这一章,讨论如何有效合理地组织数据,以及相关的编程技术。
16.1 描述了单元长度的标号
之前,我们一直在代码段中使用标号来标记指令、数据、段的起始地址。比如,下面的程序将 code 段中的 a 标号处的 8 个数据累加,结果存储到 b 标号处的字中。
assume cs:codecode segmenta: db 1,2,3,4,5,6,7,8b: dw 0start: mov si,offset amov bx,offset bmov cx,8s: mov al,cs:[si]mov ah,0 # ax=0001, 0002, ..., 0008add cs:[bx],ax # 直接累加到 cs:[bx] 处inc siloop smov ax,4c00hint 21hcode endsend start
程序中,code、a、b、start、s都是标号,这些标号仅仅表示了内存单元的地址。
 使用一种标号,不仅表示内存单元的地址,还表示了内存单元的长度
使用一种标号,不仅表示内存单元的地址,还表示了内存单元的长度
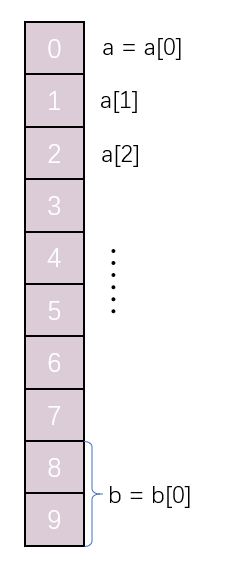
但是,我么们还可以使用一种标号,这种标号不仅表示内存单元的地址,还表示了内存单元的长度,即表示在此标号处的单元,是一个字节单元,还是字单元,还是双字单元。上面的程序还可以写成这样:
assume cs:codecode segmenta db 1,2,3,4,5,6,7,8 # a而不是a:,它是同时描述内存单元和单元长度的标号b dw 0start: mov si,0mov cx,8s: mov al,a[si]mov ah,0add b,axinc siloop smov ax,4c00hint 21hcode endsend start
在 code 段中使用的标号 a、b 后面没有 : ,它们是同时描述内存单元和单元长度的标号。
- 标号 a,描述了地址 code:0,和从这个地址开始,以后的内存单元都是字节单元;
- 标号 b,描述了地址 code:8,和从这个地址开始,以后的内存单元都是字单元。
 标号 a, b 表示一个段中的内存单元
标号 a, b 表示一个段中的内存单元
因为这种标号包含了对单元长度的描述,所以在指令中,它可以代表一个段中的内存单元。比如,对于程序的 b dw 0:
# 下面指令1和指令2是等价的mov ax,b # 指令1mov ax,cs:[8] # 指令2# 下面指令3和指令4是等价的mov b,2 # 指令3mov word ptr cs:[8],2 # 指令4# 下面指令5和指令6是等价的inc b # 指令5inc word ptr cs:[8] # 指令6
在上面的指令中,标号 b 代表了一个内存单元,地址为 code:8,长度为两个字节。
 引起错误的一些例子
引起错误的一些例子
下面的指令都是因为搞错了标号的长度(字、字节)而导致的编译错误
mov al,b # b 代表的内存单元是字单元,而 al 是8位寄存器。add b,al # 同上
对于上面程序中的开辟内存的代码 a db 1,2,3,4,5,6,7,8:
# 指令1和指令2相当mov al,a[si] # 指令1mov al,cs:0[si] # 指令2# 指令3和指令4相当mov al,a[3] # 指令3mov al,cs:0[3] # 指令4# 指令5和指令6相当mov al,a[bx+si+3] # 指令5mov al,cs:0[bx+si+3] # 指令6
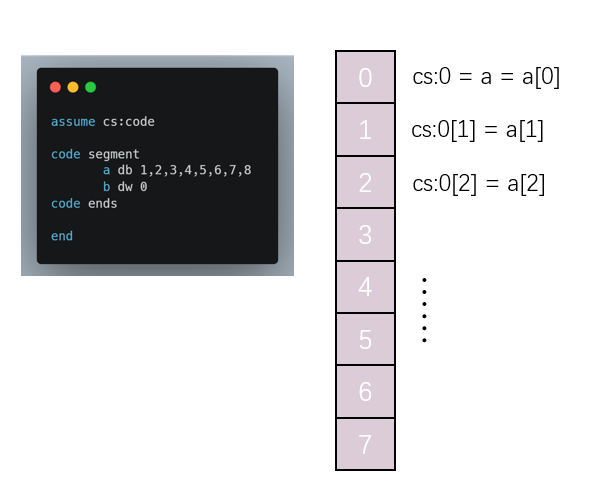
上述代码中的标号 a 代表的就是 cs:0 这个地址。可见,使用这种包含单元长度的标号,可以使得我们以简单的形式访问内存中的数据。以后,我们将这种标号成为数据标号,它标记了存储数据的单元的地址和长度。它不同于仅仅表示地址的地址表好。
 检测点 16.1
检测点 16.1

16.2 在其他段中使用数据标号
一般来说,我们不在代码段中定义数据,而是将数据定义到其他段中。在其他段中,我们也可以使用数据标号来描述存储数据的单元的地址和长度。
