Golang笔记
1.基础
单例
var instance *singletonvar once sync.Oncefunc GetInstance() *singleton {once.Do(func() {instance = &singleton{}})return instance}
保留双引号
fmt.Println("This is", strconv.Quote("studygolang.com"), "website")
// Output: This is "studygolang.com" website
unicode码和中文之间的转换
func main() {
sText := "中文"
textQuoted := strconv.QuoteToASCII(sText)
fmt.Println("textQuoted:", textQuoted) // "\u4e2d\u6587"
textUnquoted := textQuoted[1 : len(textQuoted)-1]
fmt.Println(textUnquoted) // \u4e2d\u6587
sUnicodev := strings.Split(textUnquoted, "\\u")
fmt.Println("sUnicodev:", sUnicodev) // [ 4e2d 6587]
var context string
for _, v := range sUnicodev {
if len(v) < 1 {
continue
}
temp, err := strconv.ParseInt(v, 16, 32)
if err != nil {
panic(err)
}
context += fmt.Sprintf("%c", temp)
}
fmt.Println(context) // 中文
}
按行读取文本
func main() {
textfile := "a.txt"
file, err := os.Open(textfile)
if err != nil {
panic(err)
}
defer file.Close()
scanner := bufio.NewScanner(file)
for scanner.Scan() {
line := scanner.Text()
fmt.Println(line)
}
if err := scanner.Err(); err != nil {
fmt.Println("Cannot scanner text file: %s, err: [%v]", textfile, err)
return
}
}
md5,base64
import (
"crypto/md5"
"encoding/base64"
"encoding/hex"
"fmt"
)
func main() {
fmt.Println(EncodeMD5("123456"))
fmt.Println(base64.StdEncoding.EncodeToString([]byte("abc")))
dst, err := base64.StdEncoding.DecodeString("YWJj")
fmt.Println(string(dst), err)
}
func EncodeMD5(value string) string {
m := md5.New()
m.Write([]byte(value))
return hex.EncodeToString(m.Sum(nil))
}
打印函数名、文件名、行号
func runFuncLog() {
//层级从0开始到3
funcName, file, line, ok := runtime.Caller(0)
if ok {
fmt.Println("func name: " + runtime.FuncForPC(funcName).Name()) //func name: main.runFuncLog
fmt.Printf("file: %s, line: %d\n", file, line) //file: C:/Data/GoProject/study/src/example/demo.go, line: 41
}
}
json、map、struct转换
// 1. json,struct互转
json.Marshal()
json.Unmarshal()
// 2.1 json转map
jsonStr := `
{
"name": "jqw",
"age": 18
}
`
var resultMap map[string]interface{}
json.Unmarshal([]byte(jsonStr), &resultMap)
fmt.Println(resultMap)
// 2.2 map转json
mapInstances := []map[string]interface{}{}
instance1 := map[string]interface{}{"name": "John", "age": 10}
instance2 := map[string]interface{}{"name": "Alex", "age": 12}
mapInstances = append(mapInstances, instance1, instance2)
jsonStr, err := json.Marshal(mapInstances)
if err == nil {
fmt.Println(string(jsonStr))
}
// 3.1 struct转map
func struct2Map() {
var m map[string]interface{}
person := Person{
Id: 1,
Name: "Tom",
}
d, _ := json.Marshal(person)
json.Unmarshal(d, &m)
fmt.Println(m)
}
// 3.2 map转struct
func map2Struct() {
var m = make(map[string]interface{})
m["name"] = "Tom"
m["id"] = 18
bs, _ := json.Marshal(m)
var person = Person{}
json.Unmarshal(bs, &person)
fmt.Println(person)
}
type Person struct {
Id int `json:"id"`
Name string `json:"name"`
}
使用json.Unmarshal() 反序列化时,出现了科学计数法
jsonStr := `{"number":1234567}`
result := make(map[string]interface{})
err := json.Unmarshal([]byte(jsonStr), &result)
if err != nil {
fmt.Println(err)
}
fmt.Println(result)
// 输出
// map[number:1.234567e+06]
当数据结构未知,使用map[string]interface{}来接收反序列化结果时,如果数字的位数大于 6 位,都会变成科学计数法,用到的地方都会受到影响。
方案一
强制类型转换
jsonStr := `{"number":1234567}`
result := make(map[string]interface{})
err := json.Unmarshal([]byte(jsonStr), &result)
if err != nil {
fmt.Println(err)
}
fmt.Println(int(result["number"].(float64)))
// 输出
// 1234567
方案二
尽量避免使用interface,对json字符串结构定义结构体,快捷方法可使用在线工具:https://mholt.github.io/json-to-go/。
type Num struct {
Number int `json:"number"`
}
jsonStr := `{"number":1234567}`
var result Num
err := json.Unmarshal([]byte(jsonStr), &result)
if err != nil {
fmt.Println(err)
}
fmt.Println(result)
// 输出
// {1234567}
方案三
使用UseNumber()方法。
jsonStr := `{"number":1234567}`
result := make(map[string]interface{})
d := json.NewDecoder(bytes.NewReader([]byte(jsonStr)))
d.UseNumber()
err := d.Decode(&result)
if err != nil {
fmt.Println(err)
}
fmt.Println(result)
// 输出
// map[number:1234567]
这时一定要注意result["number"]的数据类型!
fmt.Println(fmt.Sprintf("type: %v", reflect.TypeOf(result["number"])))
// 输出
// type: json.Number
通过代码可以看出json.Number其实就是字符串类型
如果转换其他类型,参考如下代码:
// 转成 int64
numInt, _ := result["number"].(json.Number).Int64()
fmt.Println(fmt.Sprintf("value: %v, type: %v", numInt, reflect.TypeOf(numInt)))
// 输出
// value: 1234567, type: int64
// 转成 string
numStr := result["number"].(json.Number).String()
fmt.Println(fmt.Sprintf("value: %v, type: %v", numStr, reflect.TypeOf(numStr)))
// 输出
// value: 1234567, type: string
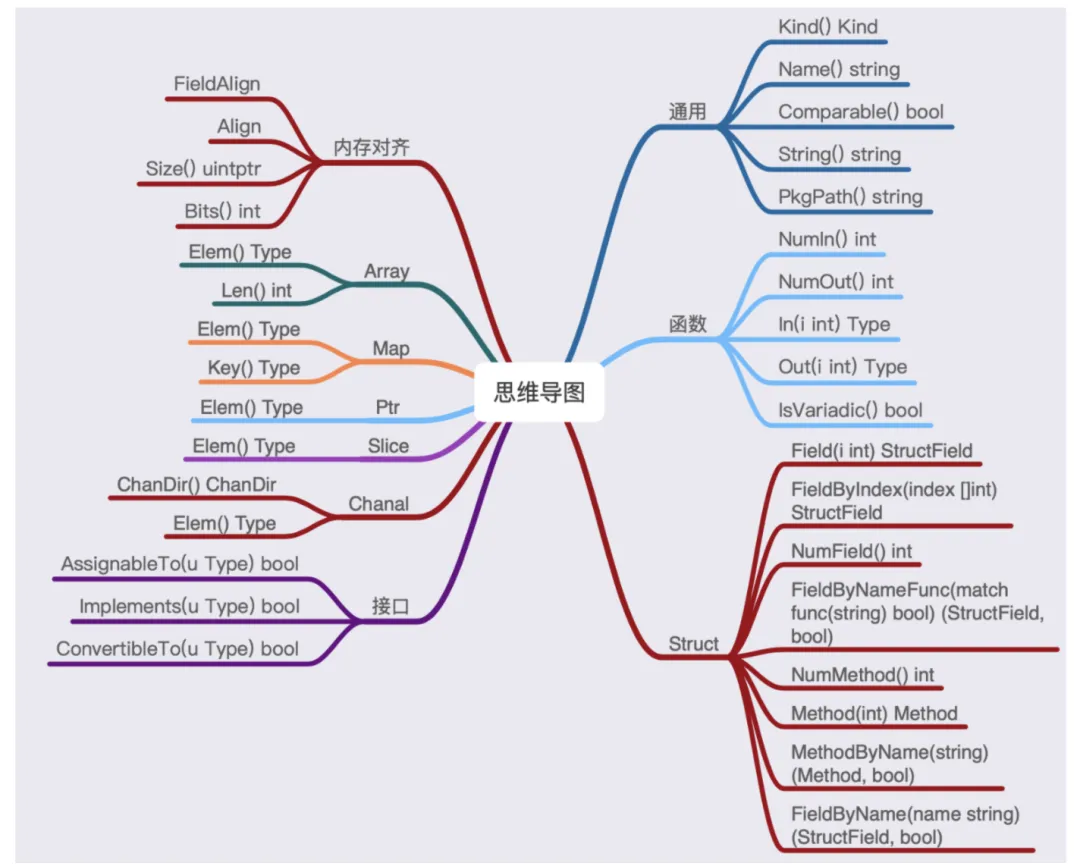
反射reflect的使用
reflect.Type和reflect.Value是反射的两大基本要素,他们的关系如下:
- 任意类型都可以转换成
Type和Value Value可以转换成TypeValue可以转换成Interface
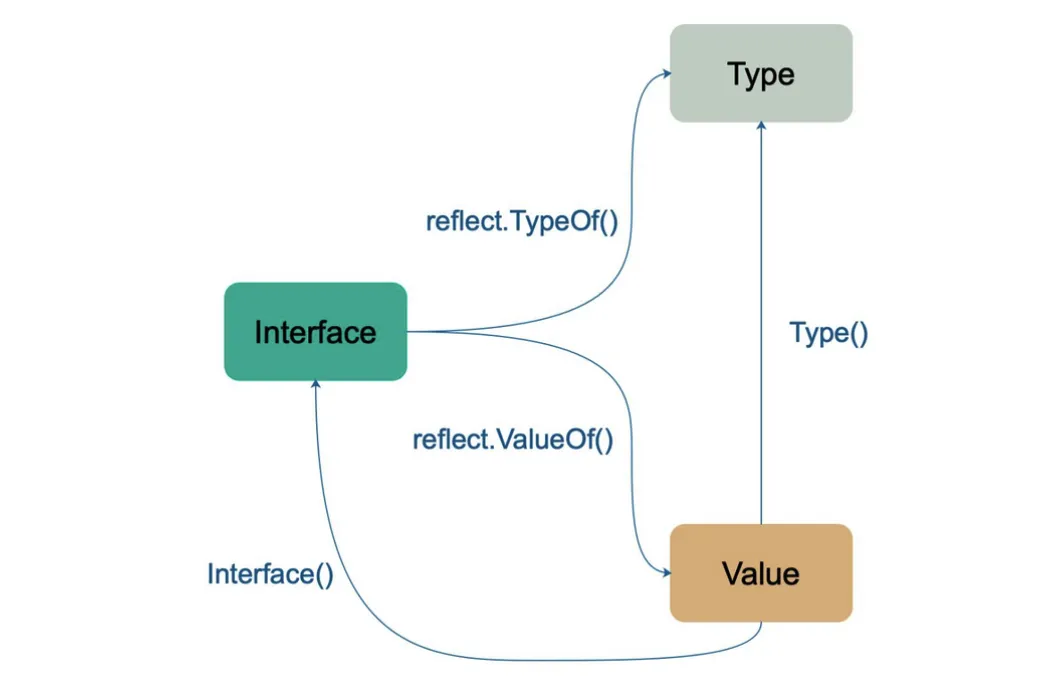
reflect.Type实际上是一个接口,它提供很多api(方法)让你获取变量的各种信息。比如对于数组提供了Len和Elem两个方法分别获取数组的长度和元素。
import (
"fmt"
"reflect"
)
type Dog struct {
Name string
Age int
}
func (dog *Dog) Eat() {
fmt.Printf("%s is eating.", dog.Name)
}
func (dog *Dog) Run() {
fmt.Printf("%s is running.", dog.Name)
}
func (dog Dog) Sleep() {
fmt.Printf("%s is sleeping.", dog.Name)
}
func (dog Dog) Jump() {
fmt.Printf("%s is jumping.", dog.Name)
}
func main() {
doggy := Dog{"doggy", 2}
checkFieldAndMethod(doggy)
fmt.Println("")
tommy := &Dog{"tommy", 2}
checkFieldAndMethod(tommy)
}
func checkFieldAndMethod(input interface{}) {
inputType := reflect.TypeOf(input)
fmt.Println("Type of input is :", inputType.Name())
inputValue := reflect.ValueOf(input)
fmt.Println("Value of input is :", inputValue)
// 如果input原始类型时指针,通过Elem()方法或者Indirect()获取指针指向的值
if inputValue.Kind() == reflect.Ptr {
inputValue = inputValue.Elem()
// inputValue = reflect.Indirect(inputValue)
fmt.Println("Value input points to is :", inputValue)
}
//使用NumField()得到结构体中字段的数量,遍历得到字段的值Field(i)和类型Field(i).Type()
for i := 0; i < inputValue.NumField(); i++ {
field := inputValue.Type().Field(i)
value := inputValue.Field(i).Interface()
fmt.Printf("%s: %v = %v\n", field.Name, field.Type, value)
}
// 获取方法
for i := 0; i < inputType.NumMethod(); i++ {
m := inputType.Method(i)
fmt.Printf("%s: %v\n", m.Name, m.Type)
}
}
// Output:
//Type of input is : Dog
//Value of input is : {doggy 2}
//Name: string = doggy
//Age: int = 2
//Jump: func(main.Dog)
//Sleep: func(main.Dog)
//
//Type of input is :
//Value of input is : &{tommy 2}
//Value input points to is : {tommy 2}
//Name: string = tommy
//Age: int = 2
//Eat: func(*main.Dog)
//Jump: func(*main.Dog)
//Run: func(*main.Dog)
//Sleep: func(*main.Dog)
反射第一定律: 反射可以将interface类型变量转换成反射对象
func main() {
var x float64 = 3.4
t := reflect.TypeOf(x) //t is reflext.Type
fmt.Println("type:", t)
v := reflect.ValueOf(x) //v is reflext.Value
fmt.Println("value:", v)
}
注意: 反射是针对interface类型变量的, 其中 TypeOf() 和 ValueOf() 接受的参数都是 interface{} 类型的, 也
即x值是被转成了interface传入的。
反射第二定律: 反射可以将反射对象还原成interface对象
func main() {
var x float64 = 3.4
v := reflect.ValueOf(x) //v is reflext.Value
var y float64 = v.Interface().(float64)
fmt.Println("value:", y)
}
对象x转换成反射对象v, v又通过Interface()接口转换成interface对象, interface对象通过.(float64)类
型断言获取float64类型的值。
反射第三定律: 反射对象可修改, value值必须是可设置的
func main() {
var x float64 = 3.4
v := reflect.ValueOf(x)
v.SetFloat(5.6) // panic: reflect: reflect.Value.SetFloat using unaddressable value
// 错误原因即是v是不可修改的。
}
func main() {
var x float64 = 3.4
v := reflect.ValueOf(&x)
v.Elem().SetFloat(5.6)
fmt.Println("x: ", v.Elem().Interface())
}
net包
构造一个简单的 Redis Server (支持多线程),实现了支持Redis协议的简易Key-Value操作(可以使用Redis-cli直接验证):
package main
import (
"bufio"
"fmt"
"io"
"net"
"strconv"
"strings"
"sync"
)
var KVMap sync.Map
func main() {
// 构造一个listener
listener, _ := net.Listen("tcp", "127.0.0.1:6379")
defer func() { _ = listener.Close() }()
for {
// 接收请求
conn, _ := listener.Accept()
// 连接的处理
go FakeRedis(conn)
}
}
// 这里做了io 读写操作,并解析了 Redis 的协议
func FakeRedis(conn net.Conn) {
defer conn.Close()
reader := bufio.NewReader(conn)
for {
data, _, err := reader.ReadLine()
if err == io.EOF {
return
}
paramCount, _ := strconv.Atoi(string(data[1:]))
var params []string
for i := 0; i < paramCount; i++ {
_, _, _ = reader.ReadLine() // 每个参数的长度,这里忽略了
sParam, _, _ := reader.ReadLine()
params = append(params, string(sParam))
}
switch strings.ToUpper(params[0]) {
case "GET":
if v, ok := KVMap.Load(params[1]); !ok {
conn.Write([]byte("$-1\r\n"))
} else {
conn.Write([]byte(fmt.Sprintf("$%d\r\n%v\r\n", len(v.(string)), v)))
}
case "SET":
KVMap.Store(params[1], params[2])
conn.Write([]byte("+OK\r\n"))
case "COMMAND":
conn.Write([]byte("+OK\r\n"))
}
}
}
获取本机IP
func GetLocalIP() (ip string, err error) {
addrs, err := net.InterfaceAddrs()
if err != nil {
return
}
for _, addr := range addrs {
ipAddr, ok := addr.(*net.IPNet)
if !ok {
continue
}
if ipAddr.IP.IsLoopback() {
continue
}
if !ipAddr.IP.IsGlobalUnicast() {
continue
}
return ipAddr.IP.String(), nil
}
return
}
位运算的配置用法
conf是一个使用位掩码的方式指定多重转换配置的整数。
const (
UPPER = 1 << iota // 大写字符串
LOWER // 小写字符串
CAP // 字符串单词首字母大写
REV // 反转字符串
)
func main() {
//fmt.Println(UPPER, LOWER, CAP, REV) // 1 2 4 8
fmt.Println(procstr("HELLO PEOPLE!", LOWER|REV|CAP)) // !elpoeP olleH
}
func procstr(str string, conf byte) string {
// 反转字符串
rev := func(s string) string {
runes := []rune(s)
n := len(runes)
for i := 0; i < n/2; i++ {
runes[i], runes[n-1-i] = runes[n-1-i], runes[i]
}
return string(runes)
}
if (conf & UPPER) != 0 {
str = strings.ToUpper(str)
}
if (conf & LOWER) != 0 {
str = strings.ToLower(str)
}
if (conf & CAP) != 0 {
str = strings.Title(str)
}
if (conf & REV) != 0 {
str = rev(str)
}
return str
}
procstr("HELLO PEOPLE!", LOWER|REV|CAP) 方法会把字符串变成小写,然后反转字符串,最后把字符串里面的单词首字母变成大写。
通过设置 conf 里的第二,三,四位的值为 14 来完成的。然后代码使用连续的 if 语句块来获取这些位操作进行对应的字符串转换。
信号量
// Semaphore 数据结构,并且还实现了Locker接口
type semaphore struct {
sync.Locker
ch chan struct{}
}
// 创建一个新的信号量
func NewSemaphore(capacity int) sync.Locker {
if capacity <= 0 {
capacity = 1 // 容量为1就变成了一个互斥锁
}
return &semaphore{ch: make(chan struct{}, capacity)}
}
// 请求一个资源
func (s *semaphore) Lock() {
s.ch <- struct{}{}
}
// 释放资源
func (s *semaphore) Unlock() {
<-s.ch
}
func main() {
sem := NewSemaphore(4)
for i := 0; i < 16; i++ {
sem.Lock()
go work(sem, i)
}
}
func work(sem sync.Locker, i int) {
defer sem.Unlock()
time.Sleep(time.Second)
fmt.Printf("work %d is running.\n", i+1)
}
发送邮件
package main
import (
"crypto/tls"
"errors"
"fmt"
"github.com/jordan-wright/email"
"net/smtp"
"time"
)
func main() {
config := NewEmailConfig()
go func() {
if err := Sendmail(`<a href="http://www.baidu.com">this is email content</a>`, true, config); err != nil {
fmt.Printf("send maile error: %v\n", err) // 打印log
}
}()
time.Sleep(10 * time.Second)
fmt.Println(time.Now(), "main is end.")
}
type ConfigEmail struct {
Account string // 帐号(xxx@qq.com)
Password string // 密码(xxxyyy)
Server string // 服务器地址(smtp.qq.com)
Port string // 服务器端口(465)
From string // 发件人(个人提醒 <xxx@qq.com>)
To []string // 收件人(yyy@qq.com)
Cc []string // 抄送人(zzz@qq.com)
Subject string // 标题(告警提醒)
}
func NewEmailConfig() ConfigEmail {
return ConfigEmail{
Account: "xxx@qq.com",
Password: "xxxyyy",
Server: "smtp.qq.com",
Port: "465",
From: "个人提醒 <xxx@qq.com>",
To: []string{"yyy@qq.com"},
Subject: "告警提醒",
}
}
// 发送邮件
func Sendmail(content string, isHtml bool, conf ConfigEmail) (err error) {
defer func() {
if er := recover(); er != nil {
err = errors.New(fmt.Sprintf("panic: %v", er))
}
}()
// 校验参数不能为空
if conf.Account == "" || conf.Password == "" || conf.Server == "" || conf.Port == "" || conf.From == "" || len(conf.To) == 0 {
err = errors.New("invalid param")
return
}
e := email.NewEmail()
e.From = conf.From
e.To = conf.To
e.Cc = conf.Cc
e.Subject = conf.Subject
if isHtml {
e.HTML = []byte(content)
} else {
e.Text = []byte(content)
}
addr := conf.Server + ":" + conf.Port
auth := smtp.PlainAuth("", conf.Account, conf.Password, conf.Server)
if err = e.SendWithTLS(addr, auth, &tls.Config{ServerName: conf.Server}); err != nil {
err = errors.New(fmt.Sprintf("send mail error: %s", err))
}
return
}
其它库:
gomail
标准化错误处理
package errcode
import (
"fmt"
"net/http"
)
var (
Success = NewError(0, "成功")
ServerError = NewError(1000, "服务内部错误")
InvalidParams = NewError(1001, "入参错误")
NotFound = NewError(1002, "找不到")
UnauthorizedAuthNotExist = NewError(1003, "鉴权失败,找不到对应的AppKey和AppSecret")
UnauthorizedTokenError = NewError(1004, "鉴权失败,Token错误")
UnauthorizedTokenTimeout = NewError(1005, "鉴权失败,Token超时")
UnauthorizedTokenGenerate = NewError(1006, "鉴权失败,Token生成失败")
TooManyRequests = NewError(1007, "请求过多")
)
type Error struct {
code int `json:"code"`
msg string `json:"msg"`
details []string `json:"details"`
}
var codes = map[int]string{}
func NewError(code int, msg string) *Error {
if _, ok := codes[code]; ok {
panic(fmt.Sprintf("错误码[%d]已存在", code))
}
codes[code] = msg
return &Error{code: code, msg: msg}
}
func (e *Error) String() string {
return fmt.Sprintf("错误码:[%d], 错误信息:[%s]", e.code, e.msg)
}
func (e *Error) Code() int {
return e.code
}
func (e *Error) Msg() string {
return e.msg
}
func (e *Error) Msgf(args []interface{}) string {
return fmt.Sprintf(e.msg, args...)
}
func (e *Error) Details() []string {
return e.details
}
func (e *Error) WithDetails(details ...string) {
e.details = details
}
func (e *Error) StatusCode() int {
switch e.code {
case Success.code:
return http.StatusOK
case ServerError.code:
return http.StatusInternalServerError
case InvalidParams.code:
return http.StatusBadRequest
case UnauthorizedAuthNotExist.code:
fallthrough
case UnauthorizedTokenError.code:
fallthrough
case UnauthorizedTokenGenerate.code:
fallthrough
case UnauthorizedTokenTimeout.code:
return http.StatusUnauthorized
case TooManyRequests.code:
return http.StatusTooManyRequests
}
return http.StatusInternalServerError
}
枚举iota
package main
import "fmt"
func main() {
fmt.Println(COMPLETED)
fmt.Println(RUNNING)
fmt.Println(STOPPED)
fmt.Println(PENDING)
}
// status.go
type Status int
const (
RUNNING Status = iota
PENDING
STOPPED
COMPLETED
)
var StatusMap = map[Status]string{
RUNNING: "Running",
PENDING: "Pending",
STOPPED: "Stopped",
COMPLETED: "Completed",
}
func (s Status) String() string {
if res, ok := StatusMap[s]; ok {
return res
}
return "Unknown"
}
使用redis生成分布式唯一ID
package main
import (
"fmt"
"github.com/go-redis/redis"
"sync"
"time"
)
var client *redis.Client
func init() {
client = redis.NewClient(&redis.Options{
Addr: "127.0.0.1:6379",
DB: 0,
})
}
func main() {
for i := 0; i < 10; i++ {
go func() {
fmt.Println(GetUid())
}()
}
time.Sleep(2 * time.Second)
}
// uid.go
var (
once sync.Once
uidKey = "crontab:uid"
defaultUid int64 = 1000000
)
func GetUid() int64 {
once.Do(setDefaultUid)
return client.Incr(uidKey).Val()
}
func setDefaultUid() {
id, err := client.Get(uidKey).Int64()
if err != nil || id == 0 {
newid := client.Set(uidKey, defaultUid, -1)
if newid.Err() != nil {
panic(newid.Err().Error())
}
}
}
2.应用
选项设计模式
在rpcx 框架中,func NewServer(options …OptionFn) *Server方法先实例化一个Server,然后再设置启动选项,一共提供了 3个 OptionFn 来设置启动选项:
// NewServer returns a server.
func NewServer(options ...OptionFn) *Server {
s := &Server{
Plugins: &pluginContainer{},
options: make(map[string]interface{}),
activeConn: make(map[net.Conn]struct{}),
doneChan: make(chan struct{}),
serviceMap: make(map[string]*service),
}
for _, op := range options {
op(s)
}
return s
}
type OptionFn func(*Server)
// WithTLSConfig sets tls.Config.
func WithTLSConfig(cfg *tls.Config) OptionFn {
return func(s *Server) {
s.tlsConfig = cfg
}
}
// WithReadTimeout sets readTimeout.
func WithReadTimeout(readTimeout time.Duration) OptionFn {
return func(s *Server) {
s.readTimeout = readTimeout
}
}
// WithWriteTimeout sets writeTimeout.
func WithWriteTimeout(writeTimeout time.Duration) OptionFn {
return func(s *Server) {
s.writeTimeout = writeTimeout
}
}
装饰器的使用
装饰器(decorator)是一个这样的函数:它的参数是具体类型的函数,并且返回值也是和参数相同类型的函数。 看下面的例子:
type StringOperator func(string) string
func ident(s string) string {
return s
}
func ToUpper(m StringOperator) StringOperator {
return func(s string) string {
lower := strings.ToUpper(s)
return m(lower)
}
}
func ToMd5(m StringOperator) StringOperator {
return func(s string) string {
h := md5.New()
h.Write([]byte(s))
b64 := base64.StdEncoding.EncodeToString(h.Sum(nil))
return m(b64)
}
}
ToUpper和ToMd5都接受func(string) string作为参数,并且返回和参数相同的类型func(string) string。 调用情况:
func TestDecorator1(t *testing.T) {
s := "Hello, World"
var fn1 StringOperator = ident
fn1 = ToMd5(ToUpper(ident))
fmt.Println(fn1(s))
var fn2 StringOperator = ident
fn2 = ToUpper(ToMd5(fn2))
fmt.Println(fn2(s))
}
net/http的http.HandleFunc也用到了装饰器模式。
type HandlerFunc func(ResponseWriter, *Request)
调用者可以自己设置http的调用链。
func hello(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hello, World! "+r.URL.Path)
}
func WithLog(h http.HandlerFunc) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
log.Printf("Recieved Request %s from %s\n", r.URL.Path, r.RemoteAddr)
h(w, r)
}
}
func TestHttp(t *testing.T) {
http.HandleFunc("/hello", WithLog(hello))
err := http.ListenAndServe(":8080", nil)
if err != nil {
log.Fatal("ListenAndServe: ", err)
}
}
装饰器的流水线(Pipeline)
有时候,多层的调用可能会导致代码不好阅读,例如ToMd5(ToUpper(ident))。这时候可以改成:
type Decorator func(StringOperator) StringOperator
func Handler(m StringOperator, decorators ...Decorator) StringOperator {
for i := len(decorators) - 1; i > 0; i-- {
m = decorators[i](m)
}
return m
}
func TestDecorator(t *testing.T) {
s := "Hello, World"
fn := Handler(ident, ToUpper, ToMd5)
fmt.Println(fn(s))
}
设置默认参数
Golang中,函数不支持设置默认参数,可以使用类似装饰器的方法来设置。 看下面的例子,通过WithNum和WithString来指定参数。
type Param struct {
p1 int
p2 OptionParam
}
type OptionParam struct {
a int
b string
}
func defaultOptionParam() OptionParam {
option := OptionParam{
a: 10,
b: "const",
}
return option
}
type SetOption func(option *OptionParam)
func WithNum(num int) SetOption {
return func(option *OptionParam) {
option.a = num
}
}
func WithString(str string) SetOption {
return func(option *OptionParam) {
option.b = str
}
}
func SetParams(p1 int, setOptions ...SetOption) Param {
option := defaultOptionParam() // set default value in the beginning
// custom
for _, set := range setOptions {
set(&option)
}
return Param{
p1: p1,
p2: option,
}
}
重试
- client
func main() {
for {
// 内层循环:1秒的心跳服务
for {
err := ping()
if err != nil {
goto RETRY
}
time.Sleep(time.Second)
}
// 外层循环:重试
RETRY:
fmt.Println("retry ping func:", time.Now())
time.Sleep(5 * time.Second)
}
}
func ping() error {
url := "http://localhost:5000"
resp, err := http.Get(url)
if err != nil {
fmt.Println("get error:", err)
return err
}
defer resp.Body.Close()
bs, _ := ioutil.ReadAll(resp.Body)
fmt.Println(time.Now(), "recv:", string(bs))
return nil
}
- server
func main() {
r := gin.Default()
r.GET("/", func(c *gin.Context) {
c.String(200, "Home")
return
})
r.Run(":5000")
}
插件的设计
package plugin
import "github.com/opentracing/opentracing-go"
// Plugin defines the standard for all plug-ins
type Plugin interface {
}
// ResolverPlugin defines the standard for all server discovery plug-ins
type ResolverPlugin interface {
Init(...Option) error
}
// TracingPlugin defines the standard for all tracing plug-ins
type TracingPlugin interface {
Init(...Option) (opentracing.Tracer, error)
}
// PluginMap defines a global plug-in map
var PluginMap = make(map[string]Plugin)
// Register opens an entry point for all plug-ins to register
func Register(name string, plugin Plugin) {
if PluginMap == nil {
PluginMap = make(map[string]Plugin)
}
PluginMap[name] = plugin
}
// Options for all plug-ins
type Options struct {
SvrAddr string // server address
Services []string // service arrays
SelectorSvrAddr string // server discovery address ,e.g. consul server address
TracingSvrAddr string // tracing server address,e.g. jaeger server address
}
// Option provides operations on Options
type Option func(*Options)
// WithSvrAddr allows you to set SvrAddr of Options
func WithSvrAddr(addr string) Option {
return func(o *Options) {
o.SvrAddr = addr
}
}
// WithSvrAddr allows you to set Services of Options
func WithServices(services []string) Option {
return func(o *Options) {
o.Services = services
}
}
// WithSvrAddr allows you to set SelectorSvrAddr of Options
func WithSelectorSvrAddr(addr string) Option {
return func(o *Options) {
o.SelectorSvrAddr = addr
}
}
// WithSvrAddr allows you to set TracingSvrAddr of Options
func WithTracingSvrAddr(addr string) Option {
return func(o *Options) {
o.TracingSvrAddr = addr
}
}
server 加载插件配置
(1)在 Server 中添加 plugins 成员变量,它是一个插件数组。
// gorpc Server, a Server can have one or more Services
type Server struct {
opts *ServerOptions
services map[string]Service
plugins []plugin.Plugin
}
(2)当调用 server.New 函数时,遍历插件 PluginMap,将所有插件 Plugin 添加到 plugins 中去。
func NewServer(opt ...ServerOption) *Server{
s := &Server {
opts : &ServerOptions{},
services: make(map[string]Service),
}
for _, o := range opt {
o(s.opts)
}
for pluginName, plugin := range plugin.PluginMap {
if !containPlugin(pluginName, s.opts.pluginNames) {
continue
}
s.plugins = append(s.plugins, plugin)
}
return s
}
(3)在调用 Server.Serve() 方法时,在 server 中的所有 service 提供服务之前,调用 InitPlugins 方法进行插件的配置初始化。
func (s *Server) Serve() {
err := s.InitPlugins()
if err != nil {
panic(err)
}
for _, service := range s.services {
go service.Serve(s.opts)
}
ch := make(chan os.Signal, 1)
signal.Notify(ch, syscall.SIGTERM, syscall.SIGINT, syscall.SIGQUIT, syscall.SIGSEGV)
<-ch
s.Close()
}
我们来看看 InitPlugins 这个方法的具体实现:
func (s *Server) InitPlugins() error {
// init plugins
for _, p := range s.plugins {
p.Init()
}
return nil
}
它的主要功能是遍历所有的插件,并进行配置初始化。这里在后面具体实现服务发现、负载均衡等插件时,配置初始化的地方有变动,这里后面再进行讲解。
插件注册
const Name = "consul"
func init() {
plugin.Register(Name, ConsulSvr)
...
