一、关于数据的问题
为什么每次都是2022-05-09 ?
因为真实的情况应该是每天都要从mysql中,埋点数据中,以及第三方的日志中获取新数据。
ods层应该每天都会有新的分区数据产生,因为我们没有,只采集了一次,所以我们就老拿这一天的数据。
每天都要重复我们项目前几天的工作。所以一般开发一次,将这些内容编写成脚本直接运行即可。
想到azkaban可以定时每天几点执行,执行任务,我们有几个任务?
任务一:从其他三个数据来源中采集数据到ods层,任务二:从ods层处理数据到dwd层,任务三:dwd-dws
任务四:dws->ads
编写ods层的命令:
里面是使用sqoop命令实现增量导入各个表数据(参照第一天的sqoopJob.sh)生成我们的ods.sh
编写dwd.sh:
#!/bin/bash/usr/local/hive/bin/hive \-f dwd.hql
将我们前几天写的dwd的sql语句全部粘贴过来,变成了 dwd.hql
就是将我们第二天的SQL语句全部粘贴到了dwd.hql里面,当然这个里面可以传参。
编写:dws.sh
#!/bin/bash/usr/local/hive/bin/hive \-f dws.hql
注意:如果在shell脚本中,使用到了某个命令一定要是 全路径,不要认为配置了环境变量就万事大吉。
dws.hql 语句就是我们第三天编写的sql语句,全部粘贴进去了,当然日期可以传参数。
编写:ads.sh
#!/bin/bash/usr/local/hive-3.1.2/bin/hive \-f ads.hql
ads.hql语句就是昨天编写的课堂上的语句,汇总在一起的东西。
现在就有4个脚本了,ods.sh,dwd.sh,dws.sh,ads.sh 四个脚本(shell编程)
编写一个azkaban的任务:
nodes:- name: adstype: commandconfig:command: sh ads.shdependsOn:- dws- name: dwstype: commandconfig:command: sh dws.shdependsOn:- dwd- name: dwdtype: commandconfig:command: sh dwd.shdependsOn:- ods- name: odstype: commandconfig:command: sh ods.sh
接着编写project, 打包上传至azkaban,即可,需要设置每天几点执行(定时任务),设置邮箱提醒。
二、复习SuperSet
如何启动/停止 superset:
先进入superset环境:conda activate superset接着在环境中,执行这个命令:gunicorn -w 1 -t 120 -b bigdata01:8787 "superset.app:create_app()"–workers:指定进程个数–timeout:worker进程超时时间,超时会自动重启–bind:绑定本机地址,即为Superset访问地址–daemon:后台运行如何停止superset?停止superset停掉gunicorn进程:ps -ef | awk '/gunicorn/ && !/awk/{print $2}' | xargs kill -9退出superset环境:conda deactivate
三、DataX(类上sqoop)
1、安装
1)将DataX上传至/home/soft下,解压至/usr/local/
tar -xvf datax.tar.gz -C /usr/local/
2)复制hive中mysql驱动至 /usr/local/datax/lib下
cp /usr/local/hive/lib/mysql-connector-java-8.0.26.jar /usr/local/datax/lib/
3)创建Hive表,将mysql的表数据抽取到hive表中,需要编写json文件
报错:
配置信息错误,您提供的配置文件[/usr/local/datax/plugin/reader/._drdsreader/plugin.json]不存在. 请检查您的配置文件
解决办法:
需要删除隐藏文件 (重要)rm -rf /usr/local/datax/plugin/*/._*
2、DataX的相关的概念
https://github.com/alibaba/DataX
github 中文中有一个叫做码云的网站:
https://gitee.com/
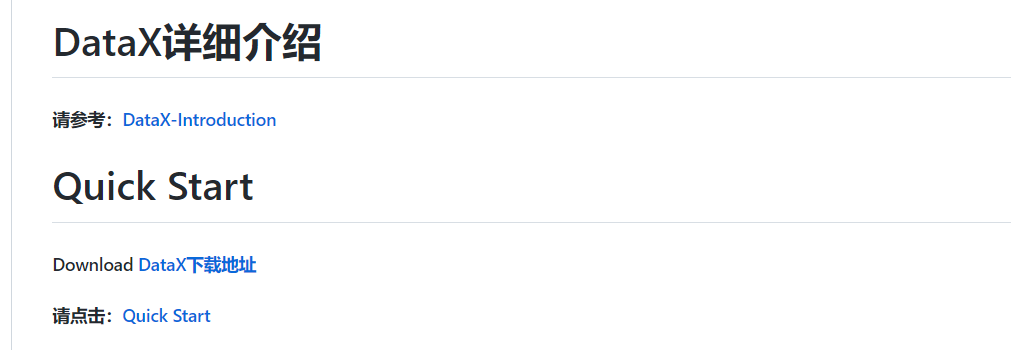
DataX 是阿里云 DataWorks数据集成 的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS 等各种异构数据源之间高效的数据同步功能。
3、使用:
mysql的数据导入hive:
导入到mysql中。
接着将area_code中的数据导入ods_nshop中。(mysql->Hive)
首先需要在hive中创建表:
create table if not exists ods_nshop.ods_01_base_area (id int COMMENT 'id标识',area_code string COMMENT '省份编码',province_name string COMMENT '省份名称',iso string COMMENT 'ISO编码')row format delimited fields terminated by ','stored as TextFilelocation '/data/nshop/ods/ods_01_base_area/'
使用datax将mysql的数据导入到hive:
需要编写datax的脚本,json格式的:,在datax 中的job 文件夹下,创建 01.json
{"job": {"setting": {"speed": {"channel": 3},"errorLimit": {"record": 0,"percentage": 0.02}},"content": [{"reader": {"name": "mysqlreader","parameter": {"writeMode": "insert","username": "root","password": "123456","column": ["id","area_code","province_name","iso"],"splitPk": "id","connection": [{"table": ["base_area"],"jdbcUrl": ["jdbc:mysql://192.168.32.100:3306/nshop"]}]}},"writer": {"name": "hdfswriter","parameter": {"defaultFS": "hdfs://bigdata01:9820","fileType": "text","path": "/data/nshop/ods/ods_01_base_area/","fileName": "base_area_txt","column": [{"name": "id","type": "int"},{"name": "area_code","type": "string"},{"name": "province_name","type": "string"},{"name": "iso","type": "string"}],"writeMode": "append","fieldDelimiter": ","}}}]}}

因为每次执行datax.py 这个命令的时候都要写路径,很麻烦,可以配置datax的环境变量:
export DATAX_HOME=/usr/local/dataxexport PATH=$PATH:$DATAX_HOME/bin
记得刷新环境变量:
source /etc/profile
继续运行我们的脚本:
datax.py job/01.json
一定要注意数据库的连接和账户密码是否正确!!!!
导入结束看一下数据是否正确:
四、DataX详细讲解
1、玩一下自带的案例 job.json 就是从控制台到控制台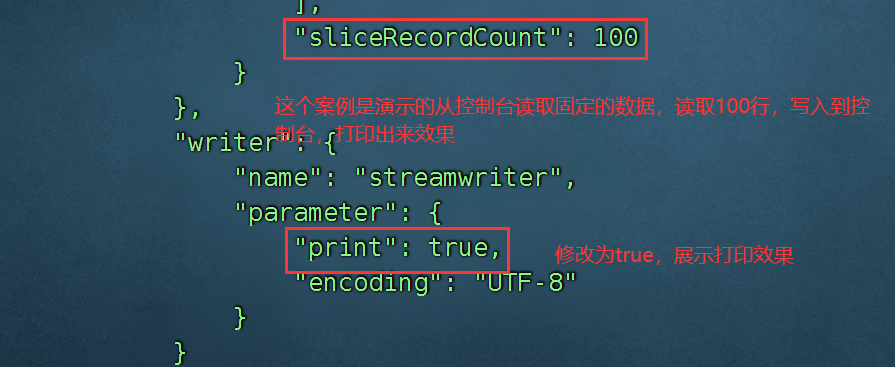

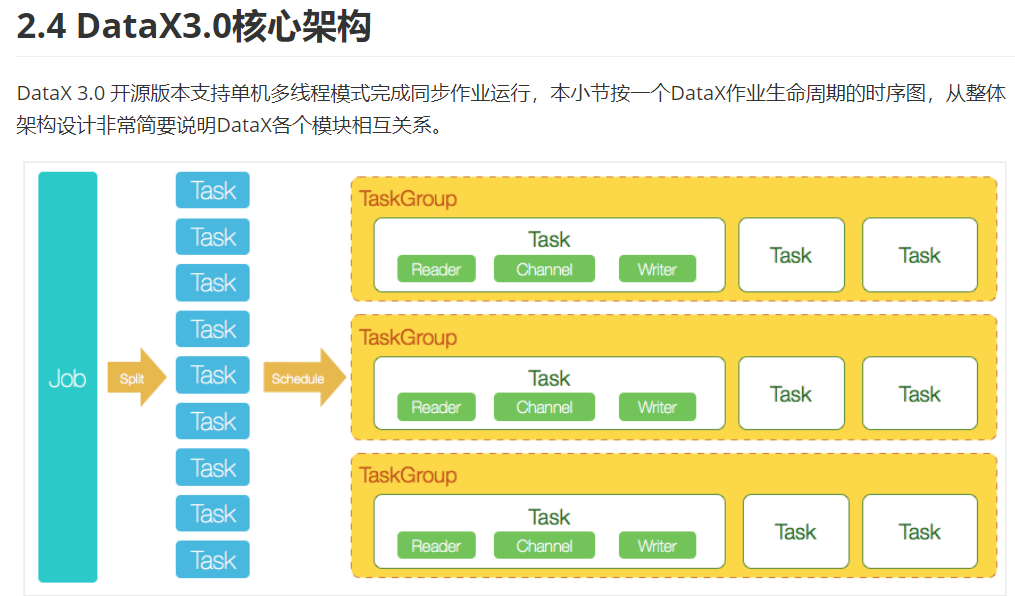
每一个TaskGroup 里面有5个并行的任务。所以我们的Datax脚本在运行的时候,是多线程同时进行的,速度很快。
DataX是基于内存的数据转换工具。Sqoop是基于磁盘的(MapTask),DataX的执行效率要远远高于Sqoop。
我们的DataX可以完成哪些类型的数据转换?