注意:在后面加有 **:** 的地址标号,只能在代码段中使用,不能在其他段中使用。
下面的程序将 data 段中 a 标号处的 8 个数据累加,结果存储到 b 标号处的字中。
assume cs:code,ds:data # 让编译器知道 ds→data,实际不一定data segmenta db 1,2,3,4,5,6,7,8b dw 0data endscode segmentstart: mov ax,datamov ds,ax # 手动设置 ds→datamov si,0mov cx,8s: mov al,a[si]mov ah,0add b,axinc siloop smov ax,4c00hint 21hcode endsend
下面是对上面代码中值得注意的地方进行讲述
 使用
使用 assume 将标号所在段和段寄存器联系,让编译器知道
注意:如果想在代码段中直接用数据标号访问数据,则需要用伪指令 assume 将标号所在的段和一个段寄存器联系起来(即,assume cs:code,标号 code 和寄存器 cs 联系起来)。否则编译器在编译的时候,无法确定标号的段地址在哪一个寄存器中。
当然,这种联系是编译器需要的,但绝对不是说,我们因为编译器的工作需要,用 assume 指令将段寄存器和某个段相联系,段寄存器中就会真的存放该段的地址。我们在程序中还要使用指令对段寄存器进行设置。
比如,在上面的程序中,我们要在代码段 code 中用 data 段中的数据标号 a、b访问数据,则必须用 assume 将一个寄存器和 data 段相联。在程序中,我们用 ds 寄存器和 data 段相联,则编译器对相关指令的编译如下。
mov al,a[si]# 编译为👇mov al,[si+0]add b,ax# 编译为👇add [8],ax

assume 只是让编译器知道,我们必须手动设置正确的的标号和段寄存器关系
因为这些实际编译出的指令,都默认访问单元的段地址在 ds 中,而实际访问的段为 data,所以如果要访问正确,在这些指令执行前,ds 中必须为 data 段的段地址。则我们在程序中使用指令:
# 设置 ds→data段mov ax,datamov ds,ax
可以将标号当作数据来定义。此时,编译器将标号所表示的地址当作数据的值。比如:
data segmenta db 1,2,3,4,5,6,7,8b dw 0c dw a,bdata ends# 数据标号c处存储的是两个字型数据为标号a, b的偏移地址。相当于:data segmenta db 1,2,3,4,5,6,7,8b dw 0c dw offset a,offset bdata ends
再比如:
data segmenta db 1,2,3,4,5,6,7,8b dw 0c dd a,bdata ends# 数据标号c处存储的两个字型数据为标号a的偏移地址和段地址、标号b的偏移地址和段地址。相当于:data segmenta db 1,2,3,4,5,6,7,8b dw 0c dw offset a,seg a,offset b,seg b # seg操作符,取得某一标号处的段地址data ends
 检测点 16.2
检测点 16.2

16.3 直接定址表
现在,我们讨论查表的方法编写相关程序的技巧。
 编写子程序
编写子程序
编写子程序:以 16 进制的形式在屏幕中间显示给定的字节型数据。
 分析
分析
一个字节需要用两个十六进制数码来表示。所以,子程序需要在屏幕上显示两个 ASCII 字符。我们当然要用“0”、“1”、”2“、”3“、”4“、”5“、”6“、”7“、”8“、 ”9“、”A“、”B“、”C“、”D“、”E“、”F“ 这 16 个字符来显示十六进制数码。
我们可以将一个字节的高 4 位和低 4 位分开,分别用它们的值得到对应的数码字符。比如 2Bh,可以得到高 4 位的值为2,低 4 位的值为11,那么如何用这两个数值得到对应的数码字符 ”2“ 和 ”B“ 呢?
