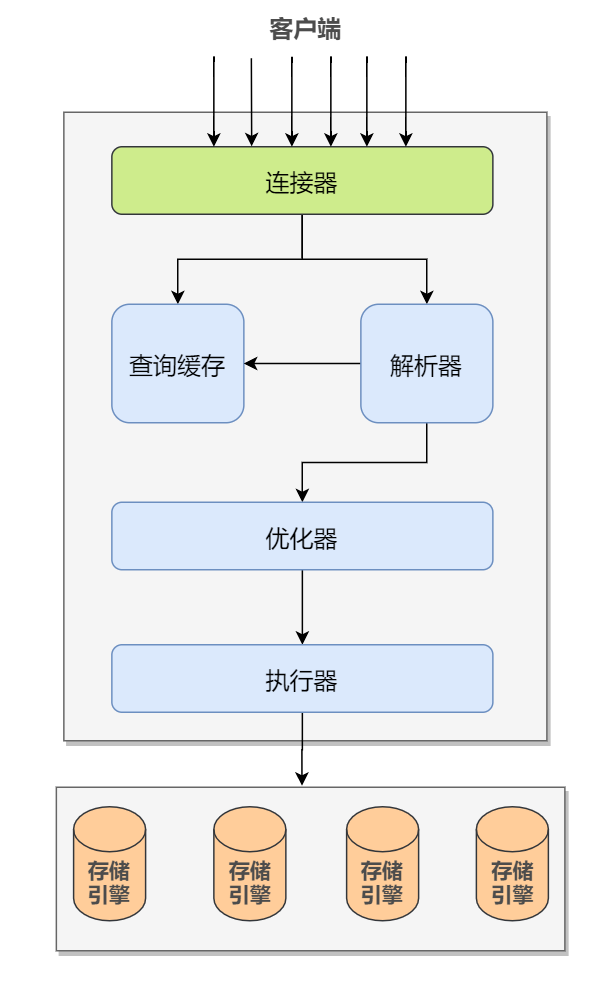
1、MySQL架构
MySQL架构从上到下可以分为4层,分别是:
- 客户端:各种开发语言都提供了连接
MySQL数据库的框架,比如Java提供了JDBC以及Druid数据库连接池等,在实际SpringBoot项目中会在application.yml配置文件中配置好数据库ip和端口信息,以及数据库连接池的信息,程序中还会用到MyBatis等ORM框架间接地与MySQL数据库交互; - Server层:包括连接器、查询缓存、分析器、优化器、执行器、MySQL管理系统等,具体的模块在下面介绍;
- 存储引擎层:负责从磁盘文件中存储和读取数据,是真正与底层物理文件打交道的组件。存储引擎被设计成可拔插的插件形式,常见的存储引擎有
InnoDB、MyIASM等; - 物理文件层:真正存储
MySQL数据库中表数据的地方,以及对应的日志。具体的MySQL中每张表以及对应的元数据是如何在Linux文件系统上存储的,可以见下一篇文章。
MySQL架构的逻辑简图如下所示:
下面重点介绍一下Service层的组成模块。
(1)连接器
连接器主要负责客户端的连接建立、用户鉴权。
- 连接管理:当一个来自客户端的请求过来时,
MySQL服务端会从线程池中分配一个线程来与客户端建立连接,当客户端退出时会与MySQL服务端断开连接,MySQL服务端并不会立即把与该客户端交互的线程销毁掉,而是把它缓存起来,在另一个新的客户端再进行连接时,把这个缓存的线程分配给新的客户端。这样就起到了不频繁创建和销毁线程的效果,从而节省开销。我们可以通过配置文件设置同一时刻连接到MySQL服务端的客户端的最大数量。 - 用户鉴权:在客户端程序发起连接的时候,需要携带主机信息、用户名、密码,服务器程序会对客户端程序提供的这些信息进行认证,如果认证失败,服务器程序会拒绝连接。
(2)查询缓存MySQL服务端接收到一个查询请求后,会先到缓存(注意不是Buffer Pool)中查看之前是否执行过这条语句。之前执行过的语句及其结果会以key-value对的形式被直接缓存在内存中,key是查询的语句,value是查询的结果。如果当前sql查询能够直接在查询缓存中找到key,那么对应的value就会被直接返回给客户端。MySQL的缓存系统会监测涉及到的每张表,如对该表使用了INSERT、 UPDATE、DELETE、TRUNCATE TABLE、ALTER TABLE、DROP TABLE或 DROP DATABASE语句,那使用该表的所有高速缓存查询都将变为无效并从高速缓存中删除!从MySQL5.7.20开始,不推荐使用查询缓存,并在MySQL 8.0中删除。
