Collection集合
Interface Collection<E> E-此集合中的元素类型
在Java中所有的容器都属于Collection接口的子类,就像异常都属于Throwable的子类一样。
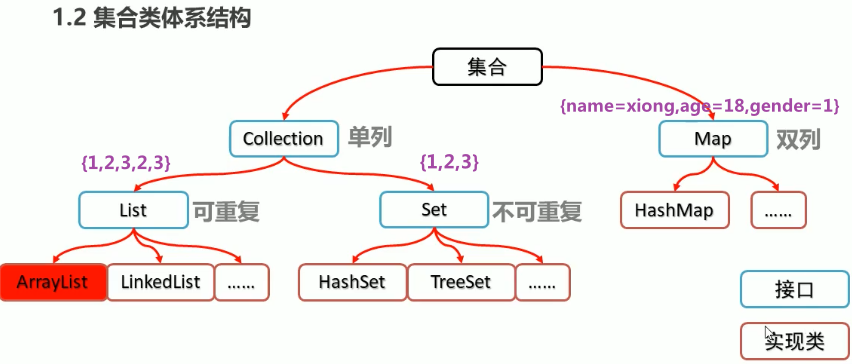
Java标准库自带的java.util包提供了集合接口:Collection,它是除Map外所有其他集合类的根接口。Java的java.util包主要提供了以下三种类型的集合:
List:一种有序列表的集合,例如,按索引排列的Student的List;Set:一种保证没有重复元素的集合,例如,所有无重复名称的Student的Set;Map:一种通过键值(key-value)查找的映射表集合,例如,根据Student的name查找对应Student的Map。
Java集合的设计有几个特点:一是实现了接口和实现类相分离,例如,有序表的接口是List,具体的实现类有ArrayList,LinkedList等。二是支持泛型,我们可以限制在一个集合中只能放入同一种数据类型的元素,例如:
List<String> list = new ArrayList<>(); // 只能放入String类型
最后,Java遍历集合是通过统一的方式——迭代器(Iterator)来实现,它最明显的好处在于无需知道集合内部元素是按什么方式存储的。
由于Java的集合设计非常久远,中间经历过大规模改进;
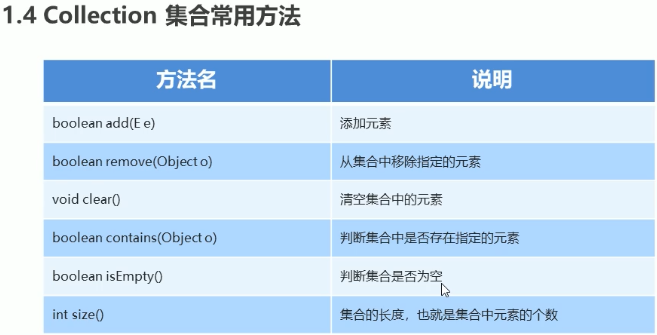
Collection集合常用方法
Collection不能直接实例化,要通过其子类实例,
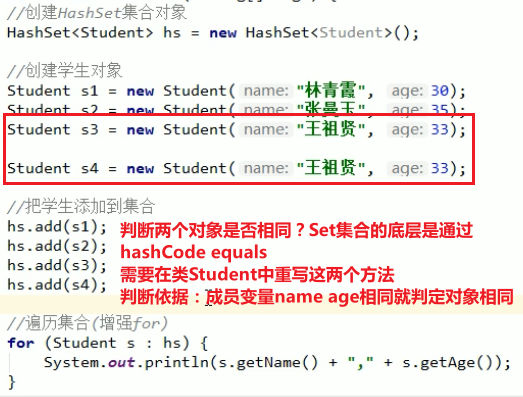
案例:创建学生类并添加到Collection集合中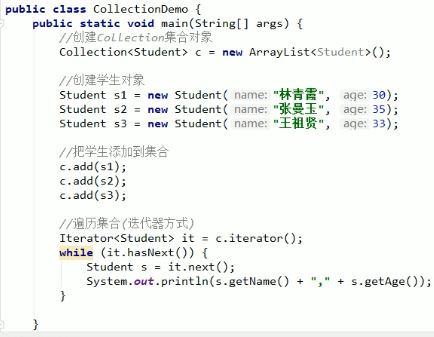
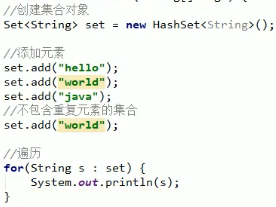
set 集合
Interface Set<E>,Set是一个接口不能直接使用,我们一般使用HashSet或TreeSet
Set集合特点:
- 不包含重复元素;
- 没有索引,不能通过for循环遍历,可以用foreach或Iterator遍历;
哈希值:**
是JDK根据对象的地址或字符串或数字根据哈希算法算出来的int类型数值


哈希表
https://www.bilibili.com/video/BV1si4y1b7Rs?from=search&seid=2727536263524650394
HashSet集合
特点:
- 底层数据结构是哈希表;
- 不保证集合的迭代顺序;
- 此类实现
Set接口,不包含重复元素; - 没有索引,不能通过for循环遍历;
瞎摆->存储的速度快;
继承关系:
java.lang.Objectjava.util.AbstractCollection<E>java.util.AbstractSet<E>java.util.HashSet<E>
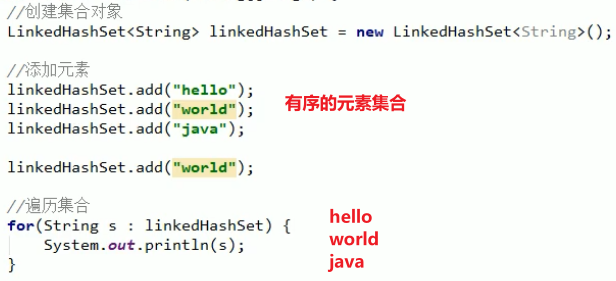
LinkedHashSet
特点:
- Hash表和
Set接口的链表实现,具有可预测的迭代顺序; - 此实现与
HashSet不同之处在于它维护了一个贯穿其所有条目的双向链表, 此链接列表定义迭代排序,即元素插入集合( 插入顺序 ) 的顺序,保证元素有序的;
继承关系:
Class LinkedHashSet<E>java.lang.Objectjava.util.AbstractCollection<E>java.util.AbstractSet<E>java.util.HashSet<E>java.util.LinkedHashSet<E>
TreeSet
按顺序摆->存储的时候帮你排序, 存储的速度就慢;
继承关系:
java.lang.Objectjava.util.AbstractCollection<E>java.util.AbstractSet<E>java.util.TreeSet<E>public class TreeSet<E>extends AbstractSet<E>implements NavigableSet<E>, Cloneable, Serializable//一个NavigableSet实现基于一个TreeMap//元件使用其有序natural ordering ,或由Comparator集合创建时提供,这取决于所使用的构造方法。


