此系列文章收录在公众号中:数据大宇宙 > 数据处理 >E-pd
经常听别人说 Python 在数据领域有多厉害,结果学了很长时间,连数据处理都麻烦得要死。后来才发现,原来不是 Python 数据处理厉害,而是他有数据分析神器—— pandas
前言
本系列上一篇文章关于合并多个 Excel 数据,许多小伙伴似乎对此比较感兴趣,问我是否可以合并不规范的数据,本文就用他们提出的需求做一个大致讲解
奇葩格式
现实中的表格数据,可能会存在标题等无用行:

- 注意看,每个文件的表格的表头位置都不固定,并且有些是空列(估计现实中不会有这么奇葩的情况)
这里的处理思路其实很简单:
- 加载时让 pandas 不要把首行作为表头
- 查找前 n 行数据,找到内容有符合表头的行,把该行作为表头
- 把无用行与列去掉
本系列多次强调,编程语言的作用是能让你把重复逻辑封装,以便日后重复使用。
这里定义一个重置表头方法:

x_df.head(10).isin(cols).sum(axis=1)>=2 ,用表格的前10行数据,用指定的表头查找,只要某一行有大于等于2个符合的内容,则这行作为标题
x_df.columns = x_df.loc[header_idx] ,通过 DataFrame.columns 可以轻松设置其表头
x_df.iloc[header_idx+1:].loc[:,cols] ,.iloc[header_idx+1:] :获取表头后的数据。.loc[:,cols]:获取指定的列
这里涉及多种 pandas 知识,希望系统学习这些知识,我只能推荐你去看看我的 pandas 专栏
看看怎么调用吧:
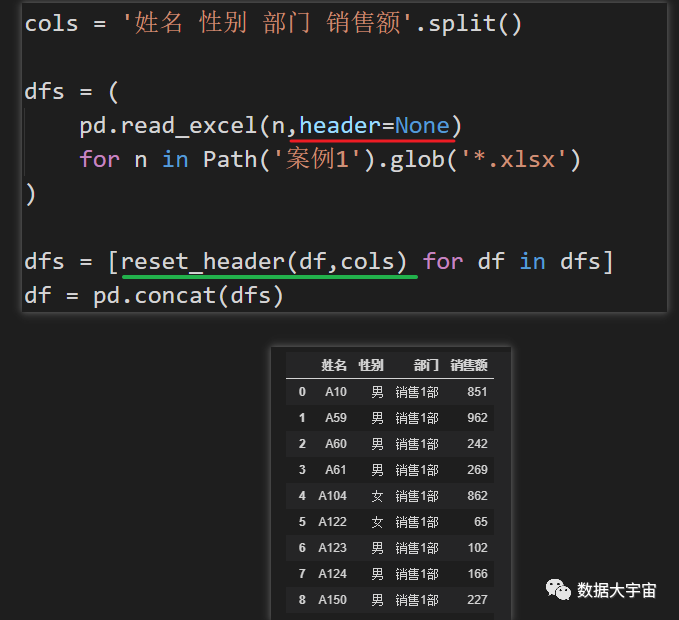
- 这里的代码与本系列上一节基本一样
- 在使用 pd.read_excel 加载数据时,设置 header=None (红线) ,让其不把任何数据设置为表头
- 加载数据后,调用之前定义的方法 reset_header 调整表格(绿线)
总结
真的不要再误以为 pandas 只能处理非常规范的数据了,这是一个类似于 Sql 的声明式数据处理分析库,同时也能使用任何命令式来细致处理数据。
“声明式数据处理”是指:不需要你编写遍历数据的逻辑代码
本文重点:
- pd.read_excel 方法中有大量参数,让你控制其加载行为。header = None 让其不把任何数据作为表头
- 充分利用 Python 的优点,不用每次都编写复杂的代码
需要源码的小伙伴,公众号发送”数据处理”
如果希望从零开始学习 pandas ,那么可以看看我的 pandas 专栏。
扫描二维码
获取更多精彩
数据大宇宙


若有收获,就点个赞吧
0 人点赞
