Day01
1.初识mongoDo数据库
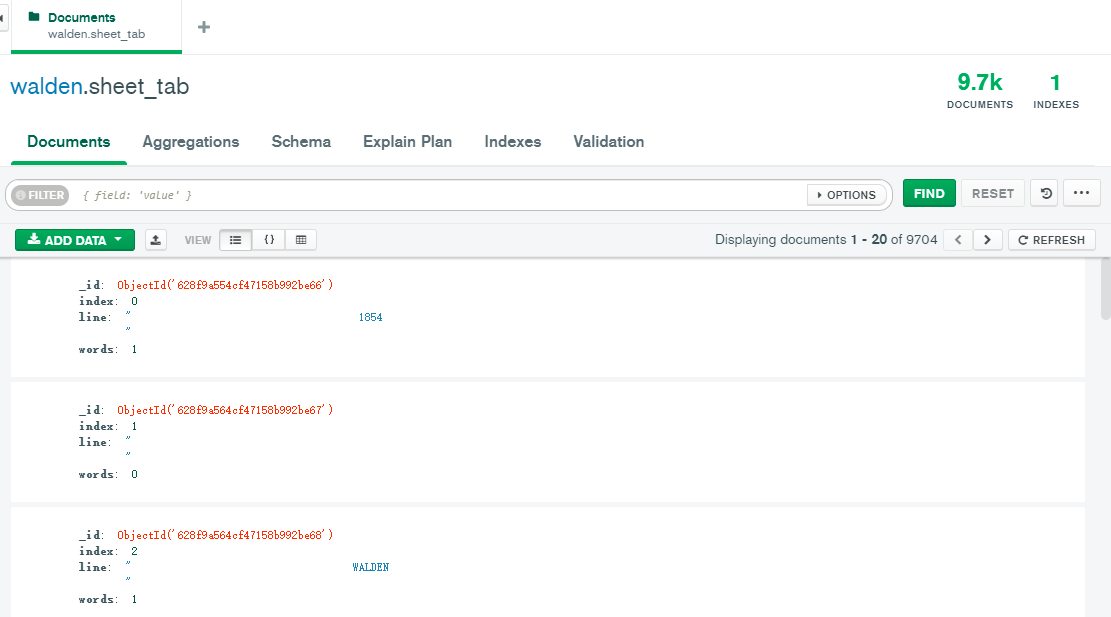
将小说的每一行都保存在mongodb中
import pymongo#将小说保存到mongodb数据库中client = pymongo.MongoClient('localhost',27017)walden = client['walden']sheet_tab = walden['sheet_tab']path = '/Users/Hou/Desktop/walden.txt'with open(path2,'r') as f:lines = f.readlines()for index,line in enumerate(lines):data = {'index':index,'line' :line,'words':len(line.split())}sheet_tab.insert_one(data)# $lt/$lte/$gt/$gte/$ne,依次等价于</<=/>/>=/!=。(l表示less g表示greater e表示equal n表示not )for item in sheet_tab.find({'words':{'$lt':5}}):print(item)
Day02
1.爬取58同城的多个页面的数据(不一定成功的)
分析流程
- 观察页面特征(不同的页面是否具有一致性)
不同页面不同规则的问题,58同城的分页问题
- 设计工作流程(确保工作能搞笑运行)
设定有两个爬虫spider1(先爬取所有的列表页,保存到url_list表中)和spider2(从表url_list中获取数据爬取详情页,将数据保存到item_info表中)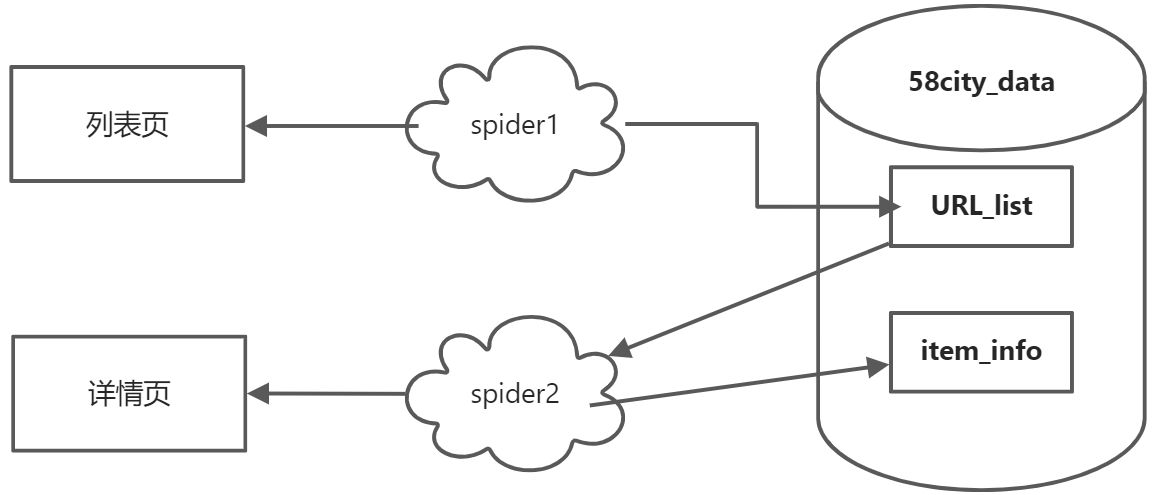
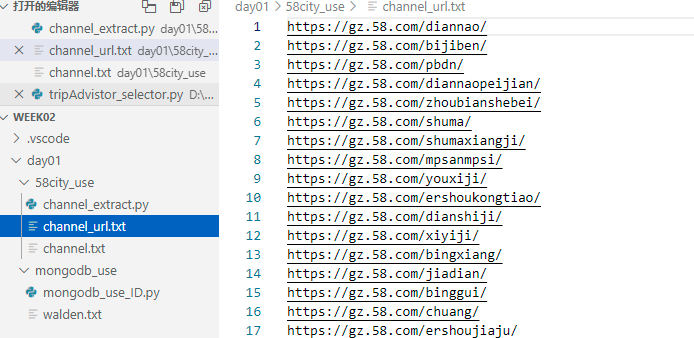
1.1 爬取58的所有分类页
from bs4 import BeautifulSoupimport requestsheaders = {'user-agent': ''}start_url = 'https://gz.58.com/sale.shtml'url_host = 'https://gz.58.com'def get_channel_url(url):wb_data = requests.get(start_url, headers = headers)#print(wb_data.text)soup = BeautifulSoup(wb_data.text, 'lxml')links = soup.select('ul.ym-submnu > li > b > a')print(links)for link in links:page_url = url_host + link.get('href')print(page_url)#ymenu-side > ul > li:nth-child(1) > ul > li:nth-child(1) > b > a# ul.ym-submnu > li > b > aget_channel_url(start_url)
