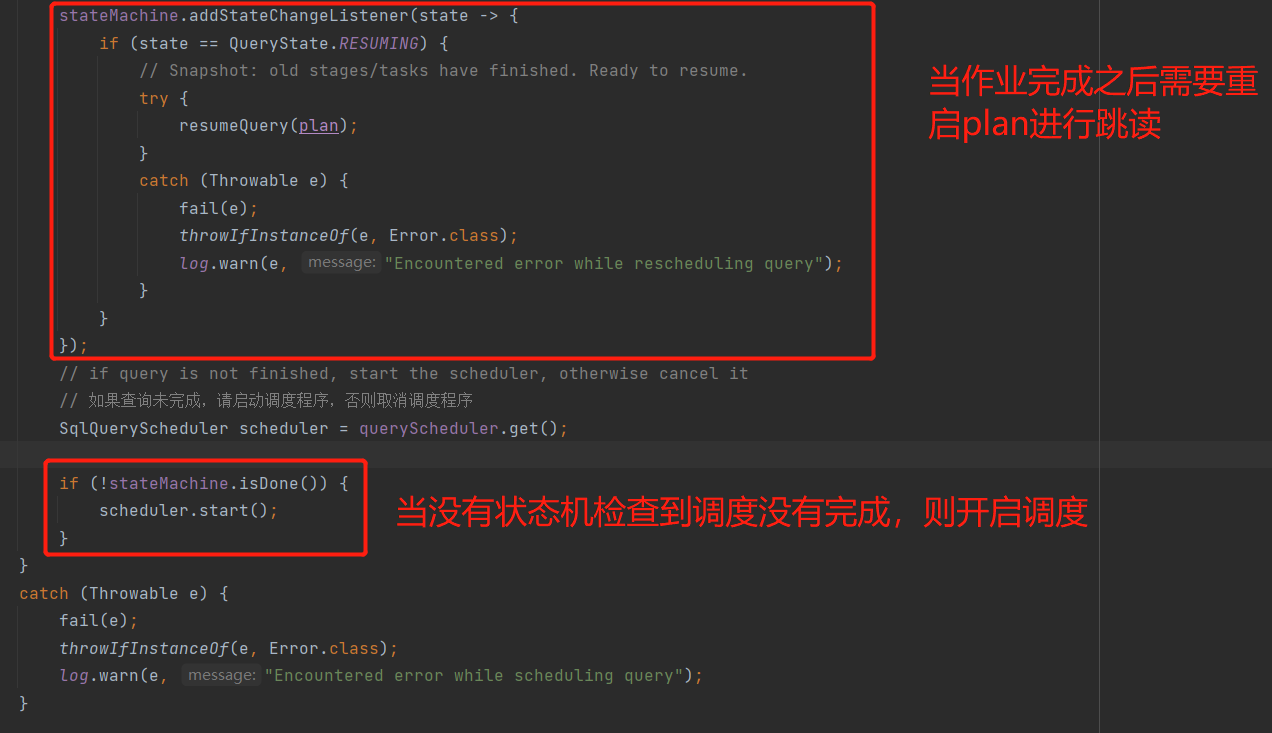
SqlQueryExecution::start方法
@Overridepublic void start(){try (SetThreadName ignored = new SetThreadName("Query-%s", stateMachine.getQueryId())) {try {// transition to planning 过渡到计划if (!stateMachine.transitionToPlanning()) {// query already started or finished// 查询已经开始或完成return;}// analyze query 根据query生成执行计划PlanRoot plan = analyzeQuery();try {// 处理跨区域动态过滤器handleCrossRegionDynamicFilter(plan);}catch (Throwable e) {// ignore any exceptionlog.warn("something unexpected happened.. cause: %s", e.getMessage());}// plan distribution of query 计划查询分布式planDistribution(plan);// transition to startingif (!stateMachine.transitionToStarting()) {// query already started or finishedreturn;}stateMachine.addStateChangeListener(state -> {if (state == QueryState.RESUMING) {// Snapshot: old stages/tasks have finished. Ready to resume.try {// 当完成分布式计划后,需要进行resumeQuery(plan);}catch (Throwable e) {fail(e);throwIfInstanceOf(e, Error.class);log.warn(e, "Encountered error while rescheduling query");}}});// if query is not finished, start the scheduler, otherwise cancel it// 如果查询未完成,请启动调度程序,否则取消调度程序SqlQueryScheduler scheduler = queryScheduler.get();if (!stateMachine.isDone()) {scheduler.start();}}catch (Throwable e) {fail(e);throwIfInstanceOf(e, Error.class);log.warn(e, "Encountered error while scheduling query");}}}
SqlQueryScheduler::start方法开始进行调度
public void start(){if (started.compareAndSet(false, true)) {executor.submit(this::schedule);}}
其实内部调用内部的schedule方法
private void schedule(){try (SetThreadName ignored = new SetThreadName("Query-%s", queryStateMachine.getQueryId())) {// 保存stageIdSet<StageId> completedStages = new HashSet<>();// 根据SqlStageExecution 属于哪个阶段的执行,执行策略创建对应的执行调度器ExecutionSchedule executionSchedule = executionPolicy.createExecutionSchedule(stages.values());// 如果while (!executionSchedule.isFinished()) {// 保存堵塞的stageList<ListenableFuture<?>> blockedStages = new ArrayList<>();//for (SqlStageExecution stage : executionSchedule.getStagesToSchedule()) {if (isReuseTableScanEnabled(session) && !SqlStageExecution.getReuseTableScanMappingIdStatus(stage.getStateMachine())) {continue;}stage.beginScheduling();// Resource group: Check if memory usage within the current resource grooup has exceeded// configured limit. If yes throttle further split scheduling.