最简单的办法就是一个个比较,如下:
- 如果数值为 0,则显示 ”0“;
- 如果数值为 1,则显示 ”1“;
- …
- 如果数值为 11,则显示 ”B“;
- …
但是,我么可以看到,这样做的话程序中要使用多条比较、转移指令。程序比较长和混乱。
显然,我们希望能够在数值 0~15 和字符 ”0“~”F“ 之间找到一种映射关系。
数值 0~9 和字符 "0"~"9"之间的映射关系为:数值+30h=对应字符的ASCII值0+30h="0"的ASCII值1+30h="1"的ASCII值2+30h="2"的ASCII值...9+30h="9"的ASCII值10~15 和字符 "A"~"F"之间的映射关系为:数值+37h=对应字符的ASCII值10+37h="A"的ASCII值11+37h="B"的ASCII值12+37h="C"的ASCII值...15+37h="F"的ASCII值
因为数值 0~15 和字符 “0”~”F” 之间没有一致的映射关系存在,所以,我们应该在它们之间建立新的映射关系。
具体的做法是:建立一张表,表中依次存储字符 “0”~”F”,我们可以通过数值 0~15 直接查找到对应的字符。
 子程序如下:
子程序如下:

; 用 al 传送要显示的数据showbyte: jmp short showtable db '0123456789ABCDEF' ; 字符表show: push bxpush esmov ah,alshr ah,1shr ah,1shr ah,1shr ah,1and al,00001111b ; 右移4位,ah中得到高4位的值, al中为低4位的值mov bl,ahmov bh,0mov ah,table [bx] ; 用高4位的值作为相对于table的偏移,取得对应的字符mov bx,0b800hmov es,bxmov es:[160*12+40*2],ahmov bl,almov bh,0mov al,table [bx] ; 用低4位的值作为相对于table的偏移,取得对应的字符mov es:[160*12+40*2+2],alpop espop bxret
可以看出,在子程序中,我们在数值 0~15 和字符 “0”~”F 之间建立的映射关系为:以数值 N 为 table 表中的偏移,可以找到对应的字符。
利用表,在两个数据集合之间建立一种映射关系,是我们可以用查表的方法根据给出的数据得到其在另一集合中的对应数据。这样做的目的一般来说有以下几个。
- 为了算法的清晰和简洁;
- 为了加快运算速度;
- 为了使程序易于扩充。
 在上面的子程序中,我们更多的是为了算法的清晰和简洁,而采用了查表的方法。下面我们来看一下,为了加快运算速度而采用查表的方法的情况。
在上面的子程序中,我们更多的是为了算法的清晰和简洁,而采用了查表的方法。下面我们来看一下,为了加快运算速度而采用查表的方法的情况。
 编写一个子程序,计算
编写一个子程序,计算 %2Cx%5Cin%5C%7B%200%5Cdegree%2C30%5Cdegree%2C60%5Cdegree%2C90%5Cdegree%2C120%5Cdegree%2C150%5Cdegree%2C180%5Cdegree%5C%7D#card=math&code=%5Csin%28x%29%2Cx%5Cin%5C%7B%200%5Cdegree%2C30%5Cdegree%2C60%5Cdegree%2C90%5Cdegree%2C120%5Cdegree%2C150%5Cdegree%2C180%5Cdegree%5C%7D&id=Nuf7C),并在屏幕中间显示计算结果。比如,
#card=math&code=%5Csin%2830%5Cdegree%29&id=hsOCf)的结果显示为 “0.5”。
我们可以利用麦克劳林公式来计算#card=math&code=%5Csin%28x%29&id=VewRe)。
为角度,麦克劳林公式中需要代入弧度,则:
%20%26%3D%20%5Csin(y)%5Capprox%20y-%5Cfrac%7B1%7D%7B3!%7D%2B%5Cfrac%7B1%7D%7B5!%7Dy%5E5%20%5C%5C%0Ay%20%26%3D%20%5Cfrac%7Bx%7D%7B180%7D*3.1415926%0A%5Cend%7Baligned%7D%0A#card=math&code=%5Cbegin%7Baligned%7D%0A%5Csin%28x%29%20%26%3D%20%5Csin%28y%29%5Capprox%20y-%5Cfrac%7B1%7D%7B3%21%7D%2B%5Cfrac%7B1%7D%7B5%21%7Dy%5E5%20%5C%5C%0Ay%20%26%3D%20%5Cfrac%7Bx%7D%7B180%7D%2A3.1415926%0A%5Cend%7Baligned%7D%0A&id=WB6SU)