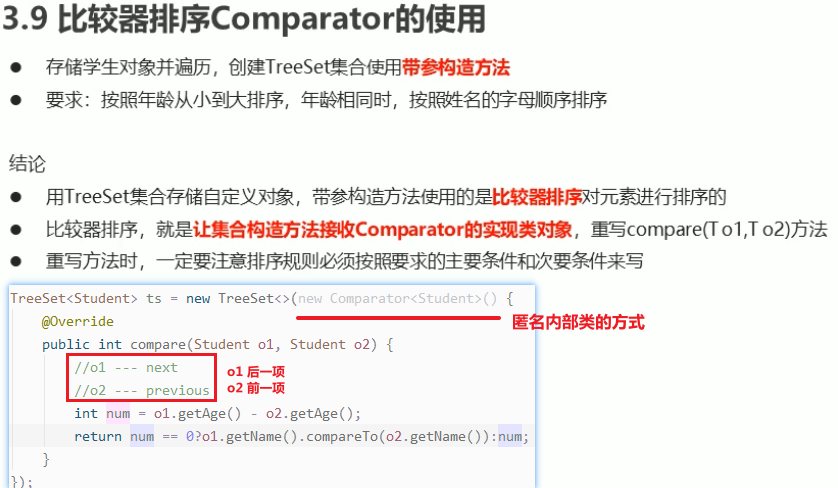
案例:对存储在TreeSet集合中的学生对象按照年龄排序,若年龄相同,则按名字字母排序
- Student类要实现 Comparable接口,重写compareTo方法
此接口对实现它的每个类的对象强加一个总排序。 这种排序被称为类的自然顺序 ,类的
compareTo方法被称为其自然比较方法 。
SetDemo.java
TreeSet<Student> ts = new TreeSet<>();Student s1 = new Student("diaocan", 26);Student s2 = new Student("xisi", 33);Student s3 = new Student("wangzhaojun", 28);Student s4 = new Student("yangguifei", 35);Student s5 = new Student("zhangmanyu", 35);Student s6 = new Student("lingqqingxia", 35);Student s7 = new Student("lingqqingxia", 35);ts.add(s1);ts.add(s2);ts.add(s3);ts.add(s4);ts.add(s5);ts.add(s6);ts.add(s7);for (Student s:ts) {System.out.println("name="+s.getName()+",age="+s.getAge());}
Student.java
public class Student implements Comparable<Student> {private String name;private int age;public Student() { }public Student(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic int compareTo(Student s) {// return 0; //相同,不添加// return 1; //后一个比前一个大,正序// return -1; //后一个比前一个小,倒序int num = this.age - s.age; //this 后一项,s 当前项//如果age相同则比较name 否则直接返回numreturn num==0?this.name.compareTo(s.name):num; //String重写了compareTo方法}}
打印:
name=diaocan,age=26 name=wangzhaojun,age=28 name=xisi,age=33 name=lingqqingxia,age=35 name=yangguifei,age=35 name=zhangmanyu,age=35
总结:
- 自然排序:要在要比较的对象类中实现
_Comparable_并重写compareTo方法; - 比较器排序:在
TreeSet构造方法中定义Comparator实例对象;
案例:
TreeSet<StudentScore> ts = new TreeSet<>(new Comparator<StudentScore>() {@Overridepublic int compare(StudentScore o1, StudentScore o2) {Double ret = o1.scoreSum() - o2.scoreSum();return ret>0?-1:1;}});StudentScore s1 = new StudentScore("zhangsan", 76.5,92.6);StudentScore s2 = new StudentScore("lisi", 79.5,88.9);StudentScore s3 = new StudentScore("wangwu", 91.6,78.6);ts.add(s1);ts.add(s2);ts.add(s3);for (StudentScore ss:ts) {System.out.println(ss.getName()+":"+ss.scoreSum());}//打印结果/*wangwu:170.2zhangsan:169.1lisi:168.4*/
List 列表
两种数据结构:
数组有索引,查询非常快,但是增加删除节点 该位置后面的节点都要移动,效率非常低;
链表是一种增删快的模型(对比数组)
链表是一种查询慢的模型(对比数组),查询每一个元素都要从头开始查
Interface List<E> java.util包public interface ``List<E> ``extendsCollection<E>
List接口特点:
- 有序集合,该接口的用户可以精确控制列表中每个元素的插入位置,用户可以通过整数索引(列表中的位置)访问元素,并搜索列表中的元素;
-
List实例方法
add(obj) 添加元素
- get(i) 查看第i个元素
- size() 查看列表中的数据个数
- isEmpty() 判断是否是空列表
- indexOf(xxx) 查看xxx元素在列表中的位置
- lastIndexOf(xxx) 查看xxx元素在列表中最后一次出现的位置
- contains(xxx) 判断列表中是否包含了xxx
- subList(start. end) 从列表中start开始截取, 截取到end 但不包括end
- toArray() 转化成数组
- remove(obj) 删除某个元素
- remove(i) 删除某个位置的元素
- clear() 清空列表
List lst = new ArrayList();lst.add("美团外卖");lst.add("饿了么");lst.add("百度外卖");lst.add("我不吃");lst.add("外卖");System.out.println(lst); // [美团外卖, 饿了么, 百度外卖, 我不吃, 外卖]System.out.println(lst.get(0)); // 查询第0个元素System.out.println(lst.get(2)); // 查询第2个元素System.out.println(lst.size()); // 列表中元素的个数// 遍历出列表中所有的数据for(int i = 0 ; i < lst.size(); i++){System.out.println(lst.get(i));}// 判断列表是否是空列表System.out.println(lst.isEmpty()); // false//查看"我不吃"元素在列表中的位置System.out.println(lst.indexOf("我不吃")); // 3//查看最后一个"百度外卖"在列表中的位置System.out.println(lst.lastIndexOf("百度外卖")); // 2//判断是否包含饿了么System.out.println(lst.contains("饿了么")); // true//列表的截取, 从1截取到3 [1,3)区间System.out.println(lst.subList(1, 3)); // [饿了么, 百度外卖]// 转化成数组System.out.println(lst.toArray());lst.remove("外卖"); // 删除"外卖"lst.remove(2); // 删除索引为2的元素
ArrayList
List接口的可调整大小的阵列实现,底层数据结构是数组,查询快,增删慢根据异常信息分析源码
描述:一个线程正在迭代List 而另一个线程去修改List(Collection 多态),会抛出ConcurrentModificationException异常
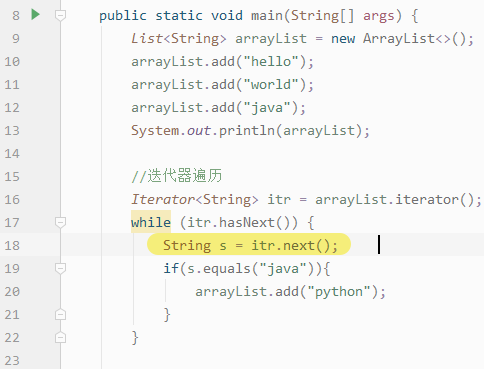
//异常Exception in thread "main" java.util.ConcurrentModificationExceptionat java.base/java.util.ArrayList$Itr.checkForComodification(ArrayList.java:1013)at java.base/java.util.ArrayList$Itr.next(ArrayList.java:967)at com.xjt.myList.ListDemo.main(ListDemo.java:18)
分析源码:
异常信息要从下往上读
1、at com.xjt.myList.ListDemo.main(ListDemo.java:18),在myList.ListDemo.main函数第18行
2、at java.base/java.util.ArrayList$Itr.next(ArrayList.java:967),ArrayList.java中第967行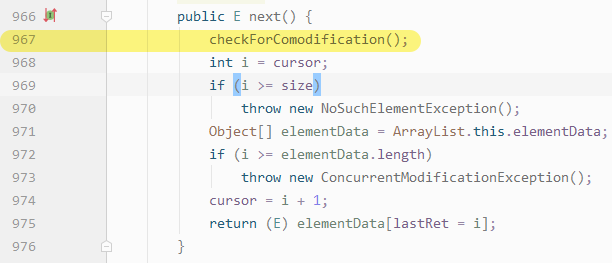
执行
itr.next()方法时,会先去执行checkForComodification``()方法
3、at java.base/java.util.ArrayList$Itr.checkForComodification(ArrayList.java:1013) 在ArrayList.java文件的1013行
判断 modCount != expectedModCount ,如果不相等 抛出 ConcurrentModificationException异常
当执行arrayList.add("python")modCount+1,下次循环进来的时候expectedModCount 和modCount就不相等了。
那么 modCount 和 expectedModCount又是什么东东呢?
我们可以发现在 类Itr 里面定义了: 
ArrayList.java中 Ctrl+F搜索发现modCount没有定义,是直接调用的,所有我们去它父类中找

