模型层(ORM语法):跟数据库打交道的
补充知识
# django自带的sqlite3数据库对日期格式不是很敏感 处理的时候容易出错
测试脚本创建
"""当你只是想测试django中的某一个py文件内容 那么你可以不用书写前后端交互的形式而是直接写一个测试脚本即可脚本代码无论是写在应用下的tests.py还是自己单独开设py文件都可以"""# 测试环境的准备 去manage.py中拷贝前四行代码 然后自己再写两行import osimport sysif __name__ == "__main__":os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day64.settings")import djangodjango.setup()# 在这个代码块的下面就可以测试django里面的单个py文件了
实例:
test.py
import osif __name__ == "__main__":os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day64.settings")import djangodjango.setup()# 所有的代码都必须等待环境准备完毕之后才能书写from app01 import models # 注意这行导入不能放在main上面导入,一定要在django.setup()下方写,因为要等上面测试环境完成models.User.objects.all()
单表操作
环境准备:
数据库

单表操作数据增删改查示例
models.py
from django.db import models# Create your models here.class User(models.Model):name = models.CharField(max_length=32)age = models.IntegerField()register_time = models.DateField() # 日期字段,表示年月日,models.DateTimeField()表示年月日,时分秒"""针对DateField()和DateTimeField()两个重要参数:auto_now=True:每次操作数据的时候,该字段会自动将当前时间更新auto_now_add=True:在创建数据的时候,会自动将当前创建时间记录下来,之后只要不人为的修改,那么就一直不变"""def __str__(self):return self.name
test.py
from django.test import TestCase# Create your tests here.import osif __name__ == "__main__":os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day64.settings")import djangodjango.setup()from app01 import models# 单表操作# 增# 方法一:# res = models.User.objects.create(name="jason",age=18,register_time="2020-5-29")# print(res) # 返回值是创建对象本身# 方法二:# import datetime# ctime = datetime.datetime.now()# user_obj = models.User(name="egon",age=99,register_time=ctime) # 日期格式还支持直接传日期对象# user_obj.save()# 删# 方法一:# res = models.User.objects.filter(pk=2).delete()# print(res) # 返回值是当前命令所影响的行数# 补充,以前是用id来取,这里pk会自动查找到当前表的主键字段,指代的就是当前表的主键,用了pk之后,就不需要知道当前表的主键字段到底叫什么## 方法二:# user_obj = models.User.objects.filter(pk=1).first()# user_obj.delete()# 修改# 方法一:# models.User.objects.filter(pk=1).update(age=22)## 方法二:user_obj = models.User.objects.filter(pk=2).first()user_obj.age = 66user_obj.save()#"""ps:user_obj = models.User.objects.get(pk=4)get方法返回的直接就是当前数据对象但是该方法不推荐使用一旦数据不存在该方法会直接报错而filter则不会所以我们还是用filter"""
单表操作必知必会13条:
test.py
from django.test import TestCase# Create your tests here.import osif __name__ == "__main__":os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day64.settings")import djangodjango.setup()from app01 import models# 必知必会13条# 1.all() 查询所有数据# 2.filter() 带有过滤条件的查询# 3.get() 直接拿数据对象 但是条件不存在直接报错# 4.first() 拿queryset里面第一个元素# res = models.User.objects.all().first()# print(res)# 5.last()# res = models.User.objects.all().last()# print(res)# 6.values() 可以指定获取的数据字段 类似数据库select name,age from User;语句 列表套字典# res = models.User.objects.values('name','age') # <QuerySet [{'name': 'jason', 'age': 18}, {'name': 'egonPPP', 'age': 84}]># print(res)# 7.values_list() 列表套元祖res = models.User.objects.values_list('name','age') # <QuerySet [('jason', 18), ('egonPPP', 84)]>print(res)"""res = models.User.objects.values_list('name','age') # <QuerySet [('jason', 18), ('egonPPP', 84)]>print(res.query) # SELECT `app01_user`.