1 评分机制详解
1.1 评分机制TF/IDF
1.1.1 算法介绍
- ElasticSearch使用的是term frequency/inverse document frequency算法,简称IF/IDF算法。TF:词频(term frequency),IDF:逆向文件频率(inverse document frequency)。
- TF(Term Frequency):搜索文本中的各个词条在每个文档的字段中出现了多少次,出现次数越多,就越相关。

- TF例子:index:medicine,搜索请求:阿莫西林。
- doc1:阿莫西林胶囊是什么。。。阿莫西林胶囊能做什么。。。阿莫西林胶囊结构。
- doc2:本药店有阿莫西林胶囊、红霉素胶囊、青霉素胶囊。。。。
- 结果:doc1>doc2。
- IDF(Inverse Document Frequency):搜索文本中的各个词条在整个索引的所有文档中出现了多少次,出现的次数越多,就越不相关。

- IDF例子:index:medicine,搜索请求:A市阿莫西林胶囊。
- doc1:A市健康大药房简介。本药店有阿莫西林胶囊、红霉素胶囊、青霉素胶囊。。。。
- doc2:B市民生大药房简介。本药店有阿莫西林胶囊、红霉素胶囊、青霉素胶囊。。。。
- doc3:C市未来大药房简介。本药店有阿莫西林胶囊、红霉素胶囊、青霉素胶囊。。。。
- 结论:整个索引库中出现少的词,相关度权重高。
- Field-length norm:field长度,field越长,相关度越弱。
- Field-length norm例子:index:medicine,搜索请求:A市阿莫西林胶囊。
- doc1:
{"title":"A市健康大药房简介","content":"本药店有红霉素胶囊、青霉素胶囊。。。一万字"}。 - doc2:
{"title":"B市民生大药房简介","content":"本药店有阿莫西林胶囊、红霉素胶囊、青霉素胶囊。。。一万字"}。 - 结论:doc1>doc2。
- doc1:
1.1.2 _score是如何被计算出来的?
 对用户输入的关键字进行分词。
对用户输入的关键字进行分词。 每个分词分别计算对每个匹配文档的tf值和idf值。
每个分词分别计算对每个匹配文档的tf值和idf值。 综合每个分词的tf/idf值,利用公式计算每个文档的总分。
综合每个分词的tf/idf值,利用公式计算每个文档的总分。- 示例:
- 开启explain执行计划:
GET /book/_search?explain=true{"query": {"match": {"description": "java程序员"}}}
- 返回:
{"took" : 655,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 3,"relation" : "eq"},"max_score" : 2.2765667,"hits" : [{"_shard" : "[book][0]","_node" : "MTYvUxUWRSqSE2GLsX8_zg","_index" : "book","_type" : "_doc","_id" : "3","_score" : 2.2765667,"_source" : {"name" : "spring开发基础","description" : "spring 在java领域非常流行,java程序员都在用。","studymodel" : "201001","price" : 88.6,"timestamp" : "2019-08-24 19:11:35","pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg","tags" : ["spring","java"]},"_explanation" : {"value" : 2.2765667,"description" : "sum of:","details" : [{"value" : 0.79664993,"description" : "weight(description:java in 1) [PerFieldSimilarity], result of:","details" : [{"value" : 0.79664993,"description" : "score(freq=2.0), computed as boost * idf * tf from:","details" : [{"value" : 2.2,"description" : "boost","details" : [ ]},{"value" : 0.47000363,"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details" : [{"value" : 2,"description" : "n, number of documents containing term","details" : [ ]},{"value" : 3,"description" : "N, total number of documents with field","details" : [ ]}]},{"value" : 0.7704485,"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details" : [{"value" : 2.0,"description" : "freq, occurrences of term within document","details" : [ ]},{"value" : 1.2,"description" : "k1, term saturation parameter","details" : [ ]},{"value" : 0.75,"description" : "b, length normalization parameter","details" : [ ]},{"value" : 16.0,"description" : "dl, length of field","details" : [ ]},{"value" : 48.666668,"description" : "avgdl, average length of field","details" : [ ]}]}]}]},{"value" : 0.18407845,"description" : "weight(description:程 in 1) [PerFieldSimilarity], result of:","details" : [{"value" : 0.18407845,"description" : "score(freq=1.0), computed as boost * idf * tf from:","details" : [{"value" : 2.2,"description" : "boost","details" : [ ]},{"value" : 0.13353139,"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details" : [{"value" : 3,"description" : "n, number of documents containing term","details" : [ ]},{"value" : 3,"description" : "N, total number of documents with field","details" : [ ]}]},{"value" : 0.62660944,"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details" : [{"value" : 1.0,"description" : "freq, occurrences of term within document","details" : [ ]},{"value" : 1.2,"description" : "k1, term saturation parameter","details" : [ ]},{"value" : 0.75,"description" : "b, length normalization parameter","details" : [ ]},{"value" : 16.0,"description" : "dl, length of field","details" : [ ]},{"value" : 48.666668,"description" : "avgdl, average length of field","details" : [ ]}]}]}]},{"value" : 0.6479192,"description" : "weight(description:序 in 1) [PerFieldSimilarity], result of:","details" : [{"value" : 0.6479192,"description" : "score(freq=1.0), computed as