前端
常用方法
[cy2Xm, cy2Gx, cy2Sfzjlx, cy2Sfzjh,cy2Lxdh].filter(Boolean).length
和 [cy2Xm, cy2Gx, cy2Sfzjlx, cy2Sfzjh, cy2Lxdh].some(item => !!item)
代表每个数组中每个元素都存在
- i=> [‘10’, ‘50’].includes(i.value) 用于filter方法内需要过滤的元素比较多的时候用数组
- DM_JY_XSDQZT.filter(i=>i.value === ‘’)
使用effect 代替onChange方法
const getXxxz = bxlx => {if ('111' === bxlx){setXxxz(IS_YEY_XXXZ);} else if ('111' !== bxlx && '' !== bxlx){setXxxz(NOT_YEY_XXXZ);} else if ('' === bxlx){setXxxz([]);}};const formData = $model.form.getFormData();useEffect(() => {getXxxz(formData.xxbxlxm);}, [formData.xxbxlxm]);useEffect(() => {setNj(DM_QJY_JCSJ_NJ.filter(i => i.value.startsWith(formData.sjyjd)));}, [formData.sjyjd]);
监听受教育阶段来获取学校性质
删除接口对接-传集合
export const deleteJcsjXgfkYmxx = ids => {return network.json('/jcsjXgfkYmxx/deleteJcsjXgfkYmxx.do', [...ids]);};
@PostMapping("/jcsjXgfkYmxx/deleteJcsjXgfkYmxx.do")public Result<Boolean> deleteJcsjXgfkYmxx(@RequestBody List<Integer> ids,User user) {return Result.of(jcsjXgfkYmxxService.deleteJcsjXgfkYmxx(ids,user));}
导出
export const getContextPath = () => {const basePath = window.SHARE.CONTEXT_PATH;return basePath.replace(location.origin, '');};exportList = async data => {return await this.network.fakeFormGet(`${getContextPath()}jcsjXgfkStu/exportStuList.do`, data);}
@GetMapping("/jcsjXgfkStu/exportStuList.do")
i.value.startsWith(props.user.xzqh.substring(0, 7))
后端
初始化赋值

定义一个初始化类实现CommandLineRunner接口,能够再项目启动的时候去做一些操作。例如这里在项目启动的时候自动去查询数据库学年信息,然后赋值给配置类AthenaPublicManagerProperties中的学年属性,在项目中有需要用到的时候就可以直接取值。
Optional 防止空指针
return Optional.of(qjyJcsjXxEntity).orElse(new QjyJcsjXxEntity()).getXxmc();
当不一定能查出对象且又需要取对象中属性值的时候,可能会出现空指针异常。例如这里当学校数据查不到的时候,会新建一个空对象去取值来防止空指针
证件号码MD5
证件号码可能带有字母,当前端填写为小写的时候,后端要转为大写,没有转换则为低级bug,处理方法一般在实体类中zjhm的get方法里面调用toUpperCase方法
return zjhm != null ? zjhm.toUpperCase() : zjhm;
证件号码校验
- 要么公司工具类IdCardUtil.validate
- 要么用hutool的工具类
业务思维
场景一 手动添加疫苗信息
- 疫苗有两针,手动添加前用学生id和针次去查询,用户正要添加的疫苗针次信息是否存在,已经存在的针次不能重复添加
- 手动录入疫苗接种信息有两种,一种是上述的已接种情况,另外一种是未接种的时候要填写未接种原因,新增未接种信息的时候,也要做一个考虑,判断数据库中这个学生有没有存在接种过疫苗的信息,存在的话说明已经存在疫苗接种信息,也就不能让这个学生去输入未接种信息
场景二 编辑疫苗信息 和编辑学生
- 第一针不能改成第二针,这个也是自己在项目开发过程中思考很久脑子一直没有转过来的场景
在接口中做一层防护,第一针的疫苗信息不能改成第二针的疫苗信息,其实拿查询返回的针次和要修改的针次做比较就可以了,不一样就抛异常
- 学生编辑也是一样,不能把当前学生的身份证号改成别人的身份证号
场景三 学生表有维护一个关于疫苗信息的字段
学生表中有是否接种疫苗字段,这个不仅是插入信息的时候需要改成是,还要在删除疫苗信息的时候判断当前学生下时候还有疫苗信息,如果没有的话代表学生两针都没有信息,是否接种状态应当改成否
