Spider
Spider是一款基于redis的分布式爬虫,适用于海量数据采集,支持断点续爬、爬虫报警、数据自动入库等功能
1. 创建项目
创建项目这一步不是必须的,一个脚本可以解决的需求,可直接创建爬虫。若需求比较复杂,需要写多个爬虫,那么最好用项目形式把这些脚本管理起来。
命令参考:命令行工具
示例:
feapder create -p spider-project
创建好项目后,开发时我们需要将项目设置为工作区间,否则引入非同级目录下的文件时,编译器会报错。不过因为main.py在项目的根目录下,因此不影响正常运行。

设置工作区间方式(以pycharm为例):项目->右键->Mark Directory as -> Sources Root
2. 创建爬虫
命令参考:命令行工具
示例:
feapder create -s spider_test请选择爬虫模板AirSpider> SpiderTaskSpiderBatchSpider
生成如下
import feapderclass SpiderTest(feapder.Spider):# 自定义数据库,若项目中有setting.py文件,此自定义可删除__custom_setting__ = dict(REDISDB_IP_PORTS="localhost:6379", REDISDB_USER_PASS="", REDISDB_DB=0)def start_requests(self):yield feapder.Request("https://www.baidu.com")def parse(self, request, response):print(response)if __name__ == "__main__":SpiderTest(redis_key="xxx:xxx").start()
因Spider是基于redis做的分布式,因此模板代码默认给了redis的配置方式,连接信息需按真实情况修改
3. 代码讲解
配置信息:
- REDISDB_IP_PORTS: 连接地址,若为集群或哨兵模式,多个连接地址用逗号分开,若为哨兵模式,需要加个REDISDB_SERVICE_NAME参数
- REDISDB_USER_PASS: 连接密码
- REDISDB_DB:数据库
Spider参数:
redis_key为redis中存储任务等信息的key前缀,如redis_key=”feapder:spider_test”, 则redis中会生成如下
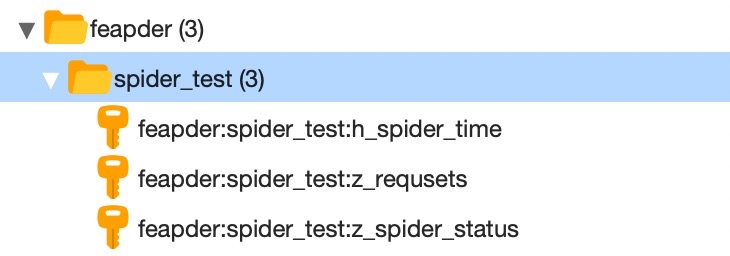
更详细的说明可查看 Spider进阶
4. 声明
AirSpider支持的方法Spider都支持,使用方式一致,下面重点讲解不同之处
5. 数据自动入库
除了导入MysqlDB这种方式外,Spider支持数据自动批量入库。我们需要将数据封装为一个item,然后返回给框架即可。步骤如下:
1.创建item,命令参考命令行工具。这里我们创建了个SpiderDataItem, 生成的代码如下:
from feapder import Itemclass SpiderDataItem(Item):"""This class was generated by feapder.command: feapder create -i spider_data."""def __init__(self, *args, **kwargs):# self.id = None # type : int(10) unsigned | allow_null : NO | key : PRI | default_value : None | extra : auto_increment | column_comment :self.title = None # type : varchar(255) | allow_null : YES | key : | default_value : None | extra : | column_comment :
2.给item赋值,然后yield返回即可
代码示例:

返回item后,item会流经到框架的ItemBuffer, ItemBuffer每.05秒或当item数量积攒到5000个,便会批量将这些item批量入库。表名为类名去掉Item的小写,如SpiderDataItem数据会落入到spider_data表。
Item详细介绍参考Item
6. 调试
开发过程中,我们可能需要针对某个请求进行调试,常规的做法是修改下发任务的代码。但这样并不好,改来改去可能把之前写好的逻辑搞乱了,或者忘记改回来直接发布了,又或者调试的数据入库了,污染了库里已有的数据,造成了很多本来不应该发生的问题。
本框架支持Debug爬虫,可针对某条任务进行调试,写法如下:
if __name__ == "__main__":spider = SpiderTest.to_DebugSpider(redis_key="feapder:spider_test", request=feapder.Request("http://www.baidu.com"))spider.start()
对比下之前的启动方式
spider = SpiderTest(redis_key="feapder:spider_test")spider.start()
可以看到,代码中 to_DebugSpider方法可以将原爬虫直接转为debug爬虫,然后通过传递request参数抓取指定的任务。
通常结合断点来进行调试,debug模式下,运行产生的数据默认不入库
除了指定request参数外,还可以指定request_dict参数,request_dict接收字典类型,如request_dict={"url":"http://www.baidu.com"}, 其作用于传递request一致。request 与 request_dict 二者选一传递即可
7. 运行多个Spider
通常,一个项目下可能存在多个爬虫,为了规范,建议启动入口统一放到项目下的main.py中,然后以命令行的方式运行指定的文件。
例如如下项目:

项目中包含了两个spider,main.py写法如下:
from spiders import *from feapder import Requestfrom feapder import ArgumentParserdef test_spider():spider = test_spider.TestSpider(redis_key="feapder:test_spider")spider.start()def test_spider2():spider = test_spider.TestSpider2(redis_key="feapder:test_spider2")spider.start()def test_debug_spider():# debug爬虫spider = test_spider.TestSpider.to_DebugSpider(redis_key="feapder:test_spider", request=Request("http://www.baidu.com"))spider.start()if __name__ == "__main__":parser = ArgumentParser(description="Spider测试")parser.add_argument("--test_spider", action="store_true", help="测试Spider", function=test_spider)parser.add_argument("--test_spider2", action="store_true", help="测试Spider2", function=test_spider2)parser.add_argument("--test_debug_spider",action="store_true",help="测试DebugSpider",function=test_debug_spider,)parser.start()
这里使用了ArgumentParser模块,使其支持命令行参数,如运行test_spider
python3 main.py --test_spider
8. 分布式
分布式说白了就是启动多个进程,处理同一批任务。Spider支持启动多份,且不会重复发下任务,我们可以在多个服务器上部署启动,也可以在同一个机器上启动多次。
9. 完整的代码示例
https://github.com/Boris-code/feapder/tree/master/tests/spider

若有收获,就点个赞吧
0 人点赞
