之前用[0]、[bx]的方法访问内存的指令中,定位内存单元的地址。本章主要通过具体的问题来讲解一些更灵活的定位内存地址的方法和相关的编程方法。
一、and和or指令
先介绍一下and和or指令
1.1 and指令
and指令:逻辑与指令,按位进行与运算,例如指令
mov al,01100011Band al,00111011B
执行后,al = 00100011B
通过该指令可将操作对象的相应位设为0,其他保持不变,例如
and al,10111111B ; 将al的第6位设为0的指令and al,01111111B ; 将al的第7位设为0的指令and al,11111110B ; 将al的第0位设为0的指令
1.2 or指令
or指令:逻辑或指令,按位进行或运算,例如指令
mov al,01100011Bor al,00111011B
执行后,al=01111011B
通过该指令可将操作对象的相应位设为1,其他位不变,例如
or al,01000000B ; 将al的第6位设为1or al,10000000B ; 将al的第7位设为1or al,00000001B ; 将al的第0位设为1
二、关于ASCII码
计算机中,所有的信息都是二进制,而人能理解的信息都是已经具有约定意义的字符。比如说,人在有一定上下文得情况下看到123,就可以知道这是一个数值,他的大小为123;看到BASIC就知道这是在说BASIC这种编程语言;看到desk就知道说的是桌子。
而我们需要把这些信息存储在计算机中,就要对其进行编码,将其转化为二进制信息进行存储。而计算机要将这些存储的信息再展示给我们看,就要再对其进行解码。只要编码和解码采用相同的规则,我们就可以将人能理解的信息存入到计算机,再从计算机中取出。
世界上有很多编码方式,有一种方案叫做ASCII编码,实在计算机系统中通常被采用的。简单地来说,所谓编码方案,就是用一套规则,它约定了用什么样的信息来表示现实对象。比如说,再ASCII编码方案中,用61H表示a,62H表示b,一种规则需要人们遵守才有意义。
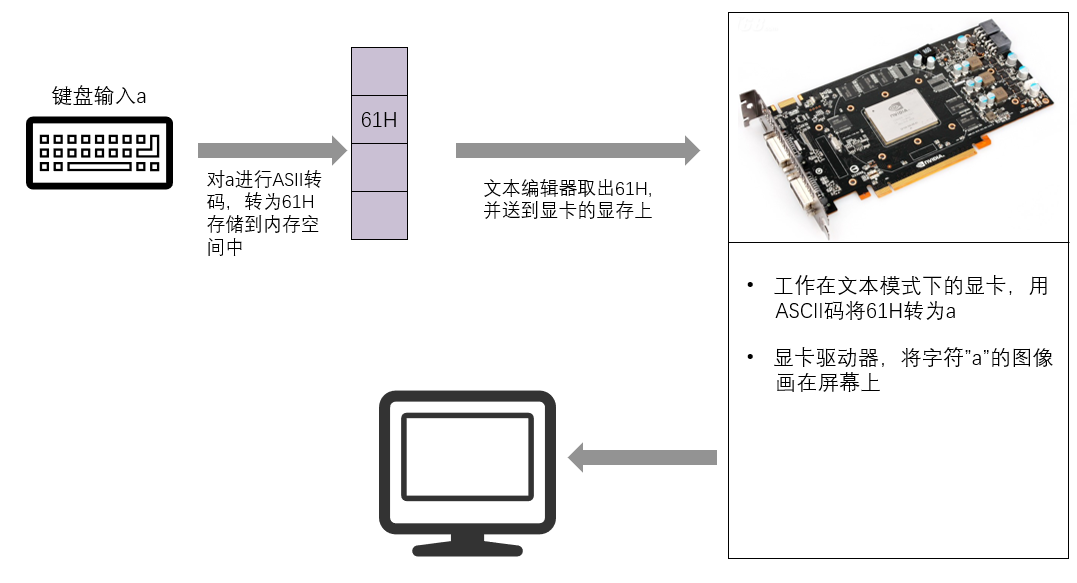
一个文本编辑过程中,就包含着按照ASCII编码规则进行的编码和解码。在文本编辑过程中,我们按一下键盘的a键,就会在屏幕上看到a,这是一个怎么样的过程呢?