场景四 导入添加学生
- 本校只能导入本校学生
- 导入学生,学生在数据库中存在,这时候又是分为两种,一种是数据库中的学生的学校和导入模板中这位学生的学校一致的话就是学生存在本校,反之就是在其他学校
项目中班号相关处理
背景 教育项目中将年级和班级拼接在一起作为班号,所以在一些需要分开操作的情况下需要有一些注意事项
场景一 截取显示
一般单独显示班级的时候,我们都是先对班号最后两位截取处理,但是这个时候最后两位可能是01,如果直接显示01班,显然不合理,因此我们用Integer的parseInt 方法对零进行忽略
if (StringUtils.isNotBlank(jcsjXgfkStuDetail.getBh()) && 4 == jcsjXgfkStuDetail.getBh().length()) {String bj = StringUtils.substring(jcsjXgfkStuDetail.getBh(), 2, 4);jcsjXgfkStuDetail.setBh(Integer.parseInt(bj) + "班");} else {jcsjXgfkStuDetail.setBh("");}
如上述代码所示,直接判断数据库是否有脏数据来防止报错,然后再截取方法再调用parseInt 方法从第一个非零数字开始算
场景二 条件筛选
以及再前端有班级筛选条件的时候,后端数据库是四位班号,所以应当做个处理
<if test="bh != null and bh != '' ">AND RIGHT(stu.BH,2) = #{bh}</if>
场景三 excel导入
excel导出字段 是 1班 12班这种数据,到数据库中需要转为四位标准班号 如果班级为一位数字要在前面拼接上一个零完成四位有效班号,两位就不需要
private String joinBh(String nj, String bh) {if (StringUtils.isBlank(bh)) {return "";}String bhNum = bh.substring(0, bh.length() - 1);return bhNum.length() == 2 ? nj + bhNum : nj + "0" + bhNum;}
四舍五入处理
int d = new BigDecimal(src).setScale(2, BigDecimal.ROUND_HALF_UP).multiply(BigDecimal.valueOf(100)).intValue();
又是熟悉的统计 有何不同?
背景 =》 此次的学生疫苗情况统计和和之前做的幼儿园新生入学招生情况统计相似又不相同。 功能需求相似但实现方式不同
回顾历史
在试用期做了幼儿园新生入学的统计功能,做法是根据要统计的字段,先遍历每一列再遍历每一行,让每一列的所有行里面的值相加达到统计的效果。
记得当时使用map的方式去实现功能,但是被指出“用map出入参不对,要用实体”的问题。当时的优化方式核心还是使用map,只是说在出参和入参的时候用实体,中间转成map去对数据处理。代码如下:
private YeyXsrxTjDetail rowData(Set<String> colSet, List<Map> dataList) {Map<String, Integer> resultMap = new HashMap<>();for (String col : colSet) {int count = 0;for (Map map : dataList) {Integer value = MapUtils.getInteger(map, col);if (value != null) {count += value;}}resultMap.put(col, count);resultMap.put("schoolName", null);}return BeanMapper.map(resultMap, YeyXsrxTjDetail.class);}
这次的写法变化
JzqkTjResultType jzqkTjResultType = new JzqkTjResultType();jzqkTjResultType.setSchoolName("合计");jzqkTjResultType.setZjzrsCount(sourceList.stream().mapToInt(JzqkTjResultType::getZjzrsCount).sum());jzqkTjResultType.setWzxCount(sourceList.stream().mapToInt(JzqkTjResultType::getWzxCount).sum());jzqkTjResultType.setSjzxCount(sourceList.stream().mapToInt(JzqkTjResultType::getSjzxCount).sum());jzqkTjResultType.setWjzCount(sourceList.stream().mapToInt(JzqkTjResultType::getWjzCount).sum());jzqkTjResultType.setWyjz1(sourceList.stream().mapToInt(JzqkTjResultType::getWyjz1).sum());jzqkTjResultType.setWyjz2(sourceList