以下部分将重点介绍常见的虚拟化任务,并解释Proxmox VE的具体配置对主机进行管理和管理。
Proxmox VE是基于Debian GNU/Linux的,有额外的存储库来提供相关的Proxmox VE包。这意味着所有Debian包都是可用的,包括安全更新和错误修正。Proxmox VE提供了它自己的基于Ubuntu内核的Linux内核。它有所有必要的东西启用了虚拟化和容器特性,并包括ZFS和几个额外的硬件驱动程序。
对于以下章节中未包含的其他主题,请参考Debian文档。debian管理员手册可以在网上找到,它提供了对Debian的全面介绍操作系统
3.1、包存储库
Proxmox VE使用APT)作为其包管理工具,就像其他基于debian的系统一样。存储库定义在/etc/apt/sources.list和/etc/apt/sources.d/中的*.list文件。
每一行都定义了一个包存储库。首选的来源必须首先出现。空行会被忽略。#行中任何位置的字符都将该行的其余部分标记为注释。可用的包来自存储库是通过运行apt-get update获得的。可以使用apt-get直接安装更新,
或者通过GUI。
/etc/apt/sources.list
deb http://ftp.debian.org/debian buster main contribdeb http://ftp.debian.org/debian buster-updates main contrib# security updatesdeb http://security.debian.org/debian-security buster/updates main contrib
Proxmox VE还提供了三种不同的包存储库。
3.1.1、PVE企业仓库
这是默认的、稳定的、推荐的存储库,所有Proxmox VE订阅用户都可以使用。它包含最稳定的包,适合生产使用。pve-enterprise存储库默认启用:
/etc/apt/sources.list.d/pve-enterprise.listdebhttps://enterprise.proxmox.com/debian/pvebuster pve-enterprise
通过电子邮件通知root@pam用户可用的更新。单击GUI中的Changelog按钮查看所选更新的更多细节。
您需要一个有效的订阅密钥来访问pve-enterprise存储库。不同的支持水平有可用。更多详情请访问https://www.proxmox.com/en/proxmox-ve/pricing。
Note:可以禁用此存储库,方法是使用#(在开头的位置注释掉上面的行线)。如果您没有订阅键,这将防止出现错误消息。请配置在这种情况下,pve-no-subscription存储库。
3.1.2、PVE No-Subscription 仓库
这是用于测试和非生产使用的推荐存储库。它的包裹没有那么重测试和验证。访问pve-no-subscription repository不需要订阅键保守党。
我们建议在/etc/apt/sources.list中配置这个存储库
/etc/apt/sources.list
deb http://ftp.debian.org/debian buster main contribdeb http://ftp.debian.org/debian buster-updates main contrib# PVE pve-no-subscription repository provided by proxmox.com,# NOT recommended for production usedeb http://download.proxmox.com/debian/pve buster pve-no-subscription# security updatesdeb http://security.debian.org/debian-security buster/updates main contrib
3.1.3、PVE test 仓库
该存储库包含最新的包,主要由开发人员用于测试新特性。来配置它,将下面一行添加到/etc/apt/sources.listdebhttp://download.proxmox.com/debian/pvebuster pvetest
警告:pvetest存储库应该(顾名思义)只用于测试新特性或错误修正。
3.1.4、Ceph Octopus 仓库
Note:Ceph Octopus(15.2)已被Proxmox VE 6.3声明为稳定版本,是最新的Ceph版本支持。在pve6.3的剩余生命周期中,它将继续获得更新为6.x版本[? informaltable]。
此存储库包含主要的Proxmox VE Ceph Octopus包。它们适合生产。使用如果在Proxmox VE上运行Ceph客户端或完整的Ceph集群,则使用此存储库。
/etc/apt/sources.list.d/ceph.list
**debhttp://download.proxmox.com/debian/ceph-octopusbuster main
3.1.5、Ceph Octopus Test 仓库
这个Ceph存储库包含Ceph包,在它们被移动到主存储库之前。使用它测试新的Ceph在Proxmox VE上的release。
/etc/apt/sources.list.d/ceph.list<br />debhttp://download.proxmox.com/debian/ceph-octopusbuster test
3.1.6、Ceph Nautilus 仓库
NoteCeph nautilus(14.2)是较老的受支持的Ceph版本,由Proxmox VE 6.0引入。将继续要更新到2021年第二季度末,所以你最终需要升级到Ceph Octopus(https://pve.proxmox.com/wiki/Ceph_Nautilus_to_Octopus)。
此存储库保存了主要的Proxmox VE Ceph Nautilus包。它们适合生产。如果在Proxmox VE上运行Ceph客户端或完整的Ceph集群,则使用此存储库。
/etc/apt/sources.list.d/ceph.list
debhttp://download.proxmox.com/debian/ceph-nautilusbuster main
3.1.7、Ceph Nautilus Test 仓库
这个Ceph存储库包含Ceph包,在它们被移动到主存储库之前。使用它测试新的Ceph在Proxmox VE上的release。
/etc/apt/sources.list.d/ceph.list**
debhttp://download.proxmox.com/debian/ceph-nautilusbuster test
3.1.8、PVE Ceph Luminous 库 升级
如果部署了Ceph,则需要从Proxmox VE 5.x升级此存储库到Proxmox VE 6.0。它提供针对proxyve 6.0版本的Ceph Luminous release版本的封装。升级5.x to 6.0文档详细解释了如何使用这个存储库
/etc/apt/sources.list.d/ceph.list
debhttp://download.proxmox.com/debian/ceph-luminousbuster main
3.1.9、SecureApt
存储库中的发布文件是用GnuPG签名的。APT正在使用这些签名来验证所有包来自可信的源。
如果通过官方ISO镜像安装Proxmox VE,则验证密钥已经安装。
如果在Debian上安装Proxmox VE,请使用以下命令下载并安装密钥:
# wgethttp://download.proxmox.com/debian/proxmox-ve-release-6.x.gpg-O \
/etc/apt/trusted.gpg.d/proxmox-ve-release-6.x.gpg
然后用以下方法验证校验和:
# sha512sum /etc/apt/trusted.gpg.d/proxmox-ve-release-6.x.gpg
输出应该是:
acca6f416917e8e11490a08a1e2842d500b3a5d9f322c6319db0927b2901c3eae23cfb5cd5df6facf2b57399d3cfa52ad7769ebdd75d9b204549ca147da52626 \/etc/apt/trusted.gpg.d/proxmox-ve-release-6.x.gpg
或
# md5sum /etc/apt/trusted.gpg.d/proxmox-ve-release-6.x.gpg
输出应该是:
f3f6c5a3a67baf38ad178e5ff1ee270c /etc/apt/trusted.gpg.d/proxmox-ve-release ←--6.x.gpg
3.2、系统软件更新
Proxmox定期为所有存储库提供更新。要安装更新,请使用基于web的GUI或使用以下CLI命令:
# apt-get update# apt-get dist-upgrade
Note:APT打包管理系统非常灵活,并提供了许多功能,参见man APT -get,或[Hertzog13]以获取更多信息。Tip:定期更新是获得最新补丁和安全相关补丁的必要条件。主要的系统升级在Proxmox VE社区论坛(https://forum.proxmox.com/)上公布。
3.3、网络配置
网络配置可以通过图形用户界面完成,也可以手动编辑/etc/network/interfaces文件,其中包含整个网络配置。“接口(5)手册”中包含完整系列格式描述。所有的Proxmox VE工具都努力保持用户的直接修改,但是使用GUI仍然更可取,因为它可以防止您犯错误。配置好网络之后,您可以使用Debian传统工具ifup和ifdown命令来启用关闭接口。
3.3.1、网络修改生效
