1.为什么gjson库会比内置库encoding/json快?(其他功能忽略,只说unsafe)
使用unsafe.Pointer破坏类型系统并读写任意内存,主要用于转换各种类型。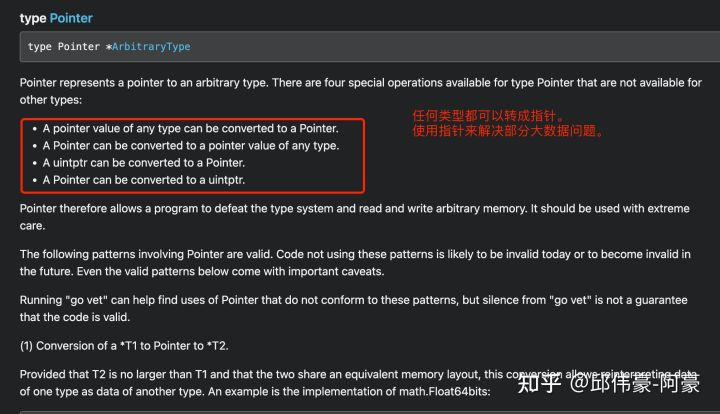
而笔者去看了一下encoding/json库,并没有发现用到unsafe。
看一组基准测试数据:
gjson的getBytes方法源码,使用unsafe。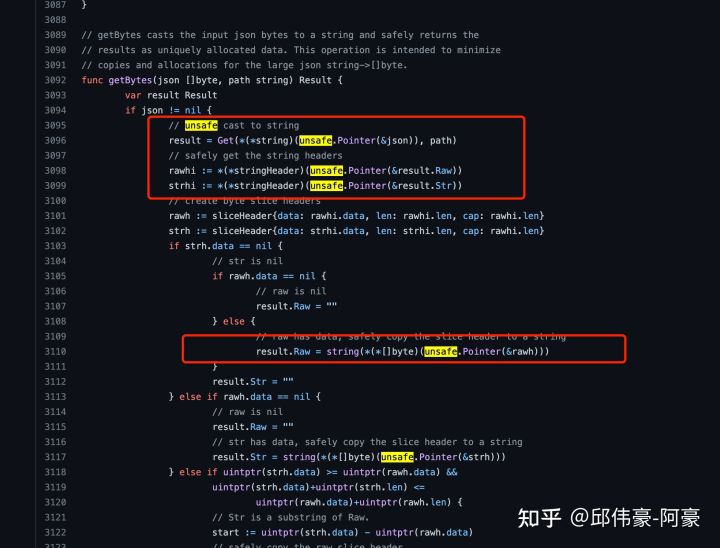
https://github.com/tidwall/gjson
easyjson的readme: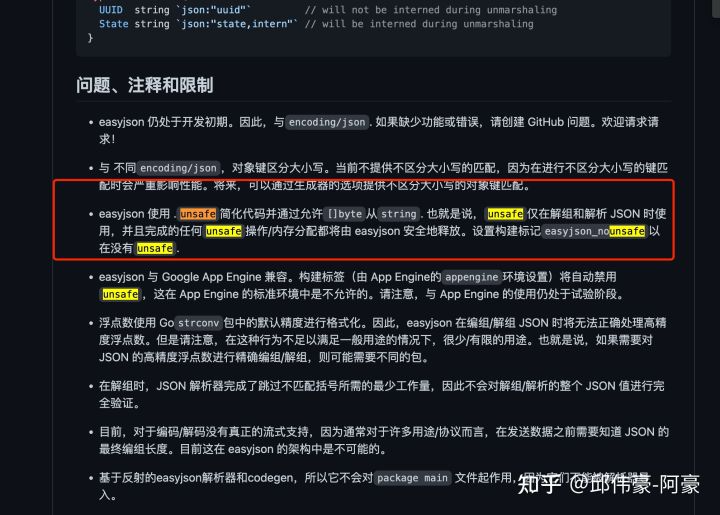
unsafe是官方提议,不安全,要小心使用。除非用来管理内存布局使用。
为什么可以做到这么快?因为使用unsafe包对内存直接进行读写, 而unsafe内置库是会绕开内存安全机制的。
官方提供:unsafe package - unsafe - Go Packages
2.如何理解unsafe 包之内存布局?
需要了解的概念和unsafe API哦:
- func Alignof(x ArbitraryType ) uintptr 对齐系数或者对齐倍数,每个字段在内存中的偏移量是对齐值的倍数
- func Sizeof(x ArbitraryType ) uintptr内存大小,2^n。如果偏移量不够,则补齐。例如某struct结构体,字段A占1个字节、字段A4个字节,则大小为1+3+4=8。
- 偏移量:计算机汇编语言,是指把存储单元的实际地址与其所在段的段地址之间的距离称为段内偏移,也称为“有效地址或偏移量”;
- func Offsetof(x ArbitraryType ) uintptr 偏移量大小
- 对齐值,此处golang的最大偏移量和内存大小有关,不同电脑有不同的值,我的是8.
不同的struct字段编排,所占有的内存不同。代码如下:
package mainimport ("fmt""unsafe")// 内存对齐影响struct的大小// struct的字段顺序影响struct的大小type user1 struct {b bytei int32j int64}type user2 struct {b bytej int64i int32}type user3 struct {i int32b bytej int64}type user4 struct {i int32j int64b byte}type user5 struct {j int64b bytei int32}type user6 struct {j int64i int32b byte}// 内存对齐影响struct的大小// struct的字段顺序影响struct的大小func main() {var u1 user1 // u1 size is 16var u2 user2 // u2 size is 24var u3 user3 // u3 size is 16var u4 user4 // u4 size is 24var u5 user5 // u5 size is 16var u6 user6 // u6 size is 16fmt.Println("u1 size is ", unsafe.Sizeof(u1))fmt.Println("u2 size is ", unsafe.Sizeof(u2))fmt.Println("u3 size is ", unsafe.Sizeof(u3))fmt.Println("u4 size is ", unsafe.Sizeof(u4))fmt.Println("u5 size is ", unsafe.Sizeof(u5))fmt.Println("u6 size is ", unsafe.Sizeof(u6))}

发现了,最后不同u1和u2内存大小不同。
结论:
1.内存对齐影响struct的大小(因为会补足到8的倍数)
2.struct的字段顺序影响struct的大小(因为)
所以有时候合理的字段顺序可以减少内存的开销。

若有收获,就点个赞吧
0 人点赞