`name`, `app01_user`.`age` FROM `app01_user`# 查看内部封装的sql语句上述查看sql语句的方式 只能用于queryset对象只有queryset对象才能够点击query查看内部的sql语句"""# 8.distinct() 去重# res = models.User.objects.values('name','age').distinct()# print(res)"""去重一定要是一模一样的数据如果带有主键那么肯定不一样 你在往后的查询中一定不要忽略主键"""# 9.order_by()# res = models.User.objects.order_by('age') # 默认升序# res = models.User.objects.order_by('-age') # 降序## print(res)# 10.reverse() 反转的前提是 数据已经排过序了 order_by()# res = models.User.objects.all()# res1 = models.User.objects.order_by('age').reverse()# print(res,res1)# 11.count() 统计当前数据的个数# res = models.User.objects.count()# print(res)# 12.exclude() 排除在外# res = models.User.objects.exclude(name='jason')# print(res)# 13.exists() 基本用不到因为数据本身就自带布尔值 返回的是布尔值# res = models.User.objects.filter(pk=10).exists()# print(res)
补充:查看内部sql语句的方法
# 方式1res = models.User.objects.values_list('name','age') # <QuerySet [('jason', 18), ('egonPPP', 84)]>print(res.query)queryset对象才能够点击query查看内部的sql语句# 方式2:所有的sql语句都能查看# 去配置文件中配置一下即可LOGGING = {'version': 1,'disable_existing_loggers': False,'handlers': {'console':{'level':'DEBUG','class':'logging.StreamHandler',},},'loggers': {'django.db.backends': {'handlers': ['console'],'propagate': True,'level':'DEBUG',},}}
神奇的双下划线查询
from django.test import TestCase# Create your tests here.import osif __name__ == "__main__":os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day64.settings")import djangodjango.setup()from app01 import models# 神奇的双下划线查询# 练习题# 1、年龄大于35岁的数据# res = models.User.objects.filter(age__gt=35)# print(res)# 2、 年龄小于35岁的数据# res = models.User.objects.filter(age__lt=35)# print(res)# 大于等于 小于等于# res = models.User.objects.filter(age__gte=32)# print(res)# res = models.User.objects.filter(age__lte=32)# print(res)# 年龄是18 或者 32 或者40# res = models.User.objects.filter(age__in=[18,32,40])# print(res)# 年龄在18到40岁之间的 首尾都要# res = models.User.objects.filter(age__range=[18,40])# print(res)# 查询出名字里面含有s的数据 模糊查询 ps:默认区分大小写# res = models.User.objects.filter(name__contains='s')# print(res)## 查询出名字里面含有p的数据 默认区分大小写# res = models.User.objects.filter(name__contains='p')# print(res)# 忽略大小写# res = models.User.objects.filter(name__icontains='p')# print(res)# res = models.User.objects.filter(name__startswith='j')# res1 = models.User.objects.filter(name__endswith='j')## print(res,res1)# 查询出注册时间是1月的(按月份找)# res = models.User.objects.filter(register_time__month='1')# 查询出注册时间是2020年的(按年份找)# res = models.User.objects.filter(register_time__year='2020')# 查询出注册时间是29号的(按日找)res = models.User.objects.filter(register_time__day="29")print(res)
多表操作
以图书管理系统为例:
环境:
models.py