}
var ConsulSvr = &Consul {
opts : &plugin.Options{},
}
实现 Plugin 接口
func (c *Consul) Init(opts ...plugin.Option) error {
...
// 一些 consul 初始化逻辑
}
我们实现了一个名字为 consul 的插件。server 在初始化时会遍历 PluginMap,拿到注册的插件 list。然后调用插件自身的 Init 方法进行插件初始化。这样就实现了将插件 ”插入“ 到框架中运行。实现了可插拔。
定时计划表
在定时计划表中,获取最近的时间点,计算休眠时间
package main
import (
"fmt"
"github.com/gorhill/cronexpr"
"time"
)
type jobPlan struct {
name string
expr *cronexpr.Expression
nextTime time.Time
}
func main() {
var (
now = time.Now()
expr *cronexpr.Expression
)
expr = cronexpr.MustParse("*/10 * * * * * *")
p1 := jobPlan{"job1", expr, expr.Next(now)}
expr = cronexpr.MustParse("*/2 * * * * * *")
p2 := jobPlan{"job2", expr, expr.Next(now)}
expr = cronexpr.MustParse("*/5 * * * * * *")
p3 := jobPlan{"job3", expr, expr.Next(now)}
plans := []jobPlan{p1, p2, p3}
rt := scheduleAfter(plans)
fmt.Println("sleep:", rt)
time.Sleep(rt)
}
func scheduleAfter(plans []jobPlan) time.Duration {
var (
now = time.Now()
nearTime time.Time
)
// 假设一个plan的执行时间少于现在
// plans[1].nextTime = now.Add(-7 * time.Second)
fmt.Printf("NOW:%s\n", now)
for _, plan := range plans {
// 判断nextTime是否比now更早,再根据now更新下一次执行时间
if plan.nextTime.Before(now) || plan.nextTime.Equal(now) {
//scheduler.TryStartJob(jobPlan)
plan.nextTime = plan.expr.Next(now) //更新nextTime的时间点
}
// 到这里nextTime大于now,计算与nearTime的差值,用于休眠时间
if nearTime.Unix() < 0 || plan.nextTime.Before(nearTime) {
nearTime = plan.nextTime
fmt.Printf("update near time: next[%s] near[%s]\n", plan.nextTime, nearTime)
}
fmt.Printf("Plan: next:[%s], near:[%s]\n", plan.nextTime, nearTime)
fmt.Println()
}
afterTime := nearTime.Sub(now)
return afterTime
}
// output
//NOW:2020-04-14 15:17:56.8097952 +0800 CST m=+0.043002401
//update near time: next[2020-04-14 15:18:00 +0800 CST] near[2020-04-14 15:18:00 +0800 CST]
//Plan: next:[2020-04-14 15:18:00 +0800 CST], near:[2020-04-14 15:18:00 +0800 CST]
//
//update near time: next[2020-04-14 15:17:58 +0800 CST] near[2020-04-14 15:17:58 +0800 CST]
//Plan: next:[2020-04-14 15:17:58 +0800 CST], near:[2020-04-14 15:17:58 +0800 CST]
//
//Plan: next:[2020-04-14 15:18:00 +0800 CST], near:[2020-04-14 15:17:58 +0800 CST]
//
//sleep: 1.1902048s
优雅地重启或停止http.Server
通过捕捉 os.Interrupt 信号 (Ctrl+C) 然后调用 server.Shutdown 方法告知服务器应停止接受新的请求并在处理完当前已接受的请求后关闭服务器。
为了与普通错误相区别,标准库提供了一个特定的错误类型 http.ErrServerClosed,我们可以在代码中通过判断是否为该错误类型来确定服务器是正常关闭的还是意外关闭的。
- http server
import (
"context"
"log"
"net/http"
"os"
"os/signal"
)
type helloHandler struct{}
func (_ *helloHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("Hello world!"))
}
func main() {
mux := http.NewServeMux()
mux.Handle("/", &helloHandler{}) // 需要实现Handler接口的ServeHTTP方法
server := &http.Server{
Addr: ":10000",
Handler: mux,
}
// 创建系统信号接收器
quit := make(chan os.Signal)
signal.Notify(quit, os.Interrupt)
// signal.Notify(quit, syscall.SIGTERM, syscall.SIGINT, syscall.SIGQUIT, syscall.SIGSEGV)
go func() {
<-quit
if err := server.Shutdown(context.Background()); err != nil {
log.Fatal("Shutdown server:", err)
}
}()
log.Println("Starting HTTP server...")
err := server.ListenAndServe()
if err != nil {
if err == http.ErrServerClosed {
log.Print("Server closed under request")
} else {
log.Fatal("Server closed unexpected")
}
}
}
- Gin http server
import (
"context"
"github.com/gin-gonic/gin"
"log"
"net/http"
"os"
"os/signal"
"time"
)
func main() {
router := gin.Default()
router.GET("/", func(c *gin.Context) {
c.String(200, "hello")
return
})
server := &http.Server{
Addr: ":10000",
Handler: router,
}
go func() {
// 启动http server
if err := server.ListenAndServe(); err != nil && err != http.ErrServerClosed {
log.Fatalf("listen: %s\n", err)
}
}()
// 等待中断信号以优雅地关闭服务器
quit := make(chan os.Signal)
signal.Notify(quit, os.Interrupt)
<-quit
log.Println("Shutdown Server ...")
// 设置 5 秒的超时时间
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
if err := server.Shutdown(ctx); err != nil {
log.Fatal("Server Shutdown:", err)
}
log.Println("Server exiting")
}
Redis数据结构
> auth abc123 // 登陆
> select 3 // 选择DB
- List
lpush:
lpop:
llen:
del:
exists:
- Hash:
hset:
hmset: 设置多个域
> hmset user:1000 username antirez birthyear 1977 verified 1
OK
> hget user:1000 username
"antirez"
> hget user:1000 birthyear
"1977"
> hgetall user:1000
1) "username"
2) "antirez"
3) "birthyear"
4) "1977"
5) "verified"
6) "1"
// 对单个域增加10
> hincrby user:1000 birthyear 10
- Set (并集,差集,获取随机元素)
sadd: 添加
sismember: 检测成员
smembers: 列出所有成员
spop: 取出一个成员
scard: 数量
sinter: 交集
sunionstore: 对多个集合取并集,并把结果存入另一个set中
- sunionstore game:1:deck deck
- Sorted sets (score set)
zadd: 添加
> zadd hackers 1940 "Alan Kay"
> zadd hackers 1957 "Sophie Wilson"
zrange: 升序列出所有成员
> zrange hackers 0 -1
zrevrange: 降序列出所有成员
> zrevrange hackers 0 -1
zremrangebyscore: 移除
zrank: 排名
zrangebylex: 按字典排序
etcd作为服务注册
package registry
import (
"context"
"fmt"
"go.etcd.io/etcd/clientv3"
"net"
"strings"
)
var (
prefix = "etcdv3_resolver"
deRegChan = make(chan struct{})
)
func Register(target, service, host, port string, ttl int) (err error) {
serviceValue := net.JoinHostPort(host, port)
serviceKey := fmt.Sprintf("/%s/%s/%s", prefix, service, serviceValue)
cli, err := clientv3.New(clientv3.Config{
Endpoints: strings.Split(target, ","),
})
if err != nil {
return err
}
resp, err := cli.Grant(context.Background(), int64(ttl))
if err != nil {
fmt.Println("etcd grant error:", err)
return err
}
if _, err = cli.Put(context.Background(), serviceKey, serviceValue, clientv3.WithLease(resp.ID)); err != nil {
fmt.Println("etcd put key error:", err)
return err
}
if _, err = cli.KeepAlive(context.Background(), resp.ID); err != nil {
fmt.Println("etcd keepalive error:", err)
return err
}
go func() {
<-deRegChan
cli.Delete(context.Background(), serviceKey)
deRegChan <- struct{}{}
fmt.Println("go run unregister.")
}()
return nil
}
func UnRegister() {
deRegChan <- struct{}{}
<-deRegChan // 等待关闭
close(deRegChan)
fmt.Println("unregister...")
}
package main
import (
"awesomeProject/src/etcd-demo/registry"
"context"
"flag"
"fmt"
"github.com/sirupsen/logrus"
pb "github.com/wwcd/grpc-lb/cmd/helloworld"
"google.golang.org/grpc"
"net"
"os"
"os/signal"
"syscall"
"time"
)
var (
serv = flag.String("service", "hello_service", "service name")
host = flag.String("host", "localhost", "listening host")
port = flag.String("port", "50001", "listening port")
reg = flag.String("reg", "http://localhost:2379", "register etcd address")
)
func main() {
flag.Parse()
lis, err := net.Listen("tcp", net.JoinHostPort(*host, *port))
if err != nil {
panic(err)
}
err = registry.Register(*reg, *serv, *host, *port, 15)
if err != nil {
panic(err)
}
ch := make(chan os.Signal, 1)
signal.Notify(ch, syscall.SIGTERM, syscall.SIGINT, syscall.SIGKILL, syscall.SIGHUP, syscall.SIGQUIT)
go func() {
s := <-ch
fmt.Printf("receive signal '%v'\n", s)
registry.UnRegister()
os.Exit(1)
}()
fmt.Printf("starting hello service at %s\n", *port)
s := grpc.NewServer()
pb.RegisterGreeterServer(s, &server{})
s.Serve(lis)
}
// server is used to implement helloworld.GreeterServer.
type server struct{}
// SayHello implements helloworld.GreeterServer
func (s *server) SayHello(ctx context.Context, in *pb.HelloRequest) (*pb.HelloReply, error) {
logrus.Infof("%v: Receive is %s\n", time.Now(), in.Name)
return &pb.HelloReply{Message: "Hello " + in.Name + " from " + net.JoinHostPort(*host, *port)}, nil
}
// Output:
starting hello service at 50001
receive signal 'interrupt'
go run unregister.
unregister...
定时器
设定超时器
func WaitChannel(conn <-chan string) bool {
timer := time.NewTimer(time.Second)
select {
case <-conn:
timer.Stop()
return true
case <-timer.C:
fmt.Println("WaitChannel timeout!")
return false
}
}
WaitChannel作用就是检测指定的管道中是否有数据到来, 通过select语句轮询conn和timer.C两个管道, timer
会在1s后向timer.C写入数据, 如果1s内conn还没有数据, 则会判断为超时。
延迟执行某个方法
func DelayFunction() {
timer := time.NewTimer(5 * time.Second)
select {
case <-timer.C:
fmt.Println("Delay 5s, start to do something.")
}
}
DelayFunction()会一直等待timer的事件到来才会执行后面的方法(打印)
After()
func AfterDemo() {
fmt.Println("Start:", time.Now())
<-time.After(time.Second)
fmt.Println("End:", time.Now())
}
AfterFunc()
func AfterFuncDemo() {
fmt.Println("after function start. ", time.Now())
time.AfterFunc(time.Second, func() {
fmt.Println("after function end.", time.Now())
})
time.Sleep(2 * time.Second) // 等待协程结束
}
time.AfterFunc()是异步执行的, 所以需要在函数最后sleep等待指定的协程退出, 否
则可能函数结束时协程还未执行。
简单定时任务
func TickerDemo() {
ticker := time.NewTicker(time.Second)
defer ticker.Stop()
for range ticker.C {
fmt.Println("Ticker tick.")
}
}
for range ticker.C 会持续从管道中获取事件, 收到事件后打印一行日志, 如果管道中没有数据会阻塞
等待事件, 由于ticker会周期性的向管道中写入事件, 所以上述程序会周期性的打印日志。
定时聚合任务
公交车发车场景:
- 公交车每隔5分钟发一班, 不管是否已坐满乘客;
- 已坐满乘客情况下, 不足5分钟也发车;
// TickerLaunch用于演示ticker聚合任务用法
func TickerLaunch() {
ticker := time.NewTicker(5 * time.Millisecond)
maxPassenger := 30
passengers := make([]string, 0, maxPassenger)
for {
passenger := GetNewPassenger() // 获取一个新乘客
if passenger != "" {
passengers = append(passengers, passenger)
} else {
time.Sleep(time.Second)
}
select {
case <-ticker.C: // 时间到, 发车
fmt.Println("时间到...")
Launch(passengers)
passengers = []string{}
default:
if len(passengers) >= maxPassenger { // 时间没到, 车已座满, 发车
fmt.Println("人数满...")
Launch(passengers)
passengers = []string{}
}
}
}
}
上面代码中for循环负责接待乘客上车, 并决定是否要发车。 每当乘客上车, select语句会先判断ticker.C中是否
有数据, 有数据则代表发车时间已到, 如果没有数据, 则判断车是否已坐满, 坐满后仍然发车。
简单接口
func Tick(d Duration) <-chan Time
这个函数内部实际还是创建一个Ticker, 但并不会返回出来, 所以没有手段来停止该Ticker。 所以, 一定要考虑具
体的使用场景。
func WrongTicker() {
for {
select {
case <-time.Tick(time.Second):
fmt.Println("Resource leak!")
}
}
}
上面代码, select每次检测case语句时都会创建一个定时器, for循环又会不断的执行select语句, 所以系统里会
有越来越多的定时器不断的消耗CPU资源, 最终CPU会被耗尽。
Ticker相关内容总结如下:
- 使用time.NewTicker()来创建一个定时器;
- 使用Stop()来停止一个定时器;
- 定时器使用完毕要释放, 否则会产生资源泄露;
导致goroutine或内存泄露的场景
time.After
这是很多人实际遇到过的内存泄露场景。如下代码:
func ProcessMessage(ctx context.Context, in <-chan string) {
for {
select {
case s, ok := <-in:
if !ok {
return
}
// handle `s`
case <-time.After(5 * time.Minute):
// do something
case <-ctx.Done():
return
}
}
}
在标准库 time.After 的文档中有一段说明:
等待持续时间过去,然后在返回的 channel 上发送当前时间。它等效于 NewTimer().C。在计时器触发之前,计时器不会被垃圾收集器回收。
所以,如果还没有到 5 分钟,该函数返回了,计时器就不会被 GC 回收,因此出现了内存泄露。因此大家使用 time.After 时一定要仔细,一般建议不用它,而是使用 time.NewTimer:
func ProcessMessage(ctx context.Context, in <-chan string) {
idleDuration := 5 * time.Minute
idleDelay := time.NewTimer(idleDuration)
// 这句必须的
defer idleDelay.Stop()
for {
idleDelay.Reset(idleDuration)
select {
case s, ok := <-in:
if !ok {
return
}
// handle `s`
case <-idleDelay.C:
// do something
case <-ctx.Done():
return
}
}
}
发送到 channel 阻塞导致 goroutine 泄露
假如存在如下的程序:
func process(term string) error {
// 创建一个在 100 ms 内取消的 context
ctx, cancel := context.WithTimeout(context.Background(), 100*time.Millisecond)
defer cancel()
// 为 goroutine 创建一个传递结果的 channel
ch := make(chan string)
// 启动一个 goroutine 来寻找记录,然后得到结果
// 并将返回值从 channel 中传回
go func() {
ch <- search(term)
}()
select {
case <-ctx.Done():
return errors.New("search canceled")
case result := <-ch:
fmt.Println("Received:", result)
return nil
}
}
// search 模拟成一个查找记录的函数
// 在查找记录时。执行此工作需要 200 ms。
func search(term string) string {
time.Sleep(200 * time.Millisecond)
return "some value"
}
这是一个挺常见的场景:要进行一些耗时操作,因此开启一个 goroutine 进行处理,它的处理结果,通过 channel 回传给原来的 goroutine;同时,这个耗时操作不能太长,因此有了 WithTimeout Context。最后通过 select-case 来监控 ctx.Done 和传递数据的 channel是否就绪。
如果超时没处理完,ctx.Done 会执行,函数返回,新开启的 goroutine 会因为 channel 中的另一端没有就绪的接收 goroutine 而一直阻塞,导致 goroutine 泄露。
解决这种因为发送到 channel 阻塞导致 goroutine 泄露的简单办法是将 channel 改为有缓冲的 channel,并保证容量充足。比如上面例子,将 ch 改为:ch := make(chan string, 1) 即可。
从 channel 接收阻塞导致 goroutine 泄露
func (u *User) SendMessage(ctx context.Context) {
for msg := range u.MessageChannel {
wsjson.Write(ctx, u.conn, msg)
}
}
for-range 循环直到 MessageChannel 这个 channel 关闭才会结束,因此需要有地方调用 close(u.MessageChannel)。
这种情况的另一种情形是:虽然没有 for-range,但给 channel 发送数据的一方已经不再发送数据了,接收的一方还在等待,这个等待会无限持续下去。唯一能取消它等待的就是 close 这个 channel。
3.功能组件
简单日志模块
package log
import (
"bytes"
"fmt"
"log"
"os"
)
const (
NULL = iota
TRACE = 1
DEBUG = 2
INFO = 3
WARNGING = 4
ERROR = 5
FATAL = 6
)
const DefaultLogPath = "gorpc.log"
// general log interface for gorpc
type Log interface {
Trace(v ...interface{})
Debug(v ...interface{})
Info(v ...interface{})
Warning(v ...interface{})
Error(v ...interface{})
Fatal(v ...interface{})
Tracef(format string, v ...interface{})
Debugf(format string, v ...interface{})
Infof(format string, v ...interface{})
Warningf(format string, v ...interface{})
Errorf(format string, v ...interface{})
Fatalf(format string, v ...interface{})
}
type logger struct{
*log.Logger
options *Options
}
var DefaultLog *logger
func init() {
logFile, err := os.OpenFile(DefaultLogPath, os.O_CREATE|os.O_RDWR|os.O_APPEND, 0666)
if err != nil {
fmt.Println("open file, error : ", err)
}
DefaultLog = &logger {
Logger : log.New(logFile, "", log.LstdFlags|log.Lshortfile),
options : &Options{
level: 2,
},
}
}
type Level int
func (level Level) String() string {
switch level {
case TRACE :
return "trace"
case DEBUG :
return "debug"
case INFO :
return "info"
case WARNGING :
return "warning"
case ERROR :
return "error"
case FATAL :
return "fatal"
default :
return "unkown"
}
return "unknown"
}
type Options struct {
path string `default:"../log/gorpc.log"` // 日志文件路径前缀,文件名为 gorpc.4019-09-46.log
frame string `default:"../log/frame.log"` // 框架 panic 日志打印路径,默认 ../log/frame.log
level Level `default:"debug"` // 日志级别,默认为 debug
}
type Option func(*Options)
// set the log path
func WithPath(path string) Option {
return func(o *Options) {
o.path = path
}
}
// set the frame log path
func WithFrame(frame string) Option {
return func(o *Options) {
o.frame = frame
}
}
// set the log level
func WithLevel(level Level) Option {
return func(o *Options) {
o.level = level
}
}
// Trace print trace log
func Trace(v ...interface{}) {
DefaultLog.Trace(v...)
}
// Tracef print a formatted trace log
func Tracef(format string, v ...interface{}) {
DefaultLog.Tracef(format, v...)
}
func (log *logger) Trace(v ...interface{}) {
if log.options.level > TRACE {
return
}
data := log.Prefix() + fmt.Sprint(v...)
Output(log, 4,"[TRACE] ", data)
}
func (log *logger) Tracef(format string, v ...interface{}) {
if log.options.level > TRACE {
return
}
data := log.Prefix() + fmt.Sprintf(format,v...)
Output(log, 4,"[TRACE] ", data)
}
// Debug print debug log
func Debug(v ...interface{}) {
DefaultLog.Debug(v...)
}
// Debugf print a formatted debug log
func Debugf(format string, v ...interface{}) {
DefaultLog.Debugf(format, v...)
}
func (log *logger) Debug(v ...interface{}) {
if log.options.level > DEBUG {
return
}
data := log.Prefix() + fmt.Sprint(v...)
Output(log, 4,"[DEBUG] ", data)
}
func (log *logger) Debugf(format string, v ...interface{}) {
if log.options.level > DEBUG {
return
}
data := log.Prefix() + fmt.Sprintf(format,v...)
Output(log, 4,"[DEBUG] ", data)
}
// Info print info log
func Info(v ...interface{}) {
DefaultLog.Info(v...)
}
// Infof print a formatted info log
func Infof(format string, v ...interface{}) {
DefaultLog.Infof(format, v...)
}
func (log *logger) Info(v ...interface{}) {
if log.options.level > INFO {
return
}
data := log.Prefix() + fmt.Sprint(v...)
Output(log, 4,"[INFO] ", data)
}
func (log *logger) Infof(format string, v ...interface{}) {
if log.options.level > INFO {
return
}
data := log.Prefix() + fmt.Sprintf(format,v...)
Output(log, 4,"[INFO] ", data)
}
// Warning print warning log
func Warning(v ...interface{}) {
DefaultLog.Warning(v...)
}
// Warningf print a formatted warning log
func Warningf(format string, v ...interface{}) {
DefaultLog.Warningf(format, v...)
}
func (log *logger) Warning(v ...interface{}) {
if log.options.level > WARNGING {
return
}
data := log.Prefix() + fmt.Sprint(v...)
Output(log, 4,"[WARNING] ", data)
}
func (log *logger) Warningf(format string, v ...interface{}) {
if log.options.level > WARNGING {
return
}
data := log.Prefix() + fmt.Sprintf(format,v...)
Output(log, 4,"[WARNING] ", data)
}
// Error print error log
func Error(v ...interface{}) {
DefaultLog.Error(v...)
}
// Errorf print a formatted error log
func Errorf(format string, v ...interface{}) {
DefaultLog.Errorf(format, v...)
}
func (log *logger) Error(v ...interface{}) {
if log.options.level > ERROR {
return
}
data := log.Prefix() + fmt.Sprint(v...)
Output(log, 4,"[ERROR] ", data)
}
func (log *logger) Errorf(format string, v ...interface{}) {
if log.options.level > ERROR {
return
}
data := log.Prefix() + fmt.Sprintf(format,v...)
Output(log, 4,"[ERROR] ", data)
}
// Fatal print fatal log
func Fatal(v ...interface{}) {
DefaultLog.Fatal(v...)
}
// Fatalf print a formatted fatal log
func Fatalf(format string, v ...interface{}) {
DefaultLog.Fatalf(format, v...)
}
func (log *logger) Fatal(v ...interface{}) {
if log.options.level > FATAL {
return
}
data := log.Prefix() + fmt.Sprint(v...)
Output(log, 4,"[FATAL] ", data)
}
func (log *logger) Fatalf(format string, v ...interface{}) {
if log.options.level > FATAL {
return
}
data := log.Prefix() + fmt.Sprintf(format,v...)
Output(log, 4,"[FATAL] ", data)
}
// call Output to write log
func Output(log *logger, calldepth int, prefix string, data string) {
var buffer bytes.Buffer
buffer.WriteString(prefix)
buffer.WriteString(data)
log.Output(calldepth, buffer.String())
}
HttpServer
Gin Content
POST请求,body的多种Content-Type的参数获取方法
func UserUpdate(c *gin.Context) {
// request body读取后,不能再从request中获取。
// 如果需要多次绑定或使用body,c.ShouldBindBodyWith会把body结果存入gin.Context中,c.Value(gin.BodyBytesKey)获取结果)
// 1. 支持body的Content-Type: form-data,x-www-form-urlencoded
var formData UserUpdateForm
if err := c.ShouldBindQuery(&formData); err != nil {
log.Warnc(c, err.Error())
c.JSON(http.StatusBadRequest, e.NewResp(e.INVALID_PARAMS, nil))
return
}
// 2. 支持body的Content-Type: raw(text,json)
var jsonData = UserUpdateForm{}
// ShouldBindBodyWith 读取 c.Request.Body 并将结果存入上下文。
if err := c.ShouldBindBodyWith(&jsonData, binding.JSON); err != nil {
log.Warnc(c, err.Error())
c.JSON(http.StatusBadRequest, e.NewResp(e.INVALID_PARAMS, nil))
return
}
log.Infoc(c, fmt.Sprintln("update userinfo ", ))
c.JSON(200, e.NewResp(e.SUCCESS, nil))
}
Gin Http拦截器
- gin
func main() {
engine := gin.New()
engine.Use(gin.Logger())
engine.Use(gin.Recovery())
engine.GET("/", func(c *gin.Context) {
c.String(200, "ok")
return
})
// Use之后的所有handler都会经过拦截器进行token校验
engine.Use(Auth())
engine.GET("/user", handlerUser)
engine.Run(":10000")
}
func handlerUser(c *gin.Context) {
fmt.Println("handler user is run")
c.String(200, "user is ok")
return
}
// Gin http请求拦截器
func Auth() gin.HandlerFunc {
return func(c *gin.Context) {
username := c.Request.FormValue("username")
token := c.Request.FormValue("token")
//验证登录token是否有效
if len(username) < 3 || !isTokenValid(token) {
resp := NewResp(-1, "token无效", nil)
c.JSON(http.StatusOK, resp)
c.Abort() //token校验失败则返回,不执行后面程序处理
return
}
c.Next()
}
}
// IsTokenValid : token是否有效
func isTokenValid(token string) bool {
if len(token) != 40 {
return false
}
// TODO: 判断token的时效性,是否过期
// TODO: 从数据库表tbl_user_token查询username对应的token信息
// TODO: 对比两个token是否一致
return true
}
func NewResp(code int, msg string, result interface{}) map[string]interface{} {
return map[string]interface{}{"code": code, "msg": msg, "result": result}
}
- http请求拦截器
// TODO HTTPInterceptor : http请求拦截器
func HTTPInterceptor(h http.HandlerFunc) http.HandlerFunc {
return http.HandlerFunc(
func(w http.ResponseWriter, r *http.Request) {
r.ParseForm()
username := r.Form.Get("username")
token := r.Form.Get("token")
//验证登录token是否有效
if len(username) < 3 || !IsTokenValid(token) {
// w.WriteHeader(http.StatusForbidden)
// token校验失败则跳转到登录页面
http.Redirect(w, r, "/static/view/signin.html", http.StatusFound)
return
}
h(w, r)
})
}
用goroutines和channels,实现客户端-服务器的应用
//Request结构,其中内嵌了一个replyChan通道。
type Request struct {
a, b int
replyChan chan int
}
type binOp func(a, b int) int
//服务器会为每一个请求启动一个协程并在其中执行run()函数
func run(op binOp, req *Request) {
req.replyChan <- op(req.a, req.b)
}
//server协程会无限循环以从chan *Request接收请求
//func server(op binOp, reqChan chan *Request) {
func server(op binOp, reqChan chan *Request, quit chan bool) {
for {
select {
case req := <-reqChan:
go run(op, req)
case <-quit:
return
}
//req := <-reqChan
//go run(op, req)
}
}
//server本身则是以协程的方式在startServer函数中启动
//func startServer(op binOp) chan *Request {
func startServer(op binOp) (reqChan chan *Request, quit chan bool) { // 通过信号通道关闭服务器
reqChan = make(chan *Request, 1000)
quit = make(chan bool, 2)
//go server(op, reqChan)
go server(op, reqChan, quit)
return reqChan, quit
}
func main() {
//adder := startServer(func(a, b int) int { return a + b })
adder, quit := startServer(func(a, b int) int { return a + b })
const N = 2000
var reqs [N]Request
startTime := time.Now().UnixNano()
for i := 0; i < N; i++ {
req := &reqs[i]
req.a = i
req.b = i + N
req.replyChan = make(chan int)
adder <- req
}
// checks:
for i := N - 1; i >= 0; i-- {
// doesn’t matter what order
if <-reqs[i].replyChan != N+2*i {
fmt.Println("fail at", i)
} else {
fmt.Println("Request", i, "is ok!")
}
}
quit <- true
fmt.Println("done", (time.Now().UnixNano()-startTime)/int64(time.Millisecond), "ms")
}
速率
使用channel速度限制1
package main
import (
"fmt"
"time"
)
func main() {
// 方案一
requests := make(chan int, 5)
for i := 1; i <= 5; i++ {
requests <- i
}
close(requests)
// 限制对收到请求的处理
// limiter 通道每 200ms 接收一个值
limiter := time.Tick(200 * time.Millisecond)
for req := range requests {
<-limiter
fmt.Println("request", req, time.Now())
}
// 方案二
// burstyLimiter 通道允许最多 3 个爆发(bursts)事件
burstyLimiter := make(chan time.Time, 3)
for i := 0; i < 3; i++ {
burstyLimiter <- time.Now()
}
// 每 200ms 我们将尝试添加一个新的值到 burstyLimiter中, 直到达到 3 个的限制。
go func() {
for t := range time.Tick(200 * time.Millisecond) {
burstyLimiter <- t
}
}()
// 模拟另外 5 个传入请求
burstyRequests := make(chan int, 5)
for i := 1; i <= 5; i++ {
burstyRequests <- i
}
close(burstyRequests)
for req := range burstyRequests {
<-burstyLimiter
fmt.Println("request", req, time.Now())
}
}
使用channel速度限制2
func main() {
a := Adapter{}
go a.Tick(10) // 10次每秒
// 5秒后关闭Adapter
time.Sleep(5 * time.Second)
a.Close()
// 1秒后退出程序
time.Sleep(time.Second)
fmt.Println("down.")