.stream().mapToInt(JzqkTjResultType::getWyjz2).sum());jzqkTjResultType.setWyjz3(sourceList.stream().mapToInt(JzqkTjResultType::getWyjz3).sum());jzqkTjResultType.setWyjz4(sourceList.stream().mapToInt(JzqkTjResultType::getWyjz4).sum());jzqkTjResultType.setYmdyz(sourceList.stream().mapToInt(JzqkTjResultType::getYmdyz).sum());jzqkTjResultType.setYmdez(sourceList.stream().mapToInt(JzqkTjResultType::getYmdez).sum());
对比区别
- 往日的写法主要依赖map集合,用法比较灵活,特别在字段多的情况下代码量不会明显变多
- 流的方法。相比map的方法而言,如果说map的方式做统计是简单粗暴,混元太极,什么数据一并过来统一处理的话,流的方法就是精准打击,指哪打哪,指定要统计的字段,忽略非数值类型字段。
结论
不管是从公司规范角度还是从“一目了然”的角度上看,应该是直接指出字段的流方式会好一些。虽然“万能”的map非常灵活,能写出很骚的代码,但是在特别是有些字段不是数值不需要统计的时候,还需要再做条件控制判断,无形之中增加了代码的复杂度。
使用map确实比较锻炼开发人员的思维,做各种各样的控制,但是也许对于维护来说可能不太通俗易懂,说不定自己写得代码一段时间后再回头看可能都会觉得比较陌生。
最后就是,根据规范,出入参要实体。这里用map的方式,需要做两次拷贝,一次实体集合转map,一次map转实体返回,这样明显能看出有些技术实现上的“妥协”。那么用了流的合计,就能从根本原因上解决问题。
项目中流的一些使用
先来一段最早写得反例代码 纯“人工智能”
njMatchSchool = Stream.of("11", "12", "13", "14").anyMatch(item -> item.equals(stuImport.getNj()));} else if (Arrays.asList("211", "312", "345").contains(bxlxByCode)) {njMatchSchool = Stream.of("21", "22", "23", "24", "25", "26").anyMatch(item -> item.equals(stuImport.getNj()));} else if (Arrays.asList("311", "312", "341", "345").contains(bxlxByCode)) {njMatchSchool = Stream.of("31", "32", "33", "34").anyMatch(item -> item.equals(stuImport.getNj()));} else if (Arrays.asList("341", "342", "345").contains(bxlxByCode)) {njMatchSchool = Stream.of("41", "42", "43").anyMatch(item -> item.equals(stuImport.getNj()));}
判断学校和受教育阶段是否匹配
// 判断学校和受教育阶段是否匹配List<QjyXx> xxList = qjyJcsjXxService.getXxList(stuImport.getSjyjd(), user);boolean xxNotMatch = xxList.stream().noneMatch(xx -> xx.getXxdm().equals(stuImport.getSchoolCode()));
背景 学生导入学校和和受教育阶段,想做一个填写学校是否和受教育阶段匹配的一个校验。因为导入不像是前端,可以对后端请求接口进行联动选择,所以说对于导入而言,用户可以填写受教育阶段为初中,但是学校又是填写小学的数据
所以这里就手动去调接口,查询模板中当前受教育阶段的学校,然后去匹配用户填写的学校看是否匹配得上,匹配上则符合条件
完善
导入模板中有三个字段,分别是受教育阶段、学校、年级。他们需要完成联动校验,乍一看,受教育阶段先要和学校匹配校验,学校再和年级做匹配校验、受教育阶段再和年级匹配校验,好像是挺繁琐的样子
其实不然,这里可以利用字段从左到右受教育阶段=》学校=>年级字段的循序进行校验,比如说先做受教育阶段和学校是否匹配的校验,如果通过了,说明前两个字段已经满足要求,现在只要让年级和受教育阶段对应上就好
List<CodeMapWrapper.CodeItem> njDm = codeLoader.getCodeMapByAlias("DM_QJY_JCSJ_NJ").getCodeItemOrderList();List<CodeMapWrapper.CodeItem> njFilterSjyjd = njDm.stream().filter(bm -> bm.getCode().substring(0, 1).equals(stuImport.getSjyjd())).collect(Collectors.toList());List<CodeMapWrapper.CodeItem> njResultList = njFilterSjyjd.stream().filter(item -> item.getCode().equals(stuImport.getNj())).collect(Collectors.toList());