from django.db import models# Create your models here.class Book(models.Model):title = models.CharField(max_length=32)price = models.DecimalField(max_digits=8,decimal_places=2)publish_date = models.DateField(auto_now_add=True)# 一对多publish = models.ForeignKey(to="Publish")# 多对多authors = models.ManyToManyField(to="Author")class Publish(models.Model):name = models.CharField(max_length=32)addr = models.CharField(max_length=64)email = models.EmailField()# varchar(254) 该字段不是给models看的,而是给后面我们会学到的校验型组件看的class Author(models.Model):name = models.CharField(max_length=32)age = models.IntegerField()# 一对一author_detail = models.OneToOneField(to="AuthorDetail")class AuthorDetail(models.Model):phone = models.BigIntegerField() # 电话号码用BigIntegerField或者直接用CharFieldaddr = models.CharField(max_length=64)
给三给表先写点数据

一对多的外键增删改查
test.py
from django.test import TestCase# Create your tests here.import osif __name__ == "__main__":os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day64.settings")import djangodjango.setup()from app01 import models# 一对多的外键增删改查 以Book表为例# 增# 方法一:直接写实际字段 id,,Book表中publish_date字段可以不给,创建时会自动写入创建时间# models.Book.objects.create(title='论语',price=899.23,publish_id=1)# models.Book.objects.create(title='聊斋',price=444.23,publish_id=2)# models.Book.objects.create(title='老子',price=333.66,publish_id=1)# 方法二:虚拟字段 对象# publish_obj = models.Publish.objects.filter(pk=3).first()# models.Book.objects.create(title='红楼梦',price=666.23,publish=publish_obj)# 删# models.Publish.objects.filter(pk=1).delete() # 级联删除# 修改# models.Book.objects.filter(pk=1).update(publish_id=2)# publish_obj = models.Publish.objects.filter(pk=1).first()# models.Book.objects.filter(pk=1).update(publish=publish_obj)
多对多的外键增删改查(就是在操作两者之间的第三者关系表)
test.py
from django.test import TestCase# Create your tests here.import osif __name__ == "__main__":os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day64.settings")import djangodjango.setup()from app01 import models# 多对多的外键增删改查 以Book表为例# 增# 方法一:add中放主键id数字# 如何在第三张表book_authors中建立书籍和作者的绑定关系# 先整一个书籍对象# book_obj = models.Book.objects.filter(pk=3).first()# print(book_obj.authors) # 就类似于你已经到了第三张关系表了,authors是Book类里的authors属性# book_obj.authors.add(1) # 书籍id为3的书籍绑定一个主键为1 的作者# book_obj.authors.add(2, 3) # 还可以绑定多个作者# 方法二:add中放对象# book_obj = models.Book.objects.filter(pk=1).first()# author_obj = models.Author.objects.filter(pk=1).first()# author_obj1 = models.Author.objects.filter(pk=2).first()# author_obj2 = models.Author.objects.filter(pk=3).first()# book_obj.authors.add(author_obj)# book_obj.authors.add(author_obj1,author_obj2) # 还可以放作者对象"""add给第三张关系表添加数据括号内既可以传数字也可以传对象 并且都支持多个"""# 删除# 方法一:# book_obj = models.Book.objects.filter(pk=1).first()# book_obj.authors.remove(2) # # 书籍id为1的书籍解除绑定一个主键为2 的作者# book_obj.authors.remove(1,3)## 方法二:# book_obj = models.Book.objects.filter(pk=1).first()# author_obj = models.Author.objects.filter(pk=1).first()# author_obj1 = models.Author.objects.filter(pk=2).first()# author_obj2 = models.Author.objects.filter(pk=3).first()# book_obj.authors.remove(author_obj,author_obj2)"""remove括号内既可以传数字也可以传对象 并且都支持多个"""# 修改# 方法一:# book_obj = models.Book.objects.filter(pk=1).first()# book_obj.authors.set([1,2]) # 括号内必须给一个可迭代对象# book_obj.authors.set([3]) # 括号内必须给一个可迭代对象# 方法二:# book_obj = models.Book.objects.filter(pk=1).first()# author_obj = models.Author.objects.filter(pk=2).first()# author_obj1 = models.Author.objects.filter(pk=3).first()# book_obj.authors.set([author_obj,author_obj1]) # 括号内必须给一个可迭代对象"""set括号内必须传一个可迭代对象,该对象内既可以数字也可以对象 并且都支持多个"""# 清空# 在第三张关系表中清空某个书籍与作者的绑定关系book_obj = models.Book.objects.filter(pk=1).first()book_obj.authors.clear()"""clear括号内不要加任何参数"""
修改单独说明:
1、
修改前
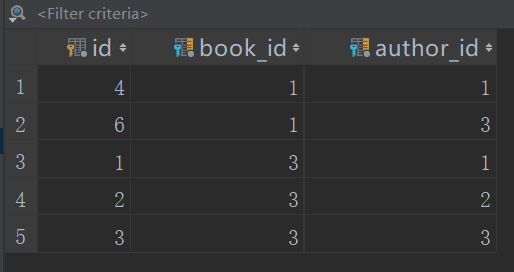
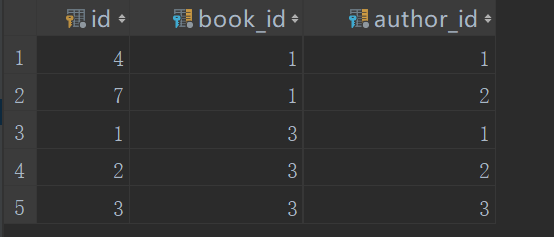
from django.test import TestCase# Create your tests here.import osif __name__ == "__main__":os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day64.settings")import djangodjango.setup()from app01 import models# 修改book_obj = models.Book.objects.filter(pk=1).first()book_obj.authors.set([1,2]) # 会将id为1的book,对应的作者从1,3改为1,2,会先将id为1的book对应的作者id为3的删掉,再重新建
2、
修改前
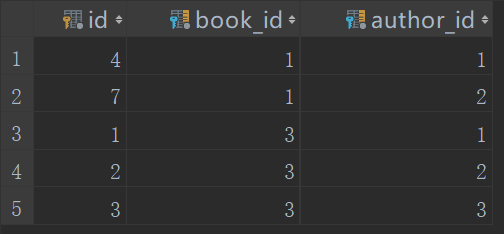
test.py
from django.test import TestCase# Create your tests here.import osif __name__ == "__main__":os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day64.settings")import djangodjango.setup()from app01 import models# 修改book_obj = models.Book.objects.filter(pk=1).first()book_obj.authors.set([3]) # 将id为1的book对应author_id为1,2的先删掉,然后再建一个id为1的book对应author_id为3
修改后
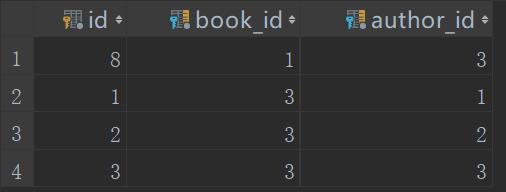
FOREIGNKEY中的DB_CONSTRAINT参数有什么用
db_constraint 唯一约束db_constraint = True 方便查询 约束字段db_constraint = fales 不约束字段 同时也可以查询
正反向概念
# 正向# 反向外键字段在我手上那么,我查你就是正向外键字段如果不在手上,我查你就是反向book >>> 外键字段在书那儿(正向)>>> publishpublish >>> 外键字段在书那儿(反向)>>>book一对一和多对多正反向的判断也是如此正向查询按外键字段:eg:author_obj = models.Author.objects.filter(name='jason').first()res = author_obj.author_detail反向查询按表名小写_set...eg:# publish_obj = models.Publish.objects.filter(name='东方出版社').first()# 出版社查书 反向# res = publish_obj.book_set # app01.Book.None# res = publish_obj.book_set.all()"""基于对象反向查询的时候当你的查询结果可以有多个的时候 就必须加_set.all()当你的结果只有一个的时候 不需要加_set.all()"""
多表查询
子查询(基于对象的跨表查询)
练习题:
from django.test import TestCase# Create your tests here.import osif __name__ == "__main__":os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day64.settings")import djangodjango.setup()from app01 import models# 正向# 子查询(基于对象的跨表查询)# 1.查询书籍主键为1的出版社# book_obj = models.Book.objects.filter(pk=1).first()# # 书查出版社 正向# res = book_obj.publish # 通过一对一多的外键publish,book_obj.publish得到书籍主键为1的出版社对象# # print(res)# print(res.name)# print(res.addr)# 2.查询书籍主键为2的作者# book_obj = models.Book.objects.filter(pk=2).first()# # 书查作者 正向# # res = book_obj.authors # app01.Author.None# res = book_obj.authors.all() # <QuerySet [<Author: Author object>, <Author: Author object>]># print(res)"""在书写orm语句的时候跟写sql语句一样的不要企图一次性将orm语句写完 如果比较复杂 就写一点看一点正向什么时候需要加.all()当你的结果可能有多个的时候就需要加.all()如果是一个则直接拿到数据对象book_obj.publishbook_obj.authors.all()author_obj.author_detail"""# 3.