我们按下键盘的a键,这个按键的信息就会被送入计算机,计算机用ASCII码的规则对其进行编码,将其转化为61H存储在内存的指定空间中;文本编辑软件从内存中取出61H,将其送到显卡上的显存中;工作在文本模式下的显卡,用ASCII码的规则解释现存中的内容,61H被当作字符”a”,显卡驱动显示器,将字符”a”的图像画在屏幕上。我们可以看到,显卡在处理文本信息的时候,是根据ASCII码的规则进行的。这也就是说,如果我们要想在显示器上看到”a”,就要给显卡提供”a”的ASCII 码,61H。如何提供?当然是写入显存中
三、以字符形式给出的数据
我们可以在汇编程序中,用' '的方式指明数据是以字符的形式给出的,编译器将把它们转化为想对印的ASCII码,如下面的程序
; *****程序7.1*****assume cs:code,ds:datadata segmentdb 'unIX'db 'foRK'data endscode segmentstart: mov al,'a'mov bl,'b'mov ax,4c00hint 21hcode endsend start
上面的源程序中:
db unIX相当于db 75H,6EH,49H,58H,u,n,I,X的ASCII码分别为75H, 6EH, 49H和58Hdb foRK相当于db 66H,6FH,52H,4BH,f,o,R,K的ASCII码分别为66H, 6FH, 52H和4BHmov al,'a'相当于mov al,61H,'a'的ASCII码为61Hmov bl,'b'相当于mov bl,62H,'b'的ASCII码为62H
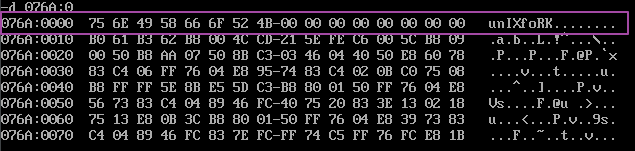
将上述程序编译、连接后,Debug的r命令查看

因为DS=075A,data段又是程序中的第一个段,它就在程序的起始处,所以它的段地址为076AH,现在使用d查看其中的内容,可以看到其中存放的数据段的内容。
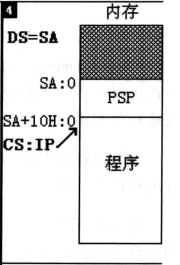
还记得之前这张图吗?
这张图就说明了
,当然这是在没有给ds赋值之前的,如果使用了
mov ds,data,就相当于把data段的段地址给了DS,此时DS就指向了不同的内容
四、大小写转换的问题
下面考虑这样一个问题,在codesg中填写代码,将datasg中的第一个字符串转化为大写,将第二个字符串转化为小写
assume cs:codesg,ds:datasgdatasg segmentdb 'BaSiC'db 'iNfOrMaTiOn'datasg endscodesg segmentstart:codesg endsend start
首先分析一下,我们知道同一个字母的大写字符和小写字符对应的ASCII码是不同的,比如”A”的ASCII码是41H,”a”的ASII码是61H。要改变一个字母的大小写,实际上就是要改变它对应的ASII码。我们可以将所有的字母的大写字符和小写字符对应的ASCII码列出来,进行对比,从其中找到规律。
| 大写字母:及其对应的十六进制:对应的二进制 | 小写字母:及其对应的十六进制:对应的二进制 |
|---|---|
| A:41H:01000001 | a:61H:01100001 |
| B:42H:01000010 | b:62H:01100010 |
| C:43H:01000011 | c:63H:01100011 |
| D:44H:01000101 | d:64H:01100100 |
| E:45H:01000101 | e:65H:01100101 |
| F:46H:01000110 | f:66H:01100110 |
| … | … |
从中我们得到如下规律
按照上面的规律,实现大小写转换
assume cs:codesg,ds:datasgdatasg segmentdb 'BaSiC'db 'iNfOrMaTion'datasg endscodesg segmentstart:mov ax,datasgmov ds,axmov bx,0mov cx,5s:mov al,[bx]; 如果(al)>61H,则为小写字母的ASCII码,则sub al,20Hmov [bx],alinc bxloop s...code endsend start
但是,判断指令我们还没有学到,所以不能解决如果al>6H这个要求,现在应该怎么办呢?