拿到年级表码,里面有code和name,分别代表年级表码和名称。筛选出当前受教育阶段下的年级,看模板填写的年级是否存在里面,没有则年级不匹配
以此类推
项目中有发现以下代码,看上去StringUtils的方法要写好几遍,代码量大
private boolean checkNotcj(StudentSimple item) {//判断这个学生是否残疾return ((StringUtils.isBlank(item.getSlqk())&& StringUtils.isBlank(item.getTlqk())&& StringUtils.isBlank(item.getYyqk())&& StringUtils.isBlank(item.getZtqk())&& StringUtils.isBlank(item.getZlqk())&& StringUtils.isBlank(item.getJsqk())&& StringUtils.isBlank(item.getQtcj()))||(XskConstant.CjStatus.CJ.equals(item.getSlqk())&& XskConstant.CjStatus.CJ.equals(item.getTlqk())&& XskConstant.CjStatus.CJ.equals(item.getYyqk())&& XskConstant.CjStatus.CJ.equals(item.getZtqk())&& XskConstant.CjStatus.CJ.equals(item.getZlqk())&& XskConstant.CjStatus.CJ.equals(item.getJsqk())&& XskConstant.CjStatus.CJ.equals(item.getQtcj())));}
可以改成
Stream.of(item.getSlqk(),item.getYyqk(),item.getYyqk(),item.getZtqk(),item.getZlqk()).allMatch(StringUtils::isBlank)||Stream.of(item.getSlqk(),item.getYyqk(),item.getYyqk(),item.getZtqk(),item.getZlqk()).allMatch(XskConstant.CjStatus.CJ::equals)
SQL
where条件中使用子查询
<if test="ymjzStatus != null and ymjzStatus != '' "><if test="ymjzStatus == 1 ">AND stu.STU_ID in(SELECT ymxx.DX_ID from T_JCSJ_XGFK_YMXX ymxx)</if><if test="ymjzStatus == 0 ">AND stu.STU_ID not in(SELECT ymxx.DX_ID from T_JCSJ_XGFK_YMXX ymxx)</if></if>
<if test="ym1StartTime != null and ym1StartTime != '' ">AND stu.STU_ID in(SELECT ymxx.DX_ID from T_JCSJ_XGFK_YMXX ymxx where ymxx.YMZC=1 and ymxx.YMJZ_TIME <![CDATA[>=]]> #{ym1StartTime})</if><if test="ym1EndTime != null and ym1EndTime != '' ">AND stu.STU_ID in(SELECT ymxx.DX_ID from T_JCSJ_XGFK_YMXX ymxx where ymxx.YMZC=1 and ymxx.YMJZ_TIME <![CDATA[<=]]> #{ym1EndTime})</if>
<if test="hasJzYm1 != null and hasJzYm1 != '' "><if test="hasJzYm1 == 1">AND stu.STU_ID in(SELECT ymxx.DX_ID from T_JCSJ_XGFK_YMXX ymxx where ymxx.YMZC=1)</if><if test="hasJzYm1 == 0">AND stu.STU_ID not in(SELECT ymxx.DX_ID from T_JCSJ_XGFK_YMXX ymxx where ymxx.YMZC=1)</if></if>
<if test="ym1Sjly != null and ym1Sjly != '' ">AND stu.STU_ID in(SELECT ymxx.DX_ID from T_JCSJ_XGFK_YMXX ymxx where ymxx.YMZC=1 and ymxx.SJLY = #{ym1Sjly})</if>
不查询某张表的字段和筛选条件直接用到这张表字段的情况下,用子查询可以直接代替连表
