一、Hive sql基础
1 切换到可以使用hive 的用户 —-自己的用户即可
2 hive + 回车 进入hive
1)常用命令—- show databases;
create database xuyunfeng; 创数据库
use xuyunfeng; 切换数据库
set hive.cli.print.current.db=true; 设置当前数据库名称
show tables; 显示数据库中的表
create table userinfo(id int,username string); 创表
insert into userinfo values(1,”one”); 向表中插入数据
select * from userinfo; 查看表
drop table 表名称; 删除表
2)DDL
关键词解释
· external: 创建内部表还是外部表,此为内外表的唯一区分关键字。external 创建表时如果是内表,加;如果是外表,就加上。CREATE TABLE (external) student(
· comment col_comment: 给字段添加注释
· comment table_comment: 给表本身添加注释
· partitioned by: 按哪些字段分区,可以是一个,也可以是多个
· clustered by col_name… into num_buckets BUCKETS:按哪几个字段做hash后分桶存储
· row format:用于设定行、列、集合的分隔符等设置
· stored as : 用于指定存储的文件类型,如text,rcfile等
· location : 设定该表存储的hdfs目录,如果不手动设定,则采用hive默认的存储路径
创建学生表student,包括id,name,classid,classname及分区和注释信息。
CREATE TABLE student( id string comment ‘学号‘, username string comment ‘姓名‘, classid int comment ‘班级id’, classname string comment ‘班级名称‘ ) comment ‘学生信息主表‘ partitioned by (come_date string comment ‘按入学年份分区‘) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\001’ LINES TERMINATED BY ‘\n’ STORED AS textfile;查看已存在表的详细信息 show create table 表名 /desc 表名
修改表名——-alter table 表 rename to 表2;
增加字段——-alter table student2 add columns(age int comment “我是新增加的列”);
创建视图——-create view student2_view as select id,username from student2;
删除视图——-drop view student2_view;
3)DML 装载顺序—rz -bye先传到本地,再put到hdfs,最后装载
3.1加载HDFS数据文件——-将之前的本地文件上传到自己的hdfs目录中。
hdfs dfs -put student.txt /user/xuyunfeng/
加载数据脚本
模板有分区LOAD DATA INPATH ‘filepath’ [OVERWRITE] INTO TABLE tablename [PARTITION (come_date string comment ‘入学年份’)]
范例 load data inpath ‘/user/xuyunfeng/student.txt’ overwrite into table student partition (come_date=’20170903’); titio 装载数据 先确保有本地数据,装载完后本地数据会消失
如果无分区,直接去掉 后面的partition即可。 load data inpath 路径 overwrite into 表名。
3.2将查询结果插入到数据表中
3.3多插入模式(一次查询多次插入)
3.4动态分区模式(让分区成为被查询出来的结果表的字段名称变量)· 脚本模板
INSERT OVERWRITE TABLE tablename PARTITION (col_name) select_statement FROM from_statement3.5 将查询结果写入hdfs目录
· 脚本模版
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 SELECT … FROM …·** 样例-指定输分隔符**
