Day01
1.认识网页的结构
html+css+JavaScript
可以做一个简单页面来熟悉标签,单纯的Html+Css
课堂作业展示:
2.爬取本地网页的信息,筛选高分文章
学习如何使用BeautifulSoup解析网页
学习如何用CSS Selector 描述要爬取的元素位置
把需要的信息筛选出来,放到字典里面
pip install bs4pip install lxml
from bs4 import BeautifulSoup as BSdata = []path = '.\\web\\new_index.html'with open(path, 'r') as f:# print(f.read())Soup = BS(f.read(), 'lxml')titles = Soup.select('ul > li > div.article-info > h3 > a')pics = Soup.select('ul > li > img')descs = Soup.select('ul > li > div.article-info > p.description')rates = Soup.select('ul > li > div.rate > span')cates = Soup.select('ul > li > div.article-info > p.meta-info')print(titles + pics + descs + rates + cates)for title, pic, desc, rate, cate in zip(titles, pics, descs, rates, cates):info = {'title': title.get_text(),'pic': pic.get('src'),'descs': desc.get_text(),'rate': rate.get_text(),'cate': list(cate.stripped_strings)}data.append(info)for i in data:if len(i['rate']) >= 3:print(i['title'], i['cate'])
获取想要元素的selector,ctrl+shift+c 点击想要获取的位置,在右边的地方右键选择复制selector获取
body > div.main-content > ul > li:nth-child(1) > div.article-info > h3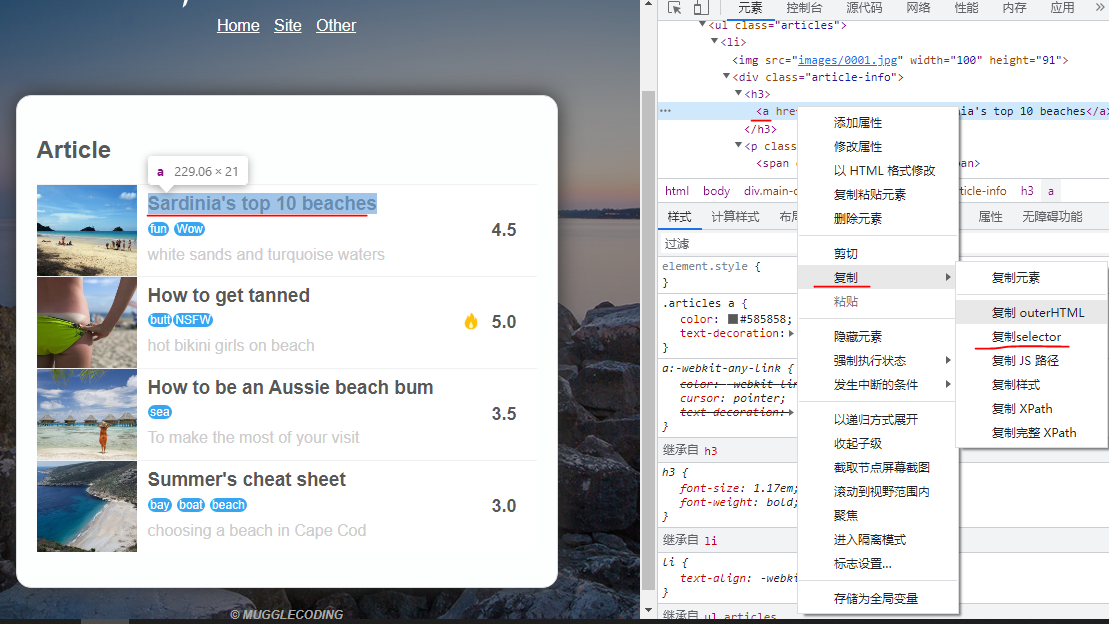
Day02
1.爬取Tripadvistor的数据
爬取选中的小标题并保存到txt中