问题找到了,那么我们怎么在遍历List时改变它的内容呢?
//for循环遍历for (int i = 0; i < arrayList.size(); i++) {if(arrayList.get(i).equals("java")){arrayList.add("python");}}
注意:增强for(foreach)内部其实就是Iterator
通过ArrayList实例的ListIterator实现遍历
ListIterator:列表的迭代器,允许程序员在任一方向上遍历列表,在迭代期间修改列表,并获取迭代器在列表中的当前位置。
ListIterator<String> lit = arrayList.listIterator();while (lit.hasNext()) {String s = lit.next();if (s.equals("java")) {arrayList.add("python");}}
这么多种遍历List方式我们怎么选择呢?
- 只是取List每一项值,不需要修改时,使用foreach最方便
- 需要获取索引值或需要修改List项的值时,选择for循环
ListIterator可以往前遍历往后遍历或从某一项索引开始遍历,且能修改List,使用最灵活Iterator遍历List可以删除/获取List每一项LinkedList
双链表实现了List和Deque接口,底层数据结构是链表,查询慢,增删快public class LinkedList<E> extends AbstractSequentialList<E>implements List<E>, Deque<E>, Cloneable, Serializable
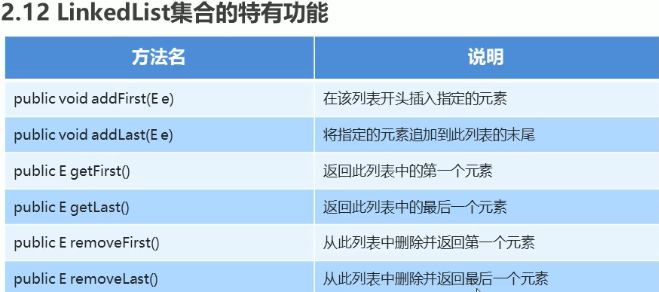
ArrayList和 LinkedList的区别对比:
| 功能 | ArrayList | LinkedList |
|---|---|---|
| 获取指定元素 | 速度很快 | 需要从头开始查找元素,慢 |
| 添加元素到末尾 | 速度很快 | 速度很快 |
| 在指定位置添加/删除 | 该位置后面的所有元素都要移动 | 不需要移动元素 |
| 内存占用 | 少 | 较大 |
ArrayList的优势是查询;
LinkedList的优势是删除和添加;
List.of()创建列表
除了使用ArrayList和LinkedList,我们还可以通过List接口提供的of()方法,根据给定元素快速创建List:
List<Integer> list = List.of(1, 2, 5);
但是List.of()方法不接受null值,如果传入null,会抛出NullPointerException异常。
Map 集合

