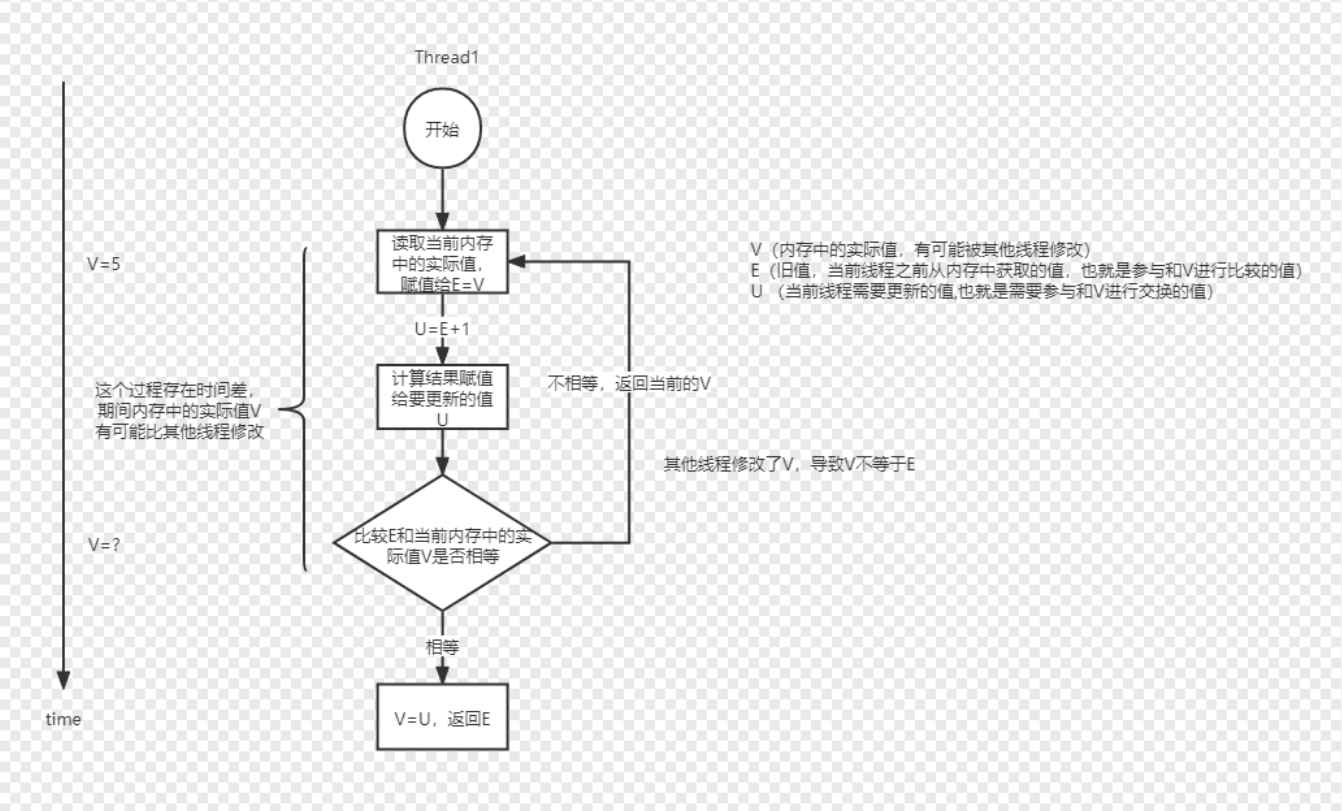
什么是CAS
CAS(Compare And Swap,比较并交换)
首先比较它的内存值与某个期望值是否相同,如果相同,就给它赋一个新值
针对一个变量
一个不可分割的原子操作,并且原子性在硬件层面得到保障的
CAS可以看做是乐观锁(对比数据库的悲观、乐观锁),Java原子类中的递增操作就通过CAS自旋实现的。
CAS是一种无锁算法,在不使用锁(没有线程被阻塞)的情况下实现多线程之间的变量同步。
CAS应用
底层Unsafe的方法 Java 虚拟机提供具体实现
public final native boolean compareAndSwapObject(Object var1, long var2, Object var4, Object var5);// 4 个参数,分别是:对象实例、内存偏移量、字段期望值、字段新值//对指定对象实例中的相应偏移量的字段执行 CAS 操作public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);public final native boolean compareAndSwapLong(Object var1, long var2, long var4, long var6);
// 示例代码public class CASTest {public static void main(String[] args) {Entity entity = new Entity();Unsafe unsafe = UnsafeFactory.getUnsafe();long offset = UnsafeFactory.getFieldOffset(unsafe, Entity.class, "x");boolean successful;// 4个参数分别是:对象实例、字段的内存偏移量、字段期望值、字段新值successful = unsafe.compareAndSwapInt(entity, offset, 0, 3);System.out.println(successful + "\t" + entity.x);successful = unsafe.compareAndSwapInt(entity, offset, 3, 5);System.out.println(successful + "\t" + entity.x);successful = unsafe.compareAndSwapInt(entity, offset, 3, 8);System.out.println(successful + "\t" + entity.x);}}public class UnsafeFactory {/*** 获取 Unsafe 对象* @return*/public static Unsafe getUnsafe() {try {Field field = Unsafe.class.getDeclaredField("theUnsafe");field.setAccessible(true);return (Unsafe) field.get(null);} catch (Exception e) {e.printStackTrace();}return null;}/*** 获取字段的内存偏移量* @param unsafe* @param clazz* @param fieldName* @return*/public static long getFieldOffset(Unsafe unsafe, Class clazz, String fieldName) {try {return unsafe.objectFieldOffset(clazz.getDeclaredField(fieldName));} catch (NoSuchFieldException e) {throw new Error(e);}}
CAS源码分析
CAS缺陷
CAS 虽然高效地解决了原子操作
- 自旋 CAS 长时间地不成功,则会给 CPU 带来非常大的开销
- 只能保证一个共享变量原子操作
- ABA 问题
ABA问题及其解决方案
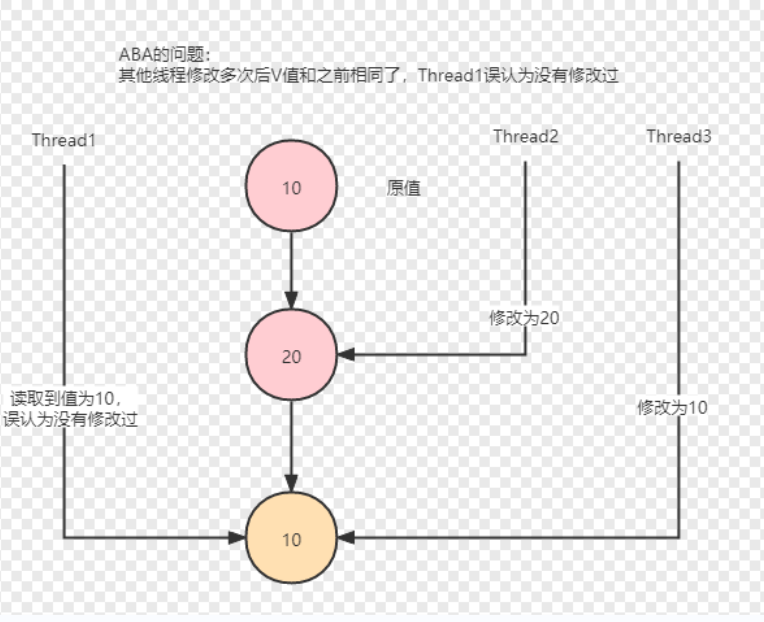
ABA问题的解决方案
引入类似版本号的字段
AtomicStampedReference
AtomicMarkableReference
public class AtomicStampedReference<V> {private static class Pair<T> {final T reference;final int stamp;//版本 每次修改可以通过+1保证版本唯一性private Pair(T reference, int stamp) {this.reference = reference;this.stamp = stamp;}static <T> Pair<T> of(T reference, int stamp) {return new Pair<T>(reference, stamp);}}private volatile Pair<V> pair;
public class AtomicMarkableReference<V> {private static class Pair<T> {final T reference;final boolean mark; //只关心是否修改过private Pair(T reference, boolean mark) {this.reference = reference;this.mark = mark;}static <T> Pair<T> of(T reference, boolean mark) {return new Pair<T>(reference, mark);}}
原子操作类
