BatchSpider
BatchSpider是一款分布式批次爬虫,对于需要周期性采集的数据,优先考虑使用本爬虫。
1. 创建项目
参考 Spider
2. 创建爬虫
命令参考:命令行工具
示例:
feapder create -s batch_spider_test请选择爬虫模板AirSpiderSpiderTaskSpider> BatchSpider
生成如下
import feapderclass BatchSpiderTest(feapder.BatchSpider):# 自定义数据库,若项目中有setting.py文件,此自定义可删除__custom_setting__ = dict(REDISDB_IP_PORTS="localhost:6379",REDISDB_USER_PASS="",REDISDB_DB=0,MYSQL_IP="localhost",MYSQL_PORT=3306,MYSQL_DB="feapder",MYSQL_USER_NAME="feapder",MYSQL_USER_PASS="feapder123",)def start_requests(self, task):yield feapder.Request("https://www.baidu.com")def parse(self, request, response):print(response)if __name__ == "__main__":spider = BatchSpiderTest(redis_key="xxx:xxxx", # 分布式爬虫调度信息存储位置task_table="", # mysql中的任务表task_keys=["id", "xxx"], # 需要获取任务表里的字段名,可添加多个task_state="state", # mysql中任务状态字段batch_record_table="xxx_batch_record", # mysql中的批次记录表batch_name="xxx(周全)", # 批次名字batch_interval=7, # 批次周期 天为单位 若为小时 可写 1 / 24)# spider.start_monitor_task() # 下发及监控任务spider.start() # 采集
因BatchSpider是基于redis做的分布式,mysql来维护任务种子及批次信息,因此模板代码默认给了redis及mysql的配置方式,连接信息需按真实情况修改
3. 代码讲解
配置信息:
- REDISDB_IP_PORTS: 连接地址,若为集群或哨兵模式,多个连接地址用逗号分开,若为哨兵模式,需要加个REDISDB_SERVICE_NAME参数
- REDISDB_USER_PASS: 连接密码
- REDISDB_DB:数据库
BatchSpider参数:
redis_key:redis中存储任务等信息的key前缀,如redis_key=”feapder:spider_test”, 则redis中会生成如下
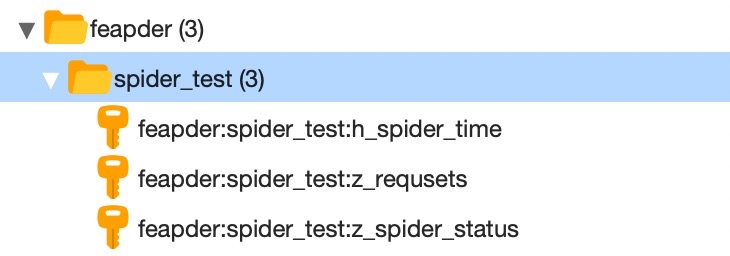
task_table:mysql中的任务表,为抓取的任务种子,需要运行前手动创建好
- task_keys:任务表里需要获取的字段,框架会将这些字段的数据查询出来,传递给爬虫,然后拼接请求
- task_state:任务表里表示任务完成状态的字段,默认是state。字段为整形,有4种状态(0 待抓取,1抓取完毕,2抓取中,-1抓取失败)
- batch_record_table:批次信息表,用于记录批次信息,由爬虫自动创建
- batch_name: 批次名称,可以理解成爬虫的名字,用于报警等
- batch_interval:批次周期 天为单位 若为小时 可写 1 / 24
启动:BatchSpider分为master及work两种程序
master负责下发任务,监控批次进度,创建批次等功能,启动方式:
spider.start_monitor_task()
worker负责消费任务,抓取数据,启动方式:
spider.start()
更详细的说明可查看 BatchSpider进阶
4. 声明
Spider支持的方法BatchSpider都支持,使用方式一致,下面重点讲解不同之处
5. 任务表
任务表为存储任务种子的,表结构需要包含id、任务状态两个字段,如我们需要对某些地址进行采集,设计如下

建表语句:
CREATE TABLE `batch_spider_task` (`id` int(10) unsigned NOT NULL AUTO_INCREMENT,`url` varchar(255) DEFAULT NULL,`state` int(11) DEFAULT '0',PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
也许有人会问,为什么要弄个任务表,直接把种子任务写到代码里不行么。答:可以的,可以用AirSpider或Spider这么搞。BatchSpider面向的场景是周期性抓取,如我们有1亿个商品需要更新,不可能把这1亿个商品id都写代码里,还是需要存储到一张表里,这个表即为任务表。
为了保证每个商品都得以更新,需要引入抓取状态字段,本例为state字段。state字段有4种状态(0 待抓取,1抓取完毕,2抓取中,-1抓取失败)。框架下发任务时,会优先分批下发状态为0的任务到redis任务队列,并将这些已下发的任务状态更新为2,当0都下发完毕且redis任务队列中无任务,这时框架会检查任务表里是否还有状态为2的任务,若有则将这些任务视为丢失的任务,然后将这些状态为2的任务置为0,再次分批下发到redis任务队列。直到任务表里任务状态只有1和-1两种状态,才算采集完毕
1 和 -1 两种状态是开发人员在代码里自己维护的。当任务做完时将任务状态更新为1,当任务无效时,将任务状态更新为-1。更新方法见更新任务状态
注意:每个批次开始时,框架默认会重置状态非-1的任务为0,然后重新抓取。-1的任务永远不会抓取
7. 拼接任务
def start_requests(self, task):pass
任务拼接在start_requests里处理。这里的task参数为BatchSpider启动参数中指定的task_keys对应的值
如表batch_spider_task,现有任务信息如下:

启动参数配置如下,注意task_keys=["id", "url"]:
def crawl_test(args):spider = test_spider.TestSpider(redis_key="feapder:test_batch_spider", # 分布式爬虫调度信息存储位置task_table="batch_spider_task", # mysql中的任务表task_keys=["id", "url"], # 需要获取任务表里的字段名,可添加多个task_state="state", # mysql中任务状态字段batch_record_table="batch_spider_batch_record", # mysql中的批次记录表batch_name="批次爬虫测试(周全)", # 批次名字batch_interval=7, # 批次周期 天为单位 若为小时 可写 1 / 24)if args == 1:spider.start_monitor_task() # 下发及监控任务else:spider.start() # 采集
这时,start_requests的task参数值即为任务表里id与url对应的值。
def start_requests(self, task):# task 为在任务表中取出的每一条任务id, url = task # id, url为所取的字段,main函数中指定的yield feapder.Request(url, task_id=id)
task值的获取方式,支持以下几种:
# 列表方式id, url = taskid = task[0]url = task[1]# 字典方式id, url = task.id, task.urlid, url = task.get("id"), task.get("url")id, url = task["id"], task["url"]
8. 更新任务状态
任务的完成状态与失败状态需要自己维护,为了更新这个状态,我们需要在请求中携带任务id,常规写法为
yield feapder.Request(url, task_id=id)
当任务解析完毕后,可使用如下方法更新
yield self.update_task_batch(request.task_id, 1) # 更新任务状态为1
这个更新不是实时的,也会先流经ItemBuffer,然后在数据入库后批量更新
9. 处理无效任务
有些任务,可能就是有问题的,我们需要将其更新为-1,防止爬虫一直重试。除了在解析函数中判断当前任务是否有效外,框架还提供了两个函数
def exception_request(self, request, response):"""@summary: 请求或者parser里解析出异常的request---------@param request:@param response:---------@result: request / callback / None (返回值必须可迭代)"""passdef failed_request(self, request, response):"""@summary: 超过最大重试次数的request---------@param request:---------@result: request / item / callback / None (返回值必须可迭代)"""pass
exception_request:处理请求失败或解析出异常的request,我们可以在这里切换request的cookie等,然后再yield request返回处理后的request
failed_request:处理超过最大重试次数的request。我们可以在这里将任务状态更新为-1
def failed_request(self, request, response):"""@summary: 超过最大重试次数的request---------@param request:---------@result: request / item / callback / None (返回值必须可迭代)"""yield requestyield self.update_task_batch(request.task_id, -1) # 更新任务状态为-1
超过最大重试次数的request会保存到redis里,key名以z_failed_requsets结尾。我们可以查看这个表里的失败任务,观察失败原因,以此来调整爬虫
10.增量采集
每个批次开始时,框架默认会重置状态非-1的任务为0,然后重新抓取。但是有些需求是增量采集的,做过的任务无需再次处理。重置任务是init_task方法实现的,我们可以将init_task方法置空来实现增量采集
def init_task(self):pass
11. 调试
与Spider调试类似。BatchSpider可以通过to_DebugBatchSpider转为调试爬虫,写法如下:
def test_debug():spider = test_spider.TestSpider.to_DebugBatchSpider(task_id=1,redis_key="feapder:test_batch_spider", # 分布式爬虫调度信息存储位置task_table="batch_spider_task", # mysql中的任务表task_keys=["id", "url"], # 需要获取任务表里的字段名,可添加多个task_state="state", # mysql中任务状态字段batch_record_table="batch_spider_batch_record", # mysql中的批次记录表batch_name="批次爬虫测试(周全)", # 批次名字batch_interval=7, # 批次周期 天为单位 若为小时 可写 1 / 24)spider.start() # 采集
DebugBatchSpider爬虫支持传递task_id或直接传递task来指定任务。还支持其他参数,全部参数如下:
@param task_id: 任务id@param task: 任务 task 与 task_id 二者选一即可@param save_to_db: 数据是否入库 默认否@param update_stask: 是否更新任务 默认否
12. 运行BatchSpider
与Spider运行方式类似。但因每个爬虫都有maser和work两个入口,因此框架提供一种更方便的方式,写法如下
from spiders import *from feapder import ArgumentParserdef crawl_test(args):spider = test_spider.TestSpider(redis_key="feapder:test_batch_spider", # 分布式爬虫调度信息存储位置task_table="batch_spider_task", # mysql中的任务表task_keys=["id", "url"], # 需要获取任务表里的字段名,可添加多个task_state="state", # mysql中任务状态字段batch_record_table="batch_spider_batch_record", # mysql中的批次记录表batch_name="批次爬虫测试(周全)", # 批次名字batch_interval=7, # 批次周期 天为单位 若为小时 可写 1 / 24)if args == 1:spider.start_monitor_task() # 下发及监控任务else:spider.start() # 采集if __name__ == "__main__":parser = ArgumentParser(description="批次爬虫测试")parser.add_argument("--crawl_test", type=int, nargs=1, help="BatchSpider demo(1|2)", function=crawl_test)parser.start()
运行master
python3 main.py --crawl_test 1
运行worker
python3 main.py --crawl_test 2
crawl_test的args参数会接收1或2两个参数,以此来运行不同的程序
13. 完整的代码示例
https://github.com/Boris-code/feapder/tree/master/tests/batch-spider

若有收获,就点个赞吧
0 人点赞
