问题导读:
1、如何使用Flink导入数据?
2、如何使用Spark导入数据?
3、如何从MySQL中导入数据?
4、如何从Hive中导入数据?
本文分享主要是ClickHouse的数据导入方式,本文主要介绍如何使用Flink、Spark、Kafka、MySQL、Hive将数据导入ClickHouse,具体内容包括:
- 使用Flink导入数据
- 使用Spark导入数据
- 从Kafka中导入数据
- 从MySQL中导入数据
- 从Hive中导入数据
使用Flink导入数据
本文介绍使用 flink-jdbc将数据导入ClickHouse,Maven依赖为:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-jdbc_${scala.binary.version}</artifactId><version>1.10.1</version></dependency>
示例
本示例使用Kafka connector,通过Flink将Kafka数据实时导入到ClickHouse
public class FlinkSinkClickHouse {public static void main(String[] args) throws Exception {String url = "jdbc:clickhouse://192.168.10.203:8123/default";String user = "default";String passwd = "hOn0d9HT";String driver = "ru.yandex.clickhouse.ClickHouseDriver";int batchsize = 500; // 设置batch size,测试的话可以设置小一点,这样可以立刻看到数据被写入// 创建执行环境EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, settings);String kafkaSource11 = "" +"CREATE TABLE user_behavior ( " +" `user_id` BIGINT, -- 用户id\n" +" `item_id` BIGINT, -- 商品id\n" +" `cat_id` BIGINT, -- 品类id\n" +" `action` STRING, -- 用户行为\n" +" `province` INT, -- 用户所在的省份\n" +" `ts` BIGINT, -- 用户行为发生的时间戳\n" +" `proctime` AS PROCTIME(), -- 通过计算列产生一个处理时间列\n" +" `eventTime` AS TO_TIMESTAMP(FROM_UNIXTIME(ts, 'yyyy-MM-dd HH:mm:ss')), -- 事件时间\n" +" WATERMARK FOR eventTime AS eventTime - INTERVAL '5' SECOND -- 在eventTime上定义watermark\n" +") WITH ( 'connector' = 'kafka', -- 使用 kafka connector\n" +" 'topic' = 'user_behavior', -- kafka主题\n" +" 'scan.startup.mode' = 'earliest-offset', -- 偏移量,从起始 offset 开始读取\n" +" 'properties.group.id' = 'group1', -- 消费者组\n" +" 'properties.bootstrap.servers' = 'kms-2:9092,kms-3:9092,kms-4:9092', -- kafka broker 地址\n" +" 'format' = 'json', -- 数据源格式为 json\n" +" 'json.fail-on-missing-field' = 'true',\n" +" 'json.ignore-parse-errors' = 'false'" +")";// Kafka SourcetEnv.executeSql(kafkaSource11);String query = "SELECT user_id,item_id,cat_id,action,province,ts FROM user_behavior";Table table = tEnv.sqlQuery(query);String insertIntoCkSql = "INSERT INTO behavior_mergetree(user_id,item_id,cat_id,action,province,ts)\n" +"VALUES(?,?,?,?,?,?)";//将数据写入 ClickHouse SinkJDBCAppendTableSink sink = JDBCAppendTableSink.builder().setDrivername(driver).setDBUrl(url).setUsername(user).setPassword(passwd).setQuery(insertIntoCkSql).setBatchSize(batchsize).setParameterTypes(Types.LONG, Types.LONG,Types.LONG, Types.STRING,Types.INT,Types.LONG).build();String[] arr = {"user_id","item_id","cat_id","action","province","ts"};TypeInformation[] type = {Types.LONG, Types.LONG,Types.LONG, Types.STRING,Types.INT,Types.LONG};tEnv.registerTableSink("sink",arr,type,sink);tEnv.insertInto(table, "sink");tEnv.execute("Flink Table API to ClickHouse Example");}}