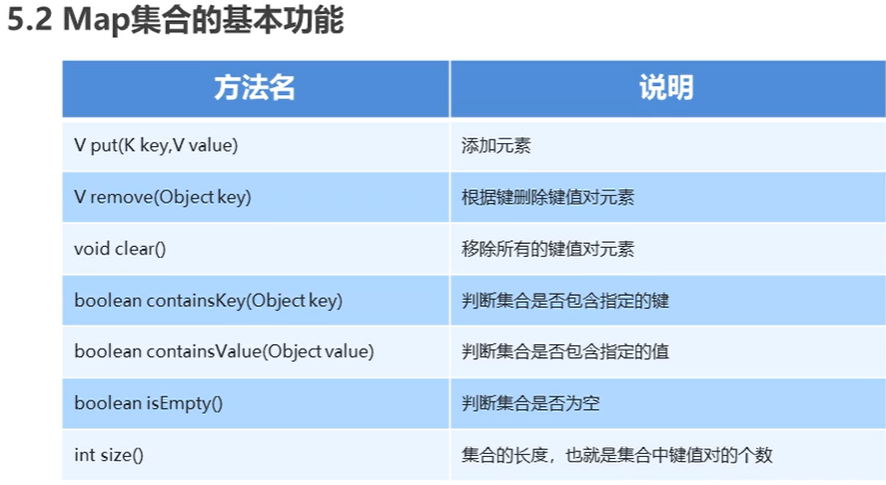
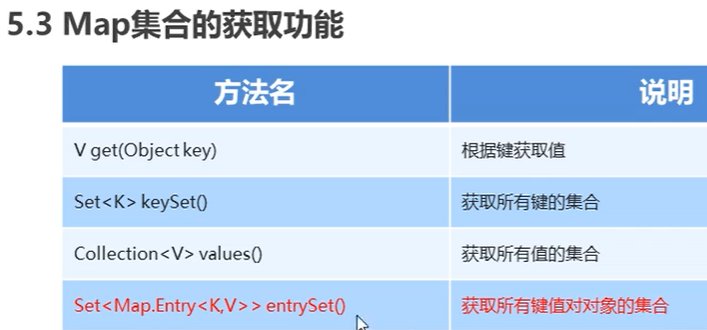
Map实例的基本方法
- put(key,value) 向映射中添加一个键值对,相同的key会把前面保存的数据顶掉;
- get(key) 使用key查询value;
- isEmpty() 判断Map是否是空的;
- size() 返回key, value键值对的个数;
- containsKey(key) 判断是否存在key 返回布尔值;
- containsValue(Object value) 判断映射中是否包含值==value 返回布尔值
- remove(key) 根据key删除信息;
- keySet() 获取到map中key的集合set;
- map.values() 获取到map中所有value值;
- map1.equals(map2) 判断两个Set集合的元素是否相同;
用法示例:
//map实例化Map<String,String> map = new HashMap<>();////基本方法//添加元素map.put("name","xiong");map.put("gender","男");Map<String,String> map2 = new HashMap<>();map2.put("2", "B");map2.put("3", "C");map.putAll(map2); //把一个map集合合并到另一个map集合里System.out.println(map);//修改元素map.remove("2","2B");//删除元素map.remove("3");//查询元素System.out.println("name="+map.get("name"));//获取集合大小System.out.println(map.size());//获取集合所有值/所有键System.out.println(map.keySet()); //所有键System.out.println(map.values()); //所有值//清空集合//map.clear();//获得map中一组组键值对的集合System.out.println(map.entrySet()); //[2=B, gender=男, name=xiong]//原始方式遍历for (Map.Entry<String,String> entry:map.entrySet()){System.out.println("key:"+entry.getKey()+";value:"+entry.getValue());}//map的forEach方式(java8新特性)map.forEach((k,v) ->System.out.println("key:"+k+";value:"+v));//迭代器方式遍历System.out.println(map); //{2=B, gender=男, name=xiong}System.out.println(map.entrySet()); //[2=B, gender=男, name=xiong]Iterator it = map.entrySet().iterator(); // 拿到map内部的entry,逗号分隔的每一项都是一个entrywhile(it.hasNext()){Map.Entry entry = (Map.Entry) it.next();System.out.println(entry.getKey()+"=>"+entry.getValue());}