查询作者jason的电话号码# author_obj = models.Author.objects.filter(name='jason').first()# res = author_obj.author_detail# print(res)# print(res.phone)# print(res.addr)# 反向查# 4.查询出版社是东方出版社出版的书# publish_obj = models.Publish.objects.filter(name='东方出版社').first()# 出版社查书 反向# res = publish_obj.book_set # app01.Book.None# res = publish_obj.book_set.all()# print(res)# 5.查询作者是jason写过的书# author_obj = models.Author.objects.filter(name='jason').first()# 作者查书 反向# res = author_obj.book_set # app01.Book.None# res = author_obj.book_set.all()# print(res)# 6.查询手机号是110的作者姓名# author_detail_obj = models.AuthorDetail.objects.filter(phone=110).first()# res = author_detail_obj.author # jason <class 'app01.models.Author'># print(res.name)"""基于对象反向查询的时候当你的查询结果可以有多个的时候 就必须加_set.all()当你的结果只有一个的时候 不需要加_set.all()"""
联表查询(基于双下划线的跨表查询)
# 基于双下划线的跨表查询# 1.查询jason的手机号和作者姓名# res = models.Author.objects.filter(name='jason').values('author_detail__phone','name') # values()支持正反向概念 # # author_detail__phone:正向利用author_detail字段跨到作者详情表,之后拿phone# print(res)# 反向# res = models.AuthorDetail.objects.filter(author__name='jason') # filter同样支持正反向的概念,拿作者姓名是jason的作者详情# res = models.AuthorDetail.objects.filter(author__name='jason').values('phone','author__name')# print(res) # # 总结: # # 利用正反向的概念,正向使用使用外键字段,反向使用表名小写# 2.查询书籍主键为1的出版社名称和书的名称# res = models.Book.objects.filter(pk=1).values('title','publish__name')# print(res)# 反向# res = models.Publish.objects.filter(book__id=1).values('name','book__title')# print(res)# 3.查询书籍主键为1的作者姓名# res = models.Book.objects.filter(pk=1).values('authors__name')# print(res)# 反向# res = models.Author.objects.filter(book__id=1).values('name')# print(res)# 查询书籍主键是1的作者的手机号# book author authordetail# res = models.Book.objects.filter(pk=1).values('authors__author_detail__phone') # authors__author_detail__phone:book通过外键字段authors进入作者表,再通过作者表中author_detail外键字段进入作者详情表# print(res)"""你只要掌握了正反向的概念以及双下划线那么你就可以无限制的跨表"""
聚合查询(聚合函数的使用)
# 聚合查询,orm要使用聚合函数要先导入模块,通常情况下聚合查询都是配合分组一起使用的# 如果不想分组但是还想使用聚合函数那么就需要使用aggregate()方法 示例:models.模型类名.objects.aggregate()"""只要是跟数据库相关的基本都在django.db.models里面如果上述没有那么应该在django.db里面"""from django.db.models import Max,Min,Sum,Avg,Count
简单示例:
test.py
from django.test import TestCase# Create your tests here.import osif __name__ == "__main__":os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day64.settings")import djangodjango.setup()from app01 import models# 聚合查询,orm要使用聚合函数要先导入模块,一般都是结合分组使用,如果想在不使用分组的情况下使用聚合函数,要使用aggregate()"""只要是跟数据库相关的基本都在django.db.models里面如果上述没有那么应该在django.db里面"""from django.db.models import Max,Min,Sum,Avg,Count# 1、统计所有书的平均价格# res = models.Book.objects.aggregate(Avg("price"))# print(res)# 2、上述方法一次性使用res = models.Book.objects.aggregate(Max('price'), Min('price'), Sum('price'), Count('pk'), Avg('price'))print(res)
分组查询
"""MySQL分组查询都有哪些特点分组之后默认只能获取到分组的依据 组内其他字段都无法直接获取了严格模式ONLY_FULL_GROUP_BY"""
简单示例:
test.py