(3)分析器
因为客户端程序发送过来的请求只是一段文本而已,所以MySQL服务器程序首先要对这段文本做分析,主要做2件事情:
- 判断请求的语法是否正确;
- 从文本中将要查询的表、各种查询条件都提取出来放到
MySQL服务器内部使用的一些数据结构上来。
(4)优化器
分析器解析之后,服务器程序获得到了需要的信息,比如要查询的列是哪些,表是哪个,搜索条件是什么等等,但光有这些是不够的,因为我们写的MySQL语句执行起来效率可能并不是很高,MySQL的优化器会对我们的语句做一些优化,比如外连接转换为内连接、表达式简化、子查询转为连接查询等。优化的结果就是生成一个执行计划,这个执行计划表明了应该使用哪些索引进行查询,表之间的连接顺序是什么样的。我们可以使用**EXPLAIN**语句来查看某个语句的执行计划,关于EXPLAIN将在后面单独写一篇文章总结。
(5)执行器
经过优化器优化后生成的执行计划,执行器会先判断线程有没有当前数据的读写权限,如果没有就会返回没有权限的错误提示,如果有权限执行器会调用底层存储引擎的api接口对保存在文件系统中的表数据进行增删改查。
(6)MySQL管理系统
英文名称是 MySQL Management Server & utilities,提供了丰富的数据库管理功能,例如:数据库备份和恢复,数据库安全管理与权限管理,数据库复制管理,集群管理,数据库元数据管理,分库分表管理等。
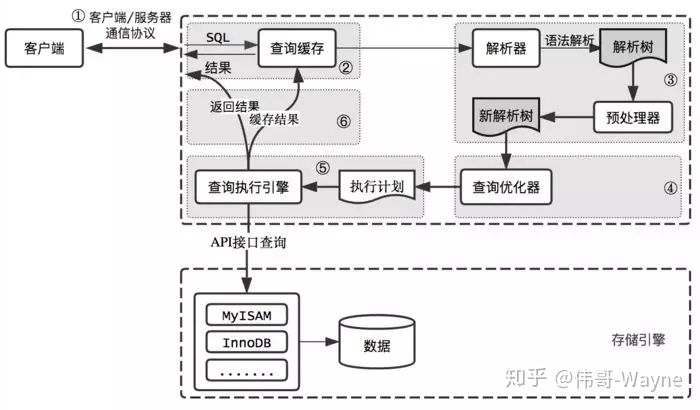
2、SQL语句的查询过程
- 客户端向MySQL服务端发送一个查询语句的请求;
- MySQL服务端的Service层先进行处理,首先是连接器,建立客户端与服务端之间的连接,并鉴权;
- MySQL服务端会先查询缓存,如果缓存命中,则直接返回缓存中数据页中的数据结果;否则进入下一阶段;
- 分析器对sql文本进行解析,生成解析树;
- 优化器对解析数进行优化,比如调整where查询条件的顺序与索引列一致,生成一个执行计划;
- 执行器基于优化器生成的执行计划,调用存储引擎底层的api来执行,并将结果返回给客户端。
参考

若有收获,就点个赞吧
0 人点赞
