状态
Redis是一个内存数据库,运行在内存中,其中可能包含多个数据库以及数据库中包含多个键值对,将Redis中这些非空的数据库和其中的键值对称为状态。
Redis的数据都存放在内存中,如果不将内存中的数据库状态保存到硬盘上,那么Redis进程结束的时候,本次运行期间数据库中所有的内容都不回被保存,下次启动Redis的时候又只是一个空数据库。
为了解决这个问题,Redis使用了持久化功能,这个功能可以将Redis中的数据保存到硬盘上进行持久存储,防止数据的意外丢失。
RDB持久化
RDB持久化可以使用save命令来进行手动存储,也可以配置服务器自动定期执行存储。
RDB读取Redis的状态来得到数据库当前存储的信息,然后将其压缩为一个RDB文件;在需要恢复Redis数据库数据的时候,在从RDB文件中读取保存的信息从而恢复数据。
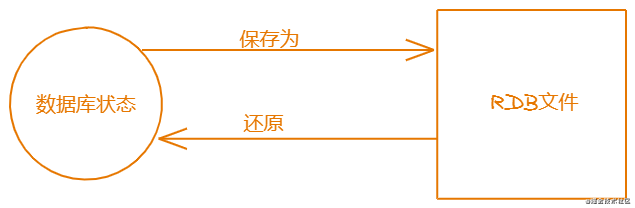
创建RDB文件
有两个命令可以来创建RDB文件,一个是SAVE、一个是BGSAVE。
- Save命令会阻塞
Redis进程,所以从Save执行直到结束,用户所有的命令都不能执行。
127.0.0.1:6379> saveOK
BGSave命令会**fork**一个子进程,然后子进程来完成RDB文件的创建,服务器进程继续执行命令请求。
127.0.0.1:6379> bgsaveBackground saving started
实际上,创建RDB的工作是由rdbSave()函数来执行的,SAVE与BGSAVE命令只是在不同的时候调用了这个函数。
伪代码如下:
function SAVE(){rdbSave(); // 直接进行调用,导致阻塞}function BGSAVE(){// 创建子进程pid = fork();if(pid==0) {// pid=0代表使用子进程来执行// 所以主进程不阻塞rdbSave();} else if (pid > 0) {# 父进程继续执行用户发送的命令....}}
自动保存RDB文件
由于BGSAVE在执行期间不阻塞用户的请求,所以可以在conf文件中设置相应的命令来使Redis自动的保存当前数据库的状态,生成RDB文件。
在conf中默认的运行BGSAVE的参数如下:
save 900 1 # 代表如果900秒以内,数据库有最少一个修改,就执行BGSAVEsave 300 10 # 如果300秒以内,数据库有最少十个修改,就执行BGSAVEsave 60 10000 # 如果60秒以内,数据库有最少10000个修改,就执行BGSAVE
可以在conf文件中配置多个save,满足其中一个则自动执行BGSAVE。
设置保存条件
服务器启动期间,读取conf文件中的save配置,生成一个保存所有save条件的数组,
struct saveparam *saveparams;struct saveparam{// save配置的秒数time_t seconds;// save配置的改变的次数int changes;}
假如配置的是:
save 900 1 # 代表如果900秒以内,数据库有最少一个修改,就执行BGSAVEsave 300 10 # 如果300秒以内,数据库有最少十个修改,就执行BGSAVEsave 60 10000 # 如果60秒以内,数据库有最少10000个修改,就执行BGSAVE
那么最终会生成:
dirty计数器+lastsave属性
dirty计数器记录了自上次成功执行SAVE或者BGSAVE以后,服务器对数据库状态修改的次数,包括添加、删除、更新等操作。
lastsave则记录了上一次执行保存操作时候的UNIX时间戳。
检查是否满足执行BGSAVE的条件
Redis有一个周期性函数serverCron默认每100ms执行一次,它的其中一个工作就是检查conf文件中save选项的条件是不是已经满足,如果满足,执行BGSAVE。
function serverCron(){.....// 遍历执行检查操作for(saveparam param:server.saveparams){int diff = now() - lastsave();// 距离上次更新的间隔时间if(diff >= param.seconds && dirty >= param.changes) {BGSAVE();}}....}