基本类型:AtomicInteger、AtomicLong、AtomicBoolean;
引用类型:AtomicReference、AtomicStampedRerence、AtomicMarkableReference;
数组类型:AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray
对象属性原子修改器:AtomicIntegerFieldUpdater、AtomicLongFieldUpdater、AtomicReferenceFieldUpdater
原子类型累加器(jdk1.8增加的类):DoubleAccumulator、DoubleAdder、LongAccumulator、LongAdder、Striped64
//以原子的方式将实例中的原值加1,返回的是自增前的旧值;public final int getAndIncrement() {return unsafe.getAndAddInt(this, valueOffset, 1);}//incrementAndGet() :以原子的方式将实例中的原值进行加1操作,并返回最终相加后的结果;public final int incrementAndGet() {return unsafe.getAndAddInt(this, valueOffset, 1) + 1;}//addAndGet(int delta) :以原子方式将输入的数值与实例中原本的值相加,并返回最后的结果;public final int addAndGet(int delta) {return unsafe.getAndAddInt(this, valueOffset, delta) + delta;}//步长 delta 加,返回当前值public final int getAndAdd(int delta) {return unsafe.getAndAddInt(this, valueOffset, delta);}//getAndSet(int newValue):将实例中的值更新为新值,并返回旧值;public final boolean getAndSet(boolean newValue) {boolean prev;do {prev = get();} while (!compareAndSet(prev, newValue));return prev;}
//底层,自旋的或许//最大的问题就是CPU的空沦陷public final int getAndAddInt(Object var1, long var2, int var4) {int var5;do {var5 = this.getIntVolatile(var1, var2);} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));return var5;}
原子更新引用类型