Stream(控制台) --> Streammysql --> Hdfshdfs --> Mysqlhive --> mysqlmysql --> Hive
调优手段:
两个地方:
1、增加并发度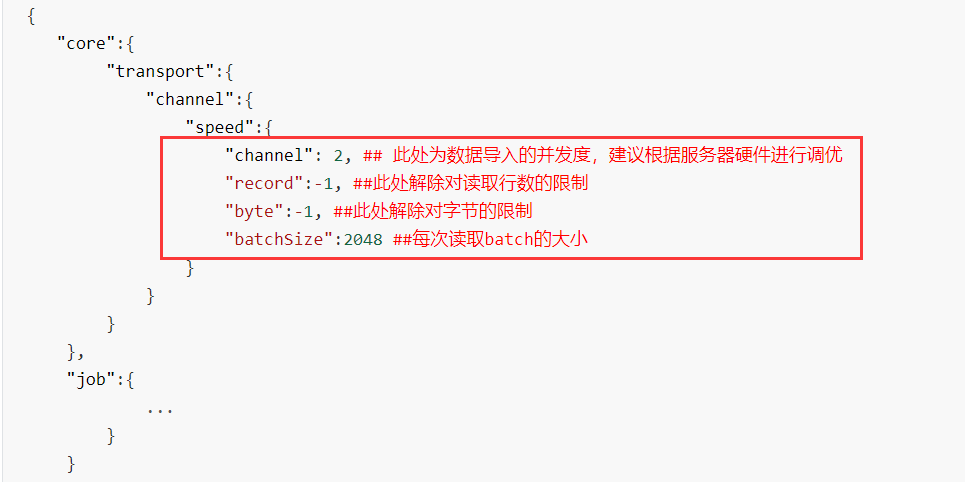
2、调整jvm内存大小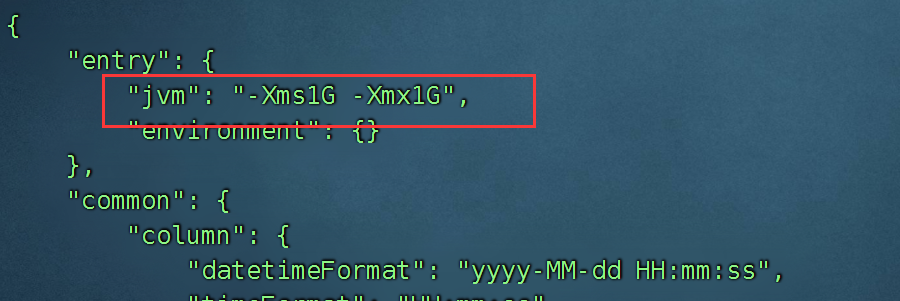
关于配置文件,有两处,一个是核心配置文件 datax的conf下的core.json
修改次数就是全局修改,一般我们不修改这个地方。
我们一般都会在自己的json文件开头的部分,设置并发度: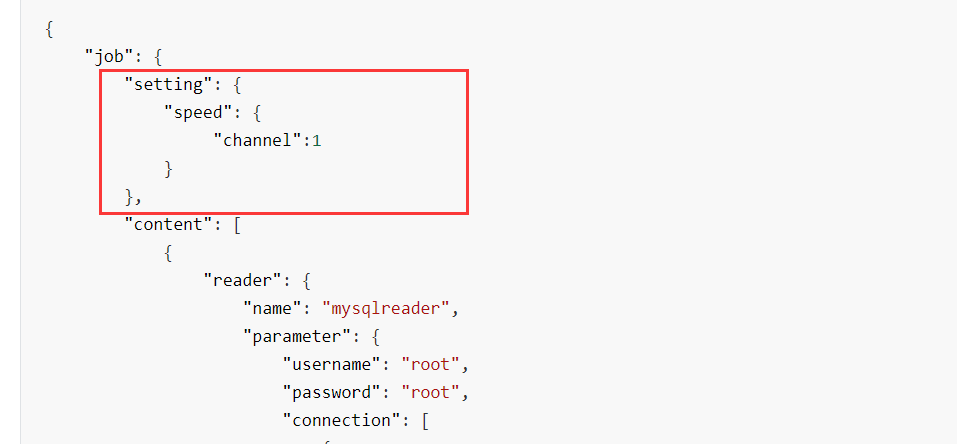
在运行json的时候,可以指定jvm内存大小:
datax.py --jvm="-Xms3G -Xmx3G" ../job/test.json
五、使用SuperSet展示图表
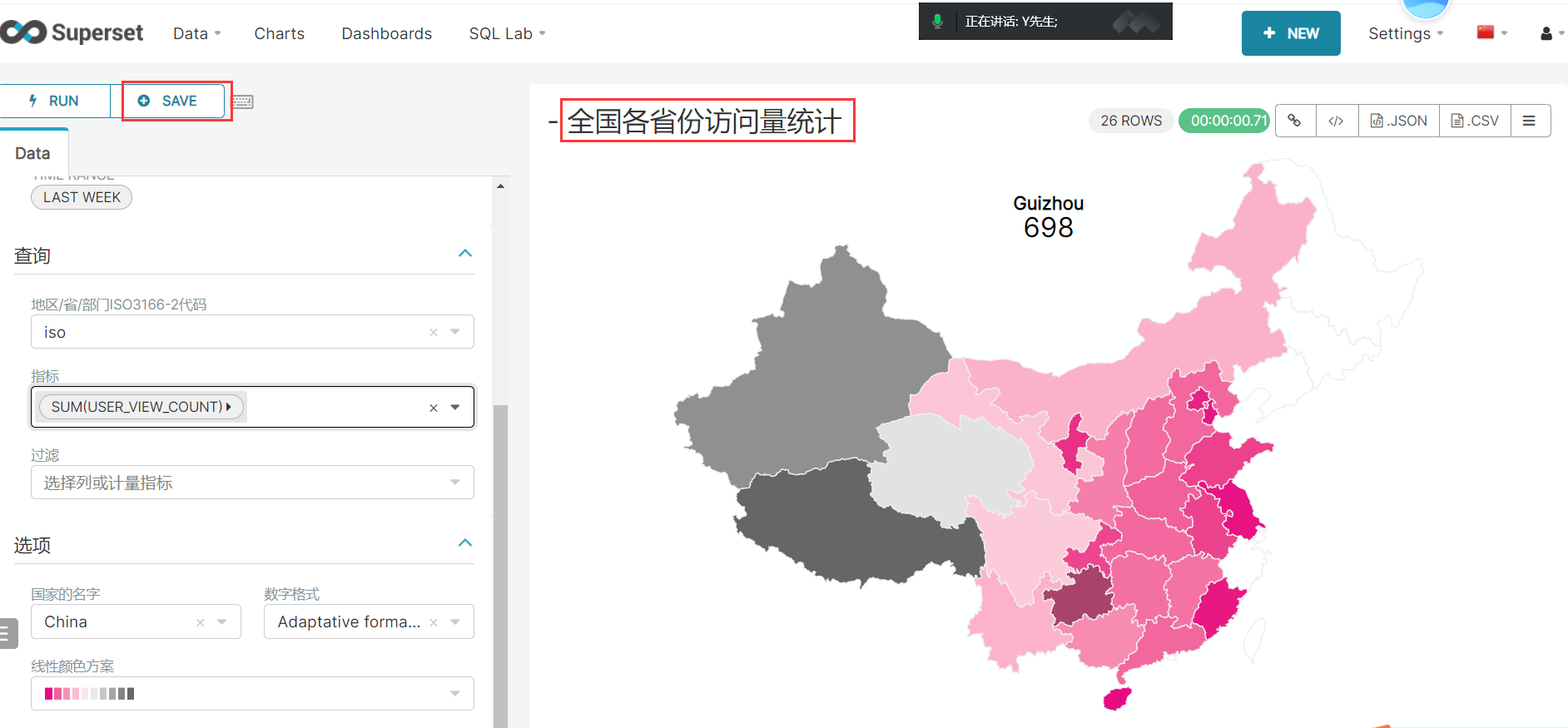
1、根据用户所在地区展示全国的访问量:
create external table if not exists ads_nshop.ads_nshop_customer(customer_gender string COMMENT '性别:1男 0女',os string comment '手机系统',customer_natives string COMMENT '所在地区ISO编码',user_view_count int comment '每个用户浏览次数') partitioned by (bdp_day string)row format delimited fields terminated by ','stored as TextFilelocation '/data/nshop/ads/operation/ads_nshop_customer/';
将之前的两个表关联,查询的数据插入到新表中:
insert overwrite table ads_nshop.ads_nshop_customer partition(bdp_day='20220509')selectb.customer_gender,a.os,c.iso,a.view_countfrom dws_nshop.dws_nshop_ulog_view ajoin ods_nshop.ods_02_customer bon a.user_id=b.customer_idjoin ods_nshop.ods_01_base_area con b.customer_natives=c.area_codewhere a.bdp_day='20220509';
将统计的结果导出到mysql中(datax)
现在mysql中创建一个表:
CREATE TABLE `ads_nshop_customer` (`customer_gender` tinyint(4) DEFAULT NULL,`os` varchar(255) DEFAULT NULL,`iso` varchar(255) DEFAULT NULL,`user_view_count` int(11) DEFAULT NULL)
接着编写02.json
{"job": {"setting": {"speed": {"channel": 3}},"content": [{"reader": {"name": "hdfsreader","parameter": {"path": "/data/nshop/ads/operation/ads_nshop_customer/bdp_day=${dt}/*","defaultFS": "hdfs://bigdata01:9820","column": [{"index": 0,"type": "string"},{"index": 1,"type": "string"},{"index": 2,"type": "string"},{"index": 3,"type": "long"}],"fileType": "text","encoding": "UTF-8","fieldDelimiter": ","}},"writer": {"name": "mysqlwriter","parameter": {"writeMode": "insert","username": "root","password": "123456","column": ["customer_gender","os","iso","user_view_count"],"connection": [{"jdbcUrl": "jdbc:mysql://bigdata01:3306/nshop","table": ["ads_nshop_customer"]}]}}}]}}
