函数介绍
CONCAT(string A/col, string B/col…)
返回输入字符串连接后的结果,支持任意个输入字符串;
CONCAT_WS(separator, str1, str2,…)
它是一个特殊形式的 CONCAT()。第一个参数是指定拼接的分隔符。分隔符可以是与剩余参数一样的字符串。如果分隔符是 NULL,返回值也将为 NULL。这个函数会跳过分隔符参数后的任何 NULL 和空字符串。分隔符将被加到被连接的字符串之间;
COLLECT_SET(col)
函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生array类型字段。
collect_list : 这个函数是传递基本数据类型,产生array类型字段,不会去重复.collect_list和COLLECT_SET使用上基本一样,唯一区别就是collect_list 不去重复,COLLECT_SET去了重复.
案例:
原始数据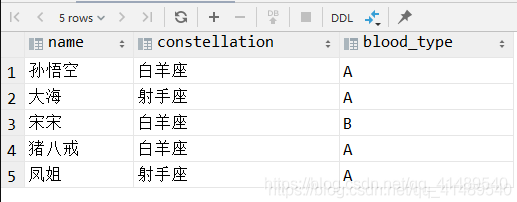
要求格式:
把星座和血型一样的人归类到一起:
射手座,A 大海|凤姐
白羊座,A 孙悟空|猪八戒
白羊座,B 宋宋
准备数据
准备 data2.txt
数据之间用 tab分隔
name constellation blood_type孙悟空 白羊座 A大海 射手座 A宋宋 白羊座 B猪八戒 白羊座 A凤姐 射手座 A
[root@zjj101 soft]# cat data2.txt孙悟空 白羊座 A大海 射手座 A宋宋 白羊座 B猪八戒 白羊座 A凤姐 射手座 A[root@zjj101 soft]# pwd/root/soft[root@zjj101 soft]#
检查是不是用分隔符分隔的
cat -T 加文件名, 因为如果不是用 tab分隔的话一会儿导入数据会导入不了
[root@zjj101 soft]# cat -T data2.txt孙悟空^I白羊座^IA大海^I射手座^IA宋宋^I白羊座^IB猪八戒^I白羊座^IA凤姐^I射手座^IA[root@zjj101 soft]#
创建hive表
sql:
create table person_info(name string,constellation string,blood_type string)row format delimited fields terminated by "\t";
导入数据
SQL:
load data local inpath"/root/soft/data2.txt" into table person_info;

写SQL思路
思路,根据星座和血型,那么就是根据这两个字段Group By一下, 前面是星座和血型,直接concat拼接一下就可以了,后面这个是相同的星座血型的人名字拼在一起.
第一列就有了
sql:
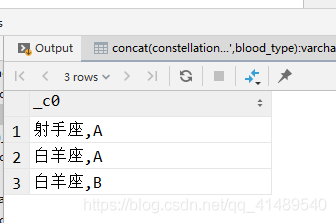
select concat(constellation,',',blood_type)from person_infogroup by constellation, blood_type;
还需要一列,那么就用星座和血型一样的拼接在一起. 这个过程就是行转列了.就需要使用CONCAT_WS函数,由于CONCAT_WS需要入参为数组,那么就需要COLLECT_SET函数了
sql:
select concat(constellation, ',', blood_type), concat_ws("|", COLLECT_SET(name))from person_infogroup by constellation, blood_type;

下面这种也能实现,但是不推荐,因为是子查询,就是两个ReduceTask了,性能不好
sql:
select t1.base,concat_ws('|', collect_set(t1.name)) namefrom (select name,concat(constellation, ",", blood_type) basefrom person_info) t1group by t1.base;

若有收获,就点个赞吧
0 人点赞
