一.概述
本篇笔记为个人学习内容全记录,参考的学习文档主要包含{骆昊先生}的《python100days》
内容若有不当还请指正
二.变量
变量是数据的载体,简单的说就是一块用来保存数据的内存空间,变量的值可以被读取和修改,这是所有计算和控制的基础。计算机能处理的数据有很多种类型,最常见的就是数值,除了数值之外还有文本、图形、音频、视频等各种各样的数据。虽然数据在计算机中都是以二进制形态存在的,但是我们可以用不同类型的变量来表示数据类型的差异。Python中的数据类型很多,而且也允许我们自定义新的数据类型(这一点在后面会讲到),这里我们需要先了解几种常用的数据类型。
猜数循环
import randomanswer = random.randint(1,100)counter = 0while True:counter += 1number = int(input('请输入:'))if number < answer:print('大于')elif number > answer:print('小于')else:print('对了')breakprint(f'你猜了{counter}次')
99乘法表
for i in range(1, 10):for j in range(1, i + 1):print(f'{i}*{j}={i * j}', end='\t')print()
判断素数
num = int(input('输入一个正整数: '))end = int(num ** 0.5)is_prime = Truefor x in range(2, end + 1):if num % x == 0:is_prime = Falsebreakif is_prime and num != 1:print(f'{num}是素数')else:print(f'{num}不是素数')
计算最大公约数和最小公倍数
x = int(input('x = '))y = int(input('y = '))if x > y:x, y = y, xfor factor in range(x, 0, -1):if x % factor == 0 and y % factor == 0:print(f'{x}和{y}的最大公约数是{factor}')print(f'{x}和{y}的最小公倍数是{x * y // factor}')break
计算一定范围内的水仙花数
# 找水仙花数min_num = int(input('请输入正整数计算范围下限: '))max_num = int(input('请输入正整数计算范围上限: '))for num in range(min_num, max_num):low = num % 10mid = num // 10 % 10high = num // 100if num == low ** 3 + mid ** 3 + high ** 3:print(num)
颠倒正整数
num = int(input('num = '))reversed_num = 0while num > 0:reversed_num = reversed_num * 10 + num % 10num //= 10print(reversed_num)
百鸡百钱问题
公鸡5元一只,母鸡3元一只,小鸡1元三只,用100块钱买一百只鸡,问公鸡、母鸡、小鸡各有多少只?
# 假设公鸡的数量为x,x的取值范围是0到20for x in range(0, 21):# 假设母鸡的数量为y,y的取值范围是0到33for y in range(0, 34):z = 100 - x - yif 5 * x + 3 * y + z // 3 == 100 and z % 3 == 0:print(f'公鸡: {x}只, 母鸡: {y}只, 小鸡: {z}只')
CRAPS赌博游戏
from random import randintmoney = int(input('输入初始金额:'))while money > 0:print(f'你的总资产为: {money}元')go_on = False# 下注金额必须大于0小于等于玩家总资产while True:debt = int(input('请下注:'))if 0 < debt <= money:break# 第一次摇色子# 用1到6均匀分布的随机数模拟摇色子得到的点数first = randint(1, 6) + randint(1, 6)print(f'\n玩家摇出了{first}点')if first == 7 or first == 11:print('玩家胜!\n')money += debtelif first == 2 or first == 3 or first == 12:print('庄家胜!\n')money -= debtelse:go_on = True# 第一次摇色子没有分出胜负游戏继续while go_on:go_on = Falsecurrent = randint(1, 6) + randint(1, 6)print(f'玩家摇出了{current}点')if current == 7:print('庄家胜!\n')money -= debtelif current == first:print('玩家胜!\n')money += debtelse:go_on = Trueprint('你破产了, 游戏结束!')