如果一个问题的解决方案,是我们陷入了一种矛盾之中。那么,很可能是我们考虑的出发点有了问题,或是说,我们起初运用的规律并不合适。
这个时候应该重新观察,寻找新的规律,观察其二进制数据,可以看到大写字母的第5位数字为0,而小写字母的第5位数字为1,这个就是新的规律了。

用什么方法将一个数据中的某一个位 置0还是置1?就是用刚刚学习过的or和and指令,完整程序如下
assume cs:codesg,ds:datasgdatasg segmentdb 'BaSiC'db 'iNfOrMaTion'datasg endscodesg segmentstart:mov ax,datasgmov ds,ax ; 设置ds指向datasg段mov bx,0 ; 设置 (bx)=0, ds:bx指向'BaSiC'的第一个字母mov cx,5 ; 设置循环次数为5s:mov al,[bx] ; 将ASCII码从ds:bx所指向的单元中取出and al,11011111B ; 将al中的ASCII码的第5位 置0,变为大写字母mov [bx],al ; 将转变后的ASCII码写回原单元inc bx ; (bx)加1,ds:bx指向下一个字母loop smov bx,5 ; 设置(bx)=5,ds:bx指向'iNfOrMaTiOn'的第一个字母mov cx,11 ; 设置循环次数11,因为'iNfOrMaTiOn'有11个字母s0:mov al,[bx]or al,00100000B ; 将al中的ASCII码的第5位设为1,变为小写字母mov [bx],alinc bxloop s0mov ax,4c00hint 21hcode endsend start
五、[bx+idata]
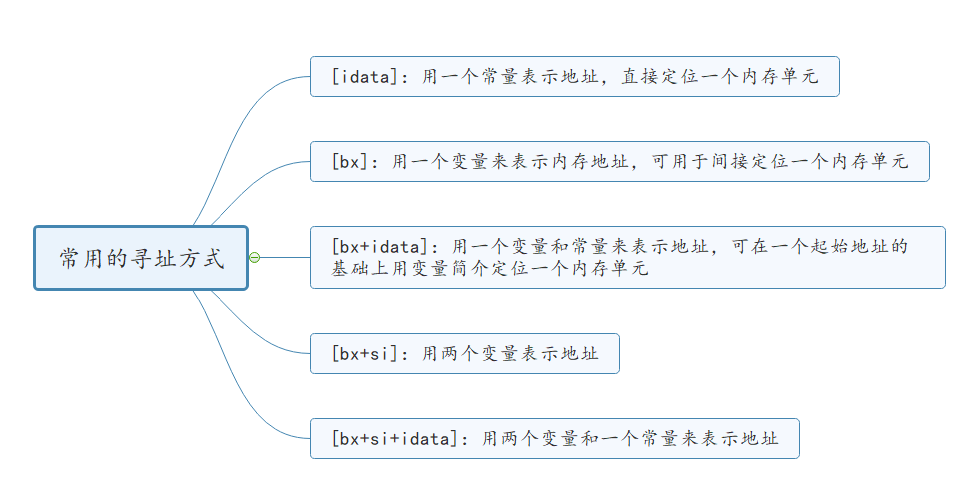
指明一个内存单元的方式
- 用
[bx]的方式来指明一个内存单元 - 用
[bx+idata]来表明一个内存单元,它的编译地址为%2Bidata%7D#card=math&code=%5Ctext%7B%28bx%29%2Bidata%7D&id=EufF3)(
中的数值加上
)
例如下面的指令
; 下面三种写法意思一样mov ax,[bx+200]mov ax,[200+bx]mov ax,[bx].200; 将一个内存单元的内容送入ax,这个内存单元的长度为2个字节(字单元),存放一个字,; 偏移地址为bx中的数值加上200,段地址在ds中
六、用[bx+idata]的方式进行数组的处理
有了这种内存表示的方式,我们就可以用更高级的结构来看待所要处理的数据。通过下面的问题来理解这一点。
在codesg中填写代码,将datasg中定义的第一个字符串转化为大写,第二个字符串转化为小写。
; 一个大致的框架程序assume cs:codesg,ds:datasgdatasg segmentdb 'BaSiC'db 'MinIX'datasg endscodesg segmentstart:; 填充的代码codesg endsend start
有了上述的框架后,现在就需要往其中填写代码实现所需要的功能,现在使用原来的[bx]的方式来定位字符位置,代码如下
; 使用[bx]方式来决定字符的位置mov ax,datasgmov ds,axmov bx,0mov cx,5s: mov al,[bx]and al,11011111bmov [bx],alinc bxloop smov bx,5mov cx,5s0: mov al,[bx]or al,000100000bmov [bx],alinc bxloop s0
现在,我们有了[bx+idata]的方式,就可以用更简化的方法来完成上面的程序,对上面的程序进行改进过后的代码如下