程序遍历所有的save参数,如果有一个满足,就执行BGSAVE操作。
RDB总结
RDB文件可以使服务器恢复Redis数据库的所有键值对数据。SAVE命令执行保存操作会阻塞服务器。BGSAVE命令在后台执行,不会阻塞服务器。- 在
conf中设置save参数来配置BGSAVE的执行条件。
优势
整个redis中只有这一个备份文件,不用经常进行备份。
适合大规模的数据恢复。性能最大化。
通过fork子进程来持久化,同时主进程又能继续处理客户端的请求。
相较于AOF机制,如果数据集很大,启动时数据恢复效率更高更快。
劣势
如果服务器突然宕机,还未来得及持久化的数据将会丢失。
如果对数据完整性要求较高,不建议采用这种方式。
由于是fork了一个与当前进程一样的进程,包含当前进程的所有数据,所以,内存中的数据增加了一倍,性能会有所影响。
AOF
RDB保存的是数据库的状态,而AOF保存的是Redis执行的所有写操作(读操作对数据库状态没有影响,不需要进行记录)。

当服务器执行:
127.0.0.1:6379> set msg vmsOK127.0.0.1:6379> sadd schools qinghua beida ustc(integer) 3127.0.0.1:6379> rpush numbers 1 2 3(integer) 3
AOF文件中保存的是:
*2$6SELECT$10*3$3set$3msg$3vms*5$4sadd$7schools$7qinghua$5beida$4ustc*5$5rpush$7numbers$11$12$13
这些命令都是刚才执行过的写命令,当Redis服务器再次启动的时候,就可以从AOF文件中复原数据库的状态。
AOF追加实现方式
- 命令追加
当AOF命令处于打开的时候,服务器执行完一个写命令后,会将执行的写命令按照所规定的格式加入到AOF_BUF缓冲区的末尾。 - 写入与同步
Redis服务器就是一个事件的循环,其中
- 文件事件:接受客户端的命令请求
- 时间事件:执行需要定时执行的命令
每次服务器结束一个文件事件的时候,由于可能执行写命令,这会让一些内容被追加到AOF_BUF缓冲区中(设置缓冲区的目的是为了提高文件的写入效率,将需要写入的数据暂存到内存缓冲区,缓冲区满或者超过一定时间时候才将数据写入硬盘),所以每次在文件事件结束的时候,都会调用flushAppendOnlyFile函数,来决定时都需要将AOF_BUF缓冲区的内容加入到AOF文件中。
伪代码:
function eventLoop(){while(true){// 处理文件事件processFileEvents();// 处理时间事件processTimeEvents();// 决定是否将aof缓冲区内容写入aof文件flushAppendOnlyFile();}}
flushAppendOnlyFile根据conf的配置来决定何时来执行AOF。
# appendfsync always # AOF_BUF的所有内容都加入AOF文件appendfsync everysec # 每一秒钟将AOF_BUF的文件加入AOF文件# appendfsync no # 何时加入来由操作系统决定
appendfsync always如果突然断电,最多会丢失一次事件循环已经执行的命令,因为每次执行完毕都会写入到AOF,但是因为每次都写入AOF文件,所以效率稍低。appendfsync everysec最多丢失一秒内执行的命令appendfsync no丢失的命令数量=上次写入到AOF以后执行命令的次数。
数据还原
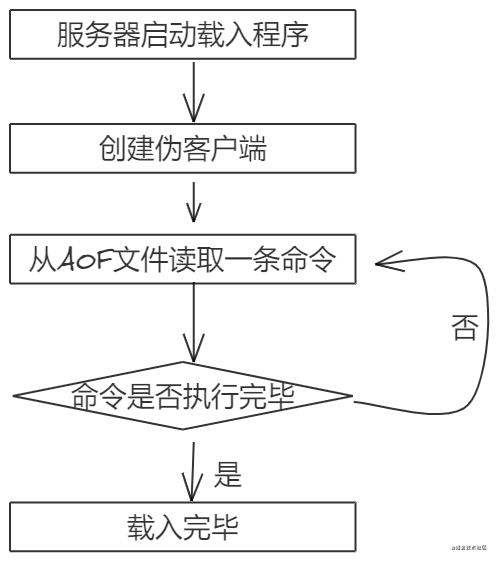
Redis读取AOF文件的步骤如下:
- 创建一个伪客户端,因为
Redis命令只能在客户端上下文中执行,而载入AOF文件中的命令来源于AOF而不是来自客户端,所以创建一个伪客户端来执行AOF中的命令。 - 从AOF读取一条写入命令