按数目需输出斐波那契数列从第三位往后的数
# 输出斐波那契数列从2往后按需数量a, b = 1, 1c = int(input('输入想要的后续数:'))print(a, b, end=' ')for _ in range(c):a, b = b, a + bprint(b, end=' ')
打印素数
# 打印素数num = int(input('素数范围:'))for num in range(2, num):# 假设num是素数is_prime = Truefor factor in range(2, num):# 在2到num-1之间寻找num的因子# 如果找到了num的因子,num就不是素数if num % factor == 0:is_prime = Falsebreakif is_prime:print(f'{num}是素数')
将重复代码收敛成函数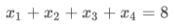
#计算阶乘m = int(input('m = '))n = int(input('n = '))# 计算m的阶乘fm = 1for num in range(1, m + 1):fm *= num# 计算n的阶乘fn = 1for num in range(1, n + 1):fn *= num# 计算m-n的阶乘fm_n = 1for num in range(1, m - n + 1):fm_n *= num# 计算C(M,N)的值print(fm // fn // fm_n)↓def test(num):answer = 1for n in range(1, num + 1):answer *= n# 返回num的阶乘(因变量)return answerm = int(input('m = '))n = int(input('n = '))# 当需要计算阶乘的时候不用再写重复的代码而是直接调用函数fac# 调用函数的语法是在函数名后面跟上圆括号并传入参数print(test(m) // test(n) // test(m - n))
可变参数函数
# 用星号表达式来表示args可以接收0个或任意多个参数def add(*args):total = 0# 可变参数可以放在for循环中去除每个参数的值for val in args:total += valreturn total# 在调用add函数时可以传入0个或任意多个参数print(add())print(add(1))print(add(1, 2, 3))print(add(1, 2, 3, 5, 7))
函数调用不讲了
无非是import module ,或者使用其中的函数from module import xxx函数 as 别名
循环遍历字符串的两种方法
s = 'abc123lht'N = len(s)# for index in range(N):# print(s[index])for ch in s:print(ch)
字符串切片和索引的基本示例
s = 'abc123lht'N = len(s)print(s[0], s[-N])print(s[N-1], s[-1])print(s[2], s[-7])print(s[-2:-8:-1])print(s[7::-1])print(s[:1:-1])
字符串大小写变换方法
s = 'abc123lht'N = len(s)d = 'ABDDD'print(s.capitalize())print(s.title())print(s.upper())print(d.lower())Abc123lhtAbc123LhtABC123LHTabddd
字符串查找的两种方法
s = 'hello, world!'# find方法从字符串中查找另一个字符串所在的位置# 找到了返回字符串中另一个字符串首字符的索引print(s.find('or')) # 8# 找不到返回-1print(s.find('shit')) # -1# index方法与find方法类似# 找到了返回字符串中另一个字符串首字符的索引print(s.index('or')) # 8# 找不到引发异常print(s.index('shit')) # ValueError: substring not found
s = 'hello good world!'# 从前向后查找字符o出现的位置(相当于第一次出现)print(s.find('o')) # 4# 从索引为5的位置开始查找字符o出现的位置print(s.find('o', 5)) # 7# 从后向前查找字符o出现的位置(相当于最后一次出现)print(s.rfind('o')) # 12
判断字符串性质
s1 = 'hello, world!'# startwith方法检查字符串是否以指定的字符串开头返回布尔值print(s1.startswith('He')) # Falseprint(s1.startswith('hel')) # True# endswith方法检查字符串是否以指定的字符串结尾返回布尔值print(s1.endswith('!')) # Trues2 = 'abc123456'# isdigit方法检查字符串是否由数字构成返回布尔值print(s2.isdigit()) # False# isalpha方法检查字符串是否以字母构成返回布尔值print(s2.isalpha()) # False# isalnum方法检查字符串是否以数字和字母构成返回布尔值print(s2.isalnum()) # True
