logkit 是一款开源的数据采集工具,可以将不同数据源如:关系型数据库(MySQL等)、非关系型数据库(MongoDB)、文件(csv等)、消息队列(kafka)、网络数据(TCP、Http POST)等的数据便捷地发送到各种数据平台( Pandora 大数据平台、ElasticSearch、InfluxDB、Kafka等)进行数据存储、分析,整个发送流程在 logkit 工具上得到可视化。logkit 提供多种配置选择,可以满足您的各种数据解析需求。除了基本的数据读取、解析、转换、发送、删除等功能,logkit 还具有集群管理的功能,让您轻松管理多个数据发送任务。
logkit 工作流程
以发送数据到 Pandora 大数据平台为例:
logkit 支持的采集数据源
- File: 读取文件中的日志数据,包括 csv 格式的文件,kafka-rest 日志文件, nginx 日志文件等,并支持以 grok 的方式解析日志。
- ElasticSearch: 读取 ElasticSearch 中的数据。
- MongoDB: 读取 MongoDB 中的数据。
- MySQL: 读取 MySQL 中的数据。
- MicroSoft SQL Server: 读取 Microsoft SQL Server中的数据。
- Postgre SQL: 读取 PostgreSQL 中的数据。
- Kafka: 读取 Kafka 中的数据。
- Redis: 读取 Redis 中的数据。
- Socket: 读取 tcp\udp\unixsocket 协议中的数据。
- Http: 作为 http 服务端,接受 POST 请求发送过来的数据。
- Script: 支持执行脚本,并获得执行结果中的数据。
- Snmp: 主动抓取 Snmp 服务中的数据。
logkit 支持的发送服务端
- Pandora Sender: 发送到 Pandora (七牛大数据处理平台)。
- Elasticsearch Sender: 发送到 ElasticSearch。
- File Sender: 发送到本地文件。
- InfluxDB Sender: 发送到 InfluxDB。
- MongoDB Accumulate Sender: 聚合后发送到 MongoDB。
- Kafka Sender: 发送到 Kafka。
- Http Sender: 以 Http POST 请求的方式发送数据。
数据解析与变换功能
配置解析方式:在数据被 logkit 读取后,用户可以根据需要配置日志解析格式,抽取数据中的字段,转化为结构化数据。logkit 支持包括 json、csv、grok等大多数主流日志解析方式。
点此了解更多 logkit 数据解析功能。
