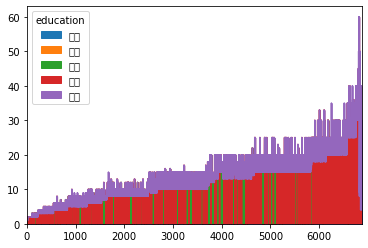
面积图,area()
df.groupby('education').apply(lambda x:x.salary).unstack().T.plot.area(stacked=True)
散点图,scatter()
#平均薪资与该薪资数量的散点图df.groupby('companyId').aggregate(['mean','count','max']).salary.plot.scatter(x='mean',y='count')
out: 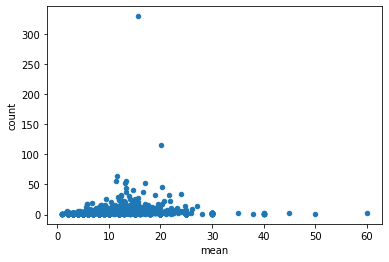
#平均薪资与最大薪资的散点图df.groupby('companyId').aggregate(['mean','count','max']).salary.plot.scatter(x='mean',y='max')
out: 
#散点图矩阵,同时绘制所有因素两两之间的散点图。该函数在pd.plotting下frame=df.groupby('companyId').aggregate(['mean','max','count']).salarypd.plotting.scatter_matrix(frame,figsize=(10,10))
out: array([[
[
[
dtype=object)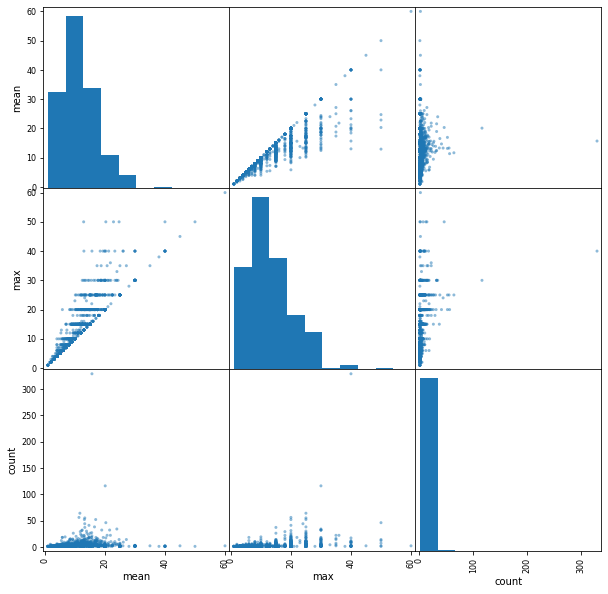
饼图,pie()
#饼图,piedf.pivot_table(values='salary',index='education',aggfunc='count').salary.plot.pie(figsize=(8,8))#注意:pie()里面的数据是Series
out: 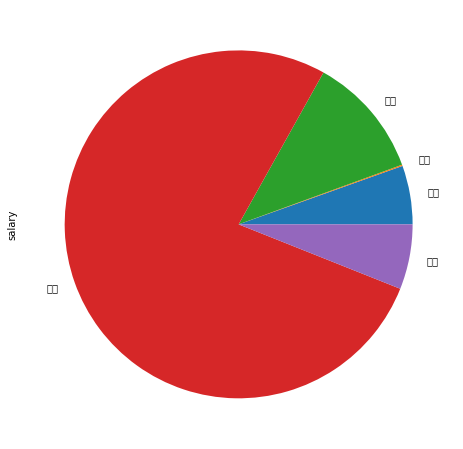

若有收获,就点个赞吧
0 人点赞