SELECTstu.SCHOOL_CODE,xx.XXMC schoolName,stu.SJYJD,4cerXx.SSJD,4cerXx.SSJD_MC,xx.BXXZ,xx.xxbxlxm,sum(if(stu.STU_STATUS=10,1,0)) sjzxCount,sum(if(stu.STU_STATUS=50,1,0)) wzxCount,sum(if(stu.STU_STATUS in (10,50),1,0)) zjzrsCount,sum(if(stu.WYMJZ_REASON in (1,2,3,4),1,0)) wjzCount,sum(if(stu.WYMJZ_REASON = 1,1,0)) wyjz1,sum(if(stu.WYMJZ_REASON = 2,1,0)) wyjz2,sum(if(stu.WYMJZ_REASON = 3,1,0)) wyjz3,sum(if(stu.WYMJZ_REASON = 4,1,0)) wyjz4,sum(if(ymxx1.YMZC = 1 and stu.STU_STATUS=10,1,0)) ymdyz,sum(if(ymxx2.YMZC = 2 and stu.STU_STATUS=10,1,0)) ymdez,ifnull(sum(if(ymxx1.YMZC = 1 and stu.STU_STATUS=10,1,0))/sum(if(stu.STU_STATUS=10,1,0)),0) dyzbl,ifnull(sum(if(ymxx2.YMZC = 2 and stu.STU_STATUS=10,1,0))/sum(if(stu.STU_STATUS=10,1,0)),0) dezblFROMT_JCSJ_XGFK_STU stuLEFT JOIN T_QJY_JCSJ_XX xx ON stu.SCHOOL_CODE = xx.XXDMLEFT JOIN T_QJY_JCSJ_XX_4CER 4cerXx on stu.SCHOOL_CODE = 4cerXx.XXDMLEFT JOIN T_JCSJ_XGFK_YMXX ymxx1 on ymxx1.YMZC = 1 and stu.STU_ID = ymxx1.DX_IDLEFT JOIN T_JCSJ_XGFK_YMXX ymxx2 on ymxx2.YMZC = 2 and stu.STU_ID = ymxx2.DX_IDGROUP BYstu.SCHOOL_CODE,stu.SJYJD
sql中利用sum和if方法可以方便统计
事务和学籍遇到的事务问题
@Transctional 常见注解失效场景
@Transactional 应用在非 public 修饰的方法上
之所以会失效是因为在Spring AOP 代理时, TransactionInterceptor (事务拦截器)在目标方法执行前后进行拦截,DynamicAdvisedInterceptor(CglibAopProxy 的内部类)的 intercept 方法或 JdkDynamicAopProxy 的 invoke 方法会间接调用 AbstractFallbackTransactionAttributeSource的 computeTransactionAttribute方法,获取Transactional 注解的事务配置信息。
此方法会检查目标方法的修饰符是否为 public,不是 public则不会获取@Transactional 的属性配置信息。

@Transactional 注解属性 propagation 设置错误
这种失效是由于配置错误,若是错误的配置以下三种 propagation,事务将不会发生回滚。 TransactionDefinition.PROPAGATION_SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。 TransactionDefinition.PROPAGATION_NOT_SUPPORTED:以非事务方式运行,如果当前存在事务,则把当前事务挂起。 TransactionDefinition.PROPAGATION_NEVER:以非事务方式运行,如果当前存在事务,则抛出异常。
@Transactional 注解属性 rollbackFor 设置错误
rollbackFor 可以指定能够触发事务回滚的异常类型。Spring默认抛出了未检查unchecked异常(继承自 RuntimeException 的异常)或者 Error才回滚事务;其他异常不会触发回滚事务。如果在事务中抛出其他类型的异常,但却期望 Spring 能够回滚事务,就需要指定 rollbackFor属性
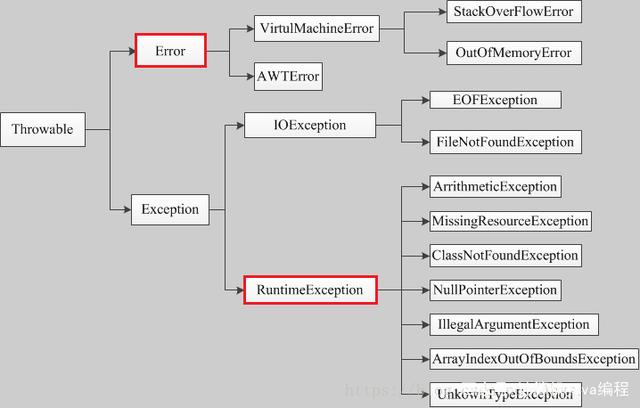
项目中我们一般指定rollbackFor = Exception.class,让属于它的子类异常触发的时候全部回滚
同一个类中方法调用,导致@Transactional失效
开发中避免不了会对同一个类里面的方法调用,比如有一个类Test,它的一个方法A,A再调用本类的方法B(不论方法B是用public还是private修饰),但方法A没有声明注解事务,而B方法有。则外部调用方法A之后,方法B的事务是不会起作用的。这也是经常犯错误的一个地方。 那为啥会出现这种情况?其实这还是由于使用Spring AOP代理造成的,因为只有当事务方法被当前类以外的代码调用时,才会由Spring生成的代理对象来管理。