示例: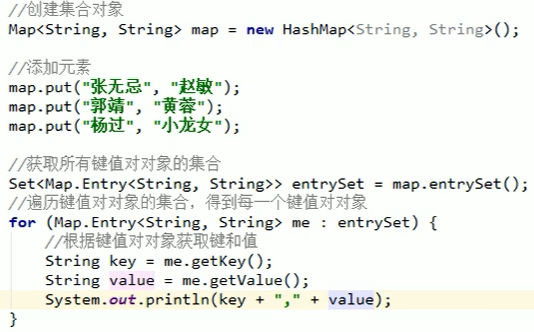
示例2:
示例3:
示例4:
ArrayList<HashMap<String, String>> arrayList = new ArrayList<>();HashMap<String, String> hm1 = new HashMap<>();hm1.put("令狐冲","任盈盈");hm1.put("岳不群","宁中则");hm1.put("林平之","岳灵珊");arrayList.add(hm1);HashMap<String, String> hm2 = new HashMap<>();hm2.put("杨过","小龙女");hm2.put("郭靖","黄蓉");arrayList.add(hm2);HashMap<String, String> hm3 = new HashMap<>();hm3.put("张无忌","赵敏");hm3.put("宋青书","周芷若");hm3.put("张无忌","小昭");arrayList.add(hm3);for (HashMap<String, String> hm:arrayList) {//Set<String> keys = hm.keySet();//for (String key:keys) {//System.out.println(key+"="+hm.get(key));//}//HashSet集合的第二种遍历方法Set<Map.Entry<String, String>> entries = hm.entrySet();for (Map.Entry<String, String> entry:entries) {String key = entry.getKey();String val = entry.getValue();System.out.println(key+"="+val);}}
示例5:
HashMap<String, ArrayList<String>> stringArrayListHashMap = new HashMap<>();ArrayList<String> arr1 = new ArrayList<>();arr1.add("张无忌");arr1.add("赵敏");arr1.add("小昭");arr1.add("周芷若");stringArrayListHashMap.put("倚天屠龙记",arr1);ArrayList<String> arr2 = new ArrayList<>();arr2.add("杨过");arr2.add("小龙女");arr2.add("李莫愁");arr2.add("金轮法王");stringArrayListHashMap.put("神雕侠侣",arr2);ArrayList<String> arr3 = new ArrayList<>();arr3.add("郭靖");arr3.add("黄蓉");arr3.add("杨康");arr3.add("穆念慈");arr3.add("欧阳克");stringArrayListHashMap.put("射雕英雄传",arr3);Set<Map.Entry<String, ArrayList<String>>> entries = stringArrayListHashMap.entrySet();for (Map.Entry<String, ArrayList<String>> entry:entries) {String key = entry.getKey();ArrayList<String> values = entry.getValue();System.out.println(key+":");for (String value:values) {System.out.println("\t"+value);}}
示例6:
HashMap<Character, Integer> hm = new HashMap<>();System.out.println("请输入一串字符:");Scanner sc = new Scanner(System.in);String line = sc.nextLine();for (int i = 0; i < line.length(); i++) {char key = line.charAt(i);Integer value = hm.get(key);if(value == null){hm.put(key,1);}else{value++;hm.put(key,value);}}StringBuilder sb = new StringBuilder();Set<Map.Entry<Character, Integer>> entries = hm.entrySet();for (Map.Entry<Character, Integer> entry:entries) {Character key = entry.getKey();Integer value = entry.getValue();sb.append(key).append("(").append(value).append(")");}System.out.println(sb.toString());
Collections工具类

Collections.sort()
Collections.reverse()
Collections.shuffle()
这些都是静态方法,通过类Collections直接调用
示例:
示例:用Collection.sort()方法对学生年龄排序,若年龄相同按学生姓名排序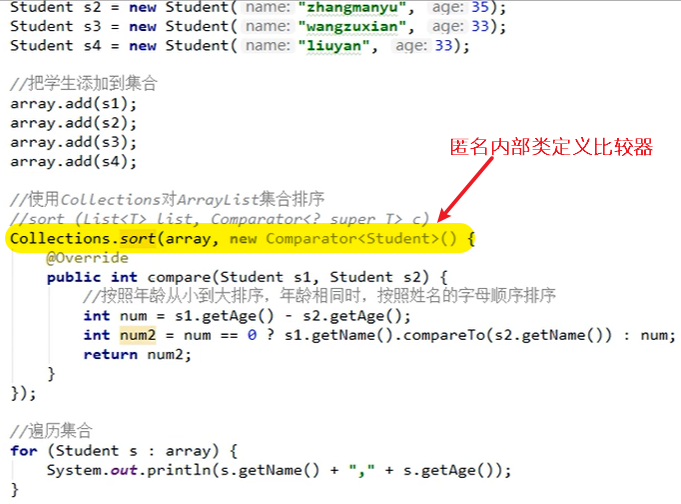
案例:模拟斗地主
public static void main(String[] args) {//1.创建一副牌//♦ 3 4 5 6 7 8 9 10 J Q K A 2//♣ 3 4 5 6 7 8 9 10 J Q K A 2//♥ 3 4 5 6 7 8 9 10 J Q K A 2//♠ 3 4 5 6 7 8 9 10 J Q K A 2List<String> pokerList = new ArrayList<>();//1.1创建花色和数字列表String[] colors = {"♦","♣","♥","♠"};String[] nums = {"3","4", "5", "6", "7", "8", "9", "10", "J", "Q", "K", "A", "2"};for (String color:colors) {for (String num:nums) {pokerList.add(color+num);}}pokerList.add("大王");pokerList.add("小王");//1.2洗牌Collections.shuffle(pokerList);System.out.println(pokerList);//2.创建3个玩家列表和一个底牌列表ArrayList<String> playerAList = new ArrayList<>();ArrayList<String> playerBList = new ArrayList<>();ArrayList<String> playerCList = new ArrayList<>();ArrayList<String> dipaiList = new ArrayList<>();//3.发牌for (int i = 0; i < pokerList.size(); i++) {if(i>=pokerList.size()-3){dipaiList.add(pokerList.get(i));}else if(i%3 == 0){playerAList.add(pokerList.get(i));}else if(i%3 == 1){playerBList.add(pokerList.get(i));}else if(i%3 == 2){playerCList.add(pokerList.get(i));}}//4.三位玩家看牌,并亮出底牌showPocker("张三丰",playerAList);showPocker("张无忌",playerBList);showPocker("张翠山",playerCList);showPocker("底牌",dipaiList);}public static void showPocker(String name, ArrayList<String> array){System.out.println("玩家-"+name+"手里的牌是:");for (String pocker:array) {System.out.print(pocker+" "); //System.out.println()这个是在输出内容之后换行,而 System.out.print()输出内容之后不换行}System.out.println(); //空行}
打印:
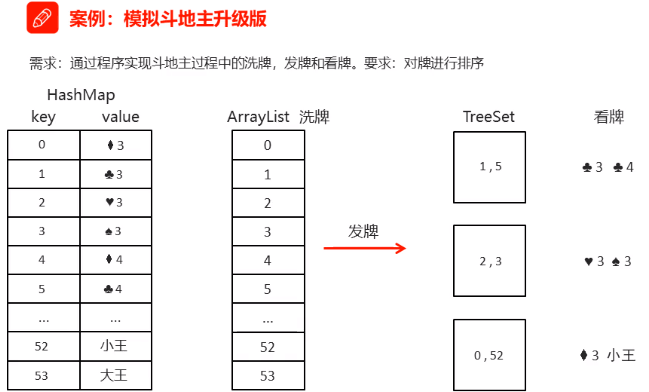

