什么是哈希表
哈希表(Hash table,散列表),是根据关键码值(Key value)而直接进行访问的数据结构。
也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。
这个映射函数叫做哈希函数,存放记录的数组叫做散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,
代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。
举个例子:统计 s=”fsgererhgerh”中字符出现次数(其中s只包含小写字母)
我们通常会使用这样的数组: int[] freq=new int[26];
这个freq就是一个哈希表
其中每一个字符都和一个索引对应:

哈希表设计思想:
- 哈希表充分体现了算法设计领域的经典思想:空间换时间。
- 哈希表是空间和时间之间的平衡
- 哈希函数的设计十分重要
- “键”通过哈希函数得到的“索引”分布越均匀越好
哈希函数的设计
哈希函数设计原则:
1.一致性:如果a==b,则hash(a)==hash(b),反之,则不成立
2.高效性:计算高效简便
3.均匀性:哈希值均匀分布
整数
- 小范围正整数:
直接使用
- 小范围负整数:
进行偏移,比如[-100,100],左右区间都+100,进行偏移,得到[0,200]
- 大整数:比如身份证号 342401199607198888
通常做法:取模
1.取后4位,相当于 mod 10000 —>获得 8888
2.取后6位,相当于mod 1000000 —> 获得 198888,但是获取的数据不可能超过32万,
因为在身份证中19为表示的是一个月的某一天,最大值是31,即所谓分布不均匀问题;
只取后6位,就没有利用所有信息。
3.解决2中的两个问题的简单解决办法:模一个素数
浮点型
浮点型在计算机中也是32位或者64位的二进制表示的,只不过是计算机解析成浮点数的,
因此,可以根据浮点数的二进制表示,转化为整数。
字符串
转换成整型处理
“163” —> 1 10^2 + 6 10^1 + 3 * 10^0
“code” —> c 26^3 + o 26^2 + d 26^1 + e 26^0
“code”也可以这样转换:
“code” —> c B^3 + o B^2 + d B^1 + e B^0
(26和B都是进制,合理选择进制即可)
因此有如下哈希函数:
hash(“code”)= (c B^3 + o B^2 + d B^1 + e B^0) % M
进一步转化:
hash(“code”)= (((c _ B + o)_B + d)*B + e) % M
(((c _ B + o)_B + d)*B + e)数据有可能过大,再进一步进行转化:
hash(“code”)= ((((c % M) B + o) % M B + d) %M * B + e) % M
对应代码如下:
int hash=0;for(int i=0;i<s.length();i++){hash=( hash * B + s.charAt(i) )%M;}
复合类型
转化成整型处理
比如:对于自定义的Date
class Date{int year;int month;int day;}
hash(date)=(((date.year % M ) B + date.month ) % M B + date.day) % M
- 注意:以上都是都是转化为整型处理,但这并不是唯一的方法。
Java中hashCode方法
- Java中hashCode函数的使用
public class Main {public static void main(String[] args) {Integer a=new Integer(3);System.out.println(a.hashCode()); //3Integer b=new Integer(-3);System.out.println(b.hashCode());//-3Double c=new Double(123.4);System.out.println(c.hashCode());//--641253373String s="abcd";System.out.println(s.hashCode());//2987074}}
- 在自定义对象中重写hashCode函数
public class Student {private int id;private double score;private String name;public Student(int id,double score,String name){this.id=id;this.score=score;this.name=name;}@Overridepublic int hashCode() {int B=26;int hash=0;hash = hash * B + id;hash = hash * B + ((Double)score).hashCode();//忽略name的大小写问题hash = hash * B + name.toLowerCase().hashCode();return hash;}}
public class Main2 {public static void main(String[] args) {Student s=new Student(1,90.0,"aaa");System.out.println(s.hashCode()); //-1999996187Student s2=new Student(1,90.0,"aaa");System.out.println(s2.hashCode());//-1999996187}}
- 重写equals()方法
- 检查是否为同一个对象的引用,如果是直接返回 true;
- 检查是否是同一个类型(判断Class对象是否相同),如果不是,直接返回 false;
- 将 Object 对象进行转型
- 判断每个关键域是否相等
@Overridepublic boolean equals(Object obj) {if(this==obj){return true;}if(obj==null || this.getClass()!=obj.getClass()){return false;}Student another=(Student)obj;return this.id==another.id &&this.score==another.score &&this.name.toLowerCase().equals(another.name.toLowerCase());}
public class Main2 {public static void main(String[] args) {Student s=new Student(1,90.0,"aaa");System.out.println(s.hashCode()); //-1999996187Student s2=new Student(1,90.0,"aaa");System.out.println(s2.hashCode());//-1999996187//s和s2的地址是不同的,但是内容是相同的System.out.println(s==s2); //falseSystem.out.println(s.equals(s2)); //true}}
- 注意:Java中每个对象默认有默认的hashCode实现。hashCode就是该对象的地址。
重写hashCode的情况:
Student s=new Student(1,90.0,"aaa");System.out.println(s.hashCode()); //-1999996187Student s2=new Student(1,90.0,"aaa");System.out.println(s2.hashCode());//-1999996187
未重写hashCode的情况:
Student s=new Student(1,90.0,"aaa");System.out.println(s.hashCode()); //21685669Student s2=new Student(1,90.0,"aaa");System.out.println(s2.hashCode());//2133927002
s和s2的hashCode不同,因为s和s2的地址不同。
哈希冲突的处理 Seperate Chaining
- 计算哈希值 (hashCode(k1) & 0x7fffffff) % M