Proxmox VE不会直接修改到/etc/network/interfaces中。我们把它写进临时文件/etc/network/interfaces.new中,这样你可以一次做很多相关的改变。这也允许在应用之前确保更改是正确的,因为网络配置是错误的可能导致节点无法访问。
重新启动节点以生效
使用默认安装的ifupdown网络管理包,您需要重新启动以提交任何挂起网络的变化。大多数时候,基本的Proxmox VE网络设置是稳定的,不会经常改变,所以不应该经常需要重新启动
用ifupdown2重新加载网络
通过可选的ifupdown2网络管理包,您还可以重新热加载网络配置,不需要重启。
Noteifupdown2无法理解OpenVSwitch语法,所以如果OVS接口是无法重新加载配置。
由于Proxmox VE 6.1,您可以使用apply在web接口上应用暂挂的网络更改节点网络面板中的“配置”按钮。
要安装ifupdown2,请确保安装了最新的Proxmox VE更新
警告安装ifupdown2将删除ifupdown,但作为ifupdown之前版本的删除脚本0.8.35+pve1有一个问题,在删除时网络完全停止一个你必须确保你有一个最新的ifupdown包版本
对于安装本身,你可以简单地做:
apt install ifupdown2
您也可以在任何时候切换回ifupdown变体,如果您遇到问题的话。
3.3.2、命名约定
我们目前对设备名称使用以下命名约定:
- 以太网设备:en*, systemd网络接口名称。这个命名方案用于新的PVE自5.0版本以来的安装。
- 以太网设备:eth[N],其中0≤N (eth0, eth1,…)此命名方案用于PVE5.0版本之前安装的主机。升级到5.0时,名称保持原样。
- 网桥:vmbr[N]0≤N≤4094(vmbr0-vmbr4094)
- Bonds:bond[N],其中0≤N (bond0,bond1,…)
- VLANs:只需将VLAN编号添加到设备名称中,以句点(eno1.50, bond1.30)分隔。这使得调试网络问题更容易,因为设备名称暗示了设备类型。
系统网络接口名称
**
Systemd对以太网网络设备使用两个字符的前缀en。下一个字符取决于设备驱动程序和哪个模式首先匹配的事实。
- o
[n |d ] -主板设备 - s
[f ][n |d ] -设备由热插拔id决定 - [P
]p s [f ][n |d ] -总线id设备 - x
-MAC地址设备
最常见的模式是:
- eno1 —— 第一个主板网卡
- enp3s0f1 —— 为pcibus 3 0号槽位的网卡,使用1号网卡功能。
有关更多信息,请参见可预测的网络接口名称。
3.3.3、选择一个网络配置
根据您当前的网络组织和资源,您可以选择桥接、路由、或者伪装网络设置
Proxmox VE服务器位于私有局域网内,通过外部网关与internet连接
**
桥接模型在这种情况下最有意义,而且这也是new Proxmox的默认模式已经安装。您的每个客户系统都将有一个附加到Proxmox VE桥接器的虚拟接口。这类似于将客户网卡直接连接到LAN上的新交换机Proxmox VE主机,扮演交换机的角色。
主机提供商的Proxmox VE服务器,为客户提供公共IP范围
**
对于这种设置,您可以使用桥接或路由模型,这取决于您的提供者允许什么。
Proxmox VE服务器在托管提供商,具有单一的公共IP地址
**
在这种情况下,为客户系统获得外出网络访问的唯一方法是使用伪装。对于进入的网络访问您的客人,您将需要配置端口转发。为了获得更大的灵活性,您可以配置vlan (IEEE 802.1q)和网络绑定(也称为“链路”)聚合”。这样就可以构建复杂而灵活的虚拟网络。
3.3.4、默认配置(网桥)
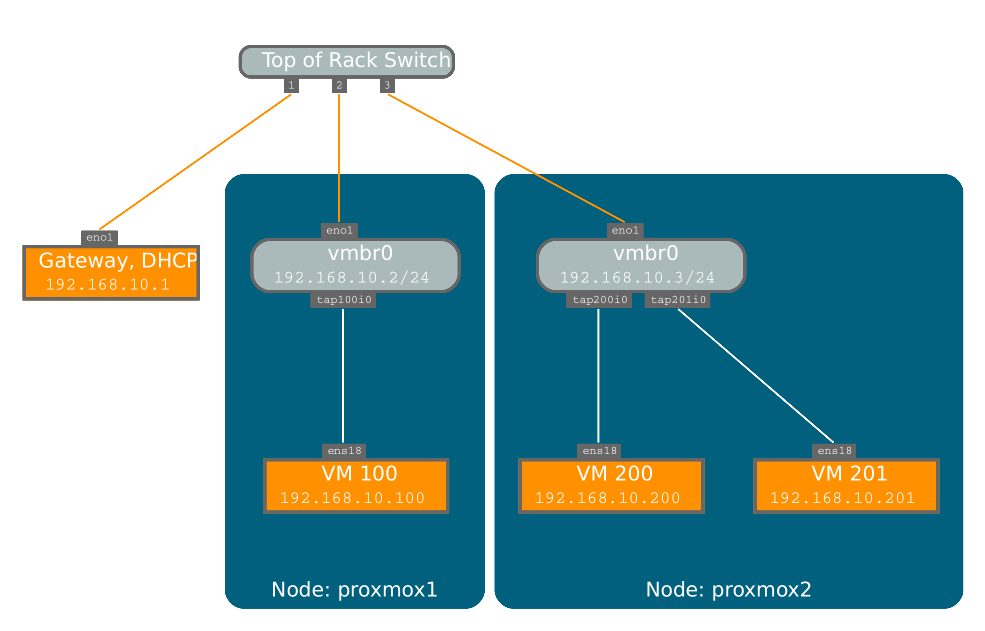
网桥就像在软件中实现的物理网络交换机。所有虚拟客人都可以共享一个端口桥接,或者您可以创建多个桥接来分隔网络域。每个主机最多可以有4094个桥梁。
安装程序创建一个名为vmbr0的网桥,它连接到第一个以太网卡。/etc/network/interfaces中相应的配置如下:
auto loiface lo inet loopbackiface eno1 inet manualauto vmbr0iface vmbr0 inet staticaddress 192.168.10.2netmask 255.255.255.0gateway 192.168.10.1bridge-ports eno1bridge-stp offbridge-fd 0
虚拟机的行为就像它们直接连接到物理网络一样。网络,反过来,认为每个虚拟机都有自己的MAC,即使只有一条网线连接所有这些虚拟机到网络。
3.3.5、路由配置
大多数主机供应商不支持上述设置。出于安全原因,一旦他们在一个接口上检测到多个MAC地址,就禁用了网络。
tip一些供应商允许你通过他们的管理界面注册额外的mac。这就避免了这个问题,但是配置起来很笨拙,因为你需要为你的每个vm注册一个MAC。
您可以通过一个接口“路由”所有流量来避免这个问题。这就确保了所有的网络报文使用相同的MAC地址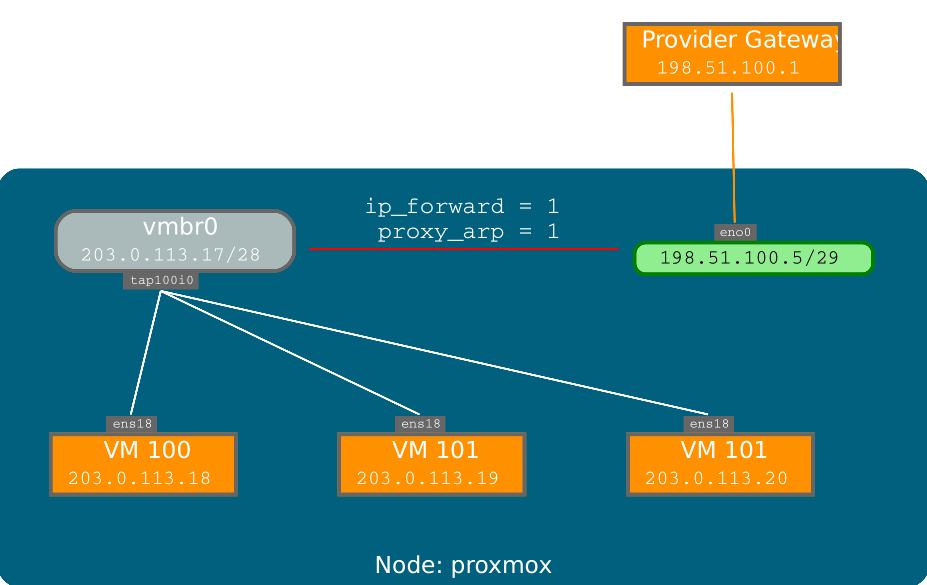
一个常见的场景是,您有一个公共IP(本例假设为198.51.100.5)和一个额外虚拟机的IP块(203.0.113.16/29)。对于这种情况,我们建议采用以下设置:
auto loiface lo inet loopbackauto eno1iface eno1 inet staticaddress 198.51.100.5netmask 255.255.255.0gateway 198.51.100.1post-up echo 1 > /proc/sys/net/ipv4/ip_forwardpost-up echo 1 > /proc/sys/net/ipv4/conf/eno1/proxy_arpauto vmbr0iface vmbr0 inet staticaddress 203.0.113.17netmask 255.255.255.248bridge-ports nonebridge-stp offbridge-fd 0
3.3.6、用iptables伪装(NAT)
伪装允许只有一个私有IP地址的来宾通过使用主机IP访问网络发送流量的地址。每个传出的数据包都被iptables重写,使其看起来像是来自它主机和响应被相应地重写,以路由到原始发送者。
auto loiface lo inet loopbackauto eno1#real IP addressiface eno1 inet staticaddress 198.51.100.5netmask 255.255.255.0gateway 198.51.100.1auto vmbr0#private sub networkiface vmbr0 inet staticaddress 10.10.10.1netmask 255.255.255.0bridge-ports nonebridge-stp offbridge-fd 0post-up echo 1 > /proc/sys/net/ipv4/ip_forwardpost-up iptables -t nat -A POSTROUTING -s ’10.10.10.0/24’ -o eno1 -j MASQUERADEpost-down iptables -t nat -D POSTROUTING -s ’10.10.10.0/24’ -o eno1 -j MASQUERADE
Note在一些启用了防火墙的伪装设置中,可能需要conntrack区域用于外出连接规划设计。否则,防火墙可能会阻止传出的连接,因为他们更喜欢发送虚拟机桥的(不包含假面舞会)。
在/etc/network/interfaces中添加这些行可以解决这个问题:
post-up iptables -t raw -I PREROUTING -i fwbr+ -j CT --zone 1post-down iptables -t raw -D PREROUTING -i fwbr+ -j CT --zone 1
有关这方面的更多信息,请参阅以下链接:
- Netfilter包流(https://commons.wikimedia.org/wiki/File:Netfilter-packet-flow.svg)
- netdev-list补丁引入了conntrack区域(https://lwn.net/Articles/370152/)
- 这篇博文很好地解释了在原始表中使用跟踪(https://blog.lobraun.de/2019/05/19/prox/)
3.3.7、Linux Bond
绑定(也称为NIC teaming或链路聚合)是一种将多个NIC绑定到单个网络设备的技术。它可以实现不同的目标,如使网络容错,增加性能或两者兼有。
像光纤通道这样的高速硬件和相关的交换硬件可能非常昂贵。通过当进行链路聚合时,两个网卡可以作为一个逻辑接口出现,导致速度加倍。这是一个大多数交换机支持的本地Linux内核特性。如果您的节点有多个以太网端口,您可以通过将网络电缆连接到不同的交换机和bonding设备来分配故障点,当网络出现故障时,连接将故障转移到一根或另一根电缆上。
聚合链接可以改善实时迁移延迟,并提高数据之间复制的速度Proxmox VE集群节点。
有7种bonding模式:
- Round-robin (balance-rr):从第一个可用网络按顺序传送网络包接口(网卡)从机通过最后一个。该模式提供负载均衡和容错功能。
- Active-backup (active-backup):bond中只有一个NIC slave处于激活状态。一个不同的奴隶主用当且仅当主用备机故障时。单个逻辑绑定接口的MAC地址在外部只在一个网卡(端口)上可见,避免网络交换机失真。该模式提供容错功能。
- XOR (balance-xor):发送基于[(源MAC地址与目的地址异或)的网络数据包MAC地址)modo NIC slave count]。这将为每个目标MAC选择相同的网卡从机地址。该模式提供负载均衡和容错功能。
