- 产品简介
- 快速体验
- logkit Pro 工作流程
- 用户指南
- 进阶与深入
- 数据源类型
- 数据解析方式
- 数据转换
- script Transformer
- pandora_key_convert Transformer
- urlparam Transformer
- Cloudtrail Transformer
- IP Transformer
- arrayexpand Transformer
- Convert Transformer
- Discard Transformer
- Date Transformer
- Replace Transformer
- Trim Transformer
- UserAgent Transformer
- k8stag Transformer
- JSON Transformer
- label Transformer
- rename Transformer
- split Transformer
- xml Transformer
- 数据发送
- 常见问题
产品简介
logkit Pro 官方网站
logkit Pro 概述
logkit Pro 是基于社区版 logkit 开发的一款面向企业的日志收集器管理平台,解决了开源 logkit 孤立运行无法统一管理的难题。致力于让企业在每台机器只安装一个 agent 的基础上,解决机器管理和运维监控的难题。
除了基础的数据读取、解析、转换、发送等功能,logkit Pro 提供了更友好的一键部署、机器监控、收集器统一分发、标签管理、监控告警等功能,弥补了开源 logkit 在规模化后管理上的缺陷。
让我们一起先来快速体验 logkit Pro 方便的日志解析、转换和发送功能吧。
快速体验
您可以通过快速体验功能迅速开始体验 logkit Pro 的数据采集、解析与发送功能。
步骤1:配置数据源
进入 logkit Pro 快速体验页面。

快速体验支持通过上传本地的日志文件、系统生成的随机数据、手动输入数据三种方式接入数据源。
- 直接上传本地文件,上传完毕点击
获取数据,验证上传是否成功:
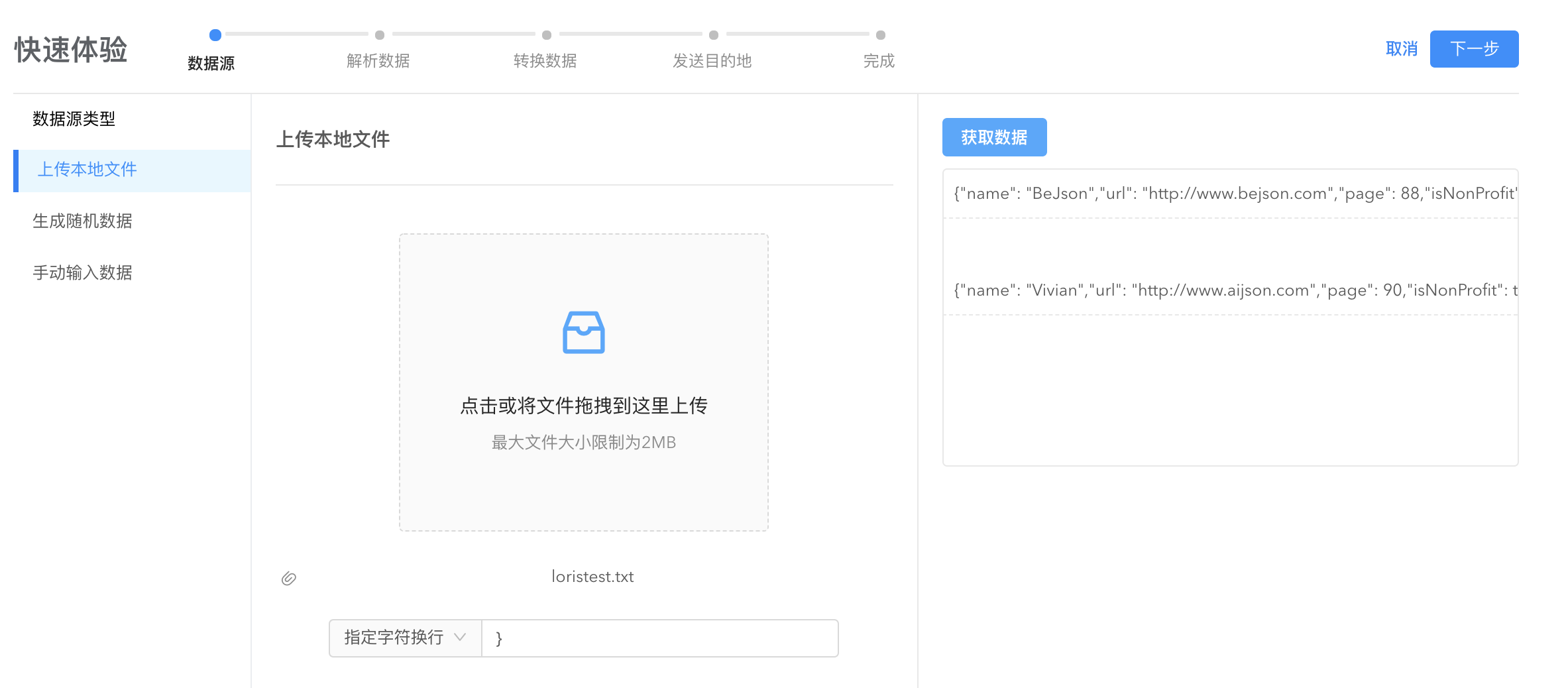
- 使用
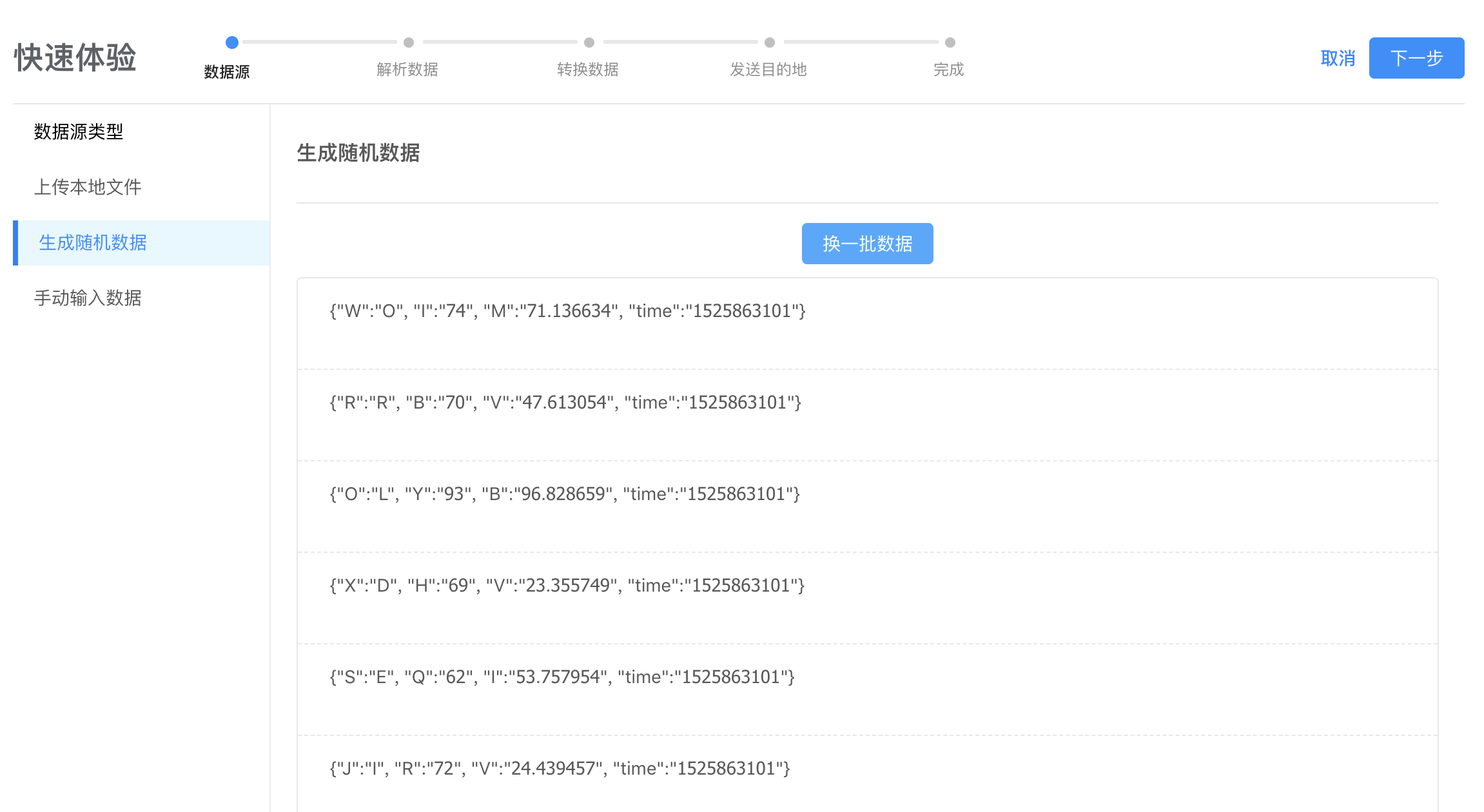
生成随机数据功能,使用系统随机生成的数据开始您的收集数据体验之旅,其中,您可以修改随机数据来玩转 logkit Pro 收集数据的功能。
- 如果本地文件和随机数据都没有您想要体验的数据,可以通过手动输入数据快速开始体验:
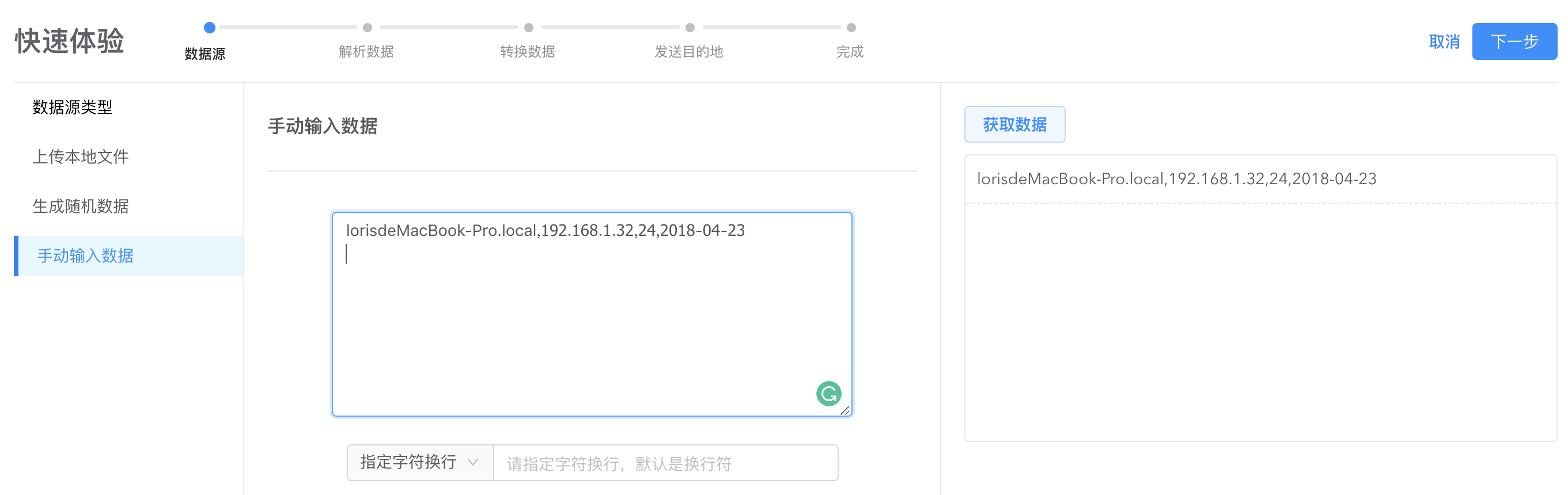
logkit Pro 快速体验支持字符换行和正则换行两种方式来规范您的数据源数据的格式:输入换行规则,点击获取数据,数据内容会按指定的格式显示。默认情况下是以换行符分隔数据。
步骤2:解析数据
根据数据源数据格式配置合适的解析方式来结构化数据内容, 方便后续在数据平台进行数据计算和分析。
logkit Pro 提供 json、csv、grok 等格式的数据解析,根据需要在左侧栏选择解析方式。
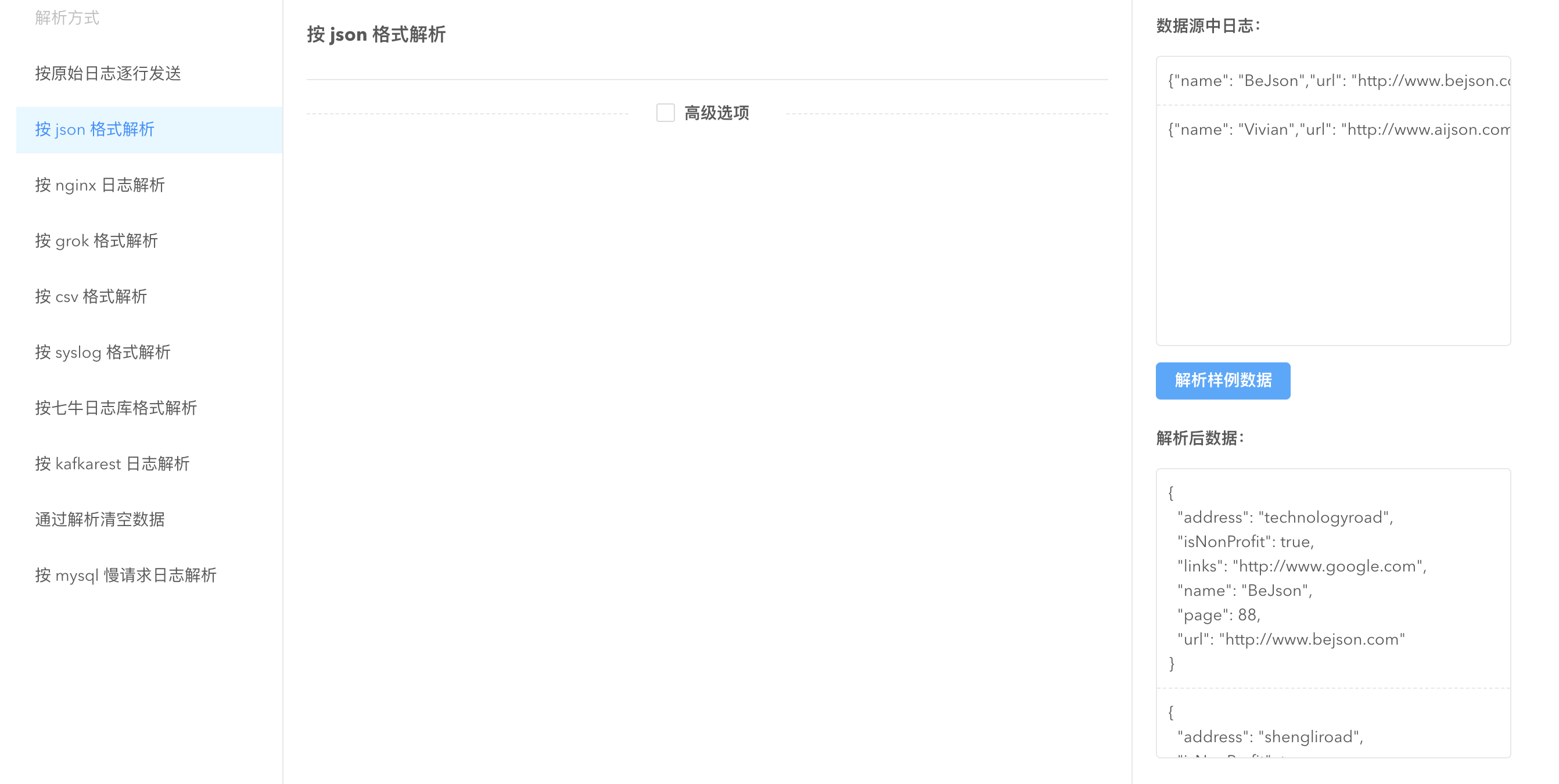
以 json 解析方式为例:
对上传的 json 格式文件,选择按 json 格式解析,
json 格式的解析无需任何配置,点击解析样例数据查看解析结果,验证您的配置的解析方式是否正确。您可以自行尝试其他数据格式的解析,感受 logkit Pro 强大便捷的一键解析功能。
步骤3:转换数据
灵活运用 logkit Pro 的转换数据功能,您可以实现更精细的字段解析。如将 ip 字符串扩展为 ip 对应的区域、城市、省份、运营商等信息,或者将指定字段解析为时间等。logkit Pro 支持包括字符串替换、ip 扩展、数组转换等多种数据变换方式,详情参考转换数据。
以字符串替换(rename)为例,rename 转换功能对字段进行重新命名:

选择进行变换的原字段名并填写新字段名,点击添加转换功能才会生效。点击转化样例数据,查看转换效果。您可以根据需求在同一个数据收集器里配置多个数据转换。
如果没有这一部分的需求,跳过这一步即可。
步骤4:发送数据
这一步可以将您的日志数据导入到七牛大数据平台,通过工作流任务的计算后,再将计算结果导出到您指定的数据分析产品中:日志仓库、时序数据库或者云存储。

查看数据
这样,您的数据就收集好啦!现在您可以去下游产品如日志仓库查看刚才收集的数据或者在工作流对数据进行计算。
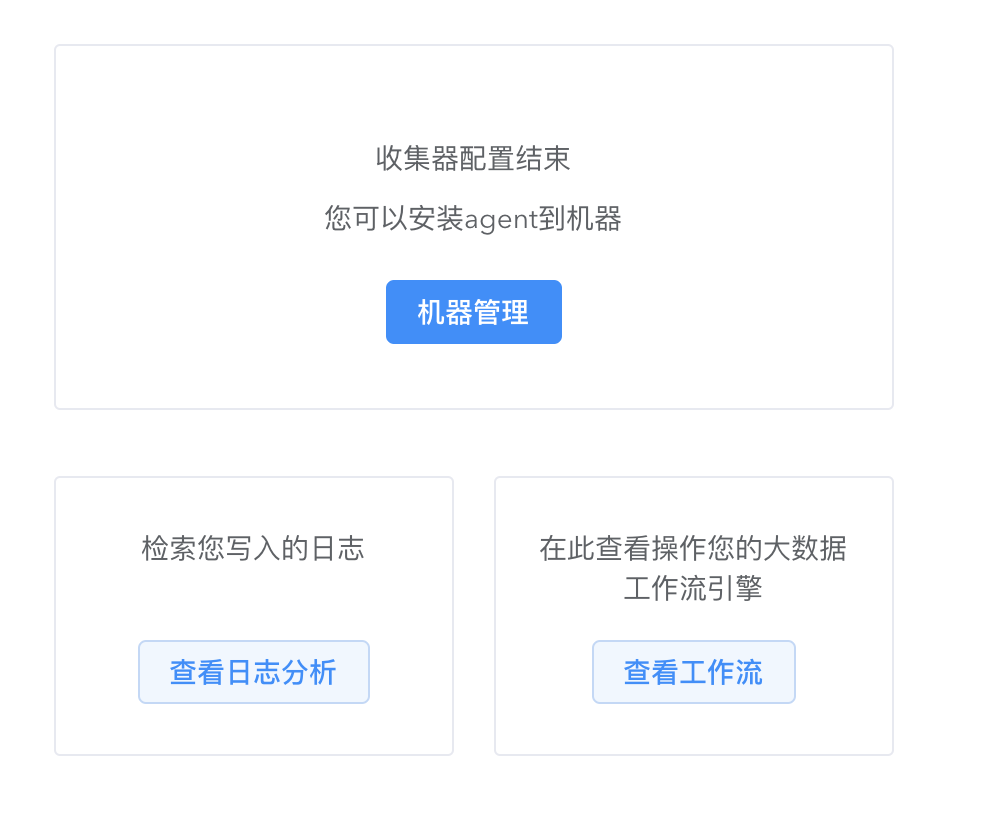
您已经体验了 logkit Pro 简单且有趣的数据收集功能,现在让我们全面了解 logkit Pro 。
logkit Pro 工作流程
logkit Pro 通过如下图的工作流程实现对机器和收集器的统一管理。

- 首先需要安装 agent 以便将您的机器添加上来,在机器上执行安装脚本即可。
- 其次就是按照您的业务添加收集器,收集器添加的过程可以通过 agent 获取实际的业务数据,进行一系列校验。
- 有了收集器,就可以将收集器分发到不同的机器上。
- 针对不同的业务组,可以将机器设置不同的标签,收集器也可以针对标签统一发送。
用户指南
安装 logkit Pro 到机器
进入 logkit Pro 官网,点击【机器管理】-> 【添加机器】,进入安装页面,logkit Pro 提供自动录入和手动安装两种方式添加机器。
- 手动安装:点击【复制地址】,就可以获取我们提供的一键式安装脚本。
在安装之前,您可以为机器指定一个标签来统一管理同一个业务下的机器。
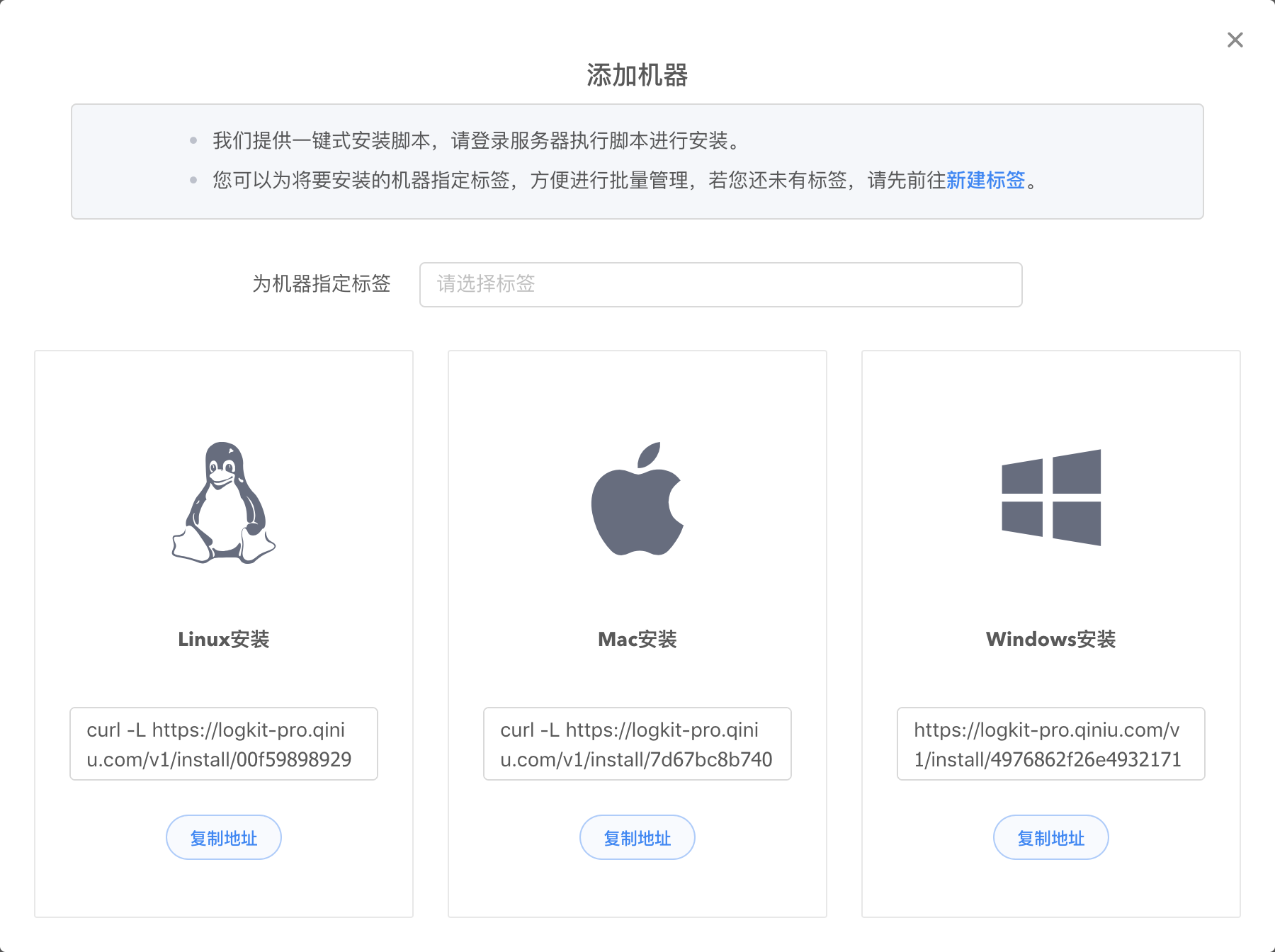
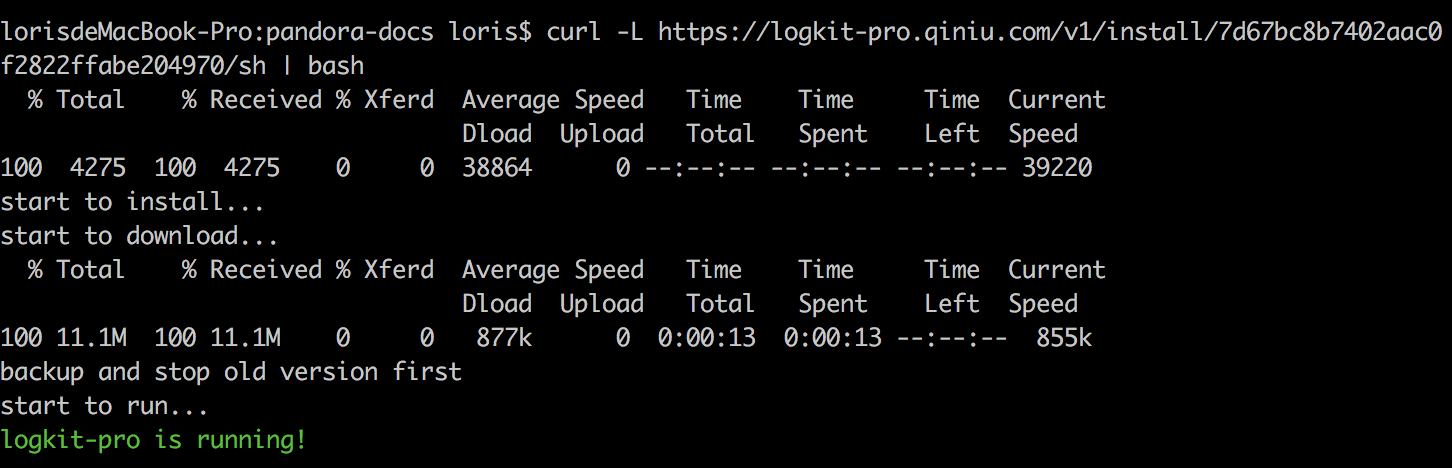
对于linux或mac用户来说,直接在控制台粘贴并执行复制的命令即可。
对于windows用户,将复制的url在浏览器打开,将内容复制到文本文件中,并另存为 logkit.vbs,再双击执行 logkit.vbs 脚本安装。
- 自动录入:输入机器 ip、ssh 端口、用户信息等在服务器上安装 Agent。