from django.test import TestCase# Create your tests here.import osif __name__ == "__main__":os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day64.settings")import djangodjango.setup()from app01 import models# 分组查询,分组查询关键字annotate() 类似MySQL中group byfrom django.db.models import Max,Min,Sum,Avg,Count# 1、统计每一本书的作者个数# res = models.Book.objects.annotate() # models后面点什么 就是按什么分组# res = models.Book.objects.annotate(author_num=Count("authors__pk")).values("title","author_num")# res1 = models.Book.objects.annotate(author_num=Count("authors")).values("title", "author_num")# # author_num=Count("authors__id") author_num是我们自己定义的别名 用来存储聚合函数统计出来的每本书对应的作者个数# # Count("authors__id") 括号里面(书查作者正向)可以使用外键字段名__字段,也可以直接写外键字段(因为orm帮我们简化了)# # res = models.Book.objects.annotate(author_num=Count("authors")).values("title","author_num")# print(res,res1)# 2、统计每个出版社卖的最便宜的书的价格(作业:复习原生SQL语句 写出来)# res = models.Publish.objects.annotate(min_price=Min("book__price")).values("name","min_price")# print(res)# 3、统计不止一个作者的图书# res = models.Book.objects.annotate(author=Count("authors")).filter(author__gt=1).values("title","author")# print(res)"""补充:只要你的orm语句得出的结果还是一个queryset对象那么它就可以继续无限制的点queryset对象封装的方法"""# 4、查询每个作者出的书的总价格# res = models.Author.objects.annotate(sum_price=Sum('book__price')).values('name','sum_price')# print(res)"""如果我想按照指定的字段分组该如何处理呢?如果annotate前面出现values那么就会按照values括号里分组models.Book.objects.values('price').annotate()后续BBS作业会使用你们的机器上如果出现分组查询报错的情况你需要修改数据库严格模式"""
F与Q查询
F查询
示例:
from django.test import TestCase# Create your tests here.import osif __name__ == "__main__":os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day64.settings")import djangodjango.setup()from app01 import models# F查询"""能够帮助你直接获取到表中某个字段对应的数据"""from django.db.models import F # F查询需要导入F# 1、查询卖出数大于库存数的书籍# res = models.Book.objects.filter(maichu__gt=F('kucun'))# print(res)# 2.将所有书籍的价格提升500块models.Book.objects.update(price=F('price') + 500)# 3.将所有书的名称后面加上爆款两个字"""在操作字符类型的数据的时候 F不能够直接做到字符串的拼接"""from django.db.models.functions import Concatfrom django.db.models import Valuemodels.Book.objects.update(title=Concat(F('title'), Value('爆款')))# models.Book.objects.update(title=F('title') + '爆款') # 所有的名称会全部变成空白
Q查询
"""filter括号内多个参数默认是and关系"""# 如果想改成or或这非not关系需要用到Q查询
示例:
from django.test import TestCase# Create your tests here.import osif __name__ == "__main__":os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day64.settings")import djangodjango.setup()from app01 import models# Q查询"""能够帮助你直接获取到表中某个字段对应的数据"""from django.db.models import Q # Q查询需要导入Q# 1、查询卖出数大于100或者价格小于600的书籍"""filter括号内多个参数是and关系"""from django.db.models import Qres = models.Book.objects.filter(Q(maichu__gt=100),Q(price__lt=600)) # Q包裹逗号分割 还是and关系# res = models.Book.objects.filter(Q(maichu__gt=100)|Q(price__lt=600)) # | or关系# res = models.Book.objects.filter(~Q(maichu__gt=100)|Q(price__lt=600)) # ~ not关系print(res)
Q查询高阶
