行存和列存对比
列存储的数据库更适合OLAP
行存储的数据库更适合OLTP
所谓的快只是针对于进行olap操作而言 我们知道,数据在存储中的基本单位为页,这也是进行数据读取时候基本单位,一次读取就是一次IO操作 以sql server为例,一个数据页大小为8K,数据页中存储的是数据,数据是连续存储的 那么我假设如下的4*4表格为一个数据页
再假设,有这样一个表格 字段1 字段2
字段1的值为 col1value1,col1value2…..
字段2的值为col2value1,col2value2……
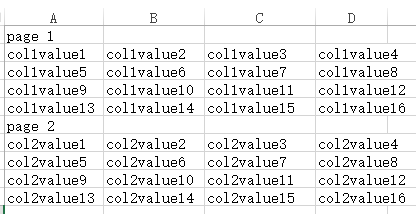
再假设一个excel的单元格为一个存储单位,数据总量占了2个页,
那么以行方式存储大概就这样的

以列方式存储则是这样的
数据压缩
列式存储很容易通过字典表压缩数据。下面之前提到的那张表本来的样子。经过字典表进行数据压缩后,表中的字符串才都变成数字了。正因为每个字符串在字典表里只出现一次了,所以达到了压缩的目的。
 关键步骤如下:
关键步骤如下:
- 去字典表里找到字符串对应数字(只进行一次字符串比较)。
- 用数字去列表里匹配,匹配上的位置设为1。
- 把不同列的匹配结果进行位运算得到符合所有条件的记录下标。
- 使用这个下标组装出最终的结果集。
查询
这时,如果我需要执行如下查询(oltp典型查询)
select 字段1,字段2 from table where 字段1=’col1value1’
以行方式查询(在有适当的索引情况下),那么,执行一次以上查询,只需要扫描一次page1就可以了
以列方式查询,需要投其扫描page1 和page2共2次,分别取得字段1,字段2的单行值
OK,我们换成olap的典型查询
select avg(字段2) from table
—(注意,这里假设字段2为一个整型数据,而且无where条件限制,即需要扫描全部数据)
对于行存储,这个查询需要两次IO将全部数据放入内存后,进行页间数据的跳读(类随机读取)
对于列存储,只需要一次IO将page2放入内存后进行连续读取,如果字段2还有多页的话,也都是进行的物理连续读取
也就是说,在进行olap操作时候,不仅是减小了IO次数,而且把随机读取变为了连续读取
以下为网上随便找的一张SSD性能测试图,注意seq(连续)和4k(随机)之间的性能区别

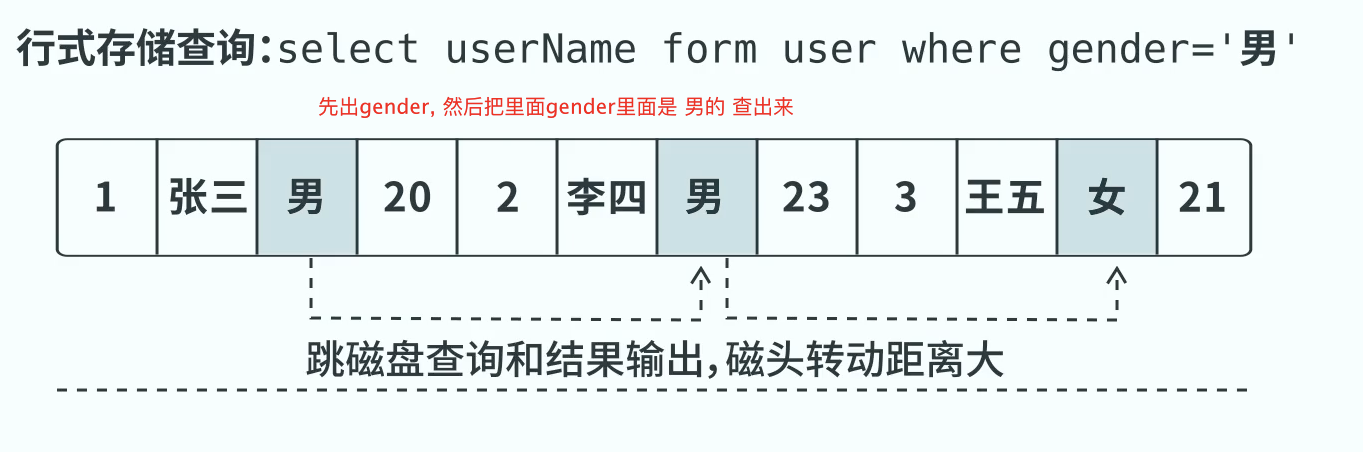
行存的查询
客户一个折线图, 表格, 不可能要几十列, 大部分就几列的数据在那管理查询要结果
数据以一行的形式存储在磁盘
我现在要找一个数据, 某一列的, 要查询多次多个行

列式存储查询
以列式将数据存储在磁盘上

数据紧凑的存储在磁盘上

各种查询
- 基于特定字段查询
- 基于特定字段进行结果输出
在数据查询过程中, 磁盘只要转动很少的次数, 就能将数据查询并返回
innodb的行存


磁盘
SSD的随机读写与顺序读写?
机械硬盘由于其物理结构的原因,顺序读写相邻的磁块比起随机读写可以有效减少磁头的移动次数,从而顺序读写的性能高于随机读写。但是SSD作为随机存储设备,其访问任意一块的时间应该是相等的。因此,可以得出随机读写性能等于顺序读写。我看了很多评测,发现实际情况却不是如此,而是像机械硬盘一样,顺序读写高于随机读写。请问这是为什么?你这个问题的关键在于把两个不同的东西用了同一个标准去比较。就像比较一个举重选手和短跑选手比赛谁能胜出一样。
顺序读写好坏标准是 “吞吐量MBPS”每秒钟读写数据的大小。读写一个大文件。
随机读写好坏的标准是“IOPS”,每秒钟读写文件的次数。读写多个小文件。
SSD硬盘的寻道时间几乎为0,顺序读写大文件的速度达到600M/s,随机读写达到了1000万次/s。
文件系统数据都是分成很多小块的,假如每块数据可以防止4KB的数据。而硬盘每次读写刚好读取4kb的情况下,当然可以达到最大读取效果。但如果每块里面只有1byte数据,而每次读写仍然是一个数据块。那么随机读写速度就会下降4000倍。而顺序读写每次都是读取最大的数据块。
加上顺序读写的优化算法,肯定是比随机读写吞吐量大一些。但并不绝对。你要理解,顺序读写和随机读写通常用两个不同的指标来表示性能的好坏。不要放在一起比较就好

若有收获,就点个赞吧
0 人点赞