}
type Adapter struct {
isClose bool
}
// 设定速率: 每秒多少次
func (a *Adapter) Tick(rate int) {
var t = time.Tick(time.Second / time.Duration(rate))
var index = 0
for {
if a.isClose {
fmt.Println("adapter is closed")
return
}
select {
case <-t:
index++
fmt.Println("index:", index, time.Now())
}
}
}
func (a *Adapter) Close() {
a.isClose = true
}
基于time/rate的限速
rate.NewLimiter(limit ,burst)
- limit表示每秒产生token, burst最多存token数
Allow判断当前是否可以取到token
Wati阻塞等待直到取到token
Reserve返回等待时间,再去取token
import (
"fmt"
"golang.org/x/time/rate"
"sync/atomic"
"time"
)
func main() {
var count uint32 = 0
limiter := rate.NewLimiter(10, 5) // 每秒10个,爆发5个
go func() {
for {
if limiter.Allow() {
doWork()
atomic.AddUint32(&count, 1)
}
}
}()
time.Sleep(10 * time.Second)
fmt.Println("count:", count) // 105
}
func doWork() {
fmt.Println("do work.", time.Now())
}
// Output:
do work. 2020-04-28 10:58:25.1863089 +0800 CST m=+0.005000301
do work. 2020-04-28 10:58:25.2173106 +0800 CST m=+0.036002001
do work. 2020-04-28 10:58:25.2173106 +0800 CST m=+0.036002001
do work. 2020-04-28 10:58:25.2173106 +0800 CST m=+0.036002001
do work. 2020-04-28 10:58:25.2173106 +0800 CST m=+0.036002001
do work. 2020-04-28 10:58:25.2863146 +0800 CST m=+0.105006001
do work. 2020-04-28 10:58:25.3863203 +0800 CST m=+0.205011701
do work. 2020-04-28 10:58:25.486326 +0800 CST m=+0.305017401
do work. 2020-04-28 10:58:25.5863317 +0800 CST m=+0.405023101
do work. 2020-04-28 10:58:25.6863375 +0800 CST m=+0.505028901
do work. 2020-04-28 10:58:25.7863432 +0800 CST m=+0.605034601
do work. 2020-04-28 10:58:25.8863489 +0800 CST m=+0.705040301
do work. 2020-04-28 10:58:25.9863546 +0800 CST m=+0.805046001
do work. 2020-04-28 10:58:26.0863603 +0800 CST m=+0.905051701
...
do work. 2020-04-28 10:58:35.0868751 +0800 CST m=+9.905566501
do work. 2020-04-28 10:58:35.1868809 +0800 CST m=+10.005572301
count: 105
基于juju/ratelimit限速
import (
"fmt"
"github.com/juju/ratelimit"
"time"
)
func main() {
bucketMap := make(map[int]*ratelimit.Bucket)
b := ratelimit.NewBucketWithQuantumAndClock(2*time.Second, 20, 10, nil)
bucketMap[1] = b
for i := 0; i < 10000; i++ {
before := b.Available()
if b.TakeAvailable(1) != 0 {
fmt.Printf("获取到令牌index:%d, 前后数量: 前:%d, 后:%d\n", i, before, b.Available())
} else {
fmt.Println("获取令牌失败, 拒绝index:", i)
}
time.Sleep(100 * time.Millisecond)
}
}
控制一下 goroutine 的并发数量
灵活 chan + sync
package main
import (
"fmt"
"sync"
"time"
)
func ConcurrentTasks(total int, coro int, fn func()) {
var (
wg sync.WaitGroup
ch = make(chan bool, coro)
)
for i := 0; i < total; i++ {
wg.Add(1)
go func() {
defer wg.Done()
// 得到true,才执行函数
if <-ch {
fn()
}
}()
}
// 控制channel长度,每秒发送给channel,最多为coro的数量
for i := 0; i < total/coro+1; i++ {
for j := 0; j < coro; j++ {
ch <- true
}
time.Sleep(time.Second)
}
close(ch)
wg.Wait()
return
}
func echoTime() {
fmt.Println("Time:", time.Now().Unix())
}
func PrintUid(uid string) func() {
return func() {
fmt.Printf("Uid:%s, Time:%v\n", uid, time.Now().Unix())
}
}
func main() {
ConcurrentTasks(10, 3, echoTime)
ConcurrentTasks(10, 3, PrintUid("abc"))
}
简单channel
package main
import (
"fmt"
"time"
)
type limiter struct {
ch chan struct{}
}
func NewLimiter(n int) *limiter {
ch := make(chan struct{}, n)
for i := 0; i < n; i++ {
ch <- struct{}{}
}
return &limiter{ch: ch}
}
func (l *limiter) Acquire() {
<-l.ch
}
func (l *limiter) Release() {
l.ch <- struct{}{}
}
func main() {
l := NewLimiter(2)
for i := 0; i < 10; i++ {
go doWork(i, l)
}
time.Sleep(time.Hour)
}
func doWork(i int, l *limiter) {
l.Acquire()
fmt.Printf("[%d]load and save data %ds\n", i, time.Now().Second())
time.Sleep(2 * time.Second)
l.Release()
}
连接池
简单连接池
type Pool struct {
m sync.Mutex // 保证多个goroutine访问时候,closed的线程安全
res chan io.Closer // 连接存储的chan
factory func() (io.Closer, error) // 新建连接的工厂方法
closed bool
}
// 利用chan来存储池里的连接
func New(fn func() (io.Closer, error), size uint) (*Pool, error) {
if size <= 0 {
return nil, errors.New("连接池的大小必须大于0")
}
return &Pool{
res: make(chan io.Closer, size),
factory: fn,
}, nil
}
//从资源池里获取一个资源
func (p *Pool) Acquire() (io.Closer, error) {
select {
case r, ok := <-p.res:
fmt.Println("Acquire:获取资源")
if !ok {
return nil, errors.New("pool is closed")
}
return r, nil
default:
fmt.Println("Acquire:新生成资源")
return p.factory()
}
}
//关闭资源池,释放资源
func (p *Pool) Close() {
p.m.Lock()
defer p.m.Unlock()
if p.closed {
return
}
p.closed = true
//关闭通道,不让写入了
close(p.res)
//关闭通道里的资源
for r := range p.res {
r.Close()
}
}
// 释放连接
func (p *Pool) Release(r io.Closer) {
//保证该操作和Close方法的操作是安全的
p.m.Lock()
defer p.m.Unlock()
if p.closed {
r.Close()
return
}
select {
case p.res <- r:
fmt.Println("资源释放到池里")
default:
fmt.Println("资源池已满")
r.Close()
}
}
- 我们对连接最大的数量没有限制,如果线程池空的话都我们默认就直接新建一个连接返回了。一旦并发量高的话将会不断新建连接,很容易(尤其是MySQL)造成too many connections的报错发生。
- 既然我们需要保证最大可获取连接数量,那么我们就不希望数量定的太死。希望空闲的时候可以维护一定的空闲连接数量idleNum,但是又希望我们能限制最大可获取连接数量maxNum。
- 第一种情况是并发过多的情况,那么如果并发量过少呢?现在我们在新建一个连接并且归还后,我们很长一段时间不再使用这个连接。那么这个连接很有可能在几个小时甚至更长时间之前就已经建立的了。长时间闲置的连接我们并没有办法保证它的可用性。便有可能我们下次获取的连接是已经失效的连接。
sync.pool
Pool就是为了减少GC压力的, 重复利用内存. 千万不能把他当成内存池使用
垃圾回收定期执行。如果你的代码不断地在一些数据结构中分配内存然后释放它们,这就会导致收集器的不断工作,使得更多的内存和 CPU 被用来在初始化结构体时分配资源。
sync.Pool允许我们重用内存而非重新分配。
此外,如果你使用的 http 服务器接收带有 JSON 请求体的 post 请求,并且它必须被解码到结构体中,你可以使用 sync.Pool 来节省内存并减少服务器响应时间。
import (
"github.com/golang/protobuf/proto"
"sync"
)
func main() {
buffer := bufferPool.Get().(*cachedBuffer)
// ...
buffer.SetBuf(nil) // 用完重置
bufferPool.Put(buffer) // 放回pool
}
var bufferPool = &sync.Pool{
New: func() interface{} {
return &cachedBuffer{
Buffer: proto.Buffer{},
lastMarshaledSize: 16,
}
},
}
type cachedBuffer struct {
proto.Buffer
lastMarshaledSize uint32
}
swagger
elasticsearch
gRPC
同一个端口支持两种协议(grpc,http)
// server端
package server
import (
"context"
"fmt"
"github.com/grpc-ecosystem/grpc-gateway/runtime"
"golang.org/x/net/http2"
"golang.org/x/net/http2/h2c"
"google.golang.org/grpc"
"grpc-demo/proto"
"net/http"
"strings"
)
var (
ServerPort string
CertName string
CertPemPath string
CertKeyPath string
)
// 支持不使用证书的http2 server
func Serve() (err error) {
server := grpc.NewServer()
proto.RegisterHelloWorldServer(server, &helloService{})
mux := http.NewServeMux() // http mux
gwmux := runtime.NewServeMux() // rpc gateway mux
dopts := []grpc.DialOption{grpc.WithInsecure()}
proto.RegisterHelloWorldHandlerFromEndpoint(context.Background(), gwmux, ":"+ServerPort, dopts)
mux.Handle("/", gwmux)
fmt.Println("grpc and http server is running")
return http.ListenAndServe(":"+ServerPort, grpcHandlerFunc(server, mux))
}
//根据不同的请求流量类型将其劫持并重定向到相应的 Hander 中去处理
func grpcHandlerFunc(grpcServer *grpc.Server, otherHandler http.Handler) http.Handler {
return h2c.NewHandler(http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
//fmt.Println("request:", r.ProtoMajor, r.RemoteAddr, r.RequestURI)
if r.ProtoMajor == 2 && strings.Contains(r.Header.Get("Content-Type"), "application/grpc") {
grpcServer.ServeHTTP(w, r)
} else {
otherHandler.ServeHTTP(w, r)
}
}), &http2.Server{})
}
// client端
var addr = "192.168.30.86:10000"
func getClient() proto.HelloWorldClient {
conn, err := grpc.Dial(addr, grpc.WithInsecure())
if err != nil {
log.Fatalln("failed to connection:", err)
}
cli := proto.NewHelloWorldClient(conn)
return cli
}
func TestClient(t *testing.T) {
cli := getClient()
rsp, err := cli.SayHelloWorld(context.Background(), &proto.HelloWorldRequest{
Referer: "Tom",
})
fmt.Println(rsp, err)
}
拦截器
grpc.UnaryInterceptor
func UnaryInterceptor(i UnaryServerInterceptor) ServerOption {
return func(o *options) {
if o.unaryInt != nil {
panic("The unary server interceptor was already set and may not be reset.")
}
o.unaryInt = i
}
}
type UnaryServerInterceptor func(ctx context.Context, req interface{}, info *UnaryServerInfo, handler UnaryHandler) (resp interface{}, err error)
// ctx context.Context:请求上下文
// req interface{}:RPC 方法的请求参数
// info *UnaryServerInfo:RPC 方法的所有信息
// handler UnaryHandler:RPC 方法本身
import "github.com/grpc-ecosystem/go-grpc-middleware"
myServer := grpc.NewServer(
grpc.StreamInterceptor(grpc_middleware.ChainStreamServer(
...
)),
grpc.UnaryInterceptor(grpc_middleware.ChainUnaryServer(
...
)),
)
实现 interceptor
// logging
func LoggingInterceptor(ctx context.Context, req interface{}, info *grpc.UnaryServerInfo, handler grpc.UnaryHandler) (interface{}, error) {
log.Printf("gRPC method: %s, %v", info.FullMethod, req)
resp, err := handler(ctx, req)
log.Printf("gRPC method: %s, %v", info.FullMethod, resp)
return resp, err
}
// recover
func RecoveryInterceptor(ctx context.Context, req interface{}, info *grpc.UnaryServerInfo, handler grpc.UnaryHandler) (resp interface{}, err error) {
defer func() {
if e := recover(); e != nil {
debug.PrintStack()
err = status.Errorf(codes.Internal, "Panic err: %v", e)
}
}()
return handler(ctx, req)
}
server
import (
"context"
"crypto/tls"
"crypto/x509"
"errors"
"io/ioutil"
"log"
"net"
"runtime/debug"
"google.golang.org/grpc"
"google.golang.org/grpc/credentials"
"google.golang.org/grpc/status"
"google.golang.org/grpc/codes"
"github.com/grpc-ecosystem/go-grpc-middleware"
pb "github.com/EDDYCJY/go-grpc-example/proto"
)
...
func main() {
c, err := GetTLSCredentialsByCA()
if err != nil {
log.Fatalf("GetTLSCredentialsByCA err: %v", err)
}
opts := []grpc.ServerOption{
grpc.Creds(c),
grpc_middleware.WithUnaryServerChain(
RecoveryInterceptor,
LoggingInterceptor,
),
}
server := grpc.NewServer(opts...)
pb.RegisterSearchServiceServer(server, &SearchService{})
lis, err := net.Listen("tcp", ":"+PORT)
if err != nil {
log.Fatalf("net.Listen err: %v", err)
}
server.Serve(lis)
}
Deadlines
始终设定截止日期
client
func main() {
...
ctx, cancel := context.WithDeadline(context.Background(), time.Now().Add(time.Duration(5 * time.Second)))
defer cancel()
client := pb.NewSearchServiceClient(conn)
resp, err := client.Search(ctx, &pb.SearchRequest{
Request: "gRPC",
})
if err != nil {
statusErr, ok := status.FromError(err)
if ok {
if statusErr.Code() == codes.DeadlineExceeded {
log.Fatalln("client.Search err: deadline")
}
}
log.Fatalf("client.Search err: %v", err)
}
log.Printf("resp: %s", resp.GetResponse())
}
// context.WithTimeout:很常见的另外一个方法,是便捷操作。实际上是对于 WithDeadline 的封装
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) {
return WithDeadline(parent, time.Now().Add(timeout))
}
// status.FromError:返回 GRPCStatus 的具体错误码,若为非法,则直接返回 codes.Unknown
Server
type SearchService struct{}
func (s *SearchService) Search(ctx context.Context, r *pb.SearchRequest) (*pb.SearchResponse, error) {
for i := 0; i < 5; i++ {
if ctx.Err() == context.Canceled {
return nil, status.Errorf(codes.Canceled, "SearchService.Search canceled")
}
time.Sleep(1 * time.Second)
}
return &pb.SearchResponse{Response: r.GetRequest() + " Server"}, nil
}
func main() {
...
}
// 而在 Server 端,由于 Client 已经设置了截止时间。Server 势必要去检测它
// 否则如果 Client 已经结束掉了,Server 还傻傻的在那执行,这对资源是一种极大的浪费
// 因此在这里需要用 ctx.Err() == context.Canceled 进行判断,为了模拟场景我们加了循环和睡眠 🤔
go-micro
- etcd注册中心
func main() {
//reg := etcd.NewRegistry(func(options *registry.Options) {
// options.Addrs = []string{
// "xx.xx.xx.xx:2379",
// }
//})
//micro.Selector(selector.NewSelector(func(options *selector.Options) {
// options.Registry=reg
//}))
// New Service
service := micro.NewService(
// micro.Registry(reg),
micro.Name("go.micro.srv.user"),
micro.Version("latest"),
)
自定义websocket对象
connection.go
package impl
import (
"errors"
"github.com/gorilla/websocket"
"sync"
)
type Connection struct {
wsConn *websocket.Conn
//读取websocket的channel
inChan chan []byte
//给websocket写消息的channel
outChan chan []byte
closeChan chan byte
mutex sync.Mutex
//closeChan 状态
isClosed bool
}
//初始化长连接
func InitConnection(wsConn *websocket.Conn) (conn *Connection, err error) {
conn = &Connection{
wsConn: wsConn,
inChan: make(chan []byte, 1000),
outChan: make(chan []byte, 1000),
closeChan: make(chan byte, 1),
}
//启动读协程
go conn.readLoop()
//启动写协程
go conn.writeLoop()
return
}
//读取websocket消息
func (conn *Connection) ReadMessage() (data []byte, err error) {
select {
case data = <-conn.inChan:
case <-conn.closeChan:
err = errors.New("connection is closed")
}
return
}
//发送消息到websocket
func (conn *Connection) WriteMessage(data []byte) (err error) {
select {
case conn.outChan <- data:
case <-conn.closeChan:
err = errors.New("connection is closed")
}
return
}
//关闭连接
func (conn *Connection) Close() {
//线程安全的Close,可重入
conn.wsConn.Close()
//只执行一次
conn.mutex.Lock()
if !conn.isClosed {
close(conn.closeChan)
conn.isClosed = true
}
conn.mutex.Unlock()
}
func (conn *Connection) readLoop() {
var (
data []byte
err error
)
for {
if _, data, err = conn.wsConn.ReadMessage(); err != nil {
goto ERR
}
//阻塞在这里,等待inChan有空闲的位置
select {
case conn.inChan <- data:
case <-conn.closeChan:
//closeChan关闭的时候
goto ERR
}
}
ERR:
conn.Close()
}
func (conn *Connection) writeLoop() {
var (
data []byte
err error
)
for {
select {
case data = <-conn.outChan:
case <-conn.closeChan:
goto ERR
}
if err = conn.wsConn.WriteMessage(websocket.TextMessage, data); err != nil {
goto ERR
}
}
ERR:
conn.Close()
}
server.go
package main
import (
"github.com/gorilla/websocket"
"net/http"
"time"
"websocket/impl"
)
var (
upgrade = websocket.Upgrader{
//允许跨域
CheckOrigin: func(r *http.Request) bool {
return true
},
}
)
func wsHandler(w http.ResponseWriter, r *http.Request) {
var (
//websocket 长连接
wsConn *websocket.Conn
err error
conn *impl.Connection
data []byte
)
//header中添加Upgrade:websocket
if wsConn, err = upgrade.Upgrade(w, r, nil); err != nil {
return
}
go func() {
var (
err error
)
for {
if err = conn.WriteMessage([]byte("heartbeat")); err != nil {
return
}
time.Sleep(time.Second * 1)
}
}()
if conn, err = impl.InitConnection(wsConn); err != nil {
goto ERR
}
if conn, err = impl.InitConnection(wsConn); err != nil {
goto ERR
}
for {
if data, err = conn.ReadMessage(); err != nil {
goto ERR
}
if err = conn.WriteMessage(data); err != nil {
goto ERR
}
}
ERR:
conn.Close()
}
func main() {
//http标准库
http.HandleFunc("/ws", wsHandler)
http.ListenAndServe("0.0.0.0:7777", nil)
}
4.资源
常用库
本地示例
博客
- Tony Bai https://tonybai.com/ 一个程序员的心路历程
- 曹春晖 https://xargin.com/
- 鸟窝 https://colobu.com/
- Draveness https://draveness.me/ Draveness写了很多Go和分布式方面的文章
- 煎鱼 https://eddycjy.com/posts/ 煎鱼大佬的迷之博客
- 枯藤 http://topgoer.com/ 枯藤大佬的超全Go知识库
- 码农桃花源 https://qcrao.com/
- 极客兔兔 https://geektutu.com/post/high-performance-go.html Go 语言高性能编程
框架
文章
- CLI 命令 (spf13/cobra)
- 配置读取器 (spf13/viper)
- Web 框架 (labstack/echo)
- 依赖注入 (uber-go/fx)
- Swagger 生成器、UI 和验证
- 自定义记录器 (sirupsen/logrus)
- 模拟生成器 (vektra/mockery)
- 迁移 (golang-migrate/migrate)
- 消息传递 (NSQ)
- SQL (jmoiron/sqlx)
5.测试
程序性能分析pprof
工具型应用的性能分析
在Go 语言中,主要关注的程序运行情况包括以下几种:
- CPU profile:报告程序的 CPU 使用情况,按照一定频率去采集应用程序在 CPU 和寄存器上面的数据
- Memory Profile(Heap Profile):报告程序的内存使用情况
- Block Profile:报告导致阻塞的同步原语的情况,可以用来分析和查找锁的性能瓶颈
- Goroutine Profile:报告 goroutines 的使用情况,有哪些 goroutine,它们的调用关系是怎样的
进行 CPU Profiling,可以调用 pprof.StartCPUProfile() 方法,它会对当前应用程序进行CPU使用情况分析,并写入到提供的参数中(w io.Writer),要停止调用 StopCPUProfile() 即可。
f, err := os.Create(*cpuprofile)
...
pprof.StartCPUProfile(f)
defer pprof.StopCPUProfile()
想要获得内存的数据,直接使用 WriteHeapProfile 就行,不用 start 和 stop 这两个步骤了:
f, err := os.Create(*memprofile)
pprof.WriteHeapProfile(f)
f.Close()
服务型应用性能分析
如果使用了默认的http.DefaultServeMux(通常是代码直接使用 http.ListenAndServe("0.0.0.0:8000", nil)),只需要在代码中添加一行,匿名引用net/http/pprof:
import _ "net/http/pprof"
如果你使用自定义的 ServerMux复用器,则需要手动注册一些路由规则:
r.HandleFunc("/debug/pprof/", pprof.Index)
r.HandleFunc("/debug/pprof/heap", pprof.Index)
r.HandleFunc("/debug/pprof/cmdline", pprof.Cmdline)
r.HandleFunc("/debug/pprof/profile", pprof.Profile)
r.HandleFunc("/debug/pprof/symbol", pprof.Symbol)
r.HandleFunc("/debug/pprof/trace", pprof.Trace)
/debug/pprof/profile:访问这个链接会自动进行 CPU profiling,持续 30s,并生成一个文件供下载,可以通过带参数?=seconds=60进行60秒的数据采集/debug/pprof/heap:Memory Profiling 的路径,访问这个链接会得到一个内存 Profiling 结果的文件/debug/pprof/block:block Profiling 的路径/debug/pprof/goroutines:运行的 goroutines 列表,以及调用关系
使用go tool pprof
使用go tool pprof工具对这些数据进行分析和保存了,一般都是使用pprof通过HTTP访问上面列的那些路由端点直接获取到数据后再进行分析,获取到数据后pprof会自动让终端进入交互模式。在交互模式里pprof为我们提供了不少分析各种指标的子命令,在交互模式下键入help后就会列出所有子命令。
CPU性能分析
进行CPU性能分析直接用go tool pprof访问上面说的/debug/pprof/profile端点即可,等数据采集完会自动进入命令行交互模式。
➜ go tool pprof http://localhost/debug/pprof/profile
Fetching profile over HTTP from http://localhost/debug/pprof/profile
Saved profile in /Users/Kev/pprof/pprof.samples.cpu.005.pb.gz
Type: cpu
Time: Nov 15, 2020 at 3:32pm (CST)
Duration: 30.01s, Total samples = 0
No samples were found with the default sample value type.
Try "sample_index" command to analyze different sample values.
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)
默认采集时长是 30s,如果在 url 最后加上 ?seconds=60 参数可以调整采集数据的时间为 60s。
采集完成我们就进入了一个交互式命令行,可以对解析的结果进行查看和导出。可以通过 help 来查看支持的子命令有哪些。
如果pprof用性能数据生成分析图的话、包括后面的go-torch火焰图都依赖软件graphviz
列出最耗时的地方
(pprof) top10
130ms of 360ms total (36.11%)
Showing top 10 nodes out of 180 (cum >= 10ms)
flat flat% sum% cum cum%
20ms 5.56% 5.56% 100ms 27.78% encoding/json.(*decodeState).object
20ms 5.56% 11.11% 20ms 5.56% runtime.(*mspan).refillAllocCache
20ms 5.56% 16.67% 20ms 5.56% runtime.futex
10ms 2.78% 19.44% 10ms 2.78% encoding/json.(*decodeState).literalStore
10ms 2.78% 22.22% 10ms 2.78% encoding/json.(*decodeState).scanWhile
10ms 2.78% 25.00% 40ms 11.11% encoding/json.checkValid
10ms 2.78% 27.78% 10ms 2.78% encoding/json.simpleLetterEqualFold
10ms 2.78% 30.56% 10ms 2.78% encoding/json.stateBeginValue
10ms 2.78% 33.33% 10ms 2.78% encoding/json.stateEndValue
10ms 2.78% 36.11% 10ms 2.78% encoding/json.stateInString
每一行表示一个函数的信息。前两列表示函数在 CPU 上运行的时间以及百分比;第三列是当前所有函数累加使用 CPU 的比例;第四列和第五列代表这个函数以及子函数运行所占用的时间和比例(也被称为累加值 cumulative),应该大于等于前两列的值;最后一列就是函数的名字。如果应用程序有性能问题,上面这些信息应该能告诉我们时间都花费在哪些函数的执行上。
生成函数调用图
pprof 不仅能打印出最耗时的地方(top),还能列出函数代码以及对应的取样数据(list)、汇编代码以及对应的取样数据(disasm),而且能以各种样式进行输出,比如 svg、gif、png等等。
其中一个非常便利的是 web 命令,在交互模式下输入 web,就能自动生成一个 svg 文件,并跳转到浏览器打开,生成了一个函数调用图(这个功能需要安装graphviz后才能使用)。
如果应用比较复杂,生成的调用图特别大,看起来很乱,有两个办法可以优化:
- 使用
web funcName的方式,只打印和某个函数相关的内容 - 运行
go tool pprof命令时加上--nodefration参数,可以忽略内存使用较少的函数,比如--nodefration=0.05表示如果调用的子函数使用的 CPU、memory 不超过 5%,就忽略它,不要显示在图片中。
分析函数性能
想更细致分析,就要精确到代码级别了,看看每行代码的耗时,直接定位到出现性能问题的那行代码。pprof 也能做到,list 命令后面跟着一个正则表达式,就能查看匹配函数的代码以及每行代码的耗时:
(pprof) list podFitsOnNode
Total: 120ms
ROUTINE ======================== k8s.io/kubernetes/plugin/pkg/scheduler.podFitsOnNode in /home/cizixs/go/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/plugin/pkg/scheduler/generic_scheduler.go
0 20ms (flat, cum) 16.67% of Total
. . 230:
. . 231:// Checks whether node with a given name and NodeInfo satisfies all predicateFuncs.
. . 232:func podFitsOnNode(pod *api.Pod, meta interface{}, info *schedulercache.NodeInfo, predicateFuncs map[string]algorithm.FitPredicate) (bool, []algorithm.PredicateFailureReason, error) {
. . 233: var failedPredicates []algorithm.PredicateFailureReason
. . 234: for _, predicate := range predicateFuncs {
. 20ms 235: fit, reasons, err := predicate(pod, meta, info)
. . 236: if err != nil {
. . 237: err := fmt.Errorf("SchedulerPredicates failed due to %v, which is unexpected.", err)
. . 238: return false, []algorithm.PredicateFailureReason{}, err
. . 239: }
. . 240: if !fit {
内存性能分析
➜ go tool pprof http://localhost/debug/pprof/heap
Fetching profile from http://localhost/debug/pprof/heap
Saved profile in
......
(pprof)
默认情况下,统计的是内存使用大小,如果执行命令的时候加上 --inuse_objects 可以查看每个函数分配的对象数;--alloc-space 查看分配的内存空间大小。
go-torch 和火焰图
go-torch。这是 uber 开源的一个工具,可以直接读取 pprof的 profiling 数据,并生成一个火焰图的 svg 文件。
火焰图 svg 文件可以通过浏览器打开,它对于调用图的优点是:可以通过点击每个方块来分析它上面的内容。
火焰图的调用顺序从下到上,每个方块代表一个函数,它上面一层表示这个函数会调用哪些函数,方块的大小代表了占用 CPU 使用的长短。火焰图的配色并没有特殊的意义,默认的红、黄配色是为了更像火焰而已。
go-torch 工具的使用非常简单,没有任何参数的话,它会尝试从 http://localhost/debug/pprof/profile 获取 profiling 数据。它有三个常用的参数可以调整:
-u --url:要访问的 URL,这里只是主机和端口部分-s --suffix:pprof profile 的路径,默认为/debug/pprof/profile--seconds:要执行 profiling 的时间长度,默认为 30s
在Echo中使用pprof
由于Echo框架使用的复用器ServerMux是自定义的,需要手动注册pprof提供的路由,网上有几个把他们封装成了包可以直接使用, 不过都不是官方提供的包。后来我看了一下pprof提供的路由Handler的源码,只需要把它转换成Echo框架的路由Handler后即可能正常处理那些pprof相关的请求,具体转换操作很简单我就直接放代码了。
func RegisterRoutes(engine *echo.Echo) {
router := engine.Group("")
......
// 下面的路由根据要采集的数据需求注册,不用全都注册
router.GET("/debug/pprof", echo.WrapHandler(http.HandlerFunc(pprof.Index)))
router.GET("/debug/pprof/allocs", echo.WrapHandler(http.HandlerFunc(pprof.Index)))
router.GET("/debug/pprof/block", echo.WrapHandler(http.HandlerFunc(pprof.Index)))
router.GET("/debug/pprof/goroutine", echo.WrapHandler(http.HandlerFunc(pprof.Index)))
router.GET("/debug/pprof/heap", echo.WrapHandler(http.HandlerFunc(pprof.Index)))
router.GET("/debug/pprof/mutex", echo.WrapHandler(http.HandlerFunc(pprof.Index)))
router.GET("/debug/pprof/cmdline", echo.WrapHandler(http.HandlerFunc(pprof.Cmdline)))
router.GET("/debug/pprof/profile", echo.WrapHandler(http.HandlerFunc(pprof.Profile)))
router.GET("/debug/pprof/symbol", echo.WrapHandler(http.HandlerFunc(pprof.Symbol)))
router.GET("/debug/pprof/trace", echo.WrapHandler(http.HandlerFunc(pprof.Trace)))
}
注册好路由后还需要对Echo框架的写响应超时WriteTimeout做一下配置,保证发生写超时的时间设置要大于pprof做数据采集的时间,这个配置对应的是/debug/pprof路由的seconds参数,默认采集时间是30秒,比如我通常要进行60秒的数据采集,那WriteTimeout配置的时间就要超过60秒,具体配置方式如下:
如果pprof做profiling的时间超过
WriteTimeout会引发一个"profile duration exceeds server's WriteTimeout"的错误。
RegisterRoutes(engine)
err := engine.StartServer(&http.Server{
Addr: addr,
ReadTimeout: time.Second * 5,
ReadHeaderTimeout: time.Second * 2,
WriteTimeout: time.Second * 90,
})
➜ go tool pprof http://{server_ip}:{port}/debug/pprof/profile
Fetching profile over HTTP from http://localhost/debug/pprof/profile
Saved profile in /Users/Kev/pprof/pprof.samples.cpu.005.pb.gz
Type: cpu
Time: Nov 15, 2020 at 3:32pm (CST)
Duration: 30.01s, Total samples = 0
No samples were found with the default sample value type.
Try "sample_index" command to analyze different sample values.
