书:Python让Excel飞起来
#批量处理xlwingsimport xlwings as xw#导入xlwings模块app = xw.App(visible=True,add_book=False)#visible设置Excel程序窗口的可见性,True显示,False为隐藏;add_book启动Excel程序窗口后是否新建程序窗口,True表示创建workbook=app.books.add()#新建一个工作薄,add()为books对象的函数#保存workbook.save('F:\\python_test\\分公.xlsx')#保存路径及文件名称—绝对路径,也可以用save(r'F:\python_test\分公.xlsx'),里面r用来取消路径的反斜杠的转义功能workbook.close()#关闭工作薄app.quit()#退出Excel程序#打开工作簿import xlwings as xwapp=xw.App(visible=True,add_book=False)workbook=app.books.open(r'F:\python_test\分公.xlsx')#指定的工作薄必须存在,并不能处于打开的状态workbook#操控工作表和单元格worksheet=workbook.sheets['Sheet1']#选中工作表里名字为Sheet1worksheet.range('A1').value='编号'#在单元格输入内容worksheet=workbook.sheets.add('产品统计表')#新增一个名为产品统计表的工作表
#模式一import matha=math.sqrt(16)print(a)#模式二 直接引用函数,不用加前缀from math import sqrt #a=sqrt(16)print(a)#\n 转义字符 换行print('2021,\n 一起加油')#打印文件路径是用\\ 代替\print('F:\\python_test\分公司1.xlsx')for i in range(len(title)): #等同于range(3)print(str(i+1)+' '+'.'+title[i])from math import sqrt #导入math模块中单个函数from turtle import forwward,backward,right,left#导入turtle模块import os #E盘下文件名称path='E:\\'file_list=os.listdir(path)print(file_list)#分离文件主名和扩展名import ospath='F:\\python_test\分公司1.xlsx'separate=os.path.splitext(path)print(separate) #返回包含两个元素的元祖#os模块重命名rename(src,dst) oldname.newnameimport osoldname='F:\\python_test\\分公司1.xlsx'newname='F:\\python_test\\分公.xlsx'os.rename(oldname,newname)#rename可以修改文件路径,newname='F:\\分公.xlsx'
#Numpy数组的基础import numpy as npa=[1,2,3,4]b=np.array([1,2,3,4]) #一维数组c=a*2d=b*2print(c) #数据复制print(d) #数据*2#print(type(a)) print(type(b))#数组存储多维数据e=[[1,3],[2,6],[3,9]]f=np.array([[1,3],[2,6],[3,9]]) #二维数组print(f)print(e)#np.arange()#1个参数:起点默认为0,参数值为终点,步长为1,左闭右开#2个参数:第1个参数值起点,第2个参数值为终点,步长为1,左闭右开#3个参数:第1个参数值起点,第2个参数值为终点,第3个参数步长,左闭右开x=np.arange(5)y=np.arange(1,5)z=np.arange(1,10,5)print(x)print(y)print(z)#np.random #创建一维c=np.random.randn(3)print(c)#np.arange() 和reshape()#创建二维d=np.arange(12).reshape(3,4)print(d)#创建二维其他方式e=np.random.randint(0,10,(4,4))#np.random.randint创建随机整数,起始数,终止数,多行多列的二维数组print(e)
#第4章#案例1:批量新建并关闭工作簿、#案例2:批量打开一个文件夹下的所有工作簿import osimport xlwings as xwfile_path=f'F:/python_test'file_list=os.listdir(file_path)app=xw.App(visible=True,add_book=False)for i in file_list:if os.path.splitext(i)[1]=='.xlsx':#判断文件夹下文件的扩展是否为.xlxsapp.books.open(file_path+'/'+i)#案例3 批量重命名工作表import xlwings as xwapp=xw.App(visible=False,add_book=False)#启动excel程序workbook=app.books.open(f'F:/python_test/tt.xlsx')worksheets=workbook.sheets#获取工作薄中所有工作表for i in range(len(worksheets)):#遍历取到的工作表worksheets[i].name=worksheets[i].name.replace('销售','')#重命名工作表workbook.save(f'F:/python_test/ttt.xlsx')#另存app.quit()#案例3 批量重命名部分工作表 比如前3个sheetimport xlwings as xwapp=xw.App(visible=False,add_book=False)workbook=app.books.open(f'F:/python_test/tt.xlsx')worksheets=workbook.sheetsfor i in range(len(worksheets))[:5]:worksheets[i].name=worksheets[i].name.replace('销售','')workbook.save(f'F:/python_test/ttt2.xlsx')app.quit()#案例4 批量重命名工作薄 前提条条件名称有规律import osfile_path='F:/python_test/t'file_list=os.listdir(file_path)old_book_name='销售'new_book_name='xs'for i in file_list:if i.startswith('~$'):#判断是否有~$开头的文件continue#如有,跳过new_file=i.replace(old_book_name,new_book_name)old_file_path=os.path.join(file_path,i)new_file_path=os.path.join(file_path,new_file)os.rename(old_file_path,new_file_path)#案例4 批量多个工作薄的同名工作表import osimport xlwings as xwfile_path='F:\\python_test\\t'file_list=os.listdir(file_path)old_sheet_name='S'new_sheet_name='gzb'app=xw.App(visible=False,add_book=False)for i in file_list:if i.startswith('~$'):continueold_file_path=os.path.join(file_path,i)workbook=app.books.open(old_file_path)for j in workbook.sheets:if j.name==old_sheet_name:j.name==new_sheet_nameworkbook.save()app.quit()
#案例9 举一反三 将工作簿名称有规律的工作表合并到一个工作表import osimport xlwings as xwworkbook_name='F:\\python_test\\t\\xin.xlsx'sheet_names=[str(sheet)+'外访回款' for sheet in range (0,2)]new_sheet_name='合并'#指定合并的新工作表名称app=xw.App(visible=False,add_book=False)header=Noneall_data=[]workbook=app.books.open(workbook_name)for i in workbook.sheets:if new_sheet_name in i.name:i.delete()#如果已经存在删除new_worksheet=workbook.sheets.add(new_sheet_name)#注意缩进title_copyed=Falsefor j in workbook.sheets:if j.name in sheet_names:if title_copyed==False:j['A1'].api.EntireRow.Copy(Destination=new_worksheet['A1'].api)#将要合并的工作表列标题复制到新增工作表title.copyed=Truerow_num=new_worksheet['A1'].current_region.last_cell.row#列出新增工作表含有数据区域的最后一行j['A1'].current_region.offset(1,0).api.Copy(Destination=new_worksheet["A{}".format(row_num+1)].api)#在最后一行的下一行复制其他要合并工作表的数据,不复制标题new_worksheet.autofit()workbook.save()app.quit()Jupyter NotebookEXCEL-PY 最后检查: 25 分钟前 (未保存改变) Current Kernel LogoPython 3FileEditViewInsertCellKernelWidgetsHelpimport xlwings as xwapp=xw.App(visible=True,add_book=False)for i in range(1,21):workbook=app.books.add()workbook.save(f'F://python_test//t//销售分公司{i}.xlsx')workbook.close()app.quit()#制定文件夹生成20个Excel工作薄#三引号定义字符串 可以换行print('''2020,hello!''')2020,hello!