第一个Stream例子
- 创建一个js文件:
``typescript const fs = require('fs') const stream = fs.createWriteStream('big_file.txt') //实际上可以理解为 这个stream可以往这个bigfile文件里面写东西 for(let i=0; i<100000; i++){ stream.write(这是第${i}行内容,我们需要很多很多内容,要不停地写文件aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa 回车\n`) }
stream.end() //别忘了关掉stream console.log(‘done’)
2. 运行该文件<br />会创建一个big_file.txt (大小:100多MB)<br /><a name="wSKiG"></a>## 分析- 打开流,多次往里面塞内容, 关闭流每次塞是不会覆盖之前的内容的,每次都是分开的- 看起来就是可以多次而已,没什么特别- 但是最终得到一个100多MB的文件<a name="g7oDy"></a># Stream - 流<a name="wWfPp"></a>## 图解: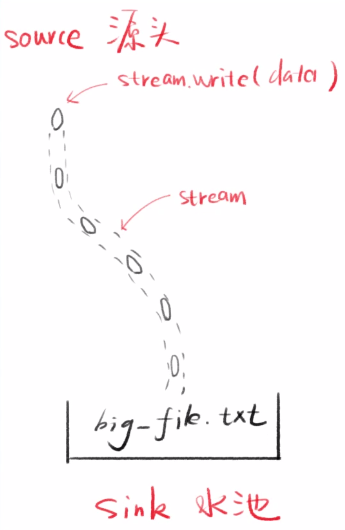<a name="Z7Gbo"></a>## 释义:结合上面的代码看- stream是水流,但默认没有水- stream.write 可以让水流中有水(数据)- 每次写的小数据叫做chunk(块)- 产生数据的一段叫做source(源头)- 得到数据的一段叫做sink(水池)chunk 数据块<br />为什么不叫data呢<br />data一般表示完整的数据,chunk只是一块数据<a name="wG1RJ"></a># 第二个例子1. 创建2.js文件```typescriptconst fs = require('fs')const http = require('http')const server = http.createServer()server.on('request',(request,response)=>{//读上面创建的big_file.txt,放到response里面fs.readFile('./big_file.txt',(error,data)=>{if(error) throw errorresponse.end(data)console.log('done')})})server.listen(8888)console.log(`8888`)
- 运行2.js

- 访问8888端口
分析
- 用任务管理器看看 Node.js 内存占用,大概130Mb
big_file 120Mb + node.js本身8Mb
- 内存占用太多了,这就是不用stream的缺点
一个用户的请求就用了100mb内存,那么10个用户,100个用户,服务器很难撑得住
- 用steam就可以解决这个问题,用stream改写这个例子
第三个例子
用stream改写第二个例子
const fs = require('fs')const http = require('http')const server = http.createServer()server.on('request',(request,response)=>{// 用流的形式去读bigFilefs.createReadStream('./big_file.txt')// 通过管道pipe将读完的bigFile传给responsestream.pipe(response)stream.on('end', ()=>console.log('done'))})server.listen(8888)console.log(`8888`)
运行该文件后,可以使用 $ curl http://localhost:8888 去请求这个bigFile
一边请求一边打开任务管理器看看占用的内存有多少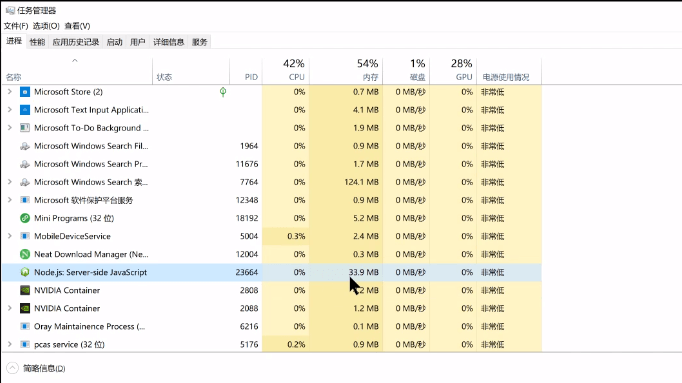
一般会稳定到30多MB,直到传完
分析
跟第二个例子对比:
节省了很多的内存,而且时间并不会非常长
- 查看node.js内存占用,基本不会高于40Mb
- 文件stream 和 response stream 通过管道相连
- 意思是 stream是一个流,response也是一个流,他们通过pipe管道连起来

- stream1 相当于 读文件的stream
- stream2 相当于 http发回给用户的response stream
- 1和2本来是没什么关系的,但是我们用了一个管道 把他们接起来了。那么stream1的数据都会自动地流向stream2。
释义
两个流可以用一个管道相连
stream1的末尾连接上stream2的开端
只要stream1有数据,就会流到stream2
常用代码
stream1.pipe(stream2)
链式操作
a.pipe(b).pipe(c)//等价于a.pipe(b)b.pipe(c)
管道
管道可以通过事件实现
//stream1一有数据就塞给stream2stream1.on('data',(chunk)=>{stream2.write(chunk)})//stream1停了,就停掉stream2stream1.on('end',()=>{stream2.end()})
- 监听stream1的on data事件,一旦触发,就把chunk数据写到stream2上
- 监听stream1的on end事件,stream1 end, stream2 也end
一般不这样写,因为写这么多代码,还不如写一个pipe
小结
- stream可以使你的内存降得非常低,从100多mb降到30多mb
比如说你有一个3g的文件,nodejs对于内存的大小使用是有限制的,3g的文件根本读不到内存里的,但是如果使用流,可以一点一点地读。当然你也可以控制每次读多少
- 管道
可以将两个流连起来,连起来之后就可以实现数据在不同的地方的转换
比如上面的例子:从文件转换到网络

若有收获,就点个赞吧
0 人点赞