安装好以后您可以在【机器管理】列表看到机器的相关信息,如机器所属标签、机器里的所有收集器、机器地址等,详细信息阅读机器管理。
收集数据
在机器上安装好 logkit Pro 之后就可以开始收集数据。进入数据收集页面,点击添加收集器开始配置收集器。
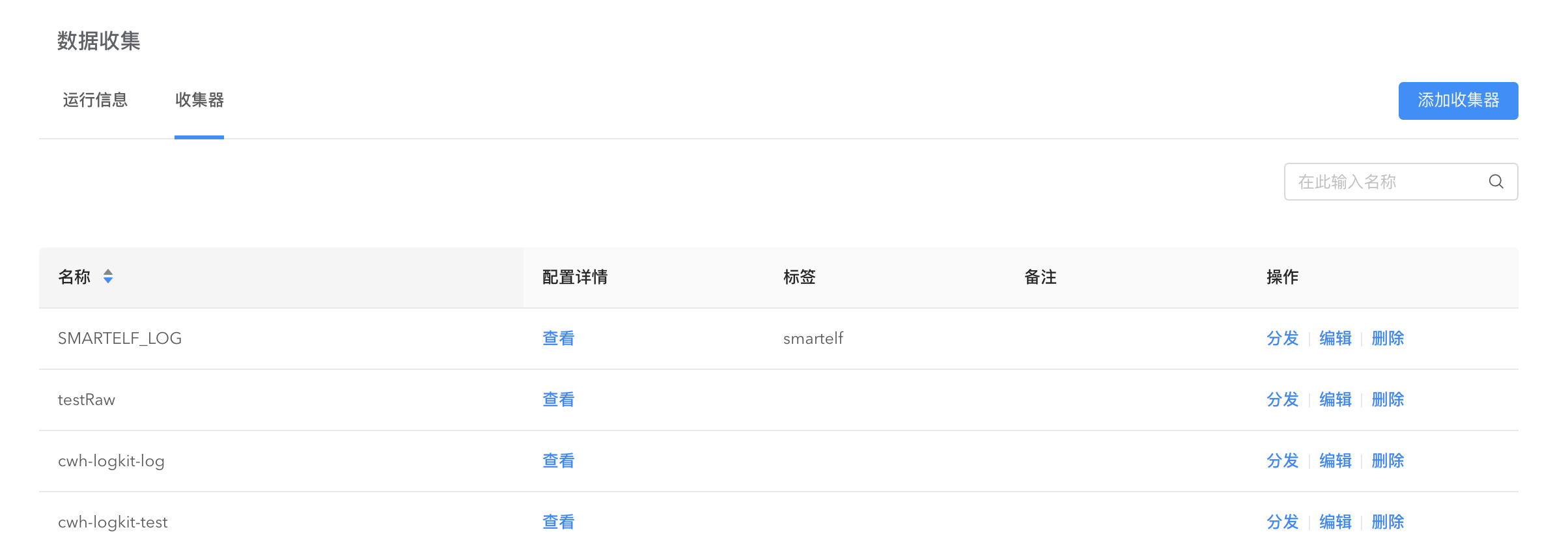
获取数据
第一步是接收数据源,logkit Pro 支持多种数据来源和读取模式,根据需要在左侧列表选取。
填写好配置信息之后,选择您添加的 agent,点击【获取数据】,系统将使用您的配置,让 agent 去获取实际的数据,并且展示样例数据以验证您的配置是否正确。
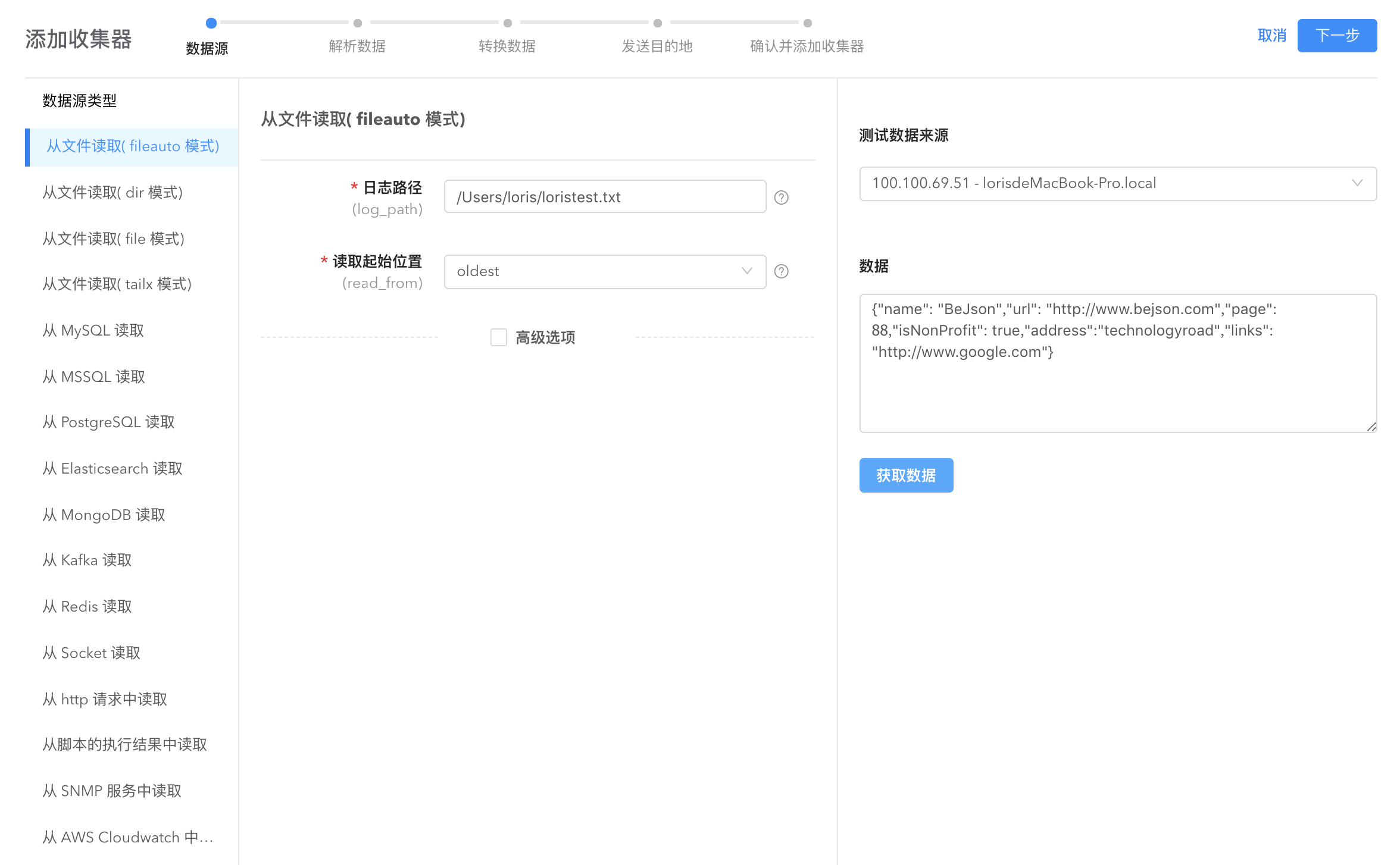
默认不需要配置高级选项,高级选项保持默认值即可。
logkit Pro 支持的采集数据源
- File: 读取文件中的日志数据,包括 csv 格式的文件,kafka-rest 日志文件, nginx 日志文件等,并支持多种读取模式(fileauto、dir、file、tailx)
- MySQL: 读取 MySQL 中的数据。
- MSSQL: 读取 Microsoft SQL Server中的数据。
- Postgre SQL: 读取 PostgreSQL 中的数据。
- ElasticSearch: 读取 ElasticSearch 中的数据。
- MongoDB: 读取 MongoDB 中的数据。
- Kafka: 读取 Kafka 中的数据。
- Redis: 读取 Redis 中的数据。
- Socket: 读取 tcp\udp\unixsocket 协议中的数据。
- Http: 作为 http 服务端,接受 POST 请求发送过来的数据。
- Script: 支持执行脚本,读取执行结果中的数据。
- Snmp: 主动抓取 Snmp 服务中的数据。
- AWS CloudWatch: 主动抓取 AWS CloudWatch接口中的数据。
- AWS CloudTrail: 主动抓取 AWS CloudTrail中的数据。
关于数据源类型以及高级选项详细介绍,请阅读数据源类型。
解析数据
第二步,根据数据源配置合适解析方式,抽取数据中的字段,转化为结构化数据,充分保障您的配置一定能在实际场景中生效。logkit Pro 支持多种格式的日志解析,按需选取并填写相应的配置信息即可。
按grok格式解析
通过配置 grok pattern 解析,将文本格式的字符串转化为结构化的数据。使用 grok 解析日志内容会使得日志分析更加容易。logkit Pro 提供默认匹配日志的 grok 表达式、grok 划词以及自定义 grok 表达式三种方式进行解析。
- 默认 grok 表达式:
使用系统匹配日志的 grok pattern 来解析您的数据:
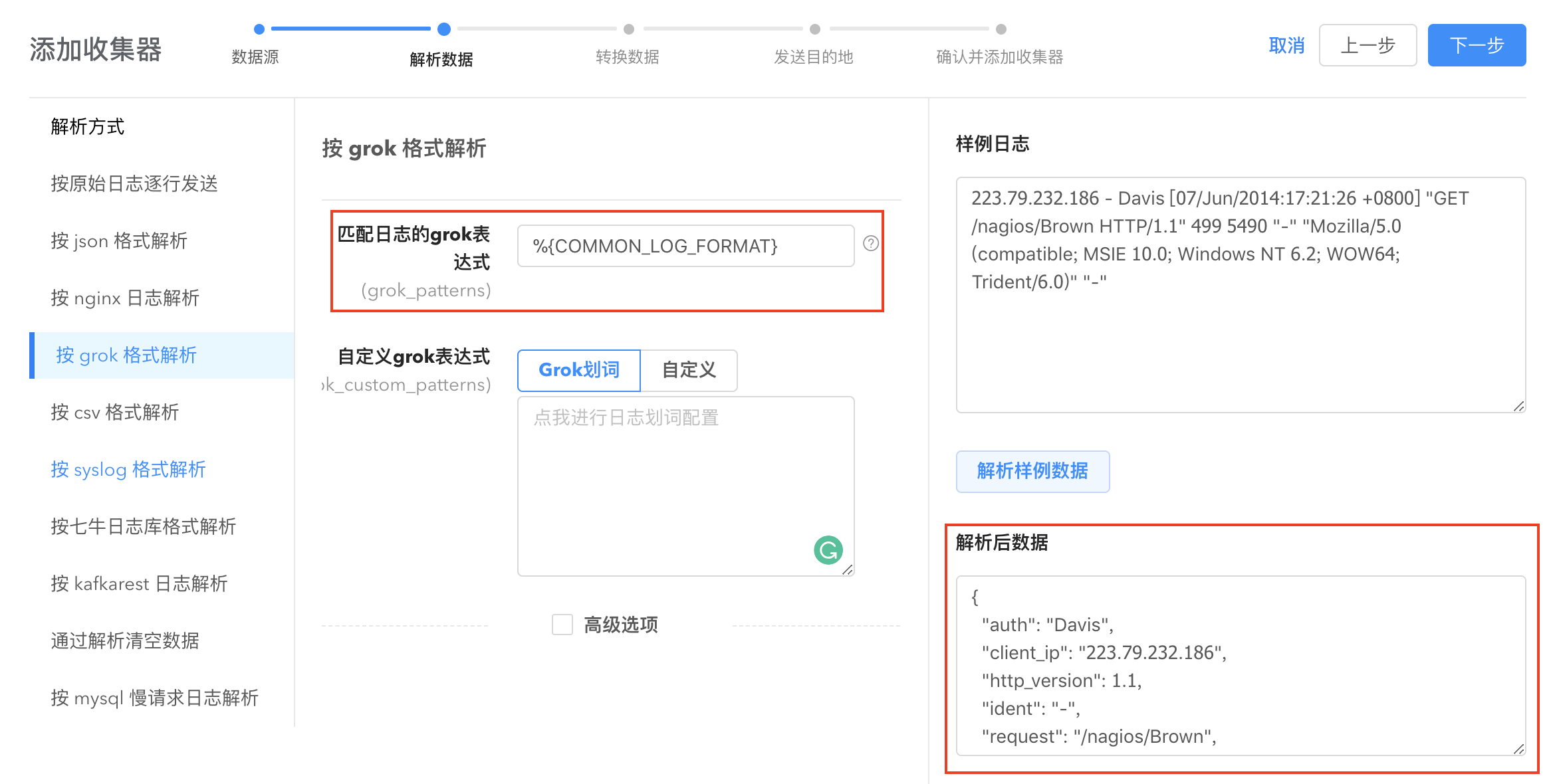
- 如果默认 pattern 解析没法满足您的需求,logkit Pro 支持自定义 grok pattern。
grok划词
通过在数据上划词解析数据:在数据上点选数据内容,系统会自动匹配 grok 变量生成 pattern,字段名、字段类型与 grok 变量均可编辑。通过划词生成的 pattern 以及 划词解析后的数据均可见。
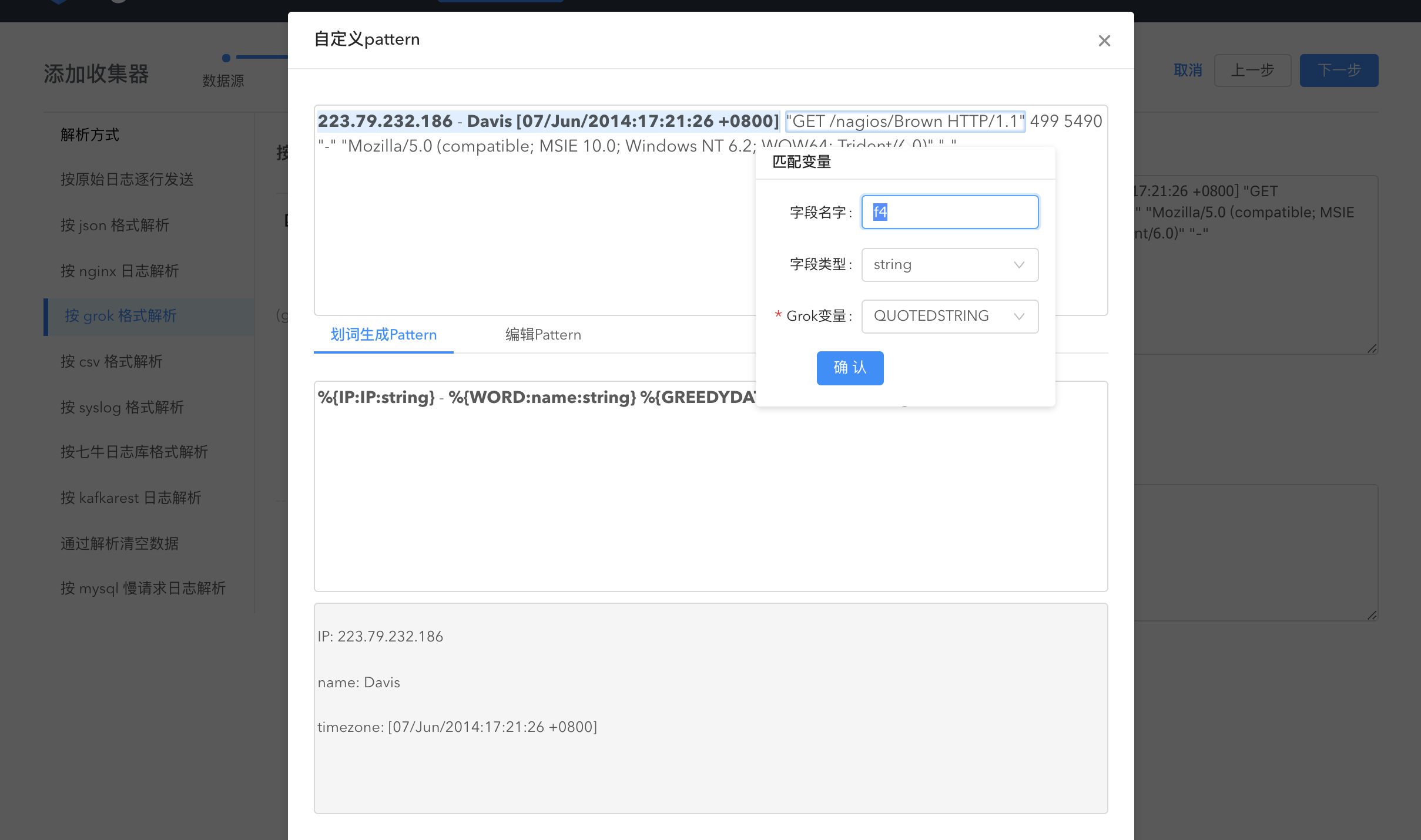
如果部分数据内容无法全部用划词解析,您还可以编辑 pattern。
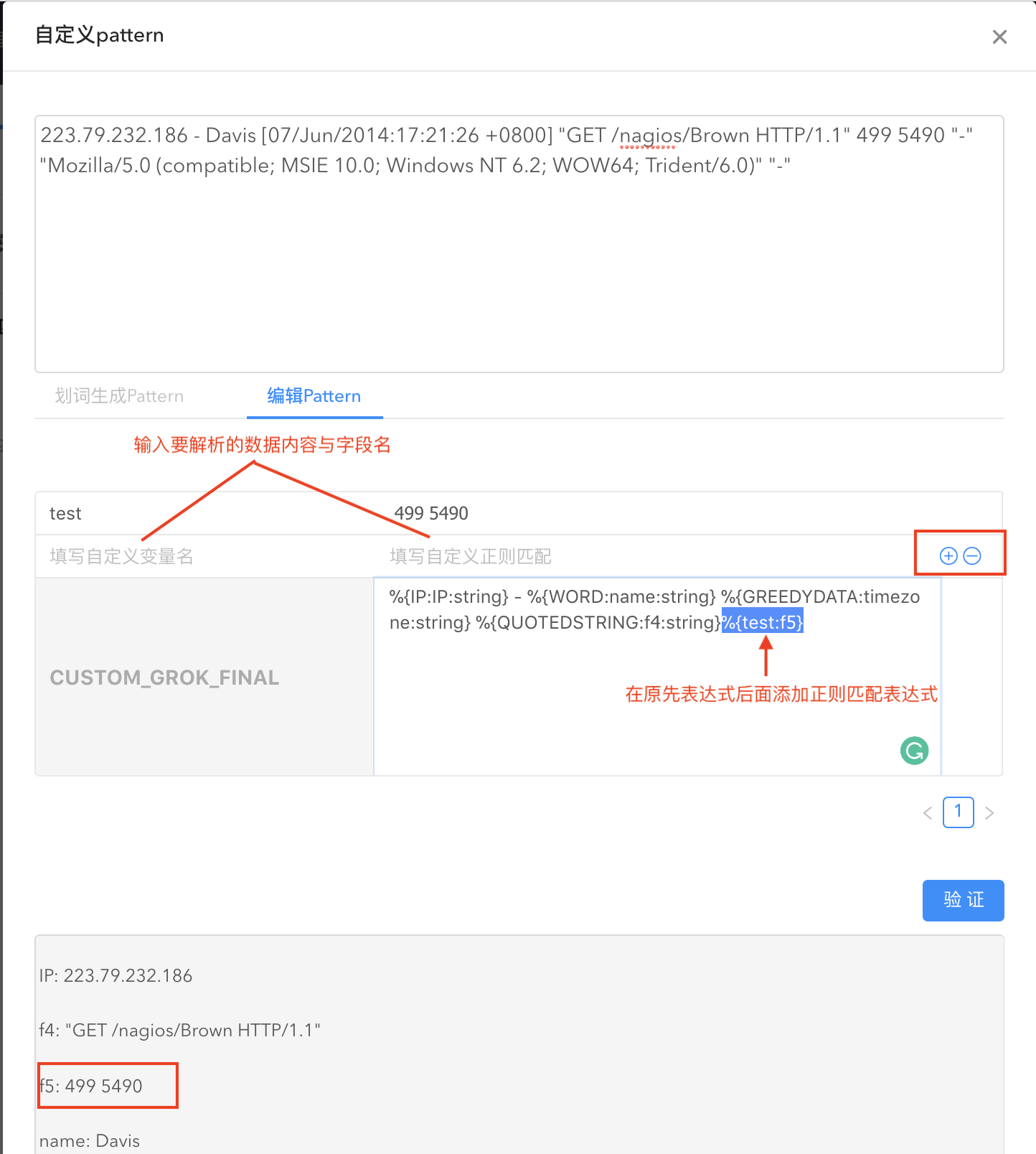
点击验证即查看解析结果。
您也可以直接输入自定义 pattern。