运行该脚本完成数据的导出:
datax.py job/02.json -p "-Ddt=20220509"
接着继续superSet的展示: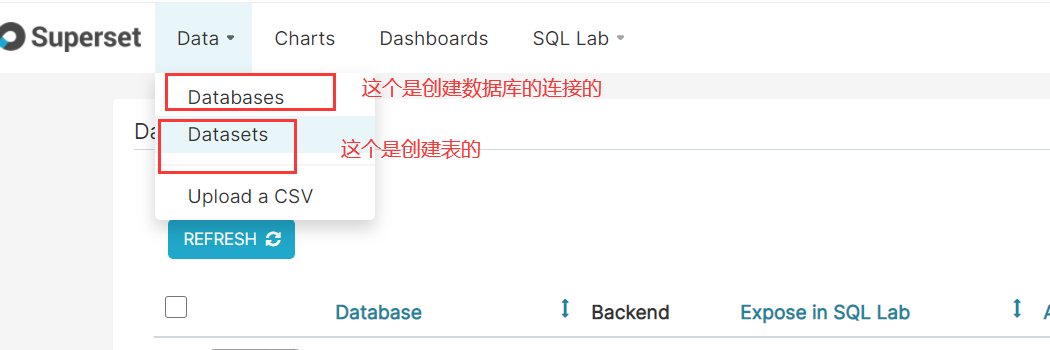
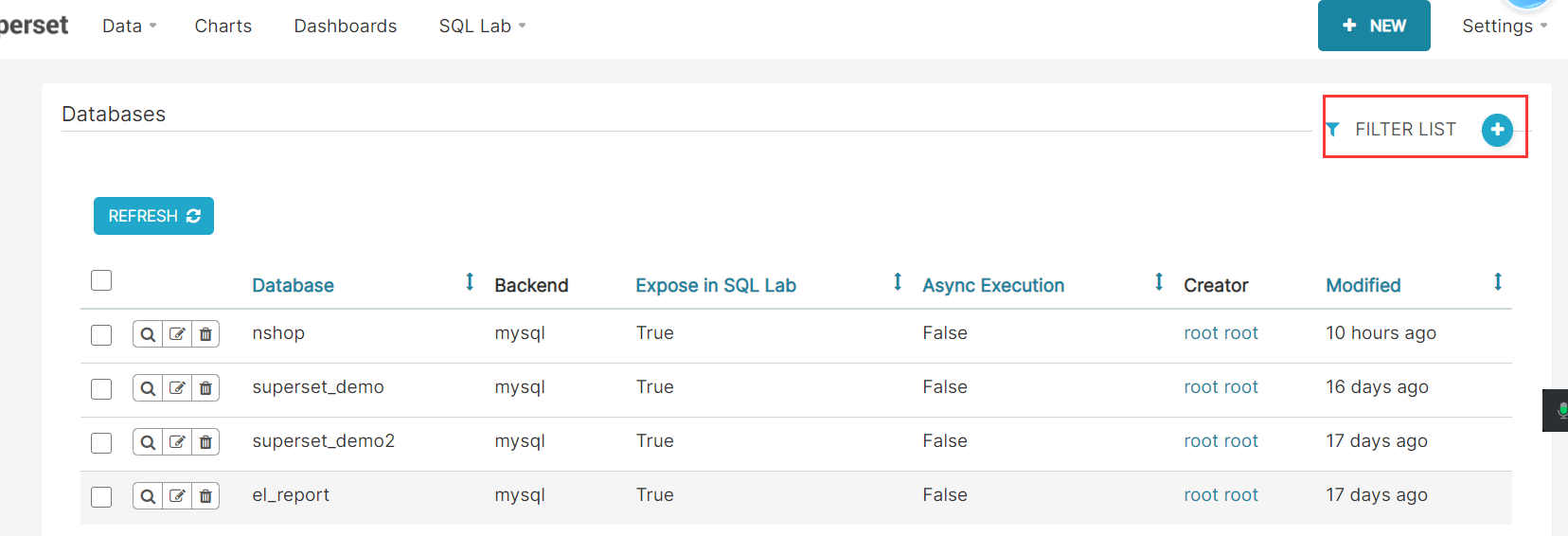
mysql://root:123456@bigdata01/nshop?charset=utf8
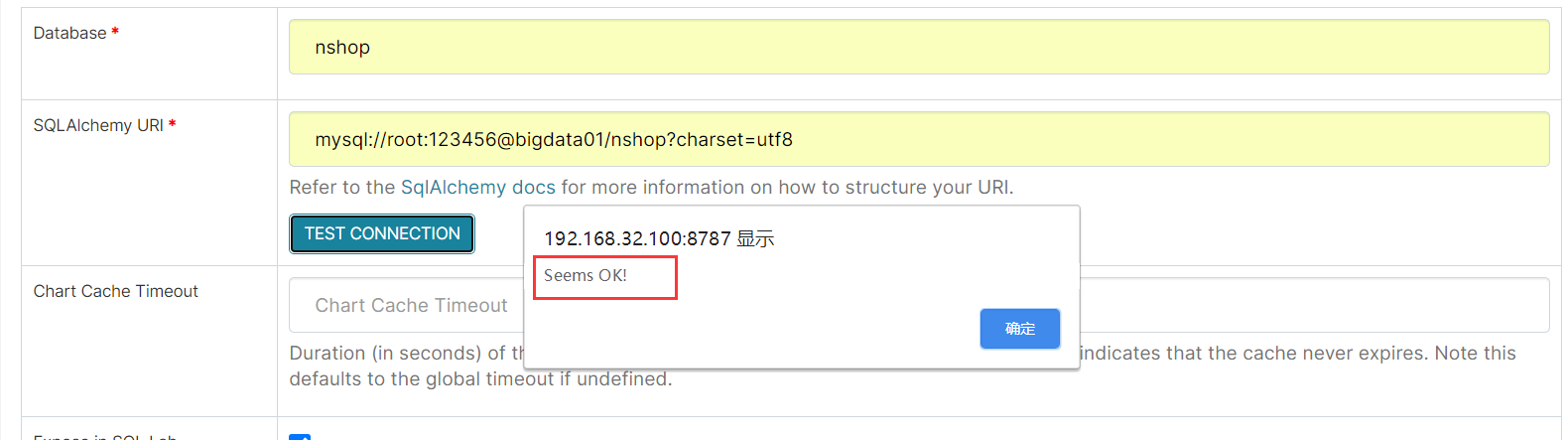
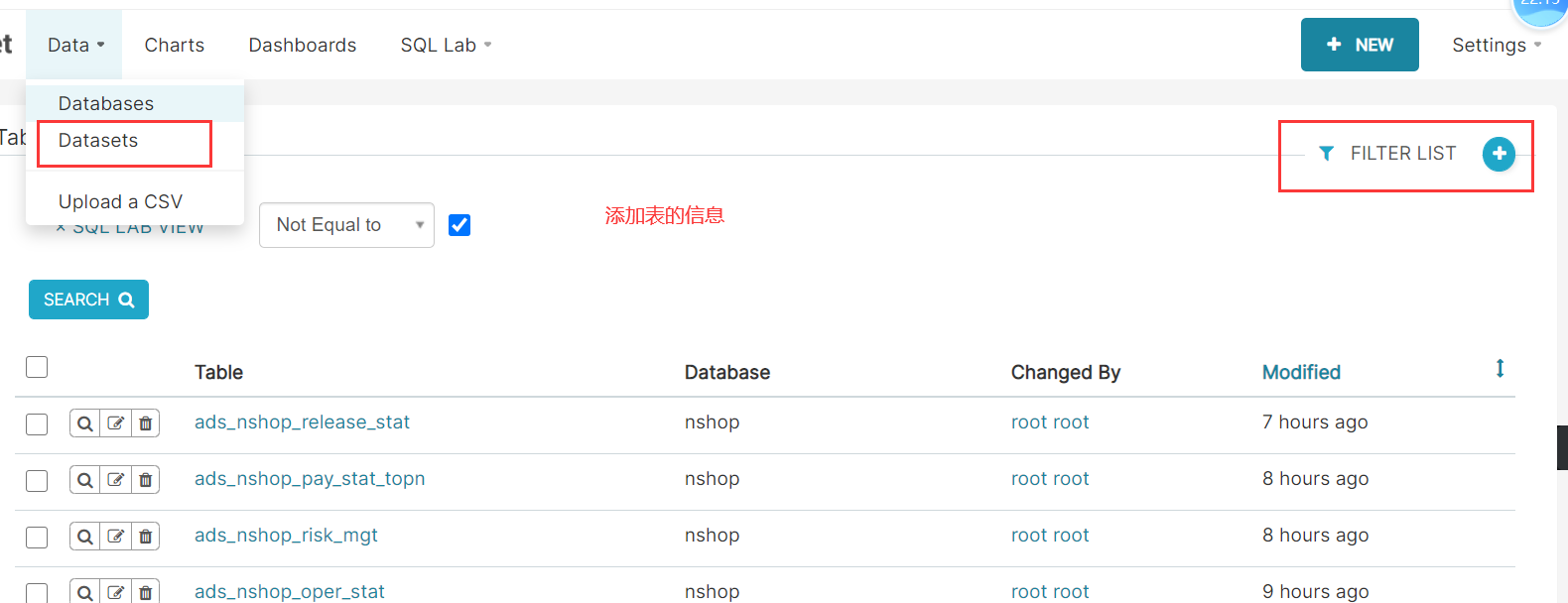
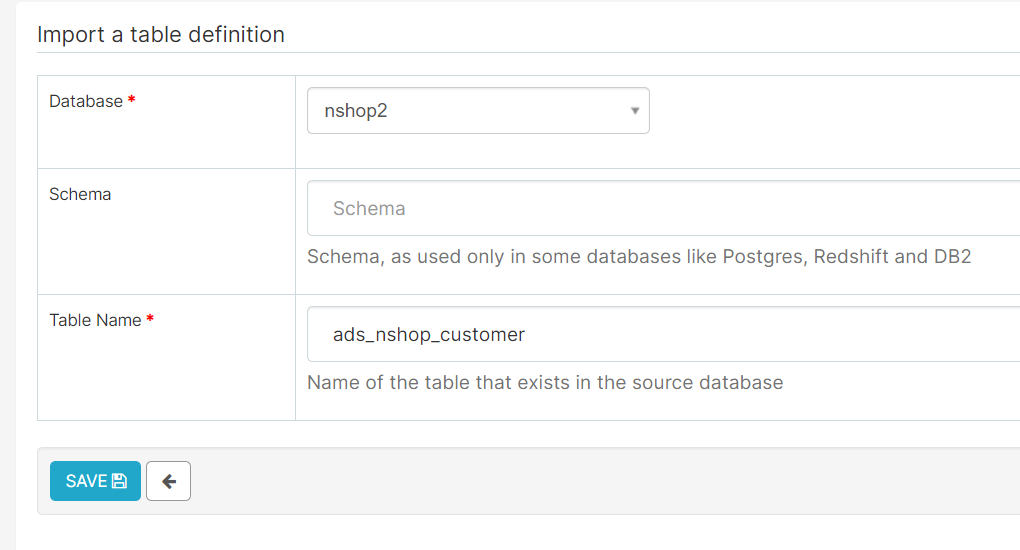

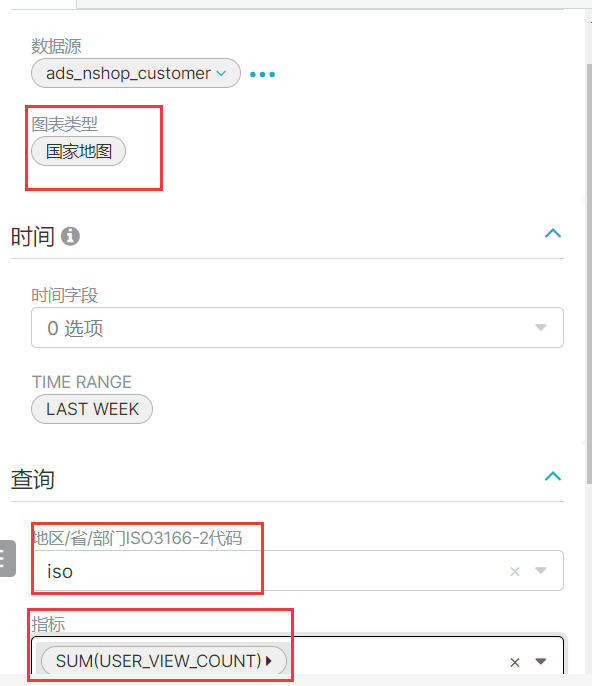
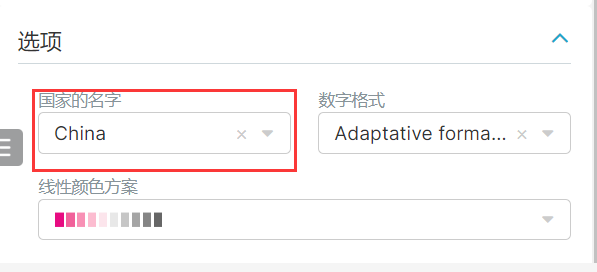
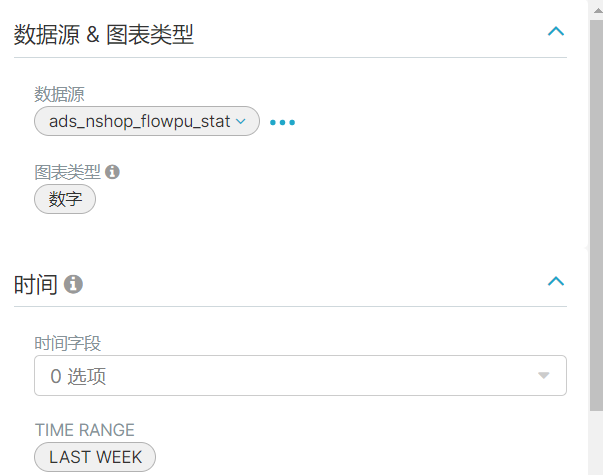
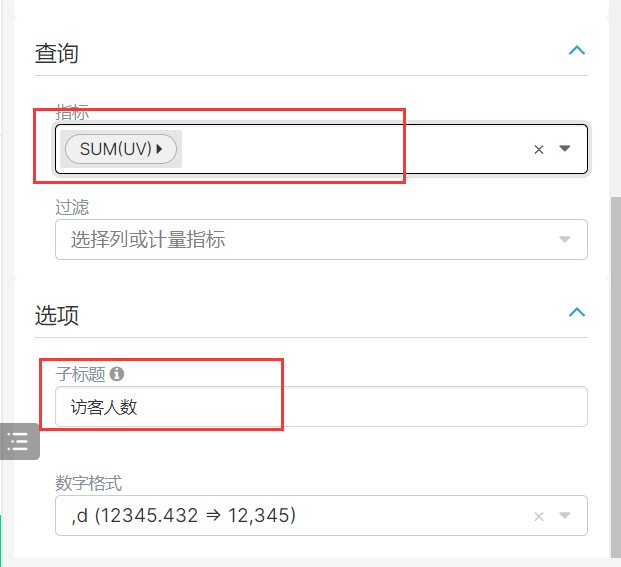
2、平台浏览统计
先在mysql中创建数据库:
CREATE TABLE `ads_nshop_flowpu_stat` (`uv` int DEFAULT NULL,`pv` int DEFAULT NULL,`pv_avg` double DEFAULT NULL)
接着将ads层统计的数据导出mysql:
{"job": {"setting": {"speed": {"channel": 3}},"content": [{"reader": {"name": "hdfsreader","parameter": {"path": "/data/nshop/ads/operation/ads_nshop_flow/bdp_day=${dt}/*","defaultFS": "hdfs://bigdata01:9820","column": [{"index": 0,"type": "Long"},{"index": 1,"type": "Long"},{"index": 2,"type": "Double"}],"fileType": "text","encoding": "UTF-8","fieldDelimiter": ","}},"writer": {"name": "mysqlwriter","parameter": {"writeMode": "insert","username": "root","password": "123456","column": ["uv","pv","pv_avg"],"connection": [{"jdbcUrl": "jdbc:mysql://bigdata01:3306/nshop","table": ["ads_nshop_flowpu_stat"]}]}}}]}}
执行job任务:
datax.py 03.json -p "-Ddt=20220509"
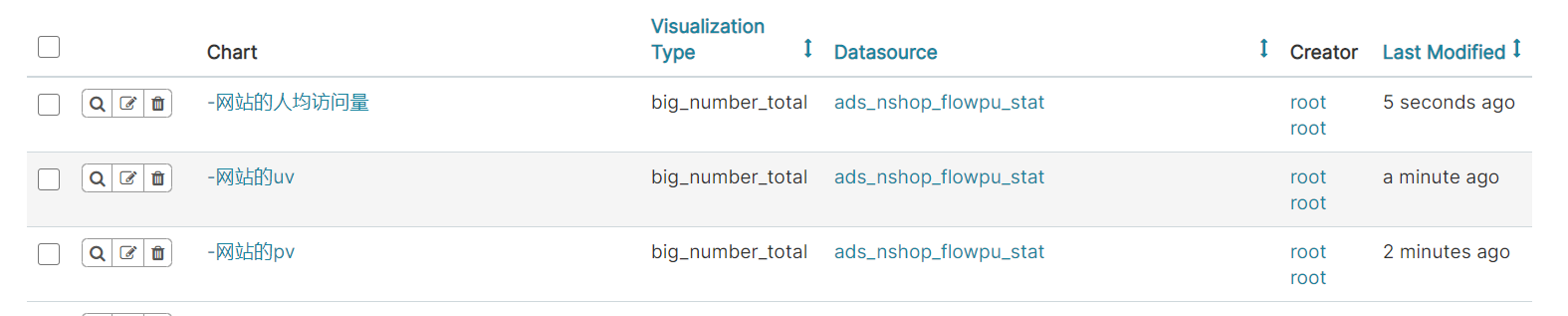
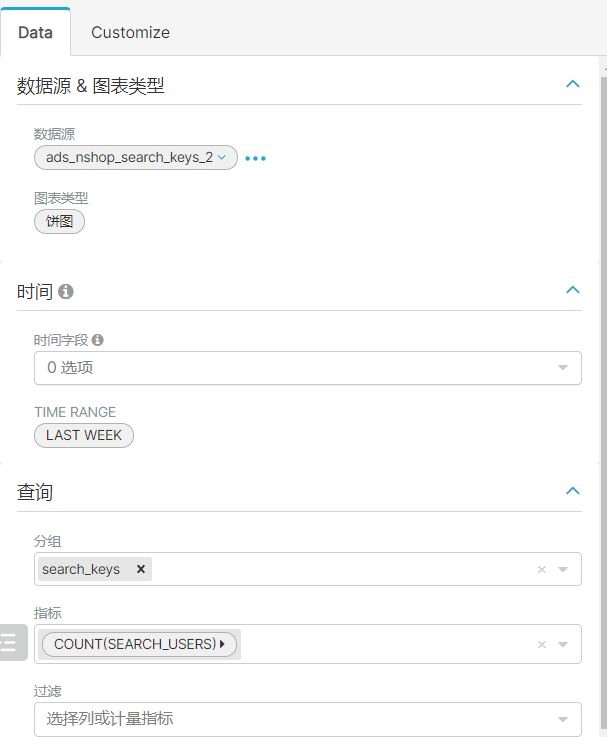
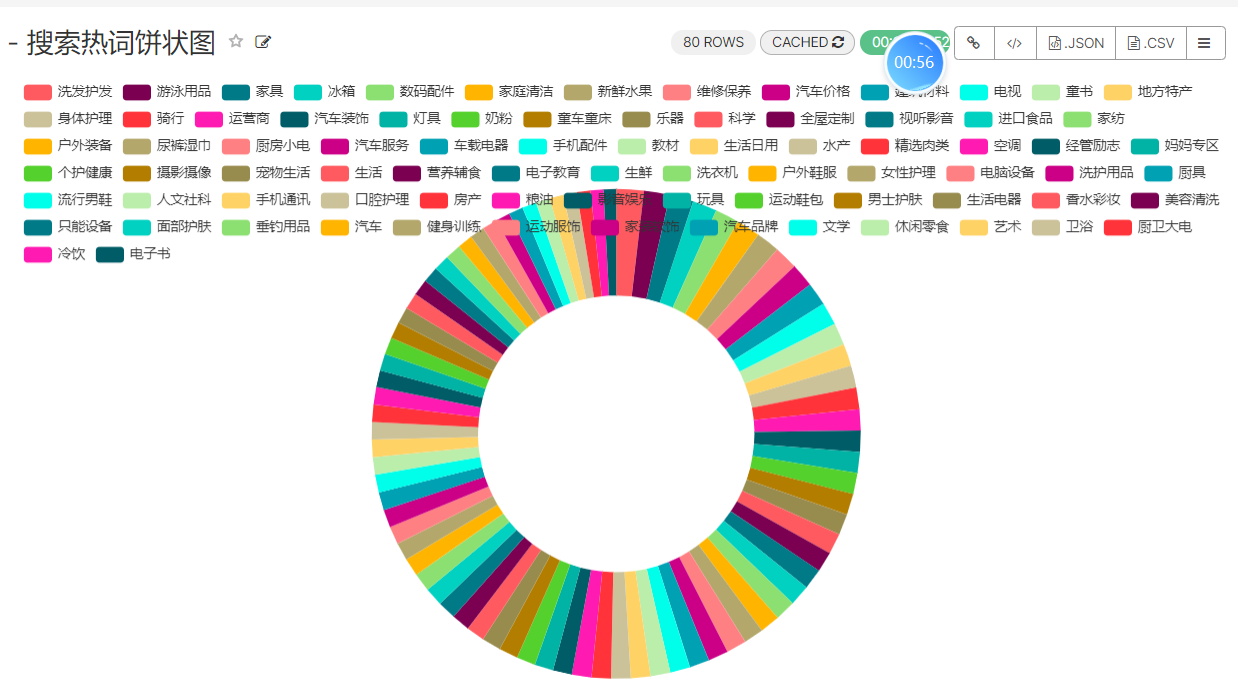
3、平台搜索热词统计
创建mysql的表:
CREATE TABLE `ads_nshop_search_keys` (`search_keys` varchar(255) DEFAULT NULL,`gender` varchar(255) DEFAULT NULL,`age_range` varchar(255) DEFAULT NULL,`os` varchar(255) DEFAULT NULL,`manufacturer` varchar(255) DEFAULT NULL,`area_code` varchar(255) DEFAULT NULL,`search_users` int DEFAULT NULL,`search_records` int DEFAULT NULL,`search_orders` varchar(255) DEFAULT NULL,`search_targets` int DEFAULT NULL)
从ads_nshop的数据库中导出数据到mysql:
{"job": {"setting": {"speed": {"channel": 3}},"content": [{"reader": {"name": "hdfsreader","parameter": {"path": "/data/nshop/ads/operation/ads_nshop_search_keys/bdp_day=${dt}/*","defaultFS": "hdfs://bigdata01:9820","column": [{"index": 0,"type": "string"},{"index": 1,"type": "string"},{"index": 2,"type": "string"},{"index": 3,"type": "string"},{"index": 4,"type": "string"},{"index": 5,"type": "string"},{"index": 6,"type": "long"},{"index": 7,"type": "long"},{"index": 8,"type": "string"},{"index": 9,"type": "long"}],"fileType": "text","encoding": "UTF-8","fieldDelimiter": ","}},"writer": {"name": "mysqlwriter","parameter": {"writeMode": "insert","username": "root","password": "123456","column": ["search_keys","gender","age_range","os","manufacturer","area_code","search_users","search_records","search_orders","search_targets"],"connection": [{"jdbcUrl": "jdbc:mysql://bigdata01:3306/nshop","table": ["ads_nshop_search_keys"]}]}}}]}}
datax.py 04.json -p "-Ddt=20220509"
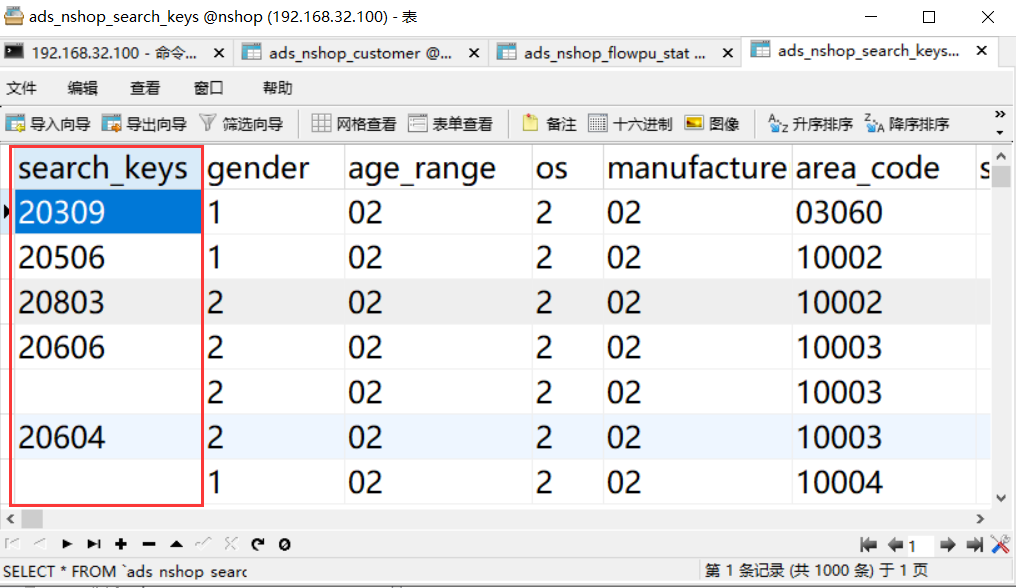
我们发现热词统计出来是一个个的编号,所以展示不好看,所以需要特殊处理一下。
在mysql中导入一个表:
导入进去之后,创建一个新的表:
CREATE TABLE `ads_nshop_search_keys_2` (`search_keys` varchar(255) DEFAULT NULL,`gender` varchar(255) DEFAULT NULL,`age_range` varchar(255) DEFAULT NULL,`os` varchar(255) DEFAULT NULL,`manufacturer` varchar(255) DEFAULT NULL,`area_code` varchar(255) DEFAULT NULL,`search_users` int DEFAULT NULL,`search_records` int DEFAULT NULL,`search_orders` varchar(255) DEFAULT NULL,`search_targets` int DEFAULT NULL)
关联shop_code 以及 ads_nshop_search_keys 将关联好的数据插入到新的表中,将来使用superset展示新的表数据即可:
insert into ads_nshop_search_keys_2(search_keys ,gender,age_range,os,manufacturer,area_code,search_users,search_records,search_orders,search_targets)SELECT name as search_keys ,gender,age_range,os,manufacturer,area_code,search_users,search_records,search_orders,search_targets FROM ads_nshop_search_keys JOIN shop_code ON search_keys=id
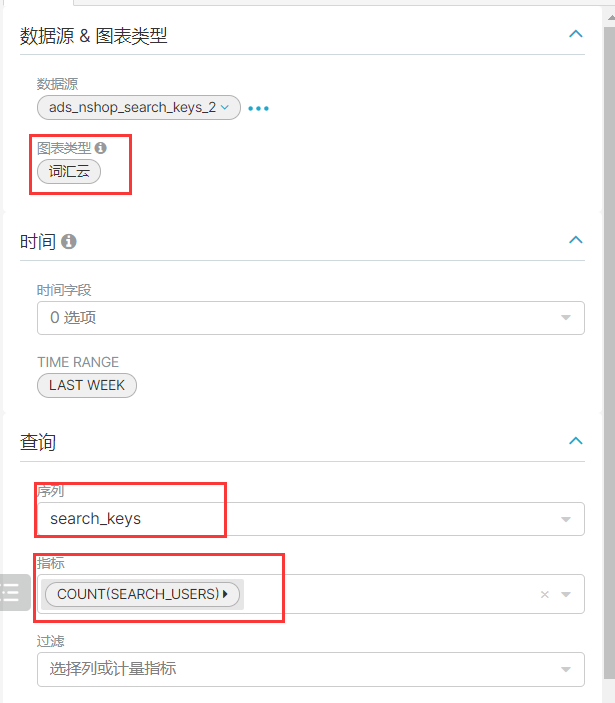
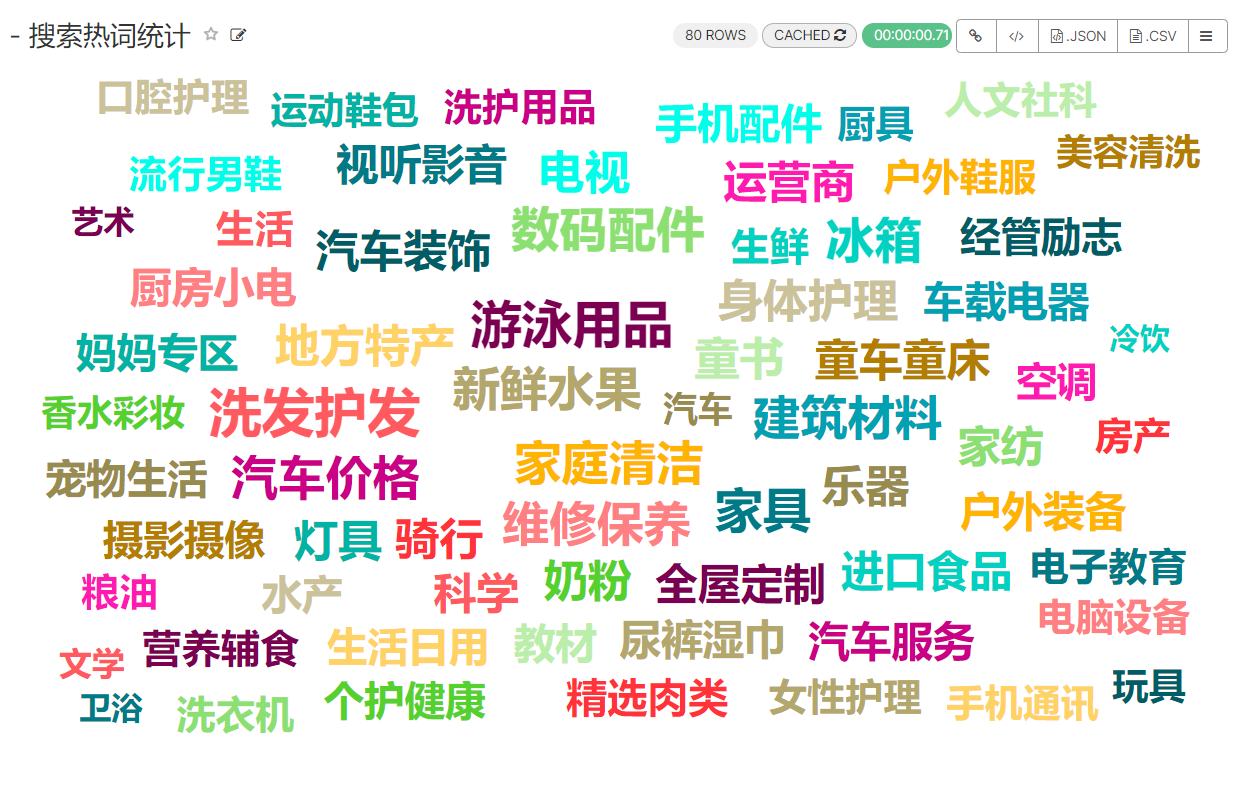
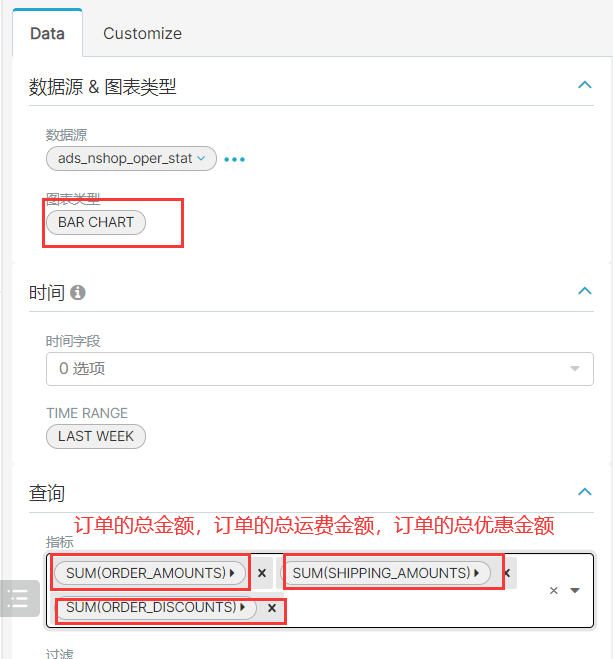
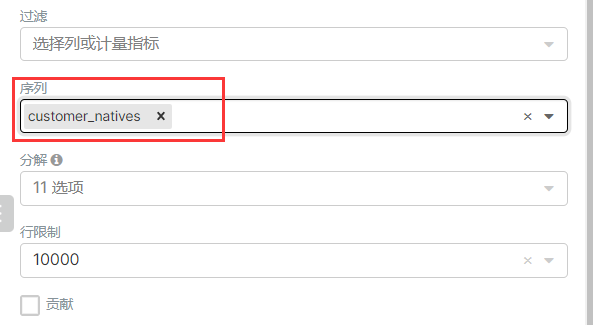
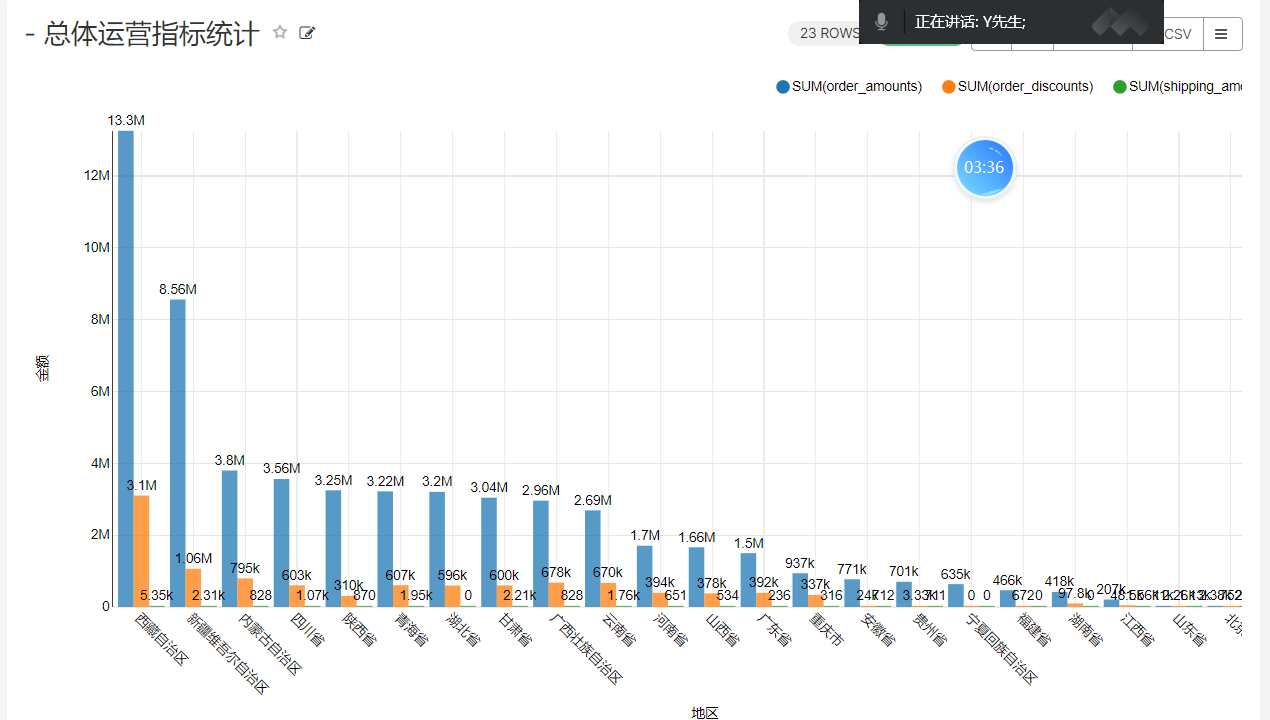