配置 transformer: 针对字段做数据变换, 来满足整体数据解析满足不了的需求,比如将 ip 字符串扩展为 ip 对应的区域、城市、省份、运营商等信息。支持包括字符串替换、ip 扩展、格式转换等多种数据变换方式。
点此了解更多 logkit 数据字段变换功能。
logkit 操作指南
1.下载 & 解压 logkit 工具
| 适用平台 | 下载链接 |
|---|---|
| Windows | windows 64位版本下载 |
| Linux Ubuntu/Debian | linux 64位版本下载 |
| Linux Centos/Redhat | linux 64位版本下载 |
| MacOS | MacOS 版本下载 |
2.打开 logkit 配置文件 logkit.conf

logkit.conf 是logkit 工具的基础配置文件,主要用于指定 logkit 运行时需要的资源和各个 runner(即每条数据采集任务) 配置文件的具体路径。
典型的配置如下:
{"max_procs": 8,"debug_level": 1,"clean_self_log":true,"bind_host":"localhost:3001","static_root_path":"./public","confs_path": ["confs*"]}
bind_hostlogkit 绑定的页面端口,通过命令行启动 logkit 后打开这个页面开始配置数据采集。static_root_pathlogkit 页面的静态资源路径,强烈建议写成绝对路径。!> 注意:老版本的移动到了 “public-old” 文件夹。
confs_path除了通过页面配置采集数据以外,logkit 还支持直接通过监控文件夹添加 runner 。(如果你只通过页面添加 logkit runner ,那么无需修改此配置) 列表中的每一项都是一个 runner 的配置文件夹,这个配置文件夹下面每个以 .conf 结尾的文件就代表了一个运行的 runner ,也就代表了一个 logkit 正在运行的推送数据的线程。如果文件夹下配置发生增加、减少或者变更,logkit 会相应的增加、减少或者变更 runner 。
3.通过命令行启动 logkit 工具
命令行进入 logkit 所在的文件夹,然后输入:
./logkit -f logkit.conf
4.通过浏览器打开logkit配置页面
启动 logkit 工具以后,您就可以通过浏览器配置数据采集啦!浏览器访问的地址就是第2步中 bind_host 的地址。
配置日志采集器
logkit 可以采集各种日志(包括 nginx 等基础组件日志)至各种数据平台进行数据分析。
1.配置数据源
在配置数据源页面,您需要填好数据来源、数据读取方式等信息。在实际配置过程中,您可以根据需要编辑高级选项,一般来说,高级选项按默认设置即可。