Note:
- 由于 ClickHouse 单次插入的延迟比较高,我们需要设置 BatchSize 来批量插入数据,提高性能。
- 在 JDBCAppendTableSink 的实现中,若最后一批数据的数目不足 BatchSize,则不会插入剩余数据。
使用Spark导入数据
本文主要介绍如何通过Spark程序写入数据到Clickhouse中。
<dependency><groupId>ru.yandex.clickhouse</groupId><artifactId>clickhouse-jdbc</artifactId><version>0.2.4</version></dependency><!-- 如果报错:Caused by: java.lang.ClassNotFoundException: com.google.common.escape.Escapers,则添加下面的依赖 --><dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>28.0-jre</version></dependency>
示例
object Spark2ClickHouseExample {val properties = new Properties()properties.put("driver", "ru.yandex.clickhouse.ClickHouseDriver")properties.put("user", "default")properties.put("password", "hOn0d9HT")properties.put("batchsize", "1000")properties.put("socket_timeout", "300000")properties.put("numPartitions", "8")properties.put("rewriteBatchedStatements", "true")case class Person(name: String, age: Long)private def runDatasetCreationExample(spark: SparkSession): Dataset[Person] = {import spark.implicits._// DataFrames转成DataSetval path = "file:///e:/people.json"val peopleDS = spark.read.json(path)peopleDS.createOrReplaceTempView("people")val ds = spark.sql("SELECT name,age FROM people").as[Person]ds.show()ds}def main(args: Array[String]) {val url = "jdbc:clickhouse://kms-1:8123/default"val table = "people"val spark = SparkSession.builder().appName("Spark Example").master("local") //设置为本地运行.getOrCreate()val ds = runDatasetCreationExample(spark)ds.write.mode(SaveMode.Append).option(JDBCOptions.JDBC_BATCH_INSERT_SIZE, 100000).jdbc(url, table, properties)spark.stop()}}
从Kafka中导入数据
主要是使用ClickHouse的表引擎。
使用方式
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster](name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],...) ENGINE = Kafka()SETTINGSkafka_broker_list = 'host:port',kafka_topic_list = 'topic1,topic2,...',kafka_group_name = 'group_name',kafka_format = 'data_format'[,][kafka_row_delimiter = 'delimiter_symbol',][kafka_schema = '',][kafka_num_consumers = N,][kafka_max_block_size = 0,][kafka_skip_broken_messages = N,][kafka_commit_every_batch = 0,][kafka_thread_per_consumer = 0]kafka_broker_list :逗号分隔的brokers地址 (localhost:9092).kafka_topic_list :Kafka 主题列表,多个主题用逗号分隔.kafka_group_name :消费者组.kafka_format – Message format. 比如JSONEachRow、JSON、CSV等等