boost * idf * tf from:","details" : [{"value" : 2.2,"description" : "boost","details" : [ ]},{"value" : 0.47000363,"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details" : [{"value" : 2,"description" : "n, number of documents containing term","details" : [ ]},{"value" : 3,"description" : "N, total number of documents with field","details" : [ ]}]},{"value" : 0.62660944,"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details" : [{"value" : 1.0,"description" : "freq, occurrences of term within document","details" : [ ]},{"value" : 1.2,"description" : "k1, term saturation parameter","details" : [ ]},{"value" : 0.75,"description" : "b, length normalization parameter","details" : [ ]},{"value" : 16.0,"description" : "dl, length of field","details" : [ ]},{"value" : 48.666668,"description" : "avgdl, average length of field","details" : [ ]}]}]}]},{"value" : 0.6479192,"description" : "weight(description:员 in 1) [PerFieldSimilarity], result of:","details" : [{"value" : 0.6479192,"description" : "score(freq=1.0), computed as boost * idf * tf from:","details" : [{"value" : 2.2,"description" : "boost","details" : [ ]},{"value" : 0.47000363,"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details" : [{"value" : 2,"description" : "n, number of documents containing term","details" : [ ]},{"value" : 3,"description" : "N, total number of documents with field","details" : [ ]}]},{"value" : 0.62660944,"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details" : [{"value" : 1.0,"description" : "freq, occurrences of term within document","details" : [ ]},{"value" : 1.2,"description" : "k1, term saturation parameter","details" : [ ]},{"value" : 0.75,"description" : "b, length normalization parameter","details" : [ ]},{"value" : 16.0,"description" : "dl, length of field","details" : [ ]},{"value" : 48.666668,"description" : "avgdl, average length of field","details" : [ ]}]}]}]}]}},{"_shard" : "[book][0]","_node" : "MTYvUxUWRSqSE2GLsX8_zg","_index" : "book","_type" : "_doc","_id" : "1","_score" : 0.94958127,"_source" : {"name" : "Bootstrap开发","description" : "Bootstrap是由Twitter推出的一个前台页面开发css框架,是一个非常流行的开发框架,此框架集成了多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长css页面开发的程序人员)轻松的实现一个css,不受浏览器限制的精美界面css效果。","studymodel" : "201002","price" : 38.6,"timestamp" : "2019-08-25 19:11:35","pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg","tags" : ["bootstrap","dev"]},"_explanation" : {"value" : 0.94958127,"description" : "sum of:","details" : [{"value" : 0.13911864,"description" : "weight(description:程 in 0) [PerFieldSimilarity], result of:","details" : [{"value" : 0.13911864,"description" : "score(freq=2.0), computed as boost * idf * tf from:","details" : [{"value" : 2.2,"description" : "boost","details" : [ ]},{"value" : 0.13353139,"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details" : [{"value" : 3,"description" : "n, number of documents containing term","details" : [ ]},{"value" : 3,"description" : "N, total number of documents with field","details" : [ ]}]},{"value" : 0.47356468,"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details" : [{"value" : 2.0,"description" : "freq, occurrences of term within document","details" : [ ]},{"value" : 1.2,"description" : "k1, term saturation parameter","details" : [ ]},{"value" : 0.75,"description" : "b, length normalization parameter","details" : [ ]},{"value" : 104.0,"description" : "dl, length of field (approximate)","details" : [ ]},{"value" : 48.666668,"description" : "avgdl, average length of field","details" : [ ]}]}]}]},{"value" : 0.48966968,"description" : "weight(description:序 in 0) [PerFieldSimilarity], result of:","details" : [{"value" : 0.48966968,"description" : "score(freq=2.0), computed as boost * idf * tf from:","details" : [{"value" : 2.2,"description" : "boost","details" : [ ]},{"value" : 0.47000363,"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details" : [{"value" : 2,"description" : "n, number of documents containing term","details" : [ ]},{"value" : 