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)
在Gin中使用pprof
在Gin框架可以通过安装Gin项目组提供的gin-contrib/pprof包,直接引入后使用就能提供pprof相关的路由访问。
package main
import (
"github.com/gin-contrib/pprof"
"github.com/gin-gonic/gin"
)
func main() {
router := gin.Default()
pprof.Register(router)
router.Run(":8080")
}
内存使用信息采集
go tool pprof http://localhost:8080/debug/pprof/heap
CPU使用情况信息采集
go tool pprof http://localhost:8080/debug/pprof/profile
怎么用pprof分析gRPC的性能
gRPC底层基于HTTP协议的,一个典型的gRPC服务的启动程序可能像下面这样
func main () {
lis, err := net.Listen("tcp", 10000)
grpcServer := grpc.NewServer()
pb.RegisterRouteGuideServer(grpcServer, &routeGuideServer{})
grpcServer.Serve(lis)
}
它是一个RPC框架不是Web框架,不支持浏览器用URL访问,所以也就没法向上一节给Echo和Gin框架单独注册pprof采集数据用的那些路由。
但是我们可以换个角度来看这个问题,pprof做CPU分析原理是按照一定的频率采集程序CPU(包括寄存器)的使用情况,确定Golang程序性能分析(二)在Echo和Gin框架中使用pprof应用程序在主动消耗 CPU 周期时花费时间的位置。所以我们可以在gRPC服务启动时,异步启动一个监听其他端口的HTTP服务,通过这个HTTP服务间接获取gRPC服务的分析数据。
go func() {
http.ListenAndServe(":10001", nil)
}()
由于使用默认的ServerMux(服务复用器),所以只要匿名导入net/http/pprof包,这个HTTP的复用器默认就会注册pprof相关的路由。
此外建议在启动程序的最开端,调用runtime.SetBlockProfileRate(1)指示对阻塞超过1纳秒的goroutine进行数据采集。
func main () {
runtime.SetBlockProfileRate(1)
go func() {
http.ListenAndServe(":10001", nil)
}()
lis, err := net.Listen("tcp", 10000)
grpcServer := grpc.NewServer()
pb.RegisterRouteGuideServer(grpcServer, &routeGuideServer{})
grpcServer.Serve(lis)
}
服务启动后就能通过{server_ip}:10001/debug/pprof/profile采集CPU的使用情况了,具体pprof工具的使用方法的详细说明参考系列的第一篇文章。
RPC测试
server.go
package main
import (
"context"
"log"
"net"
"google.golang.org/grpc"
pb "github.com/lubanproj/gorpc-benchmark/grpc/helloworld"
)
const (
port = ":8000"
)
// server is used to implement helloworld.GreeterServer.
type server struct{}
// SayHello implements helloworld.GreeterServer
func (s *server) SayHello(ctx context.Context, in *pb.HelloRequest) (*pb.HelloReply, error) {
return &pb.HelloReply{Message: "world"}, nil
}
func main() {
lis, err := net.Listen("tcp", port)
if err != nil {
log.Fatalf("failed to listen: %v", err)
}
s := grpc.NewServer()
pb.RegisterGreeterServer(s, &server{})
if err := s.Serve(lis); err != nil {
log.Fatalf("failed to serve: %v", err)
}
}
client.go
package main
import (
"context"
"flag"
"sync"
"sync/atomic"
"time"
"github.com/lubanproj/gorpc/log"
"google.golang.org/grpc"
pb "github.com/lubanproj/gorpc-benchmark/grpc/helloworld"
)
var concurrency = flag.Int64("concurrency", 500, "concurrency")
var total = flag.Int64("total", 1000000, "total requests")
func main() {
flag.Parse()
request(*total, *concurrency)
}
func request(totalReqs int64, concurrency int64) {
perClientReqs := totalReqs / concurrency
counter := &Counter{
Total: perClientReqs * concurrency ,
Concurrency: concurrency,
}
req := &pb.HelloRequest{Name: "hello"}
var wg sync.WaitGroup
wg.Add(int(concurrency))
startTime := time.Now().UnixNano()
for i:=int64(0); i<counter.Concurrency; i++ {
go func(i int64) {
// Set up a connection to the server.
conn, err := grpc.Dial("127.0.0.1:8000", grpc.WithInsecure())
if err != nil {
log.Info("did not connect: %v", err)
}
defer conn.Close()
for j:=int64(0); j< perClientReqs; j++ {
c := pb.NewGreeterClient(conn)
ctx, cancel := context.WithTimeout(context.Background(), time.Second)
defer cancel()
rsp, err := c.SayHello(ctx, req)
if err != nil {
log.Info("could not greet: %v", err)
}
if err == nil && rsp.Message == "world" {
atomic.AddInt64(&counter.Succ, 1)
} else {
log.Info("rsp fail : %v", err)
atomic.AddInt64(&counter.Fail, 1)
}
}
wg.Done()
}(i)
}
wg.Wait()
counter.Cost = (time.Now().UnixNano() - startTime) / 1000000
log.Info("took %d ms for %d requests", counter.Cost, counter.Total)
log.Info("sent requests : %d\n", counter.Total)
log.Info("received requests : %d\n", atomic.LoadInt64(&counter.Succ) + atomic.LoadInt64(&counter.Fail))
log.Info("received requests succ : %d\n", atomic.LoadInt64(&counter.Succ))
log.Info("received requests fail : %d\n", atomic.LoadInt64(&counter.Fail))
log.Info("throughput (TPS) : %d\n", totalReqs*1000/counter.Cost)
}
type Counter struct {
Succ int64 // 成功量
Fail int64 // 失败量
Total int64 // 总量
Concurrency int64 // 并发量
Cost int64 // 总耗时 ms
}
6.Go并发编程
Mutex
使用互斥锁,限定临界区只能同时由一个线程持有
当一个 goroutine 通过调用 Lock 方法获得了这个锁的拥有权后, 其它请求锁的 goroutine 就会阻塞在 Lock 方法的调用上,直到锁被释放并且自己获取到了这个锁的拥有权。
在编译(compile)、测试(test)或者运行(run)Go 代码的时候,加上 race 参数,就有可能发现并发问题。
race detector依赖运行时的检测,不是编译期探测的
go run -race counter.go
采用嵌入字段的方式
如果嵌入的 struct 有多个字段,我们一般会把 Mutex 放在要控制的字段上面,然后使用空格把字段分隔开来。
把获取锁、释放锁、计数加一的逻辑封装成一个方法
package main
import (
"fmt"
"sync"
)
// 线程安全的计数器类型
type Counter struct {
CounterType int
Name string
mu sync.Mutex
count uint64
}
// 加1的方法,内部使用互斥锁保护
func (c *Counter) Incr() {
c.mu.Lock()
c.count++
c.mu.Unlock()
}
// 得到计数器的值,也需要锁保护
func (c *Counter) Count() uint64 {
c.mu.Lock()
defer c.mu.Unlock()
return c.count
}
func main() {
// 封装好的计数器
var c Counter
var wg sync.WaitGroup
wg.Add(10)
// 启动10个goroutine
for i := 0; i < 10; i++ {
go func() {
defer wg.Done()
// 执行1万次累加
for j := 0; j < 10000; j++ {
c.Incr() // 受到锁保护的方法
}
}()
}
wg.Wait()
fmt.Println("finish.", c.Count())
}
思考题
如果 Mutex 已经被一个 goroutine 获取了锁,其它等待中的 goroutine 们只能一直等待。那么,等这个锁释放后,等待中的 goroutine 中哪一个会优先获取 Mutex 呢?
互斥锁有两种状态:正常状态和饥饿状态。
在正常状态下,所有等待锁的goroutine按照FIFO顺序等待。唤醒的goroutine不会直接拥有锁,而是会和新请求锁的goroutine竞争锁的拥有。新请求锁的goroutine具有优势:它正在CPU上执行,而且可能有好几个,所以刚刚唤醒的goroutine有很大可能在锁竞争中失败。在这种情况下,这个被唤醒的goroutine会加入到等待队列的前面。 如果一个等待的goroutine超过1ms没有获取锁,那么它将会把锁转变为饥饿模式。
在饥饿模式下,锁的所有权将从unlock的gorutine直接交给交给等待队列中的第一个。新来的goroutine将不会尝试去获得锁,即使锁看起来是unlock状态, 也不会去尝试自旋操作,而是放在等待队列的尾部。
如果一个等待的goroutine获取了锁,并且满足一以下其中的任何一个条件:(1)它是队列中的最后一个;(2)它等待的时候小于1ms。它会将锁的状态转换为正常状态。
正常状态有很好的性能表现,饥饿模式也是非常重要的,因为它能阻止尾部延迟的现象。
初版的互斥锁
// CAS操作,当时还没有抽象出atomic包
func cas(val *int32, old, new int32) bool
func semacquire(*int32)
func semrelease(*int32)
// 互斥锁的结构,包含两个字段
type Mutex struct {
key int32 // 锁是否被持有的标识
sema int32 // 信号量专用,用以阻塞/唤醒goroutine
}
// 保证成功在val上增加delta的值
func xadd(val *int32, delta int32) (new int32) {
for {
v := *val
if cas(val, v, v+delta) {
return v + delta
}
}
panic("unreached")
}
// 请求锁
func (m *Mutex) Lock() {
if xadd(&m.key, 1) == 1 { //标识加1,如果等于1,成功获取到锁
return
}
semacquire(&m.sema) // 否则阻塞等待
}
func (m *Mutex) Unlock() {
if xadd(&m.key, -1) == 0 { // 将标识减去1,如果等于0,则没有其它等待者
return
}
semrelease(&m.sema) // 唤醒其它阻塞的goroutine
}
Unlock 方法可以被任意的 goroutine 调用释放锁,即使是没持有这个互斥锁的 goroutine,也可以进行这个操作。这是因为,Mutex 本身并没有包含持有这把锁的 goroutine 的信息,所以,Unlock 也不会对此进行检查。Mutex 的这个设计一直保持至今。
一定要遵循“谁申请,谁释放”的原则
常见的 4 种错误场景
Lock/Unlock 不是成对出现
Copy 已使用的 Mutex
重入
Mutex 不是可重入的锁
检查死锁使用 vet 工具
go vet copy.go
标准库 Mutex 不是可重入锁,自己实现一个可重入锁
方案一:通过 hacker 的方式获取到 goroutine id,记录下获取锁的 goroutine id,它可以实现 Locker 接口。
- 简单方式,就是通过 runtime.Stack 方法获取栈帧信息,栈帧信息里包含 goroutine id。
- hacker 方式,常用的库 petermattis/goid
// RecursiveMutex 包装一个Mutex,实现可重入
type RecursiveMutex struct {
sync.Mutex
owner int64 // 当前持有锁的goroutine id
recursion int32 // 这个goroutine 重入的次数
}
func (m *RecursiveMutex) Lock() {
gid := goid.Get()
// 如果当前持有锁的goroutine就是这次调用的goroutine,说明是重入
if atomic.LoadInt64(&m.owner) == gid {
m.recursion++
return
}
m.Mutex.Lock()
// 获得锁的goroutine第一次调用,记录下它的goroutine id,调用次数加1
atomic.StoreInt64(&m.owner, gid)
m.recursion = 1
}
func (m *RecursiveMutex) Unlock() {
gid := goid.Get()
// 非持有锁的goroutine尝试释放锁,错误的使用
if atomic.LoadInt64(&m.owner) != gid {
panic(fmt.Sprintf("wrong the owner(%d): %d!", m.owner, gid))
}
// 调用次数减1
m.recursion--
if m.recursion != 0 { // 如果这个goroutine还没有完全释放,则直接返回
return
}
// 此goroutine最后一次调用,需要释放锁
atomic.StoreInt64(&m.owner, -1)
m.Mutex.Unlock()
}
尽管拥有者可以多次调用 Lock,但是也必须调用相同次数的 Unlock,这样才能把锁释放掉。这是一个合理的设计,可以保证 Lock 和 Unlock 一一对应。
- 方案二:调用 Lock/Unlock 方法时,由 goroutine 提供一个 token,用来标识它自己,而不是我们通过 hacker 的方式获取到 goroutine id,但是,这样一来,就不满足 Locker 接口了。
// Token方式的递归锁
type TokenRecursiveMutex struct {
sync.Mutex
token int64
recursion int32
}
// 请求锁,需要传入token
func (m *TokenRecursiveMutex) Lock(token int64) {
if atomic.LoadInt64(&m.token) == token { //如果传入的token和持有锁的token一致,说明是递归调用
m.recursion++
return
}
m.Mutex.Lock() // 传入的token不一致,说明不是递归调用
// 抢到锁之后记录这个token
atomic.StoreInt64(&m.token, token)
m.recursion = 1
}
// 释放锁
func (m *TokenRecursiveMutex) Unlock(token int64) {
if atomic.LoadInt64(&m.token) != token { // 释放其它token持有的锁
panic(fmt.Sprintf("wrong the owner(%d): %d!", m.token, token))
}
m.recursion-- // 当前持有这个锁的token释放锁
if m.recursion != 0 { // 还没有回退到最初的递归调用
return
}
atomic.StoreInt64(&m.token, 0) // 没有递归调用了,释放锁
m.Mutex.Unlock()
}
死锁
- 互斥: 至少一个资源是被排他性独享的,其他线程必须处于等待状态,直到资源被释放。
- 持有和等待:goroutine 持有一个资源,并且还在请求其它 goroutine 持有的资源,也就是咱们常说的“吃着碗里,看着锅里”的意思。
- 不可剥夺:资源只能由持有它的 goroutine 来释放。
- 环路等待:一般来说,存在一组等待进程,P={P1,P2,…,PN},P1 等待 P2 持有的资源,P2 等待 P3 持有的资源,依此类推,最后是 PN 等待 P1 持有的资源,这就形成了一个环路等待的死结。
使用 Mutex 实现一个线程安全的队列
type SliceQueue struct {
data []interface{}
mu sync.Mutex
}
func NewSliceQueue(n int) (q *SliceQueue) {
return &SliceQueue{data: make([]interface{}, 0, n)}
}
// Enqueue 把值放在队尾
func (q *SliceQueue) Enqueue(v interface{}) {
q.mu.Lock()
q.data = append(q.data, v)
q.mu.Unlock()
}
// Dequeue 移去队头并返回
func (q *SliceQueue) Dequeue() interface{} {
q.mu.Lock()
if len(q.data) == 0 {
q.mu.Unlock()
return nil
}
v := q.data[0]
q.data = q.data[1:]
q.mu.Unlock()
return v
}
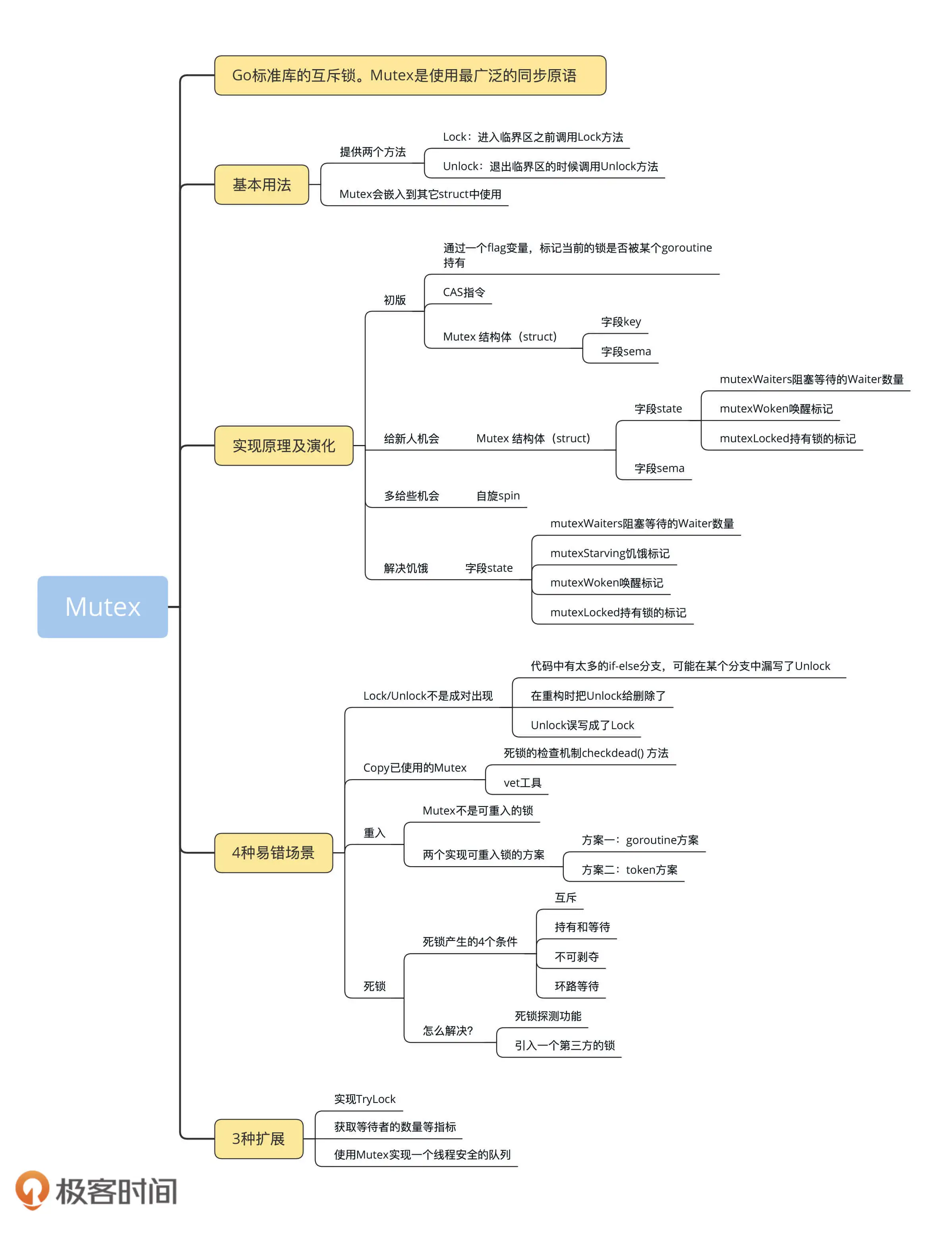
标准库中的 RWMutex 是一个 reader/writer 互斥锁。RWMutex 在某一时刻只能由任意数量的 reader 持有,或者是只被单个的 writer 持有。
- Lock/Unlock:写操作时调用的方法。如果锁已经被 reader 或者 writer 持有,那么,Lock 方法会一直阻塞,直到能获取到锁;Unlock 则是配对的释放锁的方法。
- RLock/RUnlock:读操作时调用的方法。如果锁已经被 writer 持有的话,RLock 方法会一直阻塞,直到能获取到锁,否则就直接返回;而 RUnlock 是 reader 释放锁的方法。
- RLocker:这个方法的作用是为读操作返回一个 Locker 接口的对象。它的 Lock 方法会调用 RWMutex 的 RLock 方法,它的 Unlock 方法会调用 RWMutex 的 RUnlock 方法。
func main() {
var counter Counter
for i := 0; i < 10; i++ { // 10个reader
go func() {
for {
counter.Count() // 计数器读操作
time.Sleep(time.Millisecond)
}
}()
}
for { // 一个writer
counter.Incr() // 计数器写操作
time.Sleep(time.Second)
}
}
// 一个线程安全的计数器
type Counter struct {
mu sync.RWMutex
count uint64
}
// 使用写锁保护
func (c *Counter) Incr() {
c.mu.Lock()
c.count++
c.mu.Unlock()
}
// 使用读锁保护
func (c *Counter) Count() uint64 {
c.mu.RLock()
defer c.mu.RUnlock()
return c.count
}
RWMutex 的 3 个踩坑点
坑点1:不可复制
坑点 2:重入导致死锁
坑点 3:释放未加锁的 RWMutex
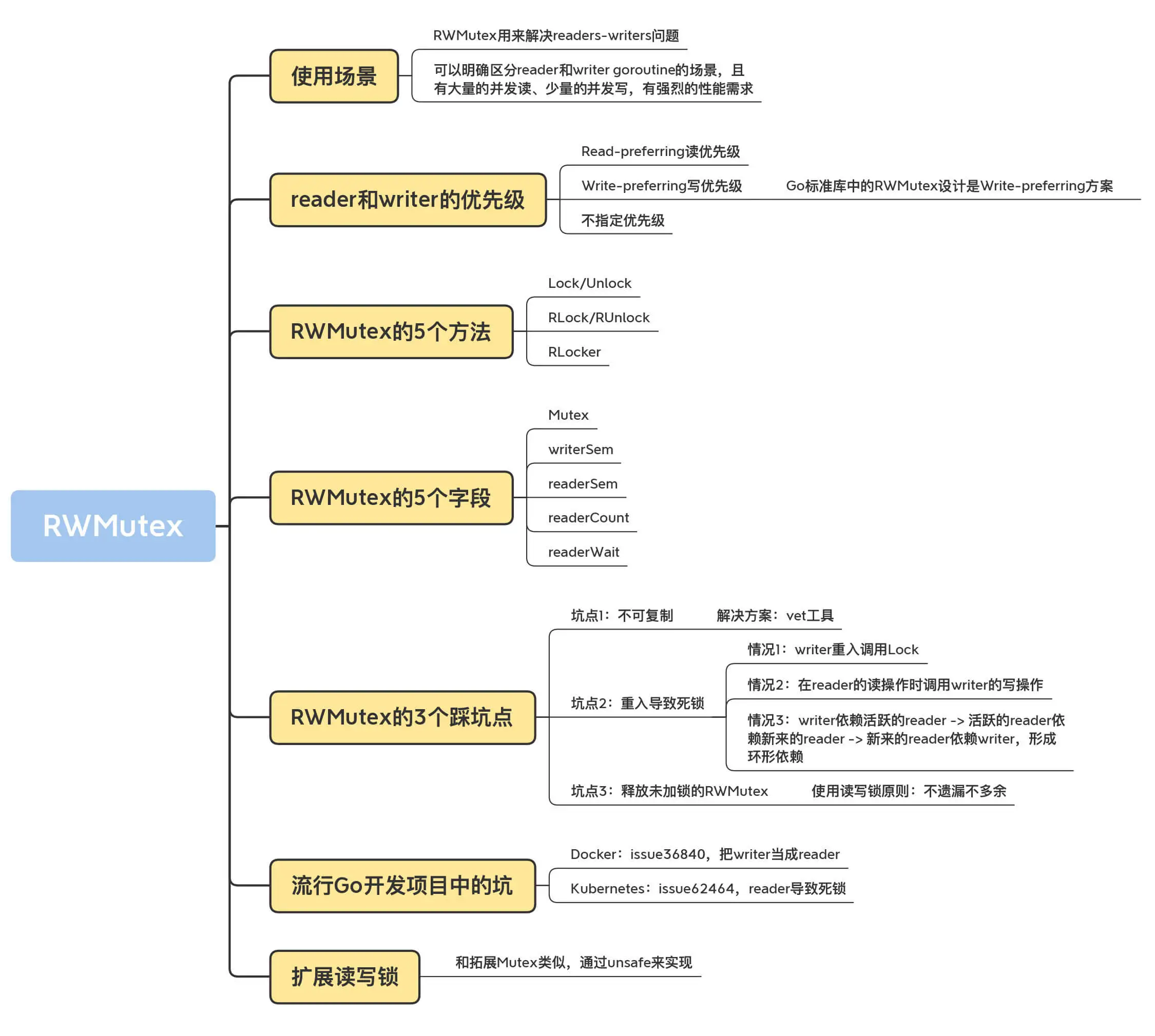
WaitGroup
使用 WaitGroup 时的常见错误
- 常见问题一:计数器设置为负值
WaitGroup 的计数器的值必须大于等于 0。我们在更改这个计数值的时候,WaitGroup 会先做检查,如果计数值被设置为负数,就会导致 panic。
一般情况下,有两种方法会导致计数器设置为负数。
第一种方法是:调用 Add 的时候传递一个负数。如果你能保证当前的计数器加上这个负数后还是大于等于 0 的话,也没有问题,否则就会导致 panic。
第二个方法是:调用 Done 方法的次数过多,超过了 WaitGroup 的计数值。
使用 WaitGroup 的正确姿势是,预先确定好 WaitGroup 的计数值,然后调用相同次数的 Done 完成相应的任务。比如,在 WaitGroup 变量声明之后,就立即设置它的计数值,或者在 goroutine 启动之前增加 1,然后在 goroutine 中调用 Done。
常见问题二:不期望的 Add 时机
在使用 WaitGroup 的时候,你一定要遵循的原则就是,等所有的 Add 方法调用之后再调用 Wait,否则就可能导致 panic 或者不期望的结果。
常见问题三:前一个 Wait 还没结束就重用 WaitGroup
“前一个 Wait 还没结束就重用 WaitGroup”这一点似乎不太好理解,我借用田径比赛的例子和你解释下吧。在田径比赛的百米小组赛中,需要把选手分成几组,一组选手比赛完之后,就可以进行下一组了。为了确保两组比赛时间上没有冲突,我们在模型化这个场景的时候,可以使用 WaitGroup。
WaitGroup 等一组比赛的所有选手都跑完后 5 分钟,才开始下一组比赛。下一组比赛还可以使用这个 WaitGroup 来控制,因为 WaitGroup 是可以重用的。只要 WaitGroup 的计数值恢复到零值的状态,那么它就可以被看作是新创建的 WaitGroup,被重复使用。
noCopy:辅助 vet 检查
我们刚刚在学习 WaitGroup 的数据结构时,提到了里面有一个 noCopy 字段。你还记得它的作用吗?其实,它就是指示 vet 工具在做检查的时候,这个数据结构不能做值复制使用。更严谨地说,是不能在第一次使用之后复制使用 ( must not be copied after first use)。
总结
学完这一讲,我们知道了使用 WaitGroup 容易犯的错,是不是有些手脚被束缚的感觉呢?其实大可不必,只要我们不是特别复杂地使用 WaitGroup,就不用有啥心理负担。
而关于如何避免错误使用 WaitGroup 的情况,我们只需要尽量保证下面 5 点就可以了:
- 不重用 WaitGroup。新建一个 WaitGroup 不会带来多大的资源开销,重用反而更容易出错。
- 保证所有的 Add 方法调用都在 Wait 之前。
- 不传递负数给 Add 方法,只通过 Done 来给计数值减 1。
- 不做多余的 Done 方法调用,保证 Add 的计数值和 Done 方法调用的数量是一样的。
- 不遗漏 Done 方法的调用,否则会导致 Wait hang 住无法返回。
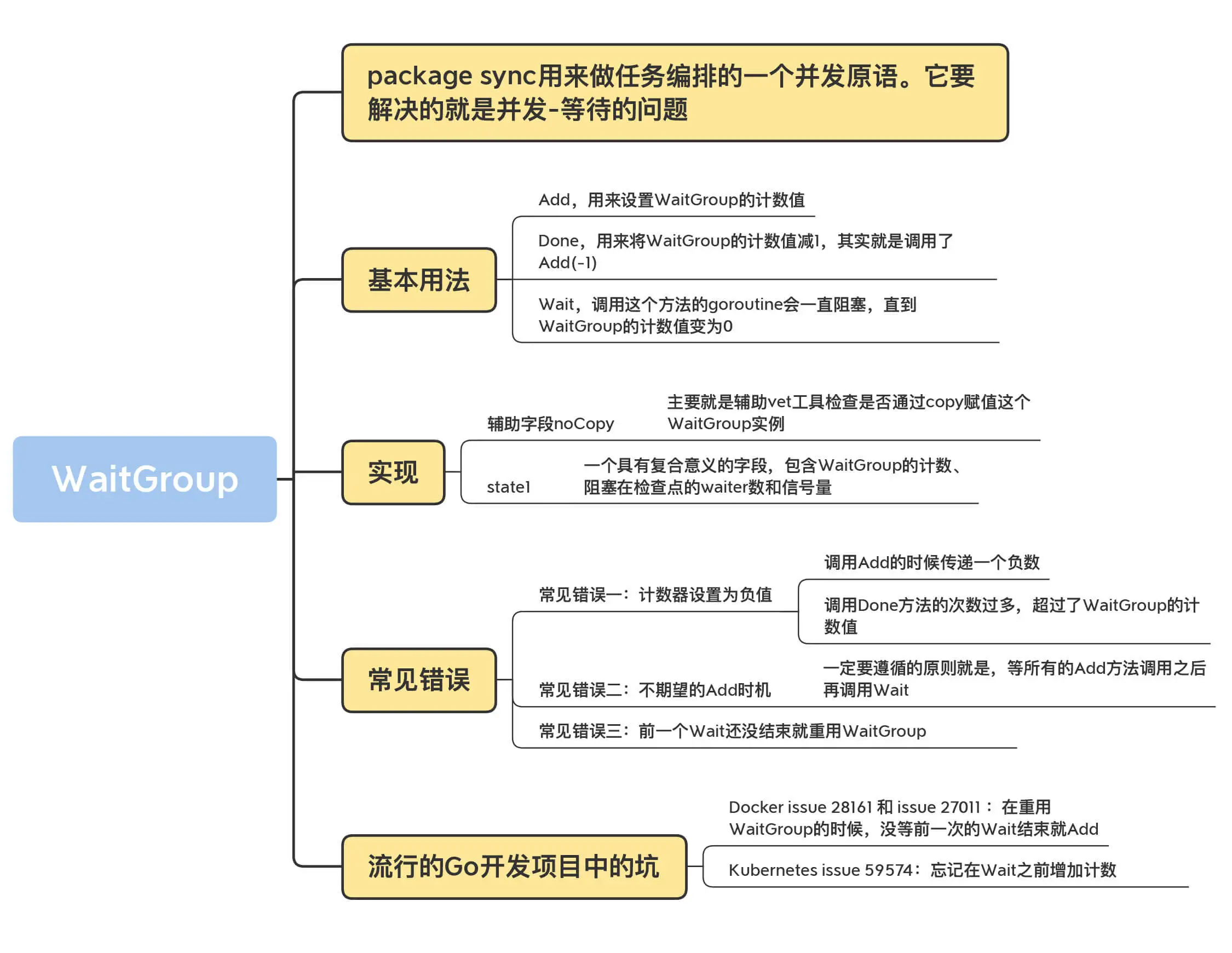
Cond
条件变量的实现机制及避坑指南
Go 标准库提供 Cond 原语的目的是,为等待 / 通知场景下的并发问题提供支持。Cond 通常应用于等待某个条件的一组 goroutine,等条件变为 true 的时候,其中一个 goroutine 或者所有的 goroutine 都会被唤醒执行。
顾名思义,Cond 是和某个条件相关,这个条件需要一组 goroutine 协作共同完成,在条件还没有满足的时候,所有等待这个条件的 goroutine 都会被阻塞住,只有这一组 goroutine 通过协作达到了这个条件,等待的 goroutine 才可能继续进行下去。
那这里等待的条件是什么呢?等待的条件,可以是某个变量达到了某个阈值或者某个时间点,也可以是一组变量分别都达到了某个阈值,还可以是某个对象的状态满足了特定的条件。总结来讲,等待的条件是一种可以用来计算结果是 true 还是 false 的条件。
从开发实践上,我们真正使用 Cond 的场景比较少,因为一旦遇到需要使用 Cond 的场景,我们更多地会使用 Channel 的方式。
func main() {
c := sync.NewCond(&sync.Mutex{})
var ready int
for i := 0; i < 10; i++ {
go func(i int) {
time.Sleep(time.Duration(rand.Int63n(10)) * time.Second)
// 加锁更改等待条件
c.L.Lock()
ready++
c.L.Unlock()
log.Printf("运动员#%d 已准备就绪\n", i)
// 广播唤醒所有的等待者
c.Broadcast()
}(i)
}
c.L.Lock()
for ready != 10 {
c.Wait()
log.Println("裁判员被唤醒一次")
}
c.L.Unlock()
//所有的运动员是否就绪
log.Println("所有运动员都准备就绪。比赛开始,3,2,1, ......")