// Throttle Logic: Wait for x seconds (Wait time will increase till max as per THROTTLE_SLEEP_TIMER)// and then let it schedule 10% of splits.if (!canScheduleMoreSplits()) {try {SECONDS.sleep(THROTTLE_SLEEP_TIMER[currentTimerLevel]);}catch (InterruptedException e) {throw new PrestoException(GENERIC_INTERNAL_ERROR, "interrupted while sleeping");}currentTimerLevel = Math.min(currentTimerLevel + 1, THROTTLE_SLEEP_TIMER.length - 1);stage.setThrottledSchedule(true);}else {stage.setThrottledSchedule(false);currentTimerLevel = 0;}// perform some scheduling work 执行一些调度工作// 根据stageId获取对应的调度器进行执行,并返回调度结果ScheduleResult result = stageSchedulers.get(stage.getStageId()).schedule();// modify parent and children based on the results of the schedulingif (result.isFinished()) {stage.schedulingComplete();}else if (!result.getBlocked().isDone()) {blockedStages.add(result.getBlocked());}stageLinkages.get(stage.getStageId()).processScheduleResults(stage.getState(), result.getNewTasks());schedulerStats.getSplitsScheduledPerIteration().add(result.getSplitsScheduled());if (result.getBlockedReason().isPresent()) {switch (result.getBlockedReason().get()) {case WRITER_SCALING:// no-opbreak;case WAITING_FOR_SOURCE:schedulerStats.getWaitingForSource().update(1);break;case SPLIT_QUEUES_FULL:schedulerStats.getSplitQueuesFull().update(1);break;case MIXED_SPLIT_QUEUES_FULL_AND_WAITING_FOR_SOURCE:case NO_ACTIVE_DRIVER_GROUP:break;default:throw new UnsupportedOperationException("Unknown blocked reason: " + result.getBlockedReason().get());}}}// make sure to update stage linkage at least once per loop to catch async state changes (e.g., partial cancel)for (SqlStageExecution stage : stages.values()) {if (!completedStages.contains(stage.getStageId()) && stage.getState().isDone()) {stageLinkages.get(stage.getStageId()).processScheduleResults(stage.getState(), ImmutableSet.of());completedStages.add(stage.getStageId());}}// wait for a state change and then schedule againif (!blockedStages.isEmpty()) {try (TimeStat.BlockTimer timer = schedulerStats.getSleepTime().time()) {tryGetFutureValue(whenAnyComplete(blockedStages), 1, SECONDS);}for (ListenableFuture<?> blockedStage : blockedStages) {blockedStage.cancel(true);}}}for (SqlStageExecution stage : stages.values()) {StageState state = stage.getState();// Snapshot: if state is resumable_failure, then state of stage and query will change soon again. Don't treat as an error.if (state != SCHEDULED && state != RUNNING && !state.isDone() && state != RESUMABLE_FAILURE) {throw new PrestoException(GENERIC_INTERNAL_ERROR, format("Scheduling is complete, but stage %s is in state %s", stage.getStageId(), state));}}}catch (Throwable t) {queryStateMachine.transitionToFailed(t);throw t;}finally {RuntimeException closeError = new RuntimeException();for (StageScheduler scheduler : stageSchedulers.values()) {try {// Snapshot: when trying to reschedule, then don't close the scheduler (and more importantly, split sources in it)QueryState state = queryStateMachine.getQueryState();if (state != QueryState.RESCHEDULING && state != QueryState.RESUMING) {scheduler.close();}}catch (Throwable t) {queryStateMachine.transitionToFailed(t);// Self-suppression not permittedif (closeError != t) {closeError.addSuppressed(t);}}}// Snpashot: if resuming, notify the new scheduler so it can start scheduling new stagesschedulingFuture.set(null);if (closeError.getSuppressed().length > 0) {throw closeError;}}}

查看StageScheduler,是一个接口,实现不同阶段调度器的作用,我们以SourcePartitionedScheduler为例,schedule实现该方法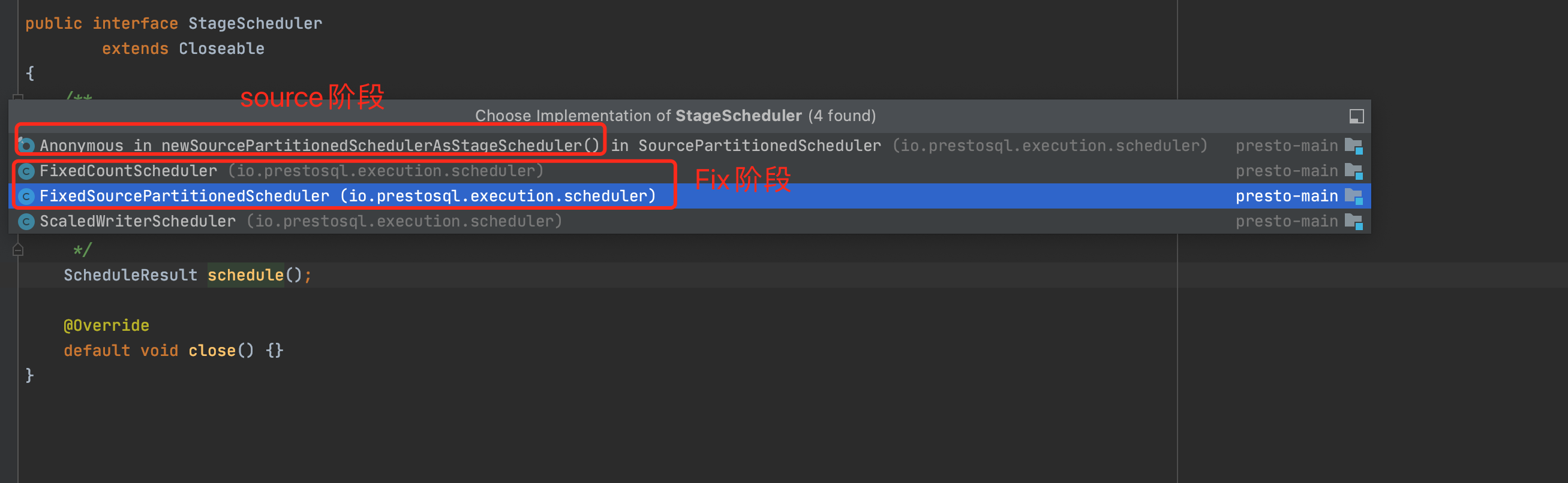
public PlanNodeId getPlanNodeId(){return partitionedNode;}/*** Obtains an instance of {@code SourcePartitionedScheduler} suitable for use as a* stage scheduler. 获取一个sourcepartitionedscheduler实例,作为一个阶段的调度器* <p>* This returns an ungrouped {@code SourcePartitionedScheduler} that requires* minimal management from the caller, which is ideal for use as a stage scheduler.* 返回一个为分组的source调度器**/public static StageScheduler newSourcePartitionedSchedulerAsStageScheduler(SqlStageExecution stage,PlanNodeId partitionedNode,SplitSource splitSource,SplitPlacementPolicy splitPlacementPolicy,int splitBatchSize,Session session,HeuristicIndexerManager heuristicIndexerManager,Map<Integer, Integer> parallelSources){// 创建源调度器,SourcePartitionedScheduler sourcePartitionedScheduler = new SourcePartitionedScheduler(stage, partitionedNode, splitSource,splitPlacementPolicy, splitBatchSize, false, session, heuristicIndexerManager,parallelSources == null ? 1 : parallelSources.getOrDefault(stage.getStageId().getId(), 1));sourcePartitionedScheduler.startLifespan(Lifespan.taskWide(), NOT_PARTITIONED);sourcePartitionedScheduler.noMoreLifespans();// 重载源schedule调度方法return new StageScheduler(){@Overridepublic ScheduleResult schedule(){ScheduleResult scheduleResult = sourcePartitionedScheduler.schedule();sourcePartitionedScheduler.drainCompletedLifespans();return scheduleResult;}@Overridepublic void close(){sourcePartitionedScheduler.close();}};}
部分代码入口,source调度器进行调度使用,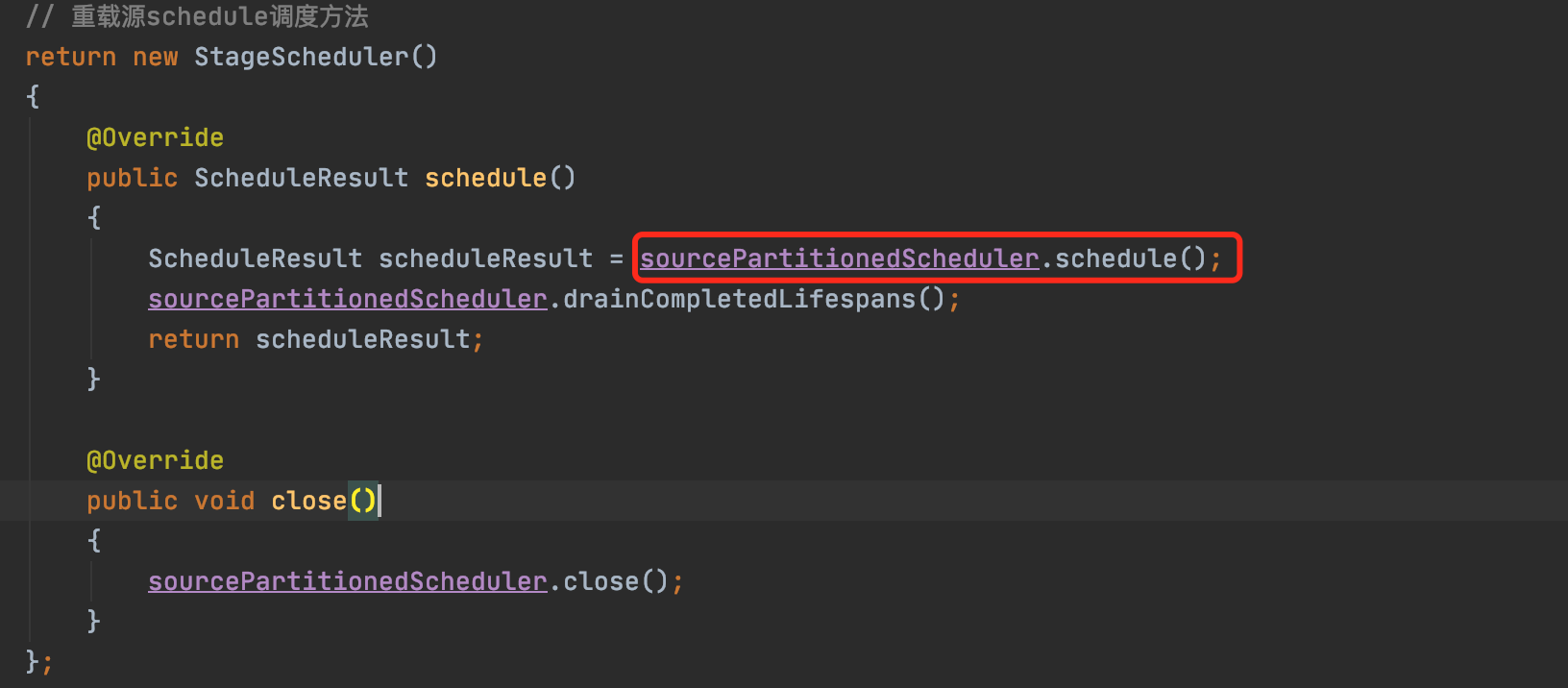
进入sourcePartitionedScheduler::schedule方法内
@Overridepublic synchronized ScheduleResult schedule(){// 遍历分组的调度器for (Entry<Lifespan, ScheduleGroup> entry : scheduleGroups.entrySet()) {// .....// 分配好split进行task的创建// assign the splits with successful placementsoverallNewTasks.addAll(assignSplits(splitAssignment, noMoreSplitsNotification));// ......}}