3,"description" : "N, total number of documents with field","details" : [ ]}]},{"value" : 0.47356468,"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details" : [{"value" : 2.0,"description" : "freq, occurrences of term within document","details" : [ ]},{"value" : 1.2,"description" : "k1, term saturation parameter","details" : [ ]},{"value" : 0.75,"description" : "b, length normalization parameter","details" : [ ]},{"value" : 104.0,"description" : "dl, length of field (approximate)","details" : [ ]},{"value" : 48.666668,"description" : "avgdl, average length of field","details" : [ ]}]}]}]},{"value" : 0.3207929,"description" : "weight(description:员 in 0) [PerFieldSimilarity], result of:","details" : [{"value" : 0.3207929,"description" : "score(freq=1.0), computed as boost * idf * tf from:","details" : [{"value" : 2.2,"description" : "boost","details" : [ ]},{"value" : 0.47000363,"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details" : [{"value" : 2,"description" : "n, number of documents containing term","details" : [ ]},{"value" : 3,"description" : "N, total number of documents with field","details" : [ ]}]},{"value" : 0.31024224,"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details" : [{"value" : 1.0,"description" : "freq, occurrences of term within document","details" : [ ]},{"value" : 1.2,"description" : "k1, term saturation parameter","details" : [ ]},{"value" : 0.75,"description" : "b, length normalization parameter","details" : [ ]},{"value" : 104.0,"description" : "dl, length of field (approximate)","details" : [ ]},{"value" : 48.666668,"description" : "avgdl, average length of field","details" : [ ]}]}]}]}]}},{"_shard" : "[book][0]","_node" : "MTYvUxUWRSqSE2GLsX8_zg","_index" : "book","_type" : "_doc","_id" : "2","_score" : 0.7534219,"_source" : {"name" : "java编程思想","description" : "java语言是世界第一编程语言,在软件开发领域使用人数最多。","studymodel" : "201001","price" : 68.6,"timestamp" : "2019-08-25 19:11:35","pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg","tags" : ["java","dev"]},"_explanation" : {"value" : 0.7534219,"description" : "sum of:","details" : [{"value" : 0.5867282,"description" : "weight(description:java in 0) [PerFieldSimilarity], result of:","details" : [{"value" : 0.5867282,"description" : "score(freq=1.0), computed as boost * idf * tf from:","details" : [{"value" : 2.2,"description" : "boost","details" : [ ]},{"value" : 0.47000363,"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details" : [{"value" : 2,"description" : "n, number of documents containing term","details" : [ ]},{"value" : 3,"description" : "N, total number of documents with field","details" : [ ]}]},{"value" : 0.567431,"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details" : [{"value" : 1.0,"description" : "freq, occurrences of term within document","details" : [ ]},{"value" : 1.2,"description" : "k1, term saturation parameter","details" : [ ]},{"value" : 0.75,"description" : "b, length normalization parameter","details" : [ ]},{"value" : 25.0,"description" : "dl, length of field","details" : [ ]},{"value" : 48.666668,"description" : "avgdl, average length of field","details" : [ ]}]}]}]},{"value" : 0.16669367,"description" : "weight(description:程 in 0) [PerFieldSimilarity], result of:","details" : [{"value" : 0.16669367,"description" : "score(freq=1.0), computed as boost * idf * tf from:","details" : [{"value" : 2.2,"description" : "boost","details" : [ ]},{"value" : 0.13353139,"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details" : [{"value" : 3,"description" : "n, number of documents containing term","details" : [ ]},{"value" : 3,"description" : "N, total number of documents with field","details" : [ ]}]},{"value" : 0.567431,"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details" : [{"value" : 1.0,"description" : "freq, occurrences of term within document","details" : [ ]},{"value" : 1.2,"description" : "k1, term saturation parameter","details" : [ ]},{"value" : 0.75,"description" : "b, length normalization parameter","details" : [ ]},{"value" : 25.0,"description" : "dl, length of field","details" : [ ]},{"value" : 48.666668,"description" : "avgdl, average length of field","details" : [ ]}]}]}]}]}}]}}