AtomicReference作用是对普通对象的封装,它可以保证你在修改对象引用时的线程安全性。
public final boolean compareAndSet(V expect, V update) {return unsafe.compareAndSwapObject(this, valueOffset, expect, update);}
对象属性原子修改器
AtomicIntegerFieldUpdater可以线程安全地更新对象中的整型变量。
使用的约束
(1)字段必须是volatile类型的,在线程之间共享变量时保证立即可见.eg:volatile int value = 3
(2)字段的描述类型(修饰符public/protected/default/private)与调用者与操作对象字段的关系一致。也就是说调用者能够直接操作对象字段,那么就可以反射进行原子操作。但是对于父类的字段,子类是不能直接操作的,尽管子类可以访问父类的字段。
(3)只能是实例变量,不能是类变量,也就是说不能加static关键字。
(4)只能是可修改变量,不能使final变量,因为final的语义就是不可修改。实际上final的语义和volatile是有冲突的,这两个关键字不能同时存在。
(5)对于AtomicIntegerFieldUpdater和AtomicLongFieldUpdater只能修改int/long类型的字段,不能修改其包装类型(Integer/Long)。如果要修改包装类型就需要使用AtomicReferenceFieldUpdater。
LongAdder/DoubleAdder详解
逻辑是采用自旋的方式不断更新目标值,直到更新成功。
较低并发下,自旋次数不多,但是高高并发下,会有大量的失败
LongAdder引入的初衷——解决高并发环境下AtomicInteger,AtomicLong的自旋瓶颈问题
LongAdder原理
基本思路是分散热点,把value分散到一个数组中,不同线程会命中到数据的不同槽中
各个线程只对自己槽中的值进行CAS,热点被分散,冲突概率就小了,
最终把各个槽的变量值累加返回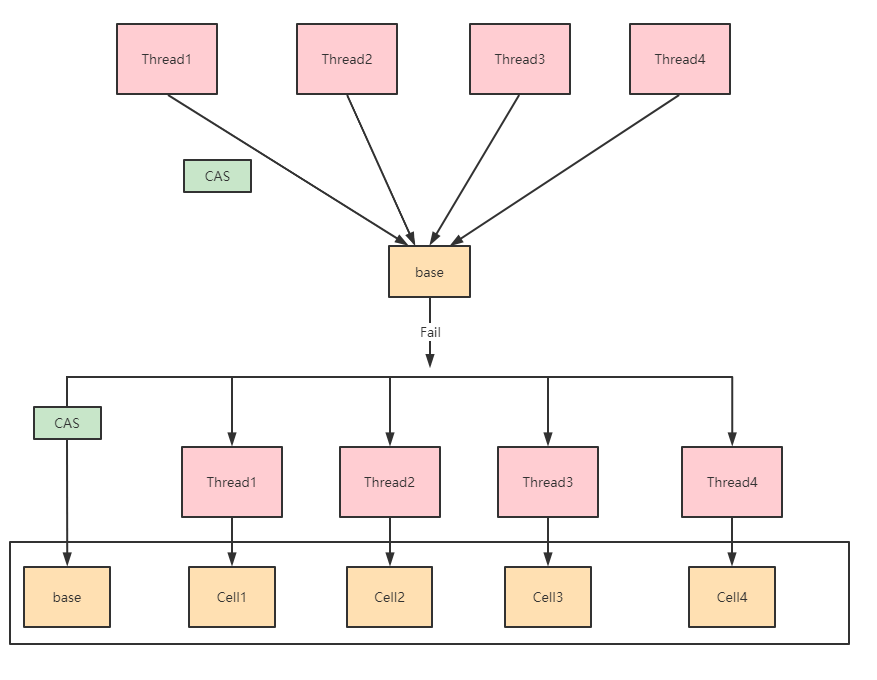
LongAdder的内部结构
LongAdder内部有一个base变量,一个Cell[]数组:
base变量:非竞态条件下,直接累加到该变量上
Cell[]数组:竞态条件下,累加个各个线程自己的槽Cell[i]中
/** Number of CPUS, to place bound on table size */// CPU核数,用来决定槽数组的大小static final int NCPU = Runtime.getRuntime().availableProcessors();/*** Table of cells. When non-null, size is a power of 2.