#\n 转义字符 换行print('2021,\n 一起加油')#打印文件路径是用\\ 代替\print('F:\\python_test\分公司1.xlsx')2021,一起加油F:\python_test\分公司1.xlsxfor i in range(5):if i ==1:print('安静')else:print('加油')加油安静加油加油加油title=['标题1','标题2','标题3']print(len(title))3for i in range(len(title)): #等同于range(3)print(str(i+1)+' '+'.'+title[i])1 .标题12 .标题23 .标题3#模式一import matha=math.sqrt(16)print(a)4.0#模式二 直接引用函数,不用加前缀from math import sqrt #a=sqrt(16)print(a)4.0from math import sqrt #导入math模块中单个函数from turtle import forwward,backward,right,left#导入turtle模块import ospath=os.getcwd()print(path)C:\Users\Administratorimport os #E盘下文件名称path='E:\\'file_list=os.listdir(path)print(file_list)['$RECYCLE.BIN', 'Anaconda', 'BaiduNetdisk', 'BaiduNetdiskDownload', 'Program Files (x86)', 'System Volume Information', 'WeChat', 'write', '工作—报表', '工作报表', '蜜蜂', '记录']#分离文件主名和扩展名import ospath='F:\\python_test\分公司1.xlsx'separate=os.path.splitext(path)print(separate) #返回包含两个元素的元祖('F:\\python_test\\分公司1', '.xlsx')#os模块重命名rename(src,dst) oldname.newnameimport osoldname='F:\\python_test\\分公司1.xlsx'newname='F:\\python_test\\分公.xlsx'os.rename(oldname,newname)#rename可以修改文件路径,newname='F:\\分公.xlsx'#批量处理xlwingsimport xlwings as xw#导入xlwings模块app = xw.App(visible=True,add_book=False)#visible设置Excel程序窗口的可见性,True显示,False为隐藏;add_book启动Excel程序窗口后是否新建程序窗口,True表示创建workbook=app.books.add()#新建一个工作薄,add()为books对象的函数#保存workbook.save('F:\\python_test\\分公.xlsx')#保存路径及文件名称—绝对路径,也可以用save(r'F:\python_test\分公.xlsx'),里面r用来取消路径的反斜杠的转义功能workbook.close()#关闭工作薄app.quit()#退出Excel程序#打开工作簿import xlwings as xwapp=xw.App(visible=True,add_book=False)workbook=app.books.open(r'F:\python_test\分公.xlsx')#指定的工作薄必须存在,并不能处于打开的状态workbook<Book [分公.xlsx]>#操控工作表和单元格worksheet=workbook.sheets['Sheet1']#选中工作表里名字为Sheet1worksheet.range('A1').value='编号'#在单元格输入内容worksheet=workbook.sheets.add('产品统计表')#新增一个名为产品统计表的工作表#Numpy数组的基础import numpy as npa=[1,2,3,4]b=np.array([1,2,3,4]) #一维数组c=a*2d=b*2print(c) #数据复制print(d) #数据*2#print(type(a)) print(type(b))[1, 2, 3, 4, 1, 2, 3, 4][2 4 6 8]#数组存储多维数据e=[[1,3],[2,6],[3,9]]f=np.array([[1,3],[2,6],[3,9]]) #二维数组print(f)print(e)[[1 3][2 6][3 9]][[1, 3], [2, 6], [3, 9]]#np.arange()#1个参数:起点默认为0,参数值为终点,步长为1,左闭右开#2个参数:第1个参数值起点,第2个参数值为终点,步长为1,左闭右开#3个参数:第1个参数值起点,第2个参数值为终点,第3个参数步长,左闭右开x=np.arange(5)y=np.arange(1,5)z=np.arange(1,10,5)print(x)print(y)print(z)[0 1 2 3 4][1 2 3 4][1 6]#np.random #创建一维c=np.random.randn(3)print(c)#np.arange() 和reshape()#创建二维d=np.arange(12).reshape(3,4)print(d)#创建二维其他方式e=np.random.randint(0,10,(4,4))#np.random.randint创建随机整数,起始数,终止数,多行多列的二维数组print(e)[-0.99569137 0.41325471 -0.70682801][[ 0 1 2 3][ 4 5 6 7][ 8 9 10 11]][[1 8 5 0][6 5 9 3][8 2 9 7][7 0 2 4]]#pandas 数据导入和整理模块import pandas as pda=pd.DataFrame()#创建一个空DataFramedate=[1,3,5]score=[2,4,6]a['data']=date#注意保证date和score的长度一致,否则会报错a['score']=scoreprint(a)data score0 1 21 3 42 5 6import pandas as pddata=pd.DataFrame([[1,3],[2,6]],columns=['A','B'])data.to_excel(r'F:\python_test\test1.xlsx')data=pd.DataFrame(np.arange(1,10).reshape(3,3),index=['r1','r2','r3'],columns=['c1','c2','c3'])datac1 c2 c3r1 1 2 3r2 4 5 6r3 7 8 9#数据的选取,筛选,排序,运算和删除a=data['c1']ar1 1r2 4r3 7Name: c1, dtype: int32b=data.iloc[1:3]bc1 c2 c3r2 4 5 6r3 7 8 9b=data[1:3]bc1 c2 c3r2 4 5 6r3 7 8 9c=data.iloc[-1] ##d=data[-1]报错,-1被认为是列名cc1 7c2 8c3 9Name: r3, dtype: int32e=data.loc[['r2','r3']] #选取行ec1 c2 c3r2 4 5 6r3 7 8 9#按区块选取数据 iloc通常先取行再取列 loc方法使用字符串作为索引,iloc使用数字作为索引 无ix方法b=data.iloc[0:2][['c1','c2']]c=data.loc[['r1','r2']][['c1','c2']]cc1 c2r1 1 2r2 4 5#筛选a=data[data['c1']>1]b=data[(data['c1']>1)&(data['c2']==5)]#多个条件筛选需用用&,并且需要用小括号筛选条件括起来c=data[(data['c1']<5)|(data['c2']==5)]ac1 c2 c3r2 4 5 6r3 7 8 9bc1 c2 c3r2 4 5 6cc1 c2 c3r1 1 2 3r2 4 5 6#数据的排序sort_valuesa=data.sort_values(by='c2',ascending=False)#by用于指定按哪列排序,ascending=True为默认值,升序排列b=a.sort_index()c1 c2 c3r3 7 8 9r2 4 5 6r1 1 2 3b=a.sort_index()#按索引排序bc1 c2 c3r1 1 2 3r2 4 5 6r3 7 8 9#数据运算data['c4']=data['c3']-data['c1']datac1 c2 c3 c4r1 1 2 3 2r2 4 5 6 2r3 7 8 9 2#数据删除b=data.drop(columns='c1')#1列bc2 c3 c4r1 2 3 2r2 5 6 2r3 8 9 2c=data.drop(columns=['c1','c2'])#2列cc3 c4r1 3 2r2 6 2r3 9 2d=data.drop(index=['r1','r2'])#2行dc1 c2 c3 c4r3 7 8 9 2#上述演示的将数据删除后的新DataFrame赋给新的变量,不会改变原有结构,如想改原有结构,设置参数inplace=Truedata.drop(index=['r1','r2'],inplace=True)datac1 c2 c3 c4r3 7 8 9 2#数据的拼接merge(),concat(),append()import pandas as pddf1=pd.DataFrame({'公司':['恒盛','创锐','快学'],'分数':[90,80,85]})df2=pd.DataFrame({'公司':['恒盛','创锐','京西'],'股价':[20,180,30]})df1公司 分数0 恒盛 901 创锐 802 快学 85df2公司 股价0 恒盛 201 创锐 1802 京西 30#merge()df3=pd.merge(df1,df2)#默认为内连接df3公司 分数 股价0 恒盛 90 201 创锐 80 180#merge()df4=pd.merge(df1,df2,on='公司',how='left')#默认为内连接 设置参数how='outer'或是left,rightdf4公司 分数 股价0 恒盛 90 20.01 创锐 80 180.02 快学 85 NaN#merge()按行索引合并df5=pd.merge(df1,df2,left_index=True,right_index=True)df5公司_x 分数 公司_y 股价0 恒盛 90 恒盛 201 创锐 80 创锐 1802 快学 85 京西 30#concat() 类似union all,用axis指定连接轴向df6=pd.concat([df1,df2],ignore_index=True)#等同于pd.concat([df1,df2],axis=0);ignore_index=True生成新索引df6公司 分数 股价0 恒盛 90.0 NaN1 创锐 80.0 NaN2 快学 85.0 NaN3 恒盛 NaN 20.04 创锐 NaN 180.05 京西 NaN 30.0df7=pd.concat([df1,df2],axis=1)df7公司 分数 公司 股价0 恒盛 90 恒盛 201 创锐 80 创锐 1802 快学 85 京西 