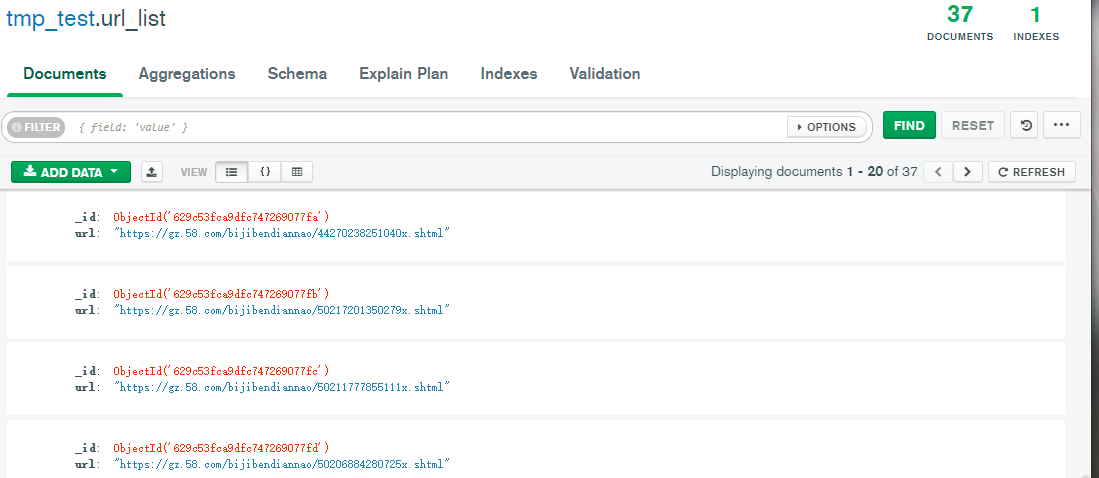
1.2 根据url解析页面(获取商家链接)
from bs4 import BeautifulSoupimport requestsimport timeimport pymongoclient = pymongo.MongoClient('localhost', 27017)tmp_58city = client['tmp_test']url_list = tmp_58city['url_list']item_info = tmp_58city['item_info']# spider 1def get_links_from(channel, pages, who_sells=0):# https://bj.58.com/bijiben/0/pn2/# 0表示个人,pn2表示第二页list_view = '{}{}/pn{}'.format(channel, str(who_sells), str(pages))#print(list_view)wb_data = requests.get(list_view, headers=headers)time.sleep(2)soup = BeautifulSoup(wb_data.text, 'lxml')# print(wb_data.text)if soup.find('td', 't'):for link in soup.select('td.t a.t'):item_link = link.get('href').split('?')[0]url_list.insert_one({'url': item_link})print(item_link)else:passdef get_item_info(url):wb_data = requests.get(url, headers = headers)soup = BeautifulSoup(wb_data_text, 'lxml')title = soup.title.textprice = soup.select('span.price.c_f50')[0].textdate = soup.select('.time')[0].textarea = list(soup.select('.c_25d a')[0].stripped_strings) if soup.find_all('span', 'c_25d') else Noneitem_info.insert_one({'title': title, 'price': price, 'date': date, 'area': area})get_links_from('https://gz.58.com/bijiben/',2)