from django.test import TestCase# Create your tests here.import osif __name__ == "__main__":os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day64.settings")import djangodjango.setup()from app01 import models# Q查询"""能够帮助你直接获取到表中某个字段对应的数据"""from django.db.models import Q # Q查询需要导入Q# Q的高阶用法 能够将查询条件的左边也变成字符串的形式q = Q()q.children.append(('maichu__gt', 100))q.children.append(('price__lt', 600))res = models.Book.objects.filter(q) # filter括号内也支持直接放q对象,默认还是and关系print(res)""""改成or关系q = Q()q.connector = 'or' # 指定为orq.children.append(('maichu__gt', 100))q.children.append(('price__lt', 600))res = models.Book.objects.filter(q)print(res)"""
Django中如何开启事务
"""事务ACID原子性不可分割的最小单位一致性跟原子性是相辅相成隔离性事务之间互相不干扰持久性事务一旦确认永久生效事务的回滚rollback事务的确认commit"""
示例:
from django.test import TestCase# Create your tests here.import osif __name__ == "__main__":os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day64.settings")import djangodjango.setup()from app01 import models# 目前你只需要掌握Django中如何简单的开启事务# 事务 需要导入transactionfrom django.db import transactiontry:with transaction.atomic():# sql1# sql2...# 在with代码快内书写的所有orm操作都是属于同一个事务except Exception as e:print(e)print('执行其他操作')
数据库设计范式
当一个关系中的所有分类都是不可再分的数据项时,该关系是规范化的。不可再分的数据项,即不存在组合数据项和多项数据项。一个低一级的关系模式,通过模式分解可以转换为若干高一级范式的关系模式的集合,这个过程就叫规范化。二维数据表可以分为5级范式为1NF、2NF、3NF、4NF、5NF。第一范式满足最低的要求条件,第五范式满足最高要求的条件。
第一范式条件:必须不包含重复组的关系,即每一列都是不可拆分的原子项。
如以下表存在可再分项(高级职称),所以不满足第一范式
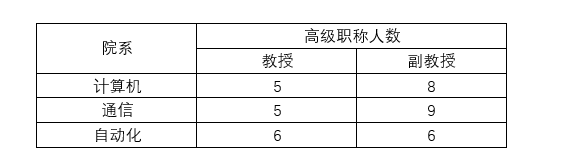
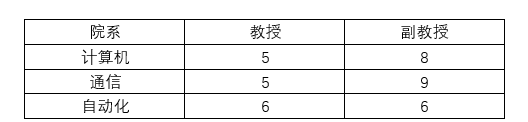
非规范化转换为规范化的第一范式方法很简单,将表分别从横向、纵向展开即可。将高级职称横向展开即可以得到满足第一范式的表结构。
第二范式条件:关系模式必须满足第一范式,并且所有非主属性都完全依赖于主码。注意,符合第二范式的关系模型可能还存在数据冗余、更新异常等问题。
举例如关系模型(职工号,姓名,职称,项目号,项目名称)中,职工号->姓名,职工号->职称,而项目号->项目名称。显然依赖关系不满足第二范式,常用的解决办法是差分表格,比如拆分为职工信息表和项目信息表。
第三范式的条件:关系模型满足第二范式,所有非主属性对任何候选关键字都不存在传递依赖。即每个属性都跟主键有直接关系而不是间接关系,像:a—>b—>c。一般数据库设计中,一般要求达到3NF,第四第五较少涉及。
比如Student表(学号,姓名,年龄,性别,所在院校,院校地址,院校电话)这样一个表结构,就存在上述关系。 学号—> 所在院校 —> (院校地址,院校电话)。我们应该拆开来,如下:
(学号,姓名,年龄,性别,所在院校)—(所在院校,院校地址,院校电话)
ORM中常用字段以及参数
AutoField主键字段 primary_key=TrueCharField varcharverbose_name 字段的注释max_length 长度IntegerField intBigIntegerField bigintDecimalFieldmax_digits=8decimal_places=2EmailFiled varchar(254)DateField dateDateTimeField datetimeauto_now:每次修改数据的时候都会自动更新当前时间auto_now_add:只在创建数据的时候记录创建时间后续不会自动修改了BooleanField(Field) - 布尔值类型该字段传布尔值(False/True) 数据库里面存0/1TextField(Field) - 文本类型该字段可以用来存大段内容(文章、博客...) 没有字数限制后面的bbs作业 文章字段用的就是TextFieldFileField(Field) - 字符类型upload_to = "/data"给该字段传一个文件对象,会自动将文件保存到/data目录下然后将文件路径保存到数据库中/data/a.txt后面bbs作业也会涉及# 更多字段直接参考博客:https://www.cnblogs.com/Dominic-Ji/p/9203990.html
自定义字段
# django除了给你提供了很多字段类型之外 还支持你自定义字段
自定义类型示例:
models.py
# 自定义字段需要让类继承feildclass MyCharField(models.Field):def __init__(self, max_length, *args, **kwargs):self.max_length = max_length# 调用父类的init方法super().__init__(max_length=max_length, *args, **kwargs) # 一定要是关键字的形式传入def db_type(self, connection):"""返回真正的数据类型及各种约束条件"""return 'char(%s)' % self.max_length# 自定义字段使用class Book(models.Model):title = models.CharField(max_length=32)price = models.DecimalField(max_digits=8,decimal_places=2)publish_date = models.DateField(auto_now_add=True)# 自定义字段myfield = MyCharField(max_length=16)
外键字段及参数