30#append()df8=df1.append(df2) #类似pd.concat([df1,df2],axis=0)df8公司 分数 股价0 恒盛 90.0 NaN1 创锐 80.0 NaN2 快学 85.0 NaN0 恒盛 NaN 20.01 创锐 NaN 180.02 京西 NaN 30.0df9=df1.append({'公司':'腾飞','分数':90},ignore_index=True)df9公司 分数0 恒盛 901 创锐 802 快学 853 腾飞 90#Matplotlibimport matplotlib.pyplot as plt#plt.plot()#plt.bar()#plt.pie()#折线图import matplotlib.pyplot as pltx=[1,2,3,4,5]y=[2,4,6,8,10]plt.plot(x,y)plt.show()#柱形图x=[1,2,3,4,5,6]y=[6,5,4,3,2,1]plt.bar(x,y)plt.show()#模块的交互#案例1 与pandasimport xlwings as xwimport pandas as pdapp=xw.App(visible=False)workbook=app.books.add()worksheet=workbook.sheets.add('新工作表')df=pd.DataFrame([[1,2],[3,4]],columns=['a','b'])worksheet.range('A1').value=dfworkbook.save(f'F://python_test//tt.xlsx')workbook.close()app.quit()#案例2 xlwings与matplotlibimport xlwings as xwimport matplotlib.pyplot as pltfigure=plt.figure()x=[1,2,3,4,5]y=[2,4,6,8,10]plt.plot(x,y)app=xw.App(visible=False)workbook=app.books.add()worksheet=workbook.sheets.add('新工作表')worksheet.pictures.add(figure,name='图片1',update=True,left=100)workbook.save(r'F:\python_test\tt3.xlsx')workbook.close()app.quit()#第4章#案例1:批量新建并关闭工作簿、#案例2:批量打开一个文件夹下的所有工作簿import osimport xlwings as xwfile_path=f'F:/python_test'file_list=os.listdir(file_path)app=xw.App(visible=True,add_book=False)for i in file_list:if os.path.splitext(i)[1]=='.xlsx':#判断文件夹下文件的扩展是否为.xlxsapp.books.open(file_path+'/'+i)#案例3 批量重命名工作表import xlwings as xwapp=xw.App(visible=False,add_book=False)#启动excel程序workbook=app.books.open(f'F:/python_test/tt.xlsx')worksheets=workbook.sheets#获取工作薄中所有工作表for i in range(len(worksheets)):#遍历取到的工作表worksheets[i].name=worksheets[i].name.replace('销售','')#重命名工作表workbook.save(f'F:/python_test/ttt.xlsx')#另存app.quit()#案例3 批量重命名部分工作表 比如前3个sheetimport xlwings as xwapp=xw.App(visible=False,add_book=False)workbook=app.books.open(f'F:/python_test/tt.xlsx')worksheets=workbook.sheetsfor i in range(len(worksheets))[:5]:worksheets[i].name=worksheets[i].name.replace('销售','')workbook.save(f'F:/python_test/ttt2.xlsx')app.quit()#案例4 批量重命名工作薄 前提条条件名称有规律import osfile_path='F:/python_test/t'file_list=os.listdir(file_path)old_book_name='销售'new_book_name='xs'for i in file_list:if i.startswith('~$'):#判断是否有~$开头的文件continue#如有,跳过new_file=i.replace(old_book_name,new_book_name)old_file_path=os.path.join(file_path,i)new_file_path=os.path.join(file_path,new_file)os.rename(old_file_path,new_file_path)#案例4 批量重命名多个工作薄的同名工作表import osimport xlwings as xwfile_path='F:\\python_test\\t'file_list=os.listdir(file_path)old_sheet_name='Sheet1'new_sheet_name='gzb'app=xw.App(visible=True,add_book=False)for i in file_list:if i.startswith('~$'):continueold_file_path=os.path.join(file_path,i)workbook=app.books.open(old_file_path)for j in workbook.sheets:if j.name==old_sheet_name: #判断j.name=new_sheet_name #赋值workbook.save()app.quit()#案例5 在多个工作薄新增工作表import osimport xlwings as xwfile_path='F:\\python_test\\t'file_list=os.listdir(file_path)sheet_name='xinzeng'app=xw.App(visible=False,add_book=False)for i in file_list:if i.startswith('~$'):continuefile_paths=os.path.join(file_path,i)workbook=app.books.open(file_paths)sheet_names=[j.name for j in workbook.sheets]if sheet_name not in sheet_names:workbook.sheets.add(sheet_name)workbook.save()app.quit()#案例5 举一反三 批量删除工作表import osimport xlwings as xwfile_path='F:\\python_test\\t'file_list=os.listdir(file_path)sheet_name='xinzeng'app=xw.App(visible=False,add_book=False)for i in file_list:if i.startswith('~$'):continuefile_paths=os.path.join(file_path,i)workbook=app.books.open(file_paths)for j in workbook.sheets:if j.name==sheet_name:j.delete()breakworkbook.save()app.quit()#案例6 批量打印工作薄 PrintOut()import osimport xlwings as xwfile_path='F:\\python_test\\t'file_list=os.listdir(file_path)app=xw.App(visible=False,add_book=False)for i in file_list:if i.startswith('~$'):continuefile_paths=os.path.join(file_path,i)workbook=app.books.open(file_paths)workbook.api.PrintOut()#打印app.quit()#案例6 批量打印工作薄指定工作表import osimport xlwings as xwfile_path='F:\\python_test\\t'file_list=os.listdir(file_path)sheet_name='gzb'app=xw.App(visible=False,add_book=False)for i in file_list:if i.startswith('~$'):continuefile_paths=os.path.join(file_path,i)workbook=app.books.open(file_paths)for j in workbook.sheets:if j.name==sheet_name:j.api.PrintOut()#打印app.quit()#案例7 将一个工作薄批量复制到其他工作薄import osimport xlwings as xwapp=xw.App(visible=True,add_book=False)file_path='F:\\python_test\\t'file_list=os.listdir(file_path)workbook=app.books.open('F:\\python_test\\资管外访日报20210512.xlsx')worksheet=workbook.sheetsfor i in file_list:if os.path.splitext(i)[1]=='.xlsx':workbooks=app.books.open(file_path+'\\'+i)for j in worksheet:contents=j.range('A1').expand('table').valuename=j.nameworkbooks.sheets.add(name=name,after=len(workbooks.sheets))workbooks.sheets[name].range('A1').value=contentsworkbooks.save()app.quit()#案例7 举一反三 将某个工作表的数据批量复制到其他工作簿指定工作表中import osimport xlwings as