使用示例
在kafka中创建user_behavior主题,并向该主题写入数据,数据示例为:
{"user_id":63401,"item_id":6244,"cat_id":143,"action":"pv","province":3,"ts":1573445919}{"user_id":9164,"item_id":2817,"cat_id":611,"action":"fav","province":28,"ts":1573420486}{"user_id":63401,"item_id":6244,"cat_id":143,"action":"pv","province":3,"ts":1573445919}
在ClickHouse中创建表,选择表引擎为Kafka(),如下:
CREATE TABLE kafka_user_behavior (user_id UInt64 COMMENT '用户id',item_id UInt64 COMMENT '商品id',cat_id UInt16 COMMENT '品类id',action String COMMENT '行为',province UInt8 COMMENT '省份id',ts UInt64 COMMENT '时间戳') ENGINE = Kafka()SETTINGSkafka_broker_list = 'cdh04:9092',kafka_topic_list = 'user_behavior',kafka_group_name = 'group1',kafka_format = 'JSONEachRow';-- 查询cdh04 :) select * from kafka_user_behavior ;-- 再次查看数据,发现数据为空cdh04 :) select count(*) from kafka_user_behavior;SELECT count(*)FROM kafka_user_behavior┌─count()─┐│ 0 │└─────────┘
通过物化视图将kafka数据导入ClickHouse
当我们一旦查询完毕之后,ClickHouse会删除表内的数据,其实Kafka表引擎只是一个数据管道,我们可以通过物化视图的方式访问Kafka中的数据。
- 首先创建一张Kafka表引擎的表,用于从Kafka中读取数据
- 然后再创建一张普通表引擎的表,比如MergeTree,面向终端用户使用
- 最后创建物化视图,用于将Kafka引擎表实时同步到终端用户所使用的表中
-- 创建Kafka引擎表CREATE TABLE kafka_user_behavior_src (user_id UInt64 COMMENT '用户id',item_id UInt64 COMMENT '商品id',cat_id UInt16 COMMENT '品类id',action String COMMENT '行为',province UInt8 COMMENT '省份id',ts UInt64 COMMENT '时间戳') ENGINE = Kafka()SETTINGSkafka_broker_list = 'cdh04:9092',kafka_topic_list = 'user_behavior',kafka_group_name = 'group1',kafka_format = 'JSONEachRow';-- 创建一张终端用户使用的表CREATE TABLE kafka_user_behavior (user_id UInt64 COMMENT '用户id',item_id UInt64 COMMENT '商品id',cat_id UInt16 COMMENT '品类id',action String COMMENT '行为',province UInt8 COMMENT '省份id',ts UInt64 COMMENT '时间戳') ENGINE = MergeTree()ORDER BY user_id;-- 创建物化视图,同步数据CREATE MATERIALIZED VIEW user_behavior_consumer TO kafka_user_behaviorAS SELECT * FROM kafka_user_behavior_src ;-- 查询,多次查询,已经被查询的数据依然会被输出cdh04 :) select * from kafka_user_behavior;Note:Kafka消费表不能直接作为结果表使用。Kafka消费表只是用来消费Kafka数据,没有真正的存储所有数据。
从MySQL中导入数据
同kafka中导入数据类似,ClickHouse同样支持MySQL表引擎,即映射一张MySQL中的表到ClickHouse中。
数据类型对应关系
MySQL中数据类型与ClickHouse类型映射关系如下表。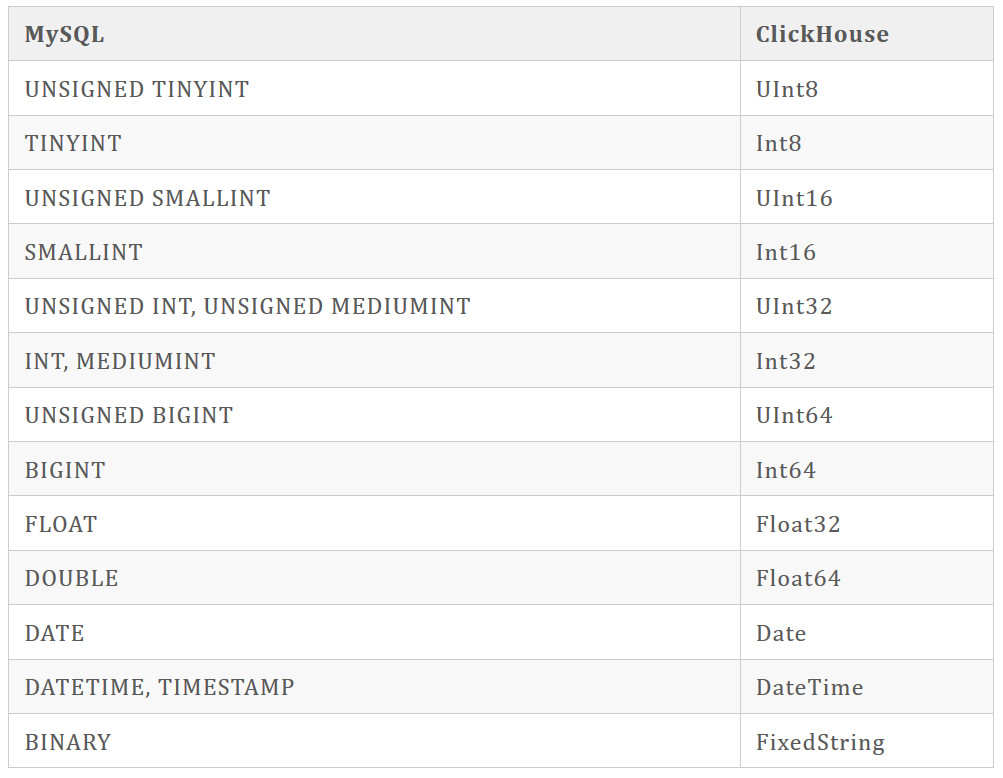