1.1.3 生产环境下判断某一个文档是否匹配上
- 示例:
GET /book/_explain/3{"query": {"match": {"description": "java程序员"}}}
1.2 Doc value
1.2.1 概述
- 搜索的时候,需要依靠倒排索引;排序的时候,需要依靠正排索引,看到每个document的每个field,然后进行排序,所谓的正排索引,其实就是doc value。
- 在建立索引的时候,一方面会建立倒排索引,以供搜索用;另一方面会建立正排索引,即doc value,以供排序、聚合、过滤等操作使用。
- doc value是被保存在磁盘上的,如果内存足够,ES会自动将其缓存到内存中,性能会很高;但是,如果内存不够,OS会将其写入到磁盘上。
1.2.2 倒排索引应用案例
- 示例:
- doc1:
hello world you and me。 - doc2:
hi, world, how are you。 | term | doc1 | doc2 | | —- | —- | —- | | hello | | | | world | | | | you | | | | and | | | | me | | | | hi | | | | how | | | | are | | |
- 搜索的步骤:
- ①搜索hello you,会将hello you进行分词,分为hello和you。
- ②hello对应doc1。
- ③you对应doc1和doc2。
- 但是排序的时候,会出现问题。
1.2.3 正排索引的案例
- 示例:
- doc1:
{ "name": "jack", "age": 27 }。 - doc2:
{ "name": "tom", "age": 30 }。 | document | name | age | | —- | —- | —- | | doc1 | jack | 27 | | doc2 | tom | 30 |
- 正排索引在建立索引的时候,会将字段类似数据库表中的字段一样保存起来,也就是不进行分词,所以可以进行排序、聚合、过滤等操作。
1.3 ES分页的终极解决方案
1.3.1 前言
- 假设现在有3个主分片,分别为P0、P1和P2,每个分片上有1亿数据,用户需要查询开始索引为9999,条数为10,并且name的名称是java的数据。
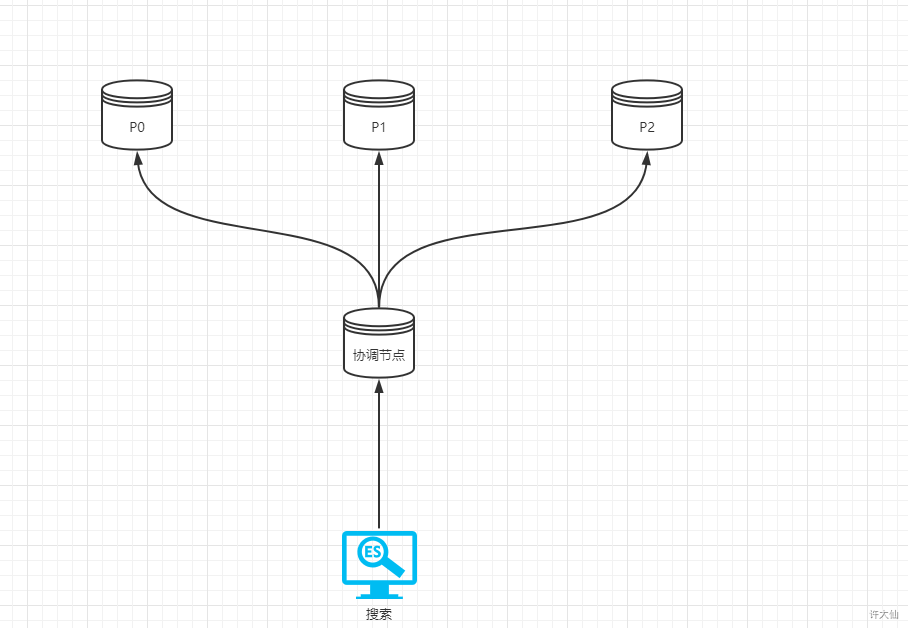
- ES会分为两个步骤:
- query phase:ES会将前10000条的id,score等少量信息汇总到协调节点进行排序,然后获取到指定条数的数据的id,score等信息。
- fetch phase:协调节点将指定条数的数据的id、score等信息构建mget到各个分片上去获取数据,返回给客户端。
ES如果不这样做的原因:如果一次性的将前10000条数据全部汇总到ES的协调节点,一旦每条数据的信息过大,会造成协调节点宕机。
1.3.2 query phase
- query phase工作流程:
- 搜索请求发送到某一个coordinate node,构建一个priority queue,长度以paging操作from和size为准,默认为10。
- coordinate node将请求转发到所有shard,每个shard本地搜索,并构建一个本地的priority queue。
- 各个shard将自己的priority queue返回给coordinate node,并构建一个全局的priority queue。
- replica shard如何提升搜索吞吐量:一次请求要打到所有shard的一个replica/primary上去,如果每个shard都有多个replica,那么同时并发过来的搜索请求可以同时打到其他的replica上去。
1.3.3 fetch phase
- fetch phbase工作流程:
- coordinate node构建完priority queue之后,就发送mget请求去所有shard上获取对应的document。
- 各个shard将document返回给coordinate node。
- coordinate node将合并后的document结果返回给client客户端。
- 一般搜索,如果不加from和size,就默认搜索前10条,按照_score排序。
1.4 搜索参数小结
1.4.1 preference
- bouncing results问题(跳跃结果问题):两个document排序,field值相同;不同的shard上,可能排序不同;每次请求轮询打到不同的replica shard上,每次页面看到的搜索结果的排序都不一样。
- 解决方案:将preference设置为一个字符串,比如说user_id,让每个user每次搜索的时候,都使用同一个replica shard去执行,就不会看到bouncing results问题。
- preference参数决定了那些shard会被用来执行搜索问题。有
_primary,_primary_first,_local,_only_node:xyz,_prefer_node:xyz,_shards:2,3。
GET /_search?preference=_shards:2,3
1.4.2 timeout
- 限定在一定时间内,将部分获取的数据直接返回,避免查询耗时过长。
GET /_search?timeout=10ms
1.4.3 routing
- document文档路由,默认是_id路由,可以使用routing设置文档路由,让同一个请求发送到一个shard上去。
GET /_search?routing=user123
2 聚合入门
2.1 聚合查询
2.1.1 分组查询
- SQL写法:
SELECT studymodel,count(*) as `count`FROM bookgroup by studymodel;
- Query DSL写法:
GET /book/_search{"size": 0,"query": {"match_all": {}},"aggs": {"count": {"terms": {"field": "studymodel"}}}}
2.1.2 Terms分组查询
- 准备工作:
PUT /book/_mapping{"properties": {"tags": {"type": "text","fielddata": true}}}
- 示例:按照tags进行分组查询
GET /book/_search{"size": 0,"query": {"match_all": {}},"aggs": {"count": {"terms": {"field": "tags"}}}}
2.1.3 加上搜索条件Terms分组查询
- 示例:按照tags进行分组,并查询name中包含java的信息
GET /book/_search{"size": 0,"query": {"match": {"name": "java"}},"aggs": {"count": {"terms": {"field": "tags"}}}}
2.1.4 多字段分组查询
- 示例:先按照tags进行分组,再计算每个tag下面的平均价格
GET /book/_search{"size": 0,"query": {"match_all": {}},"aggs": {"group_by_tags": {"terms": {"field": "tags"},"aggs": {"avg_price": {"avg": {"field": "price"}}}}}}
2.1.5 多字段分组查询排序
- 示例:先按照tags进行分组,计算每个tag下面的平均价格,并按照平均价格降序
GET /book/_search{"size": 0,"query": {"match_all": {}},"aggs": {"group_by_tags": {"terms": {"field": "tags","order": {"avg_price": "desc"}},"aggs": {"avg_price": {"avg": {"field": "price"}}}}}}
2.1.6 按照指定的价格范围进行分组查询
- 示例:
GET /book/_search{"size": 0,"aggs": {"group_by_price": {"range": {"field": "price","ranges": [{"from": 0,"to": 40},{"from": 40,"to": 60},{"from": 60,"to": 80}]}}}}
2.2 核心概念:bucket和metric
2.2.1 bucket:一个数据分组
| city | name |
|---|---|