xwapp=xw.App(visible=True,add_book=False)file_path='F:\\python_test\\t'file_list=os.listdir(file_path)workbook=app.books.open('F:\\python_test\\资管外访日报20210512.xlsx')worksheet=workbook.sheets['外访回款0']#选择工作薄里面的工作表value=worksheet.range('A1').expand('table')#读取工作表里面数据start_cell=(2,1)end_cell=(value.shape[0],value.shape[1])cell_area=worksheet.range(start_cell,end_cell).value#根据前面设定的区域选取复制的数据for i in file_list:if os.path.splitext(i)[1]=='.xlsx':try:workbooks=xw.Book(file_path+'\\'+i)sheet=workbooks.sheets['gzb']#选择要粘贴数据的工作表scope=sheet.range('A1').expand()#选中要粘贴数据的区域sheet.range(scope.shape[0]+1,1).value=cell_area#粘贴数据workbooks.save()finally:workbooks.close()workbook.close()app.quit()#案例8 按条件将一个工作表拆分为多个工作簿 ************import xlwings as xwapp=xw.App(visible=True,add_book=True)file_path='F:\\python_test\\资管外访日报20210512.xlsx'sheet_name='外访回款'workbook=app.books.open(file_path)worksheet=workbook.sheets[sheet_name]value=worksheet.range('A2').expand('table').value#读取拆分工作表的所有是数据data=dict()for i in range(len(value)):product_name=value[i][10]#获取当前行的产品名称,名称不要带/,识别不了报错if product_name not in data:data[product_name]=[]data[product_name].append(value[i])for key,value in data.items():new_workbook=xw.books.add()new_worksheet=new_workbook.sheets.add(key)new_worksheet['A1'].value=worksheet['A1:Y1'].value#将拆分的的工作表列标题复制到新表中new_worksheet['A2'].value=valuenew_workbook.save('{}.xlsx'.format(key))#以当前产品名作为文件名称new_workbook.save()workbook.close()app.quit()#案例8 举一反三 按条件将一个工作表拆分为多个工作表 默认保存地址为C:\Users\Administrator\Documentsimport xlwings as xwimport pandas as pdapp=xw.App(visible=True,add_book=False)workbook=app.books.open('F:\\python_test\\日报20210512.xlsx')worksheet=workbook.sheets['外访回款0']value=worksheet.range('A1').options(pd.DataFrame,header=1,index=False,expand='table').valuedata=value.groupby('产品')for idx,group in data:new_worksheet=workbook.sheets.add(idx)#数据新增到工作表new_worksheet['A1'].options(index=False).value=group#数据新增到工作表workbook.save()workbook.close()app.quit()#案例8 举一反三 按条件将一个工作簿里多个工作表拆分为多个工作薄import xlwings as xwworkbook_name='F:\\python_test\\资管外访日报20210512.xlsx'app=xw.App(visible=True,add_book=False)header=Noneall_data=[]workbook=app.books.open(workbook_name)for i in workbook.sheets:workbook_split=app.books.add()#新建目标工作簿sheet_split=workbook_split.sheets[0]#选择目标工作簿的第一个工作表i.api.Copy(Before=sheet_split.api)#将来源工作簿中当前的工作表复制到目前工作簿的第一个工作表之前workbook_split.save('{}'.format(i.name))#以当前工作表名称作为文件名保存目标工作薄app.quit()#案例9 批量合并多个工作薄的同名工作表import osimport xlwings as xwfile_path='F:\\python_test\\t'file_list=os.listdir(file_path)sheet_name='外访回款0'#合并的同名工作表名称app=xw.App(visible=False,add_book=False)header=None#定义变量,初始值为空对象,后续用于存放要合并数据的列标题all_data=[]for i in file_list:if i.startswith('~$'):continuefile_paths=os.path.join(file_path,i)workbook=app.books.open(file_paths)for j in workbook.sheets:if j.name==sheet_name:if header==None:header=j['A1:Y1'].valuevalues=j['A2'].expand('table').valueall_data=all_data+valuesnew_workbook=xw.Book()#新建工作薄new_worksheet=new_workbook.sheets.add(sheet_name)#新建工作表,表名为外访回款0new_worksheet['A1'].value=headernew_worksheet['A2'].value=all_datanew_worksheet.autofit()#根据合并后的互数据自动调整新增工作表的行高和列宽new_workbook.save('F:\\python_test\\t\\xin.xlsx')#保存app.quit()#案例9 举一反三 将工作簿名称有规律的工作表合并到一个工作表import osimport xlwings as xwworkbook_name='F:\\python_test\\t\\xin.xlsx'sheet_names=[str(sheet)+'外访回款' for sheet in range (0,2)]new_sheet_name='合并'#指定合并的新工作表名称app=xw.App(visible=False,add_book=False)header=Noneall_data=[]workbook=app.books.open(workbook_name)for i in workbook.sheets:if new_sheet_name in i.name:i.delete()#如果已经存在删除new_worksheet=workbook.sheets.add(new_sheet_name)#注意缩进title_copyed=Falsefor j in workbook.sheets:if j.name in sheet_names:if title_copyed==False:j['A1'].api.EntireRow.Copy(Destination=new_worksheet['A1'].api)#将要合并的工作表列标题复制到新增工作表title.copyed=Truerow_num=new_worksheet['A1'].current_region.last_cell.row#列出新增工作表含有数据区域的最后一行j['A1'].current_region.offset(1,0).api.Copy(Destination=new_worksheet["A{}".format(row_num+1)].api)#在最后一行的下一行复制其他要合并工作表的数据,不复制标题new_worksheet.autofit()workbook.save()app.quit()
day3
#第5章 python 批量处理行、列和单元格 os pandas xlwings#案例01 精确调整多个工作薄的行高和列宽 xlwings de column_width,row_heightimport osimport xlwings as xwfile_path='F:\\python_test'#注意该路径下不要存在其他类型文件,识别不了会报错file_list=os.listdir(file_path)app=xw.App(visible=True,add_book=True)for i in file_list:if i.startswith('~$'):continuefile_paths=os.path.join(file_path,i)#多个参数workbook=app.books.open(file_paths)for j in workbook.sheets:value=j.range('A1').expand('table')value.column_width=12value.row_height=20workbook.save()workbook.close()app.quit()#案例01 举一反三 精确调整1个工作薄的行高和列宽import xlwings as xwapp=xw.App(visible=True,add_book=False)workbook=app.books.open('F:\\python_test\\资管外访日报20210512.xlsx')for i in workbook.sheets:value=i.range('A1').expand('table')value.column_width=12value.row_height=20workbook.save()app.quit()#案例02 批量修改多个工作薄的数据格式 ********************import osimport xlwings as xwfile_path='F:\\python_test'file_list=os.listdir(file_path)app=xw.App(visible=True,add_book=True)for i in file_list:if i.startswith('~$'):continuefile_paths=os.path.join(file_path,i)workboook=app.books.open(file_paths)for j in