overallNewTasks 保存了所有的task,其中调用了assignSplits的方法,具体实现如下所示:
private Set<RemoteTask> assignSplits(Multimap<InternalNode, Split> splitAssignment, Multimap<InternalNode, Lifespan> noMoreSplitsNotification){ImmutableSet.Builder<RemoteTask> newTasks = ImmutableSet.builder();// 收集所有的节点ImmutableSet<InternalNode> nodes = ImmutableSet.<InternalNode>builder().addAll(splitAssignment.keySet()).addAll(noMoreSplitsNotification.keySet()).build();// 遍历每个nodefor (InternalNode node : nodes) {// source partitioned tasks can only receive broadcast data; otherwise it would have a different distribution// 源分区任务只能接受广播数据,否则它有一个不同的分布式ImmutableMultimap<PlanNodeId, Split> splits = ImmutableMultimap.<PlanNodeId, Split>builder().putAll(partitionedNode, splitAssignment.get(node)) // 每个节点对应的split.build();// 每个节点对应的生命周阶段ImmutableMultimap.Builder<PlanNodeId, Lifespan> noMoreSplits = ImmutableMultimap.builder();if (noMoreSplitsNotification.containsKey(node)) {noMoreSplits.putAll(partitionedNode, noMoreSplitsNotification.get(node));}// node, split, lifespan 共同创建tasknewTasks.addAll(stage.scheduleSplits(node,splits,noMoreSplits.build()));}return newTasks.build();}
进一步分析SqlStageExecution::scheduleSplits的方法
public synchronized Set<RemoteTask> scheduleSplits(InternalNode node, Multimap<PlanNodeId, Split> splits, Multimap<PlanNodeId, Lifespan> noMoreSplitsNotification){requireNonNull(node, "node is null");requireNonNull(splits, "splits is null");// 如果检测到stage的状态已完成,则返回空任务, 并将split调度表示置为trueif (stateMachine.getState().isDone()) {return ImmutableSet.of();}splitsScheduled.set(true);checkArgument(stateMachine.getFragment().getPartitionedSources().containsAll(splits.keySet()), "Invalid splits");// 创建新任务集合ImmutableSet.Builder<RemoteTask> newTasks = ImmutableSet.builder();Collection<RemoteTask> tasks = this.tasks.get(node);RemoteTask task;/*** 1。如果tasks集合中没有对应的远程任务是需要进行创建* 2。否则需要将splits添加到对应的任务中去*/if (tasks == null) {// The output buffer depends on the task id starting from 0 and being sequential, since each// task is assigned a private buffer based on task id.TaskId taskId = new TaskId(stateMachine.getStageId(), nextTaskId.getAndIncrement());task = scheduleTask(node, taskId, splits, OptionalInt.empty()); // TODO 主要用于创建任务newTasks.add(task);}else {task = tasks.iterator().next();task.addSplits(splits);}if (noMoreSplitsNotification.size() > 1) {// The assumption that `noMoreSplitsNotification.size() <= 1` currently holds.// If this assumption no longer holds, we should consider calling task.noMoreSplits with multiple entries in one shot.// These kind of methods can be expensive since they are grabbing locks and/or sending HTTP requests on change.throw new UnsupportedOperationException("This assumption no longer holds: noMoreSplitsNotification.size() < 1");}for (Entry<PlanNodeId, Lifespan> entry : noMoreSplitsNotification.entries()) {task.noMoreSplits(entry.getKey(), entry.getValue());}return newTasks.build();}