from bs4 import BeautifulSoup as BSimport requesturl = ''headers = {'User-Agent' : '' , #当前浏览器访问url的请求数据'Cookie' : ''}web_data = request.get(url, headers = headers)#查看是否访问网站,请求成功print("访问状态码" + web_data.status_code)with open('./data.txt', 'a', encoding = 'utf-8') as file:soup = BS(web_data.txt, 'lxml')titles = soup.select('') #里面放你想筛选的网页属性selectorfor title in titles:data = {'titles' : title.get_text()}print(data)file.write(str(data) + '\n')
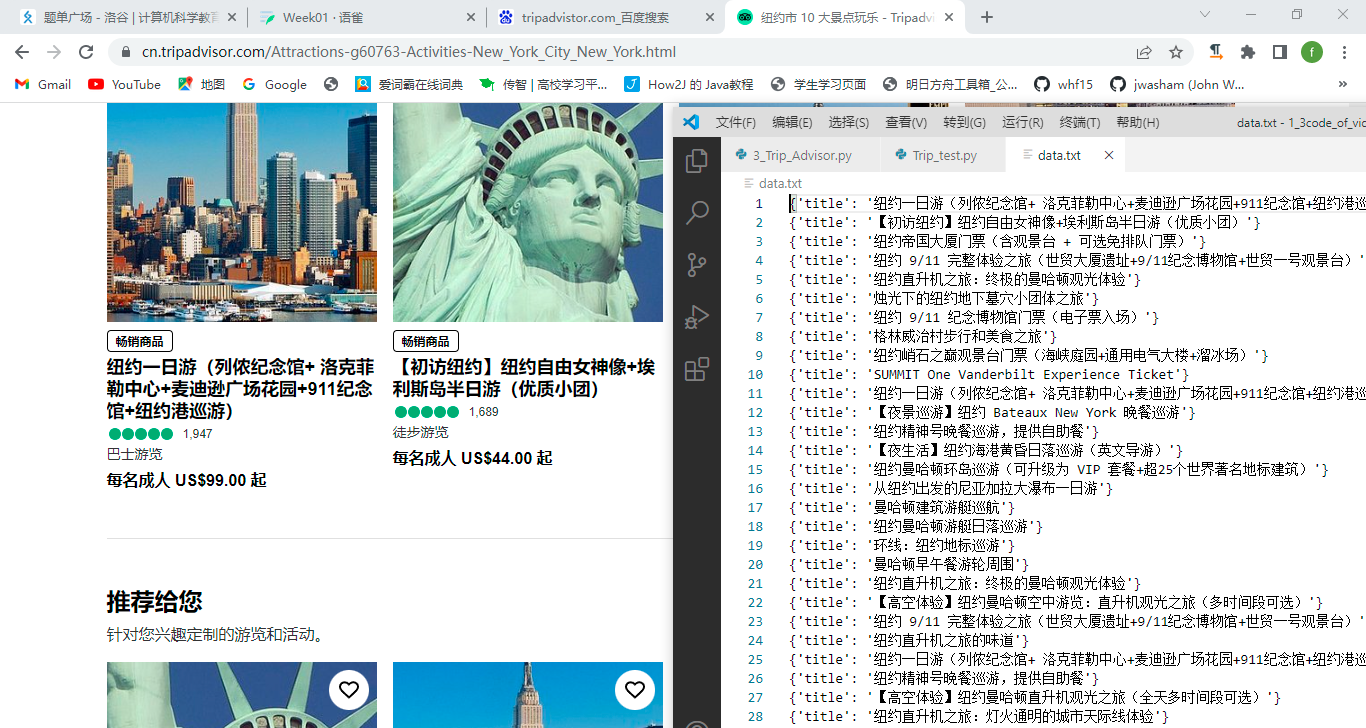
小结:
爬取一个真实的网站,TripAdvistor
理解Request和Response的原理
明白Request库的get方法怎么用
真实网页中定位元素位置的方法,找唯一特征
使用headers,如何连续爬取多页内容的方法,尝试走手机端爬取
def get_attractions(url, data=None):my_data = requests.get(url, headers=headers)print(my_data.status_code)time.sleep(3)with open('./data_cate.txt', "a", encoding='utf-8') as file:soup = BS(my_data.text, 'lxml')# titles = soup.select('div.fdltM > div.WlYyy.cPsXC.biNiR.cKUMi.dpKLb.eYhTT.cWWWn.fmARL.fPuGtitlea')titles = soup.select('div.eHyiI > span > div')cates = soup.select('article > div.eLWnh.P0 > div.IcpoT.P0 > div.bTLYC.P0 > div > div')imgs = soup.select('li.bBdQR._A.bxQEm > picture > img')for title, cate, img in zip(titles, cates, imgs):data = {'title' : title.get_text(),'cate' : list(cate.stripped_strings),'img' : img.get('src')}print(data)file.write(str(data) + '\n')get_attractions(url)for tmp_url in urls:get_attractions(tmp_url)