- Broadcast (broadcast):在所有从网口上发送网络报文。这种模式提供了容错。
- IEEE 802.3ad Dynamic link aggregation (802.3ad)(LACP)创建共享相同的速度和双工设置。根据802.3ad规范,使用活动聚合器组中的所有从网络接口。
- Adaptive transmit load balancing (balance-tlb):Linux bonding驱动模式,不需要任何配置特殊的网络交换机的支持。流出的网络报文流量根据当前流量进行分配在每个网络接口slave上加载(相对于速度计算)。传入的流量由一个接收当前指定的从网络接口。如果这个接收slave失败,另一个slave接管MAC失败的接收slave的地址。
- Adaptive load balancing (balance-alb):包括balance-tlb和IPV4的rlb流量,不需要任何特殊的网络交换机支持。接收负载均衡由ARP谈判。bonding驱动程序会在ARP发送出去时拦截本地系统发送的ARP应答并覆盖源硬件地址与唯一的硬件地址的网卡奴隶之一单一的逻辑绑定接口,使不同的网络对等体使用不同的MAC地址网络包流量。
如果您的交换机支持LACP (IEEE 802.3ad)协议,那么我们建议使用相应的协议成键模式(802.3)。否则一般使用active-backup模式。如果打算在绑定接口上运行集群网络,则必须使用主动-被动模式bonding接口不支持其他模式。
以下bond配置适用于分布式/共享存储网络。好处是你会得到更快的速度,网络也会容错。
示例:选择“与固定IP地址绑定”
**
auto loiface lo inet loopbackiface eno1 inet manualiface eno2 inet manualiface eno3 inet manualauto bond0iface bond0 inet staticbond-slaves eno1 eno2address 192.168.1.2netmask 255.255.255.0bond-miimon 100bond-mode 802.3adbond-xmit-hash-policy layer2+3auto vmbr0iface vmbr0 inet staticaddress 10.10.10.2netmask 255.255.255.0gateway 10.10.10.1bridge-ports eno3bridge-stp offbridge-fd 0
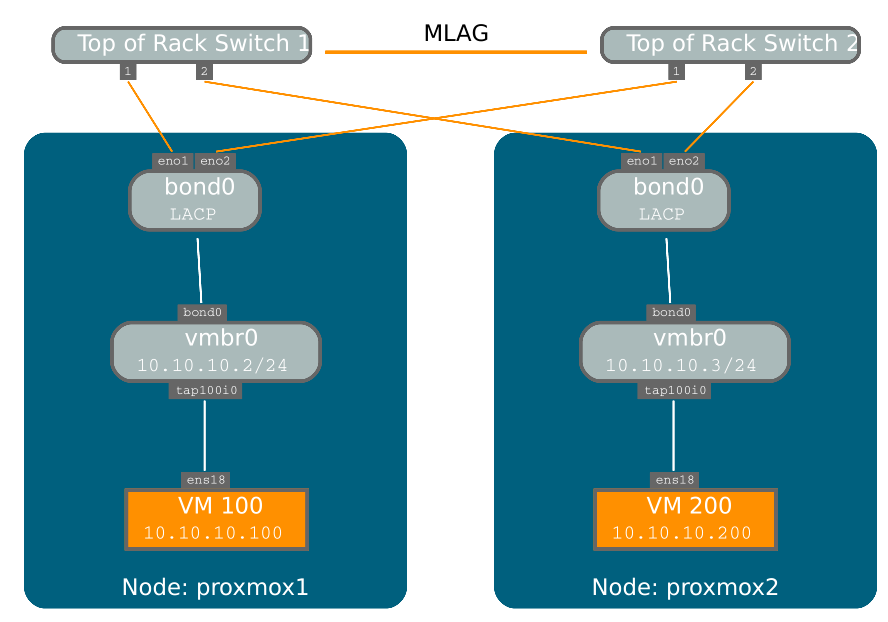
另一种可能是直接使用bond作为桥接端口。这可以用来制作客户网络容错。
示例:使用bond作为桥接端口
auto loiface lo inet loopbackiface eno1 inet manualiface eno2 inet manualauto bond0iface bond0 inet manualbond-slaves eno1 eno2bond-miimon 100bond-mode 802.3adbond-xmit-hash-policy layer2+3auto vmbr0iface vmbr0 inet staticaddress 10.10.10.2netmask 255.255.255.0gateway 10.10.10.1bridge-ports bond0bridge-stp offbridge-fd 0
3.3.8、VLAN 802.1Q
VLAN (virtual LAN)是一个广播域,它在网络的二层被划分和隔离。所以它在一个物理网络中可以有多个网络(4096),每个网络独立于其他网络。每个VLAN网络由一个通常称为标签的数字来标识。然后网络包被标记来识别
他们属于哪个虚拟网络。
客户网络的VLAN
**
Proxmox VE支持这种开箱即用的设置。VLAN标签可在创建虚拟机时指定。VLAN标记是客户网络配置的一部分。网络层支持不同的模式,根据桥的配置来实现vlan:
- Linux网桥上的VLAN感知功能:在这种情况下,每个客户的虚拟网卡都被分配给一个VLAN标签,它是由Linux bridge透明支持的。中继模式也是可能的,但是在客户端进行必要的配置。
- Linux bridge上的“传统”VLAN:与VLAN感知方法相比,这种方法不是透明并为每个VLAN创建一个带关联桥接器的VLAN设备。也就是说,创建一个guest on例如,VLAN 5将创建两个接口eno1.5和vmbr0v5,它们将一直保持到重新引导发生。
- Open vSwitch VLAN:该模式使用OVS VLAN特性。
- 客户机VLAN配置:在来宾系统中分配vlan。在这种情况下,设置是完全的在客人内部做,不能受到外界的影响。好处是你可以使用更多单个虚拟网卡不能包含一个VLAN。
主机VLAN
**
允许主机与隔离网络通信。可以将VLAN标签应用到任何网络设备(网卡、Bond、网桥)。一般情况下,在接口上配置的VLAN为最小值抽象层之间的本身和物理NIC。
例如,在默认配置中,您希望将主机管理地址单独放置在一个位置上VLAN。
示例:**使用VLAN 5配置**Proxmox VE的管理IP地址传统的Linux bridge配置
auto loiface lo inet loopbackiface eno1 inet manualiface eno1.5 inet manualauto vmbr0v5iface vmbr0v5 inet staticaddress 10.10.10.2netmask 255.255.255.0gateway 10.10.10.1bridge-ports eno1.5bridge-stp offbridge-fd 0auto vmbr0iface vmbr0 inet manualbridge-ports eno1bridge-stp offbridge-fd 0
示例:使用VLAN 5的Proxmox VE管理IP地址配置VLAN aware Linux bridge
auto loiface lo inet loopbackiface eno1 inet manualauto vmbr0.5iface vmbr0.5 inet staticaddress 10.10.10.2netmask 255.255.255.0gateway 10.10.10.1auto vmbr0iface vmbr0 inet manualbridge-ports eno1bridge-stp offbridge-fd 0bridge-vlan-aware yes
下一个示例是相同的设置,但是使用了一个bond来确保网络故障安全。
示例:Proxmox VE的管理IP地址使用VLAN 5和bond0作为传统Linux bridge的IP地址
auto loiface lo inet loopbackiface eno1 inet manualiface eno2 inet manualauto bond0iface bond0 inet manualbond-slaves eno1 eno2bond-miimon 100bond-mode 802.3adbond-xmit-hash-policy layer2+3iface bond0.5 inet manualauto vmbr0v5iface vmbr0v5 inet staticaddress 10.10.10.2netmask 255.255.255.0gateway 10.10.10.1bridge-ports bond0.5bridge-stp offbridge-fd 0auto vmbr0iface vmbr0 inet manualbridge-ports bond0bridge-stp offbridge-fd 0
3.4、时间同步
Proxmox VE集群堆栈本身严重依赖于所有节点都已精确同步这一事实时间。其他一些组件,如Ceph,如果节点上的本地时间不在,也会拒绝正常工作同步。通过“网络时间协议”NTP (Network Time Protocol)可以实现节点间的时间同步。Proxmox已经默认使用systemd-timesyncd作为NTP客户端,预先配置为使用一组公共服务器。这在大多数情况下,安装工作是开箱即用的。
3.4.1、使用自定义NTP服务器
在某些情况下,可能希望不使用默认的NTP服务器。例如,如果您的Proxmox VE节点不能访问公共internet(例如,由于限制性的防火墙规则),您需要进行设置本地NTP服务器,并告诉systemd-timesyncd使用它们:
/etc/systemd/timesyncd.conf[Time]NTP=ntp1.example.com ntp2.example.com ntp3.example.com ntp4.example.com
重新启动同步服务(systemctl restart systemd-timesyncd)后,您应该这样做通过检查日志,验证新配置的NTP服务器是否被使用 ( journalctl --since -1h -u systemd-timesyncd ):
...Oct 07 14:58:36 node1 systemd[1]: Stopping Network Time Synchronization...Oct 07 14:58:36 node1 systemd[1]: Starting Network Time Synchronization...Oct 07 14:58:36 node1 systemd[1]: Started Network Time Synchronization.Oct 07 14:58:36 node1 systemd-timesyncd[13514]: Using NTP server ←-10.0.0.1:123 (ntp1.example.com).Oct 07 14:58:36 nora systemd-timesyncd[13514]: interval/delta/delay/jitter/ ←-drift 64s/-0.002s/0.020s/0.000s/-31ppm...