}
Cond 在实际项目中被使用的机会比较少
第一,同样的场景我们会使用其他的并发原语来替代。Go 特有的 Channel 类型,有一个应用很广泛的模式就是通知机制,这个模式使用起来也特别简单。所以很多情况下,我们会使用 Channel 而不是 Cond 实现 wait/notify 机制。
第二,对于简单的 wait/notify 场景,比如等待一组 goroutine 完成之后继续执行余下的代码,我们会使用 WaitGroup 来实现。因为 WaitGroup 的使用方法更简单,而且不容易出错。比如,上面百米赛跑的问题,就可以很方便地使用 WaitGroup 来实现。
使用 Cond 之所以容易出错,就是 Wait 调用需要加锁,以及被唤醒后一定要检查条件是否真的已经满足。你需要牢记这两点。
虽然我们讲到的百米赛跑的例子,也可以通过 WaitGroup 来实现,但是本质上 WaitGroup 和 Cond 是有区别的:WaitGroup 是主 goroutine 等待确定数量的子 goroutine 完成任务;而 Cond 是等待某个条件满足,这个条件的修改可以被任意多的 goroutine 更新,而且 Cond 的 Wait 不关心也不知道其他 goroutine 的数量,只关心等待条件。而且 Cond 还有单个通知的机制,也就是 Signal 方法。
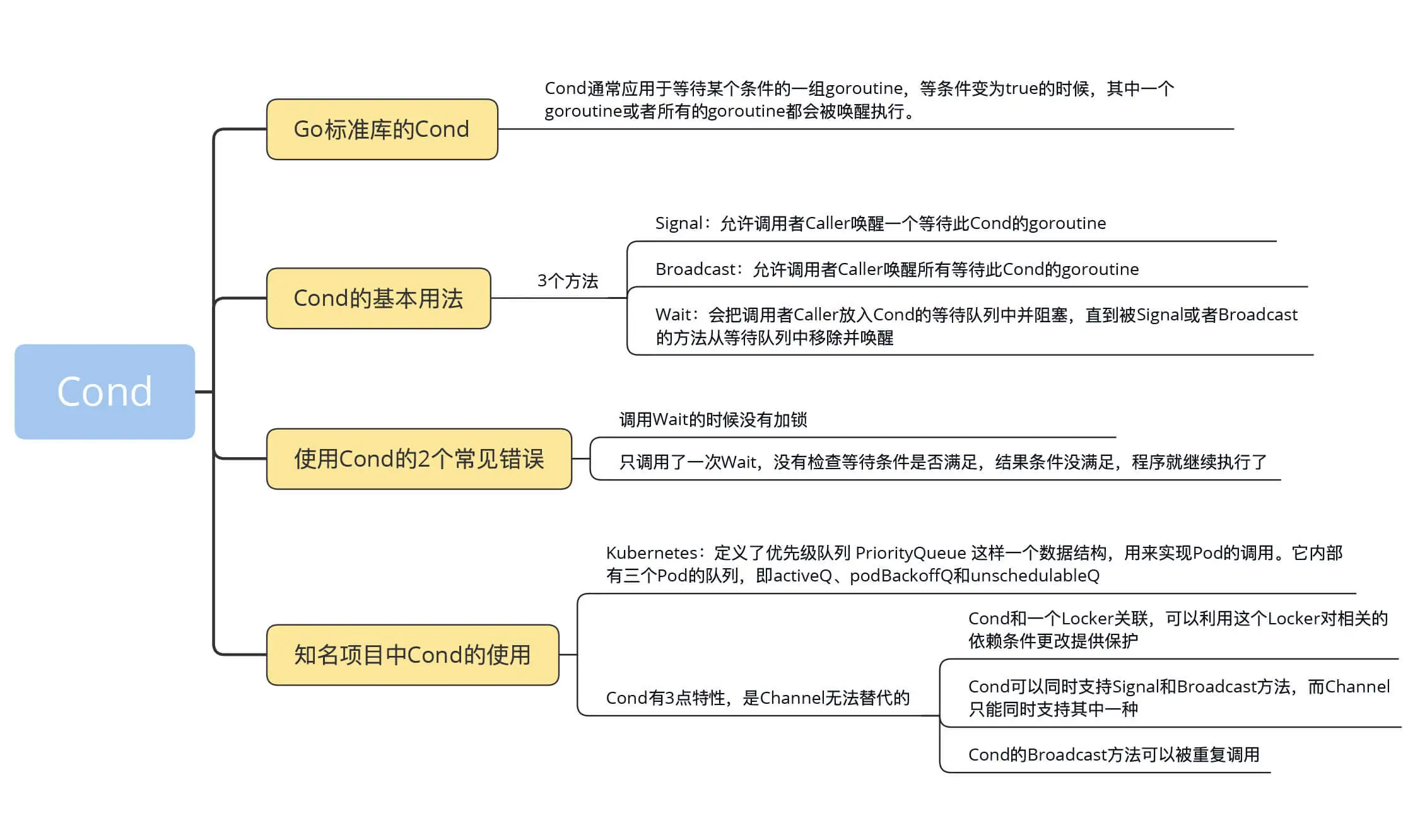
Once
Once 可以用来执行且仅仅执行一次动作,常常用于单例对象的初始化场景。
sync.Once 只暴露了一个方法 Do,你可以多次调用 Do 方法,但是只有第一次调用 Do 方法时 f 参数才会执行,这里的 f 是一个无参数无返回值的函数。
func (o *Once) Do(f func())
// 值是3.0或者0.0的一个数据结构
var threeOnce struct {
sync.Once
v *Float
}
// 返回此数据结构的值,如果还没有初始化为3.0,则初始化
func three() *Float {
threeOnce.Do(func() { // 使用Once初始化
threeOnce.v = NewFloat(3.0)
})
return threeOnce.v
}
它将 sync.Once 和 *Float 封装成一个对象,提供了只初始化一次的值 v。 你看它的 three 方法的实现,虽然每次都调用 threeOnce.Do 方法,但是参数只会被调用一次。
当你使用 Once 的时候,你也可以尝试采用这种结构,将值和 Once 封装成一个新的数据结构,提供只初始化一次的值。
Once 常常用来初始化单例资源,或者并发访问只需初始化一次的共享资源,或者在测试的时候初始化一次测试资源。
一个正确的 Once 实现要使用一个互斥锁,这样初始化的时候如果有并发的 goroutine,就会进入doSlow 方法。 互斥锁的机制保证只有一个 goroutine 进行初始化,同时利用双检查的机制(double-checking),再次判断 o.done 是否为 0,如果为 0,则是第一次执行,执行完毕后,就将 o.done 设置为 1,然后释放锁。
type Once struct {
done uint32
m Mutex
}
func (o *Once) Do(f func()) {
if atomic.LoadUint32(&o.done) == 0 {
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
o.m.Lock()
defer o.m.Unlock()
// 双检查
if o.done == 0 {
defer atomic.StoreUint32(&o.done, 1)
f()
}
}
使用 Once 可能出现的 2 种错误
第一种错误:死锁
你已经知道了 Do 方法会执行一次 f,但是如果 f 中再次调用这个 Once 的 Do 方法的话,就会导致死锁的情况出现。这还不是无限递归的情况,而是的的确确的 Lock 的递归调用导致的死锁。
第二种错误:未初始化
如果 f 方法执行的时候 panic,或者 f 执行初始化资源的时候失败了,这个时候,Once 还是会认为初次执行已经成功了,即使再次调用 Do 方法,也不会再次执行 f。
自己实现一个类似 Once 的并发原语, 既可以返回当前调用 Do 方法是否正确完成,还可以在初始化失败后调用 Do 方法再次尝试初始化,直到初始化成功才不再初始化了。
// 一个功能更加强大的Once
type Once struct {
m sync.Mutex
done uint32
}
// 传入的函数f有返回值error,如果初始化失败,需要返回失败的error
// Do方法会把这个error返回给调用者
func (o *Once) Do(f func() error) error {
if atomic.LoadUint32(&o.done) == 1 { //fast path
return nil
}
return o.slowDo(f)
}
// 如果还没有初始化
func (o *Once) slowDo(f func() error) error {
o.m.Lock()
defer o.m.Unlock()
var err error
if o.done == 0 { // 双检查,还没有初始化
err = f()
if err == nil { // 初始化成功才将标记置为已初始化
atomic.StoreUint32(&o.done, 1)
}
}
return err
}
一旦你遇到只需要初始化一次的场景,首先想到的就应该是 Once 并发原语。
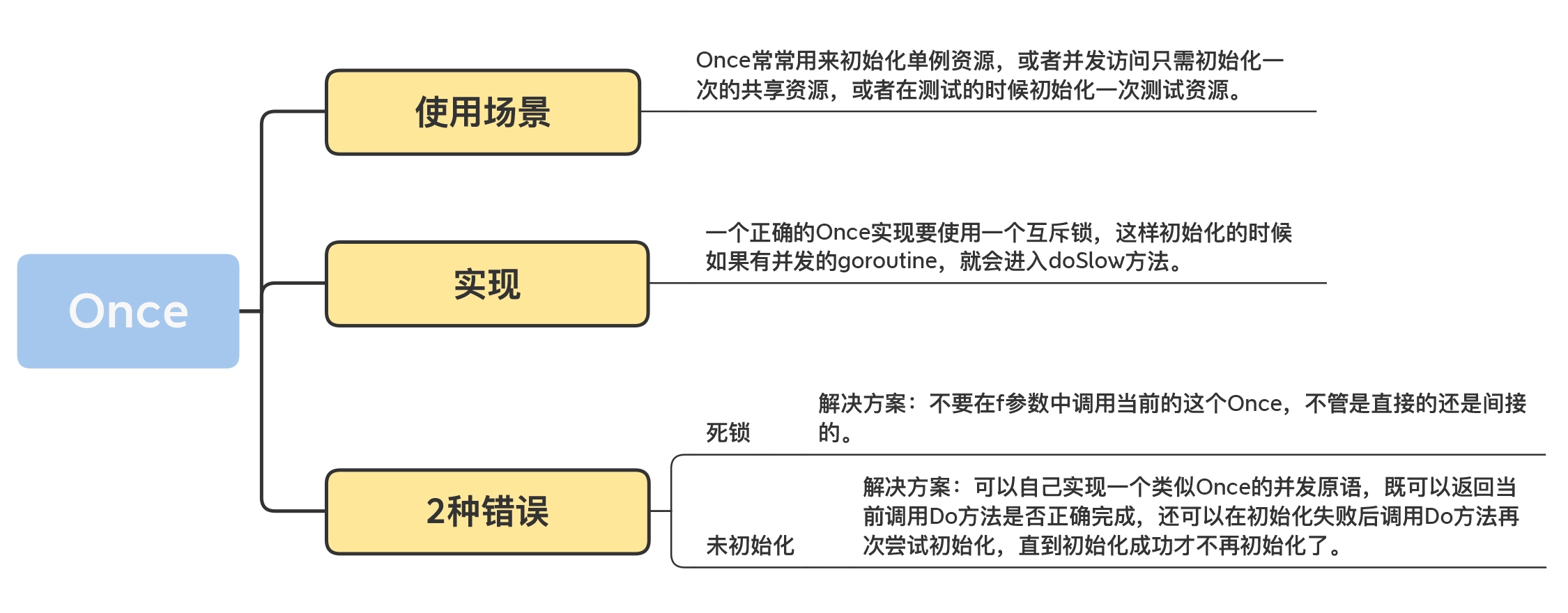
map
Go 内建的 map 类型
map[K]V
key 类型的 K 必须是可比较的(comparable)
使用 map 的 2 种常见错误
常见错误一:未初始化
有时候 map 作为一个 struct 字段的时候,就很容易忘记初始化了。
type Counter struct {
Website string
Start time.Time
PageCounters map[string]int
}
func main() {
var c Counter
c.Website = "baidu.com"
c.PageCounters["/"]++ // panic: assignment to entry in nil map
}
常见错误二:并发读写
在删除 map 对象的元素时忘记了加锁
加读写锁:扩展 map,支持并发读写
以一个具体的 map 类型为例,来演示利用读写锁实现线程安全的 map[int]int 类型:
type RWMap struct { // 一个读写锁保护的线程安全的map
sync.RWMutex // 读写锁保护下面的map字段
m map[int]int
}
// 新建一个RWMap
func NewRWMap(n int) *RWMap {
return &RWMap{
m: make(map[int]int, n),
}
}
func (m *RWMap) Get(k int) (int, bool) { //从map中读取一个值
m.RLock()
defer m.RUnlock()
v, existed := m.m[k] // 在锁的保护下从map中读取
return v, existed
}
func (m *RWMap) Set(k int, v int) { // 设置一个键值对
m.Lock() // 锁保护
defer m.Unlock()
m.m[k] = v
}
func (m *RWMap) Delete(k int) { //删除一个键
m.Lock() // 锁保护
defer m.Unlock()
delete(m.m, k)
}
func (m *RWMap) Len() int { // map的长度
m.RLock() // 锁保护
defer m.RUnlock()
return len(m.m)
}
func (m *RWMap) Each(f func(k, v int) bool) { // 遍历map
m.RLock() //遍历期间一直持有读锁
defer m.RUnlock()
for k, v := range m.m {
if !f(k, v) {
return
}
}
}
分片加锁:更高效的并发 map
在并发编程中,我们的一条原则就是尽量减少锁的使用。一些单线程单进程的应用(比如 Redis 等),基本上不需要使用锁去解决并发线程访问的问题,所以可以取得很高的性能。但是对于 Go 开发的应用程序来说,并发是常用的一个特性,在这种情况下,我们能做的就是,尽量减少锁的粒度和锁的持有时间。
减少锁的粒度常用的方法就是分片(Shard),将一把锁分成几把锁,每个锁控制一个分片。Go 比较知名的分片并发 map 的实现是orcaman/concurrent-map。
它默认采用 32 个分片,GetShard 是一个关键的方法,能够根据 key 计算出分片索引。
var SHARD_COUNT = 32
// 分成SHARD_COUNT个分片的map
type ConcurrentMap []*ConcurrentMapShared
// 通过RWMutex保护的线程安全的分片,包含一个map
type ConcurrentMapShared struct {
items map[string]interface{}
sync.RWMutex // Read Write mutex, guards access to internal map.
}
// 创建并发map
func New() ConcurrentMap {
m := make(ConcurrentMap, SHARD_COUNT)
for i := 0; i < SHARD_COUNT; i++ {
m[i] = &ConcurrentMapShared{items: make(map[string]interface{})}
}
return m
}
// 根据key计算分片索引
func (m ConcurrentMap) GetShard(key string) *ConcurrentMapShared {
return m[uint(fnv32(key))%uint(SHARD_COUNT)]
}
增加或者查询的时候,首先根据分片索引得到分片对象,然后对分片对象加锁进行操作:
func (m ConcurrentMap) Set(key string, value interface{}) {
// 根据key计算出对应的分片
shard := m.GetShard(key)
shard.Lock() //对这个分片加锁,执行业务操作
shard.items[key] = value
shard.Unlock()
}
func (m ConcurrentMap) Get(key string) (interface{}, bool) {
// 根据key计算出对应的分片
shard := m.GetShard(key)
shard.RLock()
// 从这个分片读取key的值
val, ok := shard.items[key]
shard.RUnlock()
return val, ok
}
在我个人使用并发 map 的过程中,加锁和分片加锁这两种方案都比较常用,如果是追求更高的性能,显然是分片加锁更好,因为它可以降低锁的粒度,进而提高访问此 map 对象的吞吐。如果并发性能要求不是那么高的场景,简单加锁方式更简单。
应对特殊场景的 sync.Map
只会增长的缓存系统中,一个 key 只写入一次而被读很多次;
多个 goroutine 为不相交的键集读、写和重写键值对。
当然还有一些扩展其它功能的 map 实现,比如带有过期功能的timedmap、使用红黑树实现的 key 有序的treemap等
Pool
Go 是一个自动垃圾回收的编程语言,采用三色并发标记算法标记对象并回收。和其它没有自动垃圾回收的编程语言不同,使用 Go 语言创建对象的时候,我们没有回收 / 释放的心理负担,想用就用,想创建就创建。
但是,如果你想使用 Go 开发一个高性能的应用程序的话,就必须考虑垃圾回收给性能带来的影响,毕竟,Go 的自动垃圾回收机制还是有一个 STW(stop-the-world,程序暂停)的时间,而且,大量地创建在堆上的对象,也会影响垃圾回收标记的时间。
所以,一般我们做性能优化的时候,会采用对象池的方式,把不用的对象回收起来,避免被垃圾回收掉,这样使用的时候就不必在堆上重新创建了。
Go 标准库中提供了一个通用的 Pool 数据结构,也就是 sync.Pool,我们使用它可以创建池化的对象。这节课我会详细给你介绍一下 sync.Pool 的使用方法、实现原理以及常见的坑,帮助你全方位地掌握标准库的 Pool。
不过,这个类型也有一些使用起来不太方便的地方,就是它池化的对象可能会被垃圾回收掉,这对于数据库长连接等场景是不合适的。所以在这一讲中,我会专门介绍其它的一些 Pool,包括 TCP 连接池、数据库连接池等等。
sync.Pool 本身就是线程安全的,多个 goroutine 可以并发地调用它的方法存取对象;
sync.Pool 不可在使用之后再复制使用。
sync.Pool 的使用方法
知道了 sync.Pool 这个数据类型的特点,接下来,我们来学习下它的使用方法。其实,这个数据类型不难,它只提供了三个对外的方法:New、Get 和 Put。
sync.Pool 最常用的一个场景:buffer 池(缓冲池)。
因为 byte slice 是经常被创建销毁的一类对象,使用 buffer 池可以缓存已经创建的 byte slice,比如,著名的静态网站生成工具 Hugo 中,就包含这样的实现 bufpool,你可以看一下下面这段代码:
var buffers = sync.Pool{
New: func() interface{} {
return new(bytes.Buffer)
},
}
func GetBuffer() *bytes.Buffer {
return buffers.Get().(*bytes.Buffer)
}
func PutBuffer(buf *bytes.Buffer) {
buf.Reset()
buffers.Put(buf)
}
内存泄漏
可以使用 sync.Pool 做 buffer 池,但是,如果用刚刚的那种方式做 buffer 池的话,可能会有内存泄漏的风险。为啥这么说呢?我们来分析一下。取出来的 bytes.Buffer 在使用的时候,我们可以往这个元素中增加大量的 byte 数据,这会导致底层的 byte slice 的容量可能会变得很大。这个时候,即使 Reset 再放回到池子中,这些 byte slice 的容量不会改变,所占的空间依然很大。而且,因为 Pool 回收的机制,这些大的 Buffer 可能不被回收,而是会一直占用很大的空间,这属于内存泄漏的问题。
在使用 sync.Pool 回收 buffer 的时候,一定要检查回收的对象的大小。 如果 buffer 太大,就不要回收了,否则就太浪费了。
要做到物尽其用,尽可能不浪费的话,我们可以将 buffer 池分成几层。首先,小于 512 byte 的元素的 buffer 占一个池子;其次,小于 1K byte 大小的元素占一个池子;再次,小于 4K byte 大小的元素占一个池子。这样分成几个池子以后,就可以根据需要,到所需大小的池子中获取 buffer 了。
第三方库
这是 fasthttp 作者 valyala 提供的一个 buffer 池,基本功能和 sync.Pool 相同。它的底层也是使用 sync.Pool 实现的,包括会检测最大的 buffer,超过最大尺寸的 buffer,就会被丢弃。
bpool 是基于 Channel 实现的,不像 sync.Pool 为了提高性能而做了很多优化,所以,在性能上比不过 sync.Pool。不过,它提供了限制 Pool 容量的功能,所以,如果你想控制 Pool 的容量的话,可以考虑这个库。
连接池
Pool 的另一个很常用的一个场景就是保持 TCP 的连接。一个 TCP 的连接创建,需要三次握手等过程,如果是 TLS 的,还会需要更多的步骤,如果加上身份认证等逻辑的话,耗时会更长。所以,为了避免每次通讯的时候都新创建连接,我们一般会建立一个连接的池子,预先把连接创建好,或者是逐步把连接放在池子中,减少连接创建的耗时,从而提高系统的性能。
事实上,我们很少会使用 sync.Pool 去池化连接对象,原因就在于,sync.Pool 会无通知地在某个时候就把连接移除垃圾回收掉了,而我们的场景是需要长久保持这个连接,所以,我们一般会使用其它方法来池化连接,比如接下来我要讲到的几种需要保持长连接的 Pool。
标准库中的 http client 池
标准库的 http.Client 是一个 http client 的库,可以用它来访问 web 服务器。为了提高性能,这个 Client 的实现也是通过池的方法来缓存一定数量的连接,以便后续重用这些连接。
TCP 连接池
最常用的一个 TCP 连接池是 fatih 开发的 fatih/pool,虽然这个项目已经被 fatih 归档(Archived),不再维护了,但是因为它相当稳定了,我们可以开箱即用。即使你有一些特殊的需求,也可以 fork 它,然后自己再做修改。
// 工厂模式,提供创建连接的工厂方法
factory := func() (net.Conn, error) { return net.Dial("tcp", "127.0.0.1:4000") }
// 创建一个tcp池,提供初始容量和最大容量以及工厂方法
p, err := pool.NewChannelPool(5, 30, factory)
// 获取一个连接
conn, err := p.Get()
// Close并不会真正关闭这个连接,而是把它放回池子,所以你不必显式地Put这个对象到池子中
conn.Close()
// 通过调用MarkUnusable, Close的时候就会真正关闭底层的tcp的连接了
if pc, ok := conn.(*pool.PoolConn); ok {
pc.MarkUnusable()
pc.Close()
}
// 关闭池子就会关闭=池子中的所有的tcp连接
p.Close()
// 当前池子中的连接的数量
current := p.Len()
虽然我一直在说 TCP,但是它管理的是更通用的 net.Conn,不局限于 TCP 连接。
它通过把 net.Conn 包装成 PoolConn,实现了拦截 net.Conn 的 Close 方法,避免了真正地关闭底层连接,而是把这个连接放回到池中:
type PoolConn struct {
net.Conn
mu sync.RWMutex
c *channelPool
unusable bool
}
//拦截Close
func (p *PoolConn) Close() error {
p.mu.RLock()
defer p.mu.RUnlock()
if p.unusable {
if p.Conn != nil {
return p.Conn.Close()
}
return nil
}
return p.c.put(p.Conn)
}
它的 Pool 是通过 Channel 实现的,空闲的连接放入到 Channel 中,这也是 Channel 的一个应用场景:
type channelPool struct {
// 存储连接池的channel
mu sync.RWMutex
conns chan net.Conn
// net.Conn 的产生器
factory Factory
}
数据库连接池
标准库 sql.DB 还提供了一个通用的数据库的连接池,通过 MaxOpenConns 和 MaxIdleConns 控制最大的连接数和最大的 idle 的连接数。默认的 MaxIdleConns 是 2,这个数对于数据库相关的应用来说太小了,我们一般都会调整它。

Memcached Client 连接池
Worker Pool
推荐三款易用的 Worker Pool
gammazero/workerpool:gammazero/workerpool 可以无限制地提交任务,提供了更便利的 Submit 和 SubmitWait 方法提交任务,还可以提供当前的 worker 数和任务数以及关闭 Pool 的功能。
ivpusic/grpool:grpool 创建 Pool 的时候需要提供 Worker 的数量和等待执行的任务的最大数量,任务的提交是直接往 Channel 放入任务。
dpaks/goworkers:dpaks/goworkers 提供了更便利的 Submi 方法提交任务以及 Worker 数、任务数等查询方法、关闭 Pool 的方法。它的任务的执行结果需要在 ResultChan 和 ErrChan 中去获取,没有提供阻塞的方法,但是它可以在初始化的时候设置 Worker 的数量和任务数。
类似的 Worker Pool 的实现非常多,比如还有panjf2000/ants、Jeffail/tunny 、benmanns/goworker、go-playground/pool、Sherifabdlnaby/gpool等第三方库。pond也是一个非常不错的 Worker Pool,关注度目前不是很高,但是功能非常齐全。
Context
- Context 包名导致使用的时候重复 ctx context.Context;
- Context.WithValue 可以接受任何类型的值,非类型安全;
- Context 包名容易误导人,实际上,Context 最主要的功能是取消 goroutine 的执行;
- Context 漫天飞,函数污染。
Context 基本使用方法
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key interface{}) interface{}
}
Deadline 方法会返回这个 Context 被取消的截止日期。如果没有设置截止日期,ok 的值是 false。后续每次调用这个对象的 Deadline 方法时,都会返回和第一次调用相同的结果。
Done 方法返回一个 Channel 对象。在 Context 被取消时,此 Channel 会被 close,如果没被取消,可能会返回 nil。后续的 Done 调用总是返回相同的结果。当 Done 被 close 的时候,你可以通过 ctx.Err 获取错误信息。Done 这个方法名其实起得并不好,因为名字太过笼统,不能明确反映 Done 被 close 的原因,因为 cancel、timeout、deadline 都可能导致 Done 被 close,不过,目前还没有一个更合适的方法名称。
关于 Done 方法,你必须要记住的知识点就是:如果 Done 没有被 close,Err 方法返回 nil;如果 Done 被 close,Err 方法会返回 Done 被 close 的原因。
Value 返回此 ctx 中和指定的 key 相关联的 value。
在使用 Context 的时候,有一些约定俗成的规则。
- 一般函数使用 Context 的时候,会把这个参数放在第一个参数的位置。
- 从来不把 nil 当做 Context 类型的参数值,可以使用 context.Background() 创建一个空的上下文对象,也不要使用 nil。
- Context 只用来临时做函数之间的上下文透传,不能持久化 Context 或者把 Context 长久保存。把 Context 持久化到数据库、本地文件或者全局变量、缓存中都是错误的用法。
- key 的类型不应该是字符串类型或者其它内建类型,否则容易在包之间使用 Context 时候产生冲突。使用 WithValue 时,key 的类型应该是自己定义的类型。
- 常常使用 struct{}作为底层类型定义 key 的类型。对于 exported key 的静态类型,常常是接口或者指针。这样可以尽量减少内存分配。
其实官方的文档也是比较搞笑的,文档中强调 key 的类型不要使用 string,结果接下来的例子中就是用 string 类型作为 key 的类型。你自己把握住这个要点就好,如果你能保证别人使用你的 Context 时不会和你定义的 key 冲突,那么 key 的类型就比较随意,因为你自己保证了不同包的 key 不会冲突,否则建议你尽量采用保守的 unexported 的类型。
创建特殊用途 Context 的方法
标准库中几种创建特殊用途 Context 的方法:WithValue、WithCancel、WithTimeout 和 WithDeadline,包括它们的功能以及实现方式。
我们经常使用 Context 来取消一个 goroutine 的运行,这是 Context 最常用的场景之一,Context 也被称为 goroutine 生命周期范围(goroutine-scoped)的 Context,把 Context 传递给 goroutine。但是,goroutine 需要尝试检查 Context 的 Done 是否关闭了:
func main() {
ctx, cancel := context.WithCancel(context.Background())
go func() {
defer func() {
fmt.Println("goroutine exit")
}()
for {
select {
case <-ctx.Done():
return
default:
time.Sleep(time.Second)
}
}
}()
time.Sleep(time.Second)
cancel()
time.Sleep(2 * time.Second)
}
如果你要为 Context 实现一个带超时功能的调用,比如访问远程的一个微服务,超时并不意味着你会通知远程微服务已经取消了这次调用,大概率的实现只是避免客户端的长时间等待,远程的服务器依然还执行着你的请求。
所以,有时候,Context 并不会减少对服务器的请求负担。如果在 Context 被 cancel 的时候,你能关闭和服务器的连接,中断和数据库服务器的通讯、停止对本地文件的读写,那么,这样的超时处理,同时能减少对服务调用的压力,但是这依赖于你对超时的底层处理机制。
atomic
atomic 操作的对象是一个地址,你需要把可寻址的变量的地址作为参数传递给方法,而不是把变量的值传递给方法。
Add
CAS (CompareAndSwap)
Swap
Load
Store
Value 类型
刚刚说的都是一些比较常见的类型,其实,atomic 还提供了一个特殊的类型:Value。它可以原子地存取对象类型,但也只能存取,不能 CAS 和 Swap,常常用在配置变更等场景中。

通过这个例子,你可以了解到 Value 的 Store/Load 方法的使用
type Config struct {
NodeName string
Addr string
Count int32
}
func loadNewConfig() Config {
return Config{
NodeName: "北京",
Addr: "10.77.95.27",
Count: rand.Int31(),
}
}
func main() {
var config atomic.Value
config.Store(loadNewConfig())
var cond = sync.NewCond(&sync.Mutex{})
// 设置新的config
go func() {
for {
time.Sleep(time.Duration(5+rand.Int63n(5)) * time.Second)
config.Store(loadNewConfig())
cond.Broadcast() // 通知等待着配置已变更
}
}()
go func() {
for {
cond.L.Lock()
cond.Wait() // 等待变更信号
c := config.Load().(Config) // 读取新的配置
fmt.Printf("new config: %+v\n", c)
cond.L.Unlock()
}
}()
select {}
}
使用 atomic 实现 Lock-Free queue
atomic 常常用来实现 Lock-Free 的数据结构,这次我会给你展示一个 Lock-Free queue 的实现。
package queue
import (
"sync/atomic"
"unsafe"
)
// lock-free的queue
type LKQueue struct {
head unsafe.Pointer
tail unsafe.Pointer
}
// 通过链表实现,这个数据结构代表链表中的节点
type node struct {
value interface{}
next unsafe.Pointer
}
func NewLKQueue() *LKQueue {
n := unsafe.Pointer(&node{})
return &LKQueue{head: n, tail: n}
}
// 入队
func (q *LKQueue) Enqueue(v interface{}) {
n := &node{value: v}
for {
tail := load(&q.tail)
next := load(&tail.next)
if tail == load(&q.tail) { // 尾还是尾
if next == nil { // 还没有新数据入队
if cas(&tail.next, next, n) { //增加到队尾
cas(&q.tail, tail, n) //入队成功,移动尾巴指针
return
}
} else { // 已有新数据加到队列后面,需要移动尾指针
cas(&q.tail, tail, next)
}
}
}
}
// 出队,没有元素则返回nil
func (q *LKQueue) Dequeue() interface{} {
for {
head := load(&q.head)
tail := load(&q.tail)
next := load(&head.next)
if head == load(&q.head) { // head还是那个head
if head == tail { // head和tail一样
if next == nil { // 说明是空队列
return nil
}
// 只是尾指针还没有调整,尝试调整它指向下一个
cas(&q.tail, tail, next)
} else {
// 读取出队的数据
v := next.value
// 既然要出队了,头指针移动到下一个
if cas(&q.head, head, next) {
return v // Dequeue is done. return
}
}
}
}
}
// 将unsafe.Pointer原子加载转换成node
func load(p *unsafe.Pointer) (n *node) {
return (*node)(atomic.LoadPointer(p))
}
// 封装CAS,避免直接将*node转换成unsafe.Pointer
func cas(p *unsafe.Pointer, old, new *node) (ok bool) {
return atomic.CompareAndSwapPointer(
p, unsafe.Pointer(old), unsafe.Pointer(new))
}
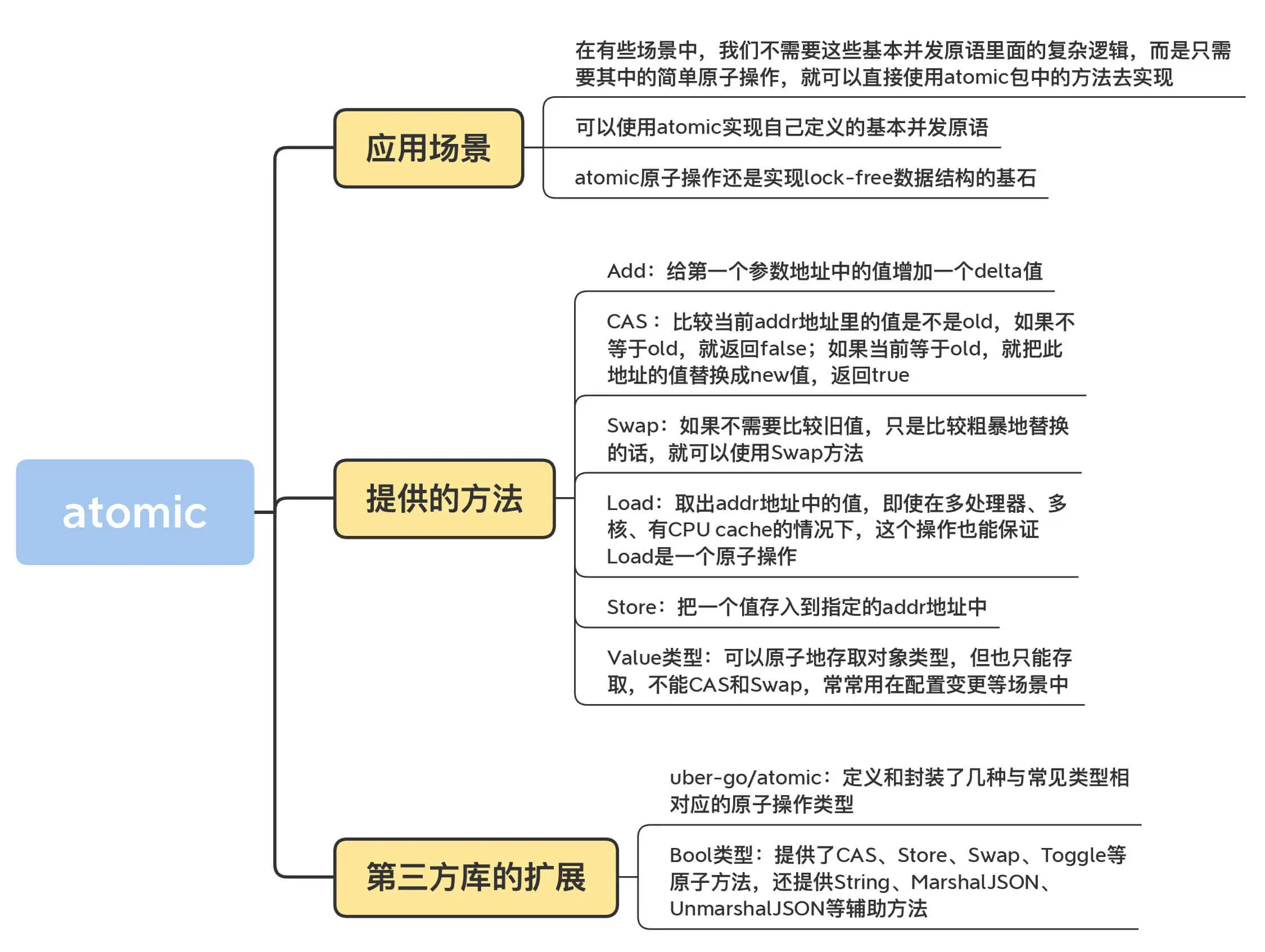
Channel
CSP 允许使用进程组件来描述系统,它们独立运行,并且只通过消息传递的方式通信。
Channel 类型是 Go 语言内置的类型,你无需引入某个包,就能使用它。
执行业务处理的 goroutine 不要通过共享内存的方式通信,而是要通过 Channel 通信的方式分享数据。
Channel 的应用场景分为五种类型
数据交流 :当作并发的 buffer 或者 queue,解决生产者 - 消费者问题。多个 goroutine 可以并发当作生产者(Producer)和消费者(Consumer)。
数据传递 :一个 goroutine 将数据交给另一个 goroutine,相当于把数据的拥有权 (引用) 托付出去。
信号通知 :一个 goroutine 可以将信号 (closing、closed、data ready 等) 传递给另一个或者另一组 goroutine 。
任务编排 :可以让一组 goroutine 按照一定的顺序并发或者串行的执行,这就是编排的功能。
锁 :利用 Channel 也可以实现互斥锁的机制。
Channel 基本用法
你可以往 Channel 中发送数据,也可以从 Channel 中接收数据,所以,Channel 类型(为了说起来方便,我们下面都把 Channel 叫做 chan)分为只能接收、只能发送、既可以接收又可以发送三种类型。下面是它的语法定义:
ChannelType = ( "chan" | "chan" "<-" | "<-" "chan" ) ElementType .
