DAG 编排规划
这个例子是通过AWEL DAG编排来展示如何通过大模型来实现用户输入自然语言问题,然后查找数据库相关表(SchemaLinking)再生成对应的 SQL,最后将 SQL 执行获取到数据库中的数据,并绘制成图片,整个编排有如下几步:
- 发起 Http 请求
- 处理请求内容
- 大模型推理得到 Schema 信息
- 大模型推理得到 SQL 语句
- 查询 SQL 结果
- 绘制图片
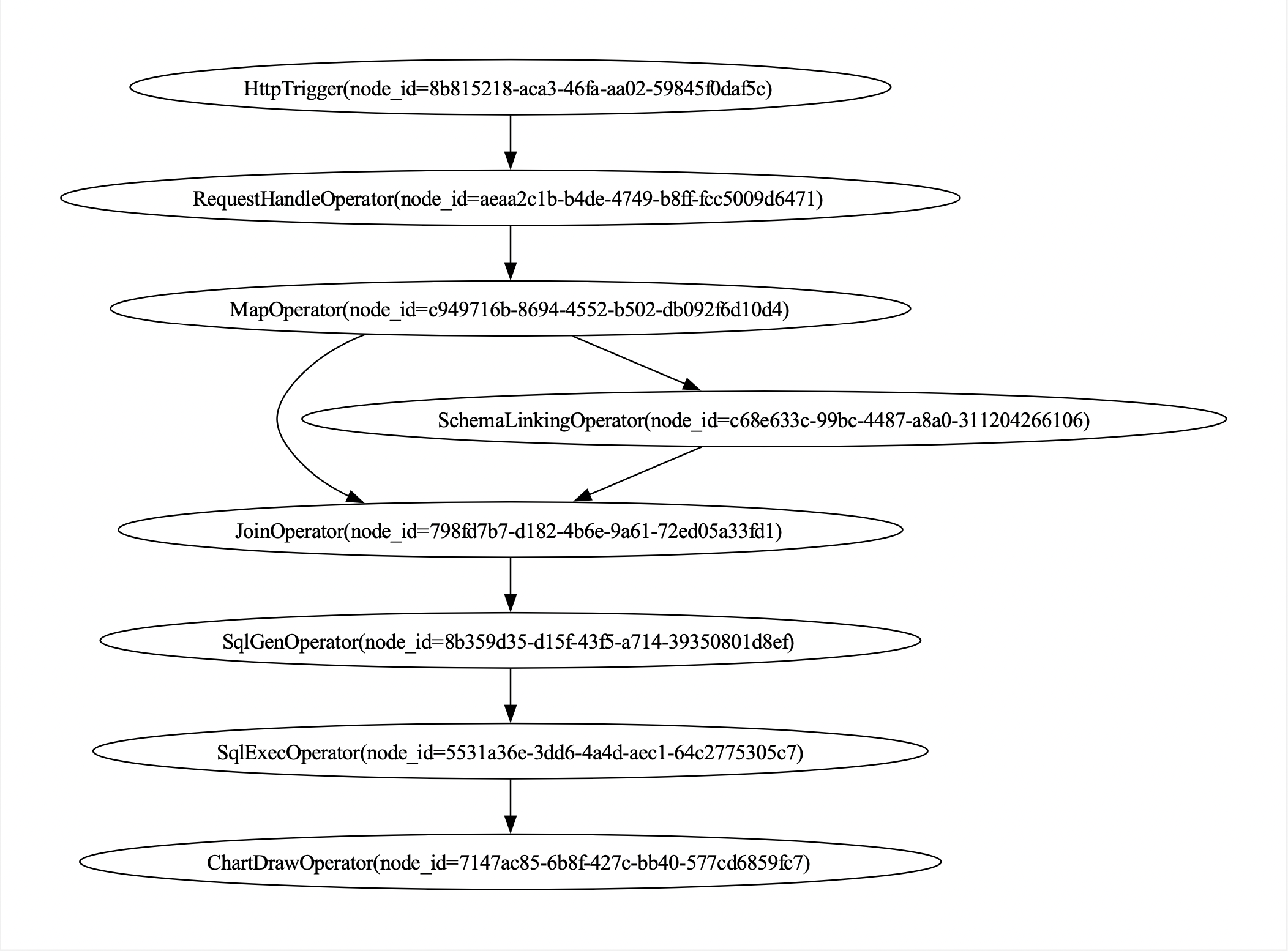
同样的,MapOperator与JoinOperator算子是DB-GPT内置算子,所以可以直接引用来使用。
import osfrom typing import Any, Dict, Optionalfrom pandas import DataFramefrom pydantic import BaseModel, Fieldfrom dbgpt.configs.model_config import MODEL_PATH, PILOT_PATHfrom dbgpt.core import LLMClient, ModelMessage, ModelMessageRoleType, ModelRequestfrom dbgpt.core.awel import DAG, HttpTrigger, JoinOperator, MapOperator
自定义算子
同样的,我们需要自定义一个处理用户请求来构造模型输入参数的算子。 首先定义用户请求参数,参数里面需要传一个内容,用户输入信息 user_query。
class TriggerReqBody(BaseModel):query: str = Field(..., description="User query")
根据请求参数来构造模型推理参数,自定义一个RequestHandleOperator的算子,此算子继承了MapOperator算子,通过重写map方法,即可实现参数的构造。
class RequestHandleOperator(MapOperator[TriggerReqBody, Dict]):def __init__(self, **kwargs):super().__init__(**kwargs)async def map(self, input_value: TriggerReqBody) -> Dict:params = {"query": input_value.query,}print(f"Receive input value: {input_value}")return params
然后通过内置的<font style="background-color:#E7E9E8;">MapOperator</font>解析得到query字符串。
query_operator = MapOperator(lambda request: request["query"])
得到query字符串后,通过自定义的SchemaLinkingOperator,重写map方法实现参数的构造,最终可以到和 query 最相关的数据表信息。具体的逻辑实现在类SchemaLinking的schema_linking_with_llm方法中。
class SchemaLinkingOperator(MapOperator[Any, Any]):"""The Schema Linking Operator."""def __init__(self,top_k: int = 5,connection: Optional[RDBMSDatabase] = None,llm: Optional[LLMClient] = None,model_name: Optional[str] = None,vector_store_connector: Optional[VectorStoreConnector] = None,**kwargs):"""Init the schema linking operatorArgs:connection (RDBMSDatabase): The connection.llm (Optional[LLMClient]): base llm"""super().__init__(**kwargs)self._schema_linking = SchemaLinking(top_k=top_k,connection=connection,llm=llm,model_name=model_name,vector_store_connector=vector_store_connector,)async def map(self, query: str) -> str:"""retrieve table schemas.Args:query (str): query.Return:str: schema info"""return str(await self._schema_linking.schema_linking_with_llm(query))