使用方式
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster](name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],...) ENGINE = MySQL('host:port', 'database', 'table', 'user', 'password'[, replace_query, 'on_duplicate_clause']);
使用示例
-- 连接MySQL中clickhouse数据库的test表CREATE TABLE mysql_users(id Int32,name String) ENGINE = MySQL('192.168.10.203:3306','clickhouse','users','root','123qwe');-- 查询数据cdh04 :) SELECT * FROM mysql_users;SELECT *FROM mysql_users┌─id─┬─name──┐│ 1 │ tom ││ 2 │ jack ││ 3 │ lihua │└────┴───────┘-- 插入数据,会将数据插入MySQL对应的表中-- 所以当查询MySQL数据时,会发现新增了一条数据INSERT INTO users VALUES(4,'robin');-- 再次查询cdh04 :) select * from mysql_users;SELECT *FROM mysql_users┌─id─┬─name──┐│ 1 │ tom ││ 2 │ jack ││ 3 │ lihua ││ 4 │ robin │└────┴───────┘
注意:对于MySQL表引擎,不支持UPDATE和DELETE操作,比如执行下面命令时,会报错:
-- 执行更新ALTER TABLE mysql_users UPDATE name = 'hanmeimei' WHERE id = 1;-- 执行删除ALTER TABLE mysql_users DELETE WHERE id = 1;-- 报错DB::Exception: Mutations are not supported by storage MySQL.
从Hive中导入数据
本文使用Waterdrop进行数据导入,Waterdrop是一个非常易用,高性能,能够应对海量数据的实时数据处理产品,它构建在Spark之上。Waterdrop拥有着非常丰富的插件,支持从Kafka、HDFS、Kudu中读取数据,进行各种各样的数据处理,并将结果写入ClickHouse、Elasticsearch或者Kafka中。
我们仅需要编写一个Waterdrop Pipeline的配置文件即可完成数据的导入。配置文件包括四个部分,分别是Spark、Input、filter和Output。
关于Waterdrop的安装,十分简单,只需要下载ZIP文件,解压即可。使用Waterdrop需要安装Spark。
在Waterdrop安装目录的config/文件夹下创建配置文件:hive_table_batch.conf,内容如下。主要包括四部分:Spark、Input、filter和Output。
- Spark部分是Spark的相关配置,主要配置Spark执行时所需的资源大小。
- Input部分是定义数据源,其中pre_sql是从Hive中读取数据SQL,table_name是将读取后的数据,注册成为Spark中临时表的表名,可为任意字段。
- filter部分配置一系列的转化,比如过滤字段
- Output部分是将处理好的结构化数据写入ClickHouse,ClickHouse的连接配置。
- 需要注意的是,必须保证hive的metastore是在服务状态。
spark {spark.app.name = "Waterdrop_Hive2ClickHouse"spark.executor.instances = 2spark.executor.cores = 1spark.executor.memory = "1g"// 这个配置必需填写spark.sql.catalogImplementation = "hive"}input {hive {pre_sql = "select * from default.users"table_name = "hive_users"}}filter {}output {clickhouse {host = "kms-1:8123"database = "default"table = "users"fields = ["id", "name"]username = "default"password = "hOn0d9HT"}}
执行任务
[kms@kms-1 waterdrop-1.5.1]$ bin/start-waterdrop.sh --config config/hive_table_batch.conf --master yarn --deploy-mode cluster
这样就会启动一个Spark作业执行数据的抽取,等执行完成之后,查看ClickHouse的数据。
总结
本文主要介绍了如何通过Flink、Spark、Kafka、MySQL以及Hive,将数据导入到ClickHouse,对每一种方式都出了详细的示例,希望对你有所帮。

若有收获,就点个赞吧
0 人点赞