chan string // 可以发送接收string
chan<- struct{} // 只能发送struct{}
<-chan int // 只能从chan接收int
我们把既能接收又能发送的 chan 叫做双向的 chan,把只能发送和只能接收的 chan 叫做单向的 chan。其中,“<-”表示单向的 chan,如果你记不住,我告诉你一个简便的方法:这个箭头总是射向左边的,元素类型总在最右边。如果箭头指向 chan,就表示可以往 chan 中塞数据;如果箭头远离 chan,就表示 chan 会往外吐数据。
Go 内建的函数 close、cap、len 都可以操作 chan 类型:close 会把 chan 关闭掉,cap 返回 chan 的容量,len 返回 chan 中缓存的还未被取走的元素数量。
chan 数据结构
它的数据类型是 runtime.hchan。
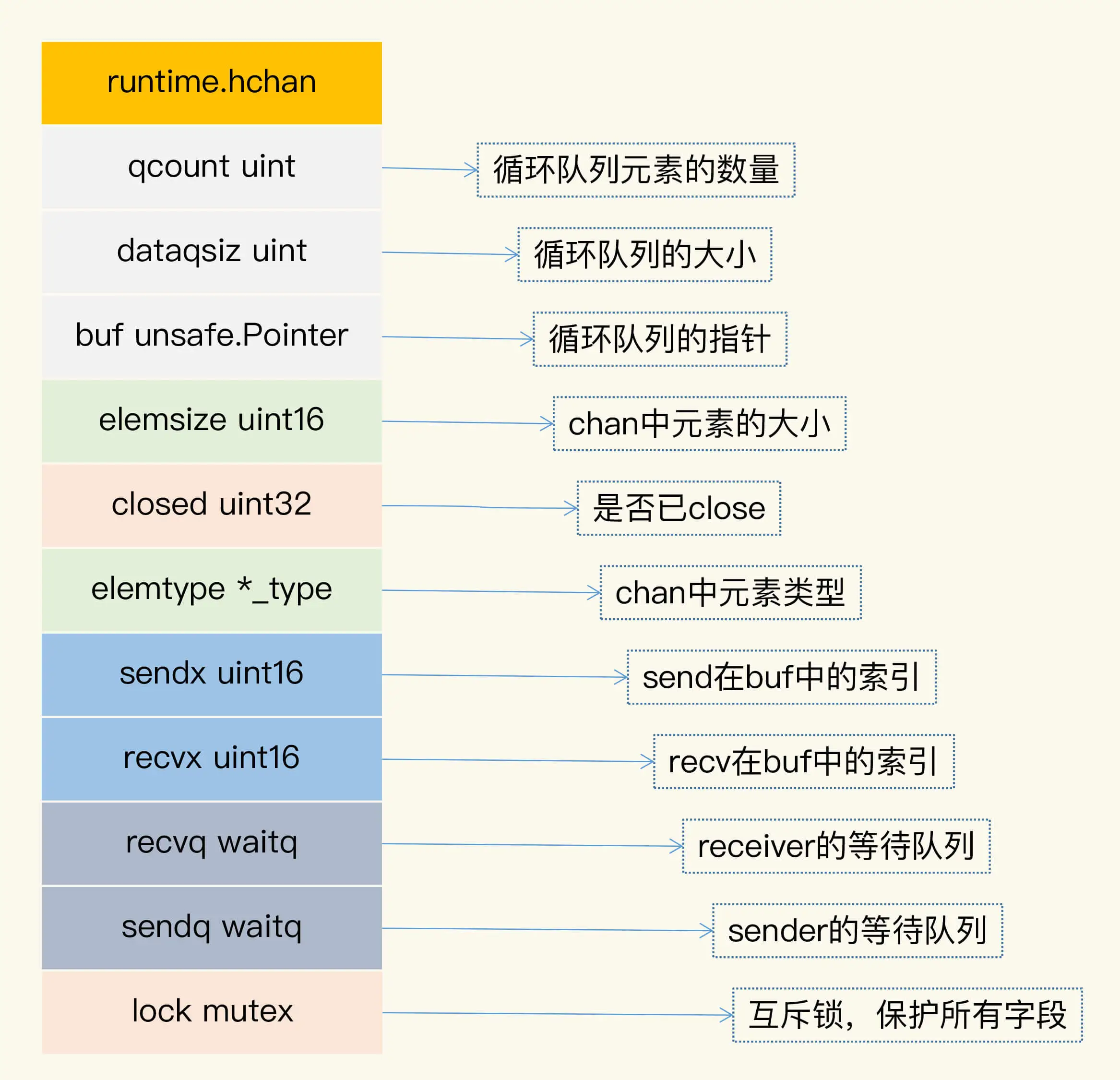
使用 Channel 容易犯的错误
使用 Channel 最常见的错误是 panic 和 goroutine 泄漏。
总结下会 panic 的情况,总共有 3 种:
- close 为 nil 的 chan;
- send 已经 close 的 chan;
- close 已经 close 的 chan。
func process(timeout time.Duration) bool {
ch := make(chan bool)
go func() {
// 模拟处理耗时的业务
time.Sleep((timeout + time.Second))
ch <- true // block
fmt.Println("exit goroutine")
}()
select {
case result := <-ch:
return result
case <-time.After(timeout):
return false
}
}
在这个例子中,process 函数会启动一个 goroutine,去处理需要长时间处理的业务,处理完之后,会发送 true 到 chan 中,目的是通知其它等待的 goroutine,可以继续处理了。
主 goroutine 接收到任务处理完成的通知,或者超时后就返回了。这段代码有问题吗?
如果发生超时,process 函数就返回了,这就会导致 unbuffered 的 chan 从来就没有被读取。我们知道,unbuffered chan 必须等 reader 和 writer 都准备好了才能交流,否则就会阻塞。超时导致未读,结果就是子 goroutine 就阻塞在第 7 行永远结束不了,进而导致 goroutine 泄漏。
解决这个 Bug 的办法很简单,就是将 unbuffered chan 改成容量为 1 的 chan,这样第 7 行就不会被阻塞了。
Go 的开发者极力推荐使用 Channel,不过,这两年,大家意识到,Channel 并不是处理并发问题的“银弹”,有时候使用并发原语更简单,而且不容易出错。所以,我给你提供一套选择的方法:
- 共享资源的并发访问使用传统并发原语;
- 复杂的任务编排和消息传递使用 Channel;
- 消息通知机制使用 Channel,除非只想 signal 一个 goroutine,才使用 Cond;
- 简单等待所有任务的完成用 WaitGroup,也有 Channel 的推崇者用 Channel,都可以;
- 需要和 Select 语句结合,使用 Channel;
- 需要和超时配合时,使用 Channel 和 Context。
一个 chan 还有未读的数据,即使把它 close 掉,你还是可以继续把这些未读的数据消费完,之后才是读取零值数据。
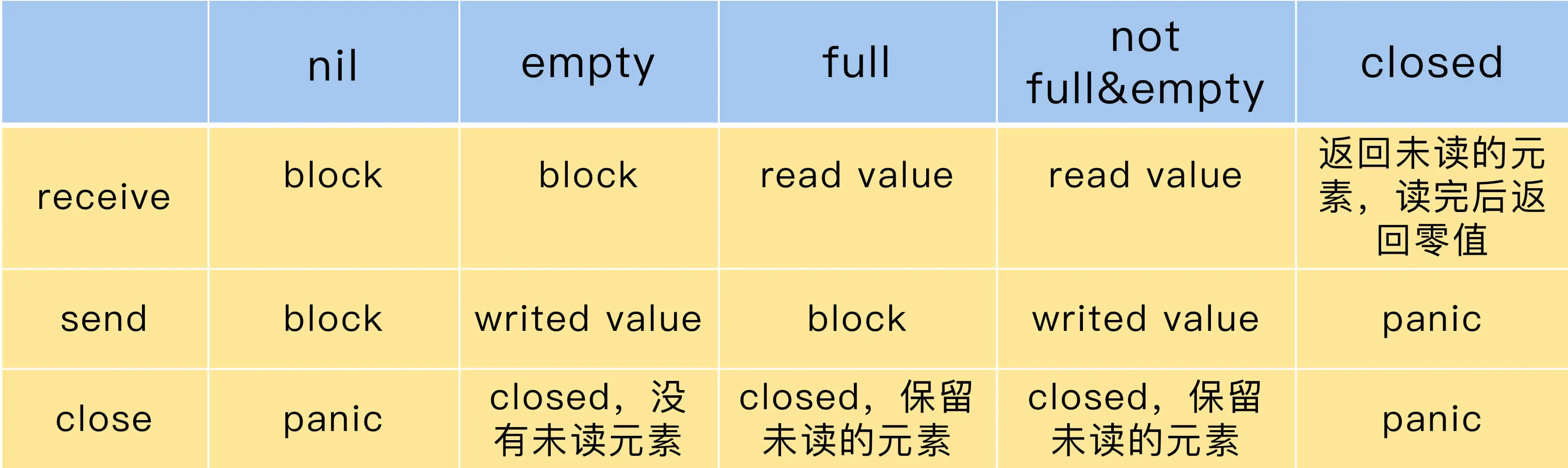
使用反射操作 Channel
通过 reflect.Select 函数,你可以将一组运行时的 case clause 传入,当作参数执行。Go 的 select 是伪随机的,它可以在执行的 case 中随机选择一个 case,并把选择的这个 case 的索引(chosen)返回,如果没有可用的 case 返回,会返回一个 bool 类型的返回值,这个返回值用来表示是否有 case 成功被选择。如果是 recv case,还会返回接收的元素。Select 的方法签名如下:
func Select(cases []SelectCase) (chosen int, recv Value, recvOK bool)
func main() {
var ch1 = make(chan int, 10)
var ch2 = make(chan int, 10)
// 创建SelectCase
var cases = createCases(ch1, ch2)
// 执行10次select
for i := 0; i < 10; i++ {
chosen, recv, ok := reflect.Select(cases)
if recv.IsValid() { // recv case
fmt.Println("recv:", cases[chosen].Dir, recv, ok)
} else { // send case
fmt.Println("send:", cases[chosen].Dir, ok)
}
}
}
func createCases(chs ...chan int) []reflect.SelectCase {
var cases []reflect.SelectCase
// 创建recv case
for _, ch := range chs {
cases = append(cases, reflect.SelectCase{
Dir: reflect.SelectRecv,
Chan: reflect.ValueOf(ch),
})
}
// 创建send case
for i, ch := range chs {
v := reflect.ValueOf(i)
cases = append(cases, reflect.SelectCase{
Dir: reflect.SelectSend,
Chan: reflect.ValueOf(ch),
Send: v,
})
}
return cases
}
消息交流
从 chan 的内部实现看,它是以一个循环队列的方式存放数据,所以,它有时候也会被当成线程安全的队列和 buffer 使用。一个 goroutine 可以安全地往 Channel 中塞数据,另外一个 goroutine 可以安全地从 Channel 中读取数据,goroutine 就可以安全地实现信息交流了。
数据传递
为了实现顺序的数据传递,我们可以定义一个令牌的变量,谁得到令牌,谁就可以打印一次自己的编号,同时将令牌传递给下一个 goroutine,我们尝试使用 chan 来实现,可以看下下面的代码。
type Token struct{}
func newWorker(id int, ch chan Token, nextCh chan Token) {
for {
token := <-ch // 取得令牌
fmt.Println((id + 1)) // id从1开始
time.Sleep(time.Second)
nextCh <- token
}
}
func main() {
chs := []chan Token{make(chan Token), make(chan Token), make(chan Token), make(chan Token)}
// 创建4个worker
for i := 0; i < 4; i++ {
go newWorker(i, chs[i], chs[(i+1)%4])
}
//首先把令牌交给第一个worker
chs[0] <- struct{}{}
select {}
}
首先,我们定义一个令牌类型(Token),接着定义一个创建 worker 的方法,这个方法会从它自己的 chan 中读取令牌。哪个 goroutine 取得了令牌,就可以打印出自己编号,因为需要每秒打印一次数据,所以,我们让它休眠 1 秒后,再把令牌交给它的下家。
这类场景有一个特点,就是当前持有数据的 goroutine 都有一个信箱,信箱使用 chan 实现,goroutine 只需要关注自己的信箱中的数据,处理完毕后,就把结果发送到下一家的信箱中。
信号通知
chan 类型有这样一个特点:chan 如果为空,那么,receiver 接收数据的时候就会阻塞等待,直到 chan 被关闭或者有新的数据到来。利用这个机制,我们可以实现 wait/notify 的设计模式。
比如,使用 chan 实现程序的 graceful shutdown,在退出之前执行一些连接关闭、文件 close、缓存落盘等一些动作。
- closing,代表程序退出,但是清理工作还没做;
- closed,代表清理工作已经做完。
func main() {
var closing = make(chan struct{})
var closed = make(chan struct{})
go func() {
// 模拟业务处理
for {
select {
case <-closing:
return
default:
// ....... 业务计算
time.Sleep(100 * time.Millisecond)
}
}
}()
// 处理CTRL+C等中断信号
termChan := make(chan os.Signal)
signal.Notify(termChan, syscall.SIGINT, syscall.SIGTERM)
<-termChan
close(closing)
// 执行退出之前的清理动作
go doCleanup(closed)
select {
case <-closed:
case <-time.After(time.Second):
fmt.Println("清理超时,不等了")
}
fmt.Println("优雅退出")
}
func doCleanup(closed chan struct{}) {
time.Sleep((time.Minute))
close(closed)
}
锁
使用 chan 也可以实现互斥锁。
chan 的内部实现中,就有一把互斥锁保护着它的所有字段。从外在表现上,chan 的发送和接收之间也存在着 happens-before 的关系,保证元素放进去之后,receiver 才能读取到(关于 happends-before 的关系,是指事件发生的先后顺序关系,我会在下一讲详细介绍,这里你只需要知道它是一种描述事件先后顺序的方法)。
要想使用 chan 实现互斥锁,至少有两种方式。一种方式是先初始化一个 capacity 等于 1 的 Channel,然后再放入一个元素。这个元素就代表锁,谁取得了这个元素,就相当于获取了这把锁。另一种方式是,先初始化一个 capacity 等于 1 的 Channel,它的“空槽”代表锁,谁能成功地把元素发送到这个 Channel,谁就获取了这把锁。
// 使用chan实现互斥锁
type Mutex struct {
ch chan struct{}
}
// 使用锁需要初始化
func NewMutex() *Mutex {
mu := &Mutex{make(chan struct{}, 1)}
mu.ch <- struct{}{}
return mu
}
// 请求锁,直到获取到
func (m *Mutex) Lock() {
<-m.ch
}
// 解锁
func (m *Mutex) Unlock() {
select {
case m.ch <- struct{}{}:
default:
panic("unlock of unlocked mutex")
}
}
// 尝试获取锁
func (m *Mutex) TryLock() bool {
select {
case <-m.ch:
return true
default:
}
return false
}
// 加入一个超时的设置
func (m *Mutex) LockTimeout(timeout time.Duration) bool {
timer := time.NewTimer(timeout)
select {
case <-m.ch:
timer.Stop()
return true
case <-timer.C:
}
return false
}
// 锁是否已被持有
func (m *Mutex) IsLocked() bool {
return len(m.ch) == 0
}
func main() {
m := NewMutex()
ok := m.TryLock()
fmt.Printf("locked v %v\n", ok)
ok = m.TryLock()
fmt.Printf("locked %v\n", ok)
}
在这段代码中,还有一点需要我们注意下:利用 select+chan 的方式,很容易实现 TryLock、Timeout 的功能。具体来说就是,在 select 语句中,我们可以使用 default 实现 TryLock,使用一个 Timer 来实现 Timeout 的功能。
任务编排
这里的编排既指安排 goroutine 按照指定的顺序执行,也指多个 chan 按照指定的方式组合处理的方式。goroutine 的编排类似“击鼓传花”的例子,我们通过编排数据在 chan 之间的流转,就可以控制 goroutine 的执行。接下来,我来重点介绍下多个 chan 的编排方式,总共 5 种,分别是 Or-Done 模式、扇入模式、扇出模式、Stream 和 map-reduce。
Or-Done 模式
你发送同一个请求到多个微服务节点,只要任意一个微服务节点返回结果,就算成功
扇入模式
扇入借鉴了数字电路的概念,它定义了单个逻辑门能够接受的数字信号输入最大量的术语。一个逻辑门可以有多个输入,一个输出。
反射的代码比较简短,易于理解,主要就是构造出 SelectCase slice,然后传递给 reflect.Select 语句。
func fanInReflect(chans ...<-chan interface{}) <-chan interface{} {
out := make(chan interface{})
go func() {
defer close(out)
// 构造SelectCase slice
var cases []reflect.SelectCase
for _, c := range chans {
cases = append(cases, reflect.SelectCase{
Dir: reflect.SelectRecv,
Chan: reflect.ValueOf(c),
})
}
// 循环,从cases中选择一个可用的
for len(cases) > 0 {
i, v, ok := reflect.Select(cases)
if !ok { // 此channel已经close
cases = append(cases[:i], cases[i+1:]...)
