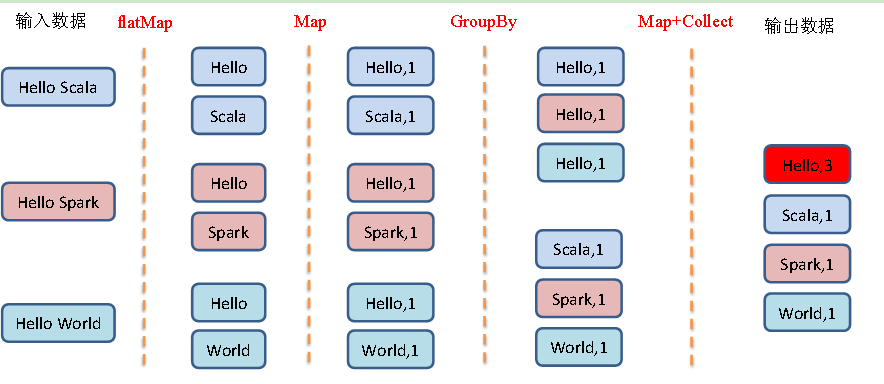
先根据flatMap进行压平,然后在根据map算子给每个词变成元祖,key就是词汇,value就是1, 然后再根据元祖的key进行分组,最后将相同key的value值进行累加.
版本1
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}object Spark06_WordCount1 {def main(args: Array[String]): Unit = {//创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//创建RDDval rdd: RDD[String] = sc.makeRDD(List("Hello Scala", "Hello Spark", "Hello World"))//简单版-实现方式1//对RDD中的元素进行扁平映射val flatMapRDD: RDD[String] = rdd.flatMap(_.split(" "))//将映射后的数据进行结构的转换,为每个单词计数val mapRDD: RDD[(String, Int)] = flatMapRDD.map((_,1))//按照key对RDD中的元素进行分组 (Hello,CompactBuffer((Hello,1), (Hello,1), (Hello,1)))val groupByRDD: RDD[(String, Iterable[(String, Int)])] = mapRDD.groupBy(_._1)//对分组后的元素再次进行映射 (Hello,3)val resRDD: RDD[(String, Int)] = groupByRDD.map {case (word, datas) => { //模式匹配(word, datas.size)}}// 关闭连接sc.stop()}}
版本2
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}object Spark06_WordCount2 {def main(args: Array[String]): Unit = {//创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//创建RDDval rdd: RDD[String] = sc.makeRDD(List("Hello Scala", "Hello Spark", "Hello World"))//简单版-实现方式2//对RDD中的元素进行扁平映射val flatMapRDD: RDD[String] = rdd.flatMap(_.split(" "))//将RDD中的单词进行分组val groupByRDD: RDD[(String, Iterable[String])] = flatMapRDD.groupBy(word=>word)//对分组之后的数据再次进行映射val resRDD: RDD[(String, Int)] = groupByRDD.map {case (word, datas) => {(word, datas.size)}}// 关闭连接sc.stop()}}
版本3
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}/**不建议使用**/object Spark06_WordCount3 {def main(args: Array[String]): Unit = {//创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//创建RDDval rdd: RDD[(String, Int)] = sc.makeRDD(List(("Hello Scala", 2), ("Hello Spark", 3), ("Hello World", 2)))//复杂版 方式1//将原RDD中字符串以及字符串出现的次数,进行处理,形成一个新的字符串val rdd1: RDD[String] = rdd.map {case (str, count) => {(str + " ") * count}}//对RDD中的元素进行扁平映射val flatMapRDD: RDD[String] = rdd1.flatMap(_.split(" "))//将RDD中的单词进行分组val groupByRDD: RDD[(String, Iterable[String])] = flatMapRDD.groupBy(word=>word)//对分组之后的数据再次进行映射val resRDD: RDD[(String, Int)] = groupByRDD.map {case (word, datas) => {println(word +"--"+ datas.size)(word, datas.size)}}resRDD.collect()/*World--2Spark--3Scala--2Hello--7*/// 关闭连接sc.stop()}}
版本4
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}/*** Desc: 使用groupBy完成WordCount案例*/object Spark06_WordCountOriginal {def main(args: Array[String]): Unit = {//创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//复杂版 方式2val rdd: RDD[(String, Int)] = sc.makeRDD(List(("Hello Scala", 2), ("Hello Spark", 3), ("Hello World", 2)))/*先给一个元祖转成两个元祖* ("Hello Scala", 2)==>(hello,2),(Scala,2) ("Hello Spark", 3)==>(hello,3),(Spark,3)*///对RDD中的元素进行扁平映射val flatMapRDD: RDD[(String, Int)] = rdd.flatMap {// 模式匹配元祖, words是多个单词组成的字符串,count 是字符串出现的次数,case (words, count) => {words.split(" ") //对字符串进行切割,结果是字符串的数组..map(word => (word, count))//对每个单词转成元祖(单词,单词出现的次数)}}//按照单词对RDD中的元素进行分组 (Hello,CompactBuffer((Hello,2), (Hello,3), (Hello,2)))// _1的意思是当前元祖的第一个元素val groupByRDD: RDD[(String, Iterable[(String, Int)])] = flatMapRDD.groupBy(_._1)//对RDD的元素重新进行映射val resRDD: RDD[(String, Int)] = groupByRDD.map {case (word, datas) => {// _2意思是:拿到元祖第二个元素进行累加.(word, datas.map(_._2).sum)}}resRDD.collect().foreach(println)// 关闭连接sc.stop()}}

若有收获,就点个赞吧
0 人点赞
