16.3 遍历
16.3.1 NodeIterator
接收以下4个参数:
❑ root,作为遍历根节点的节点。
❑ whatToShow,数值代码,表示应该访问哪些节点。(whatToShow参数是一个位掩码,通过应用一个或多个过滤器来指定访问哪些节点)
❑ filter, NodeFilter对象或函数,表示是否接收或跳过特定节点。
❑ entityReferenceExpansion,布尔值,表示是否扩展实体引用。这个参数在HTML文档中没有效果,因为实体引用永远不扩展。
NodeIterator的两个主要方法是nextNode()和previousNode()。
nextNode()方法在DOM子树中以深度优先方式进前一步,previousNode()则是在遍历中后退一步。
创建NodeIterator对象的时候,会有一个内部指针指向根节点,因此第一次调用nextNode()返回的是根节点。
当遍历到达DOM树最后一个节点时,nextNode()返回null。previousNode()方法也是类似的。
当遍历到达DOM树最后一个节点时,调用previousNode()返回遍历的根节点后,再次调用也会返回null。
// 要遍历<div>元素内部的所有元素let div = document.getElementById('div1');let iterator = document.createNodeIterator(div, NodeFilter.SHOW_ELEMENT, null, false);let node = iterator.nextNode();while (node !== null) {console.log(node.tagName); // 输出标签名node = iterator.nextNode();}// DIV// P// B// UL// LI(出现了3次)
// 若只想遍历<li>元素,可传入一个过滤器let div = document.getElementById('div1');let filter = function(node) {return node.tagName.toLowerCase() == 'li' ?NodeFilter.FILTER_ACCEPT :NodeFilter.FILTER_SKIP;};let iterator = document.createNodeIterator(div, NodeFilter.SHOW_ELEMENT, filter, false);let node = iterator.nextNode();while (node !== null) {console.log(node.tagName); // 输出标签名node = iterator.nextNode();}// LI 输出了3次
16.3.2 TreeWalker
TreeWalker是NodeIterator的高级版。
包含同样的nextNode()、previousNode()方法
TreeWalker还添加了如下在DOM结构中向不同方向遍历的方法:
❑ parentNode(),遍历到当前节点的父节点。
❑ firstChild(),遍历到当前节点的第一个子节点。
❑ lastChild(),遍历到当前节点的最后一个子节点。
❑ nextSibling(),遍历到当前节点的下一个同胞节点。
❑ previousSibling(),遍历到当前节点的上一个同胞节点。
TreeWalker对象要调用document.createTreeWalker()方法来创建,这个方法接收与document.createNodeIterator()同样的参数
因为两者很类似,所以TreeWalker通常可以取代NodeIterator
不同的是,节点过滤器(filter)除了可以返回NodeFilter.FILTER_ACCEPT和NodeFilter. FILTER_SKIP,还可以返回NodeFilter.FILTER_REJECT
TreeWalker真正的威力是可以在DOM结构中四处游走。如果不使用过滤器,单纯使用TreeWalker的漫游能力同样可以在DOM树中访问
let div = document.getElementById('div1');let walker = document.createTreeWalker(div, NodeFilter.SHOW_ELEMENT, null, false);walker.firstChild(); // 前往<p>walker.nextSibling(); // 前往<ul>let node = walker.firstChild(); // 前往第一个<li>while (node !== null) {console.log(node.tagName);node = walker.nextNode();}// LI 输出了3次
知道
TreeWalker类型有currentNode的属性,表示遍历过程中上一次返回的节点(无论使用的是哪个遍历方法)。
可以通过修改这个属性来影响接下来遍历的起点
