pychat
图表
# 例子import pyechartspyecharts.globals._WarningControl.ShowWarning = Falseimport warningswarnings.filterwarnings('ignore')#隐藏警告import numpy as npimport pandas as pdimport jsonfrom pandas.io.json import json_normalizeimport pyecharts as pefrom collections import Counterx=list(range(1,8))#x=[2,1,4,5,7,8,10]y=[114, 55, 27, 101, 125, 27, 105]from pyecharts import options as optsfrom pyecharts.charts import Barbar = Bar()bar.add_xaxis(list(x))bar.add_yaxis("name", y)bar.render_notebook()#用来在notebook中展示图形,使用render则会直接保存为html文件
#图表三种写法from pyecharts.faker import Faker#这是用来产生伪数据的包#方式1c = (Bar(init_opts=opts.InitOpts(width="620px", height="300px")).add_xaxis(Faker.choose()).add_yaxis("商家A", Faker.values()).add_yaxis("商家B", Faker.values()).set_global_opts(title_opts=opts.TitleOpts(title="Bar-基本示例", subtitle="我是副标题")))c.render_notebook()#方式2b=Bar(init_opts=opts.InitOpts(width="620px", height="300px"))b.add_xaxis(Faker.choose())b.add_yaxis("商家A", Faker.values())b.add_yaxis("商家B", Faker.values())b.set_global_opts(title_opts=opts.TitleOpts(title="Bar-基本示例", subtitle="我是副标题"))b.render_notebook()#方式3 链式调用Bar(init_opts=opts.InitOpts(width="620px", height="300px")).add_xaxis(Faker.choose()).add_yaxis("商家A", Faker.values()).add_yaxis("商家B", Faker.values()).render_notebook()
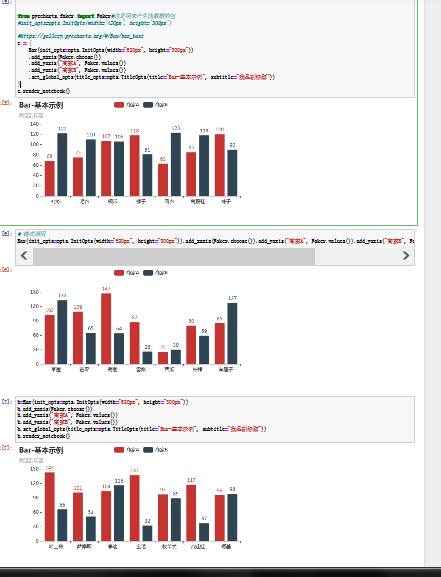
'''标记点的设定class MarkPointOpts(# 标记点数据,参考 `series_options.MarkPointItem`data: Sequence[Union[MarkPointItem, dict]] = None,class MarkPointItem(# 标注名称。name: Optional[str] = None,# 特殊的标注类型,用于标注最大值最小值等。可选:# 'min' 最大值。# 'max' 最大值。# 'average' 平均值。type_: Optional[str] = None,'''bar = Bar(init_opts=opts.InitOpts(width="620px", height="300px"))bar.add_xaxis(list(x))bar.add_yaxis("name", y)bar.set_series_opts(label_opts=opts.LabelOpts(is_show=False),markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="max", name="最大值"),opts.MarkPointItem(type_="min", name="最小值"),opts.MarkPointItem(type_="average", name="平均值"),]))#去掉bar的数字标识bar.render_notebook()
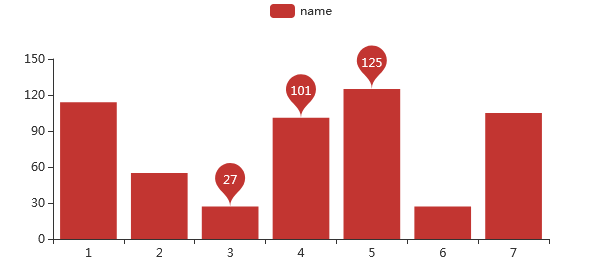
from pyecharts.globals import ThemeType#有些配置需要在图形函数中配置,比如主题的设定#LIGHT DARK CHALK ESSOS PURPLE_PASSIONbar = Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT,width="620px", height="300px"))bar.add_xaxis(x)bar.add_yaxis("name", y)bar.render_notebook()
pyecharts的数据类型以及新的数据导入逻辑https://pyecharts.org/#/zh-cn/data_format由于pyecharts背后封装的js库,会涉及到数据类型转化。它暂时要求输入数据必须是python的基础数据类型,比如字符串,列表,字典,而不能是序列这样的数据类型。因此序列输入量需要事先被转化为list等基础数据类型才能被pyecharts支持
python归一化
归一化目的
1)归一化后加快了梯度下降求最优解的速度;
2)归一化有可能提高精度(如KNN)
注:没有一种数据标准化的方法,放在每一个问题,放在每一个模型,都能提高算法精度和加速算法的收敛速度
归一化的方法
1、线性函数归一化(Min-Max scaling)
线性函数将原始数据线性化的方法转换到[0 1]的范围,归一化公式如下:
该方法实现对原始数据的等比例缩放,其中Xnorm为归一化后的数据,X为原始数据,Xmax、Xmin分别为原始数据集的最大值和最小值。
2、0均值标准化(Z-score standardization)
0均值归一化方法将原始数据集归一化为均值为0、方差1的数据集,归一化公式如下:
其中,μ、σ分别为原始数据集的均值和方法。该种归一化方式要求原始数据的分布可以近似为高斯分布,否则归一化的效果会变得很糟糕。
应用场景
1、在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,第二种方法(Z-score standardization)表现更好。
2、在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用第一种方法或其他归一化方法。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围。
应用场景说明
1)概率模型不需要归一化,因为这种模型不关心变量的取值,而是关心变量的分布和变量之间的条件概率;
2)SVM、线性回归之类的最优化问题需要归一化,是否归一化主要在于是否关心变量取值;
3)神经网络需要标准化处理,一般变量的取值在-1到1之间,这样做是为了弱化某些变量的值较大而对模型产生影响。一般神经网络中的隐藏层采用tanh激活函数比sigmod激活函数要好些,因为tanh双曲正切函数的取值[-1,1]之间,均值为0.
4)在K近邻算法中,如果不对解释变量进行标准化,那么具有小数量级的解释变量的影响就会微乎其微.
参考:https://blog.csdn.net/zenghaitao0128/article/details/78361038

若有收获,就点个赞吧
0 人点赞
