收集算法
- 标记清除算法 mark -sweep 算法
- 效率不算高,有内存碎片问题 分为两个阶段 标记清除阶段,最坏情况下需要遍历两次所有数据
- 需要使用空闲列表(内存碎片问题)
- 复制算法 copy
- 效率比较高,只需要复制所有的有效节点上的数据 最坏也只要遍历一次数据
- 需要耗费两倍的空间
- 当存活的对象数量特别多的时候,复制之后需要修改对象引用的地址。会比较的慢。所以使用在新生代的的区域,因为新生代的70%-99%的对象都是朝生夕死所有非常的恰当
- 没有碎片的问题,复制之后直接整理好了
- 复制压缩算法 mark-compact
- 标记阶段和标记清除一样,之后会把有用的移动到一起去,整理内存碎片的问题
- 效率比标记清除算法还要低,但是解决了内存碎片化的问题
- 增量收集算法
- 处理上面算法的同一问题 :stw
- 原理:每次标记一小块内存,用户线程和gc的线程交替进行,最后完成标记阶段。解决stw问题
- 缺点: 虽然解决了stw的问题,但是需要进行线程的切换等。
分区算法
原因:不同的对象存活时间不同,jvm内存分为 新生代,老年代 不同的对象使用不同的收集算法整体的效率比较高。
- 新生代:就使用复制算法 原因就是使用复制算法的原因
- 老年代:使用标记清除和标记压缩的混合
七种垃圾收集器得组合关系
其中垃圾收集器得介绍:
https://javayz.blog.csdn.net/article/details/109751818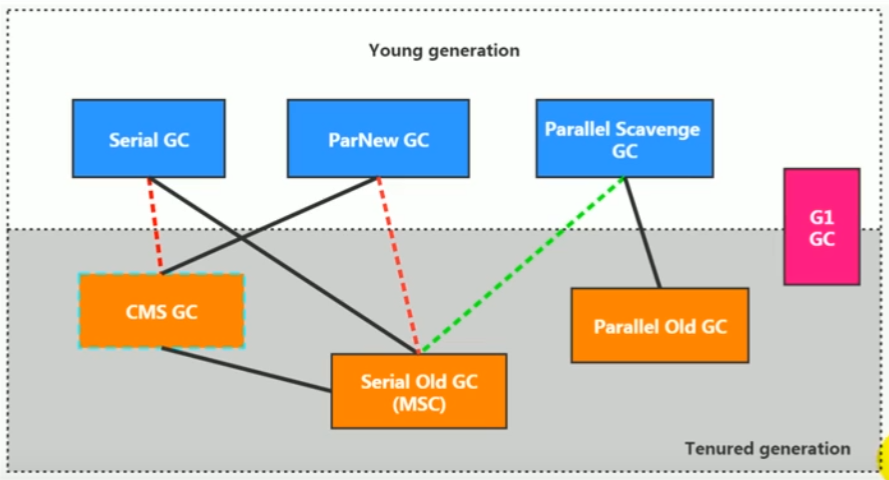
jdk 8中使用得 是 parallel Scavenge GC 和 parallerl Old GC
Serial GC
串行垃圾收集器是最基本、发展历史最悠久的收集器。
- 优点
- 在单核得cpu上运行得效率最高,实现简单,方柏霓
缺点
标记清除算法尽量得减少了停顿时间
- 并发执行,减少了gc得停顿时间
缺点

若有收获,就点个赞吧
0 人点赞