所有任务的创建都会调用到该方法:SqlStageExecution::scheduleTask
private synchronized RemoteTask scheduleTask(InternalNode node, TaskId taskId, Multimap<PlanNodeId, Split> sourceSplits, OptionalInt totalPartitions){checkArgument(!allTasks.contains(taskId), "A task with id %s already exists", taskId);// 是否开启快照功能if (SystemSessionProperties.isSnapshotEnabled(stateMachine.getSession())) {// Snapshot: inform snapshot manager so it knows about all tasks,// and can determine if a snapshot is complete for all tasks.snapshotManager.addNewTask(taskId);}ImmutableMultimap.Builder<PlanNodeId, Split> initialSplits = ImmutableMultimap.builder();initialSplits.putAll(sourceSplits);/*** 1。遍历所有源任务,查看任务状态是否为完成,如果没有完成,则需要将远程任务,并根据任务ID创建split*/sourceTasks.forEach((planNodeId, task) -> {TaskStatus status = task.getTaskStatus();if (status.getState() != TaskState.FINISHED) {initialSplits.put(planNodeId, createRemoteSplitFor(taskId, status.getSelf()));}});OutputBuffers outputBuffers = this.outputBuffers.get();checkState(outputBuffers != null, "Initial output buffers must be set before a task can be scheduled");//RemoteTask task = remoteTaskFactory.createRemoteTask(stateMachine.getSession(),taskId,node,stateMachine.getFragment(),initialSplits.build(),totalPartitions,outputBuffers,nodeTaskMap.createPartitionedSplitCountTracker(node, taskId),summarizeTaskInfo,Optional.ofNullable(parentId),snapshotManager);completeSources.forEach(task::noMoreSplits);allTasks.add(taskId);tasks.computeIfAbsent(node, key -> newConcurrentHashSet()).add(task);nodeTaskMap.addTask(node, task);task.addStateChangeListener(new StageTaskListener());task.addFinalTaskInfoListener(this::updateFinalTaskInfo);if (!stateMachine.getState().isDone()) {task.start();}else {// stage finished while we were scheduling this task// 如果stage完成了,然而我们还是调用的话,需要丢弃该任务task.abort();}return task;}
最终会调用RemoteTaskFactory::createRemoteTask的方法来执行任务的创建,HttpRemoteTaskFactory重载该方法用于创建HttpRemoteTask,具体代码实现如下:
@Overridepublic RemoteTask createRemoteTask(Session session,TaskId taskId,InternalNode node,PlanFragment fragment,Multimap<PlanNodeId, Split> initialSplits,OptionalInt totalPartitions,OutputBuffers outputBuffers,PartitionedSplitCountTracker partitionedSplitCountTracker,boolean summarizeTaskInfo,Optional<PlanNodeId> parent,QuerySnapshotManager snapshotManager){return new HttpRemoteTask(session,taskId,node.getNodeIdentifier(),locationFactory.createTaskLocation(node, taskId),fragment,initialSplits,totalPartitions,outputBuffers,httpClient,executor,updateScheduledExecutor,errorScheduledExecutor,maxErrorDuration,taskStatusRefreshMaxWait,taskInfoUpdateInterval,summarizeTaskInfo,taskStatusCodec,taskInfoCodec,taskUpdateRequestCodec,partitionedSplitCountTracker,stats,isBinaryEncoding,parent,snapshotManager);}
�HttpRemoteTask构造函数中的具体实现方式
public HttpRemoteTask(Session session,TaskId taskId,String nodeId,URI location,PlanFragment planFragment,Multimap<PlanNodeId, Split> initialSplits,OptionalInt totalPartitions,OutputBuffers outputBuffers,HttpClient httpClient,Executor executor,ScheduledExecutorService updateScheduledExecutor,ScheduledExecutorService errorScheduledExecutor,Duration maxErrorDuration,Duration taskStatusRefreshMaxWait,Duration taskInfoUpdateInterval,boolean summarizeTaskInfo,Codec<TaskStatus> taskStatusCodec,Codec<TaskInfo> taskInfoCodec,Codec<TaskUpdateRequest> taskUpdateRequestCodec,PartitionedSplitCountTracker partitionedSplitCountTracker,RemoteTaskStats stats,boolean isBinaryEncoding,Optional<PlanNodeId> parent,QuerySnapshotManager snapshotManager){requireNonNull(session, "session is null");requireNonNull(taskId, "taskId is null");requireNonNull(nodeId, "nodeId is null");requireNonNull(location, "location is null");requireNonNull(planFragment, "planFragment is null");requireNonNull(totalPartitions, "totalPartitions is null");requireNonNull(outputBuffers, "outputBuffers is null");requireNonNull(httpClient, "httpClient is null");requireNonNull(executor, "executor is null");requireNonNull(taskStatusCodec, "taskStatusCodec is null");requireNonNull(taskInfoCodec, "taskInfoCodec is null");requireNonNull(taskUpdateRequestCodec, "taskUpdateRequestCodec is null");requireNonNull(partitionedSplitCountTracker, "partitionedSplitCountTracker is null");requireNonNull(stats, "stats is null");requireNonNull(parent, "parent is null");try (SetThreadName ignored = new SetThreadName("HttpRemoteTask-%s", taskId)) {this.taskId = taskId;this.session = session;this.nodeId = nodeId;this.planFragment = planFragment;this.totalPartitions = totalPartitions;this.outputBuffers.set(outputBuffers);this.httpClient = httpClient;this.executor = executor;this.errorScheduledExecutor = errorScheduledExecutor;this.summarizeTaskInfo = summarizeTaskInfo;this.taskInfoCodec = taskInfoCodec;this.taskUpdateRequestCodec = taskUpdateRequestCodec;this.updateErrorTracker = new RequestErrorTracker(taskId, location, maxErrorDuration, errorScheduledExecutor, "updating task");this.partitionedSplitCountTracker = requireNonNull(partitionedSplitCountTracker, "partitionedSplitCountTracker is null");this.stats = stats;this.isBinaryEncoding = isBinaryEncoding;this.parent = parent;for (Entry<PlanNodeId, Split> entry : requireNonNull(initialSplits, "initialSplits is null").entries()) {ScheduledSplit scheduledSplit = new ScheduledSplit(nextSplitId.getAndIncrement(), entry.getKey(), entry.getValue());pendingSplits.put(entry.getKey(), scheduledSplit); // planNodeId --> split(splitId, plannodeId, Split)}// 统计所有split的总数pendingSourceSplitCount = planFragment.getPartitionedSources().stream().filter(initialSplits::containsKey).mapToInt(partitionedSource -> initialSplits.get(partitionedSource).size()).sum();//List<BufferInfo> bufferStates = outputBuffers.getBuffers().keySet().stream().map(outputId -> new BufferInfo(outputId, false, 0, 0, PageBufferInfo.empty())).collect(toImmutableList());TaskInfo initialTask = createInitialTask(taskId, location, nodeId, bufferStates, new TaskStats(DateTime.now(), null));this.taskStatusFetcher = new ContinuousTaskStatusFetcher(this::failTask,initialTask.getTaskStatus(),taskStatusRefreshMaxWait,taskStatusCodec,executor,httpClient,maxErrorDuration,errorScheduledExecutor,stats,isBinaryEncoding,snapshotManager);this.taskInfoFetcher = new TaskInfoFetcher(this::failTask,initialTask,httpClient,taskInfoUpdateInterval,taskInfoCodec,maxErrorDuration,summarizeTaskInfo,executor,updateScheduledExecutor,errorScheduledExecutor,stats,isBinaryEncoding);// 添加监听器, 当状态发生变化时,需要进行回调taskStatusFetcher.addStateChangeListener(newStatus -> {TaskState state = newStatus.getState();if (state.isDone()) {cleanUpTask(state);}else {partitionedSplitCountTracker.setPartitionedSplitCount(getPartitionedSplitCount());updateSplitQueueSpace();}});partitionedSplitCountTracker.setPartitionedSplitCount(getPartitionedSplitCount());updateSplitQueueSpace();}}
创建完remote task之后,继续看代码,可以看到任务执行start方法启动任务,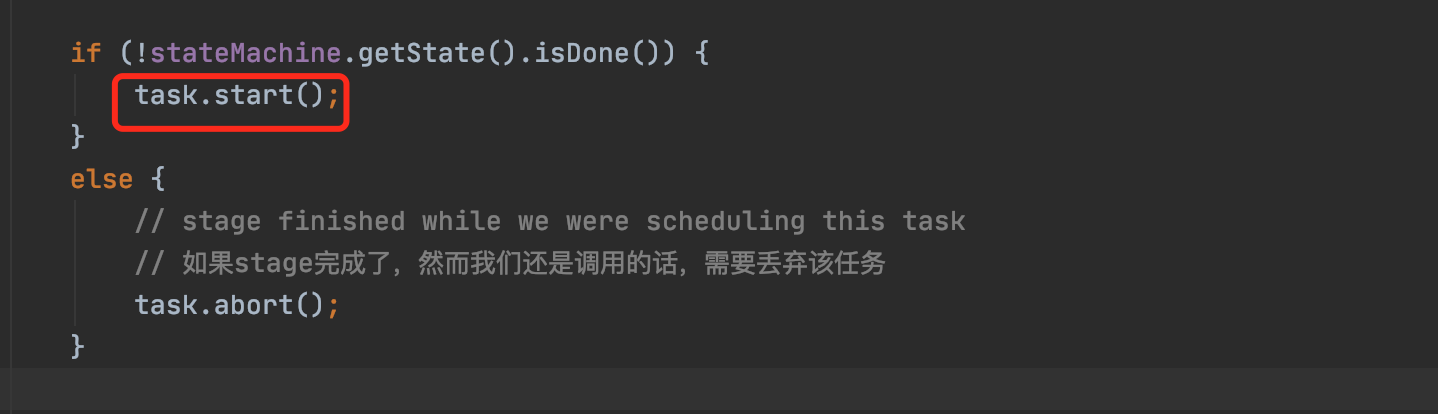
最终调用HttpRemoteTask::start方法,具体代码实现方式
@Overridepublic void start(){try (SetThreadName ignored = new SetThreadName("HttpRemoteTask-%s", taskId)) {// to start we just need to trigger an update// 启动调度任务scheduleUpdate();taskStatusFetcher.start(); // 任务状态收集器taskInfoFetcher.start(); // 任务信息收集器}}
最终会调用HttpRemoteTask::�scheduleUpdate的方法进行开始任务的调度,具体代码:
private void scheduleUpdate(){executor.execute(this::sendUpdate);}
�
private synchronized void sendUpdate(){if (abandoned.get()) {// Snapshot: Corresponding task has been canceled to resume. Stop any communication with it.// 相应任务已经取消需要重启的,需停止与他进行通信return;}TaskStatus taskStatus = getTaskStatus();// don't update if the task hasn't been started yet or if it is already finished// 如果任务未开始,或者已经结束了,不需要更新if (!needsUpdate.get() || taskStatus.getState().isDone()) {return;}// if there is a request already running, wait for it to complete// 有一个请求已经正在运行等待完成,不需要更新if (this.currentRequest != null && !this.currentRequest.isDone()) {return;}// if throttled due to error, asynchronously wait for timeout and try again// 如果误杀任务导致错误的,异步的等待超时或者重试ListenableFuture<?> errorRateLimit = updateErrorTracker.acquireRequestPermit();if (!errorRateLimit.isDone()) {errorRateLimit.addListener(this::sendUpdate, executor);return;}List<TaskSource> sources = getSources();Optional<PlanFragment> fragment = sendPlan.get() ? Optional.of(planFragment) : Optional.empty();TaskUpdateRequest updateRequest = new TaskUpdateRequest(// Snapshot: Add task instance id to all task related requests,// so receiver can verify if the instance id matchestaskStatus.getTaskInstanceId(),session.toSessionRepresentation(),session.getIdentity().getExtraCredentials(),fragment,sources,outputBuffers.get(),totalPartitions,parent);byte[] taskUpdateRequestJson = taskUpdateRequestCodec.toBytes(updateRequest);if (fragment.isPresent()) {stats.updateWithPlanBytes(taskUpdateRequestJson.length);}HttpUriBuilder uriBuilder = getHttpUriBuilder(taskStatus);Request request = setContentTypeHeaders(isBinaryEncoding, preparePost()).setUri(uriBuilder.build()).setBodyGenerator(StaticBodyGenerator.createStaticBodyGenerator(taskUpdateRequestJson))// .setBodyGenerator(createBodyGenerator(updateRequest)).build();// 是否需要进行二进制加密发送ResponseHandler responseHandler;if (isBinaryEncoding) {responseHandler = createFullSmileResponseHandler((SmileCodec<TaskInfo>) taskInfoCodec);}else {responseHandler = createAdaptingJsonResponseHandler(unwrapJsonCodec(taskInfoCodec));}updateErrorTracker.startRequest();// 开发发送ListenableFuture<BaseResponse<TaskInfo>> future = httpClient.executeAsync(request, responseHandler);currentRequest = future;currentRequestStartNanos = System.nanoTime();// The needsUpdate flag needs to be set to false BEFORE adding the Future callback since callback might change the flag value// and does so without grabbing the instance lock.needsUpdate.set(false);// 当成功结果返回后,会执行SimpleHttpResponseHandler的onSuccess, 失败会执行onFailureFutures.addCallback(future, new SimpleHttpResponseHandler<>(new UpdateResponseHandler(sources), request.getUri(), stats), executor);}

若有收获,就点个赞吧
0 人点赞