insert overwrite directory “/tmp/output2/“ row format delimited fields terminated by ‘\t’ select * from student where come_date=’20170905’;4)DQL
3.1 脚本模板
SELECT [DISTINCT] select_expr, select_expr, … FROM table_reference [WHERE where_condition] [GROUP BY col_list [HAVING condition]] [ CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY| ORDER BY col_list] ] [LIMIT number]升降序排 select * from table where id = “1” order by come_data desc limit3;
full join = inner join + left join + right join;
union all
将所有表数据,完全叠加在一起,不去重。 要求:所有表的字段和类型完全一致。
select * from student union all
select * from sutdent2;
union
将所有表数据,完全叠加在一起,总体去重。 要求:所有表的字段和类型完全一致。
· hive当中的子查询,必须要给予别名。
·** **NULL值判断
hql中用is NULL或者is not NULL来判断字段是否是NULL值,与””没有直接关系5)hive系统函数
show functions; —显示所有函数
desc function split; —显示某个函数怎样使用
count select count() from student; count(1)效率要高于count()
if select if(12<20,’too little’,’too old’); 成立就选第一个,不成立选第二个
coalesce select coalesce(null,null,2) 将参数列表中第1个不为null的值作为最后的值
case…when select case ‘sex’ when ‘boy’ then ‘this is a man’
when ‘girl’ then ‘this is a girl’else ‘ni dong de ‘
end;
split select split(“a,b,c”,”,”); 将字符串拆分成一个数组
explode:表成生成函数
将一个集合元素,打散成一行一行的组成,即将一行改成多行,换句话说行转列

lateral view:
与explode联用,形成一张新表
² 通过explode将一行转换成多行,通过lateral view将多行转换成一个表
原始表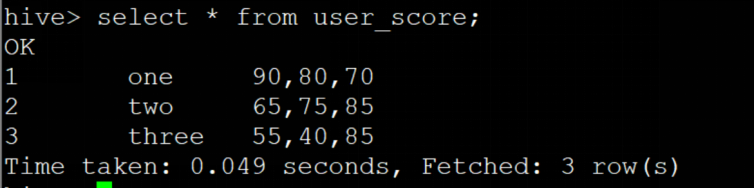
用lateral view语句查询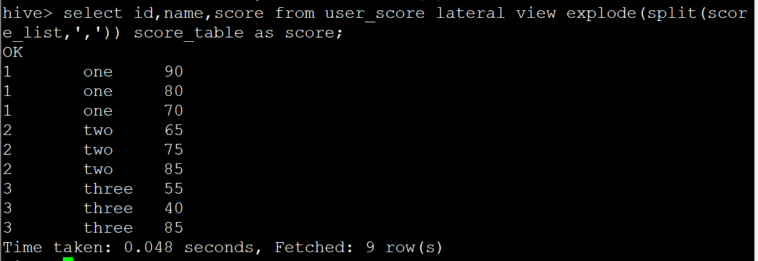
eg:² 求分数大于等于80分的有多少人

6)题总结
0.1 把所有内容取出来—-验证字段是否正确; 抽取需要字段; group by(子查询);order by(子查询); where(子查询)
1、hive子查询后面必须有别名 select x.aa from (子查询) x;
2、count 可以直接跟字段 count(score),可以在后面直接加别名
select count(distinct stdno)as fail_people,count(score)as fail_count from practice_student_score where score<60;
3、select后面想查询什么,就跟什么,用 , 隔开就可
4、2选1统计男女人数简单应用 select count(1)as total,sum(case when gender=0 then 1 end)as boy_num,sum(case when gender=1 then 1 end)as girl_num from practice_student_base_info;
5、差集、补集、并集、交集———黑白名单用差集
select select1. stdno from (select stdno from practice_course_select group by stdno)select1
except
select score.stdno from (select stdno from practice_student_score group by stdno)score;
6、inner join 可直接跟表,也可跟 查询某个表后起别名。
- (常见数据需求)结合上述表,求学生的所有的爱好标签中,受欢迎热度排行?