其他解析方式:
按原始日志逐行发送:直接按行读取日志内容。
按 json 格式解析:通过 json 反序列化解析日志内容,无需任何配置,系统根据日志内容自动解析。
按 csv 格式解析:按分隔符解析日志。
按 nginx 日志解析:专门解析 Nginx 日志。仅需指定 nginx 的配置文件地址,即可进行 nginx 日志解析。
按 syslog 格式解析:自动解析系统日志
七牛日志库格式解析: 七牛开源的 golang 日志库日志格式解析
按 kafkarest 日志解析: Kafkarest 日志解析
通过解析清空数据:清空读取的数据
按 mysql man 请求日志解析: mysql 慢请求日志解析
关于其他数据解析方式的详细解说,请阅读数据解析方式。
转换数据
logkit Pro 提供数据转换功能来满足一些更精细的字段解析需求。
在大多数场景下,用 Parser 解析就解决了问题,但是有些场合,用 Parser 来做数据解析可能过于简单,如 json parser。如果数据里面有一部分字段您希望做一些扩展,比如有个 IP 字符串,您希望将其扩展为 IP 对应的区域、城市、省份、运营商等信息,此时您就可以配置一个 Transformer,对 IP 字段进行转换。
再比如,当您希望做一些字符串替换的时候,只针对某个字段做一个字符串替换处理,那就可以配置一个 replace transformer。
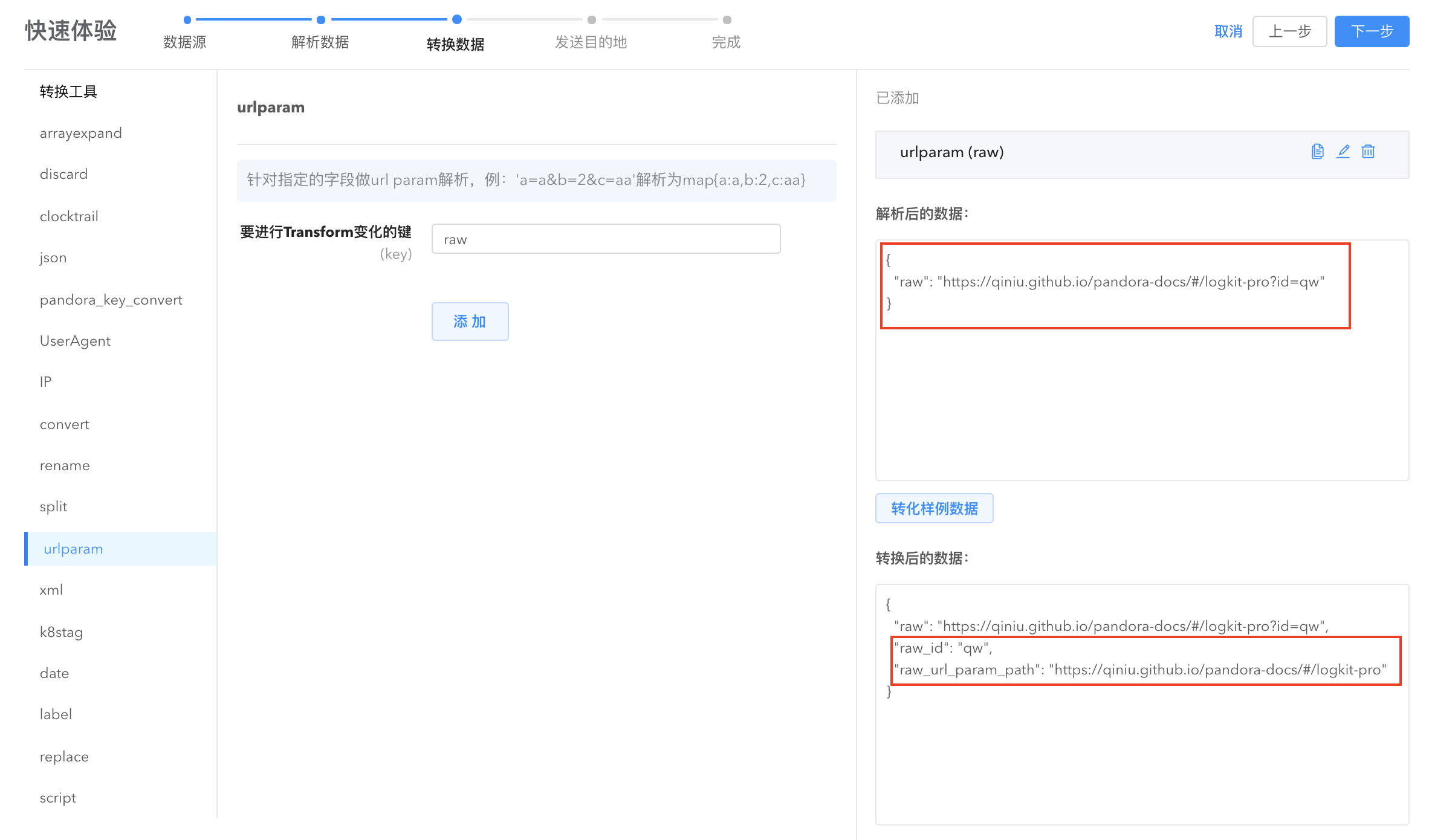
- urlparam: 将指定字段的内容按照 url 参数的格式转换为键值对。
- arrayexpand: 将数组字段展开并转换为键值对。

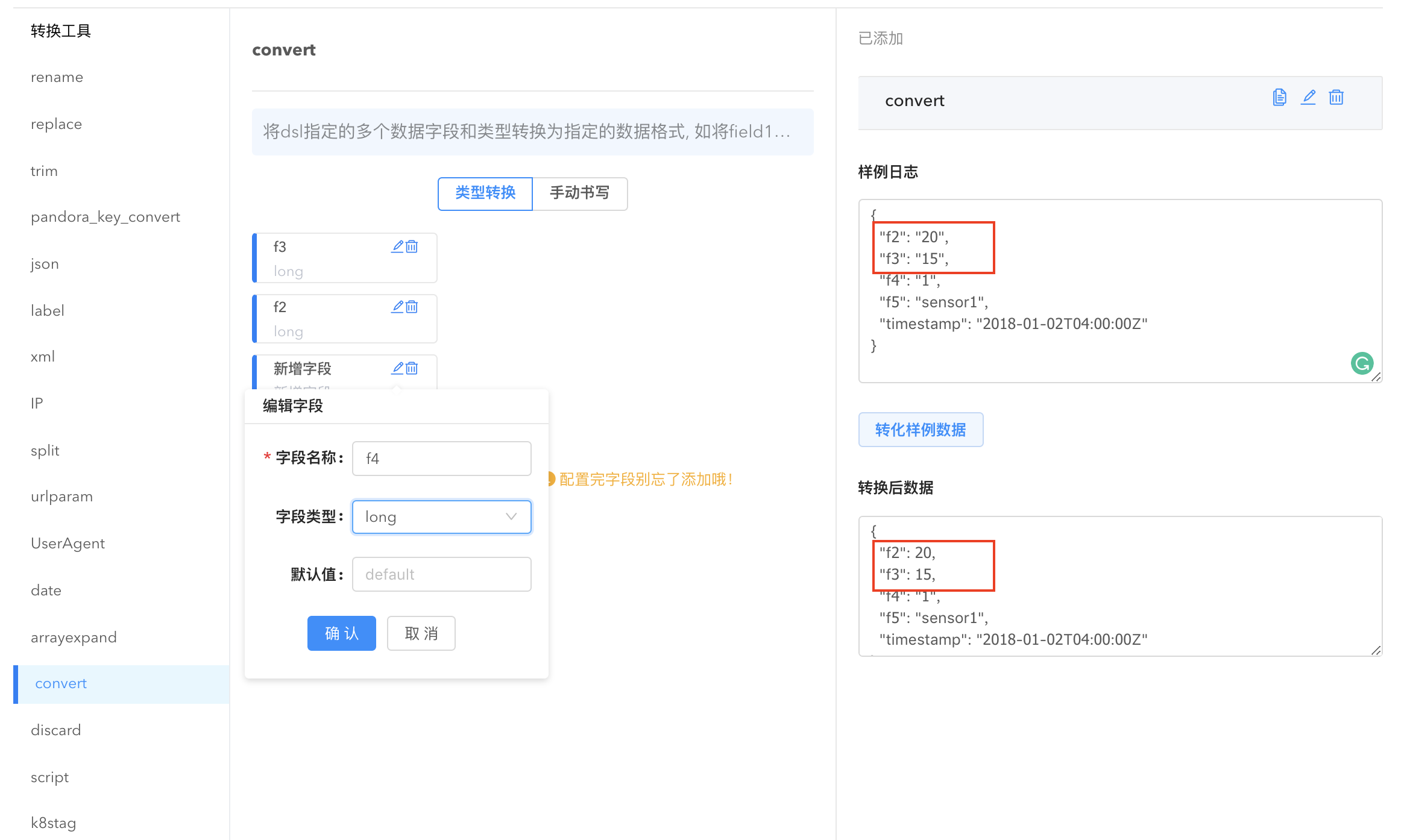
- convert: 转换数据格式。点击
新增转化字段,选择需要转换的字段名,给它指定字段类型即可完成数据格式的转换,也可手动书写 dsl 描述将数据类型转换为指定的格式。
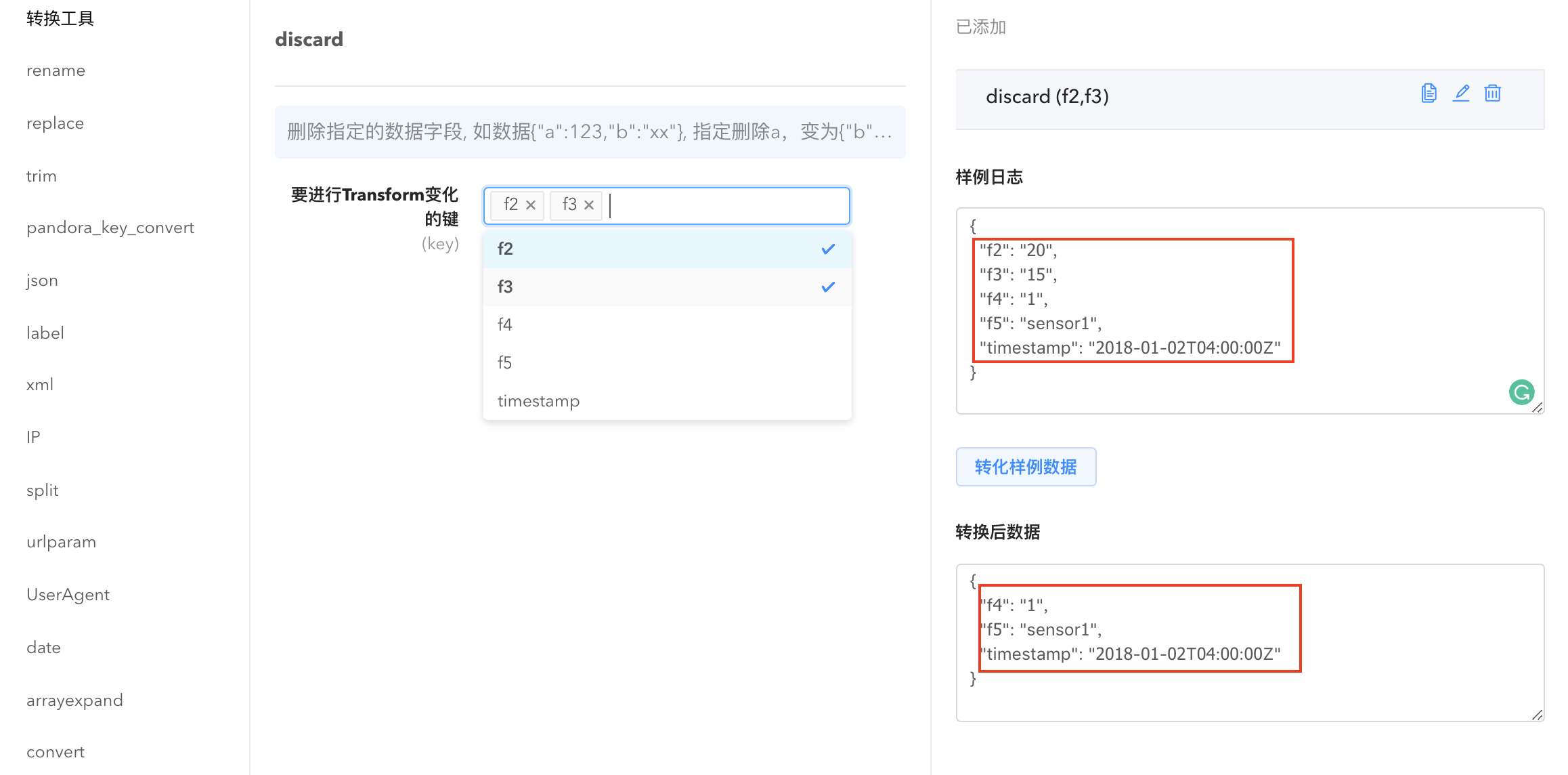
- discard: 将指定字段的数据抛弃,可以同时选择多个字段一键删除。
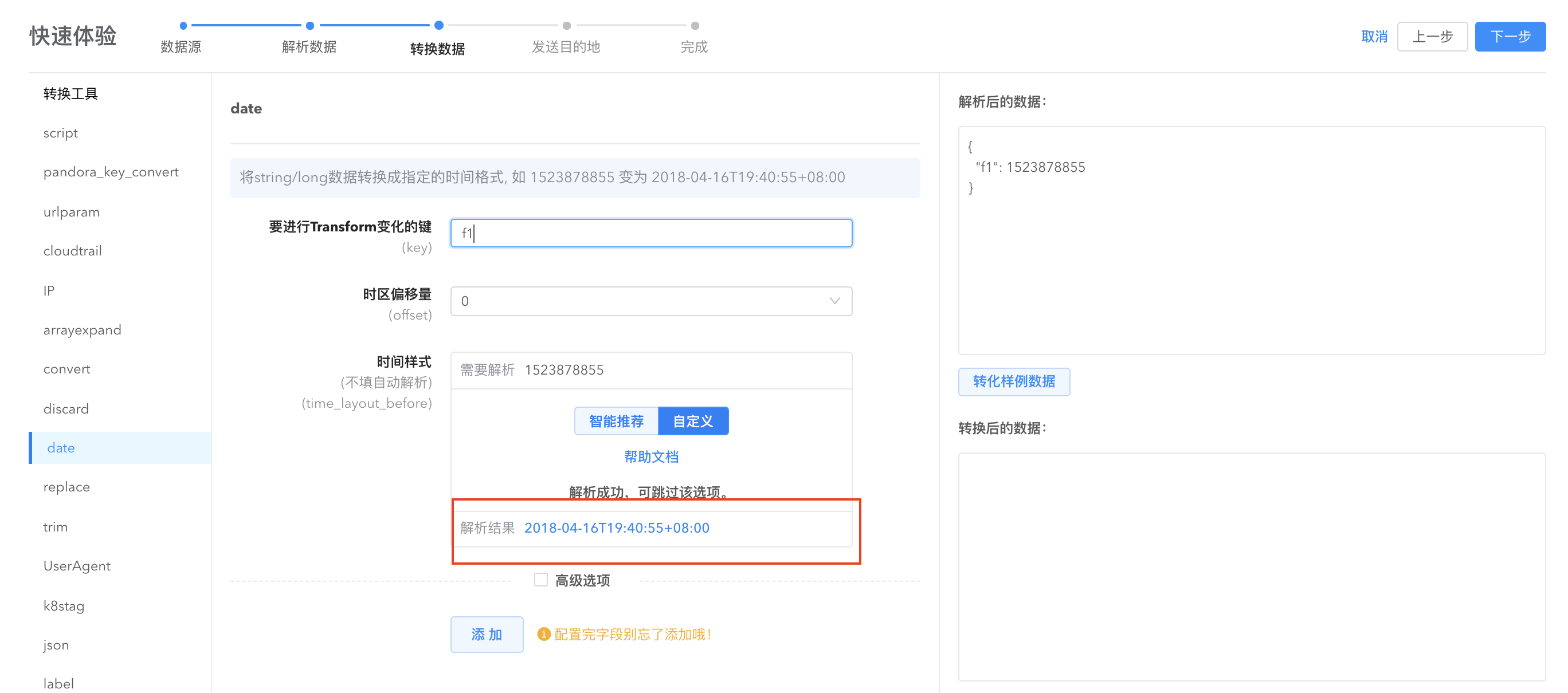
- date: 将 string/long 数据转换成指定的时间格式, 如 1523878855 变为 2018-04-16T19:40:55+08:00 。或者对时间字段进行时区转换。系统根据用户选择的 key 自动解析。
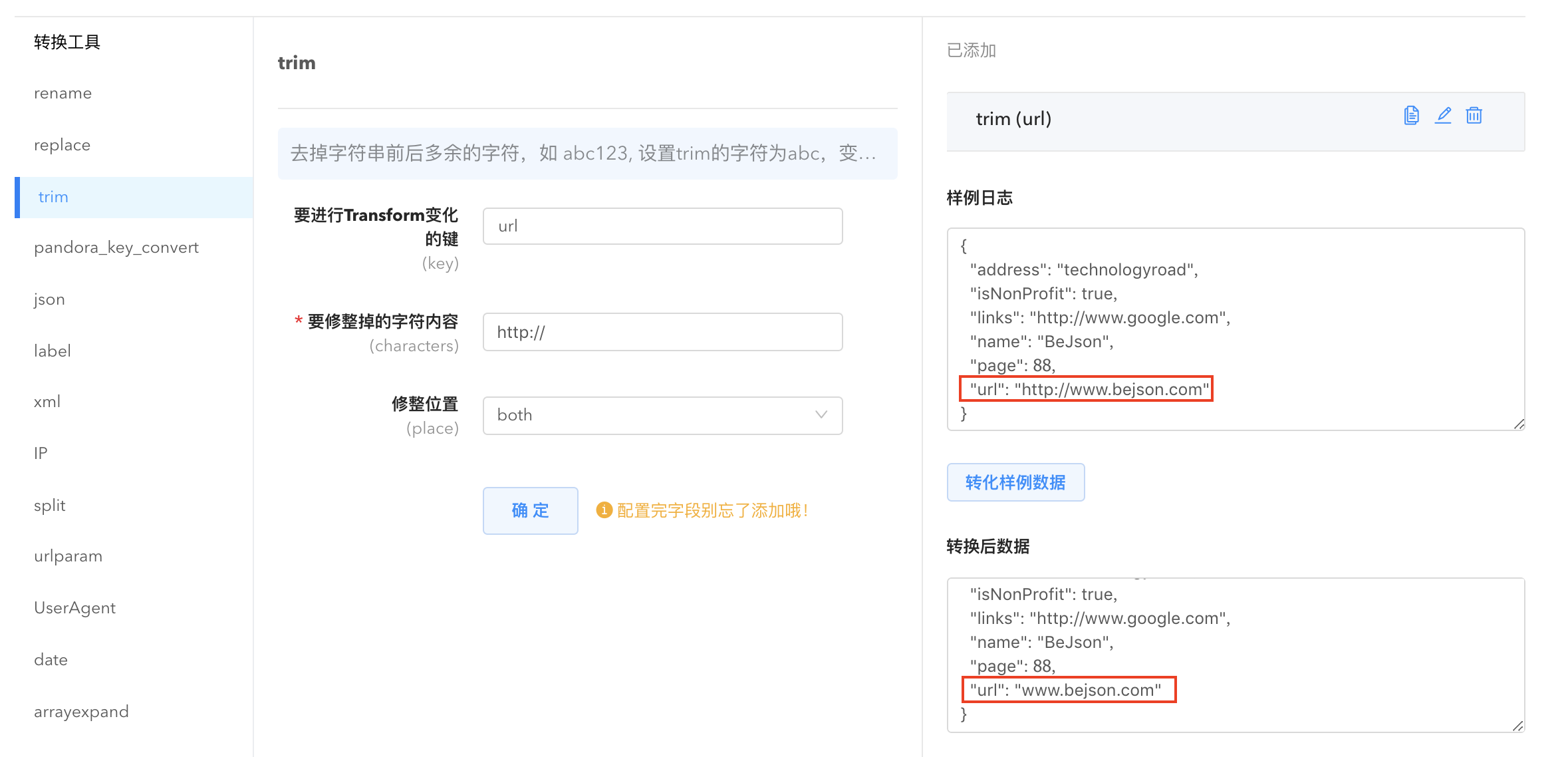
- trim: 去掉字符串多余的字符。
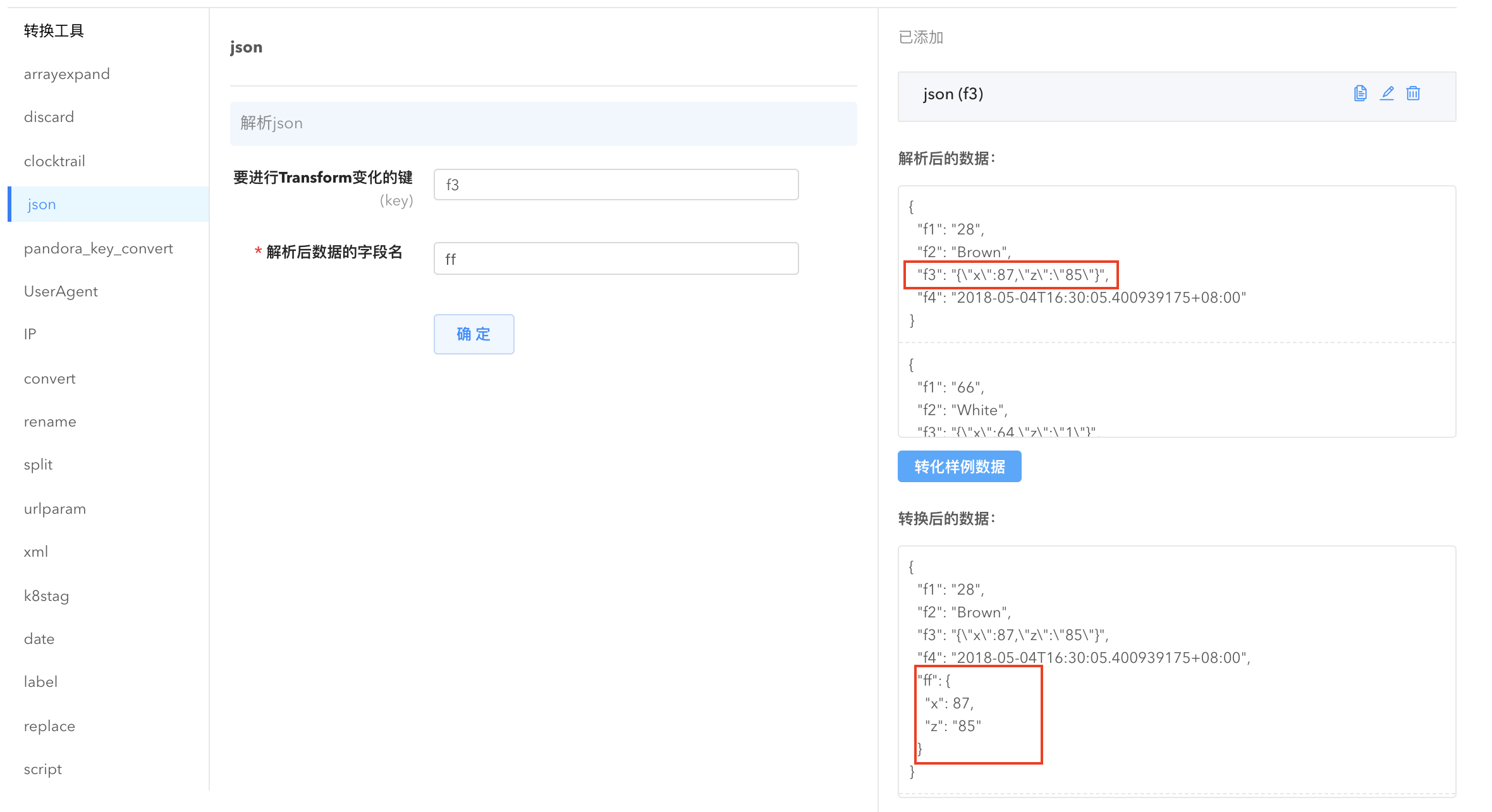
- json: 将一个符合json格式的字符串字段,反序列化为对应结构体类型。
rename: 将字段名称重命名,解决不同下游系统对字段名称中特殊字符不支持的问题。
split: 将指定字段的数据切分为字符串数组。