3.5、外部度量服务器
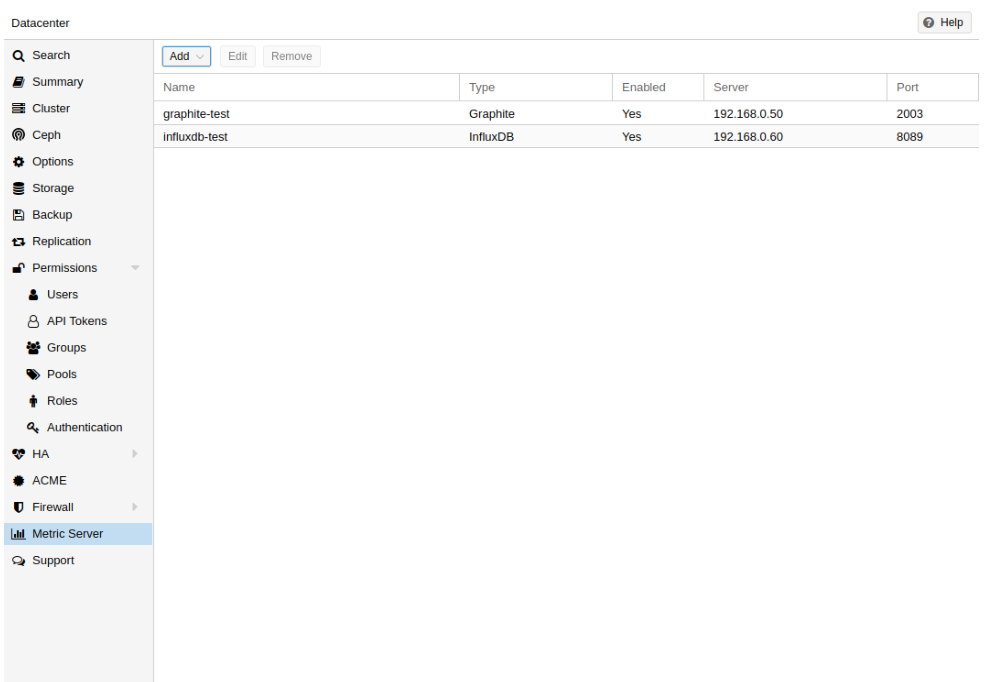
在Proxmox VE中,可以定义外部度量服务器,它将定期接收有关的各种统计信息您的主机、虚拟来宾和存储。
目前支持:
- Graphite (see http://graphiteapp.org )
- InfluxDB (see https://www.influxdata.com/time-series-platform/influxdb/ )
外部度量服务器定义保存在/etc/pve/status.cfg文件,可以通过web进行编辑接口
3.5.1、Graphite 服务器配置
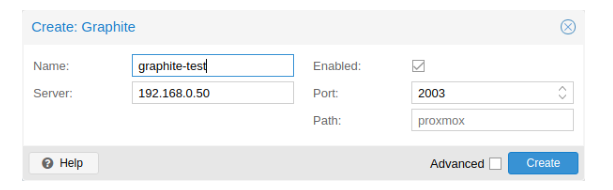
默认端口设置为2003,默认的graphite路径为proxmox。
默认情况下,Proxmox VE通过UDP发送数据,所以石墨服务器必须被配置为接受这一点。在这里,可以为不使用标准1500的环境配置最大传输单元(MTU)MTU。
你也可以配置插件来使用TCP。为了不阻塞重要的pvestatd统计信息守护进程,需要一个超时时间来处理网络问题。
3.5.2、Influxdb 插件配置
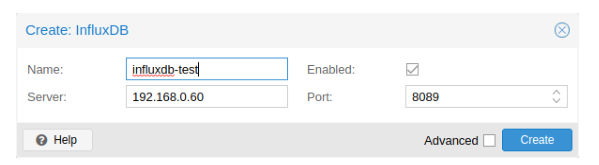
Proxmox VE通过UDP发送数据,因此必须为此配置流量数据库服务器。如果有必要,也可以在这里配置MTU。
下面是一个数据库配置示例(在您的数据库服务器上)
[[udp]]enabled = truebind-address = "0.0.0.0:8089"database = "proxmox"batch-size = 1000batch-timeout = "1s"
使用这种配置,您的服务器侦听端口8089上的所有IP地址,并将数据写入proxmox数据库
3.6、磁盘健康监测
尽管建议使用健壮的冗余存储,但它对监视的运行状况非常有帮助你的本地磁盘。
从Proxmox VE 4.3开始,软件包为smartmontools已安装且必需。这是一套工具监控和控制本地硬盘的s.m.a.r.t系统。
可以通过以下命令获取磁盘的状态:
# smartctl -a /dev/sdX
其中/dev/sdX是到本地磁盘的路径。
如果输出是:
SMART support is: Disabled
您可以使用以下命令来启用它:
# smartctl -s on /dev/sdX
有关如何使用smartctl的更多信息,请参阅man smartctl。
默认情况下,smartmontools守护进程“smartd”处于激活状态并已开启,扫描“/dev/sdX”和“/dev/sdX”下的磁盘/dev/hdX每30分钟发送一次错误和警告,如果它检测到问题,就向根用户发送一封电子邮件。
更多关于smartd的配置方法,请参见man smartd和man smartd.conf。
如果您将硬盘与硬件raid控制器一起使用,那么很可能会有一些工具来监视磁盘raid阵列和阵列本身。有关这方面的更多信息,请咨询您的raid的供应商控制器。
3.7、LVM
大多数人直接在本地磁盘上安装Proxmox VE。Proxmox VE安装光盘提供了几种方法本地磁盘管理选项,当前默认设置使用LVM。安装程序允许您选择单个磁盘用于这样的设置,并将该磁盘用作卷组(VG) pve的物理卷。以下是使用8GB磁盘的测试安装的输出:
# pvsPV VG Fmt Attr PSize PFree/dev/sda3 pve lvm2 a-- 7.87g 876.00m# vgsVG #PV #LV #SN Attr VSize VFreepve 1 3 0 wz--n- 7.87g 876.00m
安装程序在这个VG中分配三个逻辑卷(LV):
# lvsLV VG Attr LSize Pool Origin Data% Meta%data pve twi-a-tz-- 4.38g 0.00 0.63root pve -wi-ao---- 1.75gswap pve -wi-ao---- 896.00m
root
格式化为ext4,包含操作系统。
swap
交换分区
data
该卷使用LVM-thin,用于存储虚拟机镜像。LVM-thin更适合这个任务,因为它提供了对快照和克隆的有效支持。
对于高达4.1的Proxmox VE版本,安装程序创建一个称为“data”的标准逻辑卷/var/lib/vz.
从版本4.2开始,逻辑卷“data”是一个lvm精简池,用于存储基于客户机的块,而/var/lib/vz只是根文件系统上的一个目录。
3.7.1、硬件
我们强烈推荐使用硬件RAID控制器(带BBU)进行这种设置。这增加性能,提供了冗余,使磁盘替换更容易(热插拔)。
LVM本身不需要任何特殊的硬件,而且内存需求非常低。
3.7.2、引导装载程序
我们默认安装两个引导加载程序。第一个分区包含标准的GRUB引导加载程序。第二个分区是一个EFI系统分区(ESP),它使在EFI系统上引导成为可能。
3.7.3、创建卷组
假设我们有一个空磁盘/dev/sdb,我们想在其上创建一个卷组,名为“vmdata”。
谨慎:请注意,以下命令将销毁/dev/sdb上的所有现有数据
首先创建一个分区。
# sgdisk -N 1 /dev/sdb
创建一个不需要确认的物理卷(PV)和250K元数据
# pvcreate --metadatasize 250k -y -ff /dev/sdb1
在/dev/sdb1上创建卷组“vmdata”
# vgcreate vmdata /dev/sdb1
3.7.4、为/var/lib/vz创建一个额外的LV
这可以通过创建一个新的thin LV轻松完成。
# lvcreate -n <Name> -V <Size[M,G,T]> <VG>/<LVThin_pool>
一个真实的例子:
# lvcreate -n vz -V 10G pve/data
现在必须在LV上创建一个文件系统。
# mkfs.ext4 /dev/pve/vz
最后这个必须挂载上去。
警告确保/var/lib/vz是空的。在默认安装中不是这样的。
要使它始终可访问,请在/etc/fstab中添加以下一行
# echo '/dev/pve/vz /var/lib/vz ext4 defaults 0 2' >> /etc/fstab
3.7.5、调整精简池大小
可以使用以下命令来调整LV和元数据池的大小。
# lvresize --size +<size[\M,G,T]> --poolmetadatasize +<size[\M,G]> <VG>/<LVThin_pool>
Note扩展数据池时,元数据池也需要扩展。
3.7.6、创建LVM-thin池
精简池必须在卷组上创建。如何创建卷组请参见LVM章节。
# lvcreate -L 80G -T -n vmstore vmdata
3.8、Linux上ZFS
ZFS是Sun Microsystems设计的文件系统和逻辑卷管理器的组合。从Proxmox VE 3.4开始,ZFS文件系统的本地Linux内核端口,作为可选文件系统和根文件系统的附加选择。不需要手动编译ZFS模块-包含所有包。
通过使用ZFS,可以用低预算的硬件实现最大限度的企业功能,但成本也很高通过利用SSD缓存甚至仅SSD设置来实现性能系统。ZFS可以取代成本高昂的产品硬件raid卡由适中的CPU和内存负载结合,易于管理。
ZFS的一般优点:
- 简单的配置和管理与Proxmox VE GUI和CLI。
- 可靠的
- 防止数据损坏
- 文件系统级的数据压缩
- 快照
- 写时复制克隆
- 多种RAID级别:RAID0、RAID1、RAID10、RAIDZ-1、RAIDZ-2、RAIDZ-3
- 可以使用SSD作为缓存
- 自我疗愈
- 连续完整性检查
- 为高存储容量而设计
- 网络异步复制
- 开源
- 加密
- 。。。
3.8.1、硬件
ZFS在很大程度上依赖于内存,因此启动时至少需要8GB内存。在实践中,尽可能多地使用为您的硬件/预算。为了防止数据损坏,我们建议使用高质量的ECC RAM。如果您使用专用的缓存和/或日志磁盘,那么您应该使用企业级的SSD(例如Intel SSD DC S3700系列)。这可以显著提高整体性能。
重要不要在硬件控制器上使用ZFS,因为硬件控制器有自己的缓存管理。ZFS需要直接与磁盘通信。一个HBA适配器,或者像LSI控制器这样的东西是可行的在“IT”模式下闪烁。
如果您正在尝试在VM中安装Proxmox VE(嵌套虚拟化),请不要使用virtio作为虚拟机磁盘,因为ZFS不支持。使用IDE或SCSI代替(也可以使用virtio SCSI控制器类型)。
3.8.2、作为根文件系统安装
使用Proxmox VE安装程序进行安装时,可以选择ZFS作为根文件系统。你需要安装时选择RAID类型:
RAID0:
也称为“分段”。该卷的容量是所有容量的总和磁盘。但是RAID0没有增加任何冗余,所以单个驱动器会出现故障使卷无法使用。
RAID1:
也称为“镜像“。所有磁盘的写入数据完全相同。此模式需要至少2个相同大小的磁盘。由此产生的容量是单个磁盘的容量。
RAID10:
RAID0和RAID1的组合。至少需要4个磁盘。
RAIDZ-1:
RAID-5的一个变体,单一奇偶校验。至少需要3个磁盘。
RAIDZ-2:
RAID-5的一个变体,双奇偶校验。至少需要4个磁盘。
RAIDZ-3:
RAID-5的一种变体,三重奇偶校验。至少需要5个磁盘。
安装程序自动对磁盘进行分区,创建一个名为rpool的ZFS池,并安装根文件ZFS子卷rpool/ROOT/pve-1上的系统。
另一个名为rpool/data的子卷用于存储虚拟机镜像。为了在Proxmox VE工具中使用它,安装程序在/etc/pve/storage.cfg中创建如下配置项
zfspool: local-zfspool rpool/datasparsecontent images,rootdir
安装完成后,可以使用zpool命令查看ZFS池的状态:
# zpool statuspool: rpoolstate: ONLINEscan: none requestedconfig:NAME STATE READ WRITE CKSUMrpool ONLINE 0 0 0mirror-0 ONLINE 0 0 0sda2 ONLINE 0 0 0sdb2 ONLINE 0 0 0mirror-1 ONLINE 0 0 0sdc ONLINE 0 0 0sdd ONLINE 0 0 0errors: No known data errors
zfs命令用于配置和管理您的zfs文件系统。下面的命令列出了所有文件系统安装后:
# zfs listNAME USED AVAIL REFER MOUNTPOINTrpool 4.94G 7.68T 96K /rpoolrpool/ROOT 702M 7.68T 96K /rpool/ROOTrpool/ROOT/pve-1 702M 7.68T 702M /rpool/data 96K 7.68T 96K /rpool/datarpool/swap 4.25G 7.69T 64K -
3.8.3、ZFS RAID级别注意事项
在选择ZFS池的布局时,有几个因素需要考虑。ZFS池的基本构建块是虚拟设备或vdev。同一池中所有vdev的使用率相同,数据呈条带化,其中(RAID0)。查看zpool(8) manpage了解更多关于vdevs的细节。
性能
**
每种vdev类型都有不同的性能行为。IOPS(每秒输入/输出操作数)和可写/可读带宽是两个需要关注的参数。就这两个参数而言,镜像vdev (RAID1)在写入时的行为近似于单个磁盘数据。读取数据时,if的行为与镜像中的磁盘数量类似。
一种常见的情况是有4个磁盘。当将它设置为2个镜像vdevs (RAID10)时,池将拥有从IOPS和带宽来看,写特性相当于两块单盘。对于读操作,它会类似4个单个磁盘。
任何冗余级别的RAIDZ在IOPS方面的表现近似于单个磁盘带宽。带宽大小取决于RAIDZ vdev的大小和冗余级别。
对于运行中的虚拟机,IOPS在大多数情况下是更重要的指标。
大小、空间使用和冗余
**
虽然由镜像vdevs组成的池将具有最佳的性能特征,但可用空间将是50%的磁盘可用。如果一个镜像vdev包含2个以上的磁盘,例如在一个3-way镜像中。每个镜像至少需要一个正常磁盘,池才能保持功能。
N块磁盘的RAIDZ类型vdev的可用空间约为N-P, P表示RAIDZ级别。RAIDZ -“级别”表示任意有多少块硬盘故障而不丢失数据。一个特殊的情况是4 disk pool with了RAIDZ2。在这种情况下,通常最好使用2个镜像vdevs,以获得更好的可用性能空间是一样的。
在使用任何RAIDZ级别时,另一个重要的因素是用于VM磁盘的ZVOL数据集,的行为。对于每个数据块,池需要校验数据,校验数据的大小至少为最小块大小由池的移位值定义。移动12时,池的块大小是4k。默认的ZVOL的块大小是8k。因此,在RAIDZ2中,每写入一个8k块将导致两个额外的4k奇偶校验待写入的块,8k + 4k + 4k = 16k。这当然是一种简化的方法,实际情况是与元数据稍有不同,本例中没有考虑压缩等问题。
这种行为可以在检查ZVOL的以下属性时观察到:
- volsize
- refreservation(如果池不是精简配置的)
- used(如果池为精简配置,且不存在快照)
# zfs get volsize,refreservation,used <pool>/vm-<vmid>-disk-X
volsize表示磁盘呈现给虚拟机时的大小,而reservation表示预留的大小池中的空间,包括校验数据所需的预期空间。如果池为thin provisioned时,预留将被设置为0。另一种观察行为的方法是比较虚拟机内已用磁盘空间和已用属性。请注意,快照将扭曲该值。
以下是一些应对空间使用增加的方法:
- 增加volblocksize以提高数据校验比
- 使用镜像vdevs而不是RAIDZ
- 使用ashift=9(块大小为512字节)
volblocksize属性只能在创建ZVOL时设置。默认值可以修改存储配置。当这样做时,客户需要相应地调整,这取决于用例,写放大的问题,如果只是从ZFS层移动到客户端。
在创建池时使用shift=9可能会导致糟糕的性能,这取决于下面的磁盘,而且以后也无法改变。
镜像vdev (RAID1、RAID10)可以为虚拟机提供良好的工作性能。使用它们,除非你的环境有特定的需求和特性,可以接受RAIDZ的性能特性。
3.8.4、引导装载程序
根据系统是在EFI还是传统BIOS模式启动,promox VE安装程序设置将grub或system -boot作为主引导加载程序。参见Proxmox VE主机引导器章节第3.11节详细说明。
3.8.5、ZFS管理
本节给出一些常见任务的用法示例。ZFS本身非常强大而且提供许多选项。管理ZFS的主要命令是zfs和zpool。这两个命令都带有丰富手册页,可与以下内容一起阅读:
# man zpool# man zfs
创建一个新的zpool
**
创建新存储池时,至少需要一个磁盘。移位应该具有相同的扇区大小(2次方)或更大的,如基础磁盘。
# zpool create -f -o ashift=12 <pool> <device>
要激活压缩(参见ZFS中的压缩部分):
# zfs set compression=lz4 <pool>
使用RAID-0创建一个新的池
**
至少一个磁盘
# zpool create -f -o ashift=12 <pool> <device1> <device2>
使用RAID-1创建一个新的池
**
至少2个磁盘
# zpool create -f -o ashift=12 <pool> mirror <device1> <device2>
使用RAID-10创建一个新的池
**
至少4个磁盘
# zpool create -f -o ashift=12 <pool> mirror <device1> <device2> mirror <device3> \ <device4>
使用RAIDZ-1创建一个新的池
至少3个磁盘
# zpool create -f -o ashift=12 <pool> raidz1 <device1> <device2> <device3>
使用RAIDZ-2创建一个新的池
**
至少4个磁盘
# zpool create -f -o ashift=12 <pool> raidz2 <device1> <device2> <device3> <device4>
创建一个新的缓存池(L2ARC)
*
可以使用专用的缓存驱动器分区来提高性能(使用SSD)。它可以使用更多的设备,就像它显示在“创建一个新的RAID池”。
# zpool create -f -o ashift=12 <pool> <device> cache <cache_device>
使用日志创建一个新的池(ZIL)
**
可以使用专用的缓存驱动器分区来提高性能(SSD)。它可以使用更多的设备,就像它显示在“创建一个新的RAID池。
# zpool create -f -o ashift=12 <pool> <device> log <log_device>
向现有池添加缓存和日志
如果您有一个没有缓存和日志的池。第一个分区将SSD盘划分为“2”分区,使用“parted”或“gdisk”
重要始终使用GPT分区表
日志设备的最大大小应该是物理内存大小的一半左右,所以这通常相当小。SSD盘的其余部分可作为缓存使用。
# zpool add -f <pool> log <device-part1> cache <device-part2>
更换故障设备**
# zpool replace -f <pool> <old device> <new device>
更改一个失败的可引导设备
**
根据Proxmox VE的安装方式,它使用grub或systemd-boot作为引导加载程序(参见主机引导加载程序第3.11节)。