continue
}
out <- v.Interface()
}
}()
return out
}
扇出模式
有扇入模式,就有扇出模式,扇出模式是和扇入模式相反的。
func fanOut(ch <-chan interface{}, out []chan interface{}, async bool) {
go func() {
defer func() { //退出时关闭所有的输出chan
for i := 0; i < len(out); i++ {
close(out[i])
}
}()
for v := range ch { // 从输入chan中读取数据
v := v
for i := 0; i < len(out); i++ {
i := i
if async { //异步
go func() {
out[i] <- v // 放入到输出chan中,异步方式
}()
} else {
out[i] <- v // 放入到输出chan中,同步方式
}
}
}
}()
}
Stream
这里我来介绍一种把 Channel 当作流式管道使用的方式,也就是把 Channel 看作流(Stream),提供跳过几个元素,或者是只取其中的几个元素等方法。
map-reduce
map-reduce 分为两个步骤,第一步是映射(map),处理队列中的数据,第二步是规约(reduce),把列表中的每一个元素按照一定的处理方式处理成结果,放入到结果队列中。
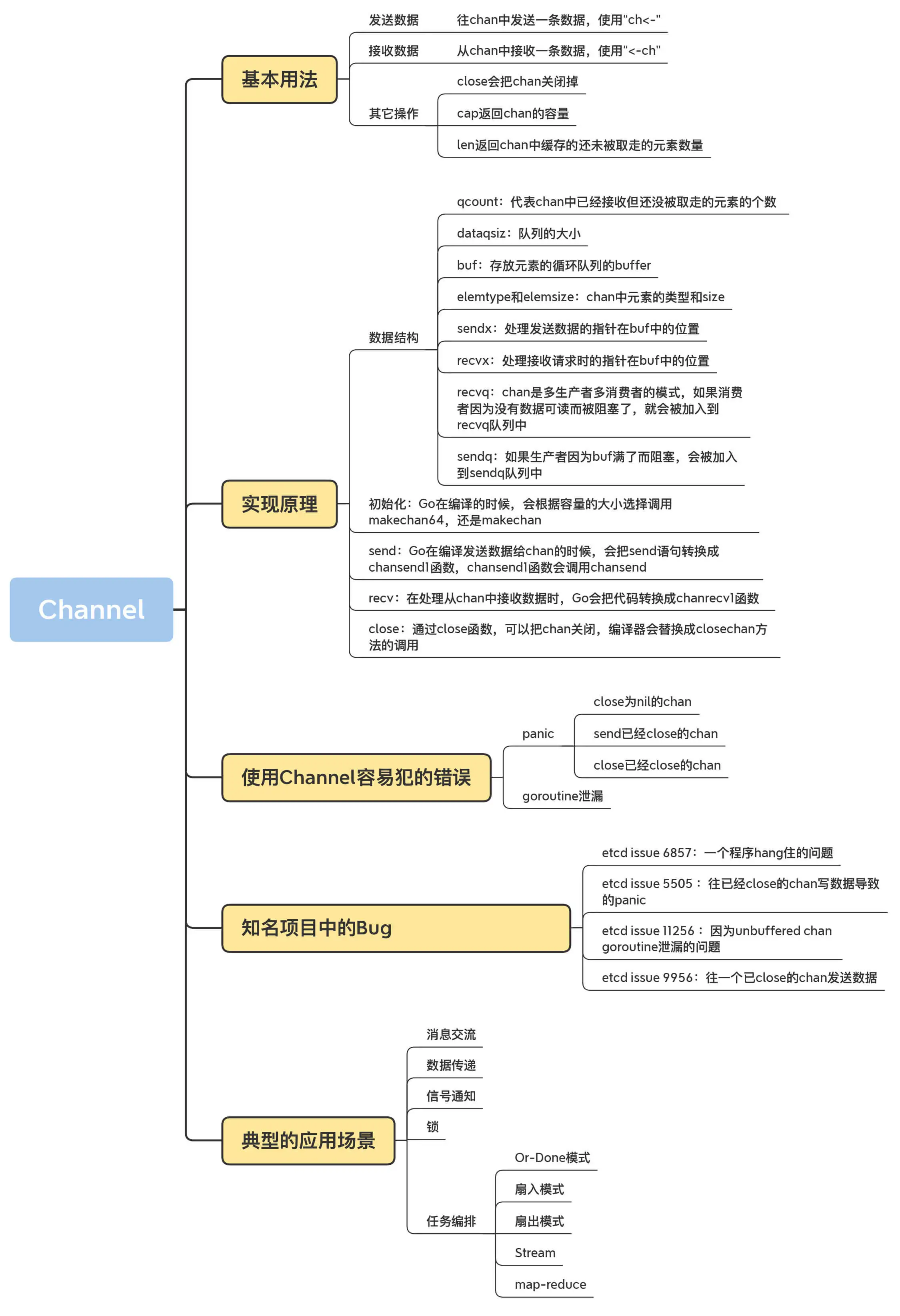
内存模型:Go如何保证并发读写的顺序
happens-before
在一个 goroutine 内部,程序的执行顺序和它们的代码指定的顺序是一样的,即使编译器或者 CPU 重排了读写顺序,从行为上来看,也和代码指定的顺序一样。
对于另一个 goroutine 来说,重排却会产生非常大的影响。因为 Go 只保证 goroutine 内部重排对读写的顺序没有影响
main 函数一定在导入的包的 init 函数之后执行。
启动 goroutine 的 go 语句的执行,一定 happens before 此 goroutine 内的代码执行。
Channel
Channel 是 goroutine 同步交流的主要方法。往一个 Channel 中发送一条数据,通常对应着另一个 goroutine 从这个 Channel 中接收一条数据。
Mutex/RWMutex
WaitGroup
Wait 方法等到计数值归零之后才返回。
Once
对于 once.Do(f) 调用,f 函数的那个单次调用一定 happens before 任何 once.Do(f) 调用的返回。换句话说,就是函数 f 一定会在 Do 方法返回之前执行。
atomic
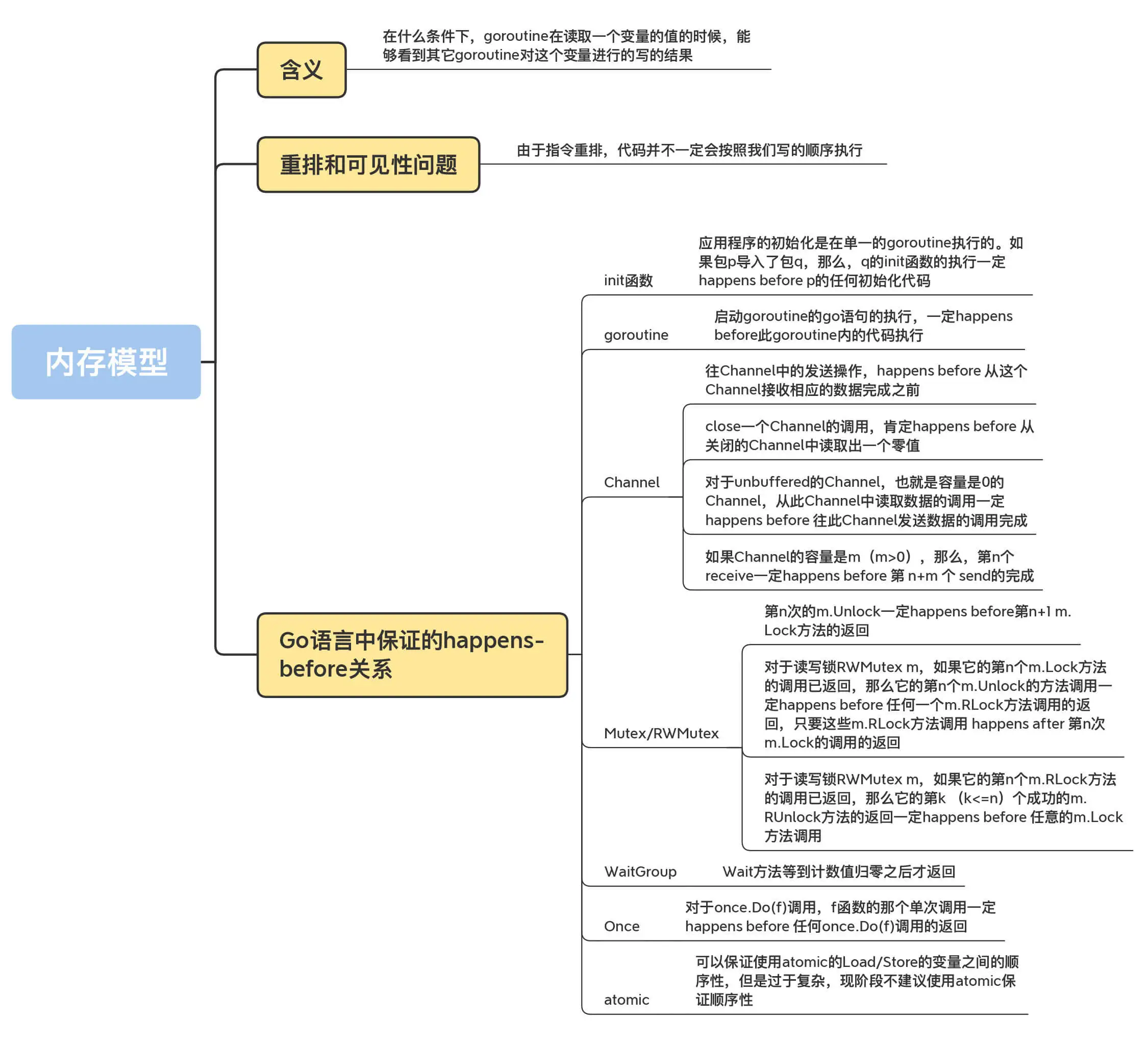
Semaphore
Go 在它的扩展包中提供了信号量semaphore,不过这个信号量的类型名并不叫 Semaphore,而是叫 Weighted。

Acquire 方法 :相当于 P 操作,你可以一次获取多个资源,如果没有足够多的资源,调用者就会被阻塞。它的第一个参数是 Context,这就意味着,你可以通过 Context 增加超时或者 cancel 的机制。如果是正常获取了资源,就返回 nil;否则,就返回 ctx.Err(),信号量不改变。
Release 方法:相当于 V 操作,可以将 n 个资源释放,返还给信号量。
TryAcquire 方法:尝试获取 n 个资源,但是它不会阻塞,要么成功获取 n 个资源,返回 true,要么一个也不获取,返回 false。
var (
maxWorkers = runtime.GOMAXPROCS(0) // worker数量
sema = semaphore.NewWeighted(int64(maxWorkers)) //信号量
task = make([]int, maxWorkers*4) // 任务数,是worker的四倍
)
func main() {
ctx := context.Background()
for i := range task {
// 如果没有worker可用,会阻塞在这里,直到某个worker被释放
if err := sema.Acquire(ctx, 1); err != nil {
break
}
// 启动worker goroutine
go func(i int) {
defer sema.Release(1)
time.Sleep(100 * time.Millisecond) // 模拟一个耗时操作
task[i] = i + 1
}(i)
}
// 请求所有的worker,这样能确保前面的worker都执行完
if err := sema.Acquire(ctx, int64(maxWorkers)); err != nil {
log.Printf("获取所有的worker失败: %v", err)
}
fmt.Println(task)
}
Go 扩展库中的信号量是使用互斥锁 +List 实现的。互斥锁实现其它字段的保护,而 List 实现了一个等待队列,等待者的通知是通过 Channel 的通知机制实现的。
type Weighted struct {
size int64 // 最大资源数
cur int64 // 当前已被使用的资源
mu sync.Mutex // 互斥锁,对字段的保护
waiters list.List // 等待队列
}
使用信号量的常见错误
- 请求了资源,但是忘记释放它;
- 释放了从未请求的资源;
- 长时间持有一个资源,即使不需要它;
- 不持有一个资源,却直接使用它。
使用信号量遵循的原则就是请求多少资源,就释放多少资源
除了官方扩展库的实现,实际上,我们还有很多方法实现信号量,比较典型的就是使用 Channel 来实现。
// Semaphore 数据结构,并且还实现了Locker接口
type semaphore struct {
sync.Locker
ch chan struct{}
}
// 创建一个新的信号量
func NewSemaphore(capacity int) sync.Locker {
if capacity <= 0 {
capacity = 1 // 容量为1就变成了一个互斥锁
}
return &semaphore{ch: make(chan struct{}, capacity)}
}
// 请求一个资源
func (s *semaphore) Lock() {
s.ch <- struct{}{}
}
// 释放资源
func (s *semaphore) Unlock() {
<-s.ch
}
当然,你还可以自己扩展一些方法,比如在请求资源的时候使用 Context 参数(Acquire(ctx))、实现 TryLock 等功能。
除了 Channel,marusama/semaphore也实现了一个可以动态更改资源容量的信号量,也是一个非常有特色的实现。
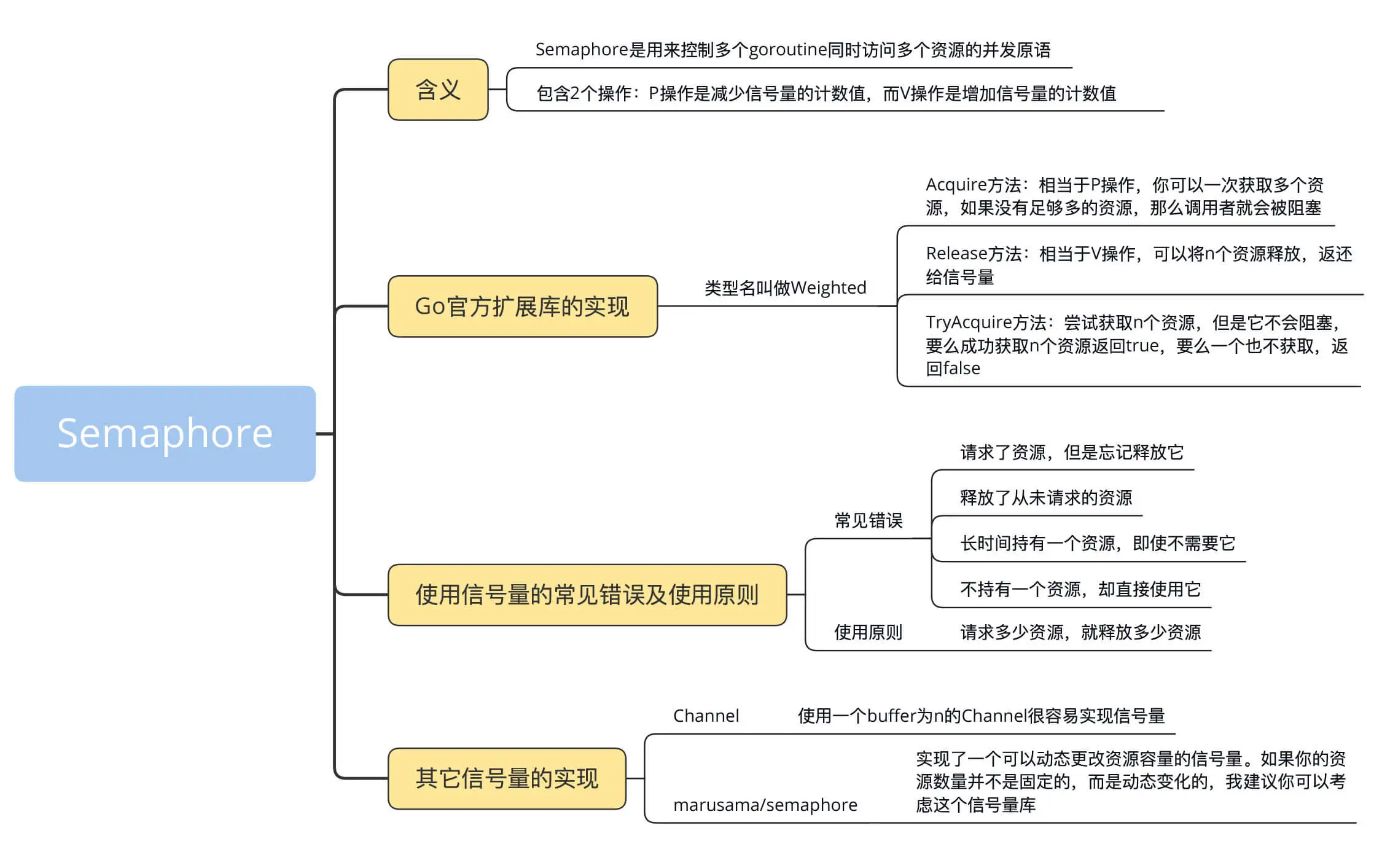
SingleFlight和CyclicBarrier:请求合并和循环栅栏
SingleFlight 是 Go 开发组提供的一个扩展并发原语。它的作用是,在处理多个 goroutine 同时调用同一个函数的时候,只让一个 goroutine 去调用这个函数,等到这个 goroutine 返回结果的时候,再把结果返回给这几个同时调用的 goroutine,这样可以减少并发调用的数量。
sync.Once 主要是用在单次初始化场景中,而 SingleFlight 主要用在合并并发请求的场景中,尤其是缓存场景。
SingleFlight 使用互斥锁 Mutex 和 Map 来实现。Mutex 提供并发时的读写保护,Map 用来保存同一个 key 的正在处理(in flight)的请求。

Do:这个方法执行一个函数,并返回函数执行的结果。你需要提供一个 key,对于同一个 key,在同一时间只有一个在执行,同一个 key 并发的请求会等待。第一个执行的请求返回的结果,就是它的返回结果。函数 fn 是一个无参的函数,返回一个结果或者 error,而 Do 方法会返回函数执行的结果或者是 error,shared 会指示 v 是否返回给多个请求。
DoChan:类似 Do 方法,只不过是返回一个 chan,等 fn 函数执行完,产生了结果以后,就能从这个 chan 中接收这个结果。
Forget:告诉 Group 忘记这个 key。这样一来,之后这个 key 请求会执行 f,而不是等待前一个未完成的 fn 函数的结果。
首先,SingleFlight 定义一个辅助对象 call,这个 call 就代表正在执行 fn 函数的请求或者是已经执行完的请求。Group 代表 SingleFlight。
CyclicBarrier允许一组 goroutine 彼此等待,到达一个共同的执行点。同时,因为它可以被重复使用,所以叫循环栅栏。具体的机制是,大家都在栅栏前等待,等全部都到齐了,就抬起栅栏放行。
处理可重用的多 goroutine 等待同一个执行点的场景的时候,CyclicBarrier 和 WaitGroup 方法调用的对应关系如下:
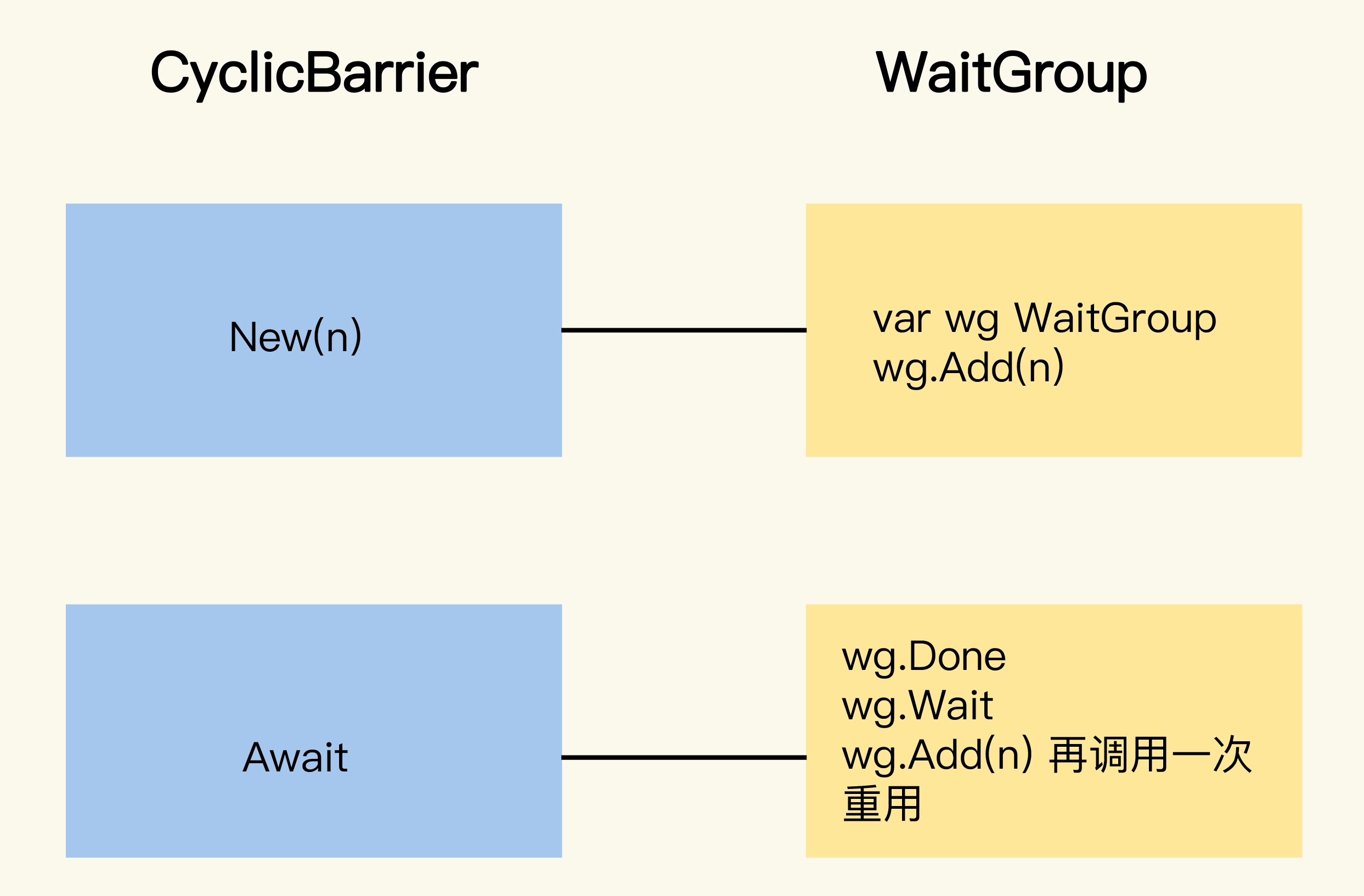
并发趣题:一氧化二氢制造工厂
题目是这样的:
有一个名叫大自然的搬运工的工厂,生产一种叫做一氧化二氢的神秘液体。这种液体的分子是由一个氧原子和两个氢原子组成的,也就是水。
这个工厂有多条生产线,每条生产线负责生产氧原子或者是氢原子,每条生产线由一个 goroutine 负责。
这些生产线会通过一个栅栏,只有一个氧原子生产线和两个氢原子生产线都准备好,才能生成出一个水分子,否则所有的生产线都会处于等待状态。也就是说,一个水分子必须由三个不同的生产线提供原子,而且水分子是一个一个按照顺序产生的,每生产一个水分子,就会打印出 HHO、HOH、OHH 三种形式的其中一种。HHH、OOH、OHO、HOO、OOO 都是不允许的。
生产线中氢原子的生产线为 2N 条,氧原子的生产线为 N 条。
首先,我们来定义一个 H2O 辅助数据类型,它包含两个信号量的字段和一个循环栅栏。
- semaH 信号量:控制氢原子。一个水分子需要两个氢原子,所以,氢原子的空槽数资源数设置为 2。
- semaO 信号量:控制氧原子。一个水分子需要一个氧原子,所以资源数的空槽数设置为 1。
- 循环栅栏:等待两个氢原子和一个氧原子填补空槽,直到任务完成。
package water
import (
"context"
"github.com/marusama/cyclicbarrier"
"golang.org/x/sync/semaphore"
)
// 定义水分子合成的辅助数据结构
type H2O struct {
semaH *semaphore.Weighted // 氢原子的信号量
semaO *semaphore.Weighted // 氧原子的信号量
b cyclicbarrier.CyclicBarrier // 循环栅栏,用来控制合成
}
func New() *H2O {
return &H2O{
semaH: semaphore.NewWeighted(2), //氢原子需要两个
semaO: semaphore.NewWeighted(1), // 氧原子需要一个
b: cyclicbarrier.New(3), // 需要三个原子才能合成
}
}
func (h2o *H2O) hydrogen(releaseHydrogen func()) {
h2o.semaH.Acquire(context.Background(), 1)
releaseHydrogen() // 输出H
h2o.b.Await(context.Background()) //等待栅栏放行
h2o.semaH.Release(1) // 释放氢原子空槽
}
func (h2o *H2O) oxygen(releaseOxygen func()) {
h2o.semaO.Acquire(context.Background(), 1)
releaseOxygen() // 输出O
h2o.b.Await(context.Background()) //等待栅栏放行
h2o.semaO.Release(1) // 释放氢原子空槽
}
在栅栏放行之前,只有两个氢原子的空槽位和一个氧原子的空槽位。只有等栅栏放行之后,这些空槽位才会被释放。栅栏放行,就意味着一个水分子组成成功。
package water
import (
"math/rand"
"sort"
"sync"
"testing"
"time"
)
func TestWaterFactory(t *testing.T) {
//用来存放水分子结果的channel
var ch chan string
releaseHydrogen := func() {
ch <- "H"
}
releaseOxygen := func() {
ch <- "O"
}
// 300个原子,300个goroutine,每个goroutine并发的产生一个原子
var N = 100
ch = make(chan string, N*3)
h2o := New()
// 用来等待所有的goroutine完成
var wg sync.WaitGroup
wg.Add(N * 3)
// 200个氢原子goroutine
for i := 0; i < 2*N; i++ {
go func() {
time.Sleep(time.Duration(rand.Intn(100)) * time.Millisecond)
h2o.hydrogen(releaseHydrogen)
wg.Done()
}()
}
// 100个氧原子goroutine
for i := 0; i < N; i++ {
go func() {
time.Sleep(time.Duration(rand.Intn(100)) * time.Millisecond)
h2o.oxygen(releaseOxygen)
wg.Done()
}()
}
//等待所有的goroutine执行完
wg.Wait()
// 结果中肯定是300个原子
if len(ch) != N*3 {
t.Fatalf("expect %d atom but got %d", N*3, len(ch))
}
// 每三个原子一组,分别进行检查。要求这一组原子中必须包含两个氢原子和一个氧原子,这样才能正确组成一个水分子。
var s = make([]string, 3)
for i := 0; i < N; i++ {
s[0] = <-ch
s[1] = <-ch
s[2] = <-ch
sort.Strings(s)
water := s[0] + s[1] + s[2]
if water != "HHO" {
t.Fatalf("expect a water molecule but got %s", water)
}
}
}
如果你没有学习 CyclicBarrier,你可能只会想到,用 WaitGroup 来实现这个水分子制造工厂的例子。
type H2O struct {
semaH *semaphore.Weighted
semaO *semaphore.Weighted
wg sync.WaitGroup //将循环栅栏替换成WaitGroup
}
func New() *H2O {
var wg sync.WaitGroup
wg.Add(3)
return &H2O{
semaH: semaphore.NewWeighted(2),
semaO: semaphore.NewWeighted(1),
wg: wg,
}
}
func (h2o *H2O) hydrogen(releaseHydrogen func()) {
h2o.semaH.Acquire(context.Background(), 1)
releaseHydrogen()
// 标记自己已达到,等待其它goroutine到达
h2o.wg.Done()
h2o.wg.Wait()
h2o.semaH.Release(1)
}
func (h2o *H2O) oxygen(releaseOxygen func()) {
h2o.semaO.Acquire(context.Background(), 1)
releaseOxygen()
// 标记自己已达到,等待其它goroutine到达
h2o.wg.Done()
h2o.wg.Wait()
//都到达后重置wg
h2o.wg.Add(3)
h2o.semaO.Release(1)
}
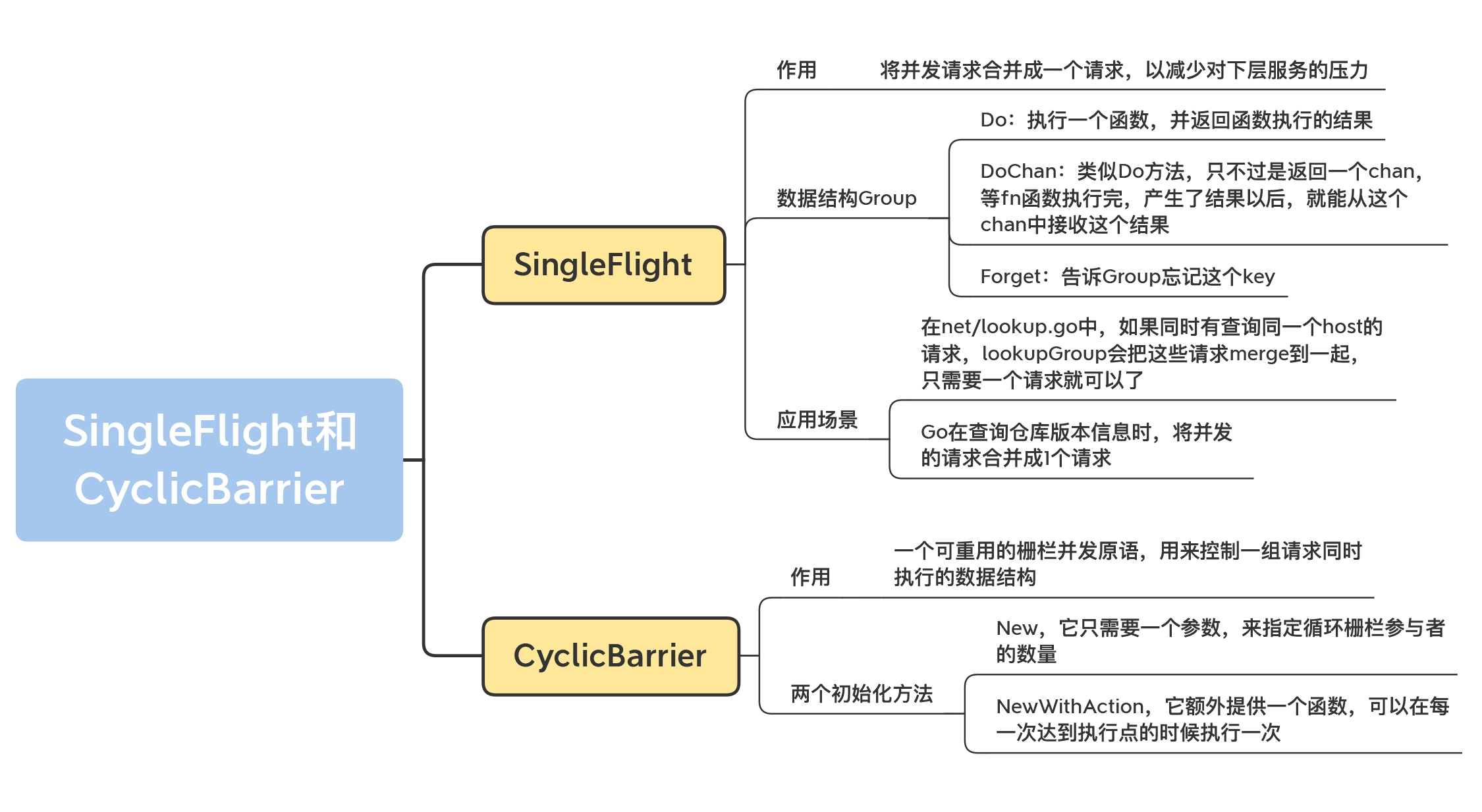
分组操作:处理一组子任务
共享资源保护、任务编排和消息传递是 Go 并发编程中常见的场景,而分组执行一批相同的或类似的任务则是任务编排中一类情形
ErrGroup
ErrGroup是 Go 官方提供的一个同步扩展库。我们经常会碰到需要将一个通用的父任务拆成几个小任务并发执行的场景,其实,将一个大的任务拆成几个小任务并发执行,可以有效地提高程序的并发度。就像你在厨房做饭一样,你可以在蒸米饭的同时炒几个小菜,米饭蒸好了,菜同时也做好了,很快就能吃到可口的饭菜。
简单例子:返回第一个错误
先来看一个简单的例子。在这个例子中,启动了三个子任务,其中,子任务 2 会返回执行失败,其它两个执行成功。在三个子任务都执行后,group.Wait 才会返回第 2 个子任务的错误。
package main
import (
"errors"
"fmt"
"time"
"golang.org/x/sync/errgroup"
)
func main() {
var g errgroup.Group
// 启动第一个子任务,它执行成功
g.Go(func() error {
time.Sleep(5 * time.Second)
fmt.Println("exec #1")
return nil
})
// 启动第二个子任务,它执行失败
g.Go(func() error {
time.Sleep(10 * time.Second)
fmt.Println("exec #2")
return errors.New("failed to exec #2")
})
// 启动第三个子任务,它执行成功
g.Go(func() error {
time.Sleep(15 * time.Second)
fmt.Println("exec #3")
return nil
})
// 等待三个任务都完成
if err := g.Wait(); err == nil {
fmt.Println("Successfully exec all")
} else {
fmt.Println("failed:", err)
}
}
下面的这个例子,就是使用 result 记录每个子任务成功或失败的结果。其实,你不仅可以使用 result 记录 error 信息,还可以用它记录计算结果。
package main
import (
"errors"
"fmt"
"time"
"golang.org/x/sync/errgroup"
)
func main() {
var g errgroup.Group
var result = make([]error, 3)
// 启动第一个子任务,它执行成功
g.Go(func() error {
time.Sleep(5 * time.Second)
fmt.Println("exec #1")
result[0] = nil // 保存成功或者失败的结果
return nil
})
// 启动第二个子任务,它执行失败
g.Go(func() error {
time.Sleep(10 * time.Second)
fmt.Println("exec #2")
result[1] = errors.New("failed to exec #2") // 保存成功或者失败的结果
return result[1]
})
// 启动第三个子任务,它执行成功
g.Go(func() error {
time.Sleep(15 * time.Second)
fmt.Println("exec #3")
result[2] = nil // 保存成功或者失败的结果
return nil
})
if err := g.Wait(); err == nil {
fmt.Printf("Successfully exec all. result: %v\n", result)
} else {
fmt.Printf("failed: %v\n", result)
}
}
任务执行流水线 Pipeline
Go 官方文档中还提供了一个 pipeline 的例子。这个例子是说,由一个子任务遍历文件夹下的文件,然后把遍历出的文件交给 20 个 goroutine,让这些 goroutine 并行计算文件的 md5。
扩展库
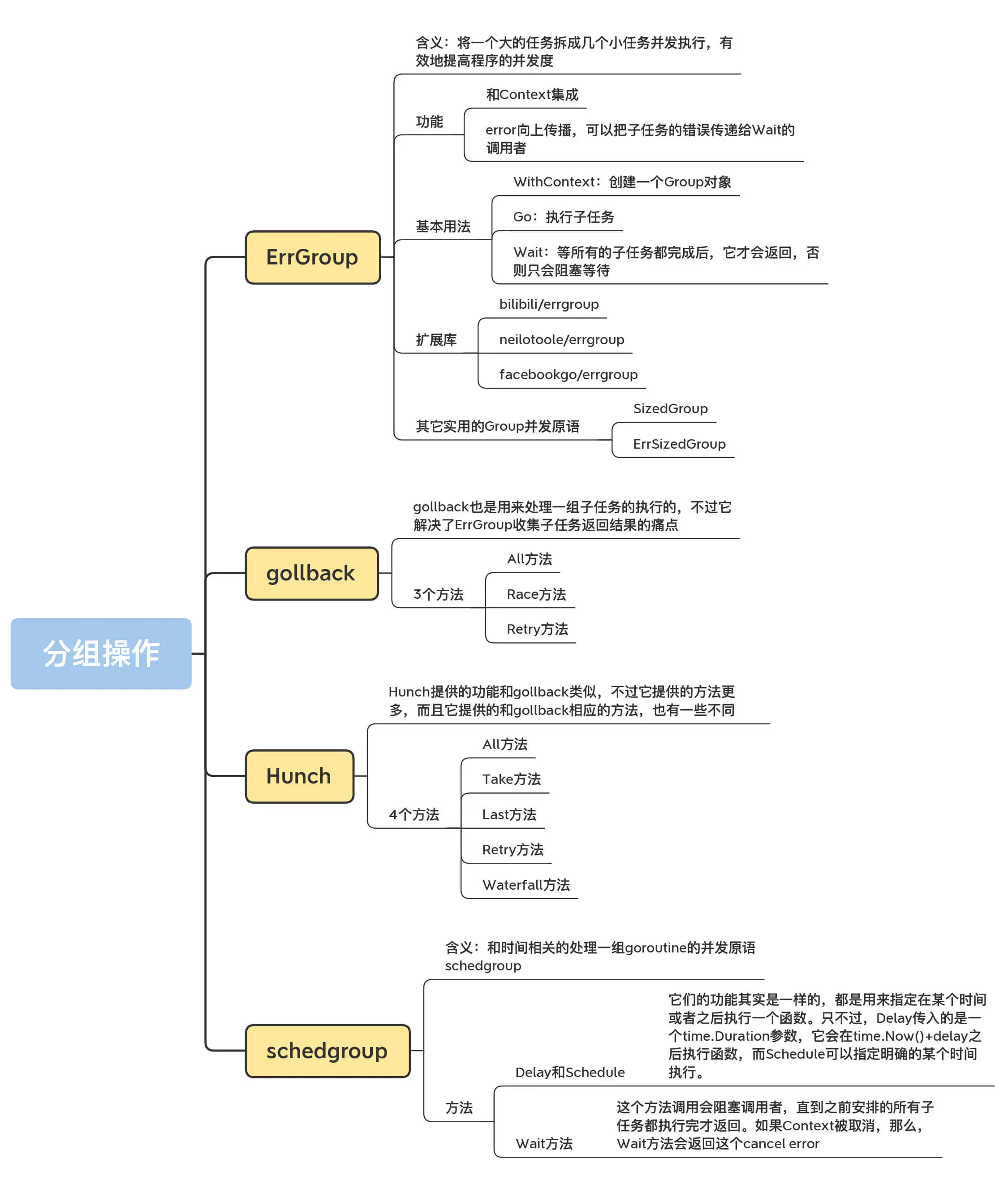
在分布式环境中,Leader选举、互斥锁和读写锁该如何实现?