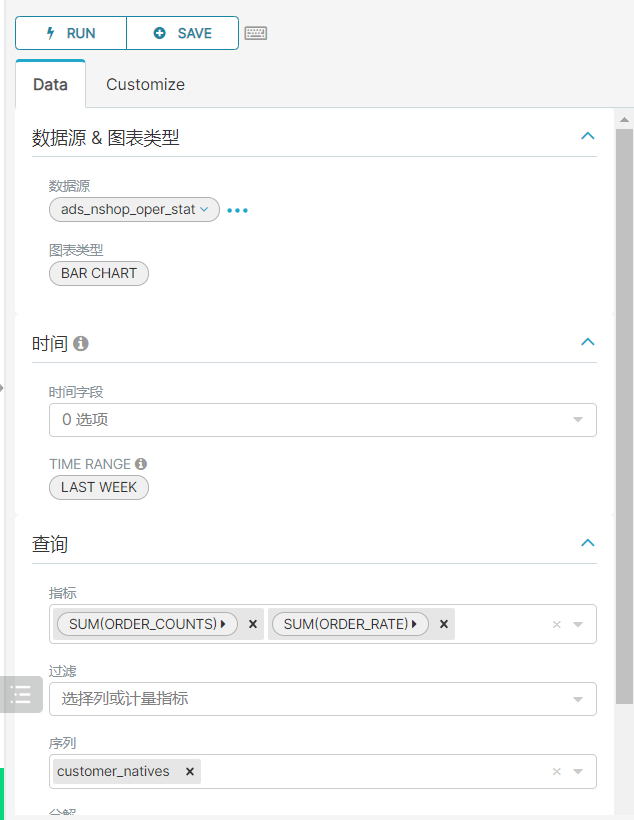
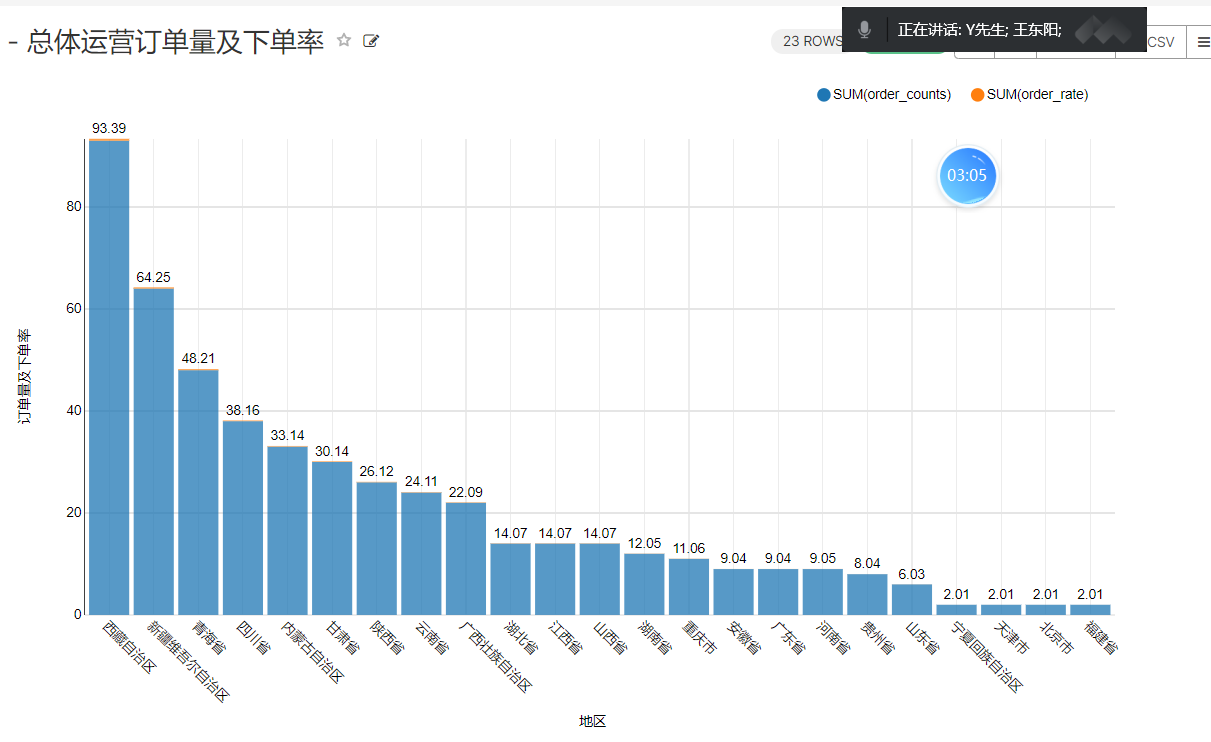
5、总体运营指标统计
insert overwrite table ads_nshop.ads_nshop_oper_stat partition(bdp_day='20220509')selecta.customer_gender,a.customer_age_range,e.province_name,c.category_code,count(distinct b.order_id) ,count(distinct b.order_id) / sum(d.view_count),sum(b.payment_money),sum(b.district_money),sum(b.shipping_money),sum(b.payment_money) / count(distinct b.customer_id)from ods_nshop.ods_02_customer ajoin dwd_nshop.dwd_nshop_orders_details bon a.customer_id=b.customer_idjoin ods_nshop.dim_pub_product con b.supplier_code=c.supplier_codejoin dws_nshop.dws_nshop_ulog_view don b.customer_id=d.user_idjoin ods_nshop.ods_01_base_area eon a.customer_natives=e.area_codewhere d.bdp_day='20220509'group bya.customer_gender,a.customer_age_range,e.province_name,c.category_code;
为什么要把昨天的指标再次统计一遍,因为今天新增了一个ods_01_base_area,统计出来的结果更加的便于展示。
运行结束后,将ads层的运营指标数据,导出到mysql中。
CREATE TABLE `ads_nshop_oper_stat` (`customer_gender` int DEFAULT NULL,`age_range` varchar(255) DEFAULT NULL,`customer_natives` varchar(255) DEFAULT NULL,`product_type` int DEFAULT NULL,`order_counts` int DEFAULT NULL,`order_rate` double DEFAULT NULL,`order_amounts` int DEFAULT NULL,`order_discounts` int DEFAULT NULL,`shipping_amounts` int DEFAULT NULL,`per_customer_transaction` int DEFAULT NULL)
编写job任务:
{"job": {"setting": {"speed": {"channel": 3}},"content": [{"reader": {"name": "hdfsreader","parameter": {"path": "/data/nshop/ads/operation/ads_nshop_oper_stat/bdp_day=${dt}/*","defaultFS": "hdfs://bigdata01:9820","column": [{"index": 0,"type": "long"},{"index": 1,"type": "string"},{"index": 2,"type": "string"},{"index": 3,"type": "long"},{"index": 4,"type": "long"},{"index": 5,"type": "double"},{"index": 6,"type": "long"},{"index": 7,"type": "long"},{"index": 8,"type": "long"},{"index": 