workbook.sheets:row_num=j['A1'].current_region.last_cell.rowj['A2:A{}'.format(row_num)].number_format='m/d'j['H2:H{}'.format(row_num)].number_format='¥#,##0.00'workbook.save()workbook.close()app.quit()#案例02 举一反三 批量更改多个工作薄外观格式import osimport xlwings as xwfile_path='F:\\python_test'file_list=os.listdir(file_path)app=xw.App(visible=True,add_book=False)for i in file_list:if i.startswith('~$'):continuefile_paths=os.path.join(file_path,i)workbook=app.books.open(file_paths)for j in workbook.sheets:j['A1:N1'].api.Font.Name='宋体'j['A1:N1'].api.Font.Size=10j['A1:N1'].api.Font.Bold=Truej['A1:N1'].api.Font.Color=xw.utils.rgb_to_int((255,255,255))j['A1:N1'].Color=xw.utils.rgb_to_int((0,0,0))j['A1:N1'].api.HorizontalAlignment=xw.constants.HAlign.xlHAlignCenter#j['A1:N1'].api.VerticalAlignment=xw.constants.VAlign.xlHAlignCenter #代码有问题报错xlHAlignCenterj['A2'].expand('table').api.Font.Name='宋体'j['A2'].expand('table').api.Font.Size=10j['A2'].expand('table').api.HorizontalAlignment=xw.constants.HAlign.xlHAlignLeft#j['A2'].expand('table').api.VerticalAlignment=xw.constants.VAlign.xlHAlignCenterfor cell in j['A1'].expand('table'):for b in range(7,12):cell.api.Borders(b).LineStyle=1cell.api.Borders(b).Weight=2workbook.save()workbook.close()app.quit()#案例03 批量替换多个工作薄的行数据import osimport xlwings as xwfile_path='F:\\python_test'file_list=os.listdir(file_path)app=xw.App(visible=True,add_book=False)for i in file_list:if i.startswith('~$'):continuefile_paths=os.path.join(file_path,i)workbook=app.books.open(file_paths)for j in workbook.sheets:value=j['A2'].expand('table').valuefor index,val in enumerate(value):#enumerate两个参数,第1个参数可以是列表,元祖和字符串;第2个参数省略默认为0if val==['背包','12','36']:value[index]=['2背包','32','96']j['A2'].expand('table').value=valueworkbook.save()workbook.close()app.quit()#案例04 批量提取一个工作薄一个工作表的特定数据import xlwings as xwimport pandas as pdapp=xw.App(visible=False,add_book=False)workbook=app.books.open('F:\\python_test\\资管外访日报20210512.xlsx')worksheet=workbook.sheetsdata=[]for i in worksheet:values=i.range('A1').expand().options(pd.DataFrame).valuefiltered=values[values['产品']=='城市信贷']if not filtered.empty:data.append(filtered)new_workbook=xw.books.add()new_worksheet=new_workbook.sheets.add('城市信贷')new_worksheet.range('A1').value=pd.concat(data,ignore_index=False)new_workbook.save()workbook.close()app.quit()#案例05 对多个工作薄工指定工作表数据分列import osimport xlwings as xwimport pandas as pdfile_path='F:\\python_test\\'file_list=os.listdir(file_path)app=xw.App(visible=True,add_book=True)for i in file_list:if i.startswith('~$'):continuefile_paths=os.path.join(file_path,i)workbook=app.books.open(file_paths)worksheet=workbook.sheets['外访回款']values=worksheet.range('A1').options(pd.DataFrame,header=1,index=False,expand='table').valuenew_values=values['拆分'].str.split('*',expand=True)values['1']=new_values[0]values['2']=new_values[1]values['3']=new_values[2]values.drop(columns=['拆分'],inplace=True)worksheet['A1'].options(index=False).value=valuesworksheet.autofit()workbook.save()workbook.close()app.quit()#案例06 批量提取一个工作簿的所有工作表的唯一值import xlwings as xwapp=xw.App(visible=False,add_book=True)workbook=app.books.open('F:\\python_test\\报表.xlsx')data=[]for i,worksheet in enumerate(workbook.sheets):#遍历工作薄的工作表values=worksheet['B2'].expand('down').value#提取所需的列data=data+valuesdata=list(set(data))#set()去重后,用list转为列表,以便于用insert()添加元素data.insert(0,'name')#增加标题new_workbook=xw.books.add()#新建booknew_worksheet=new_workbook.sheets.add('name')#新建sheet,名namenew_worksheet['A1'].options(transpose=True).value=data#转置new_worksheet.autofit()new_workbook.save()new_workbook.close()app.quit()
#第6章 python批量进行数据分析#案例01 批量在工作簿升序pandas sort_values()import xlwings as xwimport pandas as pdapp=xw.App(visible=True,add_book=True)workbook=app.books.open('F:\\python_test\\报表.xlsx')worksheet=workbook.sheetsfor i in worksheet:values=i.range('A1').expand('table').options(pd.DataFrame).value#读取数据,转换格式result=values.sort_values(by='yuan',ascending=False)i.range('A1').value=result#将排序结果写入当前工作表,替换原有数据workbook.save()workbook.close()app.quit()#案例02 筛选一个工作簿的所有工作表数据#案例03 对多个工作薄的工作表分别进行分类汇总import osimport xlwings as xwimport pandas as pdapp=xw.App(visible=True,add_book=True)file_path='F:\python_test'file_list=os.listdir(file_path)for i in file_list:if os.path.splitext(i)[1]=='.xlsx':workbook=app.books.open(file_path+'\\'+i)worksheet=workbook.sheetsfor j in worksheet:values=j.range('A1').expand('table').options(pd.DataFrame).valuevalues['数值']=values['数值'].astype('float')result=values.groupby('产品').sum()j.range('f1').value=result['数值']#将汇总结果写到当前工作表位置workbook.save()workbook.close()app.quit()#案例04 对1个工作薄所有工作表分别进行分别求和import osimport xlwings as xwimport pandas as pdapp=xw.App(visible=True,add_book=True)workbook=app.books.open('F:\\python_test\\报表.xlsx')worksheet=workbook.sheetsfor i in worksheet:values=i.range('A1').expand('table')data=values.options(pd.DataFrame).valuesums=data['数值'].sum()column=values.value[0].index('数值')+1#index()是列表对象的函数,找出某个元素的索引位置;获取数值列号row=values.shape[0]#获取数据区域最后一行的行号,shape(行数,列数)i.range(row+1,column).value=sumsworkbook.save()workbook.close()app.quit()#案例05 