| 北京 | 张三 |
| 北京 | 李四 |
| 天津 | 王五 |
| 天津 | 赵六 |
| 天津 | 田七 |
- 按照城市分组,就是分桶。
select city,count(*) from table group by city。 - 划分出来两个bucket,一个就是北京bucket,另一个就是天津bucket。
- 北京bucket:包含2个人,张三、李四。
- 天津bucket:包含3个人,王五、赵六、田七。
2.2.2 metric:对一个数据分组执行的统计
- metric:就是对一个bucket执行的某种聚合分析的操作,比如说求平均值,求最大值和求最小值等。
select city,count(*) from table group by city;
- bucket:
group by city指的是那些city相同的数据,就会被划分到一个bucket中。 - metric:
count(*),对每个bucket中的所有数据,进行统计。
3 电视案例
3.1 准备工作
- 示例:创建索引和映射
PUT /tvs{"mappings": {"properties": {"price": {"type": "long"},"color": {"type": "keyword"},"brand": {"type": "keyword"},"sold_date": {"type": "date"}}}}
- 示例:插入数据
PUT /tvs/_bulk{ "index": {}}{ "price" : 1000, "color" : "红色", "brand" : "长虹", "sold_date" : "2019-10-28" }{ "index": {}}{ "price" : 2000, "color" : "红色", "brand" : "长虹", "sold_date" : "2019-11-05" }{ "index": {}}{ "price" : 3000, "color" : "绿色", "brand" : "小米", "sold_date" : "2019-05-18" }{ "index": {}}{ "price" : 1500, "color" : "蓝色", "brand" : "TCL", "sold_date" : "2019-07-02" }{ "index": {}}{ "price" : 1200, "color" : "绿色", "brand" : "TCL", "sold_date" : "2019-08-19" }{ "index": {}}{ "price" : 2000, "color" : "红色", "brand" : "长虹", "sold_date" : "2019-11-05" }{ "index": {}}{ "price" : 8000, "color" : "红色", "brand" : "三星", "sold_date" : "2020-01-01" }{ "index": {}}{ "price" : 2500, "color" : "蓝色", "brand" : "小米", "sold_date" : "2020-02-12" }
3.2 统计那种颜色的电视销量最高
- 示例:
GET /tvs/_search{"size": 0,"query": {"match_all": {}},"aggs": {"popular_color": {"terms": {"field": "color"}}}}
3.3 统计每种颜色电视的平均价格
- 示例:
GET /tvs/_search{"size": 0,"query": {"match_all": {}},"aggs": {"color": {"terms": {"field": "color"},"aggs": {"avg_price": {"avg": {"field": "price"}}}}}}
3.4 统计每种颜色、平均价格下及每个颜色,每种品牌的平均价格
- 示例:
GET /tvs/_search{"size": 0,"query": {"match_all": {}},"aggs": {"group_by_color": {"terms": {"field": "color"},"aggs": {"avg_color_price": {"avg": {"field": "price"}},"group_by_brand": {"terms": {"field": "brand"},"aggs": {"avg_brand_price": {"avg": {"field": "price"}}}}}}}}
3.5 统计每个颜色的销售数量、平均价格、最大价格、最小价格、价格总和
- 示例:
GET /tvs/_search{"size": 0,"query": {"match_all": {}},"aggs": {"group_by_color": {"terms": {"field": "color"},"aggs": {"avg_price": {"avg": {"field": "price"}},"max_price":{"max": {"field": "price"}},"min_price":{"min": {"field": "price"}},"sum_price":{"sum": {"field": "price"}}}}}}
3.6 划分范围 histogram
- 示例:按照价格每20一个区间,求每个区间的销售总额
GET /tvs/_search{"size": 0,"aggs": {"price":{"histogram": {"field": "price","interval": 20},"aggs": {"sum_price": {"sum": {"field": "price"}}}}}}
3.7 按照日期分组聚合
- 示例:求每个月的销售个数
GET /tvs/_search{"size": 0,"aggs": {"sales": {"date_histogram": {"field": "sold_date","interval": "month","format": "yyyy-MM-dd","min_doc_count": 0,"extended_bounds": {"min": "2019-01-01","max": "2019-12-31"}}}}}
3.8 统计每个季度每个品牌的销售总额,以及每个季度的销售总额
- 示例:
GET /tvs/_search{"size": 0,"aggs": {"group_by_sold_date": {"date_histogram": {"field": "sold_date","interval": "quarter","format": "yyyy-MM-dd","min_doc_count": 0,"extended_bounds": {"min": "2019-01-01","max": "2019-12-31"}},"aggs": {"group_by_brand": {"terms": {"field": "brand"},"aggs": {"sum_price": {"sum": {"field": "price"}}}},"total_price":{"sum": {"field": "price"}}}}}}
3.9 查询某个品牌按颜色的销量
- 示例:小米品牌的各种颜色的销量
GET /tvs/_search{"size": 0,"query": {"term": {"brand": {"value": "小米"}}},"aggs": {"group_by_color": {"terms": {"field": "color"}}}}
3.10 单个品牌和所有品牌的均价对比
- 示例:
GET /tvs/_search{"size": 0,"query": {"term": {"brand": {"value": "小米"}}},"aggs": {"single_brand_avg_price": {"avg": {"field": "price"}},"all": {"global": {},"aggs": {"all_brand_avg_price": {"avg": {"field": "price"}}}}}}
3.11 统计价格大于1200的电视平均价格
- 示例:
GET /tvs/_search{"size": 0,"query": {"constant_score": {"filter": {"range": {"price": {"gte": 1200}}}}},"aggs": {"avg_price": {"avg": {"field": "price"}}}}
3.12 统计某品牌最近一个月的平均价格
- 示例:
GET /tvs/_search{"size": 0,"query": {"term": {"brand": {"value": "小米"}}},"aggs": {"recent_150d": {"filter": {"range": {"sold_date": {"gte": "now-150d"}}},"aggs": {"recent_150d_avg_price": {"avg": {"field": "price"}}}},"recent_140d": {"filter": {"range": {"sold_date": {"gte": "now-140d"}}},"aggs": {"recent_140d_avg_price": {"avg": {"field": "price"}}}},"recent_130d": {"filter": {"range": {"sold_date": {"gte": "now-130d"}}},"aggs": {"recent_130d_avg_price": {"avg": {"field": "price"}}}}}}
4 Java API实现聚合
4.1 按照颜色分组,计算每个颜色卖出的个数
- 示例:Query DSL
GET /tvs/_search{"size": 0,"query": {"match_all": {}},"aggs": {"group by color": {"terms": {"field": "color"}}}}
- 示例:
package com.sunxaiping.elk;import org.elasticsearch.action.search.SearchRequest;import org.elasticsearch.action.search.SearchResponse;import org.elasticsearch.client.RequestOptions;import org.elasticsearch.client.RestHighLevelClient;import org.elasticsearch.index.query.QueryBuilders;import org.elasticsearch.search.aggregations.AggregationBuilders;import org.elasticsearch.search.aggregations.Aggregations;import org.elasticsearch.search.aggregations.bucket.terms.Terms;import org.elasticsearch.search.builder.SearchSourceBuilder;import org.junit.jupiter.api.Test;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest;import java.io.IOException;import java.util.List;/*** Query DSL*/@SpringBootTestpublic class ElkApplicationTests {@Autowiredprivate RestHighLevelClient client;/***<pre>* GET /tvs/_search* {* "size": 0,* "query": {* "match_all": {}* },* "aggs": {* "group_by_color": {* "terms": {* "field": "color"* }* }* }* }* </pre>*/@Testpublic void test() throws IOException {//创建请求SearchRequest searchRequest = new SearchRequest("tvs");//请求体SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.size(0);searchSourceBuilder.query(QueryBuilders.matchAllQuery());searchSourceBuilder.aggregation(AggregationBuilders.terms("group_by_color").field("color"));searchRequest.source(searchSourceBuilder);//发送请求SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);//获取结果Aggregations aggregations = response.getAggregations();Terms terms = aggregations.get("group_by_color");List<? extends Terms.Bucket> buckets = terms.getBuckets();for (Terms.Bucket bucket : buckets) {String key = bucket.getKeyAsString();System.out.println("key = " + key);long docCount = bucket.getDocCount();System.out.println("docCount = " + docCount);}}}
4.2 按照颜色分组,计算每个颜色卖出的个数以及每个颜色卖出的平均价格
- 示例:Query DSL
GET /tvs/_search{"size": 0,"query": {"match_all": {}},"aggs": {"group_by_color": {"terms": {"field": "color"},"aggs": {"avg_price": {"avg": {"field": "price"}}}}}}
- 示例:
package com.sunxaiping.elk;import org.elasticsearch.action.search.SearchRequest;import org.elasticsearch.action.search.SearchResponse;import org.elasticsearch.client.RequestOptions;import org.elasticsearch.client.RestHighLevelClient;import org.elasticsearch.index.query.QueryBuilders;import org.elasticsearch.search.aggregations.AggregationBuilders;import org.elasticsearch.search.aggregations.Aggregations;import org.elasticsearch.search.aggregations.bucket.terms.Terms;import org.elasticsearch.search.aggregations.metrics.Avg;import org.elasticsearch.search.builder.SearchSourceBuilder;import org.junit.jupiter.api.Test;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest;import java.io.IOException;import java.util.List;/*** Query DSL*/@SpringBootTestpublic class ElkApplicationTests {@Autowiredprivate RestHighLevelClient client;/***<pre>* GET /tvs/_search* {* "size": 0,* "query": {* "match_all": {}* },* "aggs": {* "group_by_color": {* "terms": {* "field": "color"* },"aggs": {* "avg_price": {* "avg": {* "field": "price"* }* }* }* }* }* }* </pre>*/@Testpublic void test() throws IOException {//创建请求SearchRequest searchRequest = new SearchRequest("tvs");//请求体SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.size(0);searchSourceBuilder.query(QueryBuilders.matchAllQuery());searchSourceBuilder.aggregation(AggregationBuilders.terms("group_by_color").field("color").subAggregation(AggregationBuilders.avg("avg_price").field("price")));searchRequest.source(searchSourceBuilder);//发送请求SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);//获取结果Aggregations aggregations = response.getAggregations();Terms terms = aggregations.get("group_by_color");List<? extends Terms.Bucket> buckets = terms.getBuckets();for (Terms.Bucket bucket : buckets) {String key = bucket.getKeyAsString();System.out.println("key = " + key);long docCount = bucket.getDocCount();System.out.println("docCount = " + docCount);Avg avgPrice = bucket.getAggregations().get("avg_price");double value = avgPrice.getValue();System.out.println("value = " + value);}}}