- 采用查找表解决哈希冲突,查找表也可以使用平衡树结构
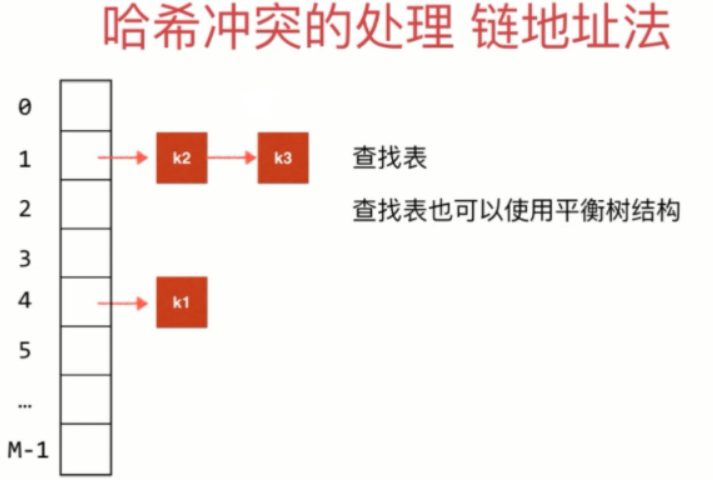
- 使用HashMap作为查找表

- 注意:
- Java 8之前,每个位置对应一个链表
- Java 8之后,当哈希冲突达到一定程度,每个位置从链表转成红黑树
哈希表编程
public class HashTable<K,V> {private TreeMap<K,V>[] hashtable;private int M;private int size;public HashTable(int M){this.M=M;this.size=0;this.hashtable=new TreeMap[M];for(int i=0;i<M;i++){hashtable[i]=new TreeMap<>();}}public HashTable(){this(97);}private int hash(K key){return (key.hashCode() & 0x7fffffff) % M;}public int getSize(){return size;}}
- 哈希表具体功能实现
public void add(K key,V value){TreeMap<K,V> map=hashtable[hash(key)];if(map.containsKey(key)){map.put(key,value);}else{map.put(key,value);size++;}}public V remove(K key){TreeMap<K,V> map=hashtable[hash(key)];V ret=null;if(map.containsKey(key)){ret=map.remove(key);size--;}return ret;}public void set(K key,V value){TreeMap<K,V> map=hashtable[hash(key)];if(!map.containsKey(key)) {throw new IllegalArgumentException(key + "does not exist!");}map.put(key,value);}public boolean contains(K key){return hashtable[hash(key)].containsKey(key);}public V get(K key){return hashtable[hash(key)].get(key);}
- 哈希表链表法时间复杂度分析
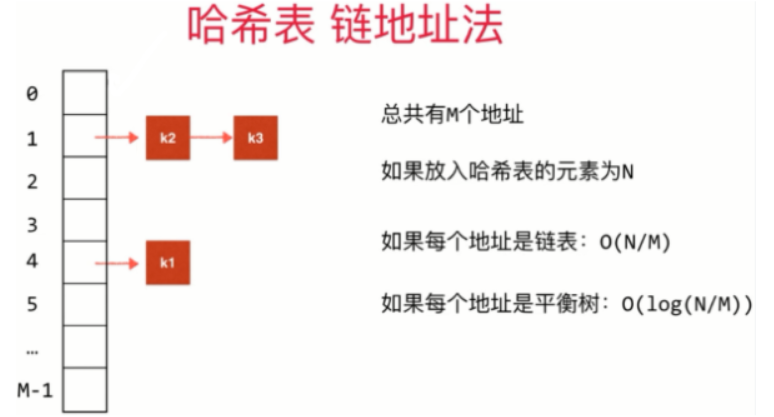
哈希表的动态空间处理