在_schema_linking_with_llm 方法中,先调用self.schema_linking方法获取数据库中所有的 表结构信息,这里使用的是 RAG中切分文档的返回格式 chunks_content,然后把 query 和得到的所有 schema 拼接为 schema_prompt,最后通过 llm生成最相关的 schema 信息。
def _schema_linking(self, query: str) -> List:"""get all db schema info"""table_summaries = _parse_db_summary(self._connection)chunks = [Chunk(content=table_summary) for table_summary in table_summaries]chunks_content = [chunk.content for chunk in chunks]return chunks_contentdef _schema_linking_with_vector_db(self, query: str) -> List:queries = [query]candidates = [self._vector_store_connector.similar_search(query, self._top_k)for query in queries]candidates = reduce(lambda x, y: x + y, candidates)return candidatesasync def _schema_linking_with_llm(self, query: str) -> List:chunks_content = self.schema_linking(query)schema_prompt = INSTRUCTION.format(str(chunks_content) + INPUT_PROMPT.format(query))messages = [ModelMessage(role=ModelMessageRoleType.SYSTEM, content=schema_prompt)]request = ModelRequest(model=self._model_name, messages=messages)tasks = [self._llm.generate(request)]# get accurate schem info by llmschema = await run_async_tasks(tasks=tasks, concurrency_limit=1)schema_text = schema[0].textreturn schema_text
得到和query字符串最相关的schema信息后,使用内置的JoinOperator算子,把query和schema拼接为 prompt。
def _prompt_join_fn(query: str, chunks: str) -> str:prompt = INSTRUCTION.format(chunks + INPUT_PROMPT.format(query))return promptprompt_join_operator = JoinOperator(combine_function=_prompt_join_fn)
得到prompt后,通过自定义的 SqlGenOperator算子,调用 llm.generate方法生成 sql
class SqlGenOperator(MapOperator[Any, Any]):"""The Sql Generation Operator."""def __init__(self, llm: Optional[LLMClient], model_name: str, **kwargs):"""Init the sql generation operatorArgs:llm (Optional[LLMClient]): base llm"""super().__init__(**kwargs)self._llm = llmself._model_name = model_nameasync def map(self, prompt_with_query_and_schema: str) -> str:"""generate sql by llm.Args:prompt_with_query_and_schema (str): promptReturn:str: sql"""messages = [ModelMessage(role=ModelMessageRoleType.SYSTEM, content=prompt_with_query_and_schema)]request = ModelRequest(model=self._model_name, messages=messages)tasks = [self._llm.generate(request)]output = await run_async_tasks(tasks=tasks, concurrency_limit=1)sql = output[0].textreturn sql
