起因
在合并项目代码中,前面一个分支打包、出包,一气呵成,一切进行顺利,非常的nice。但是在这个紧急打包分支中,一个文件死活编译不过去。提示如下:
1>SystemMsgItem.cpp1>mainwindow\systemMsg\SystemMsgItem.cpp(1): error C2014: 预处理器命令必须作为第一个非空白空间启动1>d:\program files (x86)\microsoft visual studio 10.0\vc\include\codeanalysis\sourceannotations.h(29): error C2144: 语法错误:“__w64 unsigned int”的前面应有“;”1>d:\program files (x86)\microsoft visual studio 10.0\vc\include\codeanalysis\sourceannotations.h(29): error C4430: 缺少类型说明符 - 假定为 int。注意: C++ 不支持默认 int1>mainwindow\systemMsg\SystemMsgItem.cpp(13): error C2653: “SystemMsgItem”: 不是类或命名空间名称1>mainwindow\systemMsg\SystemMsgItem.cpp(14): error C4430: 缺少类型说明符 - 假定为 int。注意: C++ 不支持默认 int1>mainwindow\systemMsg\SystemMsgItem.cpp(14): error C2039: “TWidget”: 不是“uicontrols”的成员1>mainwindow\systemMsg\SystemMsgItem.cpp(15): error C2550: “SystemMsgItem”: 构造函数初始值设定项列表只能在构造函数定义中使用1>mainwindow\systemMsg\SystemMsgItem.cpp(16): error C2355: “this”: 只能在非静态成员函数的内部引用1>mainwindow\systemMsg\SystemMsgItem.cpp(16): error C2227: “->setFixedHeight”的左边必须指向类/结构/联合/泛型类型1>mainwindow\systemMsg\SystemMsgItem.cpp(18): error C2065: “m_ptrDel”: 未声明的标识符1>mainwindow\systemMsg\SystemMsgItem.cpp(18): error C2355: “this”: 只能在非静态成员函数的内部引
马上出包呢,出现此问题,甚是头疼啊。加班一小时,终于找到问题所在.
文件的UTF-8文件格式编码被转换成了UTF-8 BOM。
分析流程
代码审查
既然编译出了问题,就需要去分析解决问题。既然有git这个利器,当然的好好使用了。
使用内置的diff 工具进行代码比对。结果如下: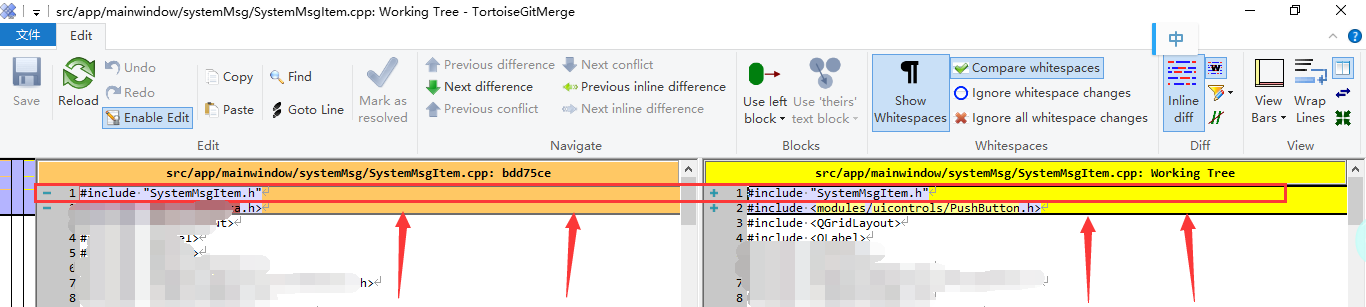
红框中并没有发现什么特别的地方。再仔细看也没什么特别的。
所以第一感觉,没什么问题。所以转去看其他问题。
排查了半个多小时,没有任何进展。所以再次回来比对文件。
第二感觉,虽然代码没有改动,但是比对结果是有差异的。
所以肯定是文件编码导致的问题。
编码问题
既然认为是编码问题,所以就要看看文件的编码,这里使用了vscode进行比对。
- 问题文件
使用vscode打开出问题的文件。vscode左下角,显示编码问题 utf-8.如图:

- 原始文件
然后使用git导出未出问题的文件,使用vscode打开。结果显示编码为UTF-8 BOM。如图

问题分析
到这里,自然就会提出一些问题
- 这两格式有什么区别呢?
- 为啥会导致这样的问题?
- 使用diff比对软件,怎么没有区分出来呢?
为了弄清楚这几个问题,我们的知道UTF-8 BOM是什么,他与UTF-8 的区别。
问题根源
BOM(byte-order mark),即字节顺序标记,它是插入到以UTF-8、UTF16或UTF-32编码Unicode文件开头的特殊标记,用来识别Unicode文件的编码类型。对于UTF-8来说,BOM并不是必须的,因为BOM用来标记多字节编码文件的编码类型和字节顺序(big-endian或little-endian)。
在绝大多数编辑器中都看不到BOM字符,因为它们能理解Unicode,去掉了读取器看不到的题头信息。
不含BOM的UTF-8才是标准形式,UTF-8不需要BOM,UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符”ZERO WIDTH NO-BREAK SPACE“的UTF-8编码是EF BB BF。所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了.
真相大白
既然知道了问题根源,所以解决也就很简单了。
- 使用utf-8 打开文件,删除掉前面的字节。然后使用utf-8进行保存。
- 使用git比对,进行代码替换。

若有收获,就点个赞吧
0 人点赞