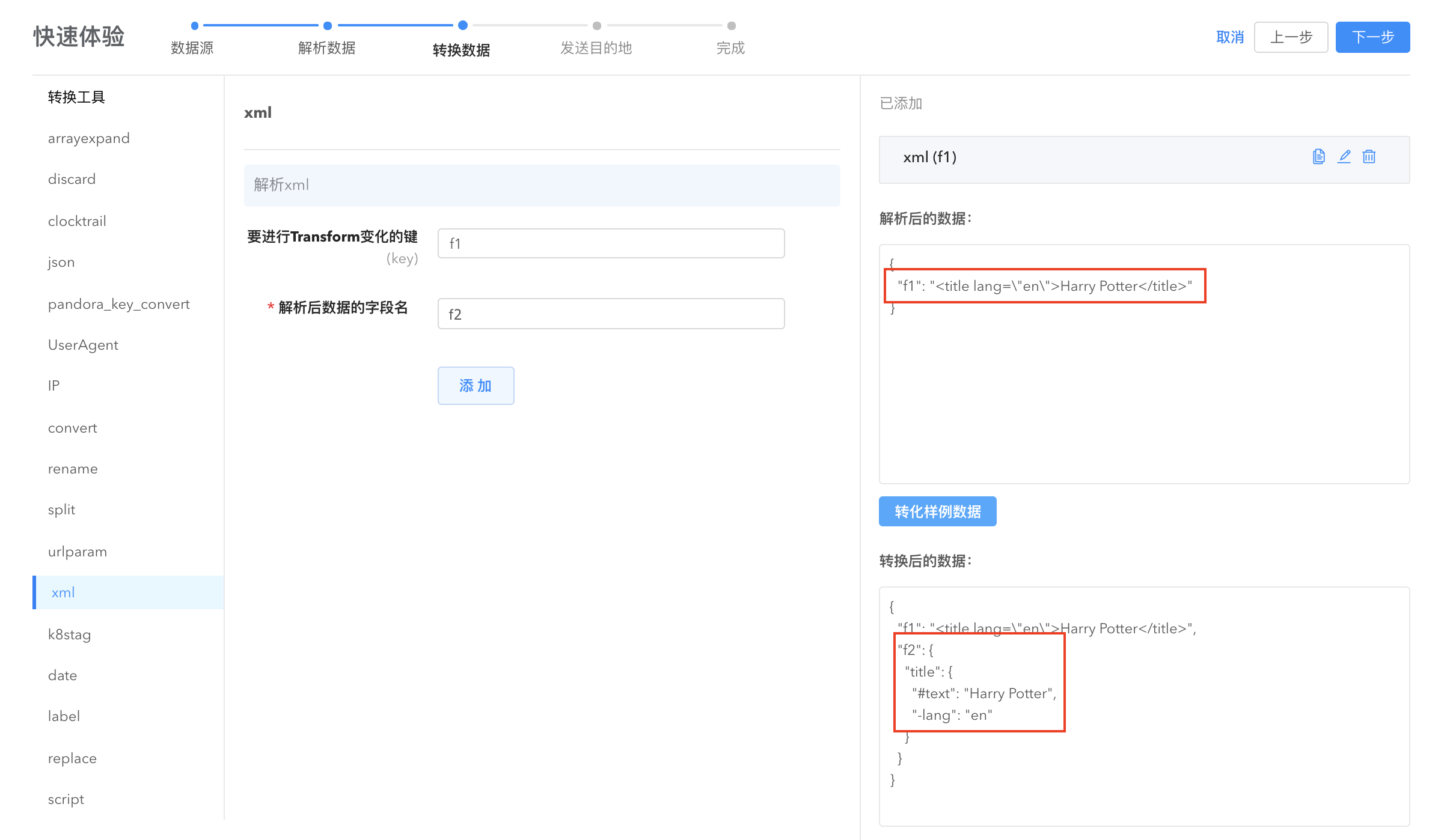
- xml: 将一个符合xml格式的字符串字段,反序列化为对应 map[string]interface{} 结构体类型。
其他字段转换功能:
- script: 执行脚本文件,并将脚本结果加入到数据中。
- pandora_key_convert: 将不符合 Pandora 字段命名规则的 key 字符转化为下划线。
- cloudtrail: 针对 AWS CloudTrail 的数据做格式转换,将 CloudTrail 的 json 格式中的 Records 逐条变为数据。
- IP: 针对 ip 做运营商信息字段扩展。
- replace: 替换原有的字符串内容。
- UserAgent: 浏览器中的 user agent 信息解析,可以解析出包括设备、操作系统、版本号在内的多种信息。
- k8stag: 从 kubernetes 存储的文件名称中获取 pod、containerID 之类的 tags 信息进行转换。
- label: 增加标签,添加一个带有固定值的字段到数据中。
关于数据转换方式的详细介绍,请阅读数据转换。
发送数据
logkit Pro 支持多种数据发送平台如七牛大数据平台、MongoDB、InfluxDB 等,根据需要在左侧列表选取。完成这一步就可以在数据平台进行后续数据计算、分析、查看。典型地,发送数据至七牛大数据平台后,数据可以在workflow进行数据计算和导出。

logkit Pro 支持的数据发送平台
- Pandora Sender: 发送到七牛大数据处理平台(Pandora)。
- File Sender: 发送到本地文件。
- MongoDB Accumulate Sender: 聚合后发送到 MongoDB 服务。
- InfluxDB Sender: 发送到 InfluxDB 服务。
- 消费数据但不发送:不执行发送行为。
- Elasticsearch Sender: 发送到 ElasticSearch 服务。
- Kafka Sender: 发送到 Kafka 服务。
- Http Sender: 以 Http POST 请求的方式发送数据。
关于数据发送平台配置的详细介绍,请阅读数据发送。
配置收集器操作案例可参考快速体验。
分发收集器
收集器配置好之后,将收集器分发到指定的机器实现收集器的统一管理。
点击【数据收集】->【收集器】进入收集器的分发和编辑。

点击分发,可以将收集器分发到机器或者直接分发到标签。

点击编辑,可以更新收集器配置。
查看收集器运行信息
完成收集器的分发后,收集器就在机器成功运行。点击【数据收集】->【运行信息】即可查看收集器的运行信息,如运行时间、读取成功条数、解析成功条数、错误日志等,结合详细配置信息,及时查错。在这里您可以对每个收集器进行停止、重启、删除操作。

机器管理
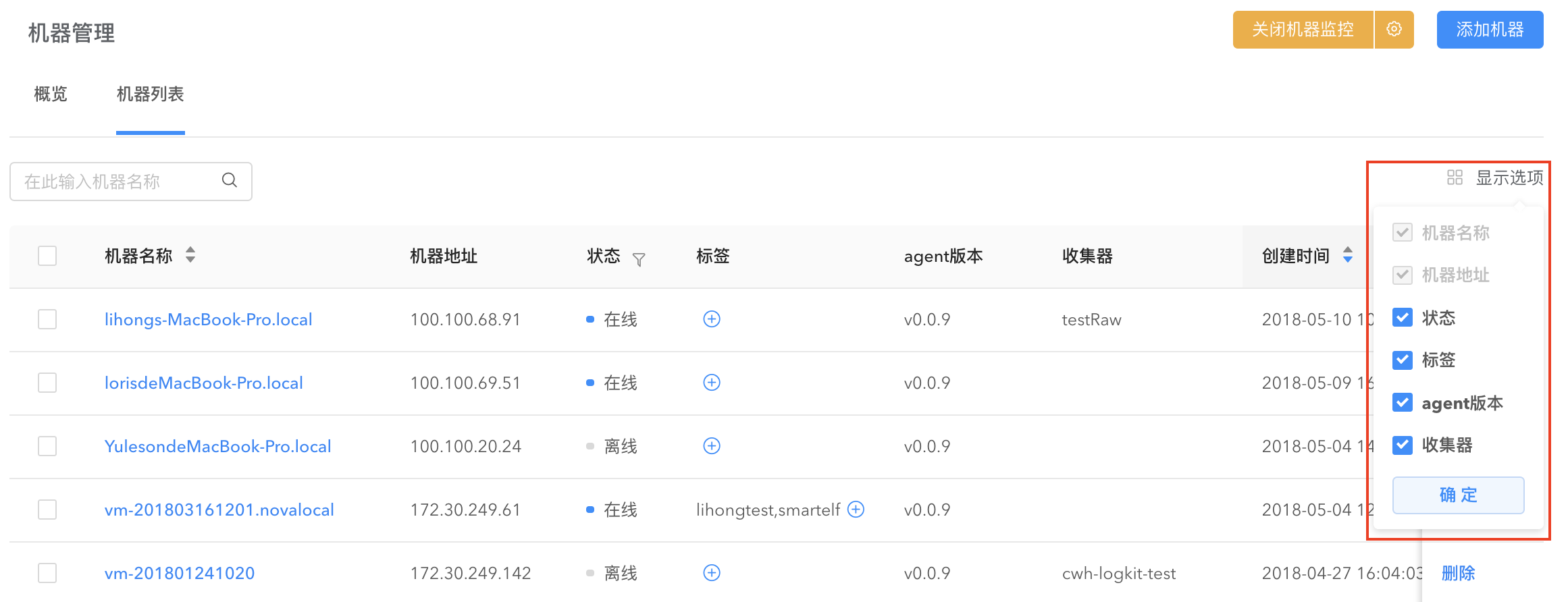
通过【机器管理】对机器运行状态进行监控。在【机器管理】界面可以看到已经添加进来的机器列表,显示机器地址、机器状态(在线、离线)等、该机器下的收集器等信息。
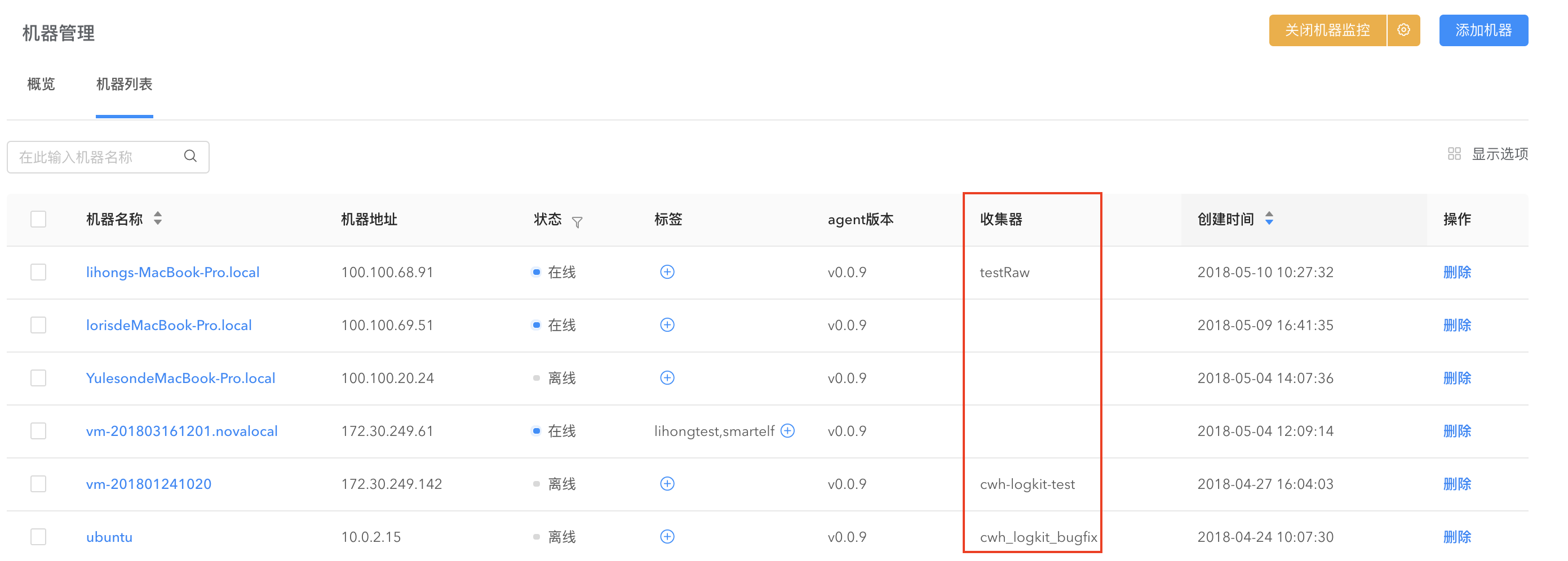
在右上角的显示选项勾选您感兴趣的显示信息。默认情况下,收集器信息不显示,需要手动勾选。
机器监控
logkit Pro 支持采集机器以及机器上部署的常见基础组件的各类指标数据对机器性能进行监控。
点击右上角【启动机器监控】,输入数据收集时间间隔与数据源名称收集机器性能信息并保存到 repo。之后您就可以在下游数据分析平台如 TSDB 查看机器性能数据。

启动机器监控以后,点击机器名称即可直接看到机器性能数据。

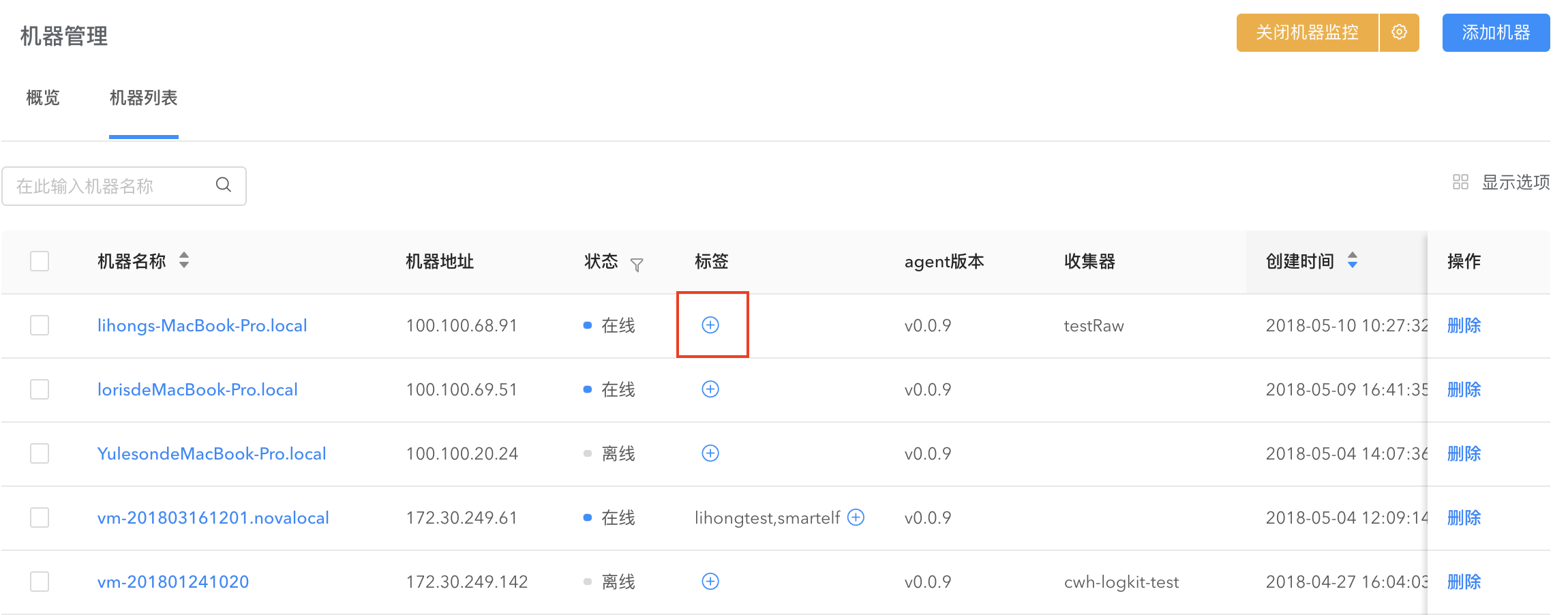
标签管理
通过标签管理功能来对同一个业务下的机器统一管理。在机器管理页面,点击添加标签按钮将指定机器添加到已有标签。

在弹出的添加标签窗口点击标签管理,可进入标签管理页面,对标签进行编辑、删除、创建标签操作。
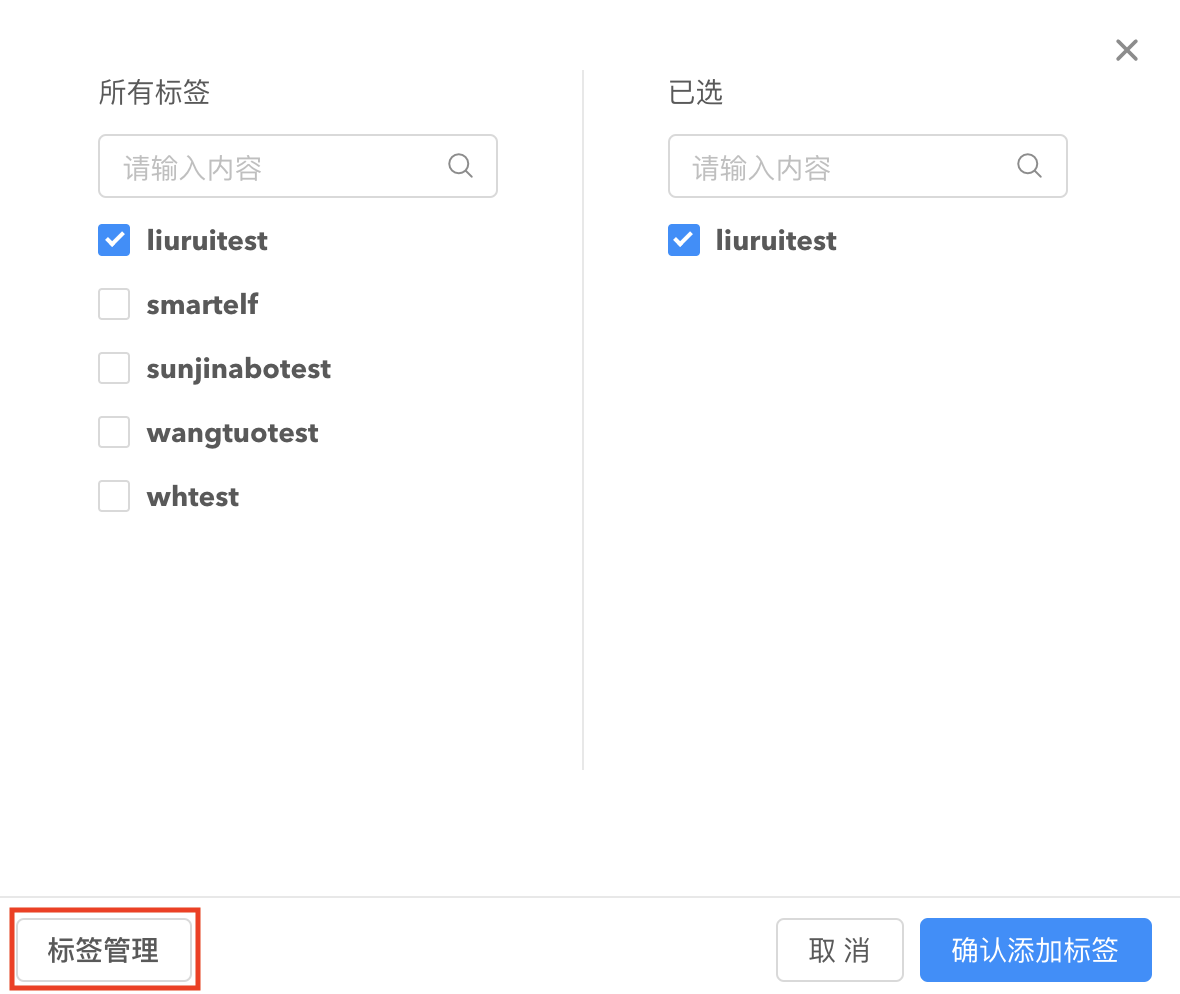
您也可以在标签管理页面对指定标签添加机器来批量管理机器。