常用来做协调工作的软件系统是 Zookeeper、etcd、Consul 之类的软件,Zookeeper 为 Java 生态群提供了丰富的分布式并发原语(通过 Curator 库),但是缺少 Go 相关的并发原语库。Consul 在提供分布式并发原语这件事儿上不是很积极,而 etcd 就提供了非常好的分布式并发原语,比如分布式互斥锁、分布式读写锁、Leader 选举,等等。所以,今天,我就以 etcd 为基础,给你介绍几种分布式并发原语。
Leader 选举
在同一时刻,系统中不能有两个主节点,否则,如果两个节点都是主,都执行写操作的话,就有可能出现数据不一致的情况,所以,我们需要一个选主机制,选择一个节点作为主节点,这个过程就是 Leader 选举。
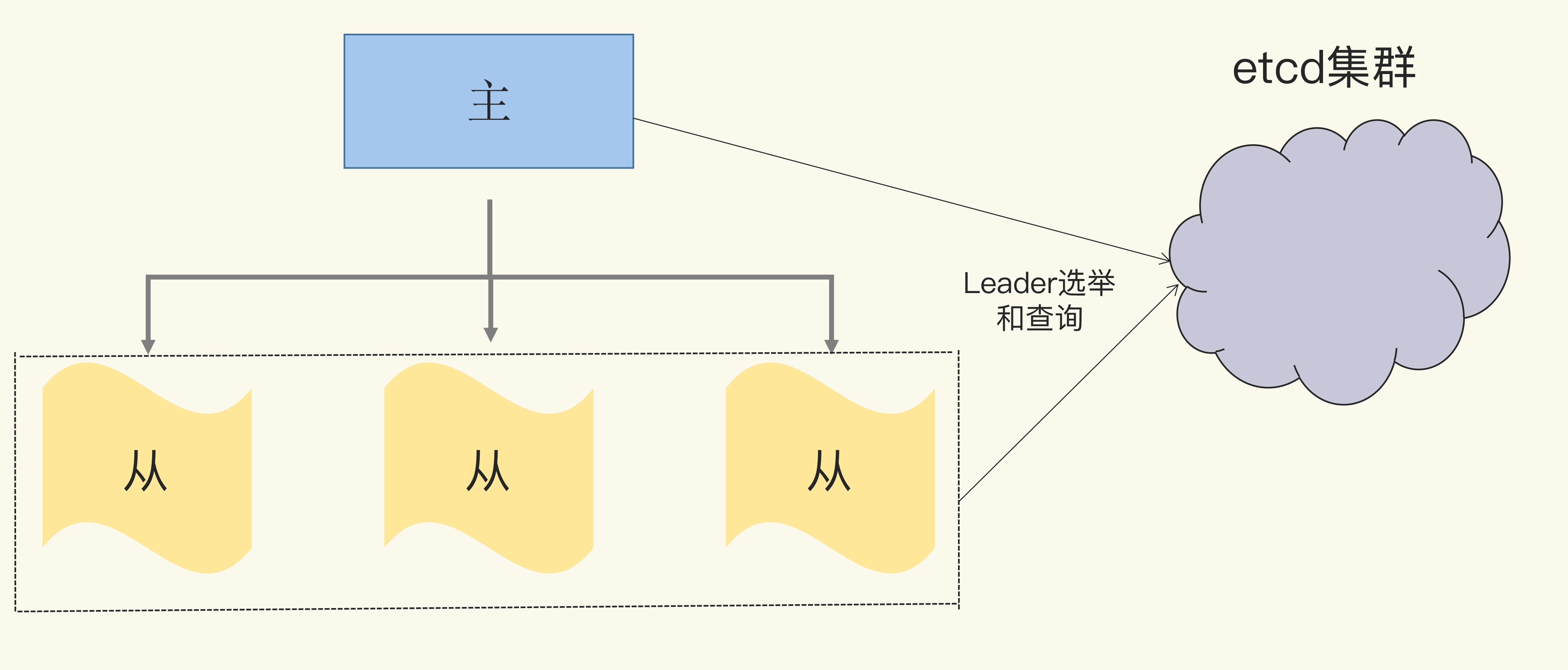
查询
除了选举 Leader,程序在启动的过程中,或者在运行的时候,还有可能需要查询当前的主节点是哪一个节点?主节点的值是什么?版本是多少?不光是主从节点需要查询和知道哪一个节点,在分布式系统中,还有其它一些节点也需要知道集群中的哪一个节点是主节点,哪一个节点是从节点,这样它们才能把读写请求分别发往相应的主从节点上。
监控
有了选举和查询方法,我们还需要一个监控方法。毕竟,如果主节点变化了,我们需要得到最新的主节点信息。
互斥锁
互斥锁是非常常用的一种并发原语,我专门花了 4 讲的时间,重点介绍了互斥锁的功能、原理和易错场景。
不过,前面说的互斥锁都是用来保护同一进程内的共享资源的,今天,我们要掌握的是分布式环境中的互斥锁。我们要重点学习下分布在不同机器中的不同进程内的 goroutine,如何利用分布式互斥锁来保护共享资源。
互斥锁的应用场景和主从架构的应用场景不太一样。使用互斥锁的不同节点是没有主从这样的角色的,所有的节点都是一样的,只不过在同一时刻,只允许其中的一个节点持有锁。
Locker
etcd 提供了一个简单的 Locker 原语,它类似于 Go 标准库中的 sync.Locker 接口,也提供了 Lock/UnLock 的机制:
func NewLocker(s *Session, pfx string) sync.Locker
package main
import (
"flag"
"log"
"math/rand"
"strings"
"time"
"github.com/coreos/etcd/clientv3"
"github.com/coreos/etcd/clientv3/concurrency"
)
var (
addr = flag.String("addr", "http://127.0.0.1:2379", "etcd addresses")
lockName = flag.String("name", "my-test-lock", "lock name")
)
func main() {
flag.Parse()
rand.Seed(time.Now().UnixNano())
// etcd地址
endpoints := strings.Split(*addr, ",")
// 生成一个etcd client
cli, err := clientv3.New(clientv3.Config{Endpoints: endpoints})
if err != nil {
log.Fatal(err)
}
defer cli.Close()
useLock(cli) // 测试锁
}
func useLock(cli *clientv3.Client) {
// 为锁生成session
s1, err := concurrency.NewSession(cli)
if err != nil {
log.Fatal(err)
}
defer s1.Close()
//得到一个分布式锁
locker := concurrency.NewLocker(s1, *lockName)
// 请求锁
log.Println("acquiring lock")
locker.Lock()
log.Println("acquired lock")
// 等待一段时间
time.Sleep(time.Duration(rand.Intn(30)) * time.Second)
locker.Unlock() // 释放锁
log.Println("released lock")
}
Mutex
事实上,刚刚说的 Locker 是基于 Mutex 实现的,只不过,Mutex 提供了查询 Mutex 的 key 的信息的功能
func useMutex(cli *clientv3.Client) {
// 为锁生成session
s1, err := concurrency.NewSession(cli)
if err != nil {
log.Fatal(err)
}
defer s1.Close()
m1 := concurrency.NewMutex(s1, *lockName)
//在请求锁之前查询key
log.Printf("before acquiring. key: %s", m1.Key())
// 请求锁
log.Println("acquiring lock")
if err := m1.Lock(context.TODO()); err != nil {
log.Fatal(err)
}
log.Printf("acquired lock. key: %s", m1.Key())
//等待一段时间
time.Sleep(time.Duration(rand.Intn(30)) * time.Second)
// 释放锁
if err := m1.Unlock(context.TODO()); err != nil {
log.Fatal(err)
}
log.Println("released lock")
}
可以看到,Mutex 并没有实现 sync.Locker 接口,它的 Lock/Unlock 方法需要提供一个 context.Context 实例做参数,这也就意味着,在请求锁的时候,你可以设置超时时间,或者主动取消请求。
读写锁
学完了分布式 Locker 和互斥锁 Mutex,你肯定会联想到读写锁 RWMutex。是的,etcd 也提供了分布式的读写锁。不过,互斥锁 Mutex 是在 github.com/coreos/etcd/clientv3/concurrency 包中提供的,读写锁 RWMutex 却是在 github.com/coreos/etcd/contrib/recipes 包中提供的。
etcd 提供的分布式读写锁的功能和标准库的读写锁的功能是一样的。只不过,etcd 提供的读写锁,可以在分布式环境中的不同的节点使用。
package main
import (
"bufio"
"flag"
"fmt"
"log"
"math/rand"
"os"
"strings"
"time"
"github.com/coreos/etcd/clientv3"
"github.com/coreos/etcd/clientv3/concurrency"
recipe "github.com/coreos/etcd/contrib/recipes"
)
var (
addr = flag.String("addr", "http://127.0.0.1:2379", "etcd addresses")
lockName = flag.String("name", "my-test-lock", "lock name")
action = flag.String("rw", "w", "r means acquiring read lock, w means acquiring write lock")
)
func main() {
flag.Parse()
rand.Seed(time.Now().UnixNano())
// 解析etcd地址
endpoints := strings.Split(*addr, ",")
// 创建etcd的client
cli, err := clientv3.New(clientv3.Config{Endpoints: endpoints})
if err != nil {
log.Fatal(err)
}
defer cli.Close()
// 创建session
s1, err := concurrency.NewSession(cli)
if err != nil {
log.Fatal(err)
}
defer s1.Close()
m1 := recipe.NewRWMutex(s1, *lockName)
// 从命令行读取命令
consolescanner := bufio.NewScanner(os.Stdin)
for consolescanner.Scan() {
action := consolescanner.Text()
switch action {
case "w": // 请求写锁
testWriteLocker(m1)
case "r": // 请求读锁
testReadLocker(m1)
default:
fmt.Println("unknown action")
}
}
}
func testWriteLocker(m1 *recipe.RWMutex) {
// 请求写锁
log.Println("acquiring write lock")
if err := m1.Lock(); err != nil {
log.Fatal(err)
}
log.Println("acquired write lock")
// 等待一段时间
time.Sleep(time.Duration(rand.Intn(10)) * time.Second)
// 释放写锁
if err := m1.Unlock(); err != nil {
log.Fatal(err)
}
log.Println("released write lock")
}
func testReadLocker(m1 *recipe.RWMutex) {
// 请求读锁
log.Println("acquiring read lock")
if err := m1.RLock(); err != nil {
log.Fatal(err)
}
log.Println("acquired read lock")
// 等待一段时间
time.Sleep(time.Duration(rand.Intn(10)) * time.Second)
// 释放写锁
if err := m1.RUnlock(); err != nil {
log.Fatal(err)
}
log.Println("released read lock")
}
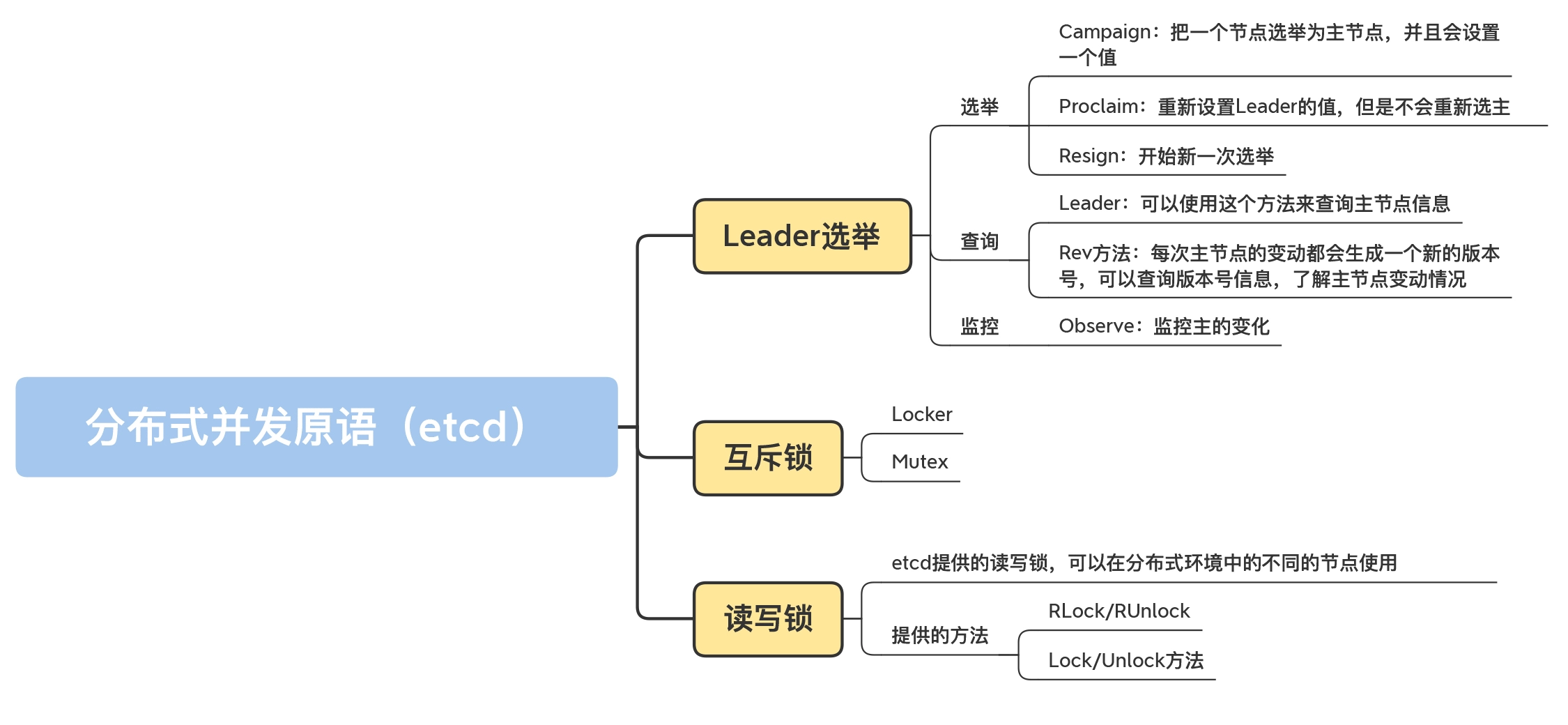
在分布式环境中,队列、栅栏和STM该如何实现?
要你学过计算机算法和数据结构相关的知识, 队列这种数据结构你一定不陌生,它是一种先进先出的类型,有出队(dequeue)和入队(enqueue)两种操作。
分布式队列和优先级队列
etcd 通过 github.com/coreos/etcd/contrib/recipes 包提供了分布式队列这种数据结构。
创建分布式队列的方法非常简单,只有一个,即 NewQueue,你只需要传入 etcd 的 client 和这个队列的名字,就可以了。
func NewQueue(client *v3.Client, keyPrefix string) *Queue
这个队列只有两个方法,分别是出队和入队,队列中的元素是字符串类型
// 入队
func (q *Queue) Enqueue(val string) error
//出队
func (q *Queue) Dequeue() (string, error)
在我接下来讲的例子中,你就可以启动两个节点,一个节点往队列中放入元素,一个节点从队列中取出元素,看看是否能正常取出来。etcd 的分布式队列是一种多读多写的队列,所以,你也可以启动多个写节点和多个读节点。
首先,我们启动一个程序,它会从命令行读取你的命令,然后执行。你可以输入push ,将一个元素入队,输入pop,将一个元素弹出。另外,你还可以使用这个程序启动多个实例,用来模拟分布式的环境:
package main
import (
"bufio"
"flag"
"fmt"
"log"
"os"
"strings"
"github.com/coreos/etcd/clientv3"
recipe "github.com/coreos/etcd/contrib/recipes"
)
var (
addr = flag.String("addr", "http://127.0.0.1:2379", "etcd addresses")
queueName = flag.String("name", "my-test-queue", "queue name")
)
func main() {
flag.Parse()
// 解析etcd地址
endpoints := strings.Split(*addr, ",")
// 创建etcd的client
cli, err := clientv3.New(clientv3.Config{Endpoints: endpoints})
if err != nil {
log.Fatal(err)
}
defer cli.Close()
// 创建/获取队列
q := recipe.NewQueue(cli, *queueName)
// 从命令行读取命令
consolescanner := bufio.NewScanner(os.Stdin)
for consolescanner.Scan() {
action := consolescanner.Text()
items := strings.Split(action, " ")
switch items[0] {
case "push": // 加入队列
if len(items) != 2 {
fmt.Println("must set value to push")
continue
}
q.Enqueue(items[1]) // 入队
case "pop": // 从队列弹出
v, err := q.Dequeue() // 出队
if err != nil {
log.Fatal(err)
}
fmt.Println(v) // 输出出队的元素
case "quit", "exit": //退出
return
default:
fmt.Println("unknown action")
}
}
}
除了刚刚说的分布式队列,etcd 还提供了优先级队列(PriorityQueue)。
它的用法和队列类似,也提供了出队和入队的操作,只不过,在入队的时候,除了需要把一个值加入到队列,我们还需要提供 uint16 类型的一个整数,作为此值的优先级,优先级高的元素会优先出队。
优先级队列的测试程序如下,你可以在一个节点输入一些不同优先级的元素,在另外一个节点读取出来,看看它们是不是按照优先级顺序弹出的:
package main
import (
"bufio"
"flag"
"fmt"
"log"
"os"
"strconv"
"strings"
"github.com/coreos/etcd/clientv3"
recipe "github.com/coreos/etcd/contrib/recipes"
)
var (
addr = flag.String("addr", "http://127.0.0.1:2379", "etcd addresses")
queueName = flag.String("name", "my-test-queue", "queue name")
)
func main() {
flag.Parse()
// 解析etcd地址
endpoints := strings.Split(*addr, ",")
// 创建etcd的client
cli, err := clientv3.New(clientv3.Config{Endpoints: endpoints})
if err != nil {
log.Fatal(err)
}
defer cli.Close()
// 创建/获取队列
q := recipe.NewPriorityQueue(cli, *queueName)
// 从命令行读取命令
consolescanner := bufio.NewScanner(os.Stdin)
for consolescanner.Scan() {
action := consolescanner.Text()
items := strings.Split(action, " ")
switch items[0] {
case "push": // 加入队列
if len(items) != 3 {
fmt.Println("must set value and priority to push")
continue
}
pr, err := strconv.Atoi(items[2]) // 读取优先级
if err != nil {
fmt.Println("must set uint16 as priority")
continue
}
q.Enqueue(items[1], uint16(pr)) // 入队
case "pop": // 从队列弹出
v, err := q.Dequeue() // 出队
if err != nil {
log.Fatal(err)
}
fmt.Println(v) // 输出出队的元素
case "quit", "exit": //退出
return
default:
fmt.Println("unknown action")
}
}
}
分布式栅栏
在第 17 讲中,我们学习了循环栅栏 CyclicBarrier,它和第 6 讲的标准库中的 WaitGroup,本质上是同一类并发原语,都是等待同一组 goroutine 同时执行,或者是等待同一组 goroutine 都完成。
etcd 也提供了相应的分布式并发原语。
- Barrier:分布式栅栏。如果持有 Barrier 的节点释放了它,所有等待这个 Barrier 的节点就不会被阻塞,而是会继续执行。
- DoubleBarrier:计数型栅栏。在初始化计数型栅栏的时候,我们就必须提供参与节点的数量,当这些数量的节点都 Enter 或者 Leave 的时候,这个栅栏就会放开。所以,我们把它称为计数型栅栏。
Barrier:分布式栅栏
分布式 Barrier 的创建很简单,你只需要提供 etcd 的 Client 和 Barrier 的名字就可以了
func NewBarrier(client *v3.Client, key string) *Barrier
func (b *Barrier) Hold() error
func (b *Barrier) Release() error
func (b *Barrier) Wait() error
- Hold 方法是创建一个 Barrier。如果 Barrier 已经创建好了,有节点调用它的 Wait 方法,就会被阻塞。
- Release 方法是释放这个 Barrier,也就是打开栅栏。如果使用了这个方法,所有被阻塞的节点都会被放行,继续执行。
- Wait 方法会阻塞当前的调用者,直到这个 Barrier 被 release。如果这个栅栏不存在,调用者不会被阻塞,而是会继续执行。
你可以在一个终端中运行这个程序,执行”hold””release”命令,模拟栅栏的持有和释放。在另外一个终端中运行这个程序,不断调用”wait”方法,看看是否能正常地跳出阻塞继续执行:
package main
import (
"bufio"
"flag"
"fmt"
"log"
"os"
"strings"
"github.com/coreos/etcd/clientv3"
recipe "github.com/coreos/etcd/contrib/recipes"
)
var (
addr = flag.String("addr", "http://127.0.0.1:2379", "etcd addresses")
barrierName = flag.String("name", "my-test-queue", "barrier name")
)
func main() {
flag.Parse()
// 解析etcd地址
endpoints := strings.Split(*addr, ",")
// 创建etcd的client
cli, err := clientv3.New(clientv3.Config{Endpoints: endpoints})
if err != nil {
log.Fatal(err)
}
defer cli.Close()
// 创建/获取栅栏
b := recipe.NewBarrier(cli, *barrierName)
// 从命令行读取命令
consolescanner := bufio.NewScanner(os.Stdin)
for consolescanner.Scan() {
action := consolescanner.Text()
items := strings.Split(action, " ")
switch items[0] {
case "hold": // 持有这个barrier
b.Hold()
fmt.Println("hold")
case "release": // 释放这个barrier
b.Release()
fmt.Println("released")
case "wait": // 等待barrier被释放
b.Wait()
fmt.Println("after wait")
case "quit", "exit": //退出
return
default:
fmt.Println("unknown action")
}
}
}
DoubleBarrier:计数型栅栏
etcd 还提供了另外一种栅栏,叫做 DoubleBarrier,这也是一种非常有用的栅栏。这个栅栏初始化的时候需要提供一个计数 count,如下所示:
func NewDoubleBarrier(s *concurrency.Session, key string, count int) *DoubleBarrier
func (b *DoubleBarrier) Enter() error
func (b *DoubleBarrier) Leave() error
当调用者调用 Enter 时,会被阻塞住,直到一共有 count(初始化这个栅栏的时候设定的值)个节点调用了 Enter,这 count 个被阻塞的节点才能继续执行。所以,你可以利用它编排一组节点,让这些节点在同一个时刻开始执行任务。
同理,如果你想让一组节点在同一个时刻完成任务,就可以调用 Leave 方法。节点调用 Leave 方法的时候,会被阻塞,直到有 count 个节点,都调用了 Leave 方法,这些节点才能继续执行。
我们再来看一下 DoubleBarrier 的使用例子。你可以起两个节点,同时执行 Enter 方法,看看这两个节点是不是先阻塞,之后才继续执行。然后,你再执行 Leave 方法,也观察一下,是不是先阻塞又继续执行的。
package main
import (
"bufio"
"flag"
"fmt"
"log"
"os"
"strings"
"github.com/coreos/etcd/clientv3"
"github.com/coreos/etcd/clientv3/concurrency"
recipe "github.com/coreos/etcd/contrib/recipes"
)
var (
addr = flag.String("addr", "http://127.0.0.1:2379", "etcd addresses")
barrierName = flag.String("name", "my-test-doublebarrier", "barrier name")
count = flag.Int("c", 2, "")
)
func main() {
flag.Parse()
// 解析etcd地址
endpoints := strings.Split(*addr, ",")
// 创建etcd的client
cli, err := clientv3.New(clientv3.Config{Endpoints: endpoints})
if err != nil {
log.Fatal(err)
}
defer cli.Close()
// 创建session
s1, err := concurrency.NewSession(cli)
if err != nil {
log.Fatal(err)
}
defer s1.Close()
// 创建/获取栅栏
b := recipe.NewDoubleBarrier(s1, *barrierName, *count)
// 从命令行读取命令
consolescanner := bufio.NewScanner(os.Stdin)
for consolescanner.Scan() {
action := consolescanner.Text()
items := strings.Split(action, " ")
switch items[0] {
case "enter": // 持有这个barrier
b.Enter()
fmt.Println("enter")
case "leave": // 释放这个barrier
b.Leave()
fmt.Println("leave")
case "quit", "exit": //退出
return
default:
fmt.Println("unknown action")
}
}
}
我们在第 17 讲学习的循环栅栏,控制的是同一个进程中的不同 goroutine 的执行,而分布式栅栏和计数型栅栏控制的是不同节点、不同进程的执行。
STM
提到事务,你肯定不陌生。在开发基于数据库的应用程序的时候,我们经常用到事务。事务就是要保证一组操作要么全部成功,要么全部失败。
etcd 提供了在一个事务中对多个 key 的更新功能,这一组 key 的操作要么全部成功,要么全部失败。etcd 的事务实现方式是基于 CAS 方式实现的,融合了 Get、Put 和 Delete 操作。
etcd 的事务操作如下,分为条件块、成功块和失败块,条件块用来检测事务是否成功,如果成功,就执行 Then(…),如果失败,就执行 Else(…):
Txn().If(cond1, cond2, ...).Then(op1, op2, ...,).Else(op1’, op2’, …)
我们来看一个利用 etcd 的事务实现转账的小例子。我们从账户 from 向账户 to 转账 amount
func doTxnXfer(etcd *v3.Client, from, to string, amount uint) (bool, error) {
// 一个查询事务
getresp, err := etcd.Txn(ctx.TODO()).Then(OpGet(from), OpGet(to)).Commit()
if err != nil {
return false, err
}
// 获取转账账户的值
fromKV := getresp.Responses[0].GetRangeResponse().Kvs[0]
toKV := getresp.Responses[1].GetRangeResponse().Kvs[1]
fromV, toV := toUInt64(fromKV.Value), toUint64(toKV.Value)
if fromV < amount {
return false, fmt.Errorf(“insufficient value”)
}
// 转账事务
// 条件块
txn := etcd.Txn(ctx.TODO()).If(
v3.Compare(v3.ModRevision(from), “=”, fromKV.ModRevision),
v3.Compare(v3.ModRevision(to), “=”, toKV.ModRevision))
// 成功块
txn = txn.Then(
OpPut(from, fromUint64(fromV - amount)),
OpPut(to, fromUint64(toV + amount))
//提交事务
putresp, err := txn.Commit()
// 检查事务的执行结果
if err != nil {
return false, err
}
return putresp.Succeeded, nil
}
要使用 STM,你需要先编写一个 apply 函数,这个函数的执行是在一个事务之中的
apply func(STM) error
type STM interface {
Get(key ...string) string
Put(key, val string, opts ...v3.OpOption)
Rev(key string) int64
Del(key string)
}
使用 etcd STM 的时候,我们只需要定义一个 apply 方法,比如说转账方法 exchange,然后通过 concurrency.NewSTM(cli, exchange),就可以完成转账事务的执行了。
下面这个例子创建了 5 个银行账号,然后随机选择一些账号两两转账。在转账的时候,要把源账号一半的钱要转给目标账号。这个例子启动了 10 个 goroutine 去执行这些事务,每个 goroutine 要完成 100 个事务。
为了确认事务是否出错了,我们最后要校验每个账号的钱数和总钱数。总钱数不变,就代表执行成功了。这个例子的代码如下:
package main
import (
"context"
"flag"
"fmt"
"log"
"math/rand"
"strings"
"sync"
"github.com/coreos/etcd/clientv3"
"github.com/coreos/etcd/clientv3/concurrency"
)
var (
addr = flag.String("addr", "http://127.0.0.1:2379", "etcd addresses")
)
func main() {
flag.Parse()
// 解析etcd地址
endpoints := strings.Split(*addr, ",")
cli, err := clientv3.New(clientv3.Config{Endpoints: endpoints})
if err != nil {
log.Fatal(err)
}
defer cli.Close()
// 设置5个账户,每个账号都有100元,总共500元
totalAccounts := 5
for i := 0; i < totalAccounts; i++ {
k := fmt.Sprintf("accts/%d", i)
if _, err = cli.Put(context.TODO(), k, "100"); err != nil {
log.Fatal(err)
}
}
// STM的应用函数,主要的事务逻辑
exchange := func(stm concurrency.STM) error {
// 随机得到两个转账账号
from, to := rand.Intn(totalAccounts), rand.Intn(totalAccounts)
if from == to {
// 自己不和自己转账
return nil
}
// 读取账号的值
fromK, toK := fmt.Sprintf("accts/%d", from), fmt.Sprintf("accts/%d", to)
fromV, toV := stm.Get(fromK), stm.Get(toK)
fromInt, toInt := 0, 0
fmt.Sscanf(fromV, "%d", &fromInt)
fmt.Sscanf(toV, "%d", &toInt)
// 把源账号一半的钱转账给目标账号
xfer := fromInt / 2
fromInt, toInt = fromInt-xfer, toInt+xfer
// 把转账后的值写回
stm.Put(fromK, fmt.Sprintf("%d", fromInt))
stm.Put(toK, fmt.Sprintf("%d", toInt))
return nil
}
// 启动10个goroutine进行转账操作
var wg sync.WaitGroup
wg.Add(10)
for i := 0; i < 10; i++ {
go func() {
defer wg.Done()
for j := 0; j < 100; j++ {
if _, serr := concurrency.NewSTM(cli, exchange); serr != nil {
log.Fatal(serr)
}
}
}()
}
wg.Wait()
// 检查账号最后的数目
sum := 0
accts, err := cli.Get(context.TODO(), "accts/", clientv3.WithPrefix()) // 得到所有账号
if err != nil {
log.Fatal(err)
}
for _, kv := range accts.Kvs { // 遍历账号的值
v := 0
fmt.Sscanf(string(kv.Value), "%d", &v)
sum += v
log.Printf("account %s: %d", kv.Key, v)
}
log.Println("account sum is", sum) // 总数
}
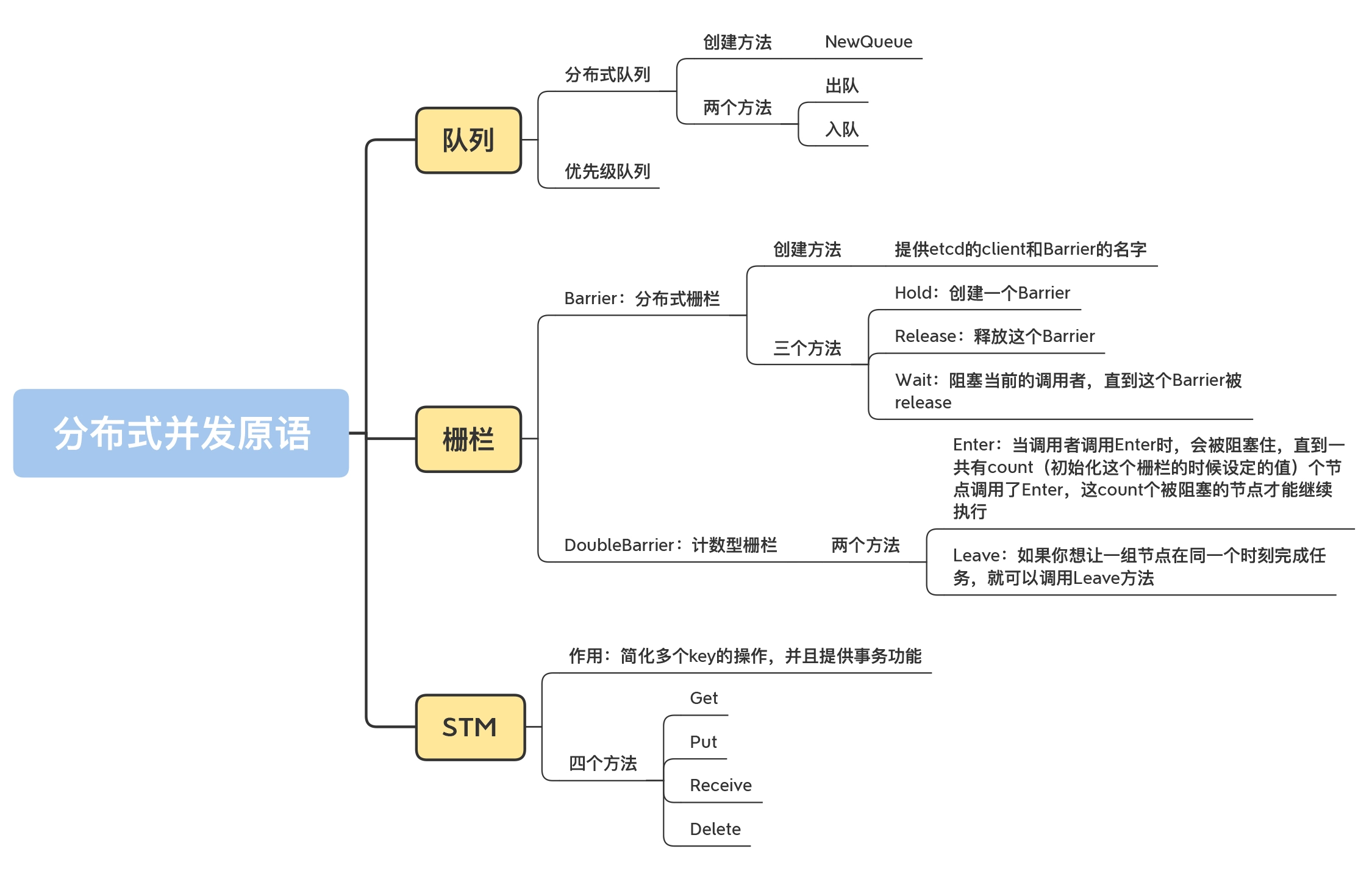
99.参考

若有收获,就点个赞吧
0 人点赞