说白了就是spring帮我们做了事务的创建和回滚提交,用了代理模式用代理对象对我们的业务方法做了增强,在我们具体业务方法之前做了事务创建,之后做了事务回滚和提交,如果本类普通调用就没办法走代理,没有事务包裹就失效了
解决方法
解决方法也比较简单,如果说直接调用不走Spring的机制,我们就手动获取代理对象去调用方法,让事务生效
**(实现类)AopContext.currentProxy().method()**
异常被你的 catch“吃了”导致@Transactional失效
代码中捕获了业务代码,但是没有再抛出运行时异常就会使事务失效
学籍管理中的问题代码
try {//同步学生信息xsId = sncyXsXx(jcsjByXs, item, me);List<TQjyJcsjXsJtcy> xsJtcyList = new ArrayList<>();if (jcsjXs != null) {xsJtcyList = xsJtcyMapper.queryJhrListByStuId(jcsjByXs.getId());}//同步学生家庭成员信息sncyJtcyXx(item, xsId, xsJtcyList);//学生残疾信息sncyXsCjxx(item, xsId, me);//学生属性表sncyXsSx(xsId, item, me);//校验详情表同步生成5条sncyXsJyXq(item, xsId, me, xsJtcyList, jcsjByXs);//学生校验结果sncyXsJyjg(xsId, me);//新增学籍记录addXjjl(item, xsId);item.setZt(XskConstant.ZtSfcg.SCUESS);} catch (Exception e) {item.setZt(XskConstant.ZtSfcg.FAIL);item.setJgsm(e.toString());}
并不是说用了事务注解事务就一定生效,这段代码在两年前根本没有事务的处理,在一年前加上了事务注解。然后今天接手代码的时候发现里面的操作一半成功一半失败,事务不生效,进入方法一看发现就是方法被捕获但是没有抛出运行时异常
这段代码的设计就是在实体中加了个字段专门判断是成功数据还是失败数据,在catch中对数据做失败赋值的处理。
因为这段代码在循环内处理,所以还不能简单得抛异常,否则导致循环中断,达不到需求。
解决方式
因为业务需求,我需要调两次try中的方法,因此我对需要事务处理的业务方法进行抽取为私有方法,从上层方法写条件控制,本方法只处理具体业务。
方法被本类调用,又是私有方法,干脆上编程式事务,不包裹查询的方法,对比注解包裹整个方法而言又体现了编程式事务的灵活和精确。
if ("31".equals(item.getSsnj()) || "41".equals(item.getSsnj())) {if (jcsjXs != null) {xsJtcyList = xsJtcyMapper.queryJhrListByStuId(jcsjXs.getId());}return sncyData(item, me, studentSimples, jcsjXs, jcsjByXs, xsJtcyList, reMap);}
return transactionTemplate.execute(status -> {int xsId = 0;try {//同步学生信息xsId = sncyXsXx(jcsjByXs, jcsjXs, item, me);//同步学生家庭成员信息sncyJtcyXx(item, xsId, xsJtcyList);//学生残疾信息sncyXsCjxx(item, xsId, me);//学生属性表sncyXsSx(xsId, item, me);//校验详情表同步生成5条sncyXsJyXq(item, xsId, me, xsJtcyList, jcsjByXs, jcsjXs);//学生校验结果sncyXsJyjg(xsId, me);//新增学籍记录addXjjl(item, xsId);item.setZt(XskConstant.ZtSfcg.SCUESS);} catch (Exception e) {e.printStackTrace();item.setZt(XskConstant.ZtSfcg.FAIL);item.setJgsm(e.toString());logger.error("学生{}同步发生错误", item.getXm());status.setRollbackOnly();}//说明更新成功,返回更新成功的信息(成功的ID用于新生入学更新学生同步状态)StudentSimple studentSimple = BeanMapper.map(item, StudentSimple.class);studentSimples.add(studentSimple);reMap.put("userName", me.getName());reMap.put("userId", me.getUserId());reMap.put("xsId", xsId);reMap.put("ywId", String.valueOf(item.getId()));reMap.put("ywlx", Constants.XSRX);return reMap;}

若有收获,就点个赞吧
0 人点赞