unique=TrueForeignKey(unique=True) ===> OneToOneField()# 你在用前面字段ForeignKey创建一对一 orm会有一个提示信息 orm推荐你使用后者但是前者也能用db_index如果db_index=True 则代表着为此字段设置索引(复习索引是什么)to_field设置要关联的表的字段 默认不写关联的就是另外一张的主键字段on_delete当删除关联表中的数据时,当前表与其关联的行的行为。"""django2.X及以上版本 需要你自己指定外键字段的级联更新级联删除"""
数据库查询优化
only与deferselect_related与prefetch_related
orm语句的特点
# orm语句的特点:惰性查询如果你仅仅只是书写了orm语句 在后面根本没有用到该语句所查询出来的参数那么orm会自动识别 直接不执行
only和defer
test.py
from django.test import TestCase# Create your tests here.import osif __name__ == "__main__":os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day64.settings")import djangodjango.setup()from app01 import models# orm语句特点:惰性查询# res = models.Book.objects.all()# print(res) # 要用数据了才会走数据库# only与defer# 1、想要获取书籍表中所有书的名字# 原先方法,拿到QuerySet对象(列表套字典)# res = models.Book.objects.values('title')# print(res)# for d in res:# print(d.get('title'))# 2、实现获取到的是一个数据对象 然后点title就能够拿到书名 并且没有其他字段# 使用only# res = models.Book.objects.only('title')# res = models.Book.objects.all()# print(res) # <QuerySet [<Book: 三国演义爆款>, <Book: 红楼梦爆款>, <Book: 论语爆款>, <Book: 聊斋爆款>, <Book: 老子爆款>]>for i in res:print(i.title) # 点击only括号内的字段 不会走数据库# print(i.price) # 点击only括号内没有的字段 会重新走数据库查询(因为其对象本身只有title属性)而all方法的对象本身就有了所有属性所以不需要走数据库了# 3、对象除了没有title属性之外其他的都有# res = models.Book.objects.defer('title') # 对象除了没有title属性之外其他的都有# # print(res)# for i in res:# print(i.price) # 点击only括号内没有的字段 不会走数据库查询# print(i.title) # 点击only括号内的字段 会重新走数据库查询"""defer与only刚好相反defer括号内放的字段不在查询出来的对象里面 查询该字段需要重新走数据而如果查询的是非括号内的字段 则不需要走数据库了"""
select_related与prefetch_related
select_related ==》 inner join
from django.test import TestCase# Create your tests here.import osif __name__ == "__main__":os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day64.settings")import djangodjango.setup()from app01 import models# select_related与prefetch_related 跟跨表操作有关# 查询每本书的出版社名称# 原先方法# res = models.Book.objects.all()# for i in res:# print(i.publish.name) # 每循环一次就要走一次数据库查询# 优化查询select_relatedres = models.Book.objects.select_related("publish") # INNER JOINfor i in res:print(i.publish.name)"""select_related内部直接先将book与publish连起来 然后一次性将大表里面的所有数据全部封装给查询出来的对象这个时候对象无论是点击book表的数据还是publish的数据都无需再走数据库查询了ps:select_related括号内只能放外键字段 一对多 一对一多对多也不行 ps2:select_related括号内可以放多个外键字段,eg: select_related(外键字段1__外键字段2__外键字段3__...)"""
prefetch_related 子查询
示例:
from django.test import TestCase# Create your tests here.import osif __name__ == "__main__":os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day64.settings")import djangodjango.setup()from app01 import models# prefetch_relatedres = models.Book.objects.prefetch_related("publish") # 子查询"""prefetch_related该方法内部其实就是子查询将子查询查询出来的所有结果也给你封装到对象中给你的感觉好像也是一次性搞定的"""for i in res:print(i.publish.name)

若有收获,就点个赞吧
0 人点赞