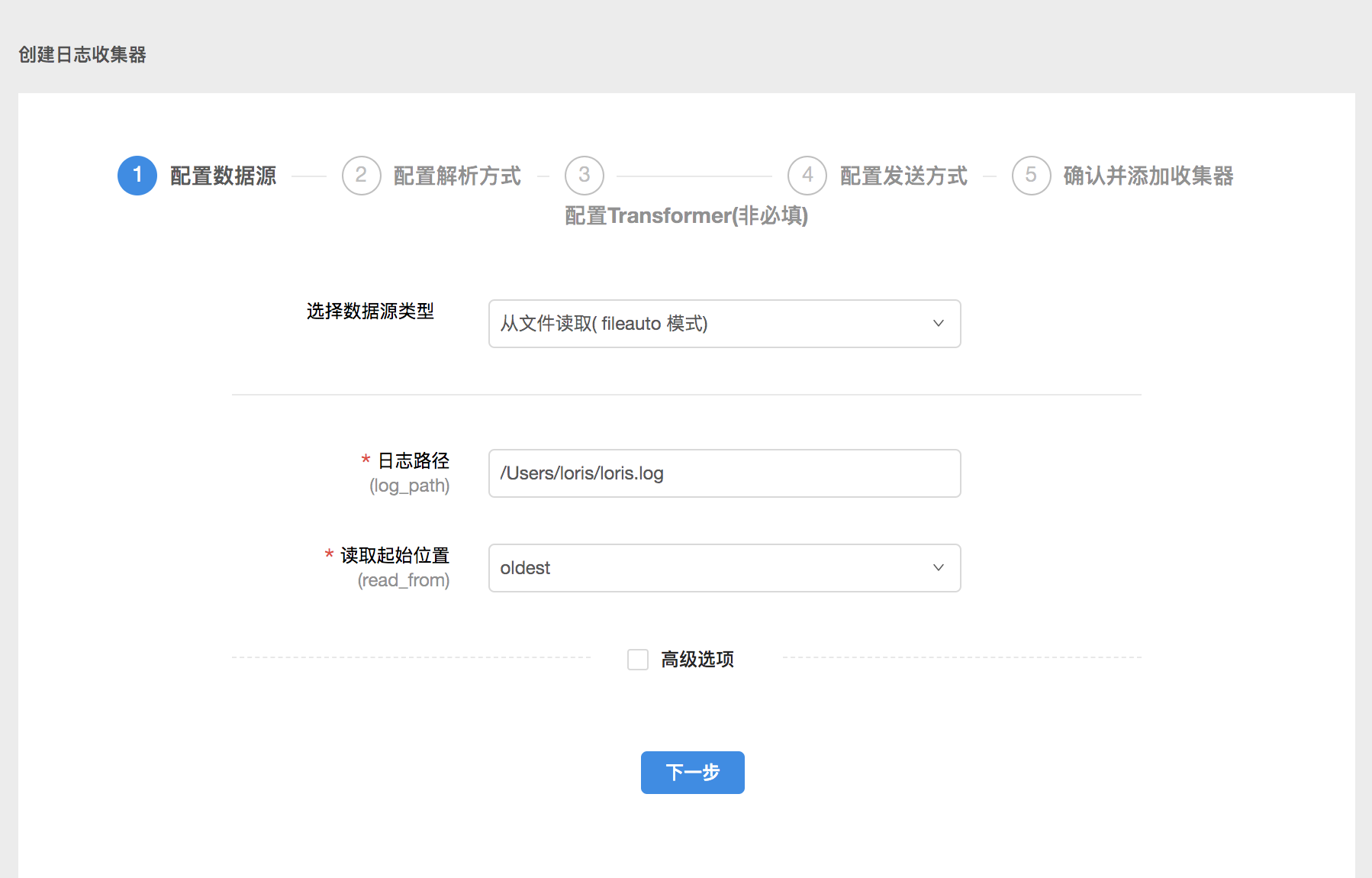
这条数据源配置的意思是从本地路径是 /Users/loris/ 的地方读取名称为 loris.log 的文件里的日志,从最早的数据读起。
2.配置解析方式
配置好数据源以后,您需要根据数据源文件的格式配置合适的解析方式。
以csv格式的日志为例:

通过输入字段类型与分割符来将日志内容转化为结构化数据,方便后续在数据平台进行数据分析。
- 字段类型
您需要在这里输入详细的字段名称与类型。
- 解析样例数据
logkit 提供解析样例数据功能,即输入一行样例日志,您可以看到解析结果,来检验您的配置是否正确。
3.配置Transformer
logkit 提供 transformer 功能来满足一些更精细的字段解析需求。
以 replace transformer 为例:
通过配置 replace transformer,您可以将指定字段的某个值替换为另一个值。

目前支持的Transformer有:
- replace transformer : 针对字段做字符串替换。
- IP transformer: 针对ip做运营商信息字段扩展。
- date transformer: 将字段解析为时间并做一些转换。
