雀不支持```text標籤MD_body = MD_body.replace("```text", '```text')MD_body = MD_body.replace("```", '```')# 添加封面圖片F = open(MD,'r').read()Data_header = yaml.load(F.split('---')[1], Loader=yaml.FullLoader)try:CP = Data_header['covercopy']except:CP = ""MD_body = "||\n" + "|:--:|\n" + "|"+CP+"|\n" + MD_body# 加個尾巴MD_body += '''---* Enjoy~本文由<span style='color:salmon'>Python腳本</span>[GitHub](https://karobben.github.io/2021/03/02/Python/yuqueAPI)/[語雀](https://www.yuque.com/liuwenkan/python/yuque_api)自動更新<span style='color:salmon'>由於語法渲染問題而影響閱讀體驗, 請移步博客閱讀~</span>GitHub: [Karobben](https://github.com/Karobben)Blog:[Karobben](https://karobben.github.io/)BiliBili:[史上最不正經的生物狗](https://space.bilibili.com/393056819)'''return MD_bodydef MDupDate(MD, Repos_ID, Doc_list):# read MD fileF = open(MD,'r').read()Data_header = yaml.load(F.split('---')[1], Loader=yaml.FullLoader)# find the ID by slug/urlfor i in Doc_list:if Data_header['url'] == i['slug']:data = {#'id': 我不想指定, 還是隨機吧'slug': i['slug'], # 這個還是最好要一個。 這個是網址'title': Data_header['title'], # 這就不用多說了吧。'format': 'markdown', # 這必須markdown 呀'body': MDbody_clean(F),'status': "1" # 0 是草稿, 直接發佈把}Doc_ID = i['id']header = {"X-Auth-Token": Identity['Token']}url = 'https://www.yuque.com/api/v2/repos/'+str(Repos_ID)+'/docs/'+ str(Doc_ID)Doc_Result = requests.put(url, data = data, headers = header).json()['data']print(MD,"is updated")Token = open('/home/ken/.yuqueToken','r').read().strip()Identity = Yml_json('yuque.yml')Identity.update({'Token':Token})Repos_ID = ReporsID_get(Identity)Doc_list = DocList_get(Repos_ID)for MD in os.listdir():if ".md" == MD[-3:]:print("updating for:", MD)try:MDupDate(MD, Repos_ID, Doc_list)except:print( '\033[91m' + "UPDAT FAILED!!!" + '\033[0m')
最後, 我麼把他寫成腳本吧
功能:
- 更新markdown文件
- 獨立語雀標題
- 填上icarus的封面圖
- 添加尾墜
- 添加Gitpage本文鏈接
- 修改語雀不支持的
```text標籤
不能: - 創建新文件(請使用瓦雀, 我怕太多太混亂了)
- 目錄編輯(瓦雀即可實現)
#!/usr/bin/env python3import argparseparser = argparse.ArgumentParser()parser.add_argument('-i','-I','--input',nargs='+') #输入文件parser.add_argument('-t','-T','--token') #输入文件parser.add_argument('-c','-C','--category', default= "summary.md") #输入文件args = parser.parse_args()INPUT = args.inputToken = args.tokenCategory = args.categoryimport threadingimport concurrent.futuresimport yamlimport requestsimport os, redef Yml_json(yml):f = open(yml, 'r')ystr = f.read()aa = yaml.load(ystr, Loader=yaml.FullLoader)return aadef ReporsID_get(Identity):url = 'https://www.yuque.com/api/v2/users/' + Identity['repo'].split('/')[0]+"/repos"header = {"X-Auth-Token": Identity['Token']}List = requests.get(url, headers = header).json()['data']for i in List:if Identity['repo'].split('/')[1] == i['slug']:Repos_ID = i['id']return Repos_IDdef DocList_get(Repos_ID):header = {"X-Auth-Token": Identity['Token']}url = 'https://www.yuque.com/api/v2/repos/'+str(Repos_ID)+'/docs'Doc_Result = requests.get(url, headers = header).json()['data']return Doc_Resultdef MDbody_clean(MD_body):MD_body = MD_body[MD_body.find('---',1)+3:]# 語雀不支持```text標籤try:AA = re.findall("```text]+>", MD_body)for PRE in AA:MD_body = MD_body.replace(PRE, '```text')except:PRE = "```text"print(PRE, "IAMHERE")print(MD_body)MD_body = MD_body.replace("```text", '```text')MD_body = MD_body.replace("```", '```')# 添加封面圖片F = open(MD,'r').read()Data_header = yaml.load(F.split('---')[1], Loader=yaml.FullLoader)try:CP = Data_header['covercopy']CP = "||\n" + "|:--:|\n" + "|"+CP+"|\n"except:CP = ""# 添加本文github鏈接try:git_url = "".join([ "\n<span style='color:salmon'>由於語法渲染問題而影響閱讀體驗, 請移步博客閱讀~</span>","\n[本文GitPage地址]","(https://karobben.github.io/",str(Data_header['date']).split(' ')[0].replace("-","/"), "/",os.getcwd().split("/")[-1],"/",MD[:-3],")\n"])except:git_url = ""# 合併前面的所有MD_body = CP+ git_url + MD_body# 加個尾巴MD_body += '''---**Enjoy~**本文由<span style='color:salmon'>Python腳本</span>[GitHub](https://karobben.github.io/2021/03/02/Python/yuqueAPI)/[語雀](https://www.yuque.com/liuwenkan/python/yuque_api)自動更新%%%GitHub: [Karobben](https://github.com/Karobben)Blog:[Karobben](https://karobben.github.io/)BiliBili:[史上最不正經的生物狗](https://space.bilibili.com/393056819)'''.replace("%%%",git_url)return MD_bodydef MDupDate(MD, Repos_ID, Doc_list):# read MD fileF = open(MD,'r').read()Data_header = yaml.load(F.split('---')[1], Loader=yaml.FullLoader)# find the ID by slug/urlif Data_header['url'] in [x['slug'] for x in Doc_list]:# 如果有單獨指定語雀標題:try:if Data_header['ytitle'] == "" :Title = Data_header['title']else:Title = Data_header['ytitle']except:Title = Data_header['title']data = {#'id': 我不想指定, 還是隨機吧'slug': Data_header['url'], # 這個還是最好要一個。 這個是網址'title': Title, # 這就不用多說了吧。'format': 'markdown', # 這必須markdown 呀'body': MDbody_clean(F),'status': "1" # 0 是草稿, 直接發佈把}Doc_ID = [x['id'] for x in Doc_list][[x['slug'] for x in Doc_list].index(Data_header['url'])]header = {"X-Auth-Token": Identity['Token']}url = 'https://www.yuque.com/api/v2/repos/'+str(Repos_ID)+'/docs/'+ str(Doc_ID)Doc_Result = requests.put(url, data = data, headers = header).json()['data']print(MD,"is updated")else:print(MD,' \033[91m', "這個文件還沒有被創建。我懶得寫一個新建接口了(防止太混亂)\n所以請覈對以後, 先上新建這個文件,再來更新把= =推薦用瓦雀直接創建", '\033[0m')def Categ(Category):try:List = open(Category,'r').read().replace(" ",'').split("](")Cate_list = [A.split(")")[0] for A in List][1:]return "導入成功", Cate_listexcept:return "導入失敗", []def run(MD):print("updating for:", MD)Cate_state , Cate_reuslt = Categ(Category)print("目錄:", Cate_state)try:Data_header = yaml.load(open(MD,'r').read().split('---')[1], Loader=yaml.FullLoader)if Data_header['url'] not in Cate_reuslt and Cate_state == "導入成功" :print(MD +' \033[91m', "該文檔未加入目錄", '\033[0m')MDupDate(MD, Repos_ID, Doc_list)except:print( MD + ' \033[91m' + "UPDAT FAILED!!!" + '\033[0m')# 線程等待Token = open(Token,'r').read().strip()# Token = open('/home/ken/.yuqueToken','r').read().strip()Identity = Yml_json('yuque.yml')Identity.update({'Token':Token})Repos_ID = ReporsID_get(Identity)Doc_list = DocList_get(Repos_ID)for MD in INPUT:run(MD)'''if __name__ == "__main__":with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:executor.map(run, INPUT)'''
Enjoy~
由於語法渲染問題而影響閱讀體驗, 請移步博客閱讀~
本文GitPage地址
GitHub: Karobben
Blog:Karobben
BiliBili:史上最不正經的生物狗

若有收获,就点个赞吧
0 人点赞