select tags_col,count(1) as love_num from practice_student_base_info lateral view explode(split(tags,’,’))tags as tags_col
group by tags_col order by love_num desc;
Hive函数方法
select psb.stdno,psb.name,vpsb.retags,count(1) over(partition by vpsb.retags) as tags_number
from practice_student_base_info psb
lateral view explode(split(psb.tags,’,’)) vpsb as retags order by tags_number desc;
8、多合一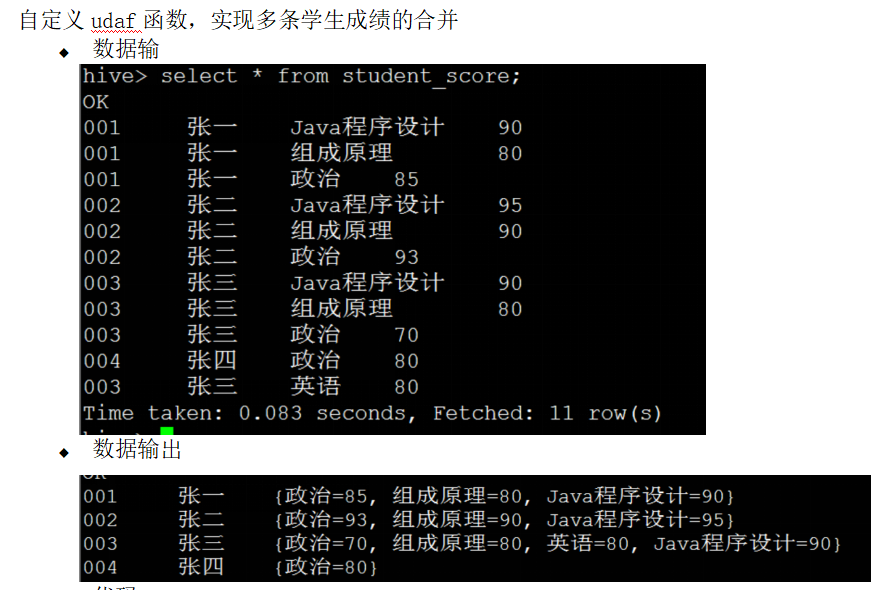 这个只处理课程名称、分数,最后直接合并了。代码中并未处理学生名称。
这个只处理课程名称、分数,最后直接合并了。代码中并未处理学生名称。
9、定义别名/字段时,注意关键字!!!! 注意格式规范!!!
10、group by可以两个字段连用 group by remark,day_hour; 意思是按remark分,再按day_hour分。
11、group by,order by 一般放最后 group by 放一个,order by 放一个,where 放一个
12、sql中还没有发现{}