1.3 根据商家链接爬取详细信息
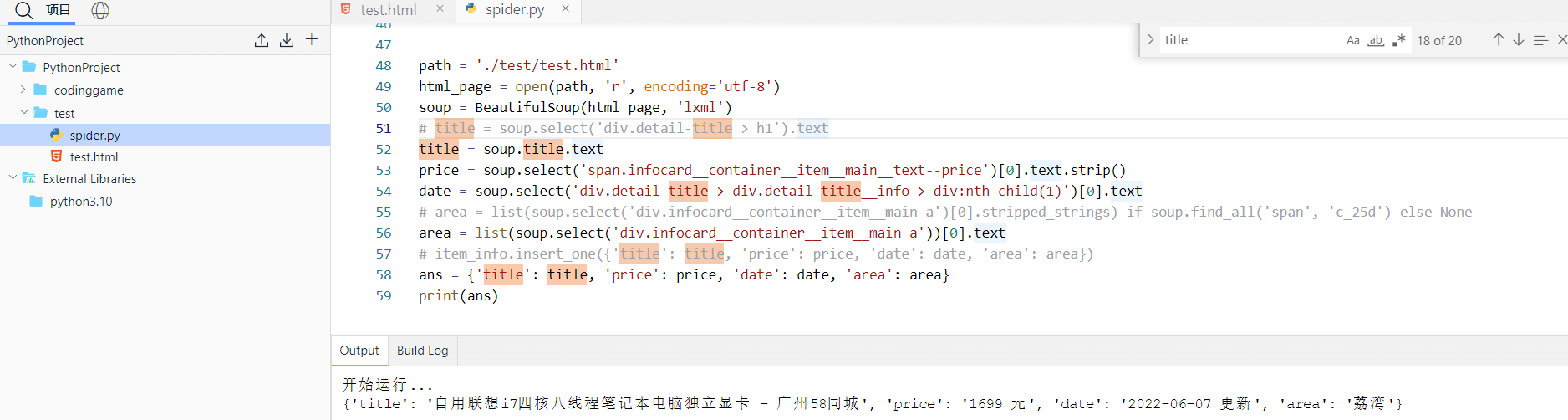
path = './test/test.html'html_page = open(path, 'r', encoding='utf-8')soup = BeautifulSoup(html_page, 'lxml')# title = soup.select('div.detail-title > h1').texttitle = soup.title.textprice = soup.select('span.infocard__container__item__main__text--price')[0].text.strip()date = soup.select('div.detail-title > div.detail-title__info > div:nth-child(1)')[0].text# area = list(soup.select('div.infocard__container__item__main a')[0].stripped_strings) if soup.find_all('span', 'c_25d') else Nonearea = list(soup.select('div.infocard__container__item__main a'))[0].text# item_info.insert_one({'title': title, 'price': price, 'date': date, 'area': area})ans = {'title': title, 'price': price, 'date': date, 'area': area}print(ans)
1.4 多进程爬虫得数据获取
创建main.py文件调用上述的几个函数
1.导入所需要的库
2.用函数填入页码
3.创建进程池
from multiprocessing import Poolfrom ahcnnel_extract import channel_listfrom page_parsing import get_links_formdef get_all_links_from(channel):for num in range(1, 101):get_links_from(channel, num)if __name__ == '__main__':pool = Pool()pool.map(get_all_links_from, channel_list.split())

若有收获,就点个赞吧
0 人点赞