现在开始玩转您的 logkit Pro 吧!
进阶与深入
数据源类型
从文件中读取(File Reader)
dir 模式从文件中读取
填写日志所在文件夹路径(log_path),如 /Users/loris/log/,logkit Pro 在启动时根据文件夹下文件更新时间顺序依次读取文件,读取到时间最新的文件时会不断读取追加的数据,直到该文件夹下出现新的文件。
收集场景
使用 dir 模式的经典日志存储方式为整个文件夹下存储单个服务的业务日志,文件夹下的日志通常有统一前缀,后缀为时间戳,根据日志的大小 rotate 到新的文件。如配置的文件夹为 logdir,下面的文件为 logdir/a.log.20170621 , logdir/a.log.20170622, logdir/a.log.20170623 这种模式的日志。即某个服务日志按文件大小分隔日志,每次分割后新命名文件并以时间戳为后缀,并且该文件夹下只有这一个服务。dir 模式首先会对文件夹下文件整体排序,依次读取各个文件,读完最后有个文件后会查找时间(文件 ctime)更新文件并重新排序,依次循环。logkit Pro 会负责将多个文件串联起来。即数据读取过程中 a.log.20170621 中最后一行的下一行就是 a.log.20170622 的第一行。
file 模式从文件中读取
填写精确的日志文件路径(log_path),如 /Users/loris/log/my.log/,logkit Pro 不断读取该文件追加的数据。
收集场景
使用 file 模式的经典日志存储方式类似于 nginx 的日志 rotate 方式,日志名称为固定的名称,如 access.log ,rotate 时直接 move 成新的文件如 access.log.1,新的数据仍然写入到 access.log。此时 配置 logkit Pro 收集永远只针对 access.log 这一个固定名称的文件进行收集。对于 logkit Pro 来说, Runner 也只会不断收集 access.log 这一个文件。检测文件是否 rotate 成功的标志是文件的 inode 号,在 windows 下则是 fd 的属性编号。对于使用 nfs 系统的用户来说,由于 inode 号不稳定,请谨慎使用这个模式。
tailx模式从文件中读取
填写匹配路径的模式串(log_path),例如 /Users//path//mylog/.log。
收集场景
tailx 模式比较灵活,几乎可以读取所有被通配符匹配上的日志文件,对于单个日志文件使用 file 模式不断追踪日志更新,logpath 是一个匹配路径的模式串,例如 /home//path//logdir/.log, 此时会展开并匹配所有符合该表达式的文件,并持续读取所有有数据追加的文件。每隔 stat_interval 的时间,重新刷新一遍 logpath 模式串,添加新增的文件。需要注意的是,使用 tailx 模式容易导致文件句柄打开过多。tailx 模式的文件重复判断标准为文件名称,若使用 rename, copy 等方式改变日志名称,并且新的名字在 logpath 模式串的包含范围内,在 read_from 为 oldest 的情况下则会导致重复写入数据,设置为 newest 则有可能在感知的时间周期内丢失一部分数据。选择 tailx 模式请谨慎配置文件名称,防止日志 rotate 时老数据的命名进入 tailx 的模式串范围内,导致不断重复读取数据。
fileauto 模式从文件中读取
自动根据用户上传的路径匹配上述三种文件读取模式中的一种。
选择的策略如下:
- 判断路径中是否带有 * , 若包含,则选择 tailx 模式。
- 判断路径是否为文件夹,若是文件夹,则选择 dir 模式。注意:dir 模式下,不同文件不断 append,会导致数据重复收集,请手动选择 tailx 模式。
- 最后选择 file 模式。
基础配置信息
读取起始位置(read_from):在创建新文件或 meta 信息损坏的时候(即历史读取记录不存在),将从文件的哪个位置开始读取。可以设置为 oldest,从文件开始的部分全量读取,也可以设置为 newest 从文件最新的部分开始读取。如果字段不填,默认从最老的开始消费。tailx 读取模式下,设置为 oldest 模式可能会导致数据重复读取(如 rotate 的方式是 copy 一份数据),设置为 newest 则有可能在感知的时间周期内丢失一部分数据。
忽略文件的最大过期时间(expire):针对 tailx 读取模式读取的日志, 写法为数字加单位符号组成的字符串 duration 写法,支持时 h、分 m、秒 s 为单位,类似 3h(3小时),10m(10分钟),5s(5秒), 默认的 expire 时间是 24h, 当达到 expire 时间的日志,就放弃追踪。
高级选项
数据保存路径(meta_path):reader 读取 offset 的记录路径,必须是一个文件夹,在这个文件夹下,会记录本次 reader 的读取位置。默认会根收集器名称结合上传路径的 hash 值自动生成。
编码方式(encoding):读取日志文件的编码方式,默认为 utf-8,即按照 utf-8 的编码方式读取文件。支持读取文件的编码格式包括:UTF-16,GB18030,GBK,cp51932,windows-51932,EUC-JP,EUC-KR,ISO-2022-JP,Shift_JIS,TCVN3 及其相关国际化通用别名。
读取速度限制(readio_limit):读取文件的磁盘限速,填写正整数,单位为 MB/s, 默认限速 20 MB/s。
来源标签(datasource_tag):表示把读取日志的路径名称也作为标签,记录到解析出来的数据结果中,默认不添加,若 datasource_tag 不为空,则以该字段名称作为标签名称。例如 “datasource_tag”:”mydatasource”; 则最终解析的日志中会增加一个字段 mydatasource 记录读取到日志的路径。可用于区分 tailx 模式下的日志数据是从哪个日志路径下读取的问题。dir 模式下,可能存在部分数据标记的不准确,偏差到下一个文件。(因为读取的时候是读到 bufferreader 的缓冲区,所以当 buffer reader 还在读前一部分数据的时候,可能底层的多文件拼接的 seq reader 已经读取到下一个文件,而此时调用的结果会是下一个文件的结果,所以出现异常。这种情况只有在数据出现在文件末尾且缓冲区已经读到下一个文件的情况。)
按正则表达式规则换行(head_pattern):默认不填,reader 每次读取一行,若要读取多行,则填写。head_pattern 表示匹配多行的第一行使用的正则表达式。tailx 模式在多行匹配时,若一条日志的多行被截断到多个文件,那么此时无法匹配多行。dir、file 模式下会自动处理文件截断的拼接。head_pattern 最多缓存 20MB 的日志文件进行匹配。使用多行匹配情况的一个经典场景就是使用 grok parser 解析应用日志,此时需要在 head_pattern 中指定行首的正则表达式,每当匹配到符合行首正则表达式的时候,就将之前的多行一起返回,交由后面的 parser 解析。
文件末尾加上换行符(newfile_newline):默认为 false,只针对 dir 模式,开启后,不同文件结尾自动添加换行符。
是否忽略隐藏文件(ignore_hidden):读取的过程中是否忽略隐藏文件,默认忽略。
忽略此类后缀文件(ignore_file_suffix):针对 dir 读取模式需要解析的日志文件,可以设置读取的过程中忽略哪些文件后缀名,默认忽略的后缀包括”.pid”, “.swap”, “.go”, “.conf”, “.tar.gz”, “.tar”, “.zip”,”.a”, “.o”, “.so”。
以 linux 通配符匹配文件(valid_file_pattern):针对 dir 读取模式需要解析的日志文件,可以设置匹配文件名的模式串,匹配方式为 linux 通配符展开方式,默认为 *,即匹配文件夹下全部文件。
- 通配符语法说明:
- 匹配任意非文件路径分隔符的零或多个字符
- ? 匹配任意非文件路径分隔符的单个字符
- [符号集] 匹配符号集中的所有字符
最大打开文件数(max_open_files):针对 tailx 读取模式读取的日志,最大能追踪的文件数,默认为 256。同时追踪的文件过多会导致打开的文件句柄超过系统限制,请谨慎配置该项。超过限制后,不再追踪新添加的日志文件,直到部分追踪文件达到 expire 时间。
扫描间隔(stat_interval):针对 tailx 读取模式读取的日志,刷新过期的跟踪日志文件, 刷新 logpath 模式串,感知新增日志的定时检查时间, 写法为数字加单位符号组成的字符串 duration 写法,支持时 h、分m、秒s为单位,类似3h(3小时),10m(10分钟),5s(5秒),默认3m(3分钟)。
从 MySQL 中读取(mysql reader)
以定时任务的形式去执行 mysql 语句,将 mysql 读取到的内容全部获取则任务结束,等到下一个定时任务的到来。mysql reader 输出的内容为 json 字符串,须使用 json parser 解析。
基础配置信息
数据库地址(mysql_datasource):由 username: 用户名, password: 用户密码, hostname: mysql 地址, port: mysql 端口组成, 一个完整 mysql_datasource 示例:”admin:123456@tcp(10.101.111.1:3306)”
数据查询语句(mysql_sql):要执行的 sql 语句,可以用 @(var) 使用魔法变量,用 ; 分号隔开,多条语句按顺序执行。多条 sql 输出的内容必须 schema 相同,否则请添加新的收集器分开收集。
- 魔法变量:目前支持
年,月,日,时,分,秒的魔法变量,以当前时间 2017 年 6 月 5 日 6 时 35 分 24 秒为例。@(YYYY)年份,就是2017@(YY)年份后两位,就是17。@(MM)月份,补齐两位,就是06@(M)月份,不补齐,就是6@(D)日,不补齐,就是5@(DD)日,补齐两位,如05@(hh)小时,补齐两位, 如06@(h)小时,如6@(mm)分钟,补齐两位,35@(m)分钟,35@(ss)秒,补齐两位,24@(s)秒,24
- 魔法变量:目前支持
启动时立即执行(msql_exec_onstart):true 表示启动时执行一次,以后再按 cron 处理;false 则表示到cron 预设的时间才执行,默认为 true。
高级选项
递增的列名称(mysql_offset_key):指定一个 mysql 的列名,作为 offset 的记录,类型必须是整型,建议使用插入(或修改)数据的时间戳(unixnano)作为该字段。每次查询会指定这个 key 做 where 条件限制,避免单次查询性能消耗过大。
分批查询的单批次大小(mysql_limit_batch):mysql_sql 的语句,若数据量大,可以填写该字段,分批次查询。
- 若 mysql_offset_key 存在,假设填写为 100,则查询范式为 select * from table where mysql_offset_key >= 0 and mysql_offset_key < 0 + 100;
- 若没填写mysql_offset_key,则类似于 select * from table limit 0,100。
定时任务(mysql_cron):定时任务触发周期
- 直接写 “loop” ,任务会不停的循环,执行完一次再接着执行下一次,后面可以跟循环的间歇时间,如”loop 10s”,表示每次循环间隔10s,支持的单位还有”m(分钟)”,”h(小时)”
- crontab 的写法,类似于 ,对应的是秒(0~59),分(0~59),时(0~23),日(1~31),月(1-12),星期(0~6),填*号表示所有遍历都执行。
- 描述式写法,类似于 “@midnight”, “@every 1h30m”,必须@符合开头,目前支持@hourly,@weekly,@monthly,@yearly,@every
手动定义 SQL 字段类型(sql_schema): 默认情况下会自动识别数据字段的类型,当不能识别时,可以 sql_schema 指定 mysql 数据字段的类型,目前支持 string、long、float 三种类型,单个字段左边为字段名称,右边为类型,空格分隔 abc float;不同的字段用逗号分隔。支持简写为float=>f,long=>l,string=>s. 如:”sql_schema”:”abc string,bcd float,xyz long”。
魔法变量时间延迟(magic_lag_duration):针对魔法变量进行时间延迟,单位支持 h(时)、m(分)、s(秒),如写 24h,则渲染出来的时间魔法变量往前 1 天,2017 年 6 月 5 日 6 时 35 分 24 秒 的 @(D) 渲染出来的就是 4。
从 MSSQL 读取(Microsoft SQL Server Reader)
以定时任务的形式去执行 sql 语句,将 sql 读取到的内容全部获取则任务结束,等到下一个定时任务的到来。mssql reader 输出的内容为 json 字符串,须使用 json parser 解析。
基础配置信息
数据库地址(mssql_datasource):由 username: 用户名, password: 用户密码, hostname: mssql地址,实例,port: mssql端口,默认 1433 组成, 一个完整的 mssql_datasource 示例:”server=localhost\SQLExpress;user id=sa;password=PassWord;port=1433”
数据查询语句(mssql_sql):要执行的 sql 语句,可以用 @(var) 使用魔法变量,用
;分号隔开,多条语句按顺序执行。多条 sql 输出的内容必须 schema 相同,否则请添加新的收集器分开收集。高级选项
递增的列名称(mssql_offset_key):指定一个 mssql 的列名,作为 offset 的记录,类型必须是整型,建议使用插入(或修改)数据的时间戳(unixnano)作为该字段。每次查询会指定这个 key 做 where 条件限制,避免单次查询性能消耗过大。
分批查询的单批次大小(mssql_limit_batch): mssql_sql 的语句,若数据量大,可以填写该字段,分批次查询。
- 若 mssql_offset_key 存在,假设填写为 100,则查询范式为 select * from table where mssql_offset_key >= 0 and mssql_offset_key < 0 + 100;
- 若没填写 mssql_offset_key,则直接执行整个 SQL select * from table,没有分页。
定时任务(mssql_cron): 定时任务触发周期,支持三种写法。
- 直接写 “loop”,任务会不停的循环,执行完一次再接着执行下一次,后面可以跟循环的间歇时间,如 “loop 10s”,表示每次循环间隔 10s,支持的单位还有”m(分钟)”,”h(小时)”
- crontab 的写法,类似于 ,对应的是秒(0~59),分(0~59),时(0~23),日(1~31),月(1-12),星期(0~6),填*号表示所有遍历都执行。
- 描述式写法,类似于 “@midnight”, “@every 1h30m”,必须@符合开头,目前支持@hourly,@weekly,@monthly,@yearly,@every
手动定义 SQL 字段类型(sql_schema): 默认情况下会自动识别数据字段的类型,当不能识别时,可以 sql_schema 指定 mysql 数据字段的类型,目前支持 string、long、float 三种类型,单个字段左边为字段名称,右边为类型,空格分隔 abc float;不同的字段用逗号分隔。支持简写为float=>f,long=>l,string=>s. 如:”sql_schema”:”abc string,bcd float,xyz long”。
魔法变量时间延迟(magic_lag_duration):针对魔法变量进行时间延迟,单位支持 h(时)、m(分)、s(秒),如写 24h,则渲染出来的时间魔法变量往前 1 天,2017 年 6 月 5 日 6 时 35 分 24 秒 的 @(D) 渲染出来的就是 4。
从 PostgreSQL 读取
以定时任务的形式去执行 PostgreSQL 查询语句,将 PostgreSQL 读取到的内容全部获取则任务结束,等到下一个定时任务的到来,也可以仅执行一次。PostgreSQL reader 输出的内容为 json 字符串,须使用 json parser 解析。
基础配置信息
- 数据库地址(postgres_datasource):填写的形式如 host=localhost port=5432, 属性和实际的值用=(等于)符号连接,属性和值中间不要有空格,不同的属性用(空格)隔开,具体支持的属性如下所示:
- dname:数据库名称,若此处填了,下面 postgres_database 可以不填。
- user : 用户名称
- password : 用户密码
- host : PostgreSQL 服务地址
- port : 要绑定的端口 (默认是 5432)
- sslmode : 使用SSL的模式,默认是开启的,若关闭需要指定 sslmode=disable,其他模式还包括require(SSL、跳过认证),verify-ca(SSL,证书认证)、verify-full( SSL,证书认证、且认证服务器的hostname包含在证书中)
- connect_timeout : 连接最大超时时间,设置为 0 表示无限制。
- sslcert : 证书路径地址,文件必须包含 PEM 编码的数据
- sslkey : Key 文件路径,文件必须包含 PEM 编码的数据
- sslrootcert : root 证书的文件路径,文件必须包含 PEM 编码的数据
一个完整的 postgres_datasource 示例:”host=localhost port=5432 connect_timeout=10 user=pqgotest password=123456 sslmode=disable”
- 数据查询语句(postgres_sql): 填写要执行的 sql 语句,可以用 @(var) 使用魔法变量
高级选项
递增的列名称(postgres_offset_key): 指定一个 PostgreSQL 的列名,作为 offset 的记录,类型必须是整型,建议使用插入(或修改)数据的时间戳(unixnano)作为该字段。每次查询会指定这个 key 做 where 条件限制,避免单次查询性能消耗过大。
分批查询的单批次大小(postgres_limit_batch): postgres_sql 的语句,若数据量大,可以填写该字段,针对 postgres_offset_key 分批次查询。
- postgres_offset_key 填写为100,则查询范式为 select * from table where postgres_offset_key >= 0 and postgres_offset_key < 0 + 100;
定时任务(postgres_cron): 定时任务触发周期,支持三种写法。
- 直接写 “loop”,任务会不停的循环,执行完一次再接着执行下一次,后面可以跟循环的间歇时间,如 “loop 10s”,表示每次循环间隔10s,支持的单位还有”m(分钟)”,”h(小时)”
- crontab 的写法,类似于 ,对应的是秒(0~59),分(0~59),时(0~23),日(1~31),月(1-12),星期(0~6),填*号表示所有遍历都执行。
- 描述式写法,类似于 “@midnight”, “@every 1h30m”,必须@符合开头,目前支持@hourly,@weekly,@monthly,@yearly,@every
从 Elasticsearch 读取
Elasticsearch Reader 输出的是 json 字符串,需要使用 json 的 parser 解析。
基础配置信息
数据库地址(es_host):es 的 host 地址以及端口,常用端口是 9200
版本(es_version):指定 Elasticsearch 客户端版本,可选参数,目前支持 3.x ,5.x,6.x 三个版本,3.x 包含了 Elasticsearch 服务端(2.x)版本。
索引名称(es_index):es 的索引名称,必填。
app 名称(es_type):es 的 type 名称,
高级选项
数据保存路径(meta_path):reader 的读取 offset 的记录路径,记录 es 读取时的 ScrollID,路径必须是一个文件夹。
分批查询的单批次大小(es_limit_batch):es一次获取的 batch size,默认为 100 条一个 batch。
offset保存时间(es_keepalive): es reader 一旦挂掉了,重启后可以继续读取数据的 ID(Offset记录)在 es 服务端保存的时长,默认 1d,写法按 es 的单位为准,m分钟,h小时,d天。
从 MongoDB 读取
MongoDB reader 输出的是 json 字符串,需要使用 json parser 解析。
基础配置信息
数据库地址(mongo_host):mongodb 的 url 地址,基础写法为填写 mongo 的 host 地址以及端口,默认是 localhost:9200,扩展形式可以写为:mongodb://[username:password@]host1[:port1][,host2[:port2],…[,hostN[:portN]]][/[database][?options]],用户名密码也可以写在这里。
递增的主键(mongo_offset_key):选填,指定一个 mongo 的列名,作为 offset 的记录,类型必须是整型(比如 unixnano 的时间,或者自增的 primary key)。 每次查询会指定这个 key 做 where 条件大于上次查询最后的记录这样的限制,避免单次查询性能消耗过大,同时也支持持续的数据导入过程中避免数据重复。 若不指定,则使用 mongo 的_id 键,_id 键是由时间戳(秒)+机器+进程号+自增位组成的,在低频数据写入的情况下是自增的,在多机器组成的 mongo 集群高并发写入的情况下,_id 不是自增的,存在漏数据的可能。 默认使用 _id,也保证了在纯粹从静态的 mongo 数据库导入 Pandora 过程中,若重启 logkit Pro 不会导致数据重复。
高级选项
数据保存路径(meta_path): 默认自动生成,是 reader 的读取 offset 的记录路径,记录 mongo 读取时的 Offset,路径必须是一个文件夹。
分批查询的单批次大小(mongo_limit_batch): 默认为 “100”, 表示单次请求获取的数据量。
定时任务(mongo_cron): 默认没有定时任务。定时任务触发周期,支持三种写法。
- 直接写 “loop”,任务会不停的循环,执行完一次再接着执行下一次,后面可以跟循环的间歇时间,如 “loop 10s”,表示每次循环间隔 10s,支持的单位还有”m(分钟)”,”h(小时)”
- crontab 的写法,类似于 ,对应的是秒(0~59),分(0~59),时(0~23),日(1~31),月(1-12),星期(0~6),填*号表示所有遍历都执行。
- 描述式写法,类似于 “@midnight”, “@every 1h30m”,必须@符合开头,目前支持@hourly,@weekly,@monthly,@yearly,@every
- 数据过滤方式(mongo_filters):表示 collection 的过滤规则,默认不过滤,全部获取。最外层是 collection 名称,里面对应的是 json 的规则。如示例所示,表示 foo 这个 collection,i 字段的值大于 10 的全部数据。
!>注意:导出 mongo 的字段中,包含_id的话,在打入 Pandora 的数据中,默认也会包含_id,这份数据如果再要导出到 LogDB,就会出现错误,因为_id 是 LogDB 的保留字段。此时可以在 Pandora Sender 中指定 pandora_schema 字段设置别名,如 “pandora_schema”:”_id id,…”, 这样就可以正常导入。其他出现字段冲突的情况都可以使用别名功能处理。
从 Kafka 读取
Kafka reader 输出的是 raw data,可根据具体情况自定义 parser 进行解析。
基础配置信息
consumer 组名称(kafka_groupid):kafka 组名,多个 logkit 同时消费时写同一个组名可以协同读取数据。
topic 名称(kafka_topic):kafka 的 topic 名称列表。
zookeeper 地址(kafka_zookeeper):zookeeper 地址列表,多个用逗号分隔,常用端口是 2181。
读取起始位置(read_from): oldest:从 partition 最开始的位置,newest:从 partition 最新的位置。默认从 oldest 位置开始消费。
高级选项
- zookeeper 中 kafka 根路径(kafka_zookeeper_chroot):kafka 在 zookeeper 根路径中的地址。
从 Redis 读取
Redis Reader 输出的是 redis 中存储的字符串,具体字符串是什么格式,可以在 parser 中用对应方式解析。
基础配置信息
数据读取模式(redis_datatype):包含 list, channel, pattern_channel 三种模式:
- list 模式固定通过 Redis 的 BLPOP 获取数据,即用户的数据是通过 LPUSH 或者 RPUSH 的方式存进 list 中(持续写入的话,推荐使用 RPUSH 的方式,以免 Redis 高并发写入下出现异常情况),然后 redis 从最左边元素依次读取。在这个模式下 redis_key 模式的就是指定 list 的名称。
- channel 模式通过 Redis 的 Pub/Sub 模式读取,启动 Redis 后,订阅(Sub) redis_key 指定的键(即 Redis 中的 channel),当该 channel 有信息被发布(Pub)时,即获取该数据。
- pattern_channel,该模式与 channel 模式几乎相同,区别是,在该模式下 redis_key 可以指定为一个模式串,如 “abc*”,则所有 “abc” 为前缀的 channel 都会被监听。
数据库名称(redis_db):Redis 的数据库名,默认为 “0”。
redis 键(redis_key):Redis 监听的键值,在不同模式(redis_datatype)下表示不同含义。
数据库地址(redis_address):Redis 的地址(IP+端口),默认为 “127.0.0.1:6379”
高级选项
- 单次读取超时时间(redis_timeout):默认为 “5s”,在模式为 list 时每次等待键值数据的超时时间。
从 Socket 读取
以端口监听的方式接受并读取日志,主要支持 tcp\udp\unix 套接字这三大类协议。
基础配置信息
- socket 监听的地址(socket_service_address): 必填项,监听的 url 地址。协议和形式也可以多样化,包括:
- tcp 监听所有 tcp 协议的数据,如
tcp://127.0.0.1:http - tcp4 仅监听 ipv4 地址传输的 tcp 协议数据,如
tcp4://:3110 - tcp6 仅监听 ipv6 地址传输的 tcp 协议数据,如
tcp6://:3110或者tcp6://[2001:db8::1]:3110 - udp 监听所有 udp 协议传输的数据,如
udp://:3110 - udp4 仅监听 ipv4 地址传输的 udp 协议数据,如
udp4://:3110 - udp6 仅监听 ipv6 地址传输的 udp 协议数据,如
udp6://:3110 - unix 监听面向字节流的unix套接字的数据传输协议,如
unix:///tmp/sys.sock - unixgram 监听面向报文的unix套接字的数据传输协议,如
unixgram:///tmp/sys.sock - unixpacket 监听面向数据包的unix套接字的数据传输协议,如
unixpacket:///tmp/sys.sock
- tcp 监听所有 tcp 协议的数据,如
高级选项
最大并发连接数(socket_max_connections): 使用 TCP 协议时最大并发连接数, 设置 0 为无限制, 默认无限制。
连接超时时间(socket_read_timeout): 面向字节流的 Socket 连接读取的超时时间(tcp\unix),设置 0 为不超时,默认为不超时,填写格式可以包含单位秒(s)、分(m)、时(h),如 3s(3秒) 1m(1分钟)等等。
连接缓存大小(socket_read_buffer_size): 读取数据的 Buffer 大小,默认设置为 65535。
连接保持时长(socket_keep_alive_period): TCP 连接的 keep_alive 时间,设置为 0 表示关闭 keep_alive ,填写格式可以包含单位秒(s)、分(m)、时(h),如3s(3秒) 1m(1分钟)等等。
从 http 请求中读取
以 http post 请求的方式接受并读取日志的形式。
监听的地址和端口(http_service_address):监听的地址和端口,格式为:
[<ip/host/不填>:port],如:3000, 监听 3000 端口的 http 请求监听地址前缀(http_service_path):监听的请求地址,如 /data
!>注意1:该 reader 支持 gzip, 但请在请求头中添加 Content-Encoding=gzip 或者 Content-Type=application/gzip
!>注意2:默认接收 request body 中所有的数据作为要读取的日志, 限制 request body 小于 100MB
!>注意3:默认将 request body 中的数据使用 \n 分割, 每行作为一条数据
从脚本的执行结果中读取
以定时任务的形式执行脚本,将脚本执行的结果全部获取则任务结束,等到下一个定时任务的到来,也可以仅执行一次。
基础配置信息
脚本执行解释器(script_exec_interpreter):默认使用 bash。
脚本路径(log_path):如 “./script.sh”。
高级选项
- 定时任务(script_cron): 定时任务触发周期,支持三种写法。
- 直接写”loop” ,任务会不停的循环,执行完一次再接着执行下一次,后面可以跟循环的间歇时间,如”loop 10s”,表示每次循环间隔10s,支持的单位还有”m(分钟)”,”h(小时)”
- crontab的写法,类似于 ,对应的是秒(0~59),分(0~59),时(0~23),日(1~31),月(1-12),星期(0~6),填*号表示所有遍历都执行。
- 描述式写法,类似于 “@midnight”, “@every 1h30m”,必须@符合开头,目前支持@hourly,@weekly,@monthly,@yearly,@every
从 SNMP 服务中读取
基础配置信息
agents 列表(snmp_agents):snmp 代理地址, 当有多个 agents 时, 地址使用 ‘,’ 分割。
tebles 配置(snmp_tables):程序将会使用 Walk 请求来获取字段数据, 需要填入一个符合 json 数组格式的字符串, 数组中的每一项有以下字段:
- table_name: 选填项 表格变量的名称,当该项为空时,会根据 table_oid 字段解析出来的内容填充
- table_oid: 必填项 表格变量的 对象标识符
- table_fields: 选填项 除了从 table_oid 中解析出来的字段外,还可以根据此配置项将简单变量放入其中
fields 配置(snmp_fields):程序将会使用 Get 请求来获取字段数据, 需要填入一个符合 json数组 格式的字符串, 数组中的每一项有以下字段:
- field_name: 选填项 字段名称, 当该项为空时,会根据 field_oid 字段解析出来的内容为空
- field_oid: 必填项 字段的 对象标识符
- field_oid_index_suffix: 选填项 填写后会剥离 field_oid 的子标示符便于将其与其他字段匹配。
高级选项
名称(snmp_reader_name):默认 system, 对于简单变量(snmp_fields中的字段), 将把该字段放入收集的数据中, 所谓标识, 类似于 table_name。
连接超时时间(snmp_time_out): 默认 5s, 超时时间。
收集频率(snmp_interval): 默认 30s, 采集频率。
重试次数(snmp_retries):默认 3, 重试次数。
最大迭代次数(snmp_max_repetitions): 默认为 50, 变量检索次数的最大值, 用来指示 getBulk 命令, 尝试 snmp_max_repetitions 次 getNext 操作。
安全等级(snmp_sec_level):默认为 `noAuthNoPriv1, snmp 安全等级, 支持 “noAuthNoPriv”, “authNoPriv”, “authPriv” 三种。
认证协议(snmp_auth_protocol):认证协议, 支持 “”, “md5”, “sha” 三种。
隐私协议(snmp_priv_protocol):加密协议, 支持 “”, “des”, “aes” 三种。
!>注意: snmp_fields 和 snmp_tables 这两项配置需要填入符合 json 数组格式的字符串, 字符串内的双引号需要转义
从 AWS Cloudwatch 中读取
从 AWS CloudWatch 服务的接口中获取数据。
基础配置信息
区域(region):使用的 AWS 服务所在区域(region),如 us-east-1, 打开 AWS cloudwatch 的控制台,您在访问的 url 中就能看到所用的 region, 如 https://console.aws.amazon.com/cloudwatch/home?region=us-east-1。
命名空间(namespace):CloudWatch 服务的命名空间(namespace),对应了 AWS 的服务,命名空间如 AWS/EC2,AWS/S3 等等,进入 CloudWatch 左侧栏的指标(Metrics)页面,就可以看到所有的命名空间,点击某一个,就能在 url 中看到命名空间(namespace),如https://console.aws.amazon.com/cloudwatch/home?region=us-east-1#metricsV2:graph=~();namespace=AWS/S3。
AK(aws_access_key):授权方式之一,AWS 的 access key ID。
SK(aws_secret_key): 授权方式之一, AWS 的 secret key。
鉴权 token(aws_token): 授权方式之一,对应 AK、SK 的token。
共享 profile(aws_profile): 授权方式之一, AWS 的共享 profile 文件,填写路径。
鉴权文件(shared_credential_file): 授权方式之一, 共享的鉴权文件路径
收集间隔(interval): 填写 1m 表示 1 分钟,10m 表示 10 分钟,单位 m 表示分钟,最小设置为 1 分钟。
metrics 名称(metrics): version 3 必填项, 指定收集的 Metrics 名称,可填写多个,逗号连接,为空全部收集。
收集维度(dimensions): version 3 必填项,指定收集的 Metric 维度,可填写多个,key value 之间空格隔开,多个用逗号连接,为空全部收集。
高级选项
授权角色(role_arn):授权方式之一,AWS 的 Assuming a Role 角色授权信息。
每秒最大请求数(ratelimit):version 3 必填项, 请求限速,默认为每分钟 200,填写 100 则设置为 100 请求每分钟。
收集延迟(delay):version 3 必填项, Cloudwatch 中延迟收集的时间,设置 5 分钟,则表示收集 5 分钟前的数据,该选项保证了如果Cloudwatch中的数据有延迟,也可以延迟收集。如果延迟了5分钟,那么现在收集5分钟以前的。
刷新 metrics 时间(cache_ttl):version 3 必填项, namespace 下的 Metric 刷新时间,刷新后自动感知新的Metric,默认设置 1 小时刷新一次。
聚合间隔(period):version 3 必填项, 从 Cloudwatch 中收集的数据聚合粒度,默认为 5m 表示 5 分钟,最小填写 1m 表示 1 分钟。
数据解析方式
按原始日志逐行发送(Raw Parser)
Raw Parser 将日志文件的每一行解析为一条日志,解析后的日志有两个字段,raw 和 timestamp,前者是每一行日志的具体内容(若为空行,则忽略),后者为解析该条日志的时间戳。