13、联查时,如果两个表中有相同字段,字段前加表名以区分。不同字段可直接写字段。
14、
7) hive对数据分析的支持
Hive数据分析函数:分析函数、窗口函数、增强Group(用的极少)三类,及用于辅助表达的over从句。
使用场景:既要明细又要聚合后的数据
如:员工既要查询当前收入多少又要显示本年度收入多少;
员工既要查询当前收入多少,又要显示历史总收入多少;
购物者既要查询当前剩余多少,又要显示历史充值多少等等。
3.2 函数分类
4.求所有人的报销明细,并计算每次报销后当前公司的年度报销总金额
//重点考查order by用法,当order by后无窗口大小限制时,即为整组的第一行到当前行, //默认会追加range between unbounded preceding and current row select workno,name,cost,orderdate,year(orderdate), sum(cost) over(partition by year(orderdate) order by orderdate asc) from expense_daily;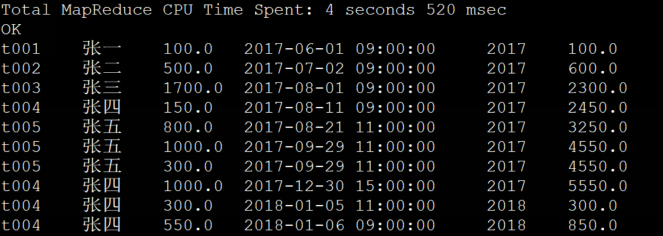
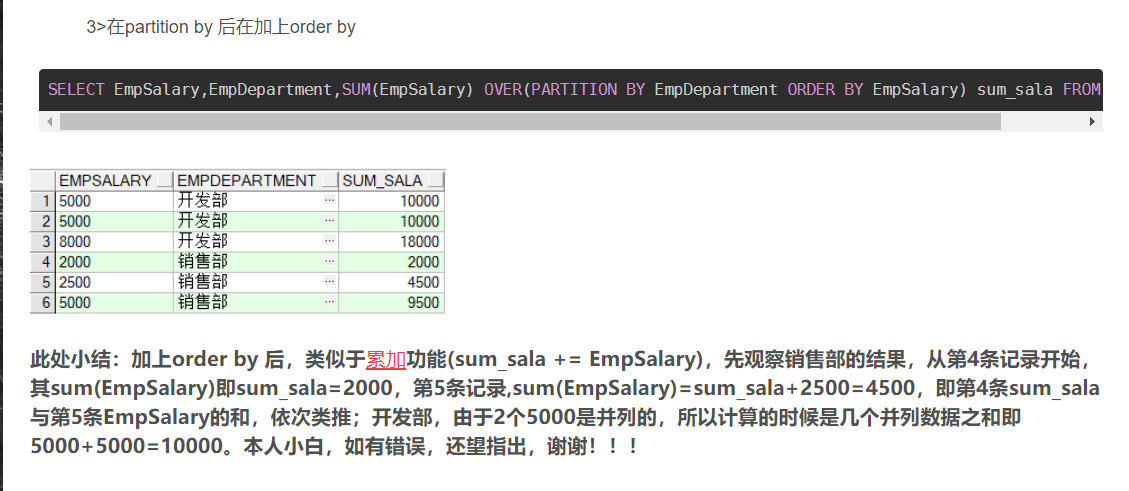
8) hive中group by 与over(partition by) 的区别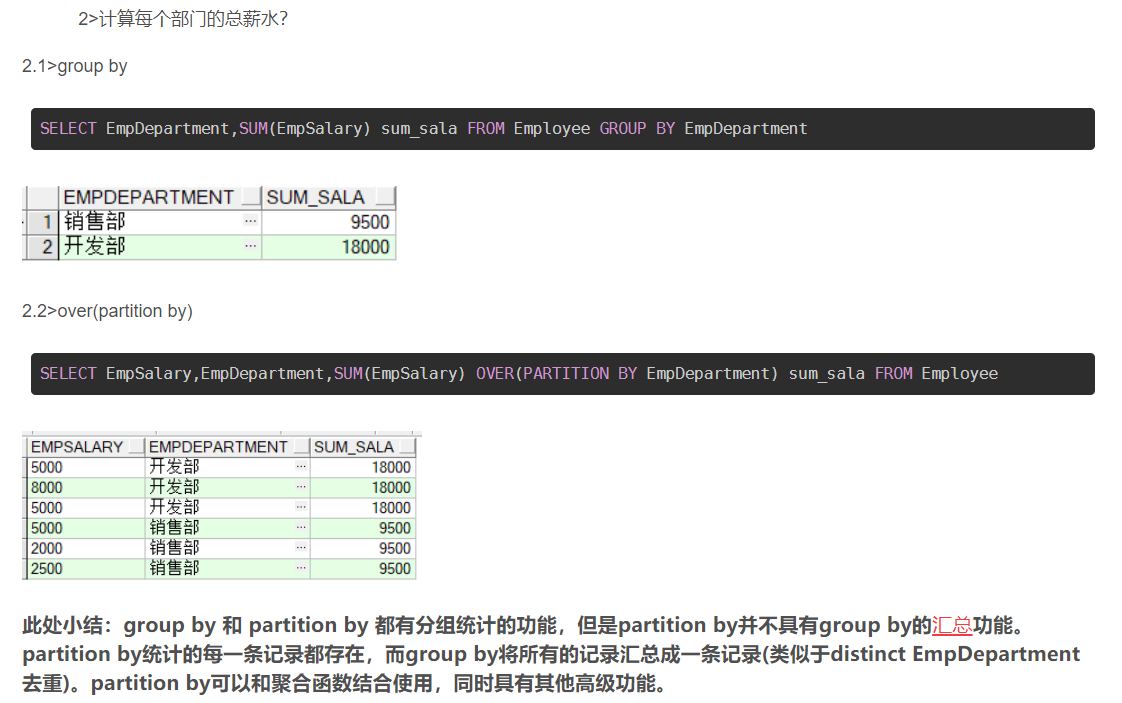

若有收获,就点个赞吧
0 人点赞