- discard transformer: 将指定字段的数据抛弃。
- split transformer: 将指定字段的数据切分为字符串数组。
- convert transformer: 按照dsl将数据进行格式转换。
- urlparam transformer: 将指定字段的数据按照url参数的格式转换为键值对。
- arrayexpand transformer: 将指定字段的数组展开并转换为键值对。
- rename transformer: 将字段名称重命名,解决不同下游系统对字段名称中特殊字符不支持的问题。
- label transformer: 添加一个带有固定值的字段到数据中,相当于加个标签。
- json transformer: 将一个符合json格式的字符串字段,反序列化为对应结构体类型。
- script transformer: 执行脚本文件并记录脚本执行结果。
- clocktrail transformer: 针对 AWS ClockTrail的数据做格式转换的Transformer,可以将ClockTrail的json格式中的 Records逐条变为数据。
- pandora_key_convert transformer: 将不符合pandora 字段类型的key字符转化为下划线。
- UserAgent transformer: 浏览器中的user agent信息解析,可以解析出包括设备、操作系统、版本号在内的多种信息。
- xml transformer: 将一个符合xml格式的字符串字段,反序列化为对应map[string]interface{}结构体类型。
如果没有字段变换需求,跳过这一步即可。
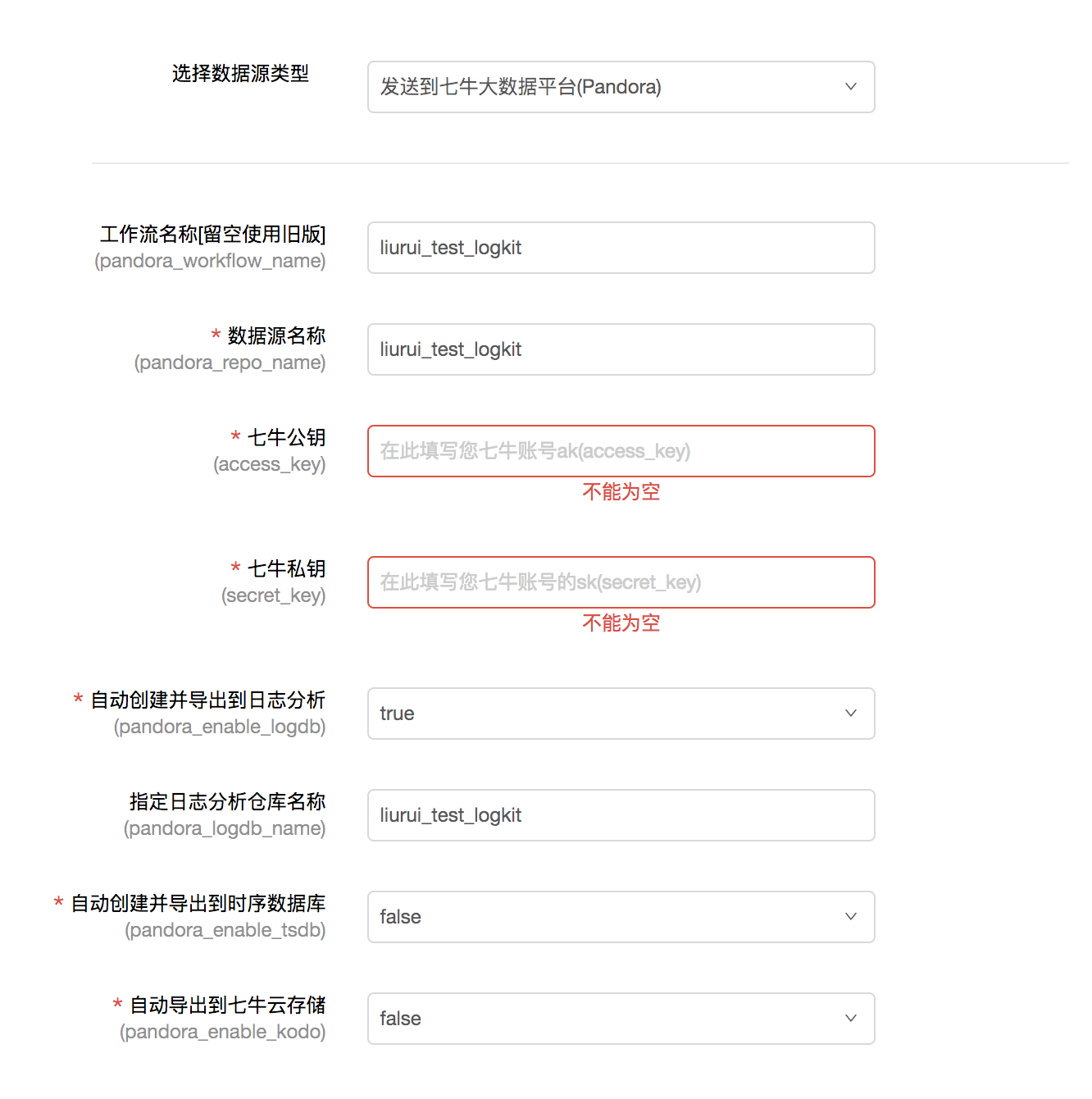
4.配置发送方式
您需要选择发送的数据平台并填写相关信息来完成发送与绑定。
以发送到七牛大数据平台为例,您需要填写数据源名称、工作流名称、您的七牛账号的公钥和私钥实现数据的接收,根据需要您可以选择是否将数据导出到日志分析、时序数据库和云存储进行数据存储与分析。
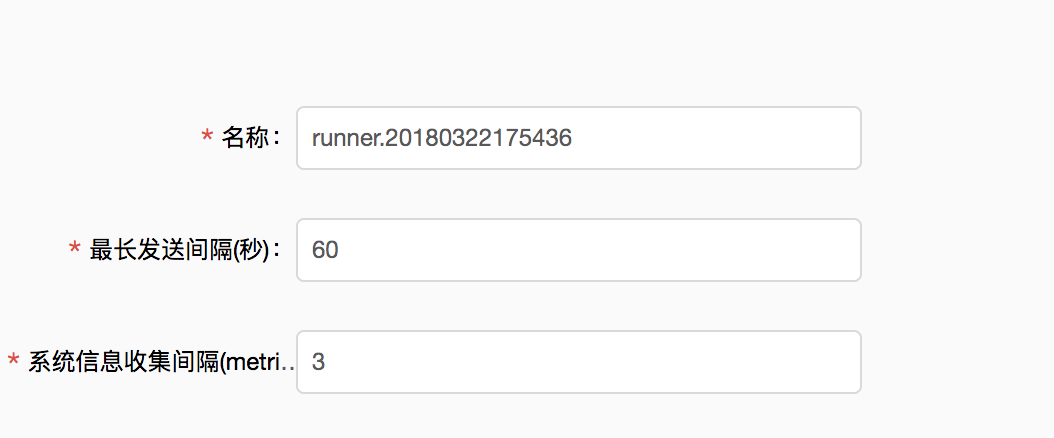
5.确认runner配置
最后设置好收集数据和发送数据的时间间隔,整个runner就配置好啦!数据已经打入七牛大数据平台,您可以去七牛大数据平台进行数据计算与导出。
在配置过程中,您每一步的操作信息都会自动保存。提交之前,您可以直接返回上一步修改之前的配置信息,不用重新输入。
根据上述数据采集配置,您可以在 Logdb 根据配置中填写的日志仓库名称查询您发送的日志详情。
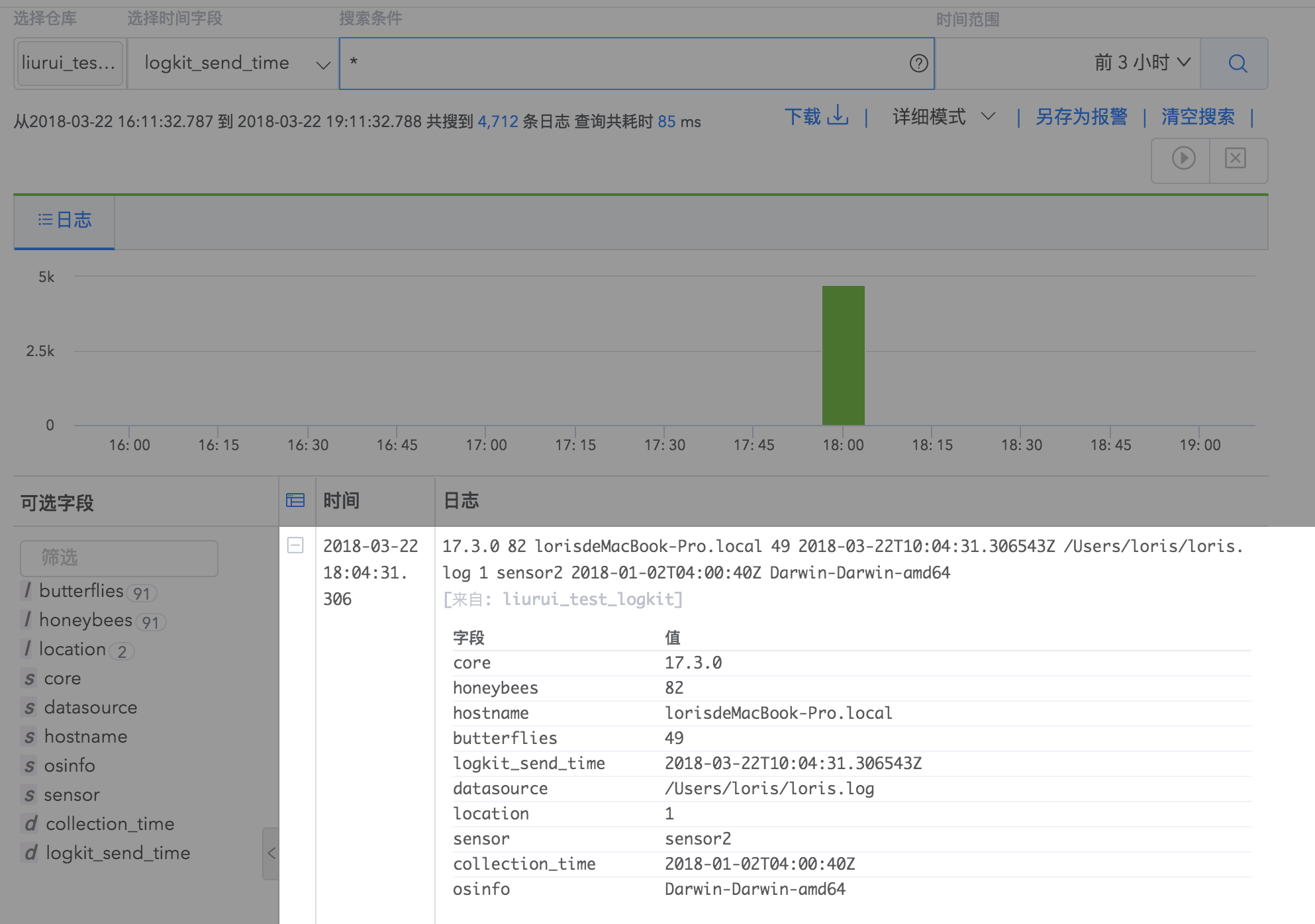
6.采集日志进行日志分析使用场景
配置系统信息采集器