复制分区表、重新发出guid和替换ZFS分区的第一步是相同的。要使系统可以从新磁盘引导,需要不同的步骤,这取决于引导加载程序在使用。
# sgdisk <healthy bootable device> -R <new device># sgdisk -G <new device># zpool replace -f <pool> <old zfs partition> <new zfs partition>
Note使用zpool status -v命令监视新磁盘的重新安装过程有多远进展。
systemd-boot:
**# pve-efiboot-tool format <new disk’s ESP># pve-efiboot-tool init <new disk’s ESP>
NoteESP代表EFI系统分区,它被Proxmox设置为可引导磁盘上的分区#2VE安装程序自版本5.4。详细信息请参见建立新分区用于同步ESP设置建立一个新的分区作为同步ESP使用。
With grub:
**# grub-install <new disk>
3.8.6、激活电子邮件通知
ZFS附带了一个事件守护进程,它监视由ZFS内核模块生成的事件。这个守护进程还可以在ZFS事件(如池错误)上发送电子邮件。较新的ZFS包单独提供这个守护进程包,您可以使用apt-get安装它:
# apt-get install zfs-zed
要激活这个守护进程,必须编辑/etc/zfs/zed.d/zed.rc与您最喜欢的编辑器,和取消对ZED_EMAIL_ADDR设置的注释:
ZED_EMAIL_ADDR="root"
请注意Proxmox VE将发送到根用户的邮件转发到为根用户配置的电子邮件地址。
重要唯一需要的设置是ZED_EMAIL_ADDR。所有其他设置都是可选的。
3.8.7、限制ZFS的内存使用
最好最多为ZFS ARC使用50%(这是默认值)的系统内存,以防止主机的性能不足。使用您首选的编辑器更改/etc/modprobe.d/zfs.conf中的配置并插入:
options zfs zfs_arc_max=8589934592
这个示例设置限制使用8GB。
重要如果你的根文件系统是ZFS,你必须每次这个值改变时更新你的initramfs:# update-initramfs -u
3.8.8、ZFS Swap
在zvol上创建的交换空间可能会产生一些问题,比如阻塞服务器或产生较高的IO加载,通常在启动对外部存储的备份时看到。
我们强烈建议使用足够的内存,这样您通常就不会遇到内存不足的情况。如果您需要或希望添加交换空间,那么最好在物理磁盘上创建一个分区并使用它swapdevice。您可以在安装程序的高级选项中为这个目的留出一些空间。此外,你可以降低“swappiness”值。对于服务器来说,一个好的值是10:
# sysctl -w vm.swappiness=10
要使切换持久,请使用您选择的编辑器打开/etc/sysctl.conf,并添加以下行:
vm.swappiness = 10
表3.1 Linux内核交换参数值
| 值 | 策略 |
|---|---|
| vm.swappiness = 0 | 内核只会交换以避免内存不足的情况 |
| vm.swappiness = 1 | 在不完全禁用的情况下进行最小数量的交换。 |
| vm.swappiness = 10 | 为了提高性能,有时建议使用此值当系统有足够的内存时 |
| vm.swappiness = 60 | 默认值 |
| vm.swappiness = 100 | 内核会主动进行交换。 |
3.8.9、ZFS加密的数据集
Linux版本0.8.0上的ZFS引入了对数据集原生加密的支持。从以前的ZFS在Linux版本,加密功能可以启用每个池:
# zpool get feature@encryption tankNAME PROPERTY VALUE SOURCEtank feature@encryption disabled local# zpool set feature@encryption=enabled# zpool get feature@encryption tankNAME PROPERTY VALUE SOURCEtank feature@encryption enabled local
警告目前不支持使用Grub从带有加密数据集的池中引导,而且只支持有限的支持自动解锁加密的数据集在引导。旧版本的ZFS没有加密支持将无法解密存储的数据。Note建议要么在启动后手动解锁存储数据集,要么写入一个自定义单元将启动时解锁所需的密钥材料传递给zfs load-key警告在启用生产数据加密功能之前,请先建立并测试备份流程。如果是,关联的密钥材料/密码/密钥文件已经丢失,不能再访问加密数据可能的。
在创建数据集/zvol时需要设置加密,并且默认继承给子数据集。为创建加密数据集tank/encrypted_data并将其配置为PVE中的存储,执行如下命令:
# zfs create -o encryption=on -o keyformat=passphrase tank/encrypted_dataEnter passphrase:Re-enter passphrase:
# pvesm add zfspool encrypted_zfs -pool tank/encrypted_data
在此存储上创建的所有来宾卷/磁盘都将使用父节点的共享密钥材料进行加密数据集。要实际使用存储,需要加载关联的密钥材料和数据集安装。这可以通过以下步骤完成:
# zfs mount -l tank/encrypted_dataEnter passphrase for ’tank/encrypted_data’:
也可以使用(随机)密钥文件,而不是通过设置密钥位置提示输入密码短语和keyformat属性,无论是在创建时或使用zfs change-key对现有数据集:
# dd if=/dev/urandom of=/path/to/keyfile bs=32 count=1# zfs change-key -o keyformat=raw -o keylocation=file:///path/to/keyfile \ tank/encrypted_data
警告在使用密钥文件时,需要特别小心以保护密钥文件不受未经授权的攻击访问或意外损失。没有密钥文件,就不可能访问明文数据!
在加密数据集下面创建的来宾卷将设置其encryptionroot属性相应的行动。密钥材料只需要在每个encryptionroot上加载一次,就可以对所有加密的用户可用下面的数据集。查看encryptionroot,encryption , keylocation , keyformat和keystatus属性、zfs load-key、zfs unload-key和zfs change-key命令以及 Encryption更多详细信息和高级用法,请参阅man zfs部分。
3.8.10、ZFS压缩
当在数据集上启用压缩时,ZFS尝试在写入所有新块之前压缩它们在阅读时给他们减压。已经存在的数据不会被追溯压缩。你可以通过以下方式启用压缩:
# zfs set compression=<algorithm> <dataset>
我们建议使用lz4算法,因为它只增加很少的CPU开销。lzjb和gzip-N(其中N是一个从1(最快)到9(最佳压缩比)的整数)等算法也可用。根据算法和数据的可压缩性,启用压缩甚至可以提高I / O性能。
你可以在任何时候禁用压缩:
# zfs set compression=off <dataset>
同样,只有新块会受到此更改的影响。
3.8.11、ZFS特殊设备
由于版本0.8.0,ZFS支持特殊设备。池中有一个特殊的设备用来存储元数据数据、重复数据删除表和可选的小文件块。
一种特殊的设备可以提高由低速旋转的硬盘组成的池的速度元数据的变化。例如,涉及创建、更新或删除大量的工作负载文件将受益于特殊设备的存在。ZFS数据集也可以配置为存储整个小文件在专用设备上可以进一步提高性能。使用快速ssd硬盘特殊的设备。
重要特殊设备的冗余度应该与池的冗余度匹配,因为特殊设备的冗余度应该与池的冗余度匹配设备是整个池的故障点。警告向池中添加特殊设备是无法撤消的!
创建具有特殊设备和RAID-1的池:
**# zpool create -f -o ashift=12 <pool> mirror <device1> <device2> special mirror \ <device3> <device4>
在已有的RAID-1池中添加特殊设备
**# zpool add <pool> special mirror <device1> <device2>
ZFS数据集暴露special_small_blocks=属性。大小可以为0来禁用在专用设备上存储小文件块或512B ~ 128K范围内的2的次方。设置属性后,将在特殊设备上分配小于size的新文件块。
重要如果special_small_blocks的值大于或等于recordsize(默认值128K)的数据集,所有数据都将写入专用设备,所以要小心!