public static void main(String[] args) {//1.创建一副牌//♦ 3 4 5 6 7 8 9 10 J Q K A 2//♣ 3 4 5 6 7 8 9 10 J Q K A 2//♥ 3 4 5 6 7 8 9 10 J Q K A 2//♠ 3 4 5 6 7 8 9 10 J Q K A 2//1.1HashMap键值0 1 2 3 ...52 值对应的牌♦3 ♦4...HashMap<Integer, String> pockerHM = new HashMap<>();ArrayList<Integer> array = new ArrayList<>(); //存储牌的键值Integer index = 0;//1.1创建花色和数字列表String[] colors = {"♦","♣","♥","♠"};String[] nums = {"3","4", "5", "6", "7", "8", "9", "10", "J", "Q", "K", "A", "2"};for (String color:colors) {for (String num:nums) {array.add(index);pockerHM.put(index,color+num);index++;}}array.add(index);pockerHM.put(index,"大王");index++;array.add(index);pockerHM.put(index,"小王");//1.2洗牌Collections.shuffle(array);// System.out.println(array);// System.out.println(pockerHM);//2.创建3个玩家列表和一个底牌列表(存储的HashMap键值)TreeSet<Integer> playerATreeSet = new TreeSet<>();TreeSet<Integer> playerBTreeSet = new TreeSet<>();TreeSet<Integer> playerCTreeSet = new TreeSet<>();TreeSet<Integer> dipaiTreeSet = new TreeSet<>();//3.发牌for (int i = 0; i < pockerHM.size(); i++) {Integer idx = array.get(i);if(i>=pockerHM.size()-3){dipaiTreeSet.add(idx);}else if(i%3 == 0){playerATreeSet.add(idx);}else if(i%3 == 1){playerBTreeSet.add(idx);}else if(i%3 == 2){playerCTreeSet.add(idx);}}//4.三位玩家看牌,并亮出底牌showPocker("张三丰",playerATreeSet,pockerHM);showPocker("张无忌",playerBTreeSet,pockerHM);showPocker("张翠山",playerCTreeSet,pockerHM);showPocker("底牌",dipaiTreeSet,pockerHM);}public static void showPocker(String name, TreeSet<Integer> array,HashMap<Integer,String> playerHashMap){System.out.println(name+"手里的牌是:");for (Integer i:array) {System.out.print(playerHashMap.get(i)+" "); //System.out.println()这个是在输出内容之后换行,而 System.out.print()输出内容之后不换行}System.out.println(); //空行}
打印:
作业:
有字符串”k:1,k1:2,k2:3,k3:4” 处理成Map: {‘k’=1,’k1’=2….}
package com.xjt.homework;import java.util.HashMap;import java.util.Map;public class Work1 {public static void main(String[] args) {/*1. 有字符串”k:1,k1:2,k2:3,k3:4” 处理成Map: {‘k’=1,’k1’=2….}*/String str = "k:1,k1:2,k2:3,k3:4";Map<String,Integer> mymap = new HashMap<String,Integer>();String[] lst = str.split(",");for (String item:lst) {String StrKey = item.split(":")[0];String StrValue = item.split(":")[1];mymap.put(StrKey,Integer.parseInt(StrValue));}System.out.println(mymap);}}
元素分类, 有如下值 int[] li= {11,22,33,44,55,66,77,88,99,90},将所有大于 等于66 的值保存至Map的第一个key中,将小于 66 的值保存至第二个key的值中。
即: {‘k1’: 大于66的所有值列表, ‘k2’: 小于66的所有值列表}package com.xjt.homework;import java.util.*;public class Work2 {public static void main(String[] args) {int[] li= {11,22,33,44,55,66,77,88,99,90};//定义一个有泛型映射Map<String, List<Integer>> map = new HashMap<String,List<Integer>>();//定义两个有泛型的列表List<Integer> lst1 = new ArrayList<>();List<Integer> lst2 = new ArrayList<>();for (Integer item:li) {if(item>=66){lst1.add(item);}else{lst2.add(item);}}map.put("k1",lst1);map.put("k2",lst2);System.out.println(map); //{k1=[66, 77, 88, 99, 90], k2=[11, 22, 33, 44, 55]}}}
作业参考答案:

给定一组连续的整数,例如:10,11,12,……,20,但其中缺失一个数字,试找出缺失的数字:
package com.xjt.homework;import java.util.ArrayList;import java.util.Collections;import java.util.List;public class Test1 {static int findMissingNumber(int start, int end, List<Integer> list) {int ret=0;for (int i = start; i <= end; i++) {if (!list.contains(i)) {ret = i;}}return ret;}public static void main(String[] args) {// 构造从start到end的序列:final int start = 10;final int end = 20;List<Integer> list = new ArrayList<>();for (int i = start; i <= end; i++) {list.add(i);}// 洗牌算法shuffle可以随机交换List中的元素位置:Collections.shuffle(list);// 随机删除List中的一个元素:int removed = list.remove((int) (Math.random() * list.size()));int found = findMissingNumber(start, end, list);System.out.println(list.toString());System.out.println("missing number: " + found);System.out.println(removed == found ? "测试成功" : "测试失败");}}
Iterator 迭代器
我们可以使用get() size() 搭配for循环来完成遍历,但是想一个问题. set好像没有get()方法. 那set集合怎么遍历啊….这就要用到咱们本节课讲的这个叫Iterator的东西. 这个东西叫迭代器。
啥是迭代器. 想一个事儿. 我们村以前有那种乡村诊所. 病人来了之后呢就在门口一站. 然后大夫在诊治的时候会喊一嗓子~ 下一个. 下一个人就进来了. 大夫不关心外面多少人, 也不关心外面的病人是谁. 他只关心”下一个”. OK. 咱们今天要说的这个叫迭代器的东西, 和乡村诊所里的大夫是一样一样的~~.
先看用法:
Set set = new HashSet();set.add("王大锤");set.add("二麻子");set.add("三愣子");set.add("哈利路呀大大大锤");// 创建迭代器对象, 相当于创建一个医生Iterator it = set.iterator();// 吼一嗓子, 进来一个人String s1 = (String) it.next();System.out.println(s1);// 吼一嗓子, 进来一个人String s2 = (String) it.next();System.out.println(s2);// 吼一嗓子, 进来一个人String s3 = (String) it.next();System.out.println(s3);// 吼一嗓子, 进来一个人String s4 = (String) it.next();System.out.println(s4);// 没人了. 还吼, 吼破了喉咙也不会有人理你的. 报错String s5 = (String) it.next(); //Exception in thread "main" java.util.NoSuchElementExceptionSystem.out.println(s5);
next() 会自动帮我们获取到元素,并且指针指向下一个元素。
但是呢,这时候我们发现迭代器, 太容易出错了,我也不知道啥时候还有没有元素了。怎么解决呢? 在next()之前, 我们可以做一个判断, 判断是否还有下一个元素。
set集合使用迭代器遍历
Set set = new HashSet();set.add("王大锤");set.add("王小锤");set.add("王不大不小锤");set.add("哈利路呀大大大锤");// 拿到迭代器, 相当于创建一个医生Iterator it = set.iterator(); //集合迭代器while(it.hasNext()){ // 判断是否还有下一个元素String s = (String) it.next();System.out.println(s);}
List使用迭代器遍历
package com.xyq.collection;import java.util.*;public class TestIter {public static void main(String[] args) {List list = new ArrayList();list.add("武大郎");list.add("武二郎");list.add("武三郎");Iterator it = list.iterator(); //列表迭代器while(it.hasNext()){System.out.println(it.next());}}}
Map使用迭代器进行遍历
Map map = new HashMap();map.put("浪里白条", "张顺");map.put("及时雨", "松江");map.put("行者", "悟空");Iterator it = map.keySet().iterator(); //map映射迭代器,要对map映射的所有键进行迭代while(it.hasNext()){Object key = it.next();Object value = map.get(key); // 通过key获取到valueSystem.out.println(key+"=>"+value);}
Map集合还可以这样遍历.
Map map = new HashMap();map.put("浪里白条", "张顺");map.put("及时雨", "松江");map.put("行者", "悟空");Iterator it = map.entrySet().iterator(); // 拿到map内部的entry,逗号分隔的每一项都是一个entrywhile(it.hasNext()){Map.Entry entry = (Map.Entry) it.next();System.out.println(entry.getKey()+"=>"+entry.getValue());}
迭代器存在的意义:
一是可以让不同的数据类型拥有相同的遍历方式,List, Set, Map,完全不同的三种数据类型,但是都可以使用Iterator进行遍历;
二是:使用迭代器遍历比for循环遍历效率要高;
1.for each == iterator
有童鞋可能觉得使用Iterator访问List的代码比使用索引更复杂。但是,要记住,通过Iterator遍历List永远是最高效的方式。并且,由于Iterator遍历是如此常用,所以,Java的for each循环本身就可以帮我们使用Iterator遍历。把上面的代码再改写如下:
List<String> list = List.of("apple", "pear", "banana");for (String s : list) {System.out.println(s);}
上述代码就是我们编写遍历List的常见代码。
实际上,只要实现了Iterable接口的集合类都可以直接用for each循环来遍历,Java编译器本身并不知道如何遍历集合对象,但它会自动把for each循环变成Iterator的调用,原因就在于Iterable接口定义了一个Iterator iterator()方法,强迫集合类必须返回一个Iterator实例。
2.List和Array转换
把List变为Array有三种方法,第一种是调用toArray()方法直接返回一个Object[]数组:
List<String> list = List.of("apple", "pear", "banana");Object[] array = list.toArray();for (Object s : array) {System.out.println(s);}
这种方法会丢失类型信息,所以实际应用很少。
第二种方式是给toArray(T[])传入一个类型相同的Array,List内部自动把元素复制到传入的Array中:
List<Integer> list = List.of(12, 34, 56);Integer[] array = list.toArray(new Integer[3]);for (Integer n : array) {System.out.println(n);}
注意到这个toArray(T[])方法的泛型参数并不是List接口定义的泛型参数,所以,我们实际上可以传入其他类型的数组,例如我们传入Number类型的数组,返回的仍然是Number类型:
List<Integer> list = List.of(12, 34, 56);Number[] array = list.toArray(new Number[3]);for (Number n : array) {System.out.println(n);}
但是,如果我们传入类型不匹配的数组,例如,String[]类型的数组,由于List的元素是Integer,所以无法放入String数组,这个方法会抛出ArrayStoreException。
如果我们传入的数组大小和List实际的元素个数不一致怎么办?根据List接口)的文档,我们可以知道:
如果传入的数组不够大,那么List内部会创建一个新的刚好够大的数组,填充后返回;如果传入的数组比List元素还要多,那么填充完元素后,剩下的数组元素一律填充null。
实际上,最常用的是传入一个“恰好”大小的数组:
Integer[] array = list.toArray(new Integer[list.size()]);
最后一种更简洁的写法是通过List接口定义的T[] toArray(IntFunction generator)方法:
Integer[] array = list.toArray(Integer[]::new);
这种函数式写法我们会在后续讲到。
反过来,把Array变为List就简单多了,通过List.of(T...)方法最简单:
Integer[] array = { 1, 2, 3 };List<Integer> list = List.of(array);
对于JDK 11之前的版本,可以使用Arrays.asList(T...)方法把数组转换成List。
要注意的是,返回的List不一定就是ArrayList或者LinkedList,因为List只是一个接口,如果我们调用List.of(),它返回的是一个只读List:
List<Integer> list = List.of(12, 34, 56); //返回一个只读的Listlist.add(999); // UnsupportedOperationException
对只读List调用add()、remove()方法会抛出UnsupportedOperationException。
泛型
泛型概述
前面我们说了三种容器. 这三种容器有一个共同的特点, 就是所有存放在容器中的内容最终都被当成了Object来保存。当前, 我们能理解为了通用性把所有的元素向上转型成Object。
但是这样存储是有问题的。比如,酱油瓶里就应该装酱油,醋瓶就应该装醋。混着装不是不能装,是不能用 对吧。所以呢,我们要对容器进行规范,不能乱七八糟的乱装,这就需要用到泛型。通过泛型可以强制规定容器能装什么东西。就好比,给你家里的瓶瓶罐罐贴上标签来说明这个瓶子是用来装什么的。
规范集合存储数据类型,取数据时不需要强转了,在以后的代码中, 如果没有特殊要求,推荐使用泛型