let node = walker.nextNode();console.log(node === walker.currentNode); // truewalker.currentNode = document.body; // 修改为起点
相比于NodeIterator, TreeWalker类型为遍历DOM提供了更大的灵活性。
16.4 范围
范围可用于在文档中选择内容,而不用考虑节点之间的界限。(选择在后台发生,用户是看不到的。)范围在常规DOM操作的粒度不够时可以发挥作用。
16.4.1 DOM范围
DOM2在Document类型上定义了一个createRange()方法,暴露在document对象上。用这个方法可创建一个DOM范围对象
16.4.2 简单选择
selectNode()或selectNodeContents()方法
都接收一个节点作为参数,并将该节点的信息添加到调用它的范围
selectNode()方法选择整个节点,包括其后代节点,
selectNodeContents()只选择节点的后代
<html><body><p id="p1"><b>Hello</b> World!</p></body></html>
let range1 = document.createRange(),range2 = document.createRange(),p1 = document.getElementById('p1');range1.selectNode(p1);range2.selectNodeContents(p1);
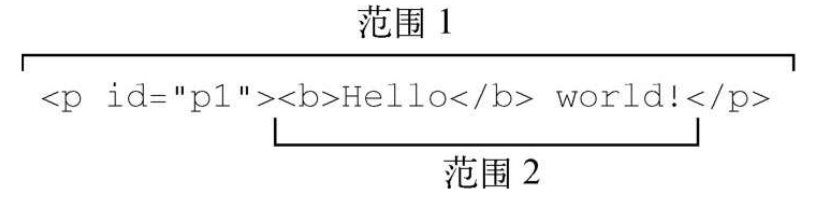
16.4.3 复杂选择
要创建复杂的范围,需使用setStart()和setEnd()方法。
都接收两个参数:参照节点和偏移量。
对setStart()来说,参照节点会成为startContainer,而偏移量会赋值给startOffset
对setEnd()而言,参照节点会成为endContainer,而偏移量会赋值给endOffset
使用这两个方法,可以模拟selectNode()和selectNodeContents()的行为
16.4.4 操作范围
创建范围之后,浏览器会在内部创建一个文档片段节点,用于包含范围选区中的节点。
为操作范围的内容,选区中的内容必须格式完好。
在前面的例子中,因为范围的起点和终点都在文本节点内部,并不是完好的DOM结构,所以无法在DOM中表示。
不过,范围能够确定缺失的开始和结束标签,从而可以重构出有效的DOM结构,以便后续操作。
操作范围的内容的方法:
deleteContents()会从文档中删除范围包含的节点
因为前面介绍的范围选择过程通过修改底层DOM结构保证了结构完好,所以即使删除范围之后,剩下的DOM结构照样是完好的。
extractContents()跟deleteContents()类似,也会从文档中移除范围选区。
不同的是,extractContents()方法返回范围对应的文档片段。
这样,就可以把范围选中的内容插入文档中其他地方
若不想把范围从文档中移除,也可使用cloneContents()创建一个副本,然后把这个副本插入到文档其他地方
这个方法跟extractContents()很相似,因为它们都返回文档片段。
主要区别是cloneContents()返回的文档片段包含范围中节点的副本,而非实际的节点。
16.4.5 范围插入
insertNode()方法可在范围选区的开始位置插入一个节点
surroundContents()方法插入包含范围的内容。
接收一个参数,即包含范围内容的节点。
调用这个方法时,后台会执行如下操作:
(1)提取出范围的内容;
(2)在原始文档中范围之前所在的位置插入给定的节点;
(3)将范围对应文档片段的内容添加到给定节点。
这种功能适合在网页中高亮显示某些关键词
16.4.6 范围折叠
如果范围并没有选择文档的任何部分,则称为折叠(collapsed)。
折叠范围有点类似文本框:如果文本框中有文本,那么可以用鼠标选中以高亮显示全部文本。这时候,如果再单击鼠标,则选区会被移除,光标会落在某两个字符中间。而在折叠范围时,位置会被设置为范围与文档交界的地方,可能是范围选区的开始处,也可能是结尾处。
折叠范围可用collapse()方法。接收一个参数:布尔值,表示折叠到范围哪一端。
true表示折叠到起点,false表示折叠到终点。
要确定范围是否已经被折叠,可检测范围的collapsed属性
16.4.7 范围比较
如果有多个范围,可用compareBoundaryPoints()方法,确定范围之间是否存在公共的边界(起点或终点)。
接收两个参数:要比较的范围和一个常量值,表示比较的方式。
16.4.8 复制范围
调用范围的cloneRange()方法可以复制范围。
这个方法会创建调用它的范围的副本
新范围包含与原始范围一样的属性,修改其边界点不会影响原始范围。
16.4.9 清理
在使用完范围之后,最好调用detach()方法,把范围从创建它的文档中剥离。
调用detach()之后,就可以放心解除对范围的引用,以便垃圾回收程序释放它所占用的内存。

若有收获,就点个赞吧
0 人点赞