批量统计工作薄的最大值最小值#案例06 批量制作数据透视表import osimport xlwings as xwimport pandas as pdapp=xw.App(visible=True,add_book=True)file_path='F:\python_test'file_list=os.listdir(file_path)for i in file_list:if os.path.splitext(i)[1]=='.xlsx':workbook=app.books.open(file_path+'\\'+i)worksheet=workbook.sheetsfor j in worksheet:values=j.range('A1').expand('table').options(pd.DataFrame).valuepivottale=pd.pivot_table(values,values='数值',index='产品',columns='类型',aggfunc='sum',fill_value=0,margins=True,margins_name='总计')j.range('f1').value=pivottale#将汇总结果写到当前工作表位置workbook.save()workbook.close()app.quit()#pd.pivot_table是pandas模块的函数 data 必选 指用于制作数据透视表的区域,values 可选 指定汇总计算的字段#index 必选 指定行字段 columns必须 指定列 aggfunc 指定汇总计算方式(sum,mean)#fill_value 用于指定填充缺失值的内容,默认不填充#margins 用于是否这只显示行列的总计数据,false不显示#margins_name 总计行名称#dropna#案例07 使用相关系数判断数据的相关性 corr()import pandas as pddf=pd.read_excel('F:\\t\\相关分析.xlsx',sheet_name='0')result=df.corr()print(result)#案例08 使用方差分析对比数据的差异import pandas as pdfrom statsmodels.formula.api import olsfrom statsmodels.stats.anova import anova_lmimport xlwings as xwdf=pd.read_excel('F:\\t\\方差分析.xlsx')df=df[['AA','BB','CC','DD','EE']]df_melt=df.melt()#把列名转换为列数据,重构DataFramedf_melt.columns=['Treat','Value']df_describe=pd.DataFrame()#df_describe,总结数据集中分布趋势,生成描述性统计df_describe['AA']=df['AA'].describe()df_describe['BB']=df['BB'].describe()df_describe['CC']=df['CC'].describe()df_describe['DD']=df['DD'].describe()df_describe['EE']=df['EE'].describe()model=ols('Value~C(Treat)',data=df_melt).fit()#对样本进行最小二乘线性拟合激素那anova_table=anova_lm(model,typ=3)#样本进行方差分析app=xw.App(visible=False)workbook=app.books.open('F:\\t\\方差分析.xlsx')worksheet=workbook.sheets['单因素方差分析']worksheet.range('H2').value=df_describe.T#计算后的值转置worksheet.range('H14').value='方差分析'worksheet.range('H15').value=anova_tableworkbook.save()workbook.close()app.quit()#案例08 举一反三(箱型图,观察数据的离散情况和异常值)import pandas as pdimport matplotlib.pyplot as pltimport xlwings as xwdf=pd.read_excel('F:\\t\\方差分析.xlsx')df=df[['AA','BB','CC','DD','EE']]figure=plt.figure()#创建绘图窗口plt.rcParams['font.sans-serif']=['SimHei']#解决中文乱码df.boxplot(grid=False)#绘制箱型图并删除网格线app=xw.App(visible=False)workbook=app.books.open('F:\\t\\方差分析.xlsx')worksheet=workbook.sheets['单因素方差分析']worksheet.pictures.add(figure,name='p1',update=True,left=500,top=10)#将绘制图形插入表workbook.save()workbook.close()app.quit()#案例09 使用描述性统计和直方图定目标import pandas as pdimport matplotlib.pyplot as pltimport xlwings as xwdf=pd.read_excel('F:\\t\\制定目标.xlsx')df.columns=['序号','员工姓名','销售额']df=df.drop(columns=['序号','员工姓名'])df_describe=df.astype('float').describe()df_cut=pd.cut(df['销售额'],bins=7,precision=2)#分成七个均等的区间cut_count=df['销售额'].groupby(df_cut).count()#统计人数df_all=pd.DataFrame()df_all['计数']=cut_countdf_all_new=df_all.reset_index()#索引重置为数字序号df_all_new['销售额']=df_all_new['销售额'].apply(lambda x: str(x))fig=plt.figure()plt.rcParams['font.sans-serif']=['SimHei']#解决中文乱码n,bins,pathes=plt.hist(df['销售额'],bins=7,edgecolor='black',linewidth=0.5)#使用销售额数据绘制直方图 柱子的边框颜色和粗细plt.xticks(bins)#直方图x轴刻度标签设置为各区间的端点值plt.title('销售额分布')plt.xlabel('销售额')plt.ylabel('频数')app=xw.App(visible=False)workbook=app.books.open('F:\\t\\制定目标.xlsx')worksheet=workbook.sheets['1']worksheet.range('A2').value=df_describeworksheet.range('AA2').value=df_all_newworksheet.pictures.add(figure,name='p1',update=True,left=500,top=10)#将绘制图形插入表worksheet.autofit()workbook.save()workbook.close()app.quit()#pandas里面cut()函数进行离散化处理,将数据从最大值到最小值进行等距划分#matplotlib里hist()函数绘制直方图#案例10 使用回归分析预测未来值import pandas as pdfrom sklearn import linear_modeldf=pd.read_excel('F:\\t\\回归.xlsx')df=df[2:]df.columns=['序号','gg1','gg2','销售额']x=df[['gg1','gg2']]y=df['销售额']model=linear_model.LinearRegression()#创建线性回归模型#LinearRegression 属于sklearn函数 (fit_intercept=True,normalize=False,copy_X=True,n_j)#fit_intercept可选参数,是否计算截距,默认True;normalize选参数,是否数据标准化,默认False;#copy_X可选参数默认True,表示复制X值,Flase表示该值可能被覆盖;n_j可选参数,表示计算使用的CPU数量,默认为1model.fit(x,y)#用自变量和因变量数据对线性回归模型进行训练,拟合coef=model.coef_#获取自变量系数model_intercept=model.intercept_#获取截距result='y={}x1+{}x2'.format(coef[0],coef[1],model_intercept)#获取线性回归方程print(result)R2=model.score(x,y)#属于sklearn函数 计算回归模型的R2值 范围[0,1] 越接近1拟合效果越好print(R2)
day4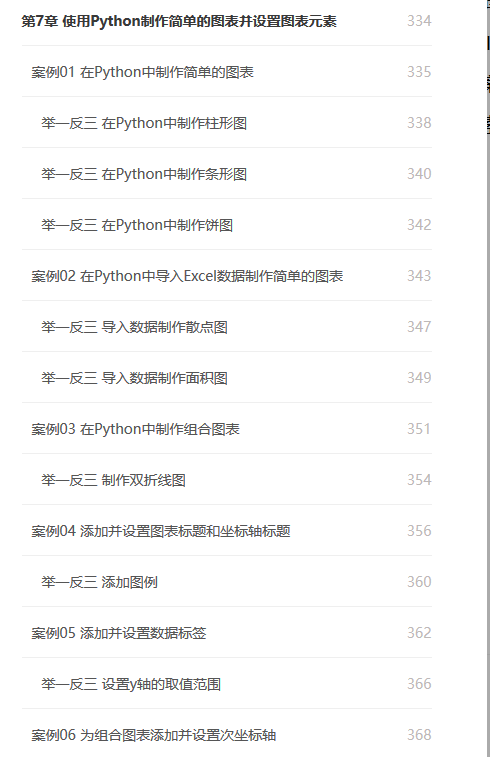
#第7章 制作简单图表并设置图表元素#案例1import matplotlib.pyplot as pltx=[1,2,3,4,5,6]y=[2,4,6,8,10,12]plt.plot(x,y,color='red',linewidth=3,linestyle='solid')#会中折线图 折线颜色、粗细、线型:实线plt.show()#案例2 导入Excel数据制作简单图表import pandas as pdimport matplotlib.pyplot as pltimport xlwings as xwdf=pd.read_excel('F:\\t\\回归.xlsx')figure=plt.figure()plt.rcParams['font.sans-serif']=['SimHei']#为图表中文字体设置默认字体:黑体 (Micsoft YaHei:微软雅黑)plt.rcParams['axes.unicode_minus']=False#解决坐标轴为负数时无法正常显示负号x=df['序号']y=df['销售额']plt.bar(x,y,color='green')app=xw.App(visible=True)workbook=app.books.open('F:\\t\\回归.xlsx')worksheet=workbook.sheets[1]worksheet.pictures.add(figure,left=850)#left参数用于图表插入的位置workbook.save()workbook.close()app.quit()#案例3 组合图 相当于叠加,注意两个指标用同一坐标轴,数据差距不能太大import pandas as pdimport matplotlib.pyplot as