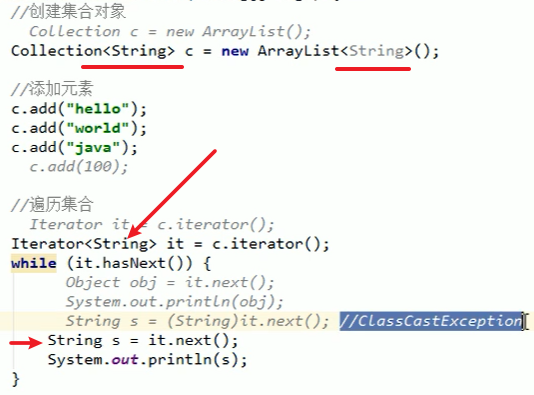
List<String> list = new ArrayList<String>(); // 强制规定这个列表只能装字符串,第二个尖括号里面的String可以省略// list.add(1);// 报错. 只能装字符串list.add("NB"); // OK// 好处是, 从list中获取到的数据不需要强转了.String s = list.get(0) ;// 这个列表只能装字符串, 拿出来也一定是字符串System.out.println(s);
创建一个只能装歌手的列表(自定义泛型类)
package com.xjt.fanxing;import java.util.ArrayList;import java.util.List;public class Test1 {public static void main(String[] args) {List<Singer> singerList = new ArrayList<Singer>(); // 只能装歌手类型Singer singer1 = new Singer("周杰伦",45);singerList.add(singer1); // 添加歌手Singer singer2 = new Singer("王菲",50);singerList.add(singer2); // 添加歌手Singer ss = singerList.get(0); // 查询歌手System.out.println(ss);}}class Singer{String name;int age;@Overridepublic String toString() {return "Singer{" +"name='" + name + '\'' +", age=" + age +'}';}public Singer(String name, Integer age) {this.name = name;this.age = age;}}
Set集合和List的泛型是一样的,强制规定集合中元素的类型
Set<String> set = new HashSet<>();set.add("apple");set.add("banana");set.add("pear");set.add("orange");for (String s : set) {System.out.println(s);}List<String> list = new ArrayList<>();list.add("apple"); // size=1list.add("pear"); // size=2list.add("apple"); // 允许重复添加元素,size=3System.out.println(list.size());
Map集合的泛型比较特殊. 因为这个鬼东西里面有key和value.两项内容.
Map<String, String> map = new HashMap<String, String>();map.put("萝莉", "小蔡");map.put("御姐", "苏打强");// map.put(1, 2) ; // 报错, 只能是字符串String v = map.get("萝莉");System.out.println(v);
定义泛型类

泛型方法
- 在调用该方法时决定传入什么类型参数

public class GenericDemo1 {public static void main(String[] args) {//调用普通方法Generic g1 = new Generic();g1.show("hello");g1.show(111);g1.show(true);//泛型类的方法调用Generic2<String> g21 = new Generic2<String>();g21.show("hello");Generic2<Integer> g22 = new Generic2<Integer>();g22.show(123);Generic2<Boolean> g23 = new Generic2<Boolean>();g23.show(true);//泛型方法调用(终极版)Generic3 g3 = new Generic3();g3.show("hello");g3.show(111);g3.show(true);g3.show(12.34);}}class Generic{//普通方法public void show(String s){System.out.println(s);}public void show(Integer s){System.out.println(s);}public void show(Boolean s){System.out.println(s);}}//泛型类改进class Generic2<T>{public void show(T t){System.out.println(t);}}//泛型方法改进class Generic3{public <T> void show(T t){System.out.println(t);}}
泛型接口


具体可参考Collection接口及其实现类 ArrayList
Interface Collection<E> //接口定义的是泛型public interface List<E> //List接口继承的仍然是泛型extends Collection<E>public class ArrayList<E> //最终实现类extends AbstractList<E>implements List<E>, RandomAccess, Cloneable, Serializable//方法仍然是泛型void add(int index, E element) //将指定元素插入此列表中的指定位置。boolean add(E e) //将指定的元素追加到此列表的末尾。
类型通配符


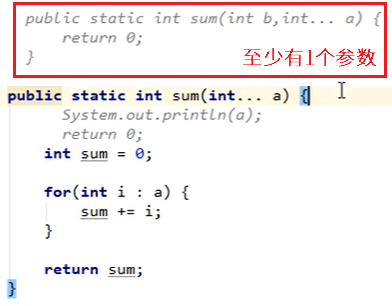
可变参数

第一个确定的参数必须放置前面,后面不确定个数的参数封装到a集合里了
可变参数的使用



若有收获,就点个赞吧
0 人点赞