4.3 按照颜色分组,计算每个颜色卖出的个数,每个颜色卖出价格的平均值、最大值、最小值和总和
- 示例:Query DSL
GET /tvs/_search{"size": 0,"query": {"match_all": {}},"aggs": {"group_by_color": {"terms": {"field": "color"},"aggs": {"avg_price": {"avg": {"field": "price"}},"max_price": {"max": {"field": "price"}},"min_price": {"min": {"field": "price"}},"sum_price":{"sum": {"field": "price"}}}}}}
- 示例:
package com.sunxaiping.elk;import org.elasticsearch.action.search.SearchRequest;import org.elasticsearch.action.search.SearchResponse;import org.elasticsearch.client.RequestOptions;import org.elasticsearch.client.RestHighLevelClient;import org.elasticsearch.index.query.QueryBuilders;import org.elasticsearch.search.aggregations.AggregationBuilders;import org.elasticsearch.search.aggregations.Aggregations;import org.elasticsearch.search.aggregations.bucket.terms.Terms;import org.elasticsearch.search.aggregations.bucket.terms.TermsAggregationBuilder;import org.elasticsearch.search.aggregations.metrics.Avg;import org.elasticsearch.search.aggregations.metrics.Max;import org.elasticsearch.search.aggregations.metrics.Min;import org.elasticsearch.search.aggregations.metrics.Sum;import org.elasticsearch.search.builder.SearchSourceBuilder;import org.junit.jupiter.api.Test;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest;import java.io.IOException;import java.util.List;/*** Query DSL*/@SpringBootTestpublic class ElkApplicationTests {@Autowiredprivate RestHighLevelClient client;/***<pre>* GET /tvs/_search* {* "size": 0,* "query": {* "match_all": {}* },* "aggs": {* "group_by_color": {* "terms": {* "field": "color"* },* "aggs": {* "avg_price": {* "avg": {* "field": "price"* }* },* "max_price": {* "max": {* "field": "price"* }* },* "min_price": {* "min": {* "field": "price"* }* },* "sum_price":{* "sum": {* "field": "price"* }* }* }* }* }* }* </pre>*/@Testpublic void test() throws IOException {//创建请求SearchRequest searchRequest = new SearchRequest("tvs");//请求体SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.size(0);searchSourceBuilder.query(QueryBuilders.matchAllQuery());TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.terms("group_by_color").field("color");termsAggregationBuilder.subAggregation(AggregationBuilders.avg("avg_price").field("price"));termsAggregationBuilder.subAggregation(AggregationBuilders.max("max_price").field("price"));termsAggregationBuilder.subAggregation(AggregationBuilders.min("min_price").field("price"));termsAggregationBuilder.subAggregation(AggregationBuilders.sum("sum_price").field("price"));searchSourceBuilder.aggregation(termsAggregationBuilder);searchRequest.source(searchSourceBuilder);//发送请求SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);//获取结果Aggregations aggregations = response.getAggregations();Terms terms = aggregations.get("group_by_color");List<? extends Terms.Bucket> buckets = terms.getBuckets();for (Terms.Bucket bucket : buckets) {String key = bucket.getKeyAsString();System.out.println("key = " + key);long docCount = bucket.getDocCount();System.out.println("docCount = " + docCount);Avg avgPrice = bucket.getAggregations().get("avg_price");System.out.println("avgPrice = " + avgPrice.getValue());Max maxPrice = bucket.getAggregations().get("max_price");System.out.println("maxPrice = " + maxPrice.getValue());Min minPrice = bucket.getAggregations().get("min_price");System.out.println("minPrice = " + minPrice.getValue());Sum sumPrice = bucket.getAggregations().get("sum_price");System.out.println("sumPrice = " + sumPrice.getValue());}}}
4.4 按照售价每2000价格划分范围,算出每个区间的销售总额
- 示例:Query DSL