得到 sql后,通过自定义的SqlExecOperator算子,调用run_to_df函数实现执行 sql,返回从数据库中的执行结果。
class SqlExecOperator(MapOperator[Any, Any]):"""The Sql Execution Operator."""def __init__(self, connection: Optional[RDBMSDatabase] = None, **kwargs):"""Args:connection (Optional[RDBMSDatabase]): RDBMSDatabase connection"""super().__init__(**kwargs)self._connection = connectiondef map(self, sql: str) -> DataFrame:"""retrieve table schemas.Args:sql (str): query.Return:str: sql execution"""dataframe = self._connection.run_to_df(command=sql, fetch="all")print(f"sql data is \n{dataframe}")return dataframe
得到 sql查询结果后,通过自定义的 ChartDrawOperator算子,使用 matplotlib.pyplot绘制图片。
class ChartDrawOperator(MapOperator[Any, Any]):"""The Chart Draw Operator."""def __init__(self, **kwargs):"""Args:connection (RDBMSDatabase): The connection."""super().__init__(**kwargs)def map(self, df: DataFrame) -> str:"""get sql result in db and draw.Args:sql (str): str."""import matplotlib.pyplot as pltcategory_column = df.columns[0]count_column = df.columns[1]plt.figure(figsize=(8, 4))plt.bar(df[category_column], df[count_column])plt.xlabel(category_column)plt.ylabel(count_column)plt.show()return str(df)
DAG 编排
编写好算子之后,下一步即可进行算子的编排,通过AWEL DAG进行算子编排。
trigger >> request_handle_task >> query_operator >> prompt_join_operator
(
trigger
>> request_handle_task
>> query_operator
>> retriever_task
>> prompt_join_operator
)
prompt_join_operator >> sql_gen_operator >> sql_exec_operator >> draw_chart_operator
测试验证
- 安装
openai依赖:pip install "db-gpt[openai]" - 设置
openai环境变量 :export OPENAI_API_KEY={your_openai_key}和export OPENAI_API_BASE={your_openai_base} - 运行代码:
python examples/awel/simple_nl_schema_sql_chart_example.py curl测试代码:
curl --location 'http://127.0.0.1:5555/api/v1/awel/trigger/examples/rag/schema_linking' \
--header 'Content-Type: application/json' \
--data '{"query": "Statistics of user age in the user table are based on three categories: age is less than 10, age is greater than or equal to 10 and less than or equal to 20, and age is greater than 20. The first column of the statistical results is different ages, and the second column is count."}'
:::danger ⚠️注意: 测试端口跟启动端口保持一致
:::

若有收获,就点个赞吧
0 人点赞