9,"type": "long"}],"fileType": "text","encoding": "UTF-8","fieldDelimiter": ","}},"writer": {"name": "mysqlwriter","parameter": {"writeMode": "insert","username": "root","password": "123456","column": ["customer_gender","age_range","customer_natives","product_type","order_counts","order_rate","order_amounts","order_discounts","shipping_amounts","per_customer_transaction"],"connection": [{"jdbcUrl": "jdbc:mysql://bigdata01:3306/nshop","table": ["ads_nshop_oper_stat"]}]}}}]}}
运行:
datax.py 05.json -p "-Ddt=20220509"
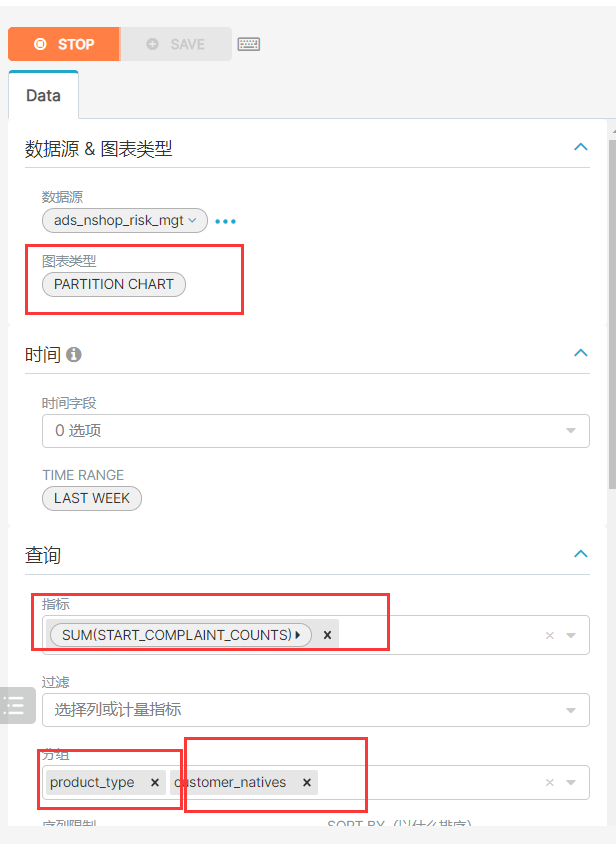
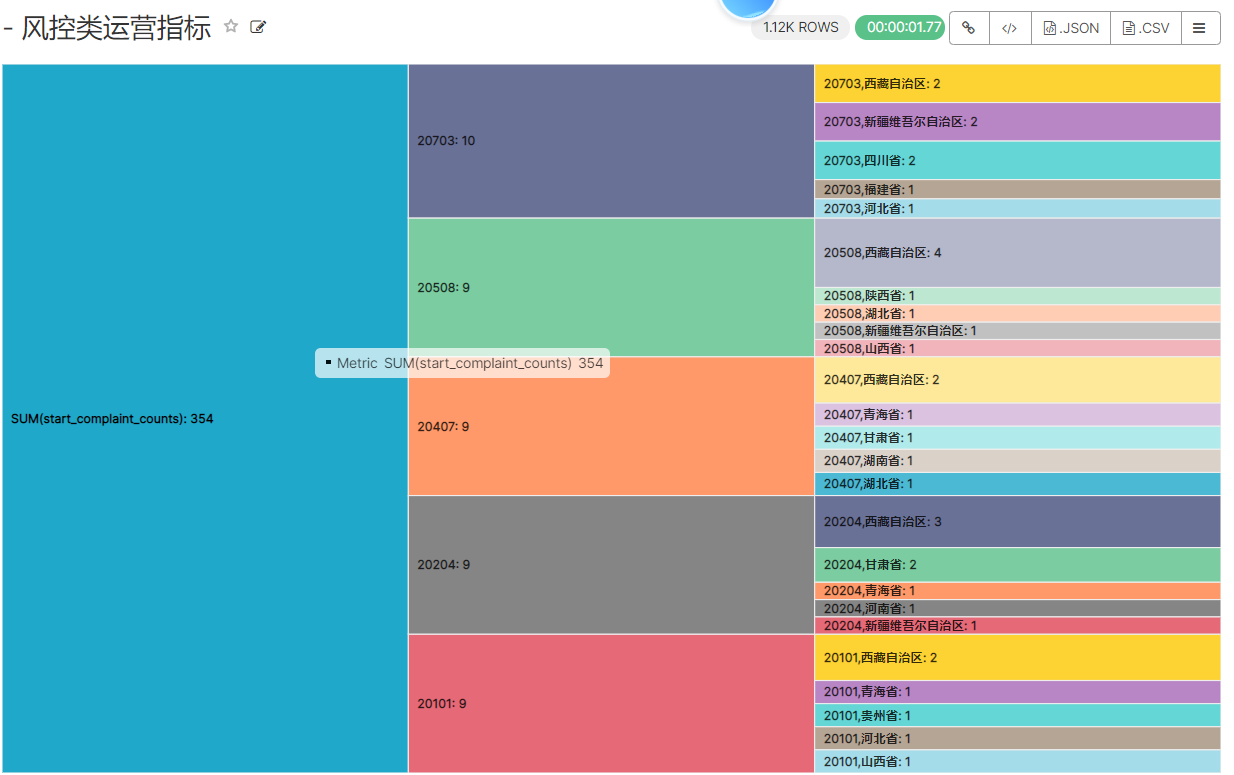
6、风控类指标统计
insert overwrite table ads_nshop.ads_nshop_risk_mgt partition(bdp_day='20220509')selecta.customer_gender,a.customer_age_range,e.province_name,c.category_code,count(distinct case when b.order_status=6 then b.order_id end),count(distinct case when b.order_status=6 then b.order_id end)/count(distinct b.order_id)*100from ods_nshop.ods_02_customer ajoin dwd_nshop.dwd_nshop_orders_details bon a.customer_id=b.customer_idjoin ods_nshop.dim_pub_product con b.supplier_code=c.supplier_codejoin ods_nshop.ods_01_base_area eon a.customer_natives=e.area_codewhere b.bdp_day='20220509'group bya.customer_gender,a.customer_age_range,e.province_name,c.category_code;
创建mysql的表:
CREATE TABLE `ads_nshop_risk_mgt` (`customer_gender` int DEFAULT NULL,`age_range` varchar(255) DEFAULT NULL,`customer_natives` varchar(255) DEFAULT NULL,`product_type` varchar(255) DEFAULT NULL,`start_complaint_counts` int DEFAULT NULL,`complaint_rate` double DEFAULT NULL)
将hive中新跑的数据导出到mysql中:
{"job": {"setting": {"speed": {"channel": 3}},"content": [{"reader": {"name": "hdfsreader","parameter": {"path": "/data/nshop/ads/operation/ads_nshop_risk_mgt/bdp_day=${dt}/*","defaultFS": "hdfs://bigdata01:9820","column": [{"index": 0,"type": "long"},{"index": 1,"type": "string"},{"index": 2,"type": "string"},{"index": 3,"type": "string"},{"index": 4,"type": "long"},{"index": 5,"type": "double"}],"fileType": "text","encoding": "UTF-8","fieldDelimiter": ","}},"writer": {"name": "mysqlwriter","parameter": {"writeMode": "insert","username": "root","password": "123456","column": ["customer_gender","age_range","customer_natives","product_type","start_complaint_counts","complaint_rate"],"connection": [{"jdbcUrl": "jdbc:mysql://bigdata01:3306/nshop","table": ["ads_nshop_risk_mgt"]}]}}}]}}