可以看出,计算 #card=math&code=%5Csin%28x%29&id=kNy9M)需要进行多次乘法和除法。乘法是非常费时的运算,它们的执行时间大约是加法、比较等指令的 5 倍。如何才能够不做乘除而计算
#card=math&code=%5Csin%28x%29&id=desh8)呢?我们看一下需要计算的
#card=math&code=%5Csin%28x%29&id=KDdeQ)的结果:
%3D0#card=math&code=%5Csin%280%5Cdegree%29%3D0&id=l8T1A)
%3D0.5#card=math&code=%5Csin%2830%5Cdegree%29%3D0.5&id=n5W0y)
%3D0.866#card=math&code=%5Csin%2860%5Cdegree%29%3D0.866&id=lDZxf)
%3D1#card=math&code=%5Csin%2890%5Cdegree%29%3D1&id=pbCzk)
%3D0.866#card=math&code=%5Csin%28120%5Cdegree%29%3D0.866&id=ipkb9)
%3D0.5#card=math&code=%5Csin%28150%5Cdegree%29%3D0.5&id=Y0geu)
%3D0#card=math&code=%5Csin%28180%5Cdegree%29%3D0&id=IJIt0)
我们可以看出,其实用不着计算,可以占用一些内存空间来换取运算的速度。将所要计算的 #card=math&code=%5Csin%28x%29&id=xdzLh)的结果存储到一张表中;然后用角度值来查表,找到对应的
#card=math&code=%5Csin%28x%29&id=wBgSN) 的值。
 用 ax 向子程序传递角度,程序如下:
用 ax 向子程序传递角度,程序如下:
showsin: jmp short showtable dw ag0,ag30,ag60,ag90,ag120,ag150,ag180 ; 字符串偏移地址表ag0 db '0',0 ; sin(0)对应的字符串"0"ag30 db '0.5',0 ; sin(30)对应的字符串"0.5"ag60 db '0.866',0 ; sin(60)对应的字符串"0.866"ag90 db '1',0 ; sin(90)对应的字符串"0.866"ag120 db '0.866',0 ; sin(120)对应的字符串"0.866"ag150 db '0.5',0 ; sin(150)对应的字符串"0.866"ag180 db '0',0 ; sin(180)对应的字符串"0.866"show: push axpush espush simov bx,0b800hmov es,bx; 以下用 角度值/30 作为相对于table的偏移,取得对应的字符串的偏移地址,放在bx中mov ah,0mov bl,30div blmov bl,almov bh,0add bx,bxmov bx,table[bx]; 以下显示sin(x)对应的字符串mov si,160*12+40*2shows: mov ah,cs:[bx]cmp ah,0je showretmov es:[si],ahinc bxadd si,2jmp short showsshowret: pop sipop espop bxret
在上面的子程序中,我们在角度值 X 和表示 #card=math&code=%5Csin%28x%29&id=BLtzA)的字符串集合
table 之间建立的映射关系为:以 角度值/30 为 table 表中的偏移,可以找到对应的字符串的首地址。
编程的时候要注意程序的容错性,即对于错误的输入要有处理能力。在上面的子程序中,我们还应该再加上对提供的角度值是否超范围的检测。如果提供的角度值不在合法的集合中,程序将定位不到正确的字符串,出现错误。