高级选项
额外的标签信息(labels): 填一些额外的标签信息,同样逗号分隔,每个部分由空格隔开,左边是标签的 key,右边是value。
按 json 格式解析(JSON Parser)
JSON parser 是一个 schema free 的 parser,会把 json 的字符串反序列化成 Golang 中map[string]interface{} 的形式,然后交由 sender 做处理。若日志的 json 格式不规范,则解析失败,解析失败的数据会被忽略。
高级选项
额外的标签信息(labels):labels 中定义的标签如果跟数据有冲突,labels 中的标签会被舍弃
禁止记录解析失败数据(disable_record_errdata):默认为 false,解析失败的数据会默认出现在 “pandora_stash” 字段,该选项可以禁止记录解析失败的数据。
按 nginx 日志解析(Nginx Parser)
Nginx Parser 是专门解析 Nginx 日志的解析器。仅需指定 nginx 的配置文件地址,即可进行 nginx 日志解析。
Nginx Parser 的解析原理
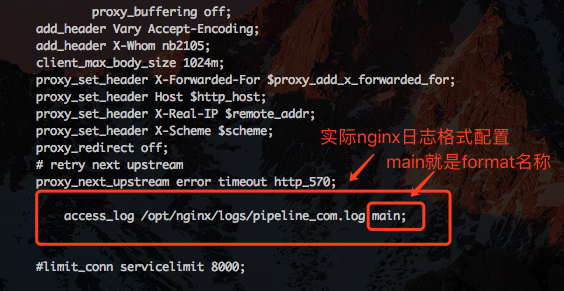
Nginx Parser 会根据 Nginx 配置文件去寻找 Nginx 日志的生成格式,举例来说:
log_format main '$remote_addr - $remote_user [$time_local] "$request" ''$status $bytes_sent $body_bytes_sent "$http_referer" ''"$http_user_agent" "$http_x_forwarded_for" ''$upstream_addr $host $sent_http_x_reqid $request_time';
这个日志格式会生成一个正则表达式,匹配每个$符号后的字符串,以格式中定义的分隔符为正则表达式的终结符。 如$remote_addr后面跟着空格,则认为匹配的 remote_addr 字段,匹配到空格为止。 如果被双引号””包裹,如"$http_user_agent",则认为匹配到双引号为止,又比如[$time_local]会认为匹配左括号[开始到右括号]结尾。
通过上述生成的正则表达式,就可以匹配 Nginx access日志了。
上述方式生成的正则表达式可以解析大部分情况下的 Nginx 配置,但是确实也存在一些情况会出现解析异常,如上述的 case 下,如果 http_user_agent 没有通过双引号引起来,那么就会导致提前匹配到 http_user_agent 中可能存在的空格,导致解析失败。针对这样的情况,我们就推荐使用Grok Parser来解析。
基础配置信息
nginx配置路径(nginx_log_format_path):填写 nginx 配置文件,配置文件中需要包含 log_format 格式。

nginx日志格式名称(nginx_log_format_name):实际 access log 使用的格式名称。
高级选项
手动指定字段类型(nginx_schema):默认情况下 nginx 日志都被解析为 string,指定该格式可以设置为float、long、date 等三种类型。指定范式为逗号分隔每个字段和类型,每个字段和类型用空格分隔,左边为字段名称,右边为类型。
指定名称(name):Nginx Parser 是根据您 Nginx 配置文件自动生成配置正则表达式解析日志的方式,parser名称和 Nginx 配置文件中 log_format 定义的名称一致。
额外的标签信息(labels):中定义的标签如果跟数据有冲突,labels 中的标签会被舍弃
禁止记录解析失败数据(disable_record_errdata):默认为 false,解析失败的数据会默认出现在”pandora_stash”字段,该选项可以禁止记录解析失败的数据。
grok格式解析
Grok Parser 是一个类似于 Logstash Grok Parser 一样的解析配置方式,其本质是按照正则表达式匹配解析日志。
基础配置信息
匹配日志的 grok 表达式(grok_patterns):用于匹配日志的 grok 表达式,多个用逗号分隔。填写解析日志的grok pattern 名称,包括一些logkit Pro 自身内置的 patterns以及自定义的 pattern 名称,以及社区的常见 grok pattern,如logstash 的内置 pattern以及常见的grok 库 pattern
- 填写方式是 %{QINIU_LOG_FORMAT},%{COMMON_LOG_FORMAT},以百分号和花括号包裹 pattern 名称,多个 pattern 名称以逗号分隔。
- 实际匹配过程中会按顺序依次去 parse 文本内容,以第一个匹配的 pattern 解析文本内容。
- 需要注意的是,每多一个 pattern,解析时都会多解析一个,直到成功为止,所以 pattern 的数量多有可能降低解析的速度,在数据量大的情况下,建议一个 pattern 解决数据解析问题。
自定义grok表达式(grok_custom_patterns):用户自定义的 grok pattern 内容,需符合 logkit Pro 自定义 pattern 的写法,按行分隔,参见自定义 pattern 的写法和用法说明。
Grok Parser 中解析出的字段就是 grok 表达式中命名的字段,还包括 labels 中定义的标签名,可以在 sender 中选择需要发送的字段和标签。
高级选项
自定义 grok 表达式文件路径(grok_custom_pattern_files):用户自定义的一些 grok pattern 文件,当自定义 pattern 太长太多,建议用文件功能。 !!!注意:如果修改 pattern 文件,需要更新 Runner 才能生效!!!
时区偏移量(timezone_offset): 解析出的时区信息默认为 UTC 时区,使用 timezone_offset 可以修改时区偏移量,默认偏移量为 0,写法为”+08”、”08”、”8” 均表示比读取时间加8小时,”-08”,”-8”,表示比读取的时间减 8 小时。若实际为东八区时间,读取为 UTC 时间,则实际多读取了 8 小时,需要写”-8”,修正回 CST 中国北京时间。
logkit Pro 自定义 pattern
- logkit Pro 的 grok pattern 其格式符合 %{<捕获语法>[:<字段名>][:<字段类型>]},其中中括号的内容可以省略。
- logkit Pro 的 grok pattern 是 logstash grok pattern 的增强版,除了完全兼容logstash grok pattern规则以外,还增加了类型,与telegraf 的 grok pattern规则一致,但是使用的类型是 logkit Pro 自身定义的。你可以在logstash grok文档中找到详细的 grok 介绍.
- 捕获语法:是一个正则表达式的名字,比如内置了 USERNAME [a-zA-Z0-9._-]+,那么此时 USERNAME 就是一个捕获语法。所以,在使用自定义的正则表达式之前,你需要先为你的正则命名,然后把这个名字当作捕获语法填写patterns 中,当然,不推荐自己写正则,建议首选内置的捕获语法。
- 字段名:按照捕获语法对应的正则表达式解析出的字段,其字段名称以此命名,该项可以不填,但是没有字段名的 grok pattern 不解析,无法被 logkit sender 使用,但可以作为一个中间捕获语法与别的捕获语法共同组合一个新的捕获语法。
- 字段类型:可以不填,默认为 string。logkit Pro 支持以下类型。
- string 默认的类型
- long 整型
- float 浮点型
- date 时间类型,包括以下格式
2006/01/02 15:04:05,2006-01-02 15:04:05 -0700 MST,2006-01-02 15:04:05 -0700,2006-01-02 15:04:05,2006/01/02 15:04:05 -0700 MST,2006/01/02 15:04:05 -0700,2006-01-02 -0700 MST,2006-01-02 -0700,2006-01-02,2006/01/02 -0700 MST,2006/01/02 -0700,2006/01/02,Mon Jan _2 15:04:05 2006 ANSIC,Mon Jan _2 15:04:05 MST 2006 UnixDate,Mon Jan 02 15:04:05 -0700 2006 RubyDate,02 Jan 06 15:04 MST RFC822,02 Jan 06 15:04 -0700 RFC822Z,Monday, 02-Jan-06 15:04:05 MST RFC850,Mon, 02 Jan 2006 15:04:05 MST RFC1123,Mon, 02 Jan 2006 15:04:05 -0700 RFC1123Z,2006-01-02T15:04:05Z07:00 RFC3339,2006-01-02T15:04:05.999999999Z07:00 RFC3339Nano,3:04PM Kitchen,Jan _2 15:04:05 Stamp,Jan _2 15:04:05.000 StampMilli,Jan _2 15:04:05.000000 StampMicro,Jan _2 15:04:05.000000000 StampNano,
- drop 表示扔掉该字段
- 验证自定义 pattern 的正确性:http://grokdebug.herokuapp.com, 这个网站可以 debug 你的 grok pattern。
如何调试您的 grok pettern[grokdebug用法]
- 访问地址:http://grokdebug.herokuapp.com
- 如下图所示,填写各类信息:
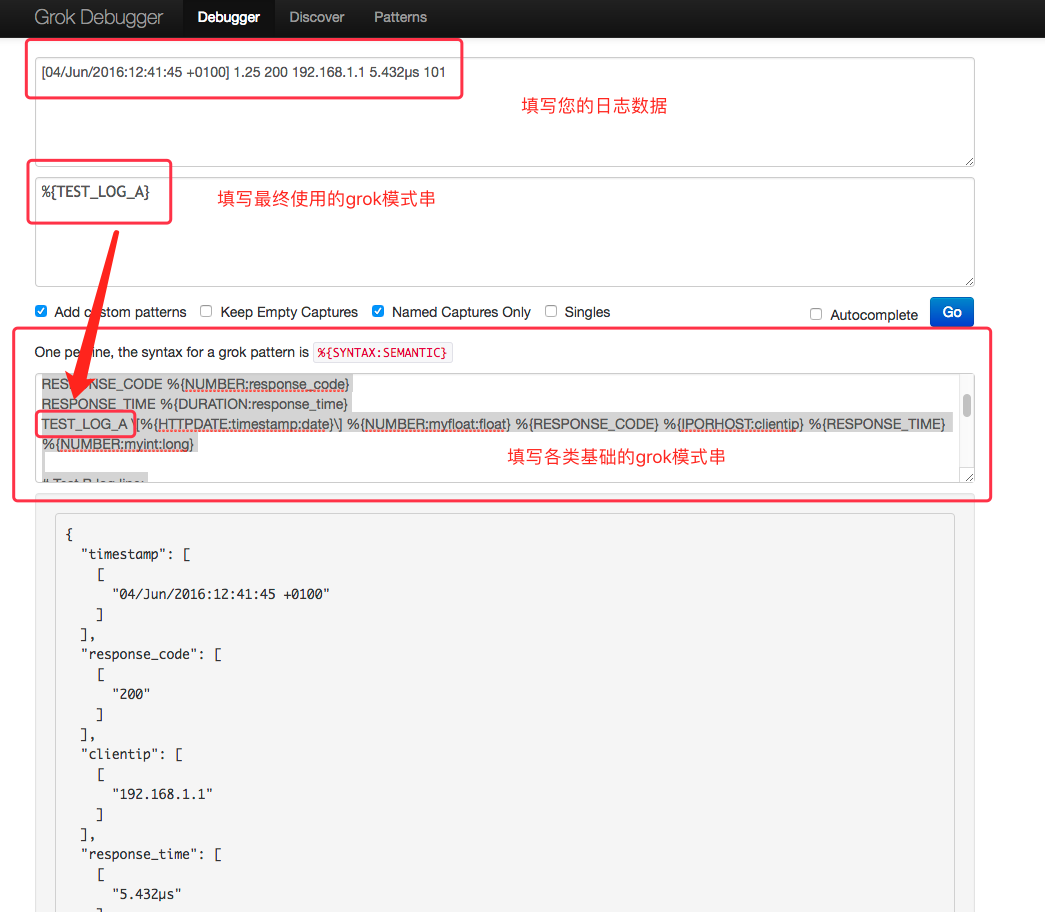
一条示例日志:
[04/Jun/2016:12:41:45 +0100] 1.25 200 192.168.1.1 5.432µs 101
最终使用的grok pattern
%{TEST_LOG_A}
基础的grok pattern 构成
# Test A log line:# [04/Jun/2016:12:41:45 +0100] 1.25 200 192.168.1.1 5.432µs 101DURATION %{NUMBER}[nuµm]?sRESPONSE_CODE %{NUMBER:response_code}RESPONSE_TIME %{DURATION:response_time}TEST_LOG_A \[%{HTTPDATE:timestamp:date}\] %{NUMBER:myfloat:float} %{RESPONSE_CODE} %{IPORHOST:clientip} %{RESPONSE_TIME} %{NUMBER:myint:long}# Test B log line:# [04/06/2016--12:41:45] 1.25 mystring dropme nomodifierTEST_TIMESTAMP %{MONTHDAY}/%{MONTHNUM}/%{YEAR}--%{TIME}TEST_LOG_B \[%{TEST_TIMESTAMP:timestamp:date}\] %{NUMBER:myfloat:float} %{WORD:mystring:string} %{WORD:dropme:drop} %{WORD:nomodifier}
将 grok pattern debug 调试完成后的配置落实到logkit Pro 的 grok 解析中,有以下两种方式:
- 将
基础的 grok pattern 构成里面的 grok pattern 填写到本地文件中,假设存储路径为 /home/user/logkit/grok_pattern。 注意,若修改这个 /home/user/logkit/grok_pattern 配置文件,需要更新 runner 才能生效。 - 将
最终使用的 grok pattern里面的模式串,填写到 grok parser 的 grok_patterns 配置项:”grok_patterns”:”%{TEST_LOG_A}”
如何使用 grok parser 解析 nginx/apache 日志
使用 grok parser 解析 nginx/apache 日志的过程,实际上就是利用 grok pattern(正则表达式)去匹配您的 nginx 日志,对于像 nginx/apache 日志这样的成熟日志内容,日志的所有组成部分均已经有非常成熟的 grok pattern 可以使用,下面我们先介绍下用于解析 nginx/apache 日志时常用的几个内置在 logkit Pro 的 grok pattern。
- 常用 grok pattern介绍
- NOTSPACE 匹配所有非空格的内容,这个是性能较高且最为常用的一个 pattern,比如你的日志内容是 abc efg,那么你只要写两个 NOTSPACE 的组合 Pattern 即可,如
%{NOTSPACE:field1} %{NOTSPACE:field2}。 - QUOTEDSTRING , 匹配所有被双引号括起来的字符串内容,跟 NOTSAPCE 类似,会包含双引号一起解析出来,如 “abc” - “efx sx” 这样一串日志,写一个组合 Pattern
%{QUOTEDSTRING:field1} - %{QUOTEDSTRING:field2},field2 就包含数据”efx sx”,这个同样性能较高,好处是不怕有空格等其他特殊字符,缺点是解析的内容包含了双引号本身,如果要转换成 long 等类型需要去掉引号。 - DATA 匹配所有字符,这个 pattern 需要结合一些特殊的语境使用,如双引号等特殊字符。举例来说 “abc” - “efx sx”,这样一串日志,可以写一个组合 Pattern
"%{DATA:field1}" - "%{DATA:field2}",这个就起到了 QUOTEDSTRING 的效果,另外数据中不会包含双引号。 - HTTPDATE 匹配常见的 HTTP 日期类型,类似 nginx 和 Apache 生产的 timestamp 都可以用这个 Pattern 解析。如
[30/Sep/2017:10:50:53 +0800],就可以写一个组合 Pattern[%{HTTPDATE:ts:date}],中括号里面包含 HTTPDATE 这个 Pattern,就把时间字符串匹配出来了。 - NUMBER 匹配数字类型,包括整数和浮点数,利用这个 Pattern 就可以把 nginx 里面的如响应时间这样的数据解析出来。如”10.10.111.117:8888” [200] “0.002”,就可以写
"%{NOTSPACE:ip}" [%{NUMBER:status:long}] "%{NUMBER:resptime:float}"来解析出 status 状态码以及 resptime 响应时间。
基本上,上述这些基础的 grok Pattern 组合起来,就可以解决几乎所有 nginx 的日志解析,但有时候会遇到一些特殊情况,如某个字段可能存在也可能不存在,比如如下两行日志,我们都希望解析。
- POST 中包含HTTP协议信息
"POST /resouce/abc HTTP/1.1"
- POST 中不包含协议信息
"GET /resouce/abc"
此时就需要编写一种组合场景,表达或的逻辑,此时可以在 Pattern 组合中融入正则表达式的组概念,如下串即可解析:
"(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion}))"
其中括号就是正则表达式的组,组里面还可以包含组,每个组通过”?”问号开头表示可以存在0次或1次,”:”冒号后表达匹配的内容。
在 nginx 日志中常常还会出现内容为空的情况,为空时 nginx 字段填充-横杠,此时也可以用类似的方法写或。 如这两种数据 0.123 以及 -,如果把”-“当成正常的数字去解析,就会出错,所以需要去掉没有数字的情况,如:
(?:%{NUMBER:bytes}|-)
最后,假设我们遇到一种不太规则的 nginx 日志写法,如:
110.220.330.550 - - [12/Oct/2017:14:16:50 +0800] "POST /v2/repos/xsxsxs/data HTTP/1.1" 200 729 2 "-" "Faraday v0.13.1" "-" 127.9.2.1:80 www.qiniu.com xsxsxsxsx122dxsxs 0.019
我们就可以用上面描述的方法拼接出如下的串:
NGINX_LOG %{NOTSPACE:client_ip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:ts:date}\] "(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:http_version:float})?|%{DATA})" %{NUMBER:resp_code} (?:%{NUMBER:resp_bytes:long}|-) (?:%{NUMBER:resp_body_bytes:long}|-) "(?:%{NOTSPACE:referrer}|-)" %{QUOTEDSTRING:agent} %{QUOTEDSTRING:forward_for} %{NOTSPACE:upstream_addr} (%{HOSTNAME:host}|-) (%{NOTSPACE:reqid}) %{NUMBER:resp_time:float}
最后,你可以在 logkit Pro 的 grok parser 功能页面上调试一下。
按 csv 格式解析(CSV Parser)
CSV Parser 是一种按分隔符解析日志的解析方式,生成默认字段名与字段内容一一对应,字段名与字段类型可修改。