- 伪客户端执行这个命令
- 重复2-3直到AOF文件中的命令执行完毕。
AOF重写
如果AOF文件体积过大,那么通常会影响服务器性能,可以通过一些操作来缓解这种情况。
例如如下命令:
127.0.0.1:6379> RPUSH list A B # [A,B](integer) 2127.0.0.1:6379> RPUSH list C # [A,B,C](integer) 3127.0.0.1:6379> RPUSH list D E # [A,B,C,D,E](integer) 5127.0.0.1:6379> LPOP list # [B,C,D,E]"A"127.0.0.1:6379> LPOP list # [C,D,E]"B"127.0.0.1:6379> RPUSH list F G # [C,D,E,F,G](integer) 5
其实这些都可以用一条命令
RPUSH list C,D,E,F,G
AOF实现这个功能的操作就是重写。
重写的实现
AOF重写并不需要对现有的AOF文件进行读取分析,而是直接读取服务器的状态来实现。
当执行这些指令来以后:
127.0.0.1:6379> RPUSH list A B # [A,B](integer) 2127.0.0.1:6379> RPUSH list C # [A,B,C](integer) 3127.0.0.1:6379> RPUSH list D E # [A,B,C,D,E](integer) 5127.0.0.1:6379> LPOP list # [B,C,D,E]"A"127.0.0.1:6379> LPOP list # [C,D,E]"B"127.0.0.1:6379> RPUSH list F G # [C,D,E,F,G](integer) 5
如果想要实现AOF文件体积的最小化,那么就可以直接从数据库读取list键对应的值,可以得到:C,D,E,F,G。
所以AOF重写可以概括为:
- 从数据库读取键现在的值
- 用一条命令(例如
RPUSH list C,D,E,F,G)去记录这个键值对来代替之前的多条的命令。
整个过程:
function aof_rewrite(newfilename){f = create_file(newfilename); // 新的aof文件for(Database db: server.Databases){if(db.empty) continue; // 当前数据库空,跳过for(Key k:keys){ // 遍历所有的keyif key.is_expired() continue;f.write(k); // 写入key以及key对应的数据}}f.close();}
- AOF重写是通过子进程实现的
因为使用的是子进程,那么子进程对AOF重写的时候,服务器可能处理新的数据,改变AOF开始重写时刻以后的数据库状态,那么可能会导致当前数据库状态和重写后AOF记录的服务器状态不一致。
为了解决这个问题,Redis设置了一个AOF重写缓冲区,这个缓冲区在子进程之后开始使用,Redis执行完一个写命令以后,同时将这个写命令发送给AOF缓冲区和AOF重写缓冲区,这样可以保障:从子进程创建开始,所有的写命令都会被记录到AOF重写缓冲区。
当子进程完成后,给父进程发送信号,父进程调用信号处理函数,并执行:
- 将AOF重写缓冲区的内容写到写的AOF中,保证数据的一致性。
- 对新的AOF文件换名,原子性的覆盖现有的AOF文件,完成新旧AOF文件的替换。
优劣势
优势
更高的数据安全性和完整性。
默认情况下每秒同步,最多丢失一秒的数据。
后台异步的,效率非常高。
提供Redis-check-aof --fix机制,确保数据正确性。
劣势
AOF文件相较于RDB文件大得多,数据恢复效率低。
AOF虽然是后台异步fsync追加日志文件,无论是每秒同步还是每修改同步,都是消耗一部分性能。
如果同时开启两种持久化方式,redis重启时会采用AOF文件来恢复数据。因为AOF文件保存的数据比RDB要完整,RDB丢失数据的风险要大一些。
参考

若有收获,就点个赞吧
0 人点赞