执行该脚本:
datax.py 06.json -p "-Ddt=20220509"
7、统计类的TopN
重新运行指标任务,原因是添加了地区:
insert overwrite table ads_nshop.ads_nshop_pay_stat_topn partition(bdp_day='20220509')selectcase when b.pay_type='10' then '网上银行' when b.pay_type='11' then '微信' when b.pay_type='12' then '支付宝' else '线下支付' end,e.province_name,count(distinct b.pay_id),sum(b.pay_amount) as pay_sumfrom ods_nshop.ods_02_customer ajoin ods_nshop.ods_02_orders_pay_records bon a.customer_id=b.customer_idjoin ods_nshop.ods_01_base_area eon a.customer_natives=e.area_codegroup bye.province_name,b.pay_type order by pay_sum desc limit 500;
在mysql中创建表:
CREATE TABLE `ads_nshop_pay_stat_topn` (`pay_type` varchar(255) DEFAULT NULL,`customer_area_code` varchar(255) DEFAULT NULL,`pay_count` int DEFAULT NULL,`pay_amounts` int DEFAULT NULL)
编写job任务:
{"job": {"setting": {"speed": {"channel": 3}},"content": [{"reader": {"name": "hdfsreader","parameter": {"path": "/data/nshop/ads/operation/ads_nshop_pay_stat_topn/bdp_day=${dt}/*","defaultFS": "hdfs://bigdata01:9820","column": [{"index": 0,"type": "string"},{"index": 1,"type": "string"},{"index": 2,"type": "long"},{"index": 3,"type": "long"}],"fileType": "text","encoding": "UTF-8","fieldDelimiter": ","}},"writer": {"name": "mysqlwriter","parameter": {"writeMode": "insert","username": "root","password": "123456","column": ["pay_type","customer_area_code","pay_count","pay_amounts"],"connection": [{"jdbcUrl": "jdbc:mysql://bigdata01:3306/nshop","table": ["ads_nshop_pay_stat_topn"]}]}}}]}}
运行任务:
datax.py 07.json -p "-Ddt=20220509"
展示: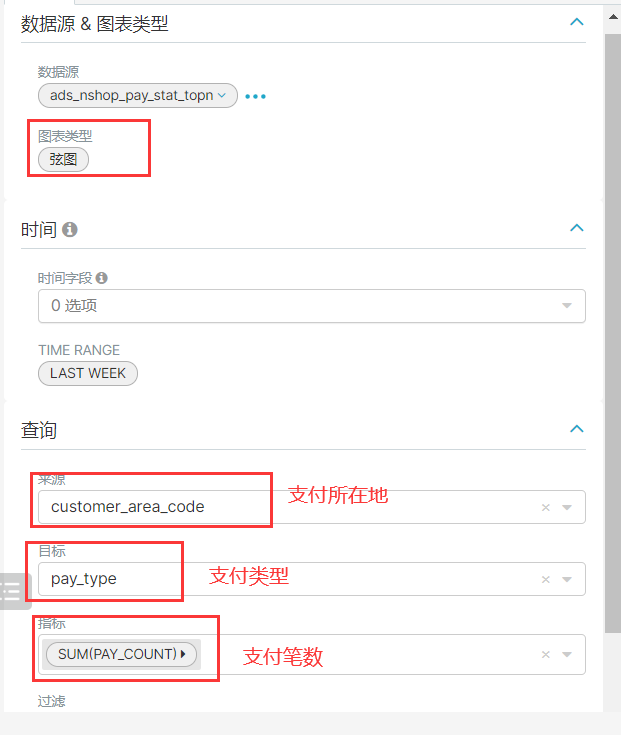
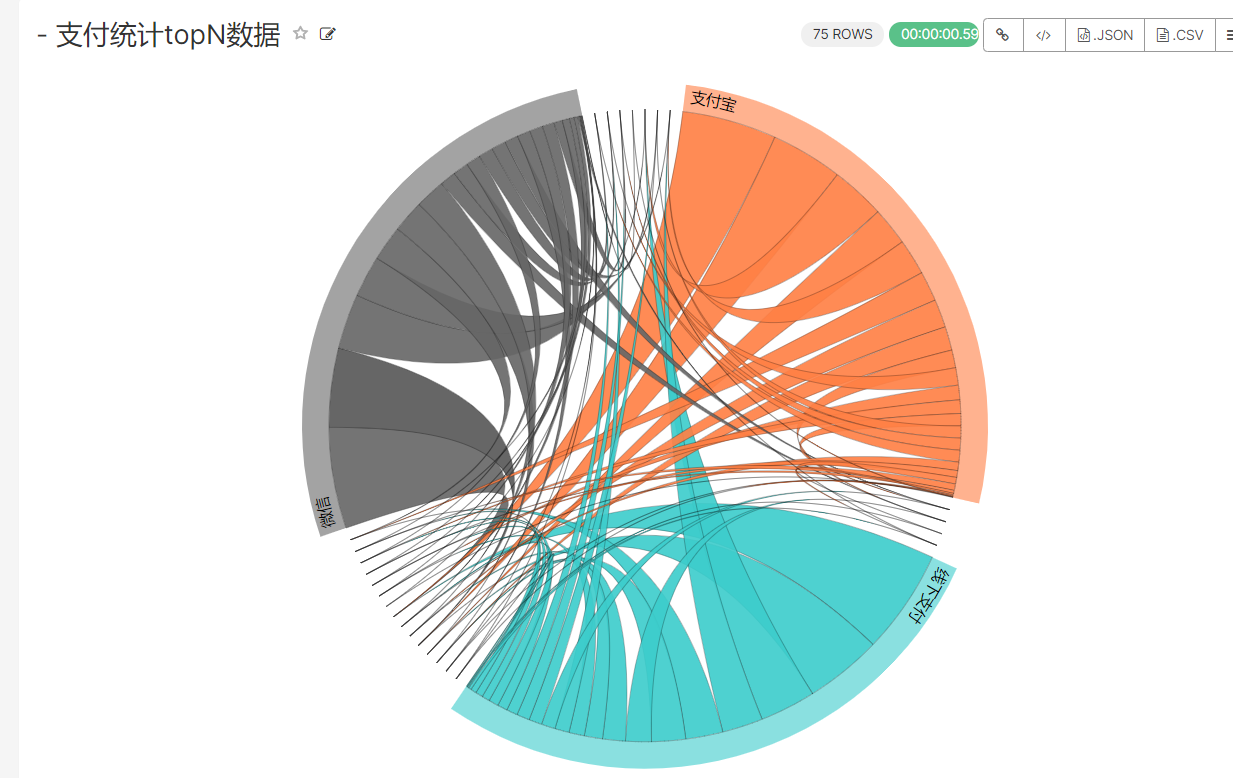
树状图统计: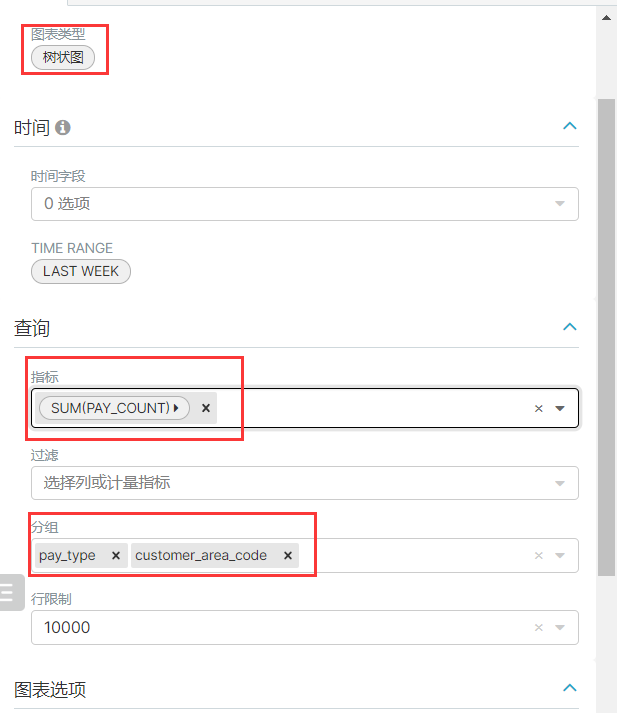
8、广告投放类指标统计
重新运行指标:
insert overwrite table ads_nshop.ads_nshop_release_stat partition(bdp_day='20220509')selecta.device_type,a.os,b.customer_gender,b.customer_age_range,e.province_name,a.release_sources,a.release_category,count(distinct a.customer_id),count(*)from dwd_nshop.dwd_nshop_releasedatas ajoin ods_nshop.ods_02_customer bon a.customer_id=b.customer_idjoin ods_nshop.ods_01_base_area eon b.customer_natives=e.area_codewhere a.bdp_day='20220509'group bya.device_type,a.os,b.customer_gender,b.customer_age_range,e.province_name,a.release_sources,a.release_category;
创建mysql数据库:
CREATE TABLE `ads_nshop_release_stat` (`device_type` varchar(255) DEFAULT NULL,`os` varchar(255) DEFAULT NULL,`customer_gender` int DEFAULT NULL,`age_range` varchar(255) DEFAULT NULL,`customer_natives` varchar(255) DEFAULT NULL,`release_sources` varchar(255) DEFAULT NULL,`release_category` varchar(255) DEFAULT NULL,`visit_total_customers` int DEFAULT NULL,`visit_total_counts` int DEFAULT NULL)
执行任务,导出数据:
{"job": {"setting": {"speed": {"channel": 3}},"content": [{"reader": {"name": "hdfsreader","parameter": {"path": "/data/nshop/ads/operation/ads_nshop_release_stat/bdp_day=${dt}/*","defaultFS": "hdfs://bigdata01:9820","column": [{"index": 0,"type": "string"},{"index": 1,"type": "string"},{"index": 2,"type": "long"},{"index": 3,"type": "string"},{"index": 4,"type": "string"},{"index": 5,"type": "string"},{"index": 6,"type": "string"},{"index": 7,"type": "long"},{"index": 8,"type": "long"}],"fileType": "text","encoding": "UTF-8","fieldDelimiter": ","}},"writer": {"name": "mysqlwriter","parameter": {"writeMode": "insert","username": "root","password": "123456","column": ["device_type","os","customer_gender","age_range","customer_natives","release_sources","release_category","visit_total_customers","visit_total_counts"],"connection": [{"jdbcUrl": "jdbc:mysql://bigdata01:3306/nshop","table": ["ads_nshop_release_stat"]}]}}}]}}
执行该任务,导出数据即可:
datax.py 08.json -p "-Ddt=20220509"
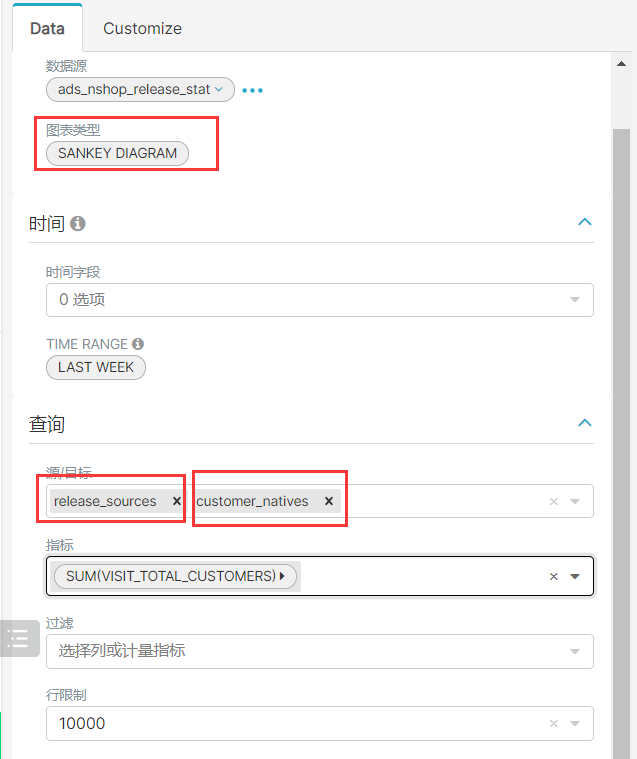
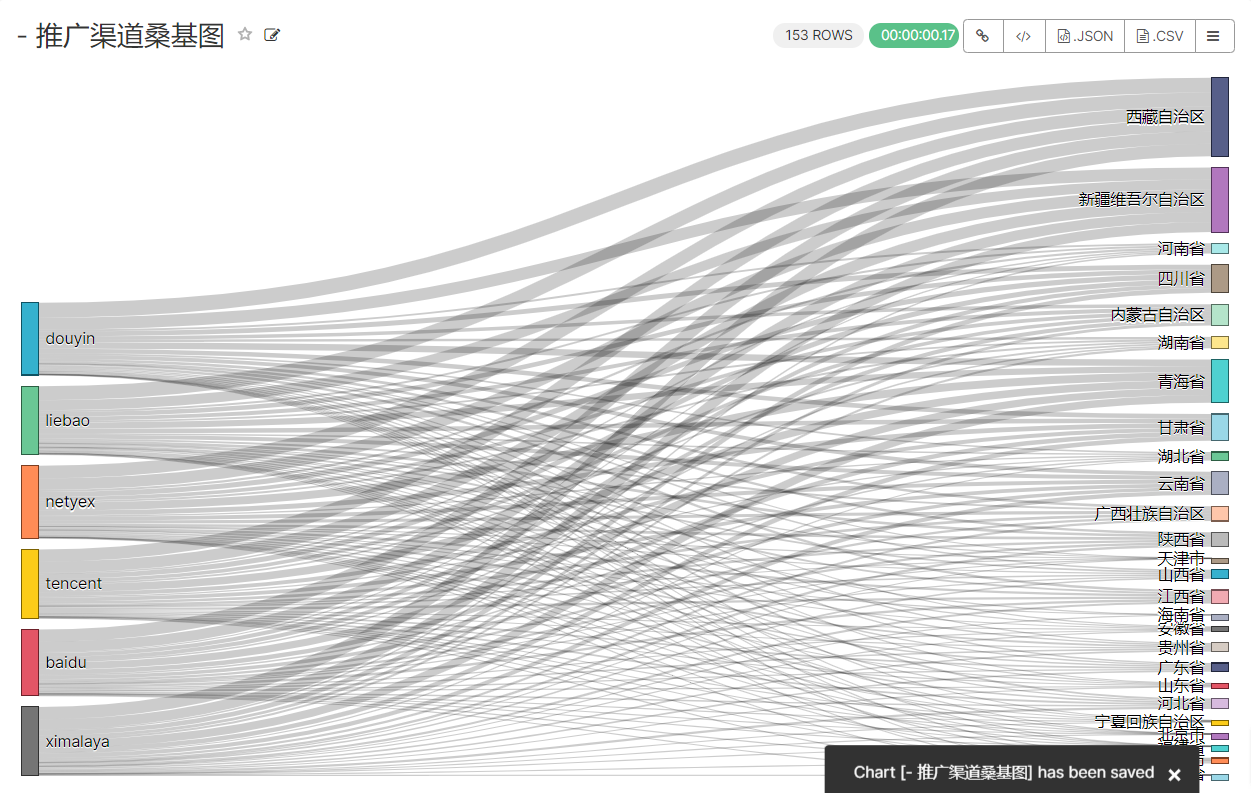
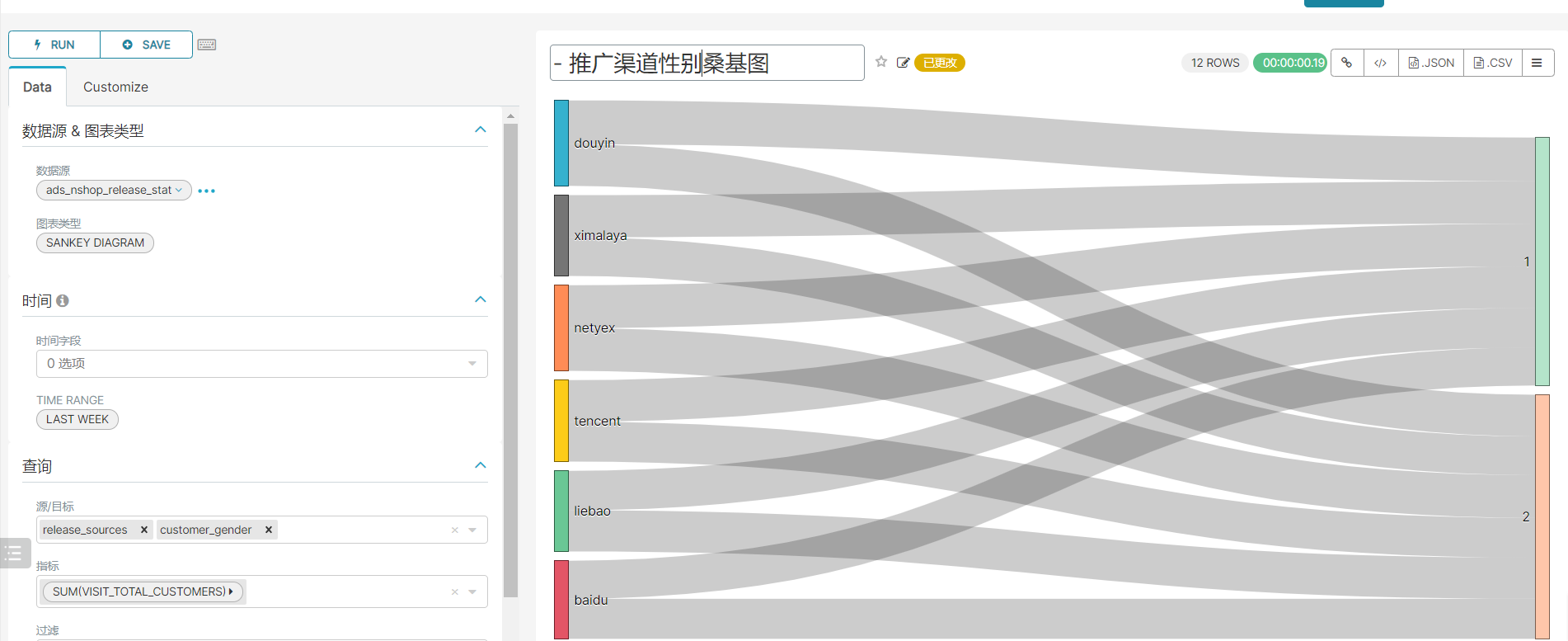
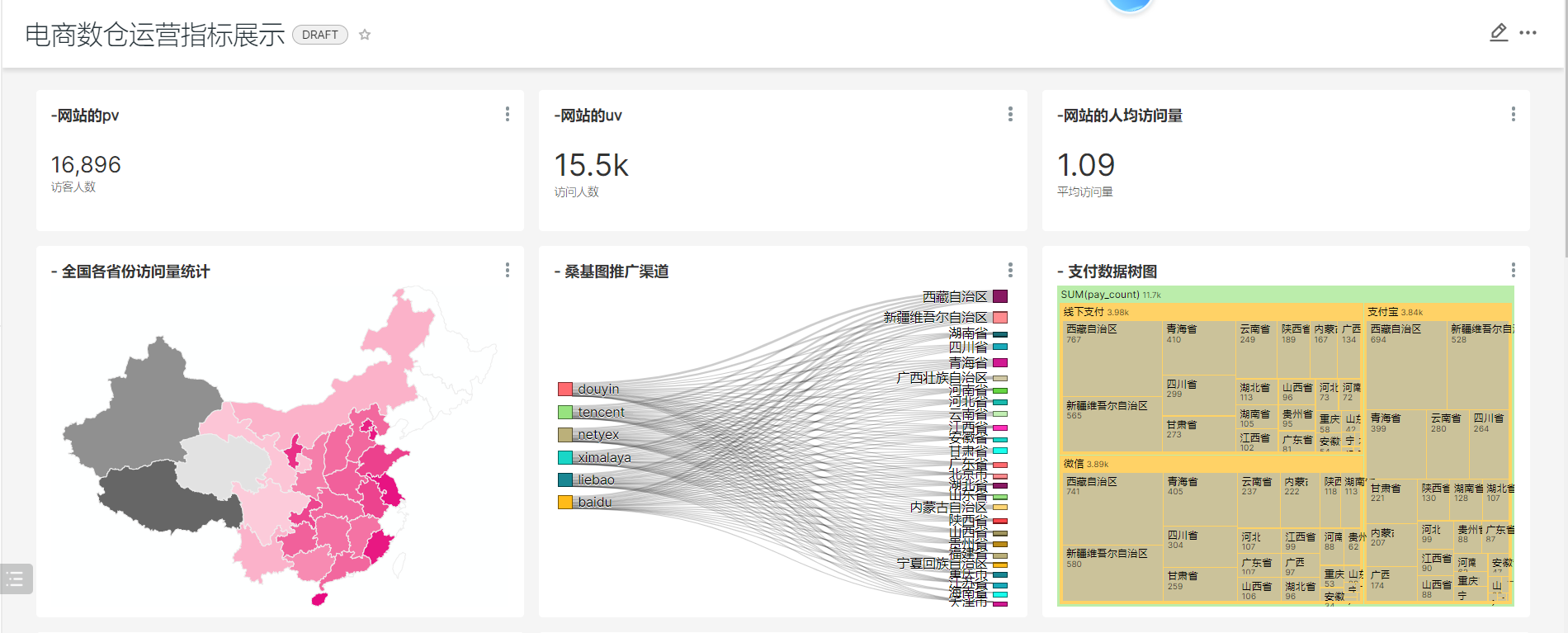
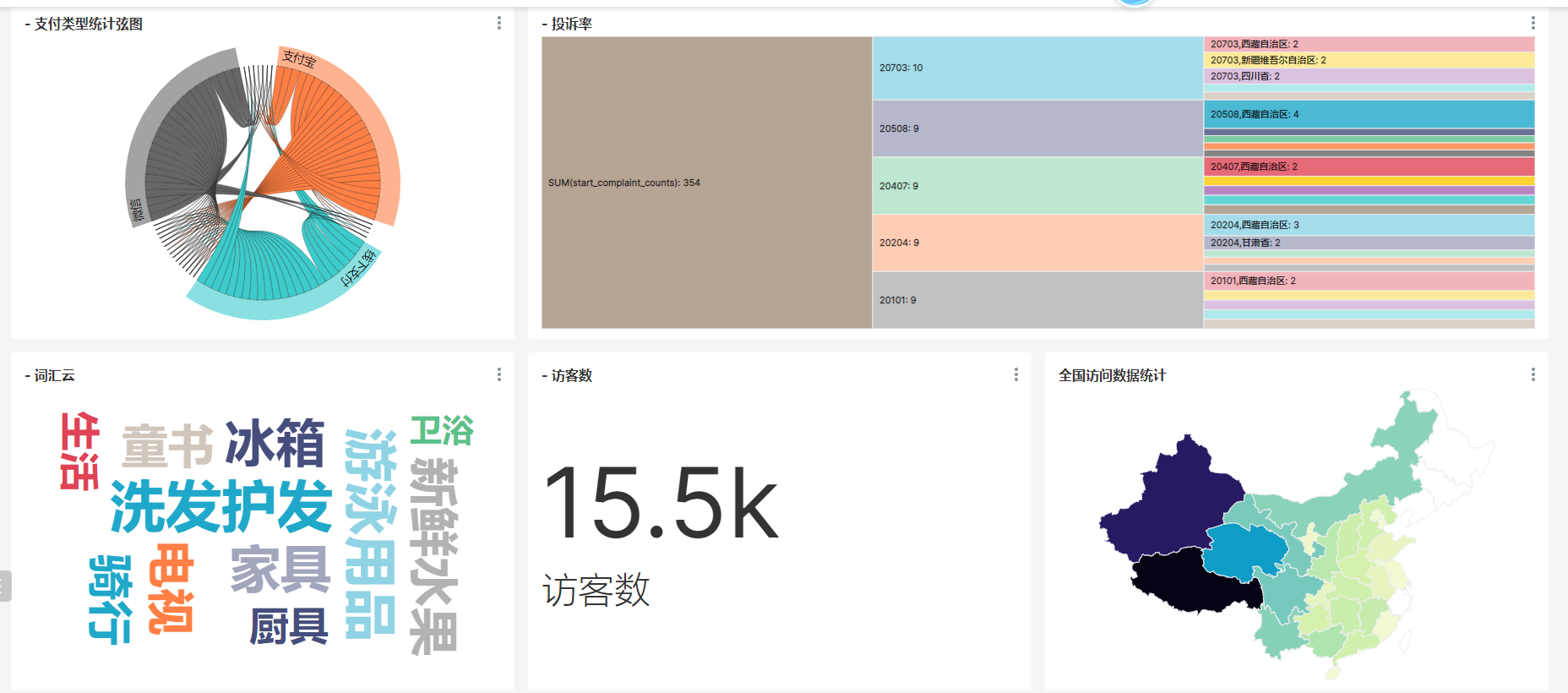
9、使用面板汇总图表


若有收获,就点个赞吧
0 人点赞