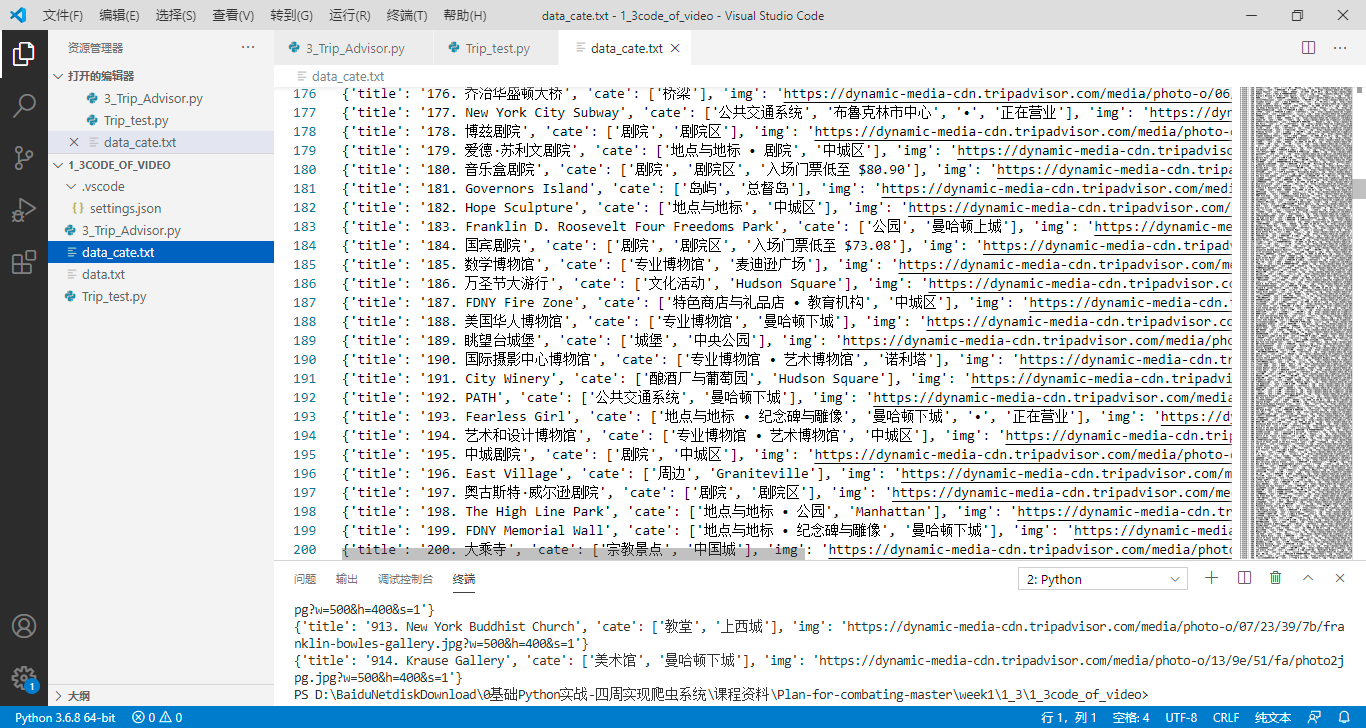
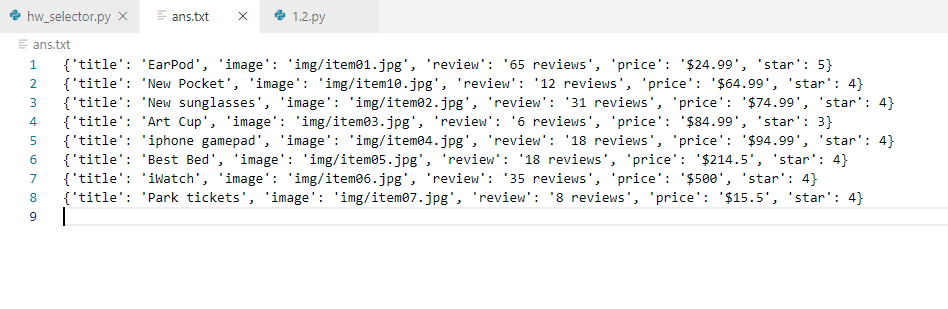
2.bootstrap的小商城单页实现

from bs4 import BeautifulSoup as BSdata = {}path = './homepage/index.html'with open(path, 'r', encoding='utf-8') as web_data:Soup = BS(web_data, 'lxml')titles = Soup.select('body > div:nth-child(2) > div > div.col-md-9 > div:nth-child(2) > div > div > div.caption > h4:nth-child(2) > a')images = Soup.select('body > div:nth-child(2) > div > div.col-md-9 > div:nth-child(2) > div > div > img')reviews = Soup.select('body > div:nth-child(2) > div > div.col-md-9 > div:nth-child(2) > div > div > div.ratings > p.pull-right')prices = Soup.select('body > div:nth-child(2) > div > div.col-md-9 > div:nth-child(2) > div > div > div.caption > h4.pull-right')stars = Soup.select('body > div:nth-child(2) > div > div.col-md-9 > div:nth-child(2) > div > div > div.ratings > p:nth-child(2)')# print(titles, images, reviews, prices, stars, sep='\n---\n')with open('ans.txt', 'a', encoding='utf-8') as ans:for title, image, review, price, star in zip(titles, images, reviews, prices, stars):data = {'title' : title.get_text(),'image' : image.get('src'),'review' : review.get_text(),'price' : price.get_text(),'star' : len(star.find_all('span', class_='glyphicon glyphicon-star'))}ans.write(str(data) + '\n')
3.爬取小猪租房得房屋信息(app反爬虫)
Day03
1.爬取weheartit网站(有反爬!)
点击网页查看源码,直接复制到本地
可以用urllib.request.urlretrieve来下载图片
def get_url(url):img_urls = []with open(full_url, 'r', encoding='utf-8') as web_data:soup = BeautifulSoup(web_data,'lxml')imgs = soup.select('#main-container > div.grid-responsive > div.col.span-content > div > div > div > div > div > a > img')for i in imgs :print(i.get('src'))img_urls.append(i.get('src'))print((len(img_urls)),'images shall be downloaded!')return img_urlsdef dl_image(url):urllib.request.urlretrieve(url,path+url.split('/')[-3] + url.split('/')[-2] + '.jpg')time.sleep(3)print('Done')
2.爬取58同城二手笔记本的数据
被封ip了好像
urlt = 'http://bj.58.com/pingbandiannao/24604629984324x.shtml'url = 'https://bj.58.com/shouji/46176488358684x.shtml'wb_data = requests.get(url, headers = headers)with open('./bj.58.com_spider/58_phone.html', 'a', encoding='utf-8') as book:book.write(wb_data.text)print('slider status:' + str(wb_data.status_code))

若有收获,就点个赞吧
0 人点赞