GET /tvs/_search{"size": 0,"query": {"match_all": {}},"aggs": {"price": {"histogram": {"field": "price","interval": 2000},"aggs": {"sum_price": {"sum": {"field": "price"}}}}}}
- 示例:
package com.sunxaiping.elk;import org.elasticsearch.action.search.SearchRequest;import org.elasticsearch.action.search.SearchResponse;import org.elasticsearch.client.RequestOptions;import org.elasticsearch.client.RestHighLevelClient;import org.elasticsearch.index.query.QueryBuilders;import org.elasticsearch.search.aggregations.AggregationBuilders;import org.elasticsearch.search.aggregations.Aggregations;import org.elasticsearch.search.aggregations.bucket.histogram.Histogram;import org.elasticsearch.search.aggregations.bucket.histogram.HistogramAggregationBuilder;import org.elasticsearch.search.aggregations.metrics.Sum;import org.elasticsearch.search.builder.SearchSourceBuilder;import org.junit.jupiter.api.Test;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest;import java.io.IOException;import java.util.List;/*** Query DSL*/@SpringBootTestpublic class ElkApplicationTests {@Autowiredprivate RestHighLevelClient client;/***<pre>* GET /tvs/_search* {* "size": 0,* "query": {* "match_all": {}* },* "aggs": {* "price": {* "histogram": {* "field": "price",* "interval": 2000* },* "aggs": {* "sum_price": {* "sum": {* "field": "price"* }* }* }* }* }* }* </pre>*/@Testpublic void test() throws IOException {//创建请求SearchRequest searchRequest = new SearchRequest("tvs");//请求体SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.size(0);searchSourceBuilder.query(QueryBuilders.matchAllQuery());HistogramAggregationBuilder histogramAggregationBuilder = AggregationBuilders.histogram("price").field("price").interval(2000);histogramAggregationBuilder.subAggregation(AggregationBuilders.sum("sum_price").field("price"));searchSourceBuilder.aggregation(histogramAggregationBuilder);searchRequest.source(searchSourceBuilder);//发送请求SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);//获取结果Aggregations aggregations = response.getAggregations();Histogram histogram = aggregations.get("price");List<? extends Histogram.Bucket> buckets = histogram.getBuckets();for (Histogram.Bucket bucket : buckets) {long docCount = bucket.getDocCount();System.out.println("docCount = " + docCount);Sum sumPrice = bucket.getAggregations().get("sum_price");System.out.println("sumPrice = " + sumPrice.getValue());}}}
5 ES7新特性之SQL
5.1 快速入门
- 示例:
POST /_sql?format=txt{"query": "SELECT * FROM tvs"}
5.2 获取结果方式
- HTTP请求。
- 客户端:elasticsearch-sql-cli.bat。
- 代码,类似于JDBC。
5.3 响应数据格式

5.4 SQL翻译
- 示例:
- 验证SQL翻译:
POST /_sql/translate{"query": "SELECT * FROM tvs"}
- 返回:
{"size" : 1000,"_source" : {"includes" : ["price"],"excludes" : [ ]},"docvalue_fields" : [{"field" : "brand"},{"field" : "color"},{"field" : "sold_date","format" : "epoch_millis"}],"sort" : [{"_doc" : {"order" : "asc"}}]}
5.5 和其他DSL的结合
- 示例:
POST /_sql?format=txt{"query": "SELECT * FROM tvs","filter":{"range": {"price": {"gte": 1000,"lte": 2000}}}}
5.6 Java代码实现SQL功能
5.6.1 前提
- 需要开启ES的白金版功能。

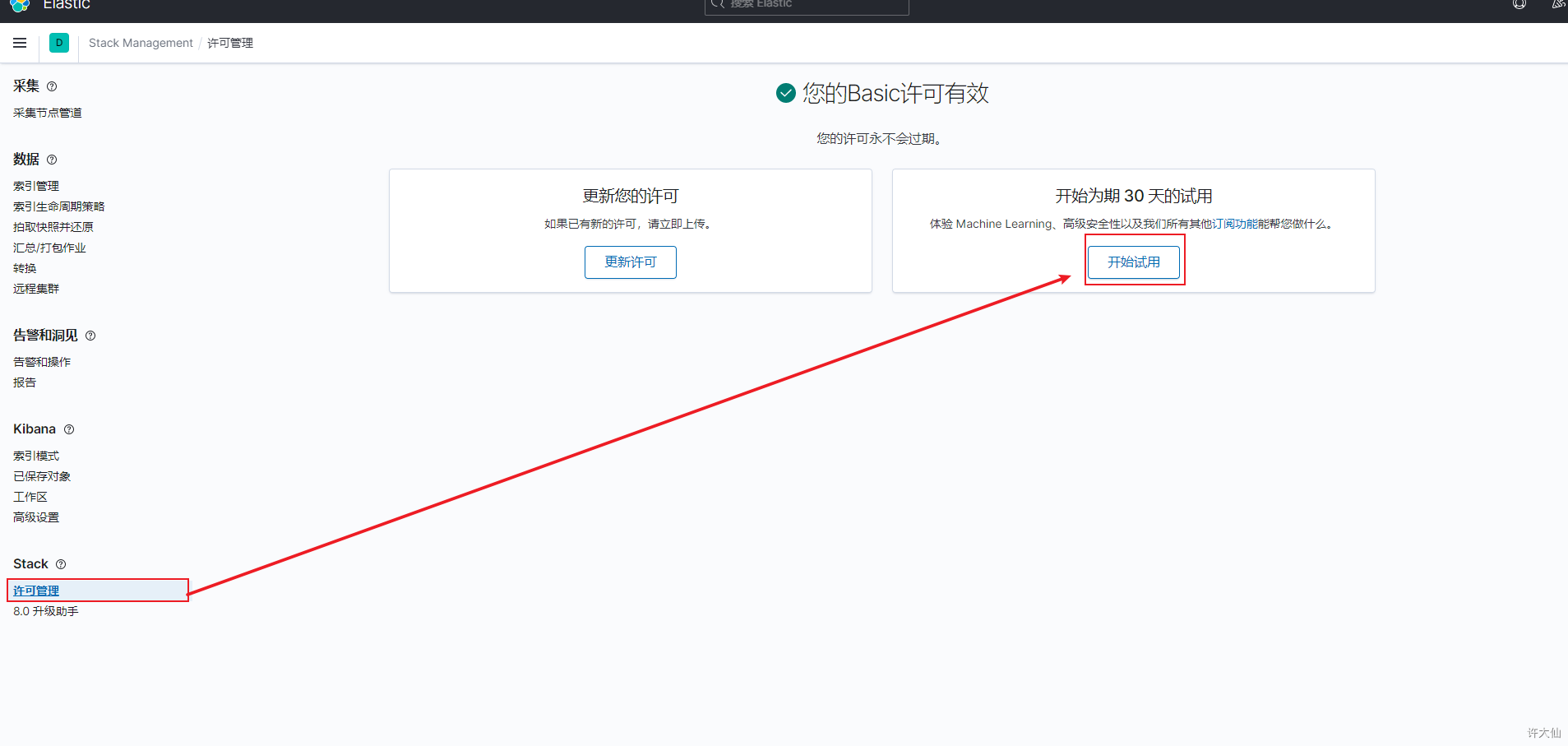
大型企业可以购买白金版,增加machine Learning,高级安全性x-pack。
5.6.2 准备工作
- 导入相关依赖:
<dependency><groupId>org.elasticsearch.plugin</groupId><artifactId>x-pack-sql-jdbc</artifactId><version>7.10.0</version></dependency>
5.6.3 应用示例
- 示例:
package com.sunxaiping.elk;import org.junit.jupiter.api.Test;import org.springframework.boot.test.context.SpringBootTest;import java.sql.*;@SpringBootTestpublic class ElkApplicationTests {@Testpublic void test() throws Exception {Class.forName("org.elasticsearch.xpack.sql.jdbc.EsDriver");Connection connection = DriverManager.getConnection("jdbc:es://http://localhost:9200");Statement statement = connection.createStatement();ResultSet resultSet = statement.executeQuery("SELECT brand,color,price,sold_date FROM tvs");while (resultSet.next()) {System.out.println(resultSet.getString(1));System.out.println(resultSet.getString(2));System.out.println(resultSet.getDouble(3));System.out.println(resultSet.getDate(4));}}}

若有收获,就点个赞吧
0 人点赞