public class HashTable2<K,V> {private static final int upperTol=10;private static final int lowerTol=2;private static final int initCapacity=7;private TreeMap<K,V>[] hashtable;private int M;private int size;public HashTable2(int M){this.M=M;this.size=0;this.hashtable=new TreeMap[M];for(int i=0;i<M;i++){hashtable[i]=new TreeMap<>();}}public HashTable2(){this(initCapacity);}private int hash(K key){return (key.hashCode() & 0x7fffffff) % M;}private void resize(int newM){TreeMap<K,V>[] newHashtable=new TreeMap[newM];for(int i=0;i<newM;i++){newHashtable[i]=new TreeMap<>();}int oldM=M;this.M=newM;for(int i=0;i<oldM;i++){TreeMap<K,V> map=hashtable[i];for(K key:map.keySet()){newHashtable[hash(key)].put(key,map.get(key));}}hashtable=newHashtable;}public int getSize(){return size;}public void add(K key,V value){TreeMap<K,V> map=hashtable[hash(key)];if(map.containsKey(key)){map.put(key,value);}else{map.put(key,value);size++;if(size >= upperTol*M){resize(2*M);}}}public V remove(K key){TreeMap<K,V> map=hashtable[hash(key)];V ret=null;if(map.containsKey(key)){ret=map.remove(key);size--;if(size < lowerTol*M && M/2>=initCapacity){resize(M/2);}}return ret;}public void set(K key,V value){TreeMap<K,V> map=hashtable[hash(key)];if(!map.containsKey(key)) {throw new IllegalArgumentException(key + "does not exist!");}map.put(key,value);}public boolean contains(K key){return hashtable[hash(key)].containsKey(key);}public V get(K key){return hashtable[hash(key)].get(key);}}
- 时间复杂度分析:
平均时间复杂度:O(1)
实际上每个操作的时间复杂度是:O( log(lowerTol) ) ~ O( log(upperTol) ),而lowerTol和upperTol都是常数。
优化哈希表
public class HashTable3<K,V> {//哈希表容量的常量表private final int[] capacity = {53, 97, 193, 389, 769, 1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433, 1572869, 3145739,6291469, 12582917, 25165843, 50331653, 100663319, 201326611,402653189, 805306457, 1610612741};//int类型的最大素数就是 1610612741private static final int upperTol=10;private static final int lowerTol=2;private int capacityIndex=0;private TreeMap<K,V>[] hashtable;private int M;private int size;public HashTable3(){this.M=capacity[capacityIndex];this.size=0;this.hashtable=new TreeMap[M];for(int i=0;i<M;i++){hashtable[i]=new TreeMap<>();}}private int hash(K key){return (key.hashCode() & 0x7fffffff) % M;}private void resize(int newM){TreeMap<K,V>[] newHashtable=new TreeMap[newM];for(int i=0;i<newM;i++){newHashtable[i]=new TreeMap<>();}int oldM=M;this.M=newM;for(int i=0;i<oldM;i++){TreeMap<K,V> map=hashtable[i];for(K key:map.keySet()){newHashtable[hash(key)].put(key,map.get(key));}}hashtable=newHashtable;}public int getSize(){return size;}public void add(K key,V value){TreeMap<K,V> map=hashtable[hash(key)];if(map.containsKey(key)){map.put(key,value);}else{map.put(key,value);size++;if(size >= upperTol*M && capacityIndex+1<capacity.length){capacityIndex++;resize(capacity[capacityIndex]);}}}public V remove(K key){TreeMap<K,V> map=hashtable[hash(key)];V ret=null;if(map.containsKey(key)){ret=map.remove(key);size--;if(size < lowerTol*M && capacityIndex-1>=0){capacityIndex--;resize(capacity[capacityIndex]);}}return ret;}public void set(K key,V value){TreeMap<K,V> map=hashtable[hash(key)];if(!map.containsKey(key)) {throw new IllegalArgumentException(key + "does not exist!");}map.put(key,value);}public boolean contains(K key){return hashtable[hash(key)].containsKey(key);}public V get(K key){return hashtable[hash(key)].get(key);}}
设计的哈希表中的不足

Java 8之前,每一个位置对应一个链表,K不要求具有可比性,所以是无序的。
Java 8之后,当哈希冲突得到一定程度时,每一个位置从链表转化成红黑树,这时就要求K具有可比性。
开放地址法解决哈希冲突
1.线性探测法
每次遇到哈希冲突,就+1
2.平方探测法
遇到哈希冲突, 就+1
再次遇到哈希冲突,就+4
再次遇到哈希冲突,就+9
…
3.二次哈希
每次遇到哈希冲突,就 +hash2(key)
其他解决哈希冲突的方法:
- 再哈希法 Rehashing
- Coalesced Hashing(综合了开放地址法和链地址法)

若有收获,就点个赞吧
0 人点赞
