配置项查看
SELECT name, value FROM system.settings WHERE name LIKE '%memory%';
会话
数据库使用情况概览最重要的就是列出当前活动连接。从OS来看到数据库的会话是看不见的,因为ClickHouse仅有一个进程、每个连接对应一个线程,所以只能依赖SQL语句查询。 列举数据库活动会话:第一个命令最简单、和MySQL命令很相似,第二个sql可以增加额外的查询条件以及排序字段,两个命令仅能获取当前正在运行的查询,不是所有到服务器的连接。 下面语句获取所有连接:
SHOW PROCESSLIST;SELECT query_id, user, address, elapsed, queryFROM system.processes ORDER BY query_id;
SELECT * FROM system.metrics WHERE metric LIKE '%Connection';
该查询返回不同类型的连接数,而不仅为先前查询的列表。
有经验的DBA会注意到后面两个查询都使用system数据库,对DBA来说这是最重要的数据库,它包括很多ClickHouse内部视图。
SELECTquery_id,read_rows,total_rows_approx,memory_usage,initial_user,initial_address,elapsed,query,client_hostnameFROM system.processes;# 字段含义# query_id 查询id,# read_rows 从表中读取的行数,# total_rows_approx 应读取的行总数的近似值,# memory_usage 请求使用的内存量# initial_user 进行查询的用户# initial_address 请求的 IP 地址# elapsed 求执行开始以来的秒数# query 查询语句
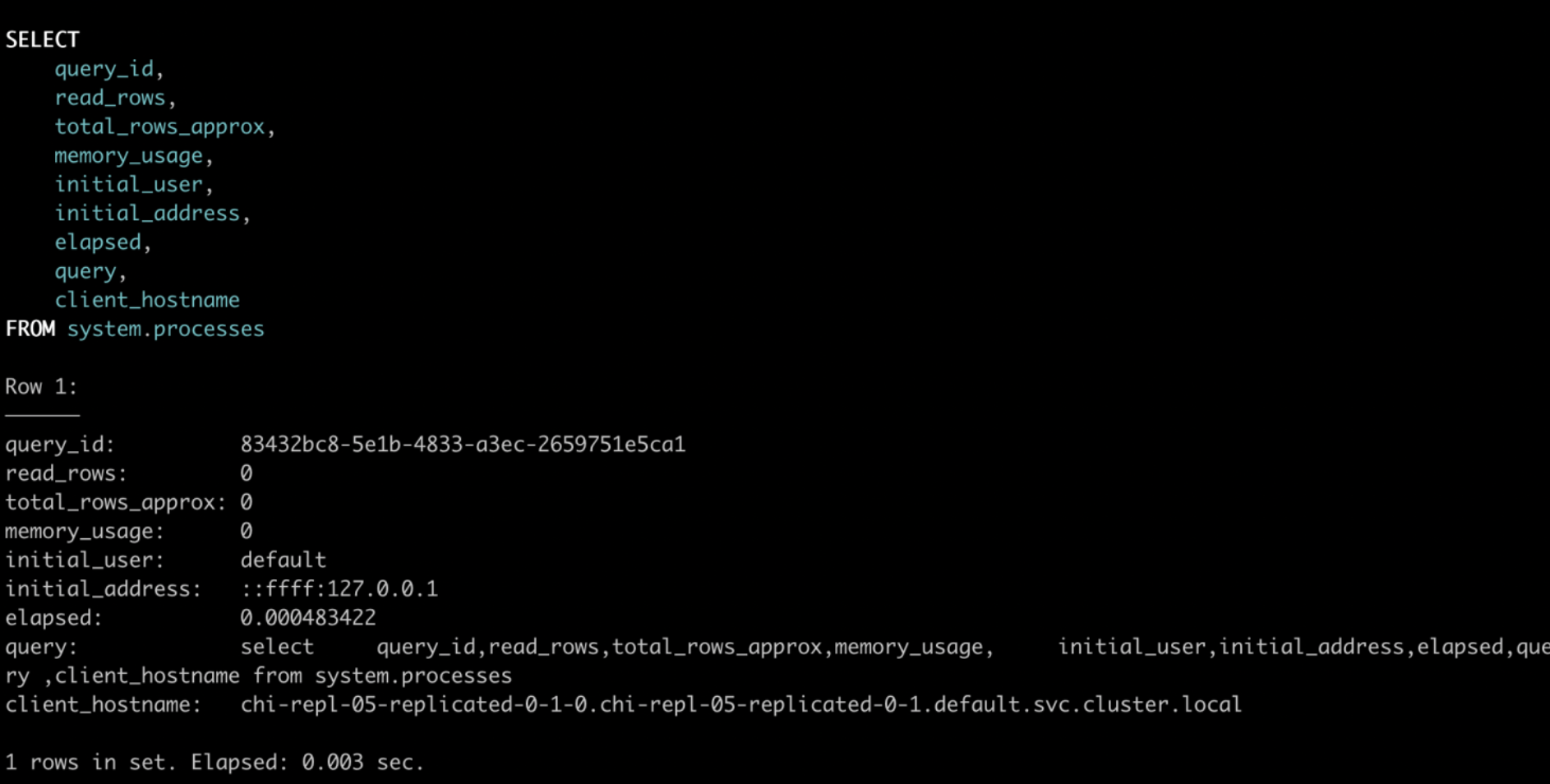
通过sql语句的查询行数和查询已经执行的时间来判断sql是不是在慢查询,或者是同事在查询的时候没有日期限定而直接查全表。一般的话如果grafana监控的CK节点出现cpu飙升的情况,就需要我们去判断CK中是否有垃圾sql在执行,根据query_id杀死该进程。
kill query where query_id='83432bc8-5e1b-4833-a3ec-2659751e5ca1';
锁
其实ClickHouse没有锁,至少没有用户可见的锁。ClickHouse异步执行INSERT:MergeTree引擎收集并在分区中插入数据,然后在后台合并。一旦插入完成,新数据在查询中会立刻可见,UPDATE和DELETE在ClickHouse中不是DML语句。这种特殊设计使得锁频率低且很短暂。
但仍然可能有长时间运行的查询。我们可以用上面描述的SHOW PROCESSLIST命令检查,然后用KILL命令中断:
ClickHouse的UPDATE和DELETE命令属于DDL,也称为变化操作,需要异步执行,且不能被回滚,但如果阻塞可以中断。下面命令与前面类似:
SHOW PROCESSLIST;KILL QUERY WHERE query_id='query_id';
注意:在KILL之前,理解你在做什么很重要。
SELECT * FROM system.mutations;KILL MUTATION mutation_id = 'trx_id';
磁盘空间利用
ClickHouse 磁盘空间管理非常重要。典型的数据仓库数据会非常大,即使ClickHouse使用高效的数据压缩算法,对DBA来说监控磁盘空间利用还是很重要。查看数据库使用磁盘空间SQL:前面查询很详细,包表、分区、块等,但还可以使用GROUP BY按数据库、表或分区进行汇总。
SELECT database, table, partition, name part_name, active, bytes_on_diskFROM system.parts ORDER BY database, table, partition, name;
下面SQL按数据库查看磁盘使用情况:
对于多个盘配置时,也可以通过特定磁盘查看空间利用情况:SELECT * FROM system.disks 在数据插入过程中,块还没有被立刻合并到分区中,为了强制进行合并,可以使用下面语句:
SELECT database, sum(bytes_on_disk)FROM system.partsGROUP BY database;
压缩因子很重要,每个列都不同。下面查询可以检测每列的空间使用:
OPTIMIZE TABLE table [PARTITION partition] [FINAL]
查看特定表每列的数据压缩比,方便优化数据类型、编码及压缩算法:
SELECT database, table, column, any(type),sum(column_data_compressed_bytes) compressed,sum(column_data_uncompressed_bytes) uncompressed,uncompressed/compressed ratio,compressed/sum(rows) bpr,sum(rows)FROM system.parts_columnsWHERE active AND database <> 'system'GROUP BY database, table, columnORDER BY database, table, column;
SELECTname,formatReadableSize(sum(data_compressed_bytes)) AS compressed_size,formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed_size,round((uncompressed_size/ compressed_size), 2) AS ratioFROM system.columnsWHERE table = 'u_table_name'GROUP BY nameORDER BY sum(data_compressed_bytes) DESC
性能
性能优化是每个DBA喜欢的工作。ClickHouse默认不跟踪查询性能,但可以在会话级或user.xml文件中修改配置参数log_queries = 1启用跟踪。 下面是查询前十个最长的查询:
SELECT user,client_hostname AS host,client_name AS client,formatDateTime(query_start_time, '%T') AS started,query_duration_ms / 1000 AS sec,round(memory_usage / 1048576) AS MEM_MB,result_rows AS RES_CNT,toDecimal32(result_bytes / 1048576, 6) AS RES_MB,read_rows AS R_CNT,round(read_bytes / 1048576) AS R_MB,written_rows AS W_CNT,round(written_bytes / 1048576) AS W_MB,queryFROM system.query_logWHERE type = 2ORDER BY query_duration_ms DESCLIMIT 10
一旦确定慢查询就可以进行优化,一般需要考虑的是:正确选择ORDER BY 列,编码和压缩,可以参考官方文档。
对性能特别有用的特性是物化视图,它可以对数据定义可选视图,物化视图可以合并数据或以不同的顺序排列数据。通过分析最繁重和最重复的查询,可以设计物化视图解决问题。
如果使用 ClickHouse version (20.3.x),可以查询system.metric_log 表,可以查询OS系统级数据:
SELECT toStartOfMinute(event_time) AS time,sum(ProfileEvent_UserTimeMicroseconds) AS user_time,bar(user_time, 0, 60000000, 80) AS barFROM system.metric_logWHERE event_date = today()GROUP BY time ORDER BY time;
注意: bar函数———— ClickHouse几百个很酷函数中的一个!
副本
它可以配置更多ClickHouse节点连接到集群。副本可以实现高可用 HA (High Availability)和并发访问,分片为了分布式查询、高吞吐量插入。该配置很灵活,因为副本和分片可以对当个表进行定义。
ClickHouse副本是异步的、多主(内部使用ZooKeeper进行协作)。副本主要为了实现HA,但有时会出错,下面语句检查可能会出错的情况
SELECT database, table, is_leader, total_replicas, active_replicasFROM system.replicasWHERE is_readonlyOR is_session_expiredOR future_parts > 20OR parts_to_check > 10OR queue_size > 20OR inserts_in_queue > 10OR log_max_index - log_pointer > 10OR total_replicas < 2OR active_replicas < total_replicas;
总结
ClickHosue对DBA非常友好,system数据库提供了所有DBA需要的信息。本文进行介绍最重要的一些SQL,远不是完整清单,但应该能帮助你快速确定问题。参考文档:https://clickhouse.com/blog/optimize-clickhouse-codecs-compression-schema;https://altinity.com/blog/2020/5/12/sql-for-clickhouse-dba

若有收获,就点个赞吧
0 人点赞