*/// 数组槽,大小为2的次幂transient volatile Cell[] cells;/*** Base value, used mainly when there is no contention, but also as* a fallback during table initialization races. Updated via CAS.*//*** 基数,在两种情况下会使用:* 1. 没有遇到并发竞争时,直接使用base累加数值* 2. 初始化cells数组时,必须要保证cells数组只能被初始化一次(即只有一个线程能对cells初始化),* 其他竞争失败的线程会讲数值累加到base上*/transient volatile long base;/*** Spinlock (locked via CAS) used when resizing and/or creating Cells.*/
LongAdder#add方法
LongAdder#add方法的逻辑如下图: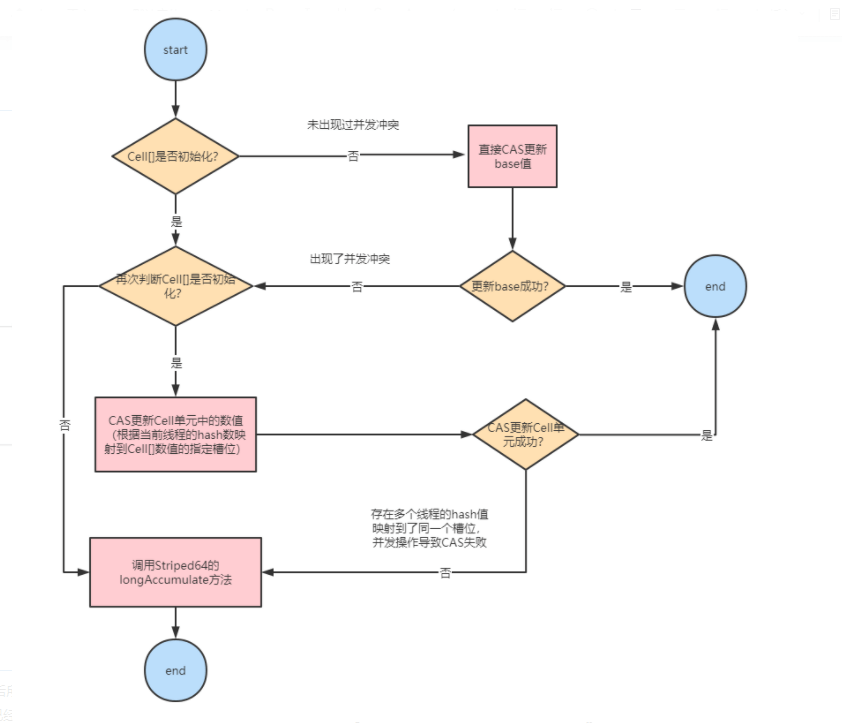
只有从未出现过并发冲突的时候,base基数才会使用到,一旦出现了并发冲突,之后所有的操作都只针对Cell[]数组中的单元Cell。
如果Cell[]数组未初始化,会调用父类的longAccumelate去初始化Cell[],如果Cell[]已经初始化但是冲突发生在Cell单元内,则也调用父类的longAccumelate,此时可能就需要对Cell[]扩容了。
这也是LongAdder设计的精妙之处:尽量减少热点冲突,不到最后万不得已,尽量将CAS操作延迟。
Striped64#longAccumulate方法
整个Striped64#longAccumulate的流程图如下: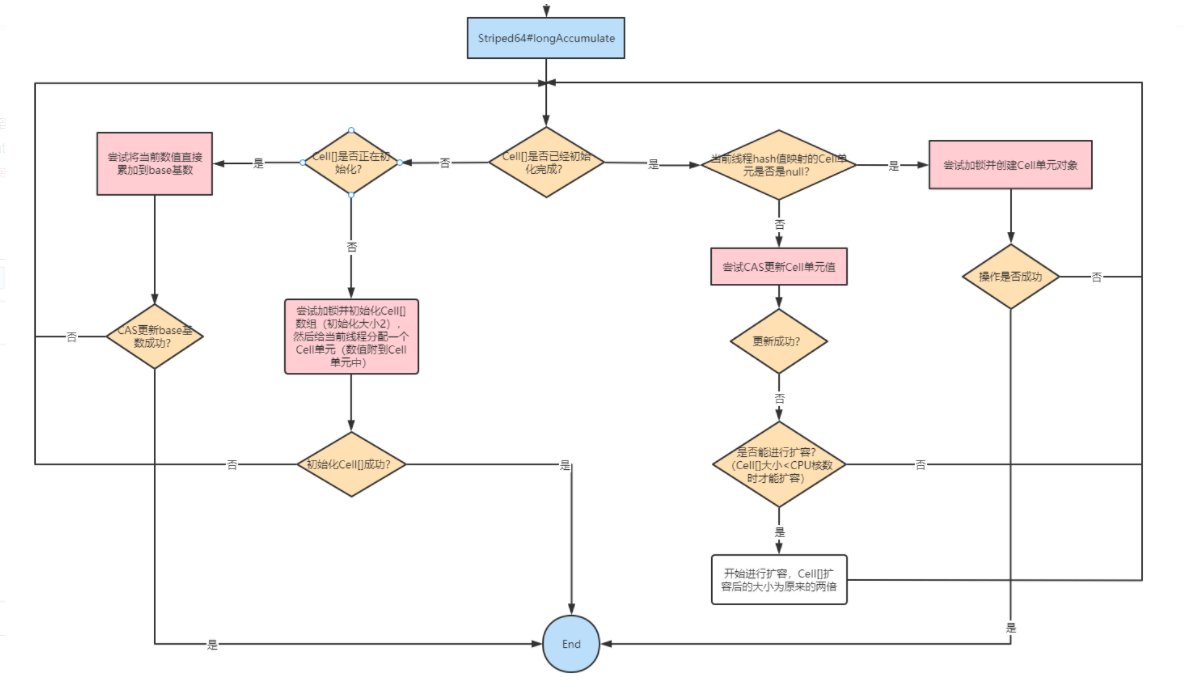
LongAdder#sum方法
/*** 返回累加的和,也就是"当前时刻"的计数值* 注意: 高并发时,除非全局加锁,否则得不到程序运行中某个时刻绝对准确的值* 此返回值可能不是绝对准确的,因为调用这个方法时还有其他线程可能正在进行计数累加,* 方法的返回时刻和调用时刻不是同一个点,在有并发的情况下,这个值只是近似准确的计数值*/public long sum() {Cell[] as = cells; Cell a;long sum = base;if (as != null) {for (int i = 0; i < as.length; ++i) {if ((a = as[i]) != null)sum += a.value;}}return sum;
LongAccumulator
LongAdder的增强版。LongAdder只能针对数值的进行加减运算,而LongAccumulator提供了自定义的函数操作。
LongAccumulator内部原理和LongAdder几乎完全一样,都是利用了父类Striped64的longAccumulate方法

若有收获,就点个赞吧
0 人点赞