在池中设置special_small_blocks属性将更改该属性的默认值对于所有的子ZFS数据集(例如,池中的所有容器都将选择小文件块)。
选择所有小于4k -块池范围的文件:
**# zfs set special_small_blocks=4K <pool>
为单个数据集选择小文件块
**# zfs set special_small_blocks=4K <pool>/<filesystem>
选择从单个数据集的小文件块退出:
**# zfs set special_small_blocks=0 <pool>/<filesystem>
3.9、Proxmox节点管理
Proxmox VE节点管理工具(pvenode)允许控制节点特定的设置和资源。
目前,pvenode允许设置一个节点的描述和管理用于该节点的SSL证书通过pveproxy实现API和web GUI
3.9.1、局域网唤醒
唤醒局域网(WoL)允许通过发送一个神奇的数据包打开网络中处于休眠状态的计算机。至少一个网卡必须支持此功能,并且需要在计算机中启用相应的选项固件(BIOS / UEFI)配置。选项名称可以从启用局域网唤醒到上电PCIE设备,检查您的主板供应商手册,如果不确定。ethtool可用于检查WoL运行以下命令配置:
ethtool <interface> | grep Wake-on
pvenode允许通过WoL唤醒集群休眠成员,使用以下命令:
pvenode wakeonlan <node>
它在UDP端口9上广播WoL魔术包,包含获得的<节点>的MAC地址从wakeonlan属性。特定于节点的wakeonlan属性可以通过以下命令设置:
pvenode config set -wakeonlan XX:XX:XX:XX:XX:XX
3.10、证书管理
3.10.1、用于集群内通信的证书
默认情况下,每个Proxmox VE集群创建自己的(自签名)证书颁发机构(CA)并生成由上述CA签名的每个节点的证书。这些证书用于与集群的pveproxy服务和Shell/Console特性(如果SPICE是)进行加密通信使用。
CA证书和密钥存储在Proxmox集群文件系统(pmxcfs)第6章中。
3.10.2、API和Web GUI的证书
REST API和web GUI是由运行在每个节点上的pveproxy服务提供的。
pveproxy使用的证书有以下选项:
- 默认情况下,指定节点的证书在/etc/pve/nodes/ nodename /pve-ssl中。使用pem。此证书由集群CA签名,因此不自动受到浏览器和操作系统。
- 使用外部提供的证书(例如由商业核证机关签署)。
- 使用ACME(让我们加密)来获得具有自动续签功能的受信任证书,这也集成在其中Proxmox VE API和web接口。
对于选项2和3,文件/etc/pve/local/pveproxy-ssl.pem (和/etc/pve/local/pveproxy-ssl.key,它需要没有密码)被使用。
Note请记住,/etc/pve/local是到/etc/pve/nodes/NODENAME的特定节点符号链接
使用Proxmox VE节点管理命令(参见pvenode(1) man-page)。
警告不替换或手动修改?中自动生成的节点证书文件/etc/pve/local/pve-ssl.pem和/etc/pve/local/pve-ssl.key或群集/etc/pve/pve-root-ca.pem目录下的CA文件和/etc/pve/priv/pve-root-ca.key
3.10.3、上传自定义证书
如果您已经有一个证书,希望用于Proxmox VE节点,则可以上传该证书只需通过web界面。修改翻译结果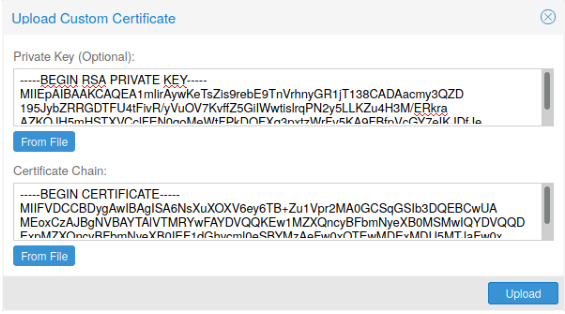
注意,如果提供了证书密钥文件,则不能使用密码保护。
3.10.4、可信证书通过Let ‘s Encrypt (ACME)
Proxmox VE包括自动证书管理环境ACME协议的实现,允许Proxmox VE管理员与Let’s Encrypt接口,以便轻松地设置受信任的TLS证书,这在大多数现代操作系统和浏览器上都是开箱即用的。
目前实现的两个ACME端点是Let’s Encrypt (LE)产品及其登台环境。我们的ACME客户机支持使用内置的web服务器验证http-01挑战使用支持所有DNS API端点acme.sh的DNS插件验证DNS -01挑战
ACME帐户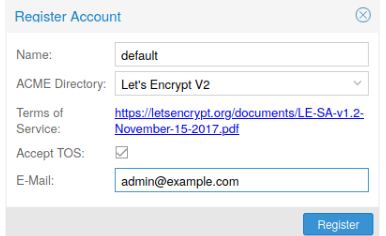
您需要为每个集群向希望使用的端点注册一个ACME帐户。电子邮件地址用于该帐户的服务器将作为来自ACME的到期续期通知或类似通知的联络点端点。
您可以通过web接口Datacenter -> ACME注册和去激活ACME帐户pvenode命令行工具。
pvenode acme account register account-name mail@example.com
提示由于速率限制,您应该在实验中使用LE staging,或者在第一次使用ACME时使用
ACME插件
**
ACME插件的任务是为您提供自动验证,从而在Proxmox VE集群下进行验证您的操作,是一个域名的真正所有者。这是自动证书的基本构建块管理。
ACME协议指定了不同类型的挑战,例如http-01,其中一个web服务器提供一个具有特定值的文件,以证明它控制一个域。有时这也是不可能的由于技术限制,或者域所指向的地址无法从公共internet访问。对于这种情况,可以使用dns-01挑战。这个挑战也提供了一定的价值,但是通过域名的权威名称服务器上的DNS记录,而不是通过文本文件。
Proxmox VE支持这两种挑战类型的开箱即用,您可以通过web界面下的Datacenter -> ACME,或使用pvenode ACME plugin add命令。
ACME插件配置文件存放在“/etc/pve/priv/acme/plugins.cfg”目录下。有一个插件可用对于集群中的所有节点。
节点域
**
每个域是特定于节点的。您可以在Node ->下添加新的或管理现有的域条目证书,或者使用pvenode config命令。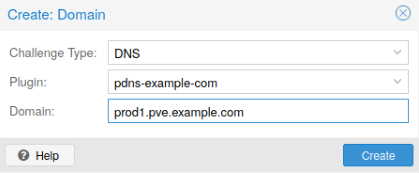
在为节点配置了所需的域并确保选中了所需的ACME帐户后,您可以通过web界面订购您的新证书。如果成功,界面将在10s后重新加载。
更新将自动发生第3.10.7节。
3.10.5、ACME HTTP挑战插件
总是有一个隐式配置的独立插件用于验证http-01挑战内置的web服务器在端口80上生成。
Note独立的名称意味着它可以自己提供验证,而不需要任何第三方服务。因此,这个插件也适用于集群节点。
使用Let’s加密ACME进行证书管理有几个先决条件。
- 您必须接受“让我们加密”的服务条款来注册帐户。
- 节点的80号端口需要与internet连接。
- 端口80上必须没有其他监听器。
- 请求的(子)域需要解析到节点的公共IP。
3.10.6、ACME DNS API挑战插件
在不可能或不希望通过http-01方法进行外部验证的系统上,它可以可以使用dns-01验证方法。此验证方法需要一个允许通过API提供TXT记录。
配置ACME DNS api进行验证
**
Proxmox VE重用了为acme.sh开发的DNS插件计划,请参阅其文献展-了解具体api的配置信息。使用DNS API配置新插件的最简单方法是使用web接口(Datacenter ->ACME)。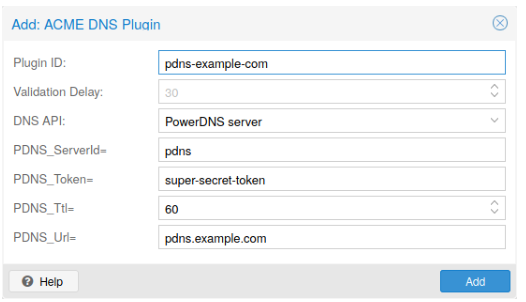
选择DNS作为挑战类型。然后您可以选择您的API提供者,输入要访问的凭据数据你的帐户,他们的API。
提示请参阅acme.sh如何使用DNS API wiki(https://github.com/acmesh-official/acme.sh/wiki/dnsapi#how-to-use-dns-api),了解有关获取API凭据的更详细信息你的供应商。
由于有如此多的API端点,Proxmox VE自动生成凭证的表单,但不是全部提供程序还带有注释。您将看到更大的文本区域,只需复制所有凭据即可KEY = VALUE对在这里。
通过CNAME别名验证DNS
可以使用特殊的别名模式在不同的域/DNS服务器上处理验证,以防您的主DNS /真实DNS不支持通过API进行配置。手动设置一个永久的CNAME记录_acme-challenge.domain1.example。指向_acme-challenge.domain2.example,将Proxmox VE节点配置文件中的alias属性设置为domain2。启用DNS服务domain2服务器。验证domain1.example所有挑战
组合的插件
**
结合http-01和dns-01验证是可能的,如果您的节点可以通过多个域访问具有不同需求/ DNS供应能力的市电。混合来自多个提供商的DNS api or实例也可以通过为每个域指定不同的插件实例来实现。
提示在多个域上访问相同的服务会增加复杂性,应该尽可能避免。
3.10.7、自动更新ACME证书
如果一个节点已经成功地配置了acme提供的证书(通过pvenode或via),证书将自动更新的pve-daily-update。服务。目前,如果证书已经过期,或将在未来30天内过期,将尝试更新。
3.10.8、使用pvenode的ACME示例
示例:使用Let ‘s Encrypt证书的示例pvenode调用
root@proxmox:~# pvenode acme account register default mail@example.invalidDirectory endpoints:0) Let’s Encrypt V2 (https://acme-v02.api.letsencrypt.org/directory)1) Let’s Encrypt V2 Staging (https://acme-staging-v02.api.letsencrypt.org/ ←-directory)2) CustomEnter selection: 1Terms of Service: https://letsencrypt.org/documents/LE-SA-v1.2-November ←--15-2017.pdfDo you agree to the above terms? [y|N]y...Task OKroot@proxmox:~# pvenode config set --acme domains=example.invalidroot@proxmox:~# pvenode acme cert orderLoading ACME account detailsPlacing ACME order...Status is ’valid’!All domains validated!...Downloading certificateSetting pveproxy certificate and keyRestarting pveproxyTask OK
示例:设置用于验证域的OVH API
请注意帐号注册的步骤是相同的,无论使用什么插件,这里不再重复。请注意OVH_AK和OVH_AS需要根据OVH API文档从OVH获取
首先,您需要获取所有信息,以便您和Proxmox VE能够访问API。
root@proxmox:~# cat /path/to/api-tokenOVH_AK=XXXXXXXXXXXXXXXXOVH_AS=YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYroot@proxmox:~# source /path/to/api-tokenroot@proxmox:~# curl -XPOST -H"X-Ovh-Application: $OVH_AK" -H "Content-type ←-: application/json" \https://eu.api.ovh.com/1.0/auth/credential -d ’{"accessRules": [{"method": "GET","path": "/auth/time"},{"method": "GET","path": "/domain"},{"method": "GET","path": "/domain/zone/ * "},{"method": "GET","path": "/domain/zone/ * /record"},{"method": "POST","path": "/domain/zone/ * /record"},{"method": "POST","path": "/domain/zone/ * /refresh"},{"method": "PUT","path": "/domain/zone/ * /record/"},{"method": "DELETE","path": "/domain/zone/ * /record/ * "}]}’{"consumerKey":"ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ","state":" ←-pendingValidation","validationUrl":"https://eu.api.ovh.com/auth/? ←-credentialToken= ←-AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA"}(open validation URL and follow instructions to link Application Key with ←-account/Consumer Key)root@proxmox:~# echo "OVH_CK=ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ" >> /path/to/ ←-api-token
现在你可以设置ACME插件:
root@proxmox:~# pvenode acme plugin add dns example_plugin --api ovh --data ←-/path/to/api_tokenroot@proxmox:~# pvenode acme plugin config example_plugin┌────────┬──────────────────────────────────────────┐│ key │ value │╞════════╪══════════════════════════════════════════╡│ api │ ovh │├────────┼──────────────────────────────────────────┤│ data │ OVH_AK=XXXXXXXXXXXXXXXX ││ │ OVH_AS=YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY ││ │ OVH_CK=ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ │├────────┼──────────────────────────────────────────┤│ digest │ 867fcf556363ca1bea866863093fcab83edf47a1 │├────────┼──────────────────────────────────────────┤│ plugin │ example_plugin │├────────┼──────────────────────────────────────────┤│ type │ dns │└────────┴──────────────────────────────────────────┘
最后,你可以配置你想要获取证书的域,并为它下证书订单:
root@proxmox:~# pvenode config set -acmedomain0 example.proxmox.com,plugin= ←-example_pluginroot@proxmox:~# pvenode acme cert orderLoading ACME account detailsPlacing ACME orderOrder URL: https://acme-staging-v02.api.letsencrypt.org/acme/order ←-/11111111/22222222Getting authorization details from ’https://acme-staging-v02.api. ←-letsencrypt.org/acme/authz-v3/33333333’The validation for example.proxmox.com is pending![Wed Apr 22 09:25:30 CEST 2020] Using OVH endpoint: ovh-eu[Wed Apr 22 09:25:30 CEST 2020] Checking authentication[Wed Apr 22 09:25:30 CEST 2020] Consumer key is ok.[Wed Apr 22 09:25:31 CEST 2020] Adding record[Wed Apr 22 09:25:32 CEST 2020] Added, sleep 10 seconds.Add TXT record: _acme-challenge.example.proxmox.comTriggering validationSleeping for 5 secondsStatus is ’valid’![Wed Apr 22 09:25:48 CEST 2020] Using OVH endpoint: ovh-eu[Wed Apr 22 09:25:48 CEST 2020] Checking authentication[Wed Apr 22 09:25:48 CEST 2020] Consumer key is ok.Remove TXT record: _acme-challenge.example.proxmox.comAll domains validated!Creating CSRChecking order statusOrder is ready, finalizing ordervalid!Downloading certificateSetting pveproxy certificate and keyRestarting pveproxyTask OK
示例:从staging目录切换到常规ACME目录
**
不支持更改帐户的ACME目录,但由于Proxmox VE支持多个帐户您可以只创建一个新帐户,以生产(受信任)ACME目录作为端点。你可以同时停用暂存帐户并重新创建它。
示例:使用pvenode将默认的ACME帐户从staging更改为directory
root@proxmox:~# pvenode acme account deactivate defaultRenaming account file from ’/etc/pve/priv/acme/default’ to ’/etc/pve/priv/ ←-acme/_deactivated_default_4’Task OKroot@proxmox:~# pvenode acme account register default example@proxmox.comDirectory endpoints:0) Let’s Encrypt V2 (https://acme-v02.api.letsencrypt.org/directory)1) Let’s Encrypt V2 Staging (https://acme-staging-v02.api.letsencrypt.org/ ←-directory)2) CustomEnter selection: 0Terms of Service: https://letsencrypt.org/documents/LE-SA-v1.2-November ←--15-2017.pdfDo you agree to the above terms? [y|N]y...Task OK
3.11、主机引导装载程序
Proxmox VE目前使用两种引导加载程序之一,这取决于安装程序中选择的磁盘安装程序。
对于使用ZFS作为根文件系统安装的EFI系统,使用系统引导。所有其他的部署使用标准的grub引导程序(这通常也适用于安装在Debian之上的系统)。
3.11.1、安装程序使用的分区方案
Proxmox VE安装程序在选择安装的引导磁盘上创建3个分区。可引导的磁盘:
- 使用ext4或xfs安装时选择的磁盘
- ZFS安装的所有磁盘都属于第一个vdev:
- 用于RAID0的第一块磁盘
- RAID1、RAIDZ1、RAIDZ2、RAIDZ3的所有磁盘
- 用于RAID10的前2块磁盘
创建的分区为:
- 一个1mb的BIOS启动分区(gdisk type EF02)
- 一个512mb的EFI系统分区(ESP, gdisk type EF00)
- 第三个分区,跨越设置的hdsize参数或用于所选存储的剩余空间类型
BIOS模式下的grub(——target i386-pc)安装在所有可引导磁盘的BIOS引导分区上支持旧系统。
3.11.2、确定使用哪个引导加载程序
确定使用哪个引导加载程序的最简单和最可靠的方法是观察的引导过程Proxmox VE节点。
您将看到grub的蓝色盒子或简单的黑上白系统引导
从正在运行的系统中确定引导加载程序可能不是100%准确的。最安全的办法是下面的命令:
# efibootmgr -v
如果它返回不支持EFI变量的消息,grub将在BIOS/Legacy模式下使用。
如果输出中包含类似于下面的一行,那么grub是在UEFI模式下使用的。
Boot0005 * proxmox [...] File(\EFI\proxmox\grubx64.efi)
如果输出包含类似下面的一行,则使用systemd-boot。
Boot0006 * Linux Boot Manager [...] File(\EFI\systemd\systemd-bootx64.efi )
3.11.3、Grub
grub多年来一直是引导Linux系统的事实上的标准,并且有很好的文档说明
内核和initrd映像取自/boot及其配置文件/boot/grub/grub.cfg由内核安装过程更新。
配置
**
对grub配置的修改是通过默认文件/etc/default/grub或配置快照在/etc/default/grub.d。在修改后重新生成/boot/grub/grub.cfg文件配置运行:
'update-grub'.
3.11.4、Systemd-boot
systemd-boot是一个轻量级的EFI引导加载程序。它直接从EFI读取内核和initrd映像ESP (Service Partition),即安装ESP的分区。直接从ESP加载内核的主要优点它不需要重新实现访问存储的驱动程序。在以ZFS为根的上下文中这意味着您可以使用根池上的所有可选特性,而不是使用这个子集同样存在于grub中的ZFS实现中,或者必须创建一个单独的小型引导池所示。
在冗余设置(RAID1, RAID10, RAIDZ)中,所有可引导磁盘(那些是第一个vdev的一部分)用ESP进行分区,确保即使第一个启动设备失败,系统也能正常启动。esp是与/etc/kernel/ postinsta保持同步。d / zz-pve-efiboot。脚本将某些内核版本和initrd映像复制到每个ESP的根目录EFI/proxmox/在loader/entries/proxmox- .conf中创建适当的配置文件。的pve-efiboot-tool脚本帮助管理同步的esp本身及其内容。
默认配置的内核版本如下:
- 当前运行的内核
- 软件包更新中新安装的版本
- 两个最新的已经安装的内核
- 倒数第二个内核系列的最新版本(如4.15,5.0),如果适用的话
- 任何手动选择的内核(见下文)
与grub相反,在常规操作期间,ESP不会一直挂载在/ boot / efi。这有助于防止文件系统损坏到vfat格式的esp在情况下系统崩溃,不再需要手动调整/etc/fstab,以防主启动设备失败。
配置
**
systemd-boot是通过EFI系统根目录下的文件加载器/loader.conf配置的分区(ESP)。详情请参见loader.conf(5)手册。
每个引导加载程序条目都放在loader/entries/目录下自己的文件中
一个示例的entry.conf是这样的(/指的是ESP的根):
title Proxmoxversion 5.0.15-1-pveoptions root=ZFS=rpool/ROOT/pve-1 boot=zfslinux /EFI/proxmox/5.0.15-1-pve/vmlinuz-5.0.15-1-pveinitrd /EFI/proxmox/5.0.15-1-pve/initrd.img-5.0.15-1-pve
手动保持内核可引导
**
您是否希望使用pve-efiboot-tool将某个内核和initrd映像添加到可引导的内核列表中内核添加。
例如,运行以下命令将使用ABI version 5.0.15-1-pve的内核添加到要添加的内核列表中保持安装和同步到所有的esp:
pve-efiboot-tool kernel add 5.0.15-1-pve
pve-efiboot-tool内核列表将列出当前选择引导的所有内核版本:
# pve-efiboot-tool kernel listManually selected kernels:5.0.15-1-pveAutomatically selected kernels:5.0.12-1-pve4.15.18-18-pve
执行pve-efiboot-tool remove从手动选择的内核列表中删除一个内核,例子:
pve-efiboot-tool kernel remove 5.0.15-1-pve
请注意需要运行pve-efiboot-tool refresh来更新所有EFI系统分区(ESPs)从上面手动添加或删除内核。
建立一个新分区作为同步ESP使用
**
将分区格式化并初始化为同步的ESP,例如,在rpool中替换失败的vdev后,或者在转换一个早于同步机制的现有系统时,从pve-kernel-helpers转换为pve-efiboot-tool可以使用。
警告format命令会格式化,请确保传入正确的设备/分区!
以将空分区/dev/sda2格式化为ESP为例,命令如下:
pve-efiboot-tool format /dev/sda2
为了安装一个现有的,卸载位于/dev/sda2上的ESP,以包含在Proxmox VE的内核更新中同步机制,使用如下:
pve-efiboot-tool init /dev/sda2
然后/etc/kernel/pve-efiboot- UUID应该包含一个新行,其中包含新创建的UUID添加分区。init命令也会自动刷新所有已配置的esp。
更新所有esp的配置
**
复制和配置所有可引导的内核,并将所有的esp列在/etc/kernel/pve-efiboot-uuid中同步时,你只需要运行:
pve-efiboot-tool refresh
(相当于在用grub引导的系统上运行update-grub)。如果您要更改内核命令行,或者想要同步所有内核,那么这是必要的initrds。
请注意update-initramfs和apt(在必要时)都将自动触发刷新。
3.11.5、编辑内核命令行
根据使用的引导加载程序,你可以在以下位置修改内核命令行:
Grub
**
内核命令行需要放在文件中的变量GRUB_CMDLINE_LINUX_DEFAULT中/etc/default/grub。运行update-grub将其内容附加到/boot/grub/grub.cfg中的所有linux条目中。
System-boot
*
内核命令行需要放在/etc/kernel/cmdline中作为一行。要应用你的更改时,运行pve-efiboot-tool refresh,为`loader/entries/proxmox- .conf `中所有配置文件设置的选项行

若有收获,就点个赞吧
0 人点赞

{kind=link}