通过 logkit 您可以采集数十类上百种系统指标:CPU、内存、进程等,并发送到大数据平台进行系统运行情况监控。
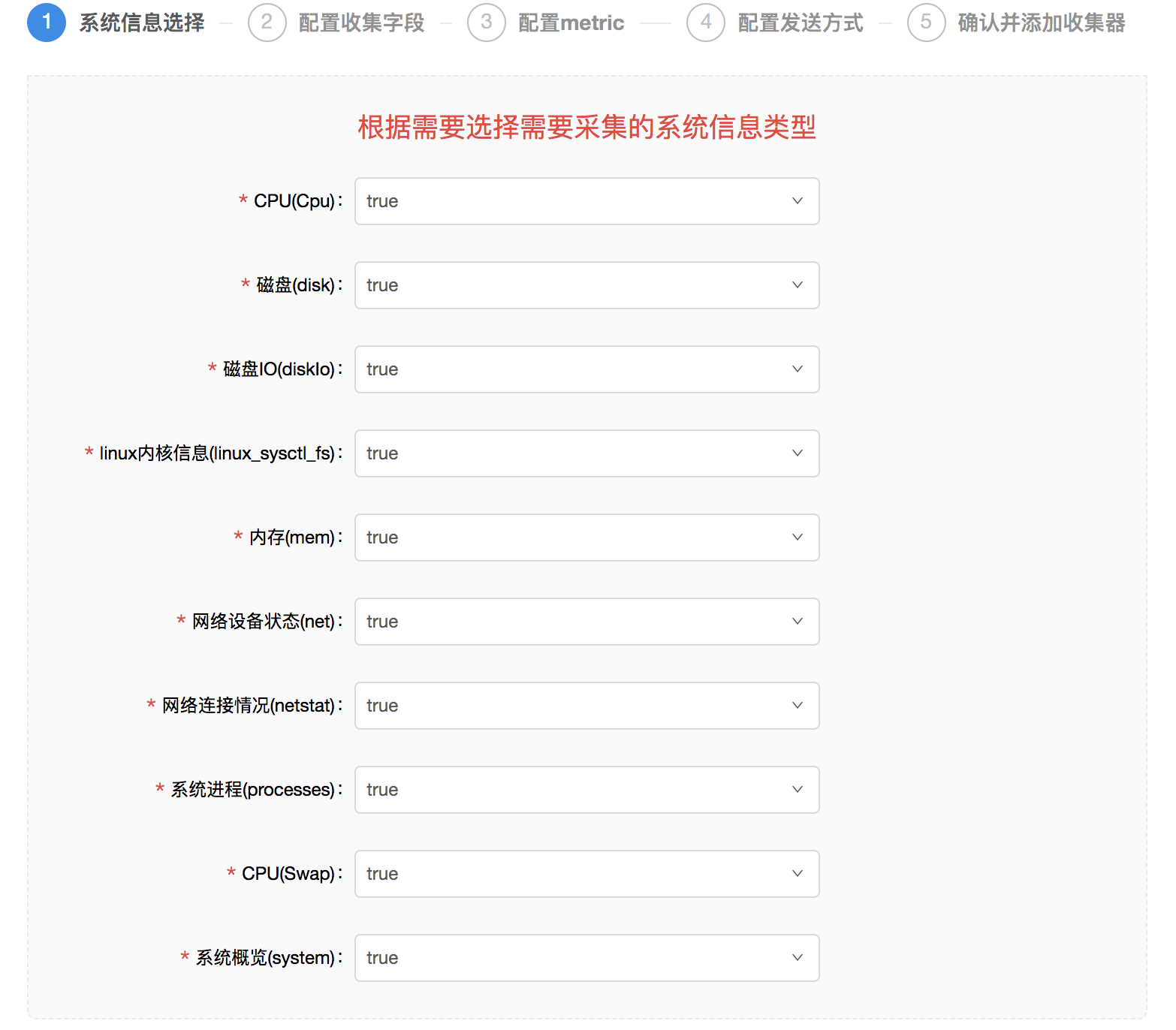
配置系统信息的过程非常方便:
1.选择您想监控的系统信息类型。
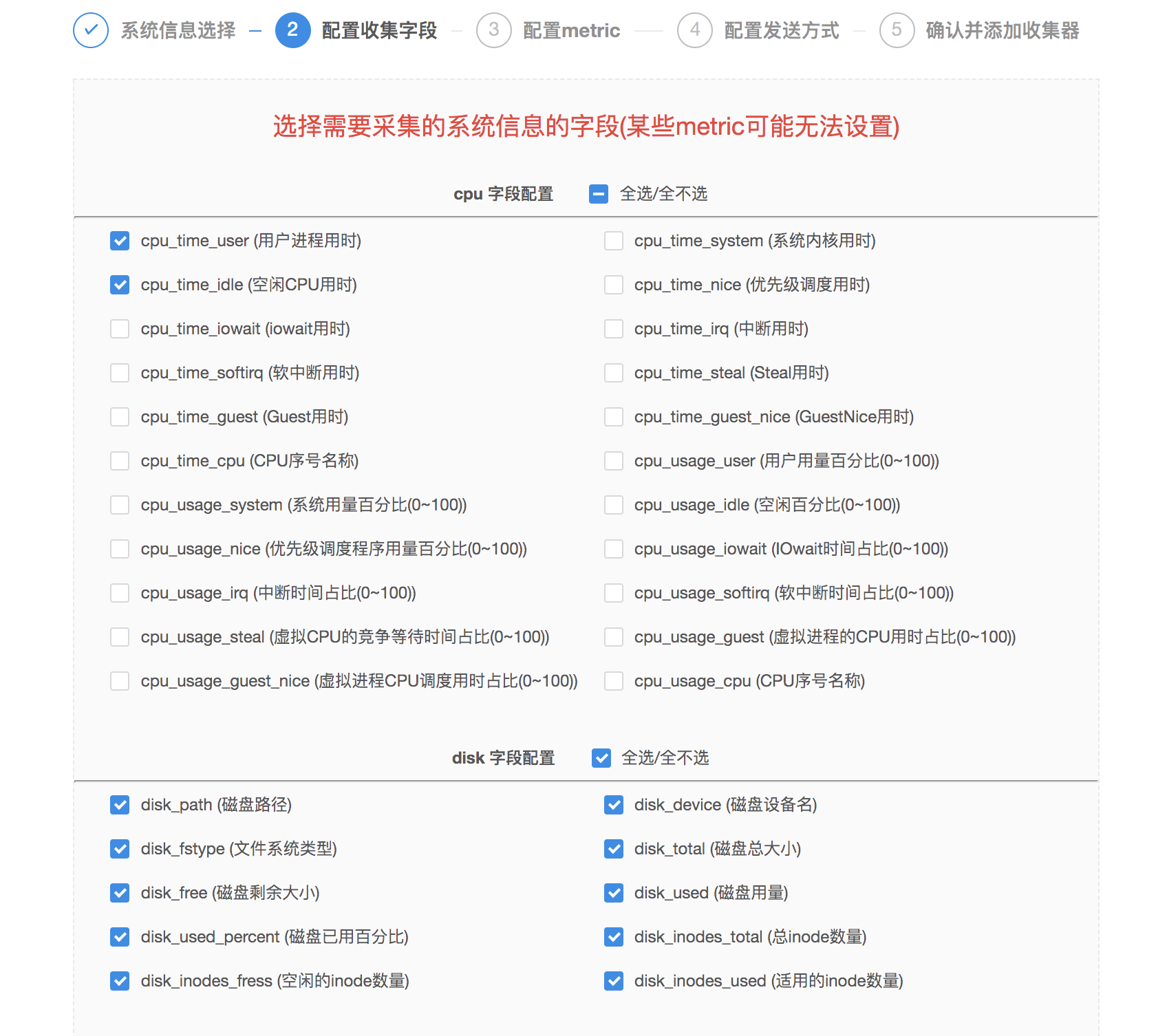
2.logkit 对每种信息类型预置了多种可供采集的字段,您通过勾选确定需要采集的系统信息的字段即可。
3.根据需要配置各种系统信息的metric。

4.配置好发送方式、确认添加收集器就完成您的系统信息采集配置啦!您可以在 Grafana 中监控系统运行情况。
采集系统信息使用场景
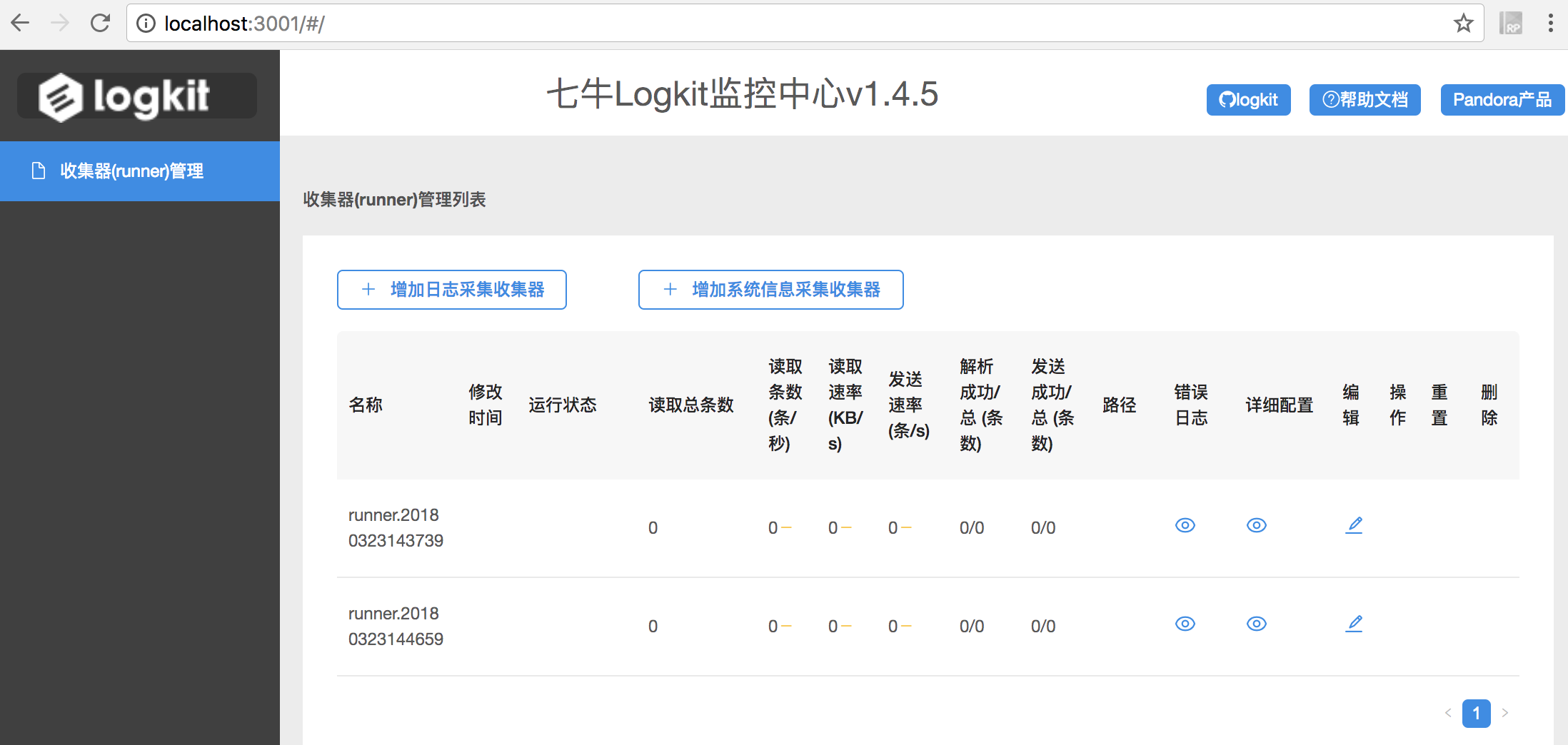
收集器(runner)管理
在 logkit 首页会显示您创建的所有收集器的相关信息:运行状态、读取的数据条数、读取速率、解析成功条数、发送成功条数等,并且可以对收集器进行编辑、重置、停止、重启和删除操作。
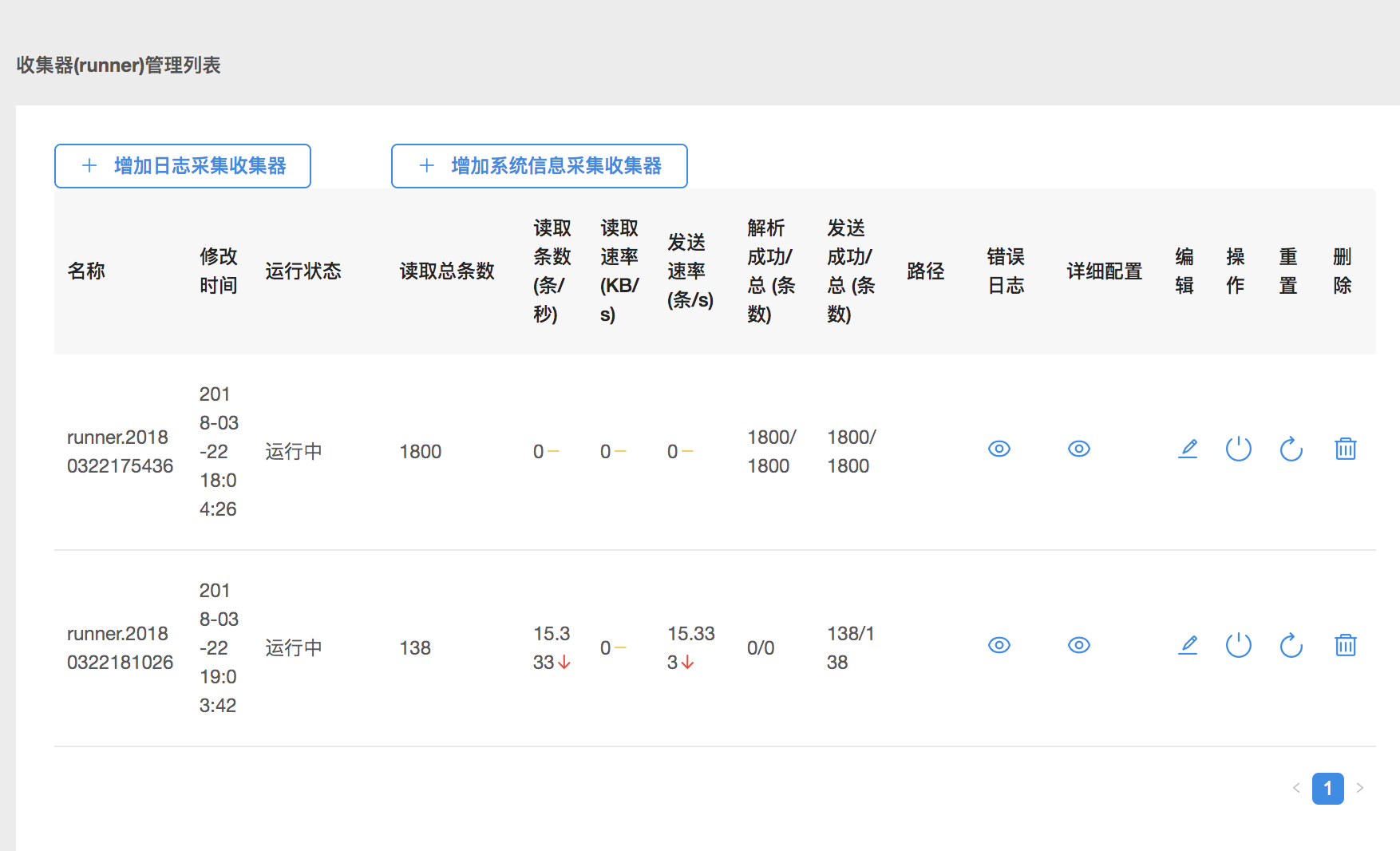
如果您创建的收集器的解析成功条数或者发送成功条数异常,您可以点击错误日志查看异常原因,然后点击编辑就可以修改收集器配置啦!
更多logkit相关功能请访问 logkit wiki。

若有收获,就点个赞吧
0 人点赞