上面的两个子程序中,我们将通过给定的数据进行计算或比较而得到结果的问题,转化为用给出的数据作为查表的依据,通过查表得到结果的问题。具体的查表方法,是用来查表的依据数据,直接计算出所要查找的元素在表中的位置。像这种可以通过依据数据,直接计算出所要找的元素的位置的表,我们称其为直接定址表。
16.4 程序入口地址的直接定址表
我们可以在直接定址表中存储子程序的地址,从而方便地实现不同子程序的调用。我们看下面的问题。
实现一个子程序 setscreen,为显示输出提供如下功能。
- 清屏;
- 设置前景色;
- 设置背景色;
- 向上滚动一行。
入口参数说明如下
- 用 ah 寄存器传递功能号:0 表示清屏、1 表示设置前景色、2 表示设置背景色、3 表示向上滚动一行
- 对于 1、2 号功能,用 al 传送颜色值,
。
下面我们讨论一下各种功能如何实现:
- 清屏:将显存中当前屏幕中的字符设为空格符;
- 设置前景色:设置现存中当前屏幕中处于奇地址的属性字节的第 0、1、2 位;
- 设置背景色:设置显存中当前屏幕中处于奇地址的属性字节的第 4、5、6位;
- 向上滚动一行:依次将第n+1 行的内容复制到第 n 行处;最后一行为空。
下面将这 4 种功能分别写为 4 个子程序,如下所示
sub1: push bxpush cxpush esmov bx,0b800hmov es,bxmov bx,0mov cx,2000sub1s: mov byte ptr es:[bx],''add bx,2loop sub1spop espop cxpop bxretsub2: push bxpush cxpush esmov bx,0b800hmov es,bxmov bx,1mov cx,2000sub2s: and byte ptr es:[bx],11111000bor es:[bx],aladd bx,2loop sub2spop espop cxpop bxretsub3: push bxpush cxpush esmov cl,4shl al,clmov bx,0b800hmov es,bxmov bx,1mov cx,2000sub3s: and byte ptr es:[bx],10001111bor es:[bx],aladd bx,2loop sub3spop espop cxpop bxretsub4: push cxpush sipush dipush espush dsmov si,0b800hmov es,simov ds,simov si,160 ; ds:si 指向第n+1行mov di,0 ; es:di 指向第n行cldmov cx,24 ; 共复制24行sub4s: push cxmov cx,160rep movsb ; 复制pop cxloop sub4smov cx,80mov si,0sub4s1: mov byte ptr [160*24+si],'' ; 最后一行清空add si,2loop sub4s1pop dspop espop dipop sipop cxret
 实现方式1
实现方式1
我们可以将这些功能子程序的入口地址存储在一个表中,它们在表中的位置和功能号相对应。对应关系为:功能号*2=对应的功能子程序在地址表中的偏移。程序如下:
setscreen: jmp short settable dw sub1,sub2,sub3,sub4set: push bxcmp ah,3 ; 判断功能号是否大于3ja sretmov bl,ahmov bh,0add bx,bx ; 根据ah中的功能号计算对应子程序在table表中的偏移call word ptr table[bx] ; 调用对应的功能子程序sret: pop bxret
根据功能号查找地址表的方法,程序的结构清晰,便于扩充。如果加入一个新的功能子程序,只需要在地址表中加入它的入口地址即可。
 实现方式2
实现方式2
我们可以将子程序 setscreen 如下实现
setscreen: cmp ah,0je do1cmp ah,1je do2cmp ah,2je do3cmp ah,3je do4jmp short sretdo1: call sub1jmp short sretdo2: call sub2jmp short sretdo3: call sub3jmp short sretdo4: call sub4sret: ret
显然,通过上述比较功能号进行转移的方法,使得程序结构很混乱并且不利于功能的扩充。

若有收获,就点个赞吧
0 人点赞