pltdf=pd.read_excel('F:\\t\\图表.xlsx')plt.rcParams['font.sans-serif']=['SimHei']#为图表中文字体设置默认字体:黑体 (Micsoft YaHei:微软雅黑)plt.rcParams['axes.unicode_minus']=False#解决坐标轴为负数时无法正常显示负号x=df['序号']y1=df['销售额']y2=df['gg1']plt.plot(x,y1,color='red')plt.bar(x,y2,color='green')plt.show()#案例4 图表及坐标轴标题 title(),xlabel(),ylabel()import pandas as pdimport matplotlib.pyplot as pltdf=pd.read_excel('F:\\t\\图表.xlsx')plt.rcParams['font.sans-serif']=['SimHei']#为图表中文字体设置默认字体:黑体 (Micsoft YaHei:微软雅黑)plt.rcParams['axes.unicode_minus']=False#解决坐标轴为负数时无法正常显示负号x=df['序号']y=df['销售额']#设置图例名plt.bar(x,y,color='pink',label='销售额')#图表及坐标轴标题plt.title(label='月销售额数据',fontdict={'family':'SimHei','color':'red','size':20},loc='center',pad=50)#title label:图表标题的文本内容,fontdict:字体色号颜色,loc:显示位置,pad标题到坐标系顶端距离plt.xlabel('月份',fontdict={'family':'SimHei','color':'black','size':16},labelpad=50)plt.ylabel('销售额',fontdict={'family':'SimHei','color':'black','size':16},labelpad=50)#添加图例plt.legend(loc='upper left',fontsize=10)plt.show()#案例5 数据标签 text()函数import pandas as pdimport matplotlib.pyplot as pltdf=pd.read_excel('F:\\t\\图表.xlsx')plt.rcParams['font.sans-serif']=['SimHei']#为图表中文字体设置默认字体:黑体 (Micsoft YaHei:微软雅黑)plt.rcParams['axes.unicode_minus']=False#解决坐标轴为负数时无法正常显示负号x=df['序号']y=df['销售额']#设置图例名plt.bar(x,y,color='pink',label='销售额')#图表及坐标轴标题plt.title(label='月销售额数据',fontdict={'family':'SimHei','color':'red','size':20},loc='center',pad=50)#title label:图表标题的文本内容,fontdict:字体色号颜色,loc:显示位置,pad标题到坐标系顶端距离plt.xlabel('月份',fontdict={'family':'SimHei','color':'black','size':16},labelpad=50)plt.ylabel('销售额',fontdict={'family':'SimHei','color':'black','size':16},labelpad=50)#添加图例plt.legend(loc='upper left',fontsize=10)#y轴的取值范围plt.ylim(0,100)#ylim(min,max)#数据标签# zip 迭代对象作为参数,将对象中对应的元素打包成一个元组,返回由这些元组组成的列表for a,b in zip(x,y):plt.text(a,b,b,fontdict={'family':'KaiTi','color':'red','size':16})#数据标签x坐标,y坐标,标签文本内容,格式plt.show()#案例6 组合图设置次坐标轴 twinx()import pandas as pdimport matplotlib.pyplot as pltdf=pd.read_excel('F:\\t\\图表.xlsx')plt.rcParams['font.sans-serif']=['SimHei']#为图表中文字体设置默认字体:黑体 (Micsoft YaHei:微软雅黑)plt.rcParams['axes.unicode_minus']=False#解决坐标轴为负数时无法正常显示负号x=df['序号']y1=df['销售额']y2=df['gg1']plt.bar(x,y2,color='green',label='销售额')plt.legend(loc='upper right',fontsize=10)plt.twinx()plt.plot(x,y1,color='red',label='gg1')plt.legend(loc='upper right',fontsize=10)#y轴添加网格线plt.grid(b=True,which='major',axis='y',color='gray',linestyle='dashed',linewidth=1)#b为True,显示网格线,反之不显示;which:可选参数 设置哪种网格线 major/minor/both 主/次要/都要;axis x/y/bothplt.show()
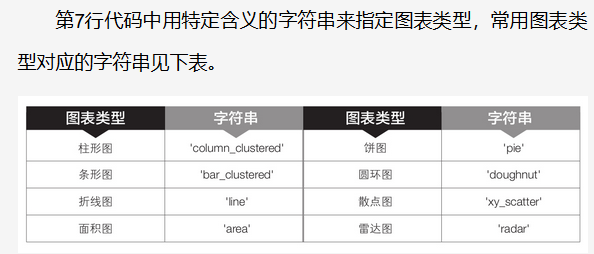
pip install scipy
报错:
Requirement already satisfied: scipy in d:\users\administrator\anaconda3\lib\site-packages (1.5.2)
Requirement already satisfied: numpy>=1.14.5 in d:\users\administrator\anaconda3\lib\site-packages (from scipy) (1.19.2)
Note: you may need to restart the kernel to use updated packages.
pip install —target=D:\Users\Administrator\anaconda3\Lib\site-packages scipy
解决:
原文链接:https://blog.csdn.net/sliver_goup/article/details/112497385
Note: you may need to restart the kernel to use updated packages.
这个问题其实就是需要你把所需要的库升级一下子,更新到最新版本,旧版本与代码用到的库版本冲突,升级。
pip install —upgrade 库名 #第8章 制作常用图表
#第8章 制作常用图表
#第8章 制作常用图表#案例1 柱形图并对比数据import xlwings as xwapp=xw.App(visible=True,add_book=False)workbook=app.books.open('F:\\t\\常用图.xlsx')for i in workbook.sheets:chart=i.charts.add(left=200,top=0,width=355,height=211)#图表位置和尺寸chart.set_source_data(i['A1'].expand())#读取制作图表数据chart.chart_type='column_clustered'#柱形图workbook.save()workbook.close()app.quit()#案例2 折线图展示数据变化趋势#plt.axis('off') 隐藏坐标轴import pandas as pdimport matplotlib.pyplot as plt # matplotlib报错 ;matplotlib.pyplot运行okimport xlwings as xwdf=pd.read_excel('F:\\t\\常用图.xlsx')figure=plt.figure()plt.rcParams['font.sans-serif']=['SimHei']plt.rcParams['axes.unicode_minus']=Falsex=df['序号']y=df['销售额']plt.plot(x,y,color='red',linewidth=3,linestyle='solid')plt.title(label='趋势图',fontdict={'color':'black','size':30},loc='center')#为最高点添加数据标签max1=df['销售额'].max()df_max=df[df['销售额']==max1]for a,b in zip(df_max['序号'],df_max['销售额']):plt.text(a,b+0.05,(a,'%.0f'%b),ha='center',va='bottom',fontsize=10)plt.axis('off')app=xw.App(visible=False)workbook=app.books.open('F:\\t\\常用图.xlsx')worksheet=workbook.sheets['0']worksheet.pictures.add(figure,name='2',update=True,left=200)workbook.save()workbook.close()app.quit()#案例2 平滑折线图import pandas as pdimport matplotlib.pyplot as pltimport numpy as npfrom scipy import interpolate #scipyimport xlwings as xwdf=pd.read_excel('F:\\t\\常用图.xlsx')figure=plt.figure()plt.rcParams['font.sans-serif']=['SimHei']plt.rcParams['axes.unicode_minus']=Falsex=df['序号']y=df['销售额']xnew=np.arange(1,9,0.1)#numpy模块函数 创建等差数组func=interpolate.interp1d(x,y,kind='cubic')#interp1d表示1维插值 返回一个插值后的函数ynew=func(xnew)plt.plot(xnew,ynew,color='red',linewidth=3,linestyle='solid')plt.title(label='趋势图',fontdict={'color':'black','size':30},loc='center')#为最高点添加数据标签max1=df['销售额'].max()df_max=df[df['销售额']==max1]for a,b in