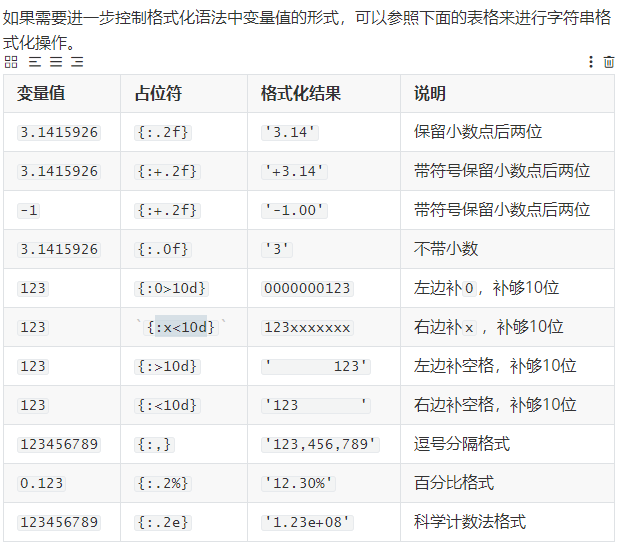
格式化字符串
s = 'hello, world!'print(s.center(20, '*'))print(s.rjust(20))print(s.ljust(20, '$'))***hello, world!****hello, world!hello, world!$$$$$$$a = 321b = 123print('%d * %d = %d' % (a, b , a * b))print('{0} * {1} = {2}'.format(a, b, a*b))print(f'{a} * {b} = {a * b}') #py3.6后开始支持,推荐使用这种方式格式化字符串321 * 123 = 39483321 * 123 = 39483321 * 123 = 39483
修剪字符串两边的空格
s = ' jackfrued@126.com \t\r\n'# strip方法获得字符串修剪左右两侧空格之后的字符串print(s.strip()) # jackfrued@126.com字符串的`strip`方法可以帮我们获得将原字符串修剪掉左右两端空格之后的字符串。这个方法非常有实用价值,通常用来将用户输入中因为不小心键入的头尾空格去掉,`strip`方法还有`lstrip`和`rstrip`两个版本,相信从名字大家已经猜出来这两个方法是做什么用的。
创建指定长度验证码函数
import randomALL_CHARS = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'm = int(input('请输入验证码长度:'))def generate_code(code_len=m):code = ''for _ in range(code_len):index = random.randrange(0, len(ALL_CHARS))code += ALL_CHARS[index]return code# 随机生成10个验证码for _ in range(10):print(generate_code())上面的函数其实还有一种更为简单的写法,直接利用`random`模块的随机抽样函数从字符串中取出指定数量的字符,然后利用字符串的`join`方法将选中的那些字符拼接起来。此外,可以利用Python标准库中的`string` 模块来获得数字和英文字母的字面常量。import randomimport stringALL_CHARS = string.digits + string.ascii_lettersm = int(input('请输入验证码长度:'))def generate_code(code_len=m):return ''.join(random.choice(ALL_CHARS, k=code_len))`random`模块的`sample`和`choices`函数都可以实现随机抽样,`sample`实现无放回抽样,这意味着抽样取出的字符是不重复的;`choices`实现有放回抽样,这意味着可能会重复选中某些字符。这两个函数的第一个参数代表抽样的总体,而参数`k`代表抽样的数量
截取文件后缀名
def get_suffix(filename):"""获取文件后缀名:param filename:文件名:return: 文件后缀"""pos = filename.rfind('.')return filename[pos + 1:] if pos > 0 else ''print(get_suffix('readme.txt')) # txtprint(get_suffix('readme.txt.md')) # mdprint(get_suffix('.readme')) #print(get_suffix('readme.')) #print(get_suffix('readme')) ##更简单的方法是直接使用`os.path`模块的`splitext`函数,这个函数会将文件名拆分成带路径的文件名和扩展名两个部分,然后返回一个二元组(下节课会讲到元组),二元组中的第二个元素就是文件的后缀名(包含`.`),如果要去掉后缀名中的`.`,可以做一个字符串的切片操作,代码如下所示。from os.path import splitextdef get_suffix2(filename):return splitext(filename)[1][1:]print(get_suffix('readme.txt')) # txtprint(get_suffix('readme.txt.md')) # mdprint(get_suffix('.readme')) #print(get_suffix('readme.')) #print(get_suffix('readme')) #
走马灯循环输出字符串
import osimport timecontent = '希 望 我 2 0 2 1 财 源 广 进 'while True:# Windows清除屏幕上的输出os.system('cls')# macOS清除屏幕上的输出#os.system('clear')print(content)# 休眠time.sleep(0.2)content = content[1:] + content[0]

若有收获,就点个赞吧
0 人点赞