CSV parser 是按行读取日志的,对于每一行,以分隔符分隔,然后通过 csv_schema 命名分隔出来的字段名称以及字段类型。
默认情况下 CSV 是按 \t 分隔日志的,可以配置的分隔符包括但不限于, 各类字母、数字、特殊符号(#、!、*、@、%、^、…)等等。
- 分隔符(csv_splitter): csv文件的分隔符定义,默认为’\t’。
csv_schema 是按照逗号分隔的字符串,每个部分格式按照字段名、字段类型构成,字段类型现在支持 string, long, jsonmap, float,date。
- 类型说明
- string:go 的 string
- long:go 的 int 64
- float:go 的 float 64
- date:时间类型,具体参见grok date 字段解析类型
- jsonmap 将 json 反序列化为 map[string]interface{},key 必须为字符串格式,value 为 string, long 或者 float。如果 value 不属于这三种格式,将会强制将 value 转成 string 类型。
- jsonmap 如果要指定 jsonmap key 的类型并且选定一些 jsonmap 中的 key,那么只要用花括号包含选定的 key 以及其类型即可,里面的语法与外部相同也是以逗号”,”分隔不同的 key 和类型。目前不支持嵌套的 jsonmap,如果除了选定的 key,其他的 key也要,就以”…“结尾即可。
按 syslog 格式解析(Syslog Parser)
Syslog Parser 是直接根据 RFC3164/RFC5424 规则解析 syslog 数据的解析器,使用该解析器请确保日志数据严格按照 RFC 协议规则配置,否则该解析器将无法正确解析。

RFC 3164 : https://tools.ietf.org/html/rfc3164 样例日志如下:
<13>Feb 5 17:32:18 10.0.0.99 Use the BFG!
RFC 5424 : https://tools.ietf.org/html/rfc5424 样例日志如下:
<165>1 2003-10-11T22:14:15.003Z mymachine.example.com evntslog - ID47 [exampleSDID@32473 iut="3" eventSource="Application" eventID="1011"] BOMAn application event log entry...
Syslog Parser 能够自动识别多行构成的同一条日志。
rfc 协议(syslog_rfc):表示日志针对的 RFC 标准,选择 automic 可以识别,也可以直接填写 rfc3164 或者 rfc5424。
禁止记录解析失败数据(disable_record_errdata):默认为 false,解析失败的数据会默认出现在”pandora_stash”字段,该选项可以禁止记录解析失败的数据。
按七牛日志库格式解析(Qiniu Log Parser)
Qiniu Log Parser 为使用了七牛开源的 Golang 日志库https://github.com/qiniu/log 生成的日志提供的解析方式。
高级选项
日志前缀(qiniulog_prefix):使用 https://github.com/qiniu/log 这个库时用到的前缀,若没用上,就不填,通常情况下没有配置,默认不填。
日志格式顺序(qiniulog_log_headers):指定字段名称的顺序, 默认为 prefix、date、time、reqid、level、file
- prefix: qiniulog 的前缀,默认为空,不解析。
- date: 日志日期
- time: 日志时间
- reqid: 日志中用户请求的ID
- level: 日志等级
- file: 日志产生的代码位置
- 可以配置成: prefix,date,time,level,reqid,file,log
log 字段表示日志体的内容,顺序一定是在最后,不能改变。
最终 qiniu log parser 解析出来的字段为 prefix、date、time、reqid、level、file、log 以及标签,可以在 sender 中选择需要发送的字段和标签。
按 kafkarest 日志解析(KafkaRest Log Parser)
KafkaRest Log Parser 将 Kafka Rest 日志文件的每一行解析为一条结构化的日志。
- KafkaRestLog 解析出的字段名是固定的,包括如下字段及标签,可以在 sender 中选择需要发送的字段和标签。
- source_ip: 源 IP
- method: 请求的方法,诸如 POST、GET、PUT、DELETE 等
- topic: 请求涉及的 kafka topic
- code: httpcode
- resp_len: 请求长度
- duration: 请求时长
- log_time: 日志产生的时间
- error: 表示是一条 error 日志,也只有 error 日志才解析出该字段
- warn: 表示是一条 warn 日志,也只有 warn 日志才解析出该字段
按 mysql 慢请求日志解析(mysql log parser)
mysql log parser 解析的是 mysql 的慢请求日志。
针对如下一条慢请求日志:
# Time: 2017-12-24T02:42:00.126000Z# User@Host: rdsadmin[rdsadmin] @ localhost [127.0.0.1] Id: 3# Query_time: 0.020363 Lock_time: 0.018450 Rows_sent: 0 Rows_examined: 1SET timestamp=1514083320;use foo;SELECT count(*) from mysql.rds_replication_status WHERE master_host IS NOT NULL and master_port IS NOT NULL GROUP BY action_timestamp,called_by_user,action,mysql_version,master_host,master_port ORDER BY action_timestamp LIMIT 1;
可以解析得到的数据为:
{"SamplePoints": [{"Database": "foo","Host": "localhost","Lock_time": 0.01845,"Query_time": 0.020363,"Rows_examined": 1,"Rows_sent": 0,"Statement": "SELECT count(*) from mysql.rds_replication_status WHERE master_host IS NOT NULL and master_port IS NOT NULL GROUP BY action_timestamp,called_by_user,action,mysql_version,master_host,master_port ORDER BY action_timestamp LIMIT 1;","Timestamp": "2017-12-24T02:42:00Z","User": "rdsadmin"}]}
数据转换
script Transformer
针对指定的字段进行替换,执行指定字段的脚本,同时支持输入脚本内容或输入脚本路径进行执行。
要进行 Transform 变化的键(key):支持多级嵌套,多级间用.符号连接,如 abc.xyz,表示 data[“abc”][“xyz”]中的数据。
新的字段名(new): 将脚本执行结果存入一个新的字段,不改变原来字段所存的内容,如果不想改变 key 指定字段所存内容又想记录脚本执行结果,可以通过这个参数设置。默认情况下无需填写,脚本执行结果会替换 key 指定字段所存内容。
脚本执行解释器:字段可以设置脚本执行解释器,默认为 bash。
指定脚本路径(scriptpath):字段支持指定脚本文件路径,如果填写了该字段,会优先执行该脚本文件,不执行 key 指定字段的脚本。默认情况下无需填写,默认会执行 key 指定字段的脚本。
指定脚本内容(script):字段支持指定所需执行脚本内容,如果填写了该字段,会优先执行该脚本内容,不执行 scriptpath 和 key 指定字段的脚本。默认情况下无需填写,默认会执行 key 指定字段的脚本。
script Transformer 可以对指定的 key 进行脚本执行结果的替换。 key 指定的字段里存的如果是具体脚本的路径,则支持执行该脚本并将脚本执行结果替换 key 指定字段的值,或者创建 new 指定的字段并将脚本执行结果存入该字段 key 指定的字段里存的如果不是路径,则需要填写 script 或者 scriptpath 内容,此时会执行 script 或者 scriptpath,并将脚本执行结果存入 key 或者 new 字段。
pandora_key_convert Transformer
将不符合 Pandora 字段类型的 key 字符转化为下划线,如 a.b/c 改为 a_b_c。
urlparam Transformer
将带有 url parameter 格式的字符串(如 uid=123&name=tom&age=10或/mytest?uid=123&name=tom&age=10),并将其转化为键值对填充到原数据中。
- 要进行Transform变化的键(key): 指定要解析的数据所在字段,支持多级嵌套,多级间用.符号连接,如 abc.xyz,表示 data[“abc”][“xyz”]中的数据。
示例:
parser 解析后的数据为:
{"field1": "aaaa","field2": "bbbb","params": "/mytest?uid=123&name=tom&age=10"}
经过 urlparam transformer 变换后的数据将变为:
{"field1": "aaaa","field2": "bbbb","params": "/mytest?uid=123&name=tom&age=10","params_uid": "123","params_name": "tom","params_age": "10","params_url_param_path": "/mytest",}
!>注意:当 url param 中扩展开来的字段名与数据中原有的字段名称冲突时,该 transformer 会在其扩展名后面添加数字以便区分。
示例:
{"params_uid": "aaaa","field2": "bbbb","params": "uid=123&name=tom&age=10"}
解析后数据将变成:
{"params_uid": "aaaa","field2": "bbbb","params": "uid=123&name=lily&age=10","params_uid1": "233","params_name": "lily","params_age": "10"}
Cloudtrail Transformer
Cloudtrail Transformer 是针对 AWS CloudTrail 的数据做格式转换的 Transformer,可以将CloudTrail 的 json 格式中的 Records逐条变为数据。
示例:
将数据由一条:
{"Records": [{"eventVersion": "1.04","userIdentity": {"type": "IAMUser","principalId": "EX_PRINCIPAL_ID","arn": "arn:aws:iam::123456789012:user/Alice","accountId": "123456789012","accessKeyId": "EXAMPLE_KEY_ID","userName": "Alice"},"eventTime": "2016-07-14T19:15:45Z","eventSource": "cloudtrail.amazonaws.com","eventName": "UpdateTrail","awsRegion": "us-east-2","sourceIPAddress": "205.251.233.182","userAgent": "aws-cli/1.10.32 Python/2.7.9 Windows/7 botocore/1.4.22","errorCode": "TrailNotFoundException","errorMessage": "Unknown trail: myTrail2 for the user: 123456789012","requestParameters": {"name": "myTrail2"},"responseElements": null,"requestID": "5d40662a-49f7-11e6-97e4-d9cb6ff7d6a3","eventID": "b7d4398e-b2f0-4faa-9c76-e2d316a8d67f","eventType": "AwsApiCall","recipientAccountId": "123456789012"},{"eventVersion": "1.0","userIdentity": {"type": "IAMUser","principalId": "EX_PRINCIPAL_ID","arn": "arn:aws:iam::123456789012:user/Alice","accountId": "123456789012","accessKeyId": "EXAMPLE_KEY_ID","userName": "Alice"},"eventTime": "2014-03-24T21:11:59Z","eventSource": "iam.amazonaws.com","eventName": "CreateUser","awsRegion": "us-east-2","sourceIPAddress": "127.0.0.1","userAgent": "aws-cli/1.3.2 Python/2.7.5 Windows/7","requestParameters": {"userName": "Bob"},"responseElements": {"user": {"createDate": "Mar 24, 2014 9:11:59 PM","userName": "Bob","arn": "arn:aws:iam::123456789012:user/Bob","path": "/","userId": "EXAMPLEUSERID"}}}]}
转变为两条:
{"eventVersion": "1.04","userIdentity": {"type": "IAMUser","principalId": "EX_PRINCIPAL_ID","arn": "arn:aws:iam::123456789012:user/Alice","accountId": "123456789012","accessKeyId": "EXAMPLE_KEY_ID","userName": "Alice"},"eventTime": "2016-07-14T19:15:45Z","eventSource": "cloudtrail.amazonaws.com","eventName": "UpdateTrail","awsRegion": "us-east-2","sourceIPAddress": "205.251.233.182","userAgent": "aws-cli/1.10.32 Python/2.7.9 Windows/7 botocore/1.4.22","errorCode": "TrailNotFoundException","errorMessage": "Unknown trail: myTrail2 for the user: 123456789012","requestParameters": {"name": "myTrail2"},"responseElements": null,"requestID": "5d40662a-49f7-11e6-97e4-d9cb6ff7d6a3","eventID": "b7d4398e-b2f0-4faa-9c76-e2d316a8d67f","eventType": "AwsApiCall","recipientAccountId": "123456789012"}
{"eventVersion": "1.0","userIdentity": {"type": "IAMUser","principalId": "EX_PRINCIPAL_ID","arn": "arn:aws:iam::123456789012:user/Alice","accountId": "123456789012","accessKeyId": "EXAMPLE_KEY_ID","userName": "Alice"},"eventTime": "2014-03-24T21:11:59Z","eventSource": "iam.amazonaws.com","eventName": "CreateUser","awsRegion": "us-east-2","sourceIPAddress": "127.0.0.1","userAgent": "aws-cli/1.3.2 Python/2.7.5 Windows/7","requestParameters": {"userName": "Bob"},"responseElements": {"user": {"createDate": "Mar 24, 2014 9:11:59 PM","userName": "Bob","arn": "arn:aws:iam::123456789012:user/Bob","path": "/","userId": "EXAMPLEUSERID"}}}
IP Transformer
对 ip 字段进行数据的扩展,扩展出如下字段:
"Region": 区域信息"City":城市信息"Country":国家信息"Isp":运营商信息
要进行 Transform 变化的键(key):支持多级嵌套,多级间用.符号连接,如 abc.xyz,表示 data[“abc”][“xyz”]中的数据。
IP 数据库路径(data_path):你拥有的 ip 数据库文件路径,可以在 ipip.net 下载,也可以使用logkit 源码包中的 ip 数据库。
arrayexpand Transformer
解析数组类型,并将其转化为键值对填充到原数据中。
- 要进行Transform变化的键(key):要解析的数据所在字段名称,支持多级嵌套,多级间用.符号连接,如abc.xyz,表示 data[“abc”][“xyz”]中的数据。
示例: parser 解析后的数据为:
{"field1": "aaaa","field2": "bbbb","arrayfield": ["a", 1, 3.0, "d", "e"]}
经过 arrayexpand 后的数据将变为:
{"field1": "aaaa","field2": "bbbb","arrayfield": ["a", 1, 3.0, "d", "e"],"arrayfield0": "a","arrayfield1": 1,"arrayfield2": 3.0,"arrayfield3": "d","arrayfield4": "e"}
!>注意:若 arrayexpand 解析生成的字段与数据中原有字段冲突,则会再加一个数字位进行重命名。 例如:
{"field1": "aaaa","field2": "bbbb","arrayfield3": "xxx","arrayfield": ["a", "b", "c", "d", "e"]}
经过 arrayexpand 后的数据将变为:
{"field1": "aaaa","field2": "bbbb","arrayfield3": "xxx","arrayfield": ["a", "b", "c", "d", "e"]"arrayfield0": "a","arrayfield1": "b","arrayfield2": "c","arrayfield3_0": "b","arrayfield4": "e"}
Convert Transformer
除了通过可视化界面配置以外,logkit 还支持手动书写 dsl: 针对 dsl 指定的字段和类型做数据格式转换,dsl 中可以包含多个数据字段和类型。如将 field1 转为 long、field2 转为 string 则写为 “field1 long, field2 string”。
DSL 语法
DSL 规则为<字段名称> <类型>,字段名称和类型用空格符隔开,不同字段用逗号隔开。若字段必填,可以转换的类型包括:
- long 类型(int64): long,LONG,l,L
- float 类型(float64): float,FLOAT,F,f
- string 类型: string,STRING,S,s
- bool 类型: bool,BOOL,B,b,boolean
- array 类型: array,ARRAY,A,a;括号中跟具体array元素的类型,如a(l),表示array里面都是long。同时,也可以省略小括号前的array类型申明,直接写(l),表示 array 类型,里面的元素是long
- map 类型: map,MAP,M,m;使用花括号表示具体类型,表达map里面的元素,如map{a l,b map{c b,x s}}, 表示map结构体里包含a字段,类型是long,b字段又是一个map,里面包含c字段,类型是bool,还包含x字段,类型是string。同时,也可以省略花括号前面的map类型,直接写{s l},表示map类型,里面的元素s为long类型。
Discard Transformer
删除指定的数据字段, 如数据{“a”:123,”b”:”xx”}, 指定删除 a,变为{“b”:”xx”}
要进行 Transform 变化的键(key):
- 支持多级嵌套,多级间用.符号连接,如abc.xyz,表示 data[“abc”][“xyz”]中的数据。
- 也支持写多个,用逗号分隔,比如 field1,field2 表示删除field1和field2 2个key。
应用场景
数据解析完后,有一些字段是不需要的,就可以用来做反选,去掉这些字段,节省传输和存储成本。
Date Transformer
对指定的 key 转换为指定的时间格式,这个 key 里面存的实际值可以是一个字符串,也可以是一个 timestamp 数字。 也可以对时间进行变换,如解析的时间没有带时区,被默认作为了 UTC 时间,但是又想变换为东八区时间,这样就只要在 Offset 处设置为 -8 即可。
要进行Transform变化的键(key): 支持多级嵌套,多级间用.符号连接,如 abc.xyz,表示 data[“abc”][“xyz”]中的数据。
时间样式(time_layout_before): 设置自己的时间类型的样式,在你的数据无法自动解析的情况下,可以通过这个参数设置。默认情况下无需填写,系统会自动解析。
解析后时间样式(time_layout_after): 设置解析后的时间,Pandora接受的时间类型(date)类型本质上是RFC3339的字符串,所以此处如果不填,默认转为RFC3339的字符串,也可根据需要转为其他样式。
时间格式(layout)的写法
时间格式的写法符合 golang 的时间格式定义方法,具体参见https://golang.org/pkg/time/#pkg-constants类似如下。
ANSIC = "Mon Jan _2 15:04:05 2006"UnixDate = "Mon Jan _2 15:04:05 MST 2006"RubyDate = "Mon Jan 02 15:04:05 -0700 2006"RFC822 = "02 Jan 06 15:04 MST"RFC822Z = "02 Jan 06 15:04 -0700" // RFC822 with numeric zoneRFC850 = "Monday, 02-Jan-06 15:04:05 MST"RFC1123 = "Mon, 02 Jan 2006 15:04:05 MST"RFC1123Z = "Mon, 02 Jan 2006 15:04:05 -0700" // RFC1123 with numeric zoneRFC3339 = "2006-01-02T15:04:05Z07:00"RFC3339Nano = "2006-01-02T15:04:05.999999999Z07:00"Kitchen = "3:04PM"// Handy time stamps.Stamp = "Jan _2 15:04:05"StampMilli = "Jan _2 15:04:05.000"StampMicro = "Jan _2 15:04:05.000000"StampNano = "Jan _2 15:04:05.000000000"
简单来说,年份必须是 2006,月份必须是 1 或者 Jan,日必须是 2, 时必须是 3(两位数必须是 15,一位数时后面要跟 PM,类似 Kitchen 的描述),分必须是 4,秒必须是 5,时区必须是 +7。比如 RFC3339 的格式定义为2006-01-02T15:04:05+07:00,又或者我们自己定义一个简单版的时间 2006|01|02|03|04|05,年月日时分秒分别用竖线|分隔,假设当前时间为 2017 年 6 月 6 日 20 时 38 分 12 秒,则按我们定义的格式显示为 2017|06|06|20|38|12。
Replace Transformer
要进行Transform变化的键(key): 支持多级嵌套,多级间用.符号连接,如 abc.xyz,表示 data[“abc”][“xyz”]中的数据。
是否启用正则匹配(regex): Replace Transformer 支持正则表达式,当 regex 标志位为 true 时,把 old 字段对应的字符串当作正则表达式处理。
Trim Transformer
去掉字符串前后多余的字符,如 abc123, 设置 trim 的字符为 abc,变化后为 123。
- 修整位置(place):只去掉前缀(prefix)、后缀(suffix)或者前缀后缀都去掉(both)。
UserAgent Transformer
解析 User Agent 中的用户信息,如下:
- UA_Family: 族信息,通常一个公司的一系列产品会形成一个族。
- UA_Major:大版本号
- UA_Minor: 小版本号
- UA_Patch:补丁版本
- UA_Device_Family:设备族信息
- UA_Device_Brand: 设备品牌
- UA_Device_Model: 设备类型
- UA_OS_Family: 操作系统族信息
- UA_OS_Patch: 操作系统补丁版本
- UA_OS_Major: 操作系统大版本号
- UA_OS_Minor: 操作系统小版本号
- UA_OS_PatchMinor: 操作系统补丁的小版本号
要进行 Transform 变化的键(key):支持多级嵌套,多级间用.符号连接,如 abc.xyz,表示 data[“abc”][“xyz”]中的数据。
UserAgent 解析正则表达式文件路径(regex_yml_path):默认可以不填,也可以填写你拥有的 useragent 正则表达式 yaml 文件,最新的文件可以在ua-parser/uap-core上获取。
示例:
传入一个 useragent 字符串,假设为:
Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_3; en-us; Silk/1.1.0-80) AppleWebKit/533.16 (KHTML, like Gecko) Version/5.0 Safari/533.16 Silk-Accelerated=true
得到的数据为:
"ua": "Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_3; en-us; Silk/1.1.0-80) AppleWebKit/533.16 (KHTML, like Gecko) Version/5.0 Safari/533.16 Silk-Accelerated=true","UA_Family": "Amazon Silk","UA_Major": "1","UA_Minor": "1","UA_Patch": "0-80","UA_OS_Family": "Android","UA_Device_Family": "Kindle","UA_Device_Brand": "Amazon","UA_Device_Model": "Kindle"
k8stag Transformer
为 Kubernetes 用户量身定做的 Transformer,对于收集的 Kubernetes 用户,其日志路径信息就带有包括 k8s_pod_name,k8s_namespace,k8s_container_name,k8s_container_id 在内的信息,所以 logkit Pro 通过收集到 Kubernetes 日志的路径,获取这些标签。
在 File Reader 的配置中,datasource_tag 这个选项会记录文件路径。logkit Pro 默认开启这个选项,并记录为 datasource 字段。
JSON Transformer
解析 json 并加入到数据中,如 json 为 {“a”:123},加入后变为 {“myNewKey”:{“a”:123}}。
要进行 Transform 变化的键(key):指定要解析的json数据所在的字段,支持多级嵌套,多级间用. 符号连接,表示data[“abc”][“xyz”] 中的数据。
解析后数据的字段名(new):指定要解析 json 数据字段的新字段,必须指定新字段。
示例:
例如, parser 解析后的数据为:
{"field1": "aaaa","field2": "bbbb","myOldKey": "{"uid":123,"name":"tom","age":10}"}
经过 json 变换后的数据将变为:
{"field1": "aaaa","field2": "bbbb","myOldKey": "{\"uid\":123,\"name\":\"tom\",\"age\":10}""myNewKey": {"uid":123,"name":"tom","age":10}}
label Transformer
增加标签, 如设置标签 {key:a,value:b}, 则数据中加入 {“a”:”b”}
要进行 Transform 变化的键(key):支持多级嵌套,多级间用.符号连接,如abc.xyz,表示 data[“abc”][“xyz”]中的数据。
要添加的数据值(仅限string类型)(value):要填充的label值,值的类型只能是string类型。
高级选项
- 要进行 Transform 变化的键已存在时,是否覆盖原有的值(override):默认为 false,选择 true 就表示如果原来有值,覆盖原有值,此处如果覆盖,原来该字段的数据就丢失了
rename Transformer
用新的字段重命名旧的字段, 如 {a:123} 改为 {b:123}。
要进行 Transform 变化的键(key):支持多级嵌套,多级间用.符号连接,如 abc.xyz,表示 data[“abc”][“xyz”]中的数据,重命名后会删除该字段,并将数据赋予到新的字段名称。
修改后的字段名(new_key_name):支持多级嵌套,多级间用.符号连接,如 abc1.xyz1,表示 data[“abc1”][“xyz1”] 中的数据。
split Transformer
针对 key 指定的字段做数据切割,按 step 指定的字符切分,转换为一个字符串数组,并填充到 newfield 指定的字段中。例如 “a,b,c” 切割为 [“a”,”b”,”c”]。
要进行 Transform 变化的键(key): 指定要切分的数据所在字段,支持多级嵌套,多级间用.符号连接,如abc.xyz,表示 data[“abc”][“xyz”]中的数据。
分隔符(sep): 指定切分的分隔符,通常情况下分隔符为逗号(“,”)、空格(“ “)、横线(“-“)、制表符(“\t”)等等。
解析后数据的字段名(newfield): 指定切分后的数据进的新字段,可以指定为新的字段,如果指定新的字段跟key字段名称相同,则相当于替换原始字段。
xml Transformer
解析 xml, 将 xml 格式转变为 map 结构。
要进行 Transform 变化的键(key): 指定要解析的 xml 数据所在的字段,支持多级嵌套,多级间用 . 符号连接,表示 data[“abc”][“xyz”] 中的数据。
解析后数据的字段(new): 指定要解析 xml 数据字段的新字段,必须指定新字段。
示例:
例如, parser 解析后的数据为:
{"key1": "value1","xml": "<?xml version=\"1.0\" encoding=\"UTF-8\"?><note><to>Tove</to><from>Jani</from><heading>Reminder</heading><body>Don't forget me this weekend!</body></note>"}
经过 xml 变换后的数据将变为:
{"key1": "value1","xml":{"note": {"heading": "Reminder","body": "Don't forget me this weekend!","to": "Tove","from": "Jani",},},},
数据发送
Senders 的主要作用是将 Parser 和 Transformer 后的数据发送至 Sender 支持的各类服务,目前支持发送到的服务包括: Pandora、ElasticSearch、File、InfluxDB、MongoDB、Kafka、Http Post、消费数据但不发送。
发送到 Pandora(Pandora Sender)
工作流名称(pandora_workflow_name):必填,七牛大数据平台工作流名称。
数据源名称(pandora_repo_name): 必填,Pandora 的 repo 名字。
自动创建并导出到日志分析(pandora_enable_logdb): 默认为 false,不启用,该字段表示是否在用户 pandora_schema_free 状态下直接将数据导出到 Pandora 日志检索服务。所以若 pandora_enable_logdb 生效的前提是 pandora_schema_free 是生效的。该配置会自动创建日志检索服务的仓库,同时在 pandora_schema_free 字段增加的情况下更新日志检索服务的仓库,更新导出。 注意,2017 年 11 月 27 日前创建的日志检索服务仓库数据默认保存 3 天,之后创建的数据仓库,数据默认保存 30 天,如需长时间保存,请到七牛官方日志检索服务页面修改数据仓库的数据保存时间;对于已经存在的数据源,并且已经创建过同名导出,自动创建导出将不生效;自动创建导出的repo名称需要统一为小写,logdb 命名的 repo 名称不支持大写。
指定日志分析仓库名称(pandora_logdb_name): 默认与 pandora_repo_name 相同,可指定 pandora_enable_logdb 创建的日志检索仓库名称。
日志分析域名(pandora_logdb_host): 默认为 https://logdb.qiniu.com ,创建日志检索仓库的服务地址。
自动创建并导出到时序数据库(pandora_enable_tsdb): 默认为 false,不启用,该字段表示是否在用户 pandora_schema_free 状态下直接将数据导出到 Pandora 时序数据库服务。所以若 pandora_enable_tsdb 生效的前提是 pandora_schema_free 是生效的。该配置会自动创建时序数据库的仓库,同时在 pandora_schema_free 字段增加的情况下更新时序数据库的仓库,更新导出。 注意,2017 年 11 月 27 日前创建的日志检索服务仓库数据默认保存 3 天,之后创建的数据仓库,数据默认保存 30 天,如需长时间保存,请到七牛官方时序数据库管理页面修改数据仓库的数据保存时间;对于已经存在的数据源,并且已经创建过同名导出,自动创建导出将不生效;自动创建导出的repo名称需要统一为小写 tsdb 命名的 repo 名称不支持大写。
指定时序数据库仓库名称(pandora_tsdb_name): 默认与 pandora_repo_name 相同,可指定 pandora_enable_tsdb 创建的时序数据库仓库名称。
指定时序数据库序列名称(pandora_tsdb_series_name): 默认与 pandora_repo_name 相同,可指定创建的时序数据库的序列名称。
指定时序数据库标签(pandora_tsdb_series_tags): 在创建序列时,将该选项中填入的字段设置为索引字段(具体请参考 Pandora 时序数据库服务), 当有多个字段时,用空格隔开。
时序数据库域名(pandora_tsdb_host): 默认为 https://tsdb.qiniu.com ,创建时序数据库仓库的服务地址。
指定时序数据库时间戳(pandora_tsdb_timestamp): 序列的时间戳字段,当字段为空时,时序数据库将自动将导出时间作为时间戳。
自动导出到七牛云存储(pandora_enable_kodo): 默认为 false,不启用,该字段表示是否在用户 pandora_schema_free 状态下直接将数据导出到七牛云存储。所以若 pandora_enable_kodo 生效的前提是 pandora_schema_free 是生效的。注意:该配置不会自动创建云存储的 bucket,使用该功能注意提前创建 bucket,同时在 pandora_schema_free 字段增加的情况下会更新导出。 注意,自动导出到云存储的数据默认保存 30 天,如需长时间保存,请到 workflow 页面修改导出的数据保存时间。
云存储仓库名称(pandora_bucket_name): 当 pandora_enable_kodo 生效是必填, 默认与 pandora_repo_name 相同,指定云存储的 bucket 名称。
高级选项
添加系统时间(logkit_send_time): 默认为 “true”,是否在发送时自动添加发送时间,时间格式为 RFC3339Nano。
大数据平台域名(pandora_host): 必填,pandora 服务地址。
创建的资源所在区域(pandora_region): 必填,Pandora 服务的地域。
自动创建数据源并更新(pandora_schema_free): 默认为 false,不启用,该字段表示在用户数据有新字段时就更新 Pandora 数据源,添加字段,如果数据源不存在,创建数据源。即
pandora_schema_free功能包含pandora_auto_create,启用该字段最大的好处是免除了数据更新导致 Pandora 数据源少收集或无法收集的困扰,使得用户可以从 schema 中解放出来,无需在意解析到的字段名称。特别适合 logkit Pro 的入门用户,一开始可以使用 pandora_schema_free 功能,快速将数据发送到 Pandora,然后调试 parser,解析出新的字段。注意,目前自动推导支持所有 Pandora 的数据类型,但是仅符合 RFC3339 格式的 string 会推导成 date 类型,其他都是按照数据的原始类型推导。以 DSL 语法自动创建数据源(pandora_auto_create): 该字段表示字段创建,默认为空,不自动创建。若填写该字段,则表示自动创建。若 repo 不存在,则先创建 repo,若 repo 存在,则在已存在的 repo 上添加字段。 repo 的 DSL 创建规则为<字段名称> <类型>,字段名称和类型用空格符隔开,不同字段用逗号隔开。若字段必填,则在类型前加*号表示。如果开启了 pandora_schema_free 这里只要声明部分想要指定的字段和类型即可,无需写完全。
- pandora date 类型:date,DATE,d,D
- pandora long 类型:long,LONG,l,L
- pandora float 类型: float,FLOAT,F,f
- pandora string 类型: string,STRING,S,s
- pandora jsonstring 类型: jsonstring,JSONSTRING,JSON,json
- pandora bool 类型: bool,BOOL,B,b,boolean
- pandora array 类型: array,ARRAY,A,a;括号中跟具体array元素的类型,如a(l),表示array里面都是long。同时,也可以省略小括号前的array类型申明,直接写(l),表示 array类型,里面的元素是long
- pandora map 类型: map,MAP,M,m;使用花括号表示具体类型,表达map里面的元素,如map{a l,b map{c b,x s}}, 表示map结构体里包含a字段,类型是long,b字段又是一个map,里面包含c字段,类型是bool,还包含x字段,类型是string。同时,也可以省略花括号前面的map类型,直接写{s l},表示map类型,里面的元素s为long类型。
筛选字段(pandora_schema): 提供了 schema 的选项和别名功能,如果不填,则认为所有 parser 出来的 field 只要符合 pandora schema 就发送;如果填,可以只选择填了的字段打向 pandora,根据逗号分隔,如果要以别名的方式打向 pandora,加上空格跟上别名即可。若最后以逗号省略号”,…”结尾则表示其他字段也以 pandora的 schema 为准发送。Pandora Sender 会在 runner 启动时获取 repo 的 schema,若用户缺少一些必填的 schema,会帮助填上默认值。
压缩发送(pandora_gzip): 是否使用 gzip 压缩传输数据,默认不压缩。注意,压缩会占用 CPU 资源,但是会节省带宽,有利有弊,请根据业务情况选择。
流量限制(flow_rate_limit): 每秒的流量限制,单位为 KB,默认不限速,注意填写的为数字字符串,如 “1024”,表示限速每秒 1024 KB,注意,限速并发准确值,会有数值上的偏差,偏差范围在 1KB 以内。若单个 batch 的大小超过了流量限制,logkit Pro 会将 batch 一拆为二。警告:若单个点的大小超过了流量限速的最大限制,logkit Pro 将发送不出该点,请根据单条日志大小谨慎配置。
请求限制(request_rate_limit): 每秒请求数限制,默认不限速,注意填写的为数字字符串,如 “500”,表示每秒限制最多 500 个请求。注意,限速并发准确值,会有数值上的偏差,偏差范围在每秒 20 个请求以内。
数据植入UUID(pandora_uuid): 是否在数据结果中自动生成 Pandora_UUID 字段,默认不开启, Pandora_UUID 的生成规则采用 RFC4122 中描述的 V4 版本 Random 规则生成。padnora_uuid 功能在数据中自动生成一个 Pandora_UUID 字段,该字段保证了发送出去的每一条数据都拥有一个唯一的 UUID,可以用于数据去重等需要。
扰动时间字段增加精度(force_microsecond): 默认 false,不启用,该参数用来将数据源中的时间类型强制转换成微秒精度,并且加上一个微妙级的时间扰动,使得秒级精度下面的数据,同一秒内的不同数据有不同的时间精度。主要应用的场景为数据导出到 Pandora TSDB 时可以有更好的精度显示,使用了该参数不会产生数据覆盖问题。
自动转换类型(pandora_force_convert): 默认为 false。开启后会强制类型转换,如定义的 pandora schema 为 long,而实际的为 string,则会尝试将 string 解析为 long类型(int 64),若无法解析,则忽略该字段内容。使用这个功能可以解决一整条数据中有些字段生成的类型不确定导致写入 Pandora 失败的问题。 pandora_auto_convert_date 可选字段,默认为 true 开启。会自动将用户的自动尝试转换为 Pandora 的时间类型(date),Pandora的时间类型为符合 RFC3339 格式的字符串,若已经符合该类型,则无需开启,关闭可节省 CPU 开销。默认开启,会尝试将进行各种类型的格式转换,包括不同的时间格式字符串的变化,整型作为 unix timestamp 进行转换等等。
数字统一为 float(number_use_float): 默认为 “false”,当填为 true 时,会将数据中所有的数字作为 float 类型。该功能适用于数字又有可能是整型又有可能是浮点型的场景,统一作为 float,可避免数据类型冲突。
忽略错误字段(ignore_invalid_field): 默认为 true 开启,会进行数据格式校验,并忽略不符合格式的字段数据,默认开启,关闭可以节省 CPU 开销。如 Pandora 的类型选择了 jsonstring,若字符串不是合法的 json 字符串,就会忽略改部分字段内容,其他字段正常上报。
服务端反转译换行/制表符(pandora_unescape): 在 Pandora 服务端反转译\n=>\n, \t=>\t; 由于 Pandora 数据上传的编码方式会占用\t和\n这两个符号,所以在sdk中打点时会默认把\t转译为\t,把\n转译为\n,开启这个选项就是在服务端把这个反转译回来。开启该选项也会转译数据中原有的这些\t和\n符号
常用功能
自动创建 Pandora 数据源,通过 pandora_auto_create 字段创建。
自动添加 Pandora 数据字段,通过 pandora_schema_free 字段,可以自动更新 Pandora 的数据源,添加字段。
流量控制,通过 request_rate_limit 以及 flow_rate_limit 可以控制每秒的请求数以及每秒的请求数据量,若设置的 batchsize 过大导致流量限制,logkit Pro 会自动将 batch 拆分。
压缩传输, 通过 pandora_gzip 配置,可以选择使用 gzip 压缩的方式传输数据,大大节约带宽。
字段选择与别名,通过 pandora_schema 可以选择要发送到 Pandora 的字段,同时可以将 Parser 出的字段名通过别名的方式与 Pandora 的名字进行一一对应。
类型转换,对于解析到的如 string,long 等类型,会根据 Pandora 实际创建的数据源字段类型,进行一定的类型转换,可以进行类型转换的 Pandora 字段包括 string(转换为字符串), long(转换为int64整型), float(转换为float64浮点型), date(转换为rfc3339格式的字符串时间表示),支持的转换为时间类型的数据包括:
- 精确到微秒的整型(可以从数字、字符串中提取)
2006/01/02 15:04:05,2006-01-02 15:04:05 -0700 MST,2006-01-02 15:04:05 -0700,2006-01-02 15:04:05,2006/01/02 15:04:05 -0700 MST,2006/01/02 15:04:05 -0700,2006-01-02 -0700 MST,2006-01-02 -0700,2006-01-02,2006/01/02 -0700 MST,2006/01/02 -0700,2006/01/02,Mon Jan _2 15:04:05 2006 ANSIC,Mon Jan _2 15:04:05 MST 2006 UnixDate,Mon Jan 02 15:04:05 -0700 2006 RubyDate,02 Jan 06 15:04 MST RFC822,02 Jan 06 15:04 -0700 RFC822Z,Monday, 02-Jan-06 15:04:05 MST RFC850,Mon, 02 Jan 2006 15:04:05 MST RFC1123,Mon, 02 Jan 2006 15:04:05 -0700 RFC1123Z,2006-01-02T15:04:05Z07:00 RFC3339,2006-01-02T15:04:05.999999999Z07:00 RFC3339Nano,3:04PM Kitchen,Jan _2 15:04:05 Stamp,Jan _2 15:04:05.000 StampMilli,Jan _2 15:04:05.000000 StampMicro,Jan _2 15:04:05.000000000 StampNano,
发送到本地文件(File Sender)
发送到指定文件(file_send_path): 发送文件路径,会将数据按照行,使用 json 格式写入本地文件。
file_send_path 支持写一个 Pattern 作为路径,例如 “file_send_path”:”data-%Y-%m-%d.txt” ,此时数据就会渲染出日期,存放为 data-2018-03-28.txt, 该功能使得数据可以 rotate 存放,非常适用于归档。
使用场景
在做测试时使用该模式,发送到本地磁盘,查看发送情况
部署虚拟文件系统,挂载 volume,使用 HDFS 等。
渲染变量
file_send_path 支持的渲染变量列表如下:
| 填写模式 | 描述 |
|---|---|
| %A | 国际化表示法的星期名全称 |
| %a | 国际化表示法的星期名简称 |
| %B | 国际化表示法的月名全称 |
| %b | 国际化表示法的月明简称 |
| %C | 年份除以100后的小数表示法,精确到2位小数 |
| %c | 国际表示法的时间和日期 |
| %D | 等价于格式: %m/%d/%y |
| %d | 日期 (01-31) |
| %F | 等价于格式: %Y-%m-%d |
| %H | 24小时表示法 (00-23)时 |
| %I | 12小时表示法 (01-12)时 |
| %j | 一年中的第几天 (001-366) |
| %M | 分钟 (00-59) |
| %m | 月份 (01-12) |
| %R | 等价于 %H:%M |
| %S | 秒钟 (00-60) |
| %T | 等价于 %H:%M:%S |
| %u | 一周中的第几天 (1-7) |
| %W | 一年中的第几周 (00-53) |
| %X | 国际化表示法的时分秒 |
| %x | 国际化表示法的年月日 |
| %Y | 年份 |
| %y | 去掉百年进制的年份 (00-99),如2018就是18 |
| %Z | 时区名称 |
| %z | 时区偏移数值 |
| %% | 转义一个 ‘%’ |
发送到 MongoDB 服务(MongoDB Accumulate Sender)
将日志数据解析并进行聚合后发送到 MongoDB。
数据库地址(mongodb_host): Mongodb 的地址:mongodb://[username:password@]host1[:port1][,host2[:port2],…[,hostN[:portN]]][/[database][?options]]。
聚合条件列(mongodb_acc_updkey): Mongodb 的聚合条件列,按逗号分隔各列名。如果需要在写入 mongodb 时候对列名进行重命名,配置时候只要在原列名后增加新名字即可,如 time5Min time 将 parse 结果中的time5Min,写入 mongodb 的 time 字段。
聚合列(mongodb_acc_acckey): Mongodb 的聚合列,按照逗号分隔各列名。如果需要在写入 mongodb 时候对列名进行重命名,配置时候只要在原列名后增加新名字即可,用法同 mongodb_acc_updkey。
发送到 InfluxDB 服务(InfluxDB Sender)
- 数据库地址(influxdb_host): influxdb 服务地址。
高级选项
自动创建数据库(influxdb_auto_create): 自动创建 influxdb 的 database、series 以及 retention policy
retention名称(influxdb_retention): influxdb 的retention policy 名字,可不填。
retention时长(influxdb_retetion_duration): 指定的 retention 名称若不存在对应 retention,会根据 influxdb_auto_create 选为 true 时自动创建,自动创建指定的时间周期由该选项确定。
标签列数据(influxdb_tags): influxdb 的 tag 列名,用”,”逗号分隔,分隔后每一个字符串中间有空格,则认为是起了别名,如 “name alias,name2” 这样
普通列数据(influxdb_fields): influxdb 的 field 列名,同 tags。
时间戳列(influxdb_timestamp): influxdb 的时间戳列名。
普通列数据(influxdb_timestamp_precision): 时间戳列的精度,如果设置 100,那么就会在 send 的时候将 influxdb_timestamp * 100 作为 nano 时间戳发送到 influxdb。
发送到 ElasticSearch(ElasticSearch Sender)
host地址(elasitc_host): elasticsearch 服务地址, 多个地址使用,分隔。
ES 版本号(elastic_version): es 服务端的版本号,目前支持 3.x(含2.x) 5.x(5.x) 以及6.x(6.x)。
索引类型名称(elastic_type): elasticsearch 索引下的 type,默认为 logkit。
自动索引模式(index_strategy): 创建索引的策略,默认为 default 用一个索引,也可以选择 year 按年创建索引,month 按月创建索引,day 按天创建索引
索引时区(elastic_time_zone): 创建索引使用的时区,支持 Local(本地时区) UTC(标准时区) 以及 PRC(中国)
添加系统时间(logkit_send_time): logkit 的数据发送时间,默认为 true,可用于查看数据是否发送延迟等。
发送到 Kafka(Kafka Sender)
broker 的 host 地址(kafka_host): 必填项,kafka broker 的服务地址,多个可以用逗号连接。如:”192.168.31.201:9092,192.168.31.202:9092”
打点的 topic 名称(kafka_topic): 必填项,发送到的 kafka topic 名称。还可以用数据路由的方式,填写格式如:%{[kafka_topic_field]},default_topic 此时会从发送的数据中寻找字段为”kafka_topic_field”的string类型数据,并将至作为topic发送,否则就使用填写的default_topic名称作为发送目的地。
压缩模式(kafka_compression): 非必填项,kafka 发送的数据压缩方式,默认不压缩。
高级选项
kafka 客户端标识 ID(kafka_client_id): 非必填项,kafka client 的 ID,默认使用 hostname。
kafka 最大错误重试次数(kafka_retry_max): 非必填项,kafka 发送的失败重试时间,默认重试 3 次。
kafka 连接超时时间(kafka_timeout): 非必填项,超时时间,默认 30s。
kafka 的 keepalive 时间(kafka_keep_alive): 非必填项,keep_alive 的时间,默认不开启。
通过 Http Post 发送
发送目的 url(http_sender_url): 必填, post 请求发送的路径。
发送数据时使用的格式(http_sender_protocol): 选填, 发送的数据格式, 有 json 和 csv 两种选择, 默认为 json。
http_sender_csv_split(csv 分隔符): 选填, 使用 csv 发送时, 不同列之前的分隔符, 默认为 \t
- http_sender_gzip: 选填, 发送时启用 gzip, 默认开启
常见问题
读取的日志在不同路径下该如何配置?
可以使用 file reader 中的tailx 模式。
定位 logkit Pro 读取的日志来源
在所有 parser 中都有一个 label 功能,这个功能可以用于填写机器编号,ip,服务名、团队名称等各种各样用于区别 logkit Pro 数据来源的标签,这些标签会附加在 logkit Pro 的日志中,便于在大的方向上定位日志来源。
如果是在 tailx 模式下,一个配置文件可以读多个路径,可以使用 datasource_tag 功能,将读取的日志路径作为一个字段记录在日志中。
不重不漏的高效发送日志数据
logkit Pro sender 支持用磁盘队列进行容错,容错策略(ft_strategy)选择:”always_save”, 此时数据就保证不重不漏了。
配置发送并发数量”ft_procs”:”2”,就是开 2 个并发发送,速度就能大大提升。
如果还嫌不够快怎么办?可以用内存管道替换磁盘队列噢,但是需要说明,使用内存队列在logkit 异常退出时有丢失数据的风险。
发送一份数据到多个数据源?
添加多个收集器分别发送。
发送到 Pandora 的数据变化怎么处理?
在发送到 Pandora 的过程中,如果数据字段有增加,只要配置 sende r的 pandora_schema_free 为 true 即可,会自动识别并更新数据源的 schema。
发送到 Pandora 的数据,类型不能被logkit Pro 自动判别怎么办? 此时在配置 pandora_schema_free 的情况下,再配置一下 pandora_auto_create, 只需要填写那些特殊的类型即可,比如 fieldx jsonstring,其他字段依旧可以通过 pandora_schema_free 自动更新。
Pandora 不接受的字段名称如何处理呢? 在 ELK 中,常见的就是 @timestamp,但是 @ 符号,Pandora 是不支持的,此时只要使用 pandora_schema 字段配置一下 pandora 的别名即可,如:”@timestamp timestamp,…”。同样不支持的符号还包括中划线、竖线等,目前 Pandora 支持的符号是数字、字母以及下划线。
注意最后要填写,… 表示其他字段都要。因为 pandora_schema 除了别名功能以外,还支持字段的选择,如果不加”,…”则表示其他字段都不选。
Grok 解析特别难怎么办?
我们特意写了一个调试 grok 的教程,欢迎阅读:https://github.com/qiniu/logkit/wiki/Grok-Parser#%E5%A6%82%E4%BD%95%E8%B0%83%E8%AF%95%E6%82%A8%E7%9A%84grok-patterngrokdebug%E7%94%A8%E6%B3%95
了解更多 logkit Pro 奥秘请阅读 logkit wiki。

若有收获,就点个赞吧
0 人点赞