zip(df_max['序号'],df_max['销售额']):plt.text(a,b+0.05,(a,'%.0f'%b),ha='center',va='bottom',fontsize=10)plt.axis('off')app=xw.App(visible=False)workbook=app.books.open('F:\\t\\常用图.xlsx')worksheet=workbook.sheets['0']worksheet.pictures.add(figure,name='2',update=True,left=200)workbook.save()workbook.close()app.quit()#案例3 制作散点图import pandas as pdimport matplotlib.pyplot as pltimport xlwings as xwdf=pd.read_excel('F:\\t\\常用图.xlsx')figure=plt.figure()plt.rcParams['font.sans-serif']=['SimHei']plt.rcParams['axes.unicode_minus']=Falsex=df['序号']y=df['销售额']plt.scatter(x,y,s=400,color='red',marker='o',edgecolor='black')plt.xlabel('序号',fontdict={'family':'SimHei','color':'black'})plt.ylabel('销售额',fontdict={'family':'SimHei','color':'black'})plt.title('销售额图',fontdict={'family':'SimHei','color':'black'},loc='center')plt.show()#案例3 制作散点图和线性趋势import pandas as pdimport matplotlib.pyplot as pltimport xlwings as xwfrom sklearn import linear_modeldf=pd.read_excel('F:\\t\\常用图.xlsx')figure=plt.figure()plt.rcParams['font.sans-serif']=['SimHei']plt.rcParams['axes.unicode_minus']=Falsex=df['序号']y=df['销售额']plt.scatter(x,y,s=400,color='red',marker='o',edgecolor='black')plt.xlabel('序号',fontdict={'family':'SimHei','color':'black'})plt.ylabel('销售额',fontdict={'family':'SimHei','color':'black'})plt.title('销售额图',fontdict={'family':'SimHei','color':'black'},loc='center')model=linear_model.LinearRegression().fit(x.values.reshape(-1,1),y)pred=model.predict(x.values.reshape(-1,1))plt.plot(x,pred,color='black',linewidth=3,linestyle='solid',label='线型趋势')plt.legend(loc='upper left')plt.show()#案例3 气泡import pandas as pdimport matplotlib.pyplot as pltimport xlwings as xwfrom sklearn import linear_modeldf=pd.read_excel('F:\\t\\常用图.xlsx')figure=plt.figure()plt.rcParams['font.sans-serif']=['SimHei']plt.rcParams['axes.unicode_minus']=Falsex=df['序号']y=df['销售额']plt.scatter(x,y,s=y*50,color='red',marker='o',edgecolor='black')#s为y的倍数,气泡图plt.xlabel('序号',fontdict={'family':'SimHei','color':'black'})plt.ylabel('销售额',fontdict={'family':'SimHei','color':'black'})plt.title('销售额图',fontdict={'family':'SimHei','color':'black'},loc='center')#气泡图显示产品类型for a,b,c in zip(x,y,z):plt.text(a,b,c,ha='center',va='center',fontsize=30,color='white')#坐标轴plt.xlim(0,10)plt.ylim(0,60)plt.show()#案例4 饼图import pandas as pdimport matplotlib.pyplot as pltdf=pd.read_excel('F:\\t\\常用图.xlsx')plt.rcParams['font.sans-serif']=['SimHei']plt.rcParams['axes.unicode_minus']=Falsex=df['序号']y=df['销售额']plt.pie(y,labels=x,labeldistance=1.1,autopct='%.2f%%',pctdistance=0.8,startangle=90,radius=1.0,explode=[0,0,0,0,0,0,0,0.2,0])plt.xlabel('序号',fontdict={'family':'SimHei','color':'black'})plt.ylabel('销售额',fontdict={'family':'SimHei','color':'black'})plt.title('销售额图',fontdict={'family':'SimHei','color':'black'},loc='center')plt.show()#案例4 圆环 wedgeprops 用于设置饼图的属性,取值为字典,字典中的元素是饼图的各个属性的值import pandas as pdimport matplotlib.pyplot as pltdf=pd.read_excel('F:\\t\\常用图.xlsx')plt.rcParams['font.sans-serif']=['SimHei']plt.rcParams['axes.unicode_minus']=Falsex=df['序号']y=df['销售额']#饼图块的宽度 'width':0.3 小于饼图半径 radius=1.0plt.pie(y,labels=x,autopct='%.2f%%',pctdistance=0.8,radius=1.0,wedgeprops={'width':0.3,'linewidth':2,'edgecolor':'white'})plt.xlabel('序号',fontdict={'family':'SimHei','color':'black'})plt.ylabel('销售额',fontdict={'family':'SimHei','color':'black'})plt.title('销售额图',fontdict={'family':'SimHei','color':'black'},loc='center')plt.show()#案例5 雷达图 ********import pandas as pdimport numpy as npimport matplotlib.pyplot as pltdf=pd.read_excel('C:\\Users\\Administrator\\Documents\\py\\雷达图.xlsx')df=df.set_index('zb')df=df.Tdf.index.name='品牌'def plot_radar(data,feature):plt.rcParams['font.sans-serif']=['SeiHei']plt.rcParams['axes.unicode_minus']=Falsecols=['zb1','zb2','zb3','zb4','zb5','zb6','zb7','zb8']#指定显示的性能评价名称colors=['green','blue','pink','red']angles=np.linspace(0.1*np.pi,2.1*np.pi,len(cols),endpoint=False)#angles = np.append(angles, angles[0]) # 在末尾添加第一个值,保证曲线闭合#angles=np.concatenate((angles,[angles[0]])) #更新版本后需要注销 连接刻度线#feature=np.concatenate((feature,[feature[0]]))fig=plt.figure(figsize=(8,8))ax=fig.add_subplot(111,polar=True)for i,c in enumerate(feature):stats=data.loc[c]#获取品牌对应坐标#stats=np.concatenate((stats,[stats[0]])) #[stats[0]] #更新版本后需要注销 连接指标品牌数据stats=np.append(stats,stats[0]) # 在末尾添加第一个值,保证曲线闭合ax.plot(angles,stats,'-',linewidth=6,c=colors[i],label='%s'%(c))#构建图ax.fill(angles,stats,color=colors[i],alpha=0.25)#填充颜色ax.legend()ax.set_yticklabels([])ax.set_thetagrids(angles*180/np.pi,cols,fontsize=16)#添加并设置数据标签plt.show()return figfig=plot_radar(df,['A','B','C','D'])#https://blog.csdn.net/u014421797/article/details/103842928 参考雷达图#案例6 温度计 ***柱形图叠加,先目标后,实际完成数据import pandas as pdimport numpy as npimport matplotlib.pyplot as pltdf=pd.read_excel('C:\\Users\\Administrator\\Documents\\py\\雷达图.xlsx')sum=0for i in range(12):sum=df['销售额'][i]+sumgoal=df['销售额'][13]percentage=sum/goalplt.bar(1,1,color='yellow')plt.bar(1,percentage,color='cyan')plt.xlim(0,2)plt.ylim(0,1.2)plt.text(1,percentage-0.01,percentage,ha='center',va='top',fontdict={'color':'black','size':20})plt.show()

若有收获,就点个赞吧
0 人点赞
