概述
扁平化就是给整体拆分成一个一个的过程
flatMap和Scala的flatMap含义几乎是一样的.
flatMap是先做Map再做flat,flatMap要想执行的话,必须是整体,如果不是整体的话,无法拆分成个体.
作用: 类似于map,但是每一个输入元素可以被映射为 0 或多个输出元素(所以func应该返回一个序列,而不是单一元素 T => TraversableOnce[U])
def flatMapU:ClassTag:RDD[U]
flatMap作用与map操作类似,将RDD中每一个元素通过应用f函数依次转换成新的元素,并封装到RDD中,区别:在flatMap操作中,f函数的返回值是一个集合,并且会将每一个该集合中的元素拆分出来放到新的RDD中.
案例
需求: 创建一个集合,集合里面存储的还是子集合,把所有的子集合中数据取出来放入到一个大的集合中.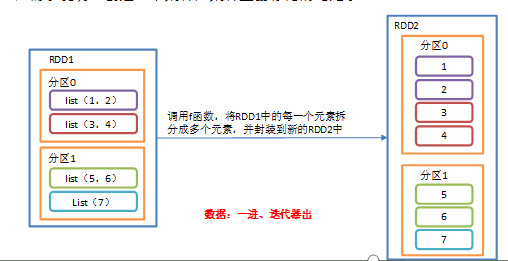
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}/**** Desc: 转换算子-faltMap* -对集合中的元素进行扁平化处理*/object demo {def main(args: Array[String]): Unit = {//创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//大集合里面放的一个个小的集合,设定默认分区数是2val rdd: RDD[List[Int]] = sc.makeRDD(List(List(1, 2), List(3, 4), List(5, 6), List(7, 8)), 2)//注意:如果匿名函数输入和输出相同,那么不能简化//datas 是整体对象// 把所有的子集合的元素取出来放到大的集合里面val newRDD: RDD[Int] = rdd.flatMap(datas => datas)//输出newRDDvar result = newRDD.collect()result.foreach(println) //原来集合里面放的是集合,现在集合里面放的都是元素,// 关闭连接sc.stop()}}
其它练习
def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("FlatMap").setMaster("local[2]")val sc: SparkContext = new SparkContext(conf)val list1 = List(30, 5, 70, 6, 1, 20)val rdd1 = sc.parallelize(list1)// 给rdd1 数据放到list集合里面val rdd2 = rdd1.flatMap(x => List(x))println(rdd2.collect().mkString(",")) //输出: 30,5,70,6,1,20// 给每个元素乘以2val rdd3 = rdd1.flatMap(x => List(x, x * 2))println(rdd3.collect().mkString(",")) //输出: 30,60,5,10,70,140,6,12,1,2,20,40// 给每个元素乘以3val rdd4 = rdd1.flatMap(x => List(x, x * 2, x * 3))println(rdd4.collect().mkString(",")) //输出: 30,60,90,5,10,15,70,140,210,6,12,18,1,2,3,20,40,60//过滤集合的值,能被整除的取出来val rdd5 = rdd1.flatMap(x => if (x % 2 == 0) List(x) else List[Int]())println(rdd5.collect().mkString(",")) //输出: 30,70,6,20sc.stop()}

若有收获,就点个赞吧
0 人点赞