; 改进版本1:使用[bx+idata]方式完成上述功能mov ax,datasgmov ds,axmov bx,0mov cx,5s: mov al,[bx] ; 定位第一个字符串中的字符and al,11011111bmov [bx],almov al,[5+bx] ; 定位第二个字符串中的字符or al,00100000bmov [5+bx],alinc bxloop s
程序也可以写为下面这个样子
; 改进版本2:使用idata[bx]方式完成上述功能mov ax,datasgmov ds,axmov bx,0mov cx,5s: mov al,0[bx] ; 定位第一个字符串中的字符and al,11011111bmov [bx],almov al,5[bx] ; 定位第二个字符串中的字符or al,00100000bmov 5[bx],alinc bxloop s
如果使用高级语言C语言来描述上面的程序,大致是这样的
char a[5]="BaSiC";char b[5]="MinIX";main (){int i;i = 0;do{a[i] = a[i] & 0xDF;b[i] = b[i] | 0x20;i++;}while (i<5);}
可以比较一下这个C程序和上面的汇编程序的相似之处,尤其注意它们定位字符串中字符的方式。
C语言: a[i], b[i]汇编语言: 0[bx], 5[bx]通过比较,可以发现,[bx+idata]的方式为高级语言实现数组提供了便利机制
七、SI和DI
SI和DI是8086CPU中和bx功能相近的寄存器,SI和DI不能够被分为两个8位寄存器来使用,下面的3组指令实现了相同的功能。
; 下面的3组指令实现相同的功能mov bx,0mov ax,[bx]mov si,0mov ax,[si]mov di,0mov ax,[di]
下面的3组指令也实现了相同的功能
mov bx,0mov ax,[bx+123]mov si,0mov ax,[si+123]mov di,0mov ax,[di+123]
八、[bx+si]和[bx+di]
在前面,我们用[bx(si或di)]和[bx(si或di)+idata]的方式来指明一个内存单元,我们还可以用更为灵活的方式:[bx+si]和[bx+di]。
[bx+si]和[bx+di]的含义相似,以[bx+si]为例子进行讲解
; [bx+si]表示一个内存单元,偏移地址为(bx)+(si),即bx中的数值加上si中的数值mov ax,[bx+si]; 指令的意思:将一个内存单元中的内容送入ax,这个内存单元的长度为2字节,存放一个字; 偏移地址为bx中的数值加上si中的数值; 段地址在ds中
之前用的[bx+idata]和idata[bx]的意思一致,这里同样的
; 下面3条指令意义一致mov ax,[bx+si]mov ax,[si][bx]mov ax,[bx][si]
九、[bx+si+idata]和[bx+di+idata]
之前学习的几种表示方法可以组合起来了,[bx+si+idata]和[bx+di+idata]的含义相似,以[bx+si+idata]为例进行讲解
; [bx+si+idata] 表示一个内存单元; 偏移地址为(bx)+(si)+idata
以一个指令为例子
mov ax,[bx+si+idata]; 将一个内存单元的内容送入ax,这个内存单元的长度为2字节,存放一个字; 偏移地址为bx中的数值加上si中的数值再加上idata,段地址在ds中
和之前的几种表示方法一样,一下几种指令都代表一个意思
mov ax,[bx+200+si]mov ax,[200+bx+si]mov ax,200[bx][si]mov ax,[bx].200[si]mov ax,[bx][si].200
十、不同的寻址方式的灵活应用
如果我们比较前面用到的几种定位内存地址的方法(或称为寻址方式),就可以发现
学习建议
完成这章的所有问题

若有收获,就点个